
Abstract
Sentiment analysis research has evolved over the years to extract relevant information from opinionated raw text. Sentiment lexicon is a compiled list of sentiment words and a core component of sentiment analysis tasks. These words play a key role in domain adaptation. Domain adaptation is challenging due to variation in sentiments across the domains. We propose a solution to this research problem by presenting a genre-level sentiment lexicon adaptation approach. The model uses a language domain sense to represent the genre pertaining to the distinct characteristics of the communicated text. The approach addresses the generalization of knowledge at the genre level by learning the multi-source domain lexicon for the selected source domains. The novelty of our approach lies in the genre level relevancy of the source lexicon to the target domains. The model uses unlabeled training data for the source and target domain sentiment lexicon learning. The lexicon adaptation is demonstrated on a long list of target domains that address the three domain adaptation challenges. Experimental results have proved that the model learns the relevant scores and polarities of sentiment words, in addition, it identifies new domain-based sentiment words. The model is evaluated in comparison with standard baselines.
Keywords
Introduction
Sentiment analysis research has evolved over the decade. The model processes opinionated raw text to provide relevant information [18, 30]. Sentiment lexicons are the fundamental components of sentiment analysis tasks. Sentiment analysis approaches are best performed with domain-based sentiment lexicons [17, 20]. A sentiment lexicon learned from one domain performs sub-optimally when applied directly to other domains. The major reason behind the suboptimal results is the variation in the polarity of the sentiment words across the domains. The polarity of the sentiment word, “short” varies with the variation of the domain. It provides a negative sense in the clothes and kitchen equipment consumer review domains as exhibited in the below sentences, where short costumes and short holes on a streak knife indicate negativity.
“I’m about 6’2, and the costume was way too short for me.”
“The steak knife holes are too short.”
However, it carries a positive sense in the Amazon instant video domain as illustrated in the below statement, where short videos are a convenient fit into daily schedules.
“A big plus for my lifestyle to have short shows to watch on a daily basis.”
Variation in the polarities of sentiment words makes it essential to introduce domain-based sentiment lexicons. However, creating sentiment lexicons independently for an infinite number of domains is an impractical task. This research gap is addressed by knowledge transfer between domains, well known as domain adaptation. Sentiment lexicon learning based on domain adaptation has been under study over the last few years [2, 35]. Domain adaptation is challenging owing to the following three major reasons: The changeover in the polarity of a sentiment word across the domains A variation in the relevancy/score of a sentiment word across the domains Identification of domain-specific sentiment words.
Domain adaptation and specifically, sentiment lexicon adaptation overcome all the three above mentioned challenges to some extent.
Knowledge transfer between domains is studied under different architectures. Domain adaptation approaches are well known for a one-to-one domain knowledge transfer, wherein the knowledge from a single source domain is adapted to a single target domain [17, 20]. However, it is observed that the adaptation task may not perform equally well with a variation of the source or target domain. Therefore, the major challenge of selecting a source domain for adaptation remains unaddressed. This introduces a limitation on the generalization of domain adaptation. Multi-domain adaptation is another architecture with limited studies that requires exploration. Another common reason for the variation in the domain adaptation results is the significant difference between the source and target data distributions. An intuitive solution for these research gaps would be multi-to-multi domain adaptation with the consideration of the relevant domains.
Most domain adaptation approaches use labelled data from the source domain and use limited or no labelled data from the target domain [2, 40]. Supervised approaches perform well; however, demand labelled data. With numerous domains, it is extremely impractical to produce manually labelled data. Although, it is rare to find approaches that eliminate the labelled data, the availability of such approaches may open new possibilities [23, 31].
In this article, we propose a novel genre-level lexicon adaptation approach. A genre indicates a style or a particular category. The model uses a language domain [31, 40] sense to represent a genre. The text data in each mode of communication has distinct characteristics, patterns of text, and style of writing, which we refer to as a genre. Such as consumer reviews tend to be descriptive but close to the spoken language and tweets tend to be concise. The proposed model presents a multi-to-multi domain adaptation process for the same genre domains. The general process of domain adaptation involves a source domain lexicon and its mapping to the target domain. The central focus of traditional adaptation research is on the adaptation process. Our approach differs in this aspect by creating a quality lexicon for adaptation. The model develops a method of selecting those source domains that learn lexicons using a progressive learning mechanism. Subsequently, it creates a genre lexicon and then propagates the knowledge to the target domain. The model uses unlabeled data for the source and the target training. The only labelled information is standard 14 polarity seed words. The adaptation process is generalized by aggregating the source domain knowledge that addresses the one-on-one domain adaptation problem. The model demonstrated results using a linear classification on a number of target domains.
Following are the major contributions A novel genre-level lexicon adaptation approach that is independent of existing lexicons. A multi-to-multi domain adaptation approach that learns knowledge from multiple source domains and transfers that knowledge to multiple target domains. The model uses unlabeled training data for source and target domain sentiment lexicon learning The model is compared with the competitive baselines and the recent research work from literature.
The remainder of this paper is organized as follows. Section 2 reviews the related research works. The proposed model is presented in Section 3. Experimental details about the data, preprocessing, and baselines are given in Section 4, and the experimental set-up is presented in Section 5. Details of the comparative experimental results and qualitative analysis are presented in Section 6. Conclusions and future directions are specified in Section 7.
Related work
The knowledge transfer between different domains is studied using various approaches. Considering the generic adaptation style between source and target domains, the approaches are of two types. Some approaches build a relation between the source and target domains for adaptation [2, 41]. Other approaches use some form of seed or lexicon information and adapt to the target domains [16, 31]. We present brief literature on these two and multi-source domain adaptation approaches.
