
Abstract
In order to improve the ability of cloud computing data scheduling, this paper proposes a new method for multi-task, multi-level cloud computing data aggregation based on fuzzy association feature extraction. Heterogeneous directed graph analysis method is used to design cloud computing data. The semantic correlation fusion method is used to implement cloud computing data feature extraction and adaptive scheduling. The fuzzy clustering is used to process the characteristic amount of cloud computing data, and the optimal aggregation of cloud computing data is realized. Simulation results show that the method has a higher recall rate for multi-task and multi-level cloud data aggregation, and the highest recall rate can reach 1, which improves the accuracy of resource aggregation.
Introduction
In the process of multi-task multi-level cloud computing data development, it is necessary to combine the big data feature distribution of multi-task multi-level cloud computing data to carry out heterogeneous reorganization, establish the big data information analysis model of multi-task multi-level cloud computing data, use the method of information fusion and resource optimization scheduling to optimize scheduling and feature extraction of multi-task multi-level cloud computing data [11], establish the optimal convergence model of multi-task multi-level cloud computing data, and improve the ability of multi-task and multi-level cloud computing data development and scheduling. Therefore, the research on multi-task multi-level cloud computing data convergence method is of great significance in promoting the further development of cloud computing [26].
At present, a multi-task multi-level cloud computing data aggregation method is mainly provided with a K-Means method, a grid area aggregation method, a particle swarm convergence method and the like, and the feature extraction and big data analysis model of the multi-task multi-level cloud computing data is established, and the relevant characteristic distributed detection method is adopted, and the multi-task multi-level cloud computing data aggregation is realized.
In this paper, a multi-task multi-level cloud computing data convergence method based on fuzzy association feature extraction is presented in this paper. In the cloud computing environment, most of the data is multi-level data, and the data faces more tasks. This paper uses this as the main entry point to cluster this type of cloud data. The sub-class characteristics of cloud computing environment data are also traditional. Methods The main reasons for the low data clustering accuracy and low recall rate. This paper uses the semantic correlation fusion method to implement cloud computing data feature extraction and adaptive scheduling. This step can effectively improve the accuracy of data clustering. Using fuzzy clustering to further process the feature quantities of cloud computing data, the recall rate of the method is improved. The paper shows the superiority of the method in improving the convergence ability of multi-level cloud computing data.
Multi-task and multi-level cloud computing data model construction and feature analysis
Multi-task and multi-level cloud computing data aggregation node model
The data pre-processing mechanism proposed in this paper needs to appropriately extend and modify the existing mechanism within Hadop’s original framework to achieve its basic functions. As shown in Fig. 1 Hadop architecture diagram, from the top to the bottom can be divided into two major subsystems, namely MapReduce and HDFS. MapReduce provides users with a parallel programming interface and necessary resource management modules including JobTrader, TaxTracker, and Task Scheduler. HDFS, as a low-level distributed file system, provides users with reliable storage services and provides data support for MapReduce. If viewed from left to right, each functional module of the Hadop framework is deployed in the master node (Master Node) and the slave node (slave Nodes). Among them, the master node is responsible for job submission, task scheduling, resource management, and distributed file metadata management, and the slave node is responsible for the specific execution of subtasks and the physical storage of distributed files. When the job arrives, Clint first submits the job to the MapReduce framework. Job Tracer is responsible for the management of the entire life cycle of the job and implements the specific scheduling strategy. Secondly, the TaxTraker running on the slave node accepts each sub-task and completes the corresponding calculation.
