
Abstract
In this research work, we propose a rule based approach for the automatic extraction of UML diagram from the unstructured format of software functional requirements. The existing work provides decent results for active sentences and positive sentences but the challenge in our work is to automatic extract class diagram elements from passive voice type sentences and negative sentences. Furthermore, there is scope to do more research in extraction process using multi-word terms. Thus, we have endeavored to automatic extract the class diagram elements by overcoming these challenges. The methodology uses the Stanford CoreNLP Tools along with Java for the practical implementation of formulated rules. Our approach has proved that without supplant the human being and their decision making, one could reduce the human effort while designing functional requirements. Several case studies were performed to compare class diagrams generated by our methodology to the ones created by experts. Our methodology outperforms the existing work and provides impressive Average completeness (0.82), Average correctness (0.92) and Average redundancy (0.15). Results show that class diagram elements extracted by our methodology are precise as well as accurate and hence, in practice, such class diagrams would be a good preliminary diagram to converge towards to precise and comprehensive class diagrams.
Introduction
Unified Modeling Language (UML) is a great deal to focus on as it portray the detailed design and description of the object oriented software development. It acts as a bridge among the participants for understanding each other like to share ideas, resolve ambiguities etc. Hence, we have carried out our work in the direction of automatic extraction of conceptual diagram i.e. class diagram which is widely used and known structural models among practitioners such as tool builders, users, and notation designer [25].
Existing research work suggests that several methodologies such as CM Builder [15], Use-Case driven Development Assistant (UCDA) [20], CIRCE [2], Visual Narrator tool [26], AnModeler [32], aToucan [36] etc. have been proposed for the extraction of conceptual models from functional requirements using Natural Language Processing (NLP) tools and techniques. Although the existing extraction rules have shown successful outcomes for active voice and positive sentences but existing tools and methodologies are facing some major limitations.
Limitations of existing work
The existing work counted out the multi-word terms during extraction process. Looking at passive voice and negative sentences, there is scope for further improvement.
Thus, we propose a methodology to overcome these shortcomings for automatic class diagram extraction from unstructured functional requirements. Firstly, we have identified the multi-word terms in functional requirements. Secondly, we have come up with the paraphrasing rules for conversion of negative sentences into affirmative sentences. We strived to devise new NLP based extraction rules for passive voice and negative sentences in conjunction with multi-word term extraction.
The rest of the paper is organized as follows: we have discussed the related work in section 2, section 3 contains a detailed description of proposed methodology and extraction rules along with their implementation form, and section 4 contains results and analysis of our findings. Our concluding remarks are presented in section 5 together with some directions for future work.
Related work
The research trend in the field of automatic extraction of UML diagram from functional requirement has witnessed a disruption in last few years. Currently, there are few factors which boost the effort in this research field such as recent progress in field of natural language (NL) analysis i.e. semantic analysis, anaphora resolution, and detection of multi-word term etc. These fields bring down the complexities in NL analysis up to some extent.
The pattern in this research field shows that researchers are using different rules and patterns for the UML diagram extraction and proposed some extraction tools such as CM Builder [15], UCDA [20], CIRCE [2], Visual Narrator tool [26], Class-Gen [10], Static UML Model Generator from Analysis of Requirements (SUGAR) [18], AnModeler [32], and aToucan [36]. Some other approaches are also presented for extracting the relation between the entities from the requirement document using linguistic pattern matching such as [21], [28], and [29]. Some researchers [9], [3], and [24] have carried out their work by emphasizing on the formulation of the extraction rules to better exploit result. Some research works such as [33], [34] employed dependency parser for the extraction of the domain element from text document. We have analysed the extraction rules employed in existing researches and observed that these rules provide commendable results as far as active voice and positive sentences are concerned but in the matter of passive sentences and negative sentences, more research is required.
Based on the analysis of these pioneering works, we have proposed a methodology and discussed in detail in the next section. The emphasis is in the direction of minimizing human efforts by improving the performance of extraction rules.
Proposed methodology
The proposed methodology can be broadly classified into two main steps such as preprocessing of functional requirements and identification of entities as described in Fig. 1.