One of the initial studies under the first approach was structural correspondence learning [2]. This method induces a correspondence between the source and target domains using the features that occur frequently in both the domains. Features play a central role in achieving adaptation. A heuristic kernel [7] approach is used to augment features by producing domain-specific and global [38] copies. Principal component analysis and the sample selection method [41] are performed to achieve closeness between the domains; it adapts the word scores from the source domain to the target domain. Active query strategy learns the most informative instances [39]. The general sentiment information is adapted to the target domain using a domain-specific sentiment similarity. A normal embedding is converted to a sentiment embedding using generic queues [9]. Most of these approaches use a labelled source and target instances. Unlike these approaches, our model uses unlabeled data for both the source and target domain training.
The second approach uses some form of a seed or lexicon from the source domain or general purpose lexicons and adapts to the target domain. The advantage in using this approach is that it provides the scope to learn new sentiment words from the target domain. This is important because the polarities and relevance of sentiment words vary over domains and time [14]. Broadly, the aforementioned approaches use relevant lexicons, general-purpose lexicons, or their combination [16]. An initial similarity-based research [16] used a relevant lexicon containing manually selected adjective list as the seed list, wherein the sentiment words were learned by applying synonym and antonym relations. Different seed lexicon based approaches are tested, such as relation-based and rule-based [10, 25]. In the past, general-purpose lexicons such as Wordnet was prominently used and explored for domain-based research [16]. A general-purpose sentiment lexicon is adapted [4] to build the relationship between a word and the expression level polarity using a set of constraints and integer linear programming. Sentiwordnet is adapted [22] in local contextual analysis. This approach is further explored for lexical and non-lexical analyses such as negation, intensification, discourse, emoticons, and letter repetition. A rule-based approach [27] is tested for the vector representation of contextual words. In this case, vectors are transformed to two-dimensional representations, and sentiment scores are calculated using a senti-circle mechanism. This approach is proposed to adapt general-purpose sentiment lexicons to Twitter data [28]. Multiple existing sentiment lexicons are combined [31] using common words with the same polarities. The combination is used as the base lexicon and expanded using point-wise mutual information (PMI). The process applies heuristic rules to add recognized sentiment words and remove the unwanted words from the sentiment lexicon for short text. Xing et al. [40] proposed a sequential learning domain lexicon adaptation approach. The approach uses several heuristics rules and adapts Senticnet to learn the target domain lexicon. The above process is based on cognitive supervision, which tracks incorrectly predicted sentences and uses them for supervision. A multilayer perceptron (MLP)-based positive and unlabeled (PU) learning approach [36] identifies sentiment words. This approach performs a double dictionary search in a Chinese dictionary to classify social media instances. A different end-to-end multi-layer perceptron approach [1] embeds the score in neural network weights. This model is trainable to numerous domains with supervision. In these approaches, the relevant seed lexicons play a vital role in performance improvement. Our research falls under this category and is focused on using a relevant seed lexicon. Our model does not use a manually created or general-purpose lexicon, instead, it automatically learns a genre lexicon for adaptation.
Multiple source adaptation has been studied theoretically [32] and experimentally [12, 42]. A two-stage multi-source domain adaptation [31] uses data from multiple sources. It re-weights the data first based on the marginal probability differences and then on the conditional probability differences between the source domains. This approach adapts multiple source domains to a single target domain and focuses on acquiring a relevant calculated combination for adaptation. A probabilistic generative model is proposed for the classification of multiple source and target domains by assigning each word a domain label, domain-dependent/independent label, and polarity [42]. A stacked denoising auto-encoder is used to build a high-level representation to learn the generic knowledge [12]. A multitask learning approach is proposed to learn from multiple domains [38]. This approach extracts global and domain-specific words, which are transferred to the target domain using the sentiment graphs of the words. Like our approach, the adaptation process segregate source and target domains. Also, similar to the approach [12], we use multiple domains and unlabeled training data. The knowledge learned from the set of source domains is adapted to numerous target domains. The model is described in the following section.
Proposed approach
In this section, we present a three-stage learning process, as depicted in Fig. 1. The process begins with preprocessing and domain clustering, which segregate the source and target domains. In the second stage, the learning mechanism is applied to the source domain that learns improved source domain lexicons. As a next step, a genre lexicon is created from the improved source domain lexicons. Finally, a genre lexicon is adapted to expand the target domain lexicon by learning from the target domain corpora.