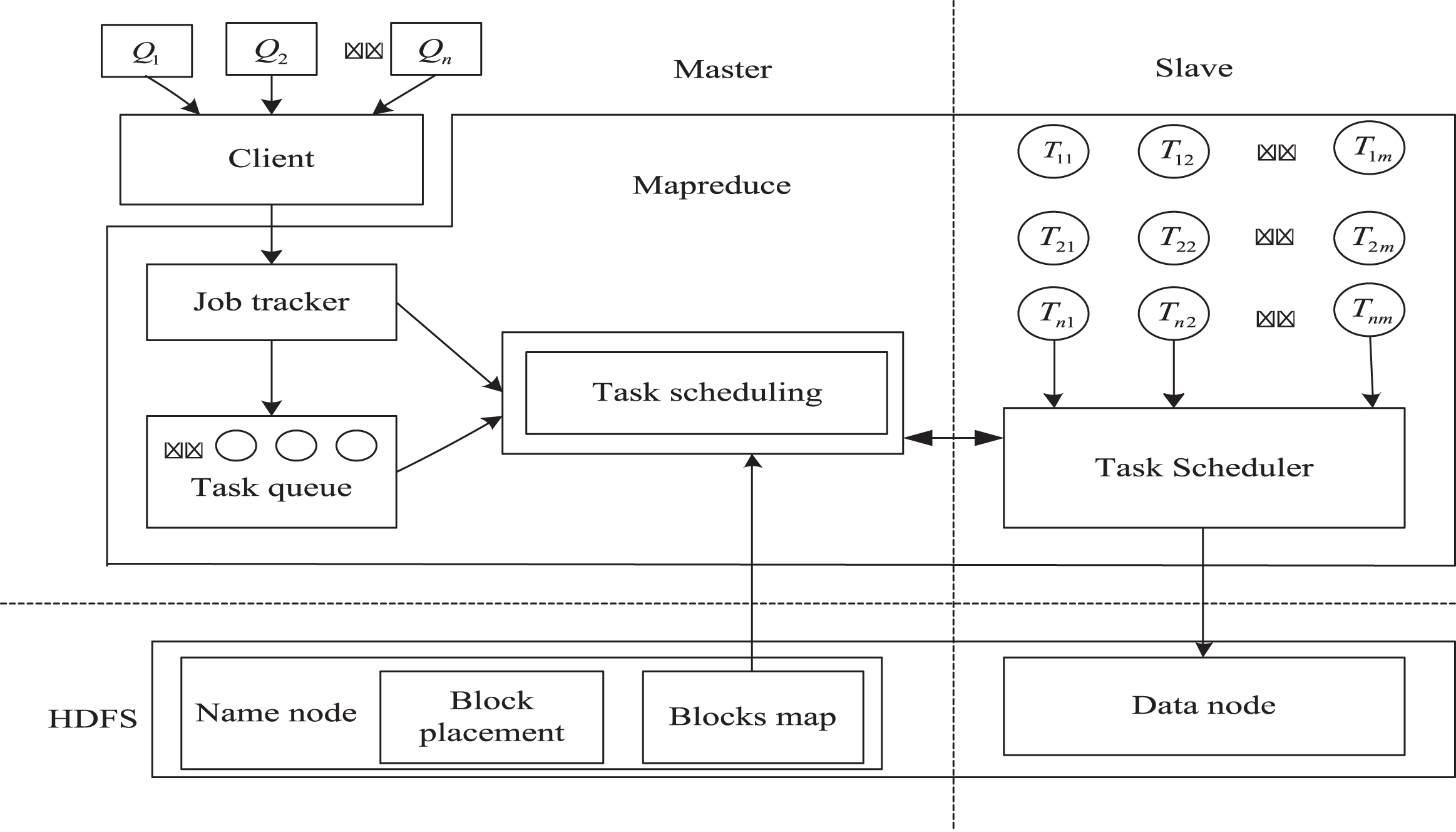
Hadoop architecture diagram.
The above data pre-processing mechanisms based on the Hadop platform can provide effective underlying platform support for upper-level online aggregation applications: The core-aware data partitioning algorithm and its data block indexing mechanism can effectively query irrelevant data blocks, improve the selection rate of related data, and thereby improve the quality of samples gathered online Through a two-stage data shuffling algorithm, on the premise of ensuring the randomness of the data block, the sequential data block scan replaces random access to obtain random samples, reducing the sampling execution time of online aggregation; The fair data block placement algorithm can ensure the load balancing of computing and storage under the premise of meeting fault tolerance requirements, and improve the parallelism of online aggregation jobs. The online aggregation application submits the query form to the Hadop platform, completes specific calculations under the MapReduce framework, and uses the above data pre-processing mechanism to achieve overall performance improvement. This section will focus on how to implement the basic functions of online aggregation based on the MapReduce framework, and introduce the basic aggregation queries of the WCOUNT, SUM, and AVGH classes. Approximate estimation method.
Under the MapReduce framework, the execution flow of the online aggregation application can be summarized into two steps. First, the query request 0 MapReduce job form is submitted to JobTracker, and after completing the scheduling, it is delivered to TaxTracker to complete the specific approximate operation. Secondly, during the execution of Query 0, feedback the query progress to the user through real-time query result detection to achieve real-time monitoring of the query process.
Regarding the definition of cloud computing, the most commonly used is the definition given by the National Institute of Standards and Technology (NIST): Cloud computing is a way to obtain computing resources in a convenient and on-demand way through the network (Network, server, storage, application) model, these resources come from a shared, configurable resource pool, and can be quickly acquired and released. Therefore, it can be seen that cloud computing provides services to users by integrating hardware resources and management through software, and users can purchase as needed. Cloud computing has greatly improved the utilization of hardware resources.
Cloud computing is a hot technology in the Internet industry at this stage. It is a trend for small Internet vendors to use cloud computing servers as their own servers. The research content of this article requires more servers. From an economic point of view, purchasing a cloud server is a very wise choice. You can customize a reasonable server according to the needs of the research, and you can use the server directly without maintenance.
In order to realize multi-task multi-level cloud computing data convergence based on fuzzy association feature extraction, a heterogeneous digraph analysis method is first adopted to carry out multi-task multi-level cloud computing data storage structure design, and a node distribution model of resource aggregation is constructed, in that invention, a multi-task multi-level cloud computing data on-line convergence optimization design is perform under a large data background, the distribution of the resulting convergence node is shown in Fig. 2.