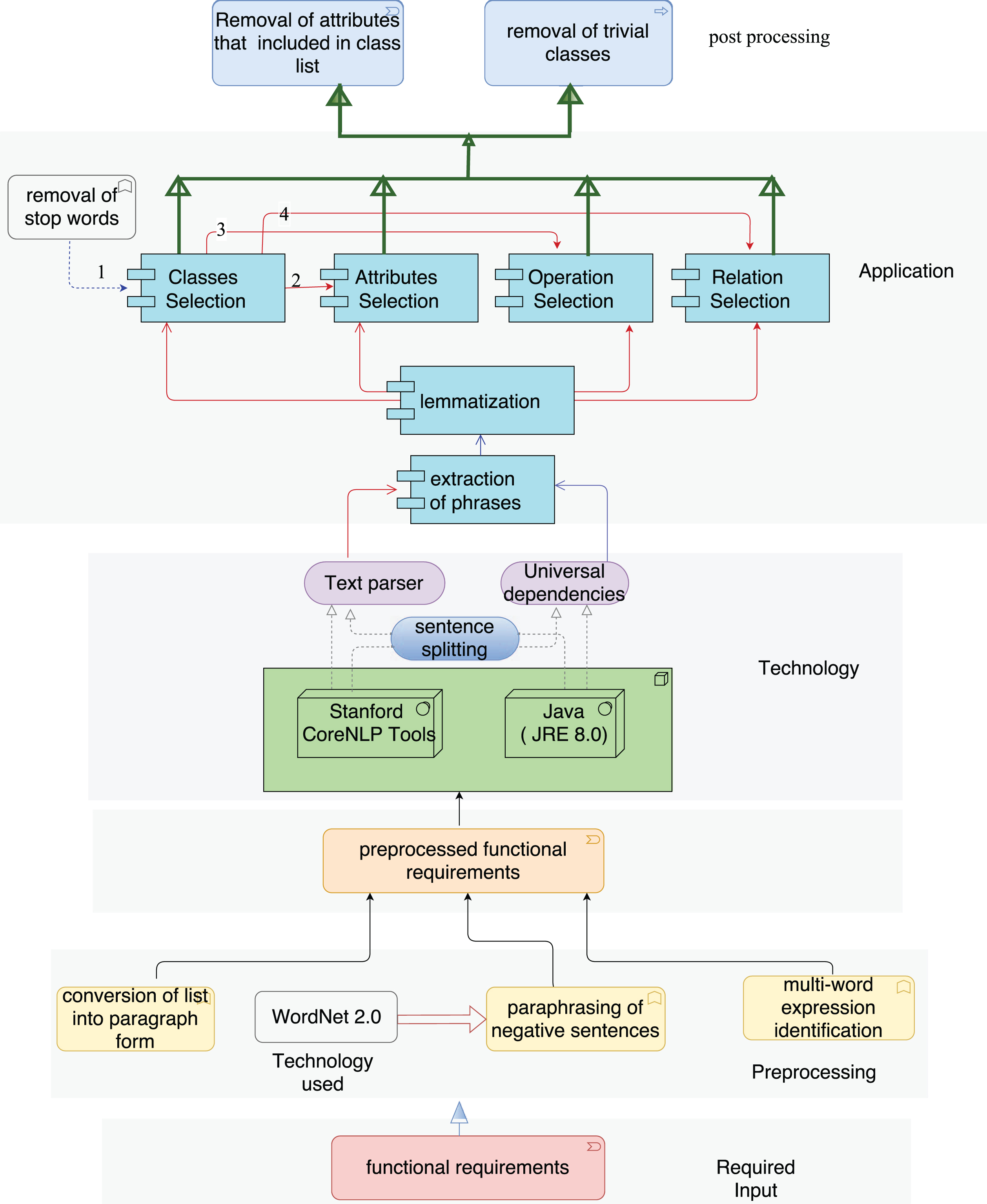
Steps followed in the proposed methodology.
This methodology employs Stanford universal dependencies from Stanford CoreNLP [13], [5], [30], [17], [7] tool. The universal dependencies provide a simple description of grammatical relationships between words present in a sentence using head and reliant. This representation contains approximately 50 universal dependencies and each dependency holds binary relationship between a head and reliant. The definitions practice Penn Treebank [22] part-of-speech tags and labels. The grammatical relations are illustrated using an example in Table 1.