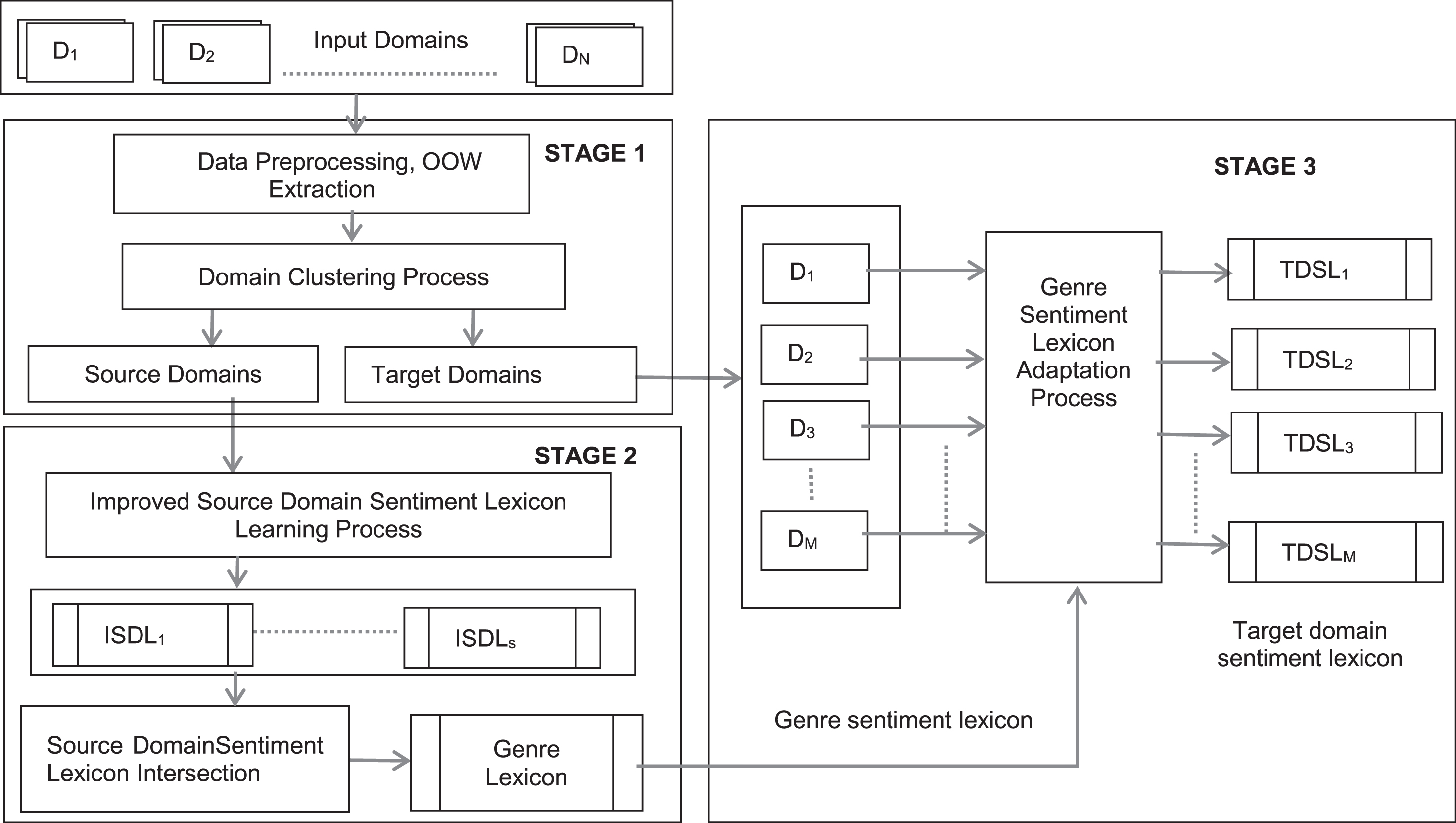
Model Schematic.
In the first stage, the data are preprocessed for noise removal, which includes the removal of unwanted characters such as URLs and non-ASCII characters, replacement of repeating characters, and application of a spell-check filter. Tokenized sentences are POS tagged and lemmatized [33]. This approach considers adjectives, adverbs, verbs, and nouns, excluding proper nouns and auxiliary verbs, as opinion-oriented words (OOWs), as proven in prior studies [16]. As a final preprocessing step, the OOWs are converted to lowercase, and the data are passed to the next process. Our approach involves “N” domains belonging to the same gene characterized by a specific form of content. The domain selection process identifies the source and target domains using a clustering approach. Document clustering is widely used in the literature [19]. Our model works at the domain level using a similar concept wherein the domains are grouped, such that the similarity tends to be high within a group and low across groups. A matrix containing the domain level tf–idf values of the OOWs used to generate the similarity scores between the domains using cosine similarity. The affinity propagation clustering algorithm [3] is applied to the similarity matrix to generate domain clusters. The clustering technique simultaneously considers all the data points as cluster centers and automatically identifies new cluster centers without any predefined input about the number of clusters or cluster center. The process groups “N” domains D1, D2, D3 …,D N into “S” clusters. The S cluster center domains act as the source domains, and the “N - S = M” cluster members act as the target domains.
Source sentiment lexicon learning
The second stage performs the genre lexicon learning process in two steps. The first step is an improved source domain sentiment lexicon (ISDL) learning, and the second step creates a genre lexicon.
The first step is depicted in Fig. 2. The sentiment lexicon learning process uses the latent semantic analysis (LSA) [8] technique, which in turn uses a truncated singular value decomposition (SVD). An OOW-review tf–idf matrix, A
pXq
, is formed for a domain, D. Each cell a
ij
in the matrix stores the tf–idf score of the i
th
OOW in the jth review. This matrix is decomposed into three matrices: matrix U
p
representing the OOW, matrix V
q
representing the reviews, and singular value matrix Σ
pXq
. Matrix reconstruction involves truncated SVD that considers only the first ‘k’ columns of matrix U
p
and first ‘k’ singular values Σ
k
, as expressed in Equation (1). This modification reduces the most matrix computations and improves the scalability of the model.