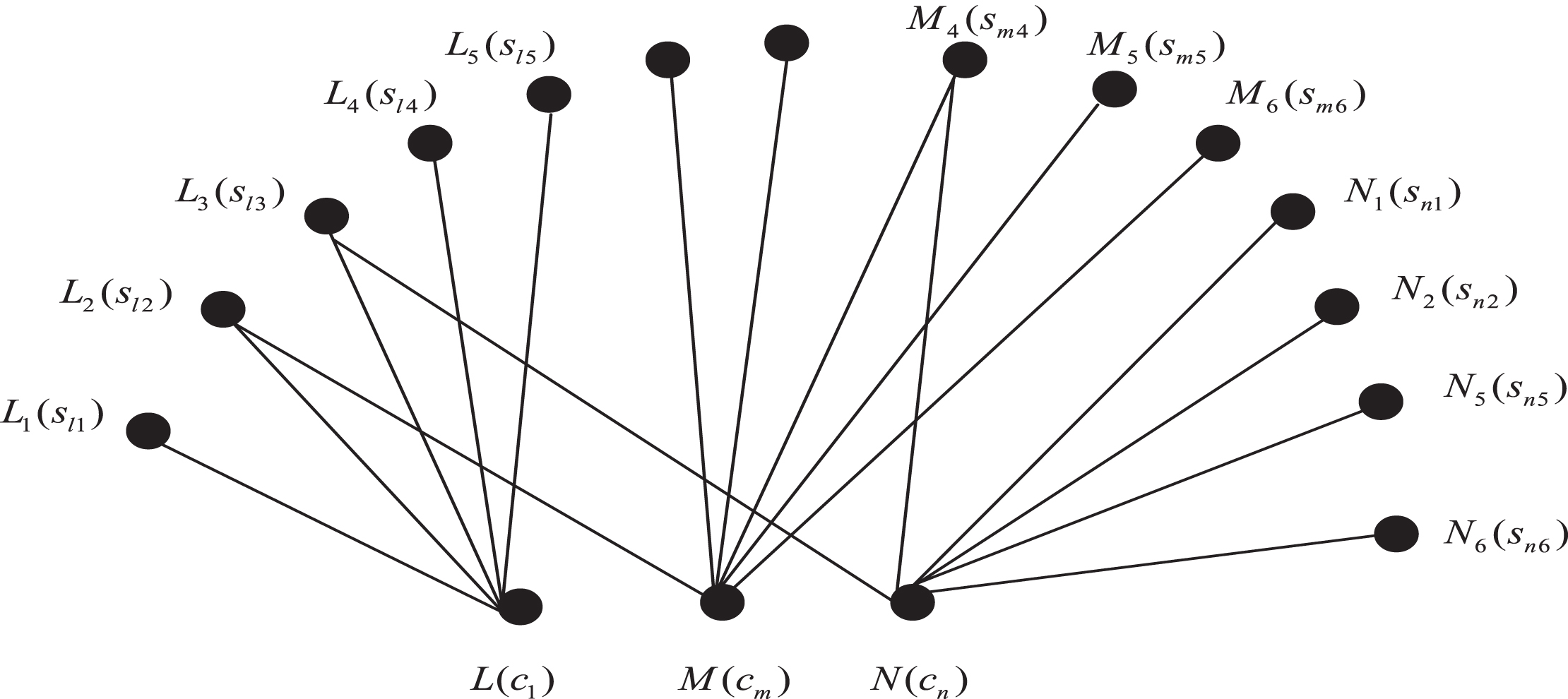
Multi-task multi-level cloud computing data aggregation node distribution.
By using the method of semantic ontology model construction, the correlation extraction and fuzzy decision of multi-task and multi-level cloud computing data aggregation between domain knowledge (Domain knowledge) ontology are carried out [3]. Through the method of autocorrelation feature matching, the relative closeness of two groups of similar multi-task and multi-level cloud computing data is analyzed as follows:
Where,
The basic idea of the content-based core-aware data partitioning strategy proposed in this paper is to divide the original data space equally according to the attributes of the data set, that is, the data blocks formed by the partitioning have the same size and size. According to different attribute ranges, a timed data block can be uniquely identified, so that the sampling operation on the data block can be more selective, that is, the data block that satisfies the predicate conditions is selected as the sample population, and then the query is implemented Effective branch shearing of irrelevant data improves query selection rate and ensures sample quality.
In order to implement the conent-aware partitioning strategy, the following four issues need to be fully considered: First, how to properly select the partitioning columns (parametric columns). The second is how to determine the granularity of each divided column. The third is how to implement specific division operations on division columns. The fourth is how to meet the data update needs.
For the first problem, the most intuitive solution is to divide all the attribute columns of the original data set as partition columns. This method can ensure that the division results meet the query requirements for different attributes for different query requests. For a long time, it will cause a dimension disaster (curse.of.dimension.), resulting in a large amount of data exchange and thus additional system overhead of block management. Another intuitive solution is to select a fixed data attribute column as the partition column. This method can effectively avoid disasters, but it cannot meet the query requirements of diverse query requests for different attributes, to this end.
This article adopts a query history load (queried) method of dynamically dividing column selection. Through statistical analysis of the query load, the currently most frequently accessed attribute column is obtained as the current partition column. When the data is updated, the query load is checked again to determine whether Trigger reselection of partitioned columns to adapt to new query needs.
For the second question, one possible solution is that the original data selects different partition granularities to obtain better partition results based on the data distribution characteristics of different attribute columns. For attribute columns subject to uniform distribution, a smaller partition granularity can be selected to appropriately reduce the number of data blocks and reduce management overhead while ensuring job parallelism. For attribute columns that obey the oblique distribution, you can choose a larger and different partition granularity according to the different degree of inclination W to separate out singular values as much as possible, so as to improve the selectivity of the sampling operation for data blocks and cut as much as possible Irrelevant data, improve sample quality. Although this method can obtain better division results, it requires users to have a qualitative or even quantitative understanding of the data distribution of each attribute column, which results in additional system overhead. In order to reduce the execution cost of the partitioning operation as much as possible, this paper adopts a static partitioning granularity selection method, that is, the partitioning column selects the same partitioning granularity and the user determines the appropriate value of the partitioning granularity according to the actual situation.