Description of universal dependencies in a sentence
Example “Account owns shopping cart and orders.” and corresponding universal dependencies produced by parser are given below.
[nsubj(owns-2, Account-1), root(ROOT-0, owns-2), compound(cart-4, shopping-3), dobj(owns-2, cart-4), cc(cart-4, and-5), dobj(owns-2, orders-6), conj:and(cart-4, orders-6)]
Requirement specification must possess three restrictions before preprocessing of functional requirements. The first restriction is that the sentences should be grammatically correct. The next restriction is that the requirement specifications do not accomplish anaphoric relation. Our proposed methodology is practised only on anaphora that refers to the subject of the same sentence, e.g. “Tutors in the organization are assigned courses to teach according to the area that they are specialized in and their availability”. Here, ‘their’ is referring to the subject of sentence. Generally, co-reference resolution leads to ambiguity in the text. So, we assume that if there is anaphora present then it refers to the subject in sentence. The third restriction is that an entity used in requirement specification should be indicated by a same term in the entire functional requirement. E.g. if “loan item” multi-word term is used for an entity then only the same shall be used in the entire document rather than “item” otherwise, it will lead to ambiguity in the document.
Generally, functional requirements include complex phrases such as multi-word term that can be decomposed into meaningful units. Thus, after conversion of listed functional requirement into paragraph form, the step is to identify the multi-word term from functional requirements using Algorithm 1 which employ universal dependencies. For example, in Table 1, we can observe “shopping cart” is a multi-word term that is represented by “compound(cart-4, shopping-3)”. We are using this dependency to substitute the word “cart” with word “shopping _ cart” in other universal dependencies also.

Paraphrasing of negative sentences
Generally, negative sentences are also used by the software analyser while gathering software requirements. These negative sentences often lead to ambiguities. In existing research works, the negative sentences are often neglected or these sentences are manually paraphrased into affirmative sentences. Thus, we have formulated paraphrasing rules for negative sentences and WordNet 2.0 [23], [11] has been employed for searching out the antonyms of certain words. We have applied Algorithm 2 for extraction and paraphrasing of the negative sentences.

For paraphrasing of negative sentences, we have implemented the rules (NR1-NR5) using universal dependencies of the sentence. Here, negation (¬) of a word symbolizes the antonyms of word and ‘S’ denotes corresponding requirement sentence.
E.g. Negative sentence- The course offerings not marked as “enrolled in” are marked as “selected” in the schedule.
Paraphrased sentence -The course offerings unmarked as “enrolled in” are marked as “selected” in the schedule.
E.g. Negative sentence- The professor is not eligible to teach any course offerings in the upcoming semester.
Paraphrased sentence - The professor is ineligible to teach any course offerings in the upcoming semester.
E.g. Negative sentence- Course offerings that do not have enough students are canceled.
Paraphrased sentence-Course offerings do miss enough students are cancelled.
e.g. Negative sentence- If no alternates are available, then no substitution will be made.
Paraphrased sentence - If alternates are available, then only substitution will be made.
e.g. Negative sentence- No Course Offerings is available.
Paraphrased sentence - Course Offerings unavailable.
Extraction of entities
The next step of our work flow is to identify the class diagram elements using Algorithm 3. In our approach, grammatical semantic analysis of requirement sentences is used for devising extraction rules and then extracted class diagram entities are lemmatized to avoid ambiguities and redundancies. Thus, we have employed different annotated (identified by human assessors) functional requirements to devise automatic extraction rules. The extraction rules employ universal dependencies to get a lot of mileage of grammatical semantics of the sentences.

The implementation form of extraction rules are described using logical representation which employ universal dependencies such as nsubjpass(n, a), cop(n, a), amod(n, a) etc. and these universal dependencies are explained in [8]. Other schemes of abbreviation and sets used in implementation form are as follows: class (a) shows extracted word ‘a’ is a class and attribute (a, b) indicates extracted word ‘b’ is an attribute for extracted class ‘a’. association (a, b, n) shows word ‘n’ is a relation between two extracted classes ‘a’ and ‘b’ whereas method (a, n) defines extracted word ‘n’ is a method for extracted class ‘a’. ‘subject’ and ‘verb’ are set of subject and verb of requirement text respectively. ‘indefinite adjective’, ‘auxiliary verb’, and ‘numeral adjective’ are set of indefinite adjective, auxiliary verbs, and numeral adjective respectively.