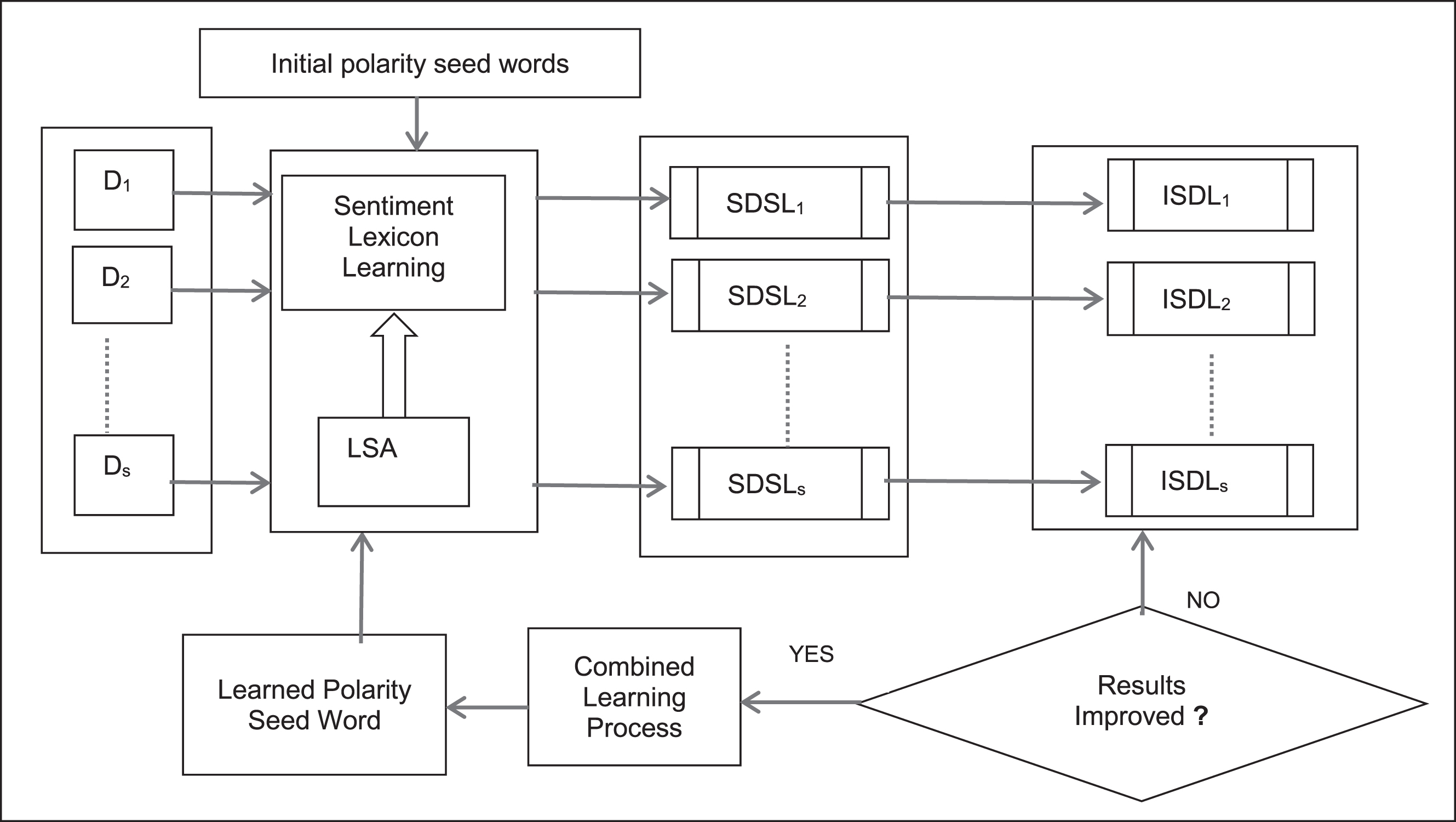
Source domain sentiment lexicon learning process.
Sentiment scores are calculated for the OOWs corresponding to a row vector in M. The learning process uses labelled seed words. Pseeds represents a set of strong positive seed words, and Nseeds represents a set of strong negative seed words.
The score of a sentiment word is calculated using Equation (2). A positive score is the average cosine similarity between the word vector and ‘p’ seed word vectors. Similarly, the negative score is calculated. The process constructs a source domain sentiment lexicon (SDSL) where ‘w’ is a number of sentiment words in a domain. The source domain sentiment lexicon evaluates on a validation set. The research in [29] presented a partially similar process. Sentiment words from the learned source lexicons with the same polarity across “S” source domains form the positive set and negative set along with the average score across all the source domains. The positive and negative sets are arranged in descending order of the absolute scores. The process uses threshold P for selecting the top seed words. The top P seed words from the positive and negative sets form a new seed word set. Every new lexicon learning iteration uses a new learned set of seed words, as shown in Fig. 2. The process continues with the next iteration if the current iteration achieves an improved accuracy across all the source domains when compared to that in the previous iteration. The process stops when the current iteration does not display an accuracy improvement across all the source domains compared to that in the previous iteration. The sentiment lexicons from the previous iteration are considered as the improved source domain lexicons (ISDLs).
The ISDLs are intersected to form a genre lexicon. A sentiment word having the same polarity across all the ISDLs and polarities to the genre lexicon. It is assigned the average score across all the ISDLs. The newly created genre lexicon is used in the next stage.
Every domain has its own set of sentiment words and their domain-level relevancy. This last stage is focused on identifying domain-based sentiment words and to learn their domain-based scores. In this learning setup, the genre lexicon from the previous stage is the input lexicon for the adaptation. The proposed model uses a co-occurrence association approach for polarity assignment. A well-known co-occurrence approach is oint-wise mutual information (PMI) [5]. This proven approach is widely used in sentiment analysis studies to identify the association between a sentiment word and a seed word [31, 34]. PMI is studied in depth for variations [26] and generalization [6]. A generalization study in the ranking context using globally weighted PMI achieved improved results. In this approach, the prior PMI score was multiplied by the co-occurrence probability.
The generalization approach is more relevant to our research problem as it offers an opportunity to generalize our model at the genre level.
Thus, we use the variation in the weighted PMI. It is expressed in Equation (3), where ‘a’ represents the sentiment word from the target domain and ‘b’ represents the sentiment word from a genre lexicon. Weighted PMI uses prior scores of the sentiment word from the genre lexicon, which is represented as sco(b). Notation p(.) in Equation (4) represents the probability of occurrence, e.g., p(a), and p(a, b) is the probability of occurrence of ‘a’ and probability of co-occurrence of ‘a’ and ‘b’, respectively, in the target domain.