The directed graph model is used to construct the aggregation node distribution structure model of multi-task and multi-level cloud computing data, and the resource information feature extraction is carried out in the multi-task and multi-level cloud computing database. { (s1, a1) , (s2, a2) , … , (sn, an) } is the binary semantic feature component of multi-task and multi-level cloud computing data, and the heterogeneous directed graph analysis method is used to design the multi-task and multi-level cloud computing data storage structure [20]. Combined with feature space reorganization technology, the data structure of multi-task and multi-level cloud computing is reorganized, and the feature quantity of correlation information of multi-task and multi-level cloud computing data is extracted [21], and the optimal weighting coefficient of resource information aggregation is obtained
The fuzzy processing of cloud computing data is carried out to construct the adaptive scheduling parameters ∇2F (x) of multi-task multi-level cloud computing data, and establish the fuzzy decision matrix of multi-task multi-level cloud computing data aggregation:
The multi-task multi-level cloud computing data convergence feature extraction problem is converted into a binary semantic decision problem, the fuzzy characteristic matching evaluation index set of the multi-task multi-level cloud computing data aggregation is Ek ∈ E (k = 1, 2, …, t), the method of matching the subject word is adopted [13], the similarity function of the X is analyzed, The fuzzy membership function of the obtained resource features is as follows:
In which,
The invention relates to a recursive graph model for reconstructing multi-task multi-level cloud computing data, and adopts a method of phase space reconstruction, realizes the sampling of the fuzzy characteristic information of the multi-task multi-level cloud computing data aggregation [15], it obtains the weight vector vi, and the related characteristic distribution matrix of the multi-task multi-level cloud computing data is expressed as:
Wherein, the base station is the search step number of the multi-task multi-level cloud computing data aggregation, and c is the semantic association degree decision coefficient. According to the analysis, the characteristic analysis and the optimization scheduling of the multi-task multi-level cloud computing data are carried out, the clustering center is obtained as μ ik , and the method for describing the multi-level cloud computing data associated feature vectors vi, v i = ((w1, t1) , (w2, t2) , … (w j , t j )) and combining the fuzzy correlation fusion is calculated, the on-line convergence criterion of the obtained resources is as follows:
The depth of the multi-task multi-level cloud computing data aggregation node is
Feature extraction and fuzzy C-means clustering
In that invention, a multi-task multi-level cloud computing data storage structure design is carry out by adopting a heterogeneous digraph analysis method [4], this paper presents a multi-task multi-level cloud computing data convergence algorithm based on fuzzy association feature extraction, which describes the constraint parameters for quantitative evaluation of multi-task multi-level cloud computing data.
Using the correlation statistical analysis method, the data sharing degree of multi-task and multi-level cloud computing is obtained as follows:
According to the level of sharing, the quantitative evaluation set of multi-task and multi-level cloud computing data is constructed, and the spatial planning model of quantitative evaluation of multi-task and multi-level cloud computing data is described as follows:
Suppose the dynamic constraint parameter model of quantitative evaluation of multi-task and multi-level cloud computing data is described as follows: x j = {x1j, x2j, . . . , x mj } T , it establishes multi-task and multi-level cloud computing data scheduling model, and obtains the optimal evaluation set of resource scheduling:
The ambiguity function, feature extraction and fuzzy C-means clustering function for quantitative evaluation of multi-task and multi-level cloud computing data represented by Ui,j (t) are as follows [7]:
The optimal solution for analyzing the fuzzy C-means clustering of multi-task multi-level cloud computing data is as follows:
According to the optimal fuzzy clustering analysis, the local optimal is avoided, and the data optimization and convergence capability is improved.
The core of the two-stage data shuffling algorithm is also to reduce the correlation between adjacent data as much as possible by scrambling the original data set, and then improve the randomness of the distribution of each data in the data set. Sequential scanning can also obtain sample data with randomness guarantee [19, 27]. As shown in Fig. 3, the first stage of the shuffle algorithm divides the data block into equal size fragments according to a certain granularity, loads the fragments into memory in turn to perform tuple-level shuffle, and forms a group of shuffle fragments. In the second stage, a random order is assigned to the shuffled fragments contained in each data block, and a slice-level shuffle is generated in this order to generate a new data block. By repeatedly executing the above-mentioned two-level shuffle algorithm, the randomness of the distribution of each data in the original data set can be effectively improved, so that sequential scanning can also obtain sample data with better randomness. The implementation object of the two-stage data shuffling algorithm described in this article is data blocks. By performing two-stage shuffling of each data block, the randomness guarantee of sequential scanning is achieved, thereby improving the efficiency of a single acquisition.