Extraction of the classes using class rule
After applying the class extraction rules, some classes are removed from class list which are in common with stop words. These stop words contain such words that treat whole system in a single unit such as ‘system’, ‘information’ etc. After extracting classes from the text, our next step is to apply attributes extraction rules.
Extraction of the attributes using attribute rule
b1 and b2 are words of multi-word term
All attribute extraction rules should follow one rule that extracted attributes should not belong to class list.
Extraction of the relation and method
Results and analysis
We have examined several test cases for the validation of extraction rules described in Section 3. The case study along with automatic extraction of class diagram elements and performance evaluation is described in section 4.1 and 4.2 respectively.
Case study and extracted class diagram elements
In this section, we have described the formulation of our rules for the case study of Library Information System domain (LIS) [4] given in Fig. 2. The corresponding gold standard class diagram [4] is illustrated in Fig. 3 which is used for the comparison of automatically generated class diagram. Other case studies from different domains have been analyzed, for example, Online Shopping System domain (OSS) [16], Automated Teller Machine domain (ATM) [27], Airport System domain (AS) [31], and the Railway Reservation System (RRS) [19], Course Registration Requirement (CRR) [6].

Functional Requirement for LIS [4].

Class Diagram for LIS [4].
In LIS [4], according to preprocessing phase of our methodology, we have identified multi-word terms and paraphrased the negative sentences using rules NR1-NR5 as described in Table 2. In order to achieve the extracted class diagram elements, we have applied class extraction rules followed by attribute, method, and relation extraction rules respectively. Here, we will describe the newly formulated extraction rules in detail. As mentioned in Table 3, we have applied class extraction rules on the functional requirements for instance subjects such as ‘Library’, ‘Membership_ card’, ‘Language_ tape’, ‘Book’, ‘Customer’, ‘Membership’ are extracted as classes from statement no. 1, 4, 10, 11, 12, 15 and 17 using rule described in [28]. The noun phrases ‘Library’ and ‘Subject_ section’ are extracted as classes from statement no. 6 because this statement comprised of ‘made up of’ phrase [28].
Paraphrasing of negative sentences
Extracted class diagram elements from the corresponding sentence
The noun phrases ‘classification_ mark’ and ‘bar_ code’ are extracted as attributes for the subject ‘subject_ section’ as this statement comprises of phrase ’denoted_ by’ [15], [28]. The same rule is also applied on statement no. 8 and noun phrase ’Bar_ code’ is extracted as attribute for the subject ‘loan_ item’ as phrase ’identified by’ indicates the presence of attribute for the subject. In statement no. 10, object‘title_ language’ and ‘level’ are extracted as attributes for the subject i.e. ’Language_ tape’ as in this statement verb ‘to have’ point out the attributes for the subject [15], [28], [35], [1]. Same rule also is applied on statement no. 12 which extracts ‘title’ and ‘author’ for the subject ‘book’.

Class Diagram for LIS [4].
As we have considered only the explicitly defined information, thus, some implicitly defined classes cannot be extracted such as ‘check-in’, ‘check-out’, ‘loan transaction’, ‘membership code’. In our process of automatically extraction of UML class diagram, the additional correct class diagram elements have been extracted such as ‘number_of_loan_item’, ‘classification_ mark’, ‘support_ facility’, and ‘stamped’. As negative sentences have also been considered for the application of extraction rules. Thus, additional class diagram elements have also been identified such as methods ‘Stamped’ and ‘issued’ are extracted for class ‘Loan_ item’. The correct identification of extra class diagram entities is an advantage for the software development.