POOW represents a set of positive words and NOOW represents a set of negative words from the genre lexicon. The score of a sentiment word “a” is the difference of its average PMI with a POOW and that of its average PMI with a NOOW, as in Equation (4).
The process calculates the score for a sentiment word to learn the target domain sentiment lexicon (TDSL), which is evaluated using the process described in the next section.
This section describes the data source, baselines, and evaluation. The model uses Amazon consumer product reviews from 24 domains [15]. The data are split into non-overlapping training,validation, and test sets. The training set for each domain contains 80,000 unlabeled reviews. The test sets contain 20,000 and the validation set contains 3000 labelled reviews with a balanced polarity class distribution.
All the experimental results including the baselines in this research are evaluated using binary classification. The score of a review is calculated by adding the sentiment scores of all the words from a review by referring the scores from the sentiment lexicon. Missing words are assigned a zero score. A review is classified as positive or negative based on the polarity of the aggregate score. The sentiment lexicon is evaluated using standard accuracy and F-measure evaluation measures.
The proposed model results are compared in two set-ups: general-purpose lexicon adaptation and recent lexicon adaptation research [40].
In the first set-up, the lexicon for the adaptation is created by intersecting a general-purpose lexicon with the polarity of the sentiment words. It is observed in prior studies that the adaptation of common words and the removal of polarity conflicting words across general-purpose lexicons yield an improved performance compared to individual general-purpose sentiment lexicon adaptation [31]. The study proved that the combination of four lexicons performs the best compared to other combinations and the individual lexicon adaptation. We consider the same general-purpose sentiment lexicon, which includes an opinion lexicon (OL) [16], a multi-perspective question-answer lexicon (MPQA) [37], and a general inquirer (GI) [11]. We replace the finance domain lexicon with the NRC emotion lexicon (NRC) [21]. We conducted experiments using individual lexicons, their combinations, and intersection. We observed that most of the baseline model results were not noteworthy, and the combined lexicons displayed extremely poor results. Therefore, only significant experiments representing the intersection of the sentiment lexicon are included as the baselines. The three baselines are composed of the intersection of two, three, and four general-purpose sentiment lexicons with sentiment words and their polarities to create a base lexicon for the adaptation. Sentiment words with conflicting polarities are removed. The sentiment lexicon, (OL ∩ NRC), contains 673, 1675, (OL ∩ NRC ∩ GI) contains 490, 1039, and (OL ∩ NRC ∩ GI ∩ MPQA) contains 482, 1029 positive and negative sentiment words, respectively. The baseline sentiment lexicon carries a discrete score. Thus, the baseline sentiment lexicon is adapted using a standard PMI approach.
In the second set-up, we compare our model results with a similar language domain lexicon adaptation model, a cognitively inspired domain adaptation model (CIDA) [40]. The CIDA model demonstrates SenticNet adaptation. As specified in the CIDA model, we used the Blitzer test data [2] for apparel, electronics, kitchen, healthcare, and movie domains containing 1000 positive and 1000 negative reviews for evaluation using the respective learned target domain sentiment lexicons. The experimental set-up is discussed in the following section.
Experimental set-up
This section describes the set-up used in the experiments at different stages of the proposed study. In the source and target domain selection, 24 domains are grouped into 6 clusters. Six cluster representative domains act as the source domains, and they are listed under the “Cluster Centers” column in Table 1. Eighteen cluster member domains acts as the target domains, and they are listed under the “Cluster Members” column in Table 1. Following the domain selection, the source domains learn the sentiment lexicons. The sentiment lexicon learning experiment uses two major parameters and selects them experimentally. In the experiment, the parameter ‘k’ value varies from 50 to 500 and the parameter ‘P’ value varies from 10 to 40. The iterative process learns the ISDLs. The sentiment word polarity statistics of the ISDLs are tabulated in Table 2. The genre lexicon is created from the ISDLs. The genre lexicon contains 536 positive and 559 negative sentiment words. The genre lexicon acts as the source lexicon in the adaptation process and learns the domain-based sentiment words and scores from the unlabeled target domain corpora. The genre lexicon is adapted to 18 target domains that learn domain-specific lexicons. The sentiment word polarity statistics of the learned target domain lexicons are listed in Table 3. Overall, the number of positive sentiment words varies from 3800 to 7500 and negative sentiment words varies from 1800 to 6000. We excluded the words with an approximately zero score from the sentiment lexicon. The number of positive sentiment words is larger than that of negative sentiment words. The target domain sentiment lexicon evaluation results and analysis are given in the following section.
Domain cluster centers and cluster members
Domain cluster centers and cluster members
Improved source domain sentiment lexicon (ISDL) polarity statistics
Target domain sentiment lexicon (TDSL) polarity statistics
This section presents the sentiment lexicon adaptation results and analysis of the target domain. The first subsection presents the proposed lexicon adaptation results in comparison to the baselines using two approaches: comparison with the baseline lexicon adaptation results, and comparison of our model results with the recently conducted lexicon adaptation research [40]. The statistical analysis test results are discussed in the second subsection. The third subsection presents the qualitative analysis of the sentiment lexicons learned by the target domain as a case study.
Sentiment lexicon adaptation results and evaluation
Our model achieved the highest accuracy of 86.04% and the highest F-measure of 86.0% in the toys & games domain compared to those in the other domains. The comparative accuracies and F-measure results are depicted in Figs. 3 and 4, respectively.