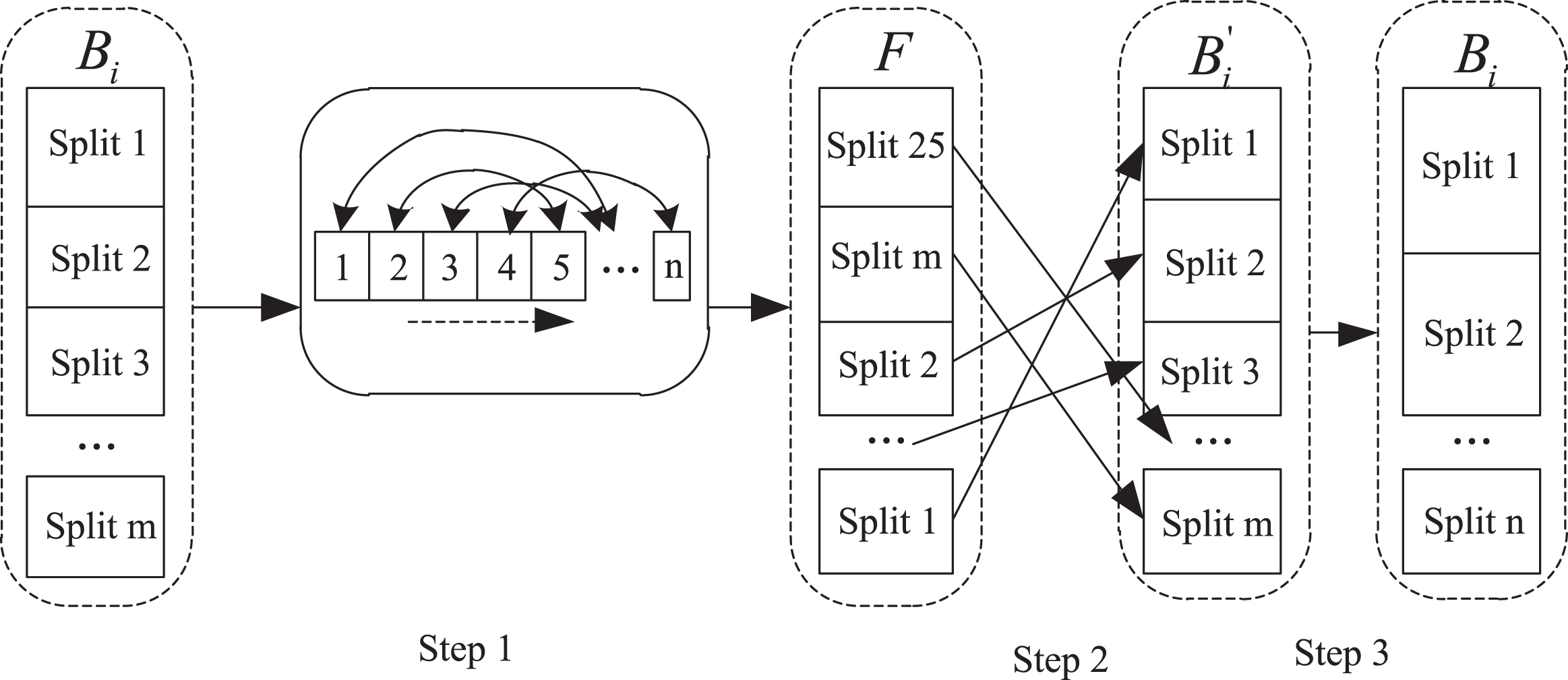
Two-stage data shuffle algorithm.
Based on this, this paper establishes a data loss rate model to verify that the improved copy strategy described above is also more fault-tolerant than the default random copy strategy of HDFS. Build a data loss rate model. At the same time, for the convenience of analysis, we assume that each storage node has a sufficient amount of storage space and uses any data block. The data loss probability P is used as a measurement parameter, and W measures the fault tolerance of the system in the case of // (/>r) failed nodes.
Suppose that the multi-task and multi-level cloud computing database dataset X = { x1, x2, ∧ , x n }, n is the number of target object set X of multi-task and multi-level cloud computing data aggregation [12, 30]. X is the feature point of multi-task and multi-level cloud computing data distribution. Fuzzy C-means clustering method is used to cluster the grid partition and attribute classification of multi-task and multi-level cloud computing data, so as to realize the optimal aggregation of multi-task and multi-level cloud computing data. A migration model for getting information aggregation for multitasking and multi-level cloud computing data:
The directed graph model is used to construct the information aggregation model of multi-task multi-level cloud computing data. The constraint planning model for constructing multi-task multi-level cloud computing data aggregation is as follows [9]:
Thus, the optimal evaluation set of multi-task multi-level cloud computing data aggregation is recorded as L1, ∧ , L
n
and
Wherein, cosinij→x (d ij , d xv ) is a fusion clustering feature set of multi-level cloud computing data [8, 29].