Our objective is to examine our extracted class diagram elements using three evaluation metrics completeness, correctness, and redundancy on comparing with the reference diagrams. These reference diagrams are created by human experts such as industry experienced person, post graduate students, and Ph.D. students with specialization in software engineering. The three evaluation metrics derived from research article [36] are explained below:
The completeness of class diagram refers the correct class diagram elements that have been extracted over the total amount of class diagram elements present in reference diagram. We have evaluated completeness in terms of Average of class completeness (CM c ), attribute completeness (CM a ), method completeness (CM m ), and relation completeness (CM r ).
CM cd = (CM c + CM a + CM m + CM r )/4, where CM c , CM a , CM m , and CM r are explained below:
CM c = No. of correct identified classes (N cc )/ No. of classes in reference class diagram (N cr )
CM a = No. of correct identified attributes (N ac )/ No. of attributes in reference class diagram (N ar )
CM m = No. of correct identified methods (N mc )/ No. of methods in reference class diagram N mr )
CM r = No. of correct identified relations (N mc )/ No. of relations in reference class diagram (N rr )
The correctness of class diagram refers the correct class diagram elements that have been extracted over the total amount of class diagram elements extracted. We have evaluated correctness in terms of Average class correctness (CR c ) and Average relation correctness (CR r ) i.e.
CR cd = (AvgCR c + AvgCR r )/2
Avg
Avg
The correctness of each class (CR c ) is calculated in terms of:
CR c = (CR cc + CR cn + CR ca + CR cm )/4 where CRcc1, CR cn , CR ca ,and CR cm are explained below:
CR cc = 1, if identified class represents significant class entity, otherwise 0.
CR cn = 1, if identified named class is correct otherwise 0.
CR ca = No. of correct identified attributes (N ac / No. of identified attributes (N a )
CR cm = No. of correct identified method (N mc )/No. of identified method (N m )
The correctness of each relation (CR r ) is calculated in terms of:
CR r = (CR rc + CR rn + CRrc1 + CRrc2 + CR rt )/5 where CR rc , CR rn , CRrc1, CRrc2, and CR rt are explained below:
CR rc = 1, if identified relation denotes significant relationship otherwise 0.
CR rn = 1, if identified relation is named correctly otherwise 0.
CRrc1 = 1, if correctly identified one related class otherwise 0.
CRrc2 = 1, if correctly identified another related class otherwise 0.
CR rt = 1, if relationship type is correctly identified otherwise 0.
The redundancy in class diagram (R cd ) is explained as the fraction of redundant class diagram elements extracted among identified class diagram elements. The redundancy is calculated in terms of class redundancy (R c ) , attribute redundancy (R a ), method redundancy (R m ), and relation redundancy (R r ).
R cd = (R c + R a + R m + R r )/4 where R c , R a , R m , and R r are explained as follows:
R c = No. of redundant classes (N rc )/ No. of identified classes (N c )
R a = No. of redundant attributes (N ra )/ No. of identified attributes (N a )
R m =No. of redundant methods (N rm )/ No. of identified methods(N m )
R r =No. of redundant relations (N rr )/No. of identified relations (N r ) where,
Redundant classes (N rc ) are extracted by our approach which are either incorrect or not included in any relation.
Redundant attributes (N ra ) and method (N rm ) are identified incorrectly by our approach.
Redundant Relation (N rr ) are those incorrect relations which are identified by our approach, these redundant relations include relation which are either incorrect or have incorrect classes.
We have conducted a comparison of obtained class diagram with the specific existing approach which was proposed in [28]. We have selected this existing approach because this is well-known approach for the unstructured functional requirements and it extracts the same class diagram elements i.e. clases, attributes, methods and relations. Thus, this approach is suitable for comparison with our approach and the obtained results are explained in Table 4 and corresponding bar chart comparison is given in Figs. 5, 6, and 7.