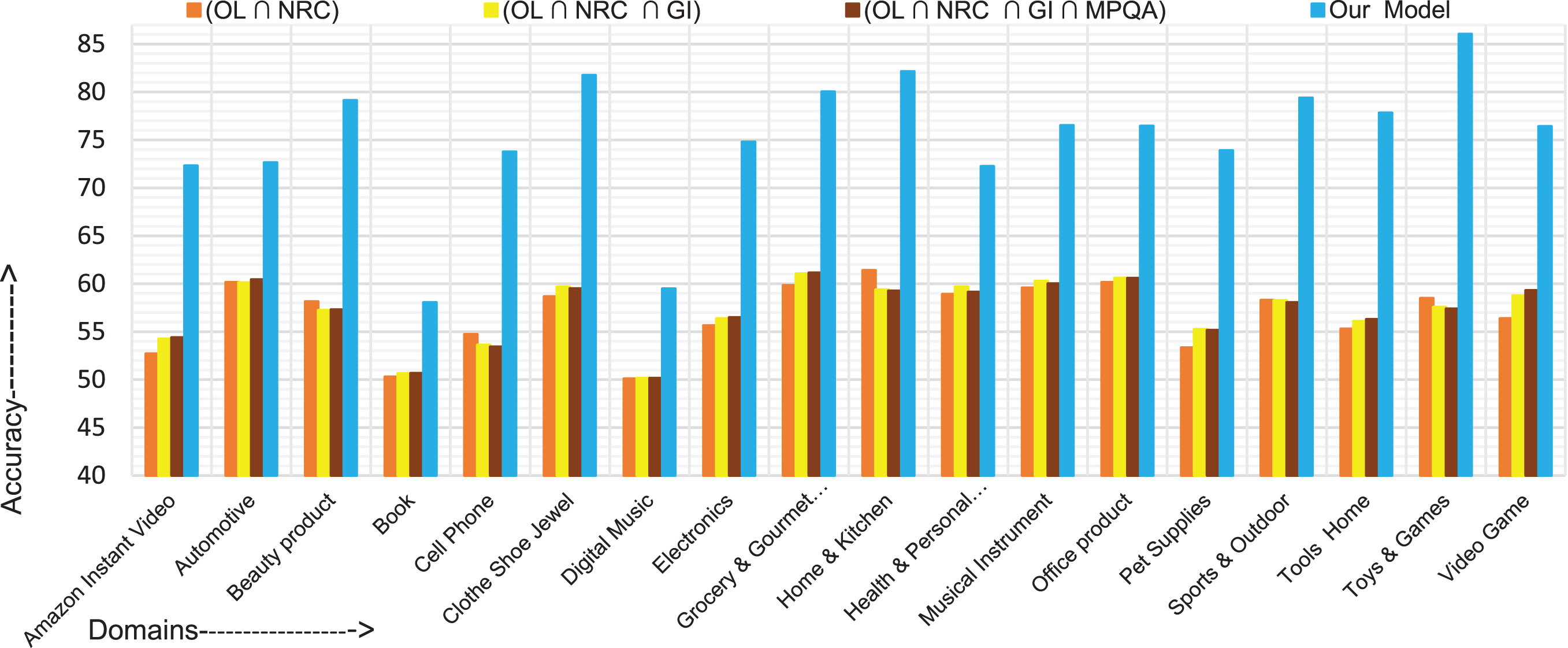
Accuracy comparison of the proposed model with the baselines.
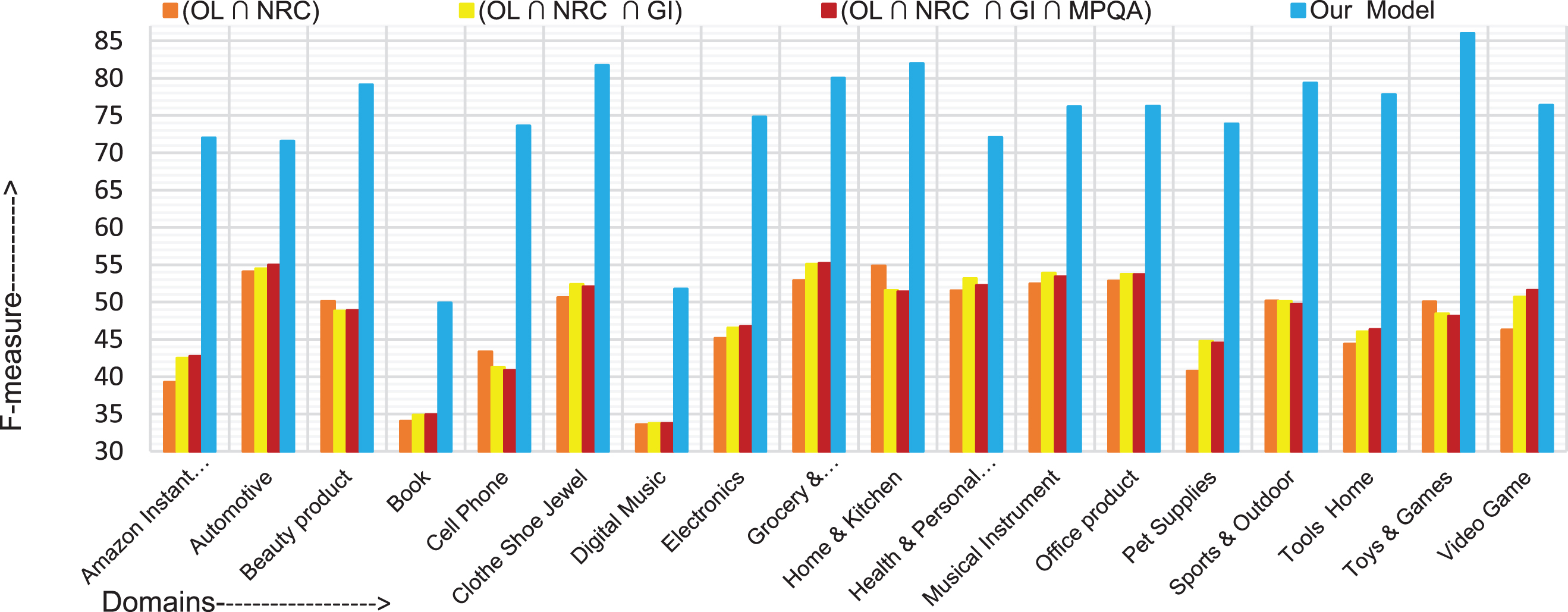
F-measure comparison of the proposed model with the baselines.