This paper aims at the performance optimization of the online aggregation mechanism in the cloud computing environment, comprehensively considers the basic characteristics of the cloud computing PaS layer parallel processing platform in data organization and management, task scheduling and execution, etc, and proposes data preprocessing for online aggregation performance optimization [6, 31]. Mechanism, concurrent query sharing optimization mechanism, and approximate query mode dynamic switching mechanism to achieve efficient and clever online aggregation mechanism in cloud computing environment. In terms of data preprocessing, fully considering the impact of skewed data distribution and sampling mode on online aggregation sampling efficiency, a data content-based partition algorithm and a two-stage data shuffling algorithm are proposed to reduce the number of samples and the execution cost of a single sample Optimize sampling efficiency in two ways. On this basis, comprehensively consider the correlation between query requests and data blocks, and propose a rational data block placement algorithm to ensure that the computing and storage loads are aligned and improve task parallelism, thereby reducing task waiting time: shared in concurrent queries In terms of optimization, fully consider the sampling correlation and calculation correlation between query jobs, and propose a two-level sharing algorithm oriented to sampling and calculation to achieve the effective combination of similar queries and reduce redundant and repeated I / O overhead [1, 25]. Calculation cost with statistics: In terms of dynamic switching of approximate query mode, a reasonable approximate estimation failure probability model is established to predict the failure probability of traditional online aggregation mechanism, and combined with Bootstrap estimation theory, a dynamic switching mechanism of approximate query mode is proposed, thereby avoiding approximate estimation Global data scanning caused by failures to optimize the performance of online aggregation [2, 23].
In order to verify the application performance of this method in realizing multi-task multi-level cloud computing data aggregation, the experimental test analysis is carried out, the algorithm of multi-task multi-level cloud computing data aggregation is processed by using C++and Matlab 7 hybrid programming, and the multi-task multi-level cloud computing data database structure model is constructed in Hadoop cloud platform. The initial sample size of multi-task multi-level cloud computing data big data distribution is 2000, the quantized distribution test set is 80, the iterative steps of adaptive learning is 0.87. Descriptive statistics for each cloud computing node is shown in Fig. 4.
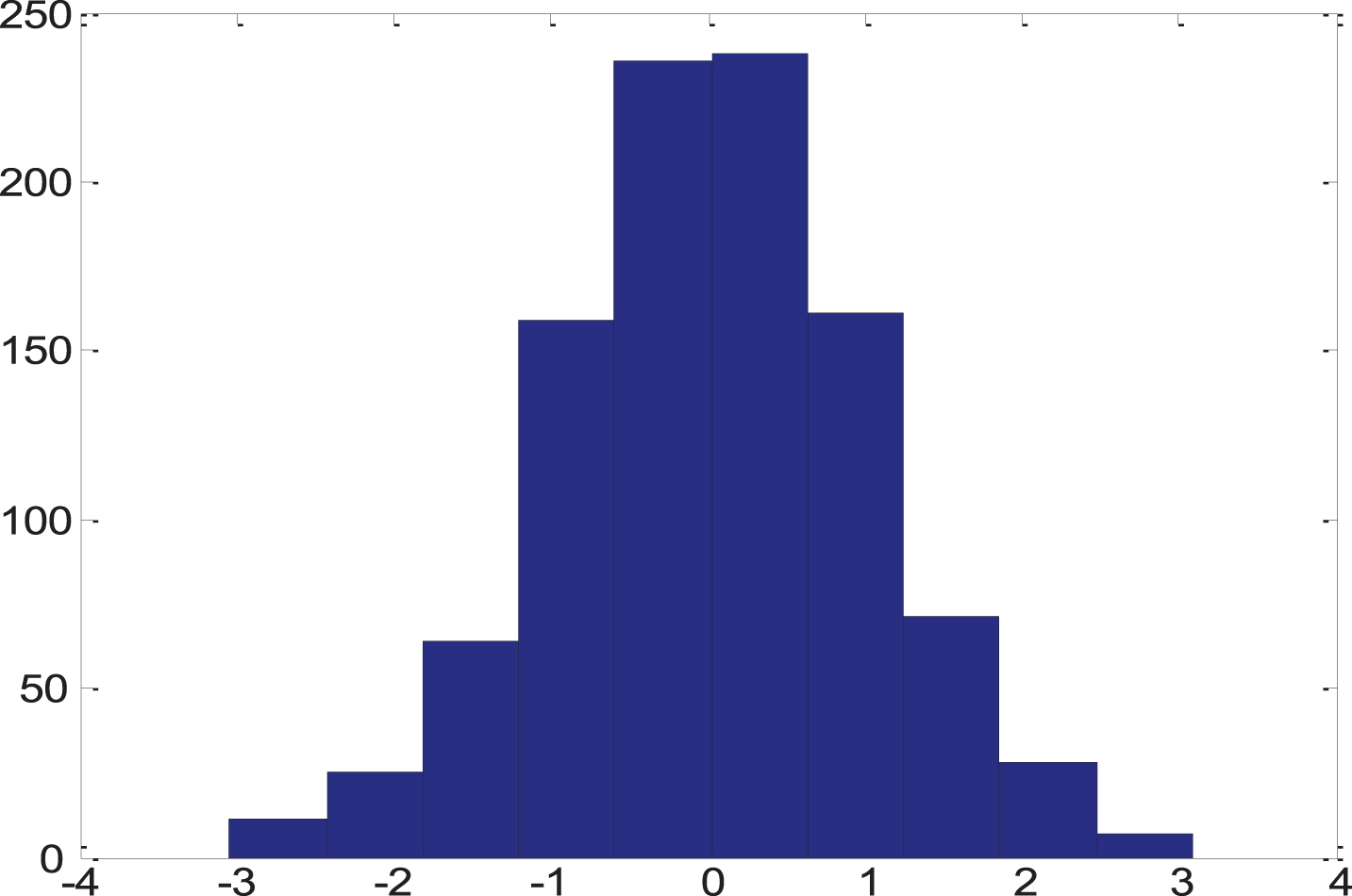
Descriptive statistics for each cloud computing node.