Comparison with existing approach
Comparison with existing approach
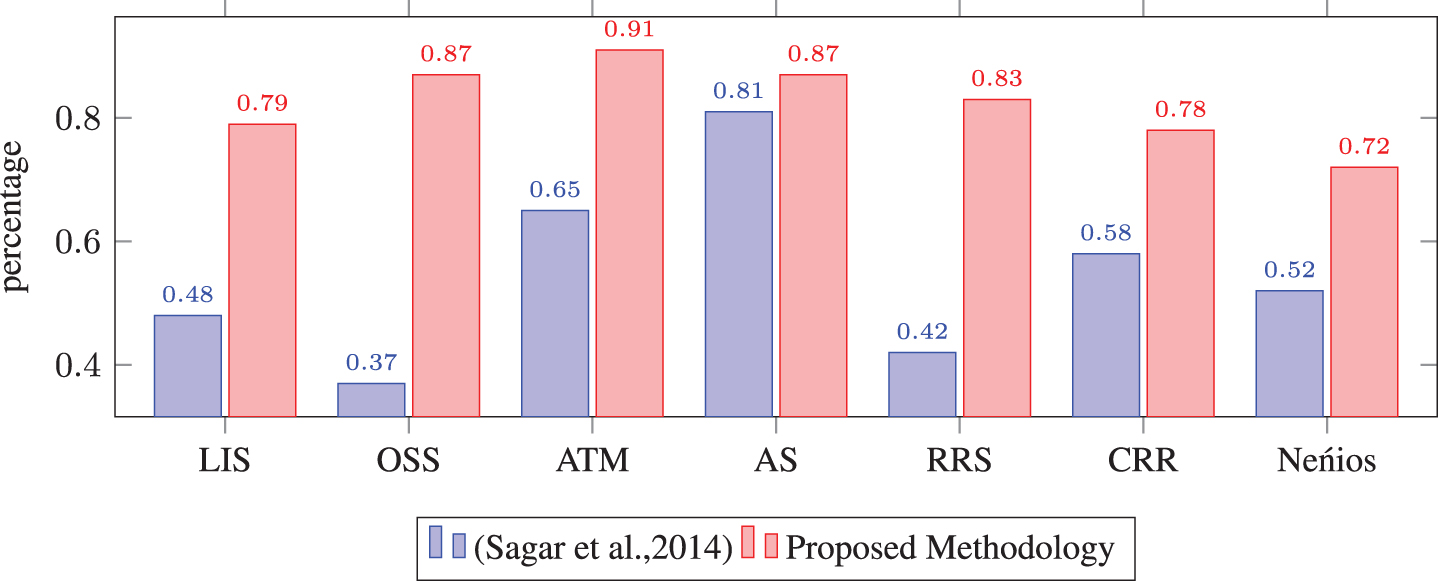
Comparison of completeness.
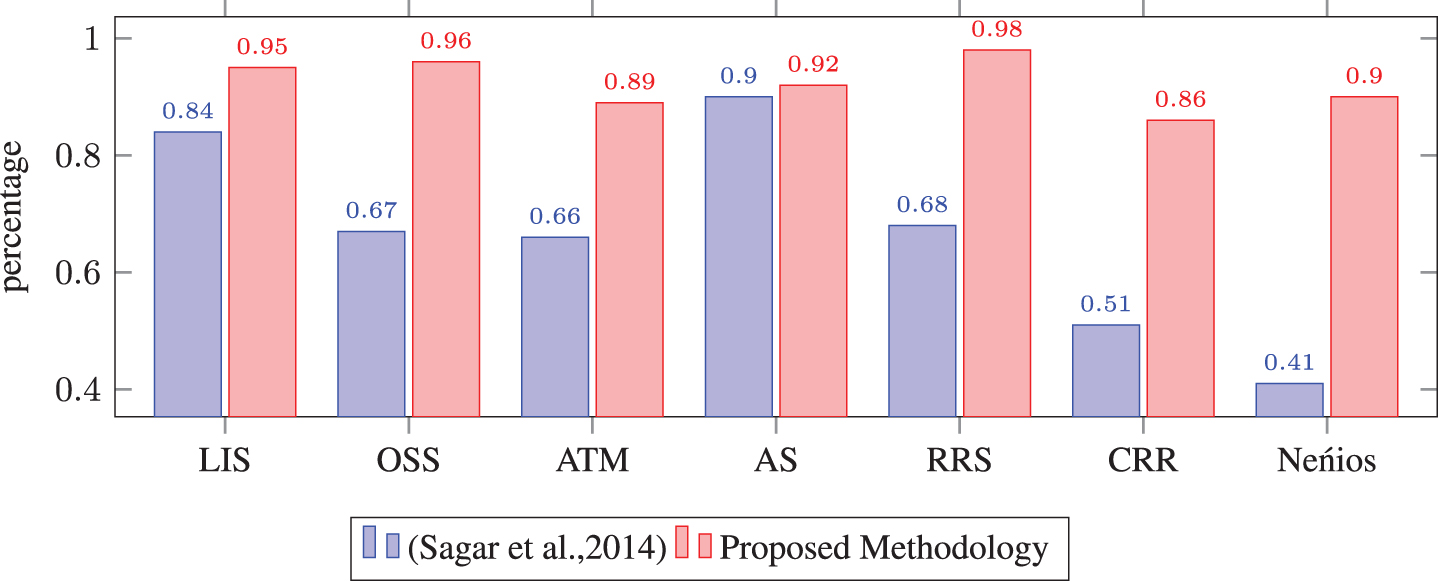
Comparison of correctness.