“Our model” displays improved results in the majority of the domains when compared to the baselines using both the evaluation measures. The model achieves an average accuracy of 75.16% and an average F-score of 74.14%.
The best performed domain shows a trend of a greater number of positive sentiment words than the number of negative words, as per Table 3. The book and digital music domains contain more negative sentiment words than the number of positive sentiment words. Thus, these two domains denoted a little deep in results. Among all the baseline intersection lexicon (OL∩ NRC∩GI) displays an improvement in the average results. The learned lexicon of the baseline contains a larger number of negative sentiment words than the number of positive sentiment words. This seems to be the reason behind the relatively lower performance of the baseline models.
Domain/lexicon adaptation is well studied and experimented in the past. Our work cannot be directly compared to other lexicon adaptation approaches because the typical lexicon adaptation approaches focus on the adaptation process. The proposed approach largely focuses on learning a meta lexicon for the adaptation, which simplifies the remaining adaptation process. Moreover, most of the research use labelled training data from the source and target domains or are studies that are conducted on different genres of data, such as Twitter data [31]. The CIDA model [40] adapts the SenticNet lexicon. The domains used in our model belong to the same genres used in the CIDA model. The comparative results with the CIDA model are listed in Table 4. Our model results exhibit an improvement in the accuracy in all the domains when compared to the CIDA model. Overall, an improvement of 5.0 to 8.4 points is achieved across the domains relative to the CIDA model results.
Accuracy comparison of the proposed model with the CIDA model
The Single-factor analysis of variance (ANOVA) test is conducted to determine the difference in the accuracies and F-measures of all the models across the various domains. The p-value obtained in the ANOVA test is less than 5 % for accuracy measure (F(6, 119)=80.04, p = 0.0000) and for F-measure (F (6,119)=68.06, p = 0.0000), which suggests that there is a significant difference between the models. The subsequent analysis results of Tukey’s post-hoc test at a 95% confidence level for accuracy and F-measure are listed in Table 5. The results show that the proposed model is statistically significant compared to all the baselines, and it depicts a statistically significant increase in the mean at a 95% confidence interval.
Turkey’s Post-hoc analysis test results of the proposed model versus the baseline results (column 2)
Turkey’s Post-hoc analysis test results of the proposed model versus the baseline results (column 2)
Our learned domain-based lexicons address the domain adaptation challenges. The domain-based sentiment words captured by our model are discussed in the following subsection.
This section presents the analyses and exploration of the proposed genre-based domain adaptation approach through different case studies. The qualitative analysis considers 26 representative words that are present or absent across 18 target domains.
The case studies sequentially address the three domain adaptation challenges specified in section 1.
The sentiment words adapt to domain-based polarities. The sentiment words are observed with varying polarities across the domains, as depicted in Fig. 5, using the words “cut,” “small,” “manual,” and “dark.” The word “cut” has a positive polarity in the health & personal care, tools home, and automotive domains, and negative polarity in all the other domains. A sentence, “blade is very sharp and cuts very well,” from the tools home domain indicates a positive sense. Sentiment word “dark” has a negative polarity in the Amazon instant video and book domains, and positive polarity in the remaining target domains. A sentence from the cell phone domain admiring dark color states, “Plus the phone’s color is a dark midnight blue.” In general, the sentiment word “manual” pertains to a negative sense. However, it possesses a positive sense in pet supplies and grocery domains, indicating the sense of a manual touch. Sentences from the grocery domain express similar emotions: “I’m using a Saeco manual espresso machine with Starbucks coffee.” Sentiment word “manual” also possesses a positive sense in the automotiv, book, and Amazon instant video domains, representing an instruction guide or information sense.