The associated information feature quantity of multi-task multi-level cloud computing data is extracted, and using semantic correlation fusion method to carry out multi-task multi-level cloud computing data feature extraction and adaptive scheduling, the time domain distribution of multi-task multi-level cloud computing data is obtained as shown in Fig. 5.
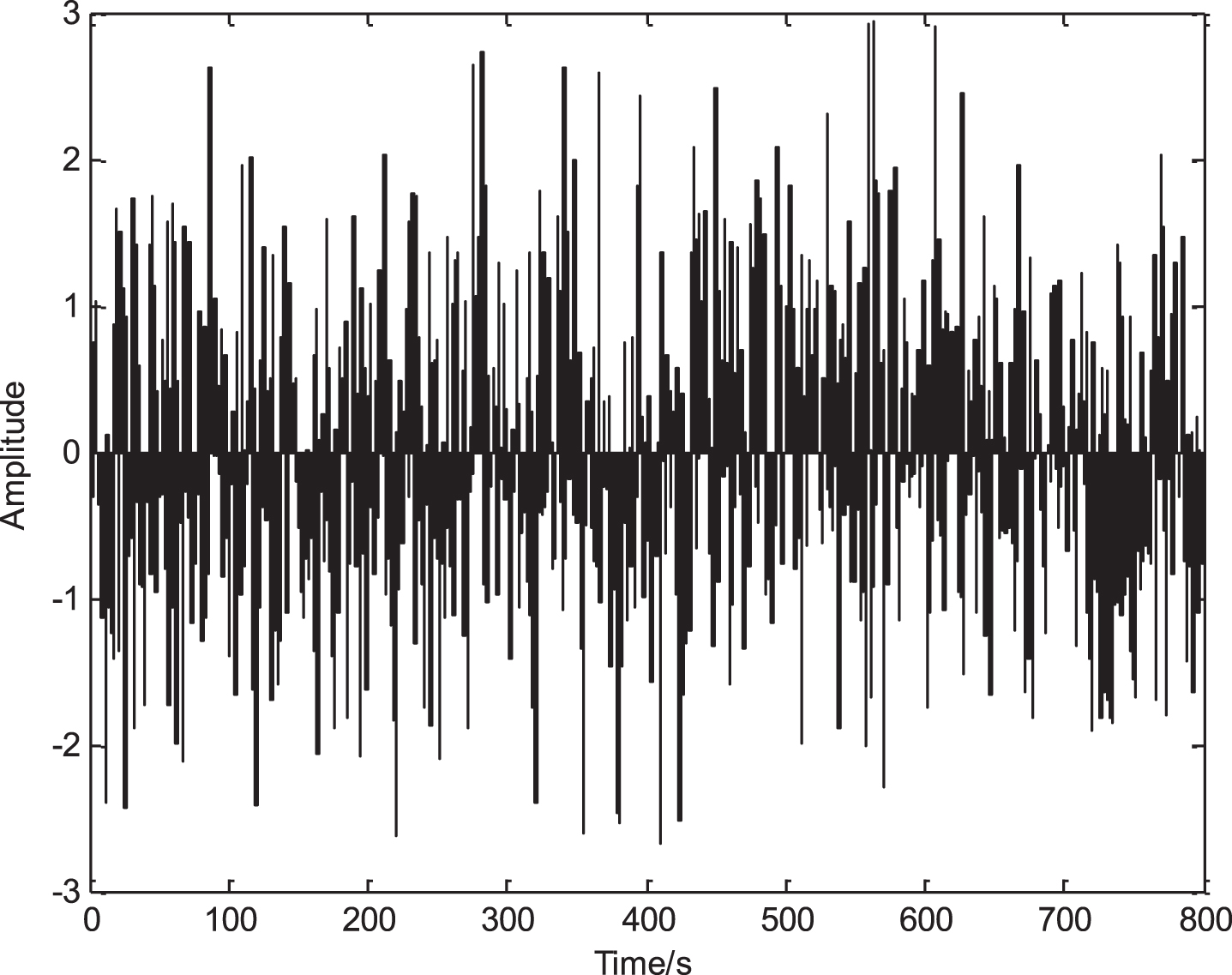
Time-domain distribution of multi-task multi-level cloud computing data.
Based on the data of Fig. 5, the hierarchical cloud computing resources are aggregated, the test precision and recall are obtained, and the test results are shown in Fig. 6. The analysis of Fig. 6 shows that the recall and precision of multi-task and multi-level cloud computing data aggregation using this method is high.
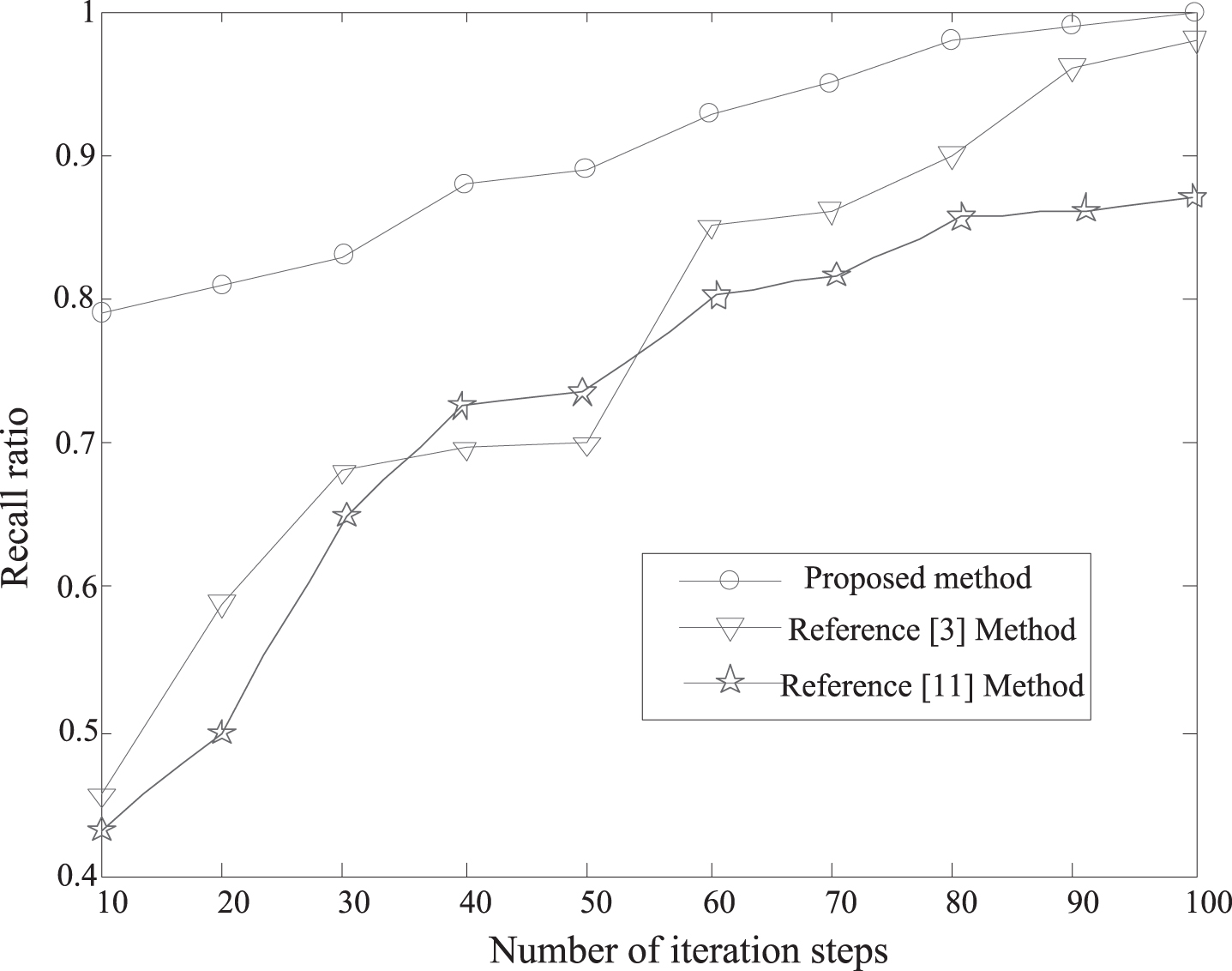
Comparison of recall rates.
The results of the analysis of Fig. 6 show that the accuracy rate and the full rate of the multi-level cloud computing data convergence are higher by this method. The test data recall rate and the comparison result are shown in Table 1. The analysis of Table 1 shows that the recall rate of multi-task multi-level cloud computing data convergence in this paper is high.
Recall rate test
The invention provides a large-data information analysis model of multi-task multi-level cloud computing data, this paper presents a multi-task multi-level cloud computing data convergence method based on fuzzy association feature extraction. the method comprises the following steps of: constructing a clustering node distribution structure model of a multi-task multi-level cloud computing data by using a directed graph model, adopting a correlation statistical analysis method to obtain a multi-task multi-level cloud computing data sharing degree level, and extracting the related information feature quantity of the multi-level cloud computing data, and realizes the optimization and convergence of the multi-task multi-level cloud computing data. The analysis shows that the method is used for multi-level and multi-level cloud computing data aggregation, and the search rate and full rate are high, and the multi-task multi-level cloud computing data sharing and aggregation scheduling capability is improved.
The research work of this article involves many aspects of the online aggregation mechanism in the cloud computing environment, and has achieved certain results, but there are still many deficiencies, some of which need to be further refined, as follows: The proposed fair data block placement strategy only supports a single file placement requirement. By defining the distance between each data block in a single file to reflect its query correlation, and achieving fair placement based on this, it satisfies the requirements of each data block within a single file. Computing and storage load balancing. However, this method of defining the distance between data blocks in a single file is not suitable for multi-file placement requirements, that is, the query correlation between data blocks belonging to different files cannot be defined. Therefore, the fair data block placement strategy proposed in this paper is not supports multiple file placement requirements. How to achieve a fair data placement strategy for multiple data files in the highly shared cloud computing environment for multiple users’ frequent query requirements for different files is one of the key topics of future research work.
Footnotes
Acknowledgment
The research is supported by Science and technology research project of Hubei Provincial Education Department in 2017: “Research and application of virtual reality technology in developing children’s safety education games” (NO. B2017217).