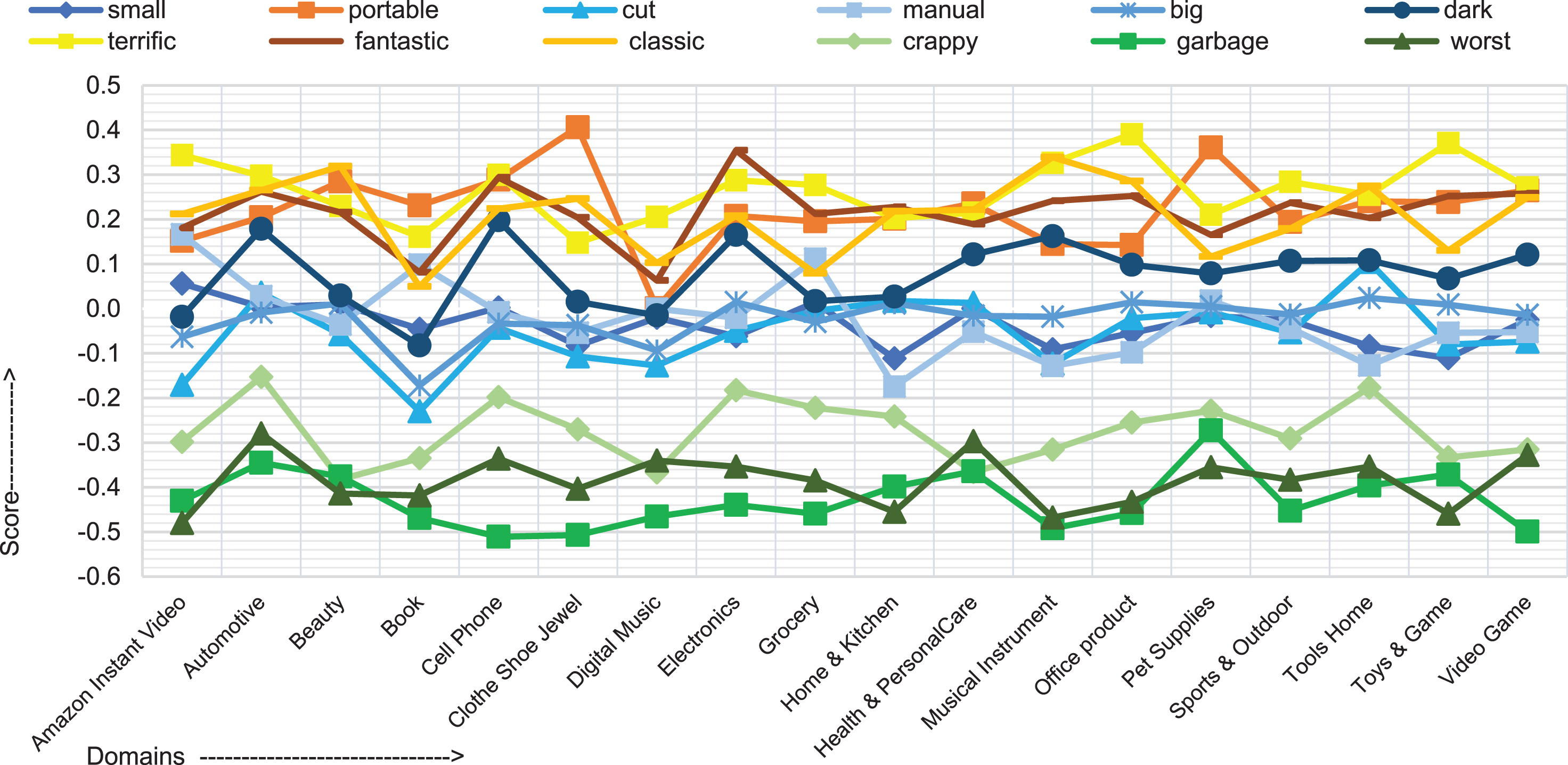
Sentiment word scores across different domains.
The score of a sentiment word displays the relevance of the sentiment word to the domain. The relevance of a sentiment word varies with the domain. Certain sentiment words such as “portable,” “excellent,” “superb,” “great,” “terrific,” “fantastic,” “enhance,” “classic,” “best,” “complex,” and “easy” are positive across all the target domains. Sentiment word “portable” is more significant in the context of the clothes shoe & jewels and pet supplies domains because handiness plays a major role. However, it is comparatively less significant in digital music and other domains. Sentiment word “classic” is frequently used in the context of beauty products and musical instruments and is highly significant for these domains. A sentence from the beauty product domain denotes a high positive significance of this word: “I would consider this a classic scent.” However, it is not important in the pet supplies, grocery, books, and toys & games domains. Moreover, it is moderately significant in the remaining domains. Certain words such as “worst,” “crappy,” “garbage,” “horrible,” “trash,” “terrible,” and “exchange” are negative across all the target domains. Sentiment word “garbage” is used in a different sense in different domains. It is highly significant in the clothes, shoe & jewel, cell phone, and other domains, but less important in the pet supplies domain.
This word has semantically evolved over time, largely the meaning is considered as “useless.” A sentence from the cell phone domain indicates a similar meaning: “The charger was such a piece of garbage that I smashed it to bits.” Sentiment word “worst” is highly significant and strongly negative across almost all the domains, but a little less significant in the health & personal care and automotive domains. A sentence from the toys & games domains reflects negativity: “These motors have some of the worst solder connection I’ve ever seen.”
Each domain contains domain specific words that are not observed in the other domains. Sentiment word “hunger” is observed in the grocery and pet supplies domains, but it also appears in the Amazon instant video, books, and video games domains owing to the different sense of the word such as “this game satisfies my hunger for an orc-smashing good time.” However, it is missing from the remaining target domains. Sentiment word “delicious” is highly relevant in the grocery domain and less relevant in the beauty domain and missing from the electronics and office product domains. A sentence from the grocery domain state: “This green curry paste is absolutely delicious!” Sentiment word “unwearable” is observed in the clothes, sports, and, beauty domains, but it is rare to find in the other domains such as electronics. A sentence from the clothes domain represents negative sentiments: “The fabric tore near the zipper and made them unwearable.”
Our observations indicate that our genre-based approach addresses the three domain adaptation challenges.
The proposed model has made a diverse contribution to the field of lexicon adaptation. The model learns a sentiment lexicon by an adaptation process and does not rely on the existing lexicons or labelled data for training. It innovatively selects the source and target domains. The source domains learn the sentiment lexicons using a novel improvement learning approach. The general-purpose lexicon provides a common knowledge, and the domain-based lexicons possess domain-based knowledge. The proposed model presents a central solution for the lexicon learning problem and learns a genre based on common knowledge. The model is tested on a variety and long list of domains of the same genre. The results of a target domain are good indicators of the quality of the learned lexicon. The major goal of the lexicon adaptation at the genre level is to achieve training without using labelled data.
In the future, other lexicon adaptation approaches can be explored for different possibilities using combined lexicons. A potential extension can be the investigation of different homogeneous knowledge transfer tasks and possible similar applications of the model in different languages wherein the labelled data are unavailable. Another possible extension can be moving toward a more general categorization.