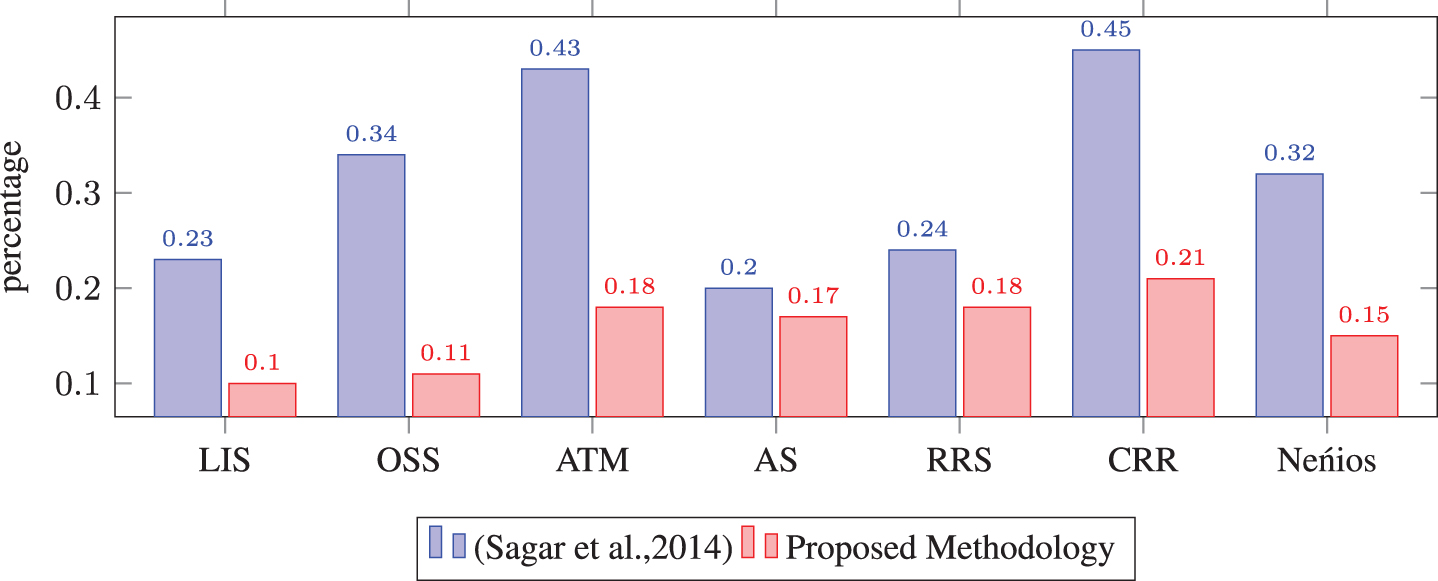
Comparison of redundancy of class diagram.
We have also applied our methodology on industrial case study i.e. Neńios Child Care Center software requirement and corresponding extracted class diagram is illustrated in Fig. 8. This document describes the child care management software which assist in managing the child care center by minimizing the administrative working time in various task such as report printing, processing invoices etc. This software also automates the activities such as tracking child immunization and maintaining child enrolment etc. so that employees spend their time in child caring. This industrial case study mostly includes passive and negative sentences, thus, in obtained result, we have observed that our methodology achieved decent results as compared to other methodologies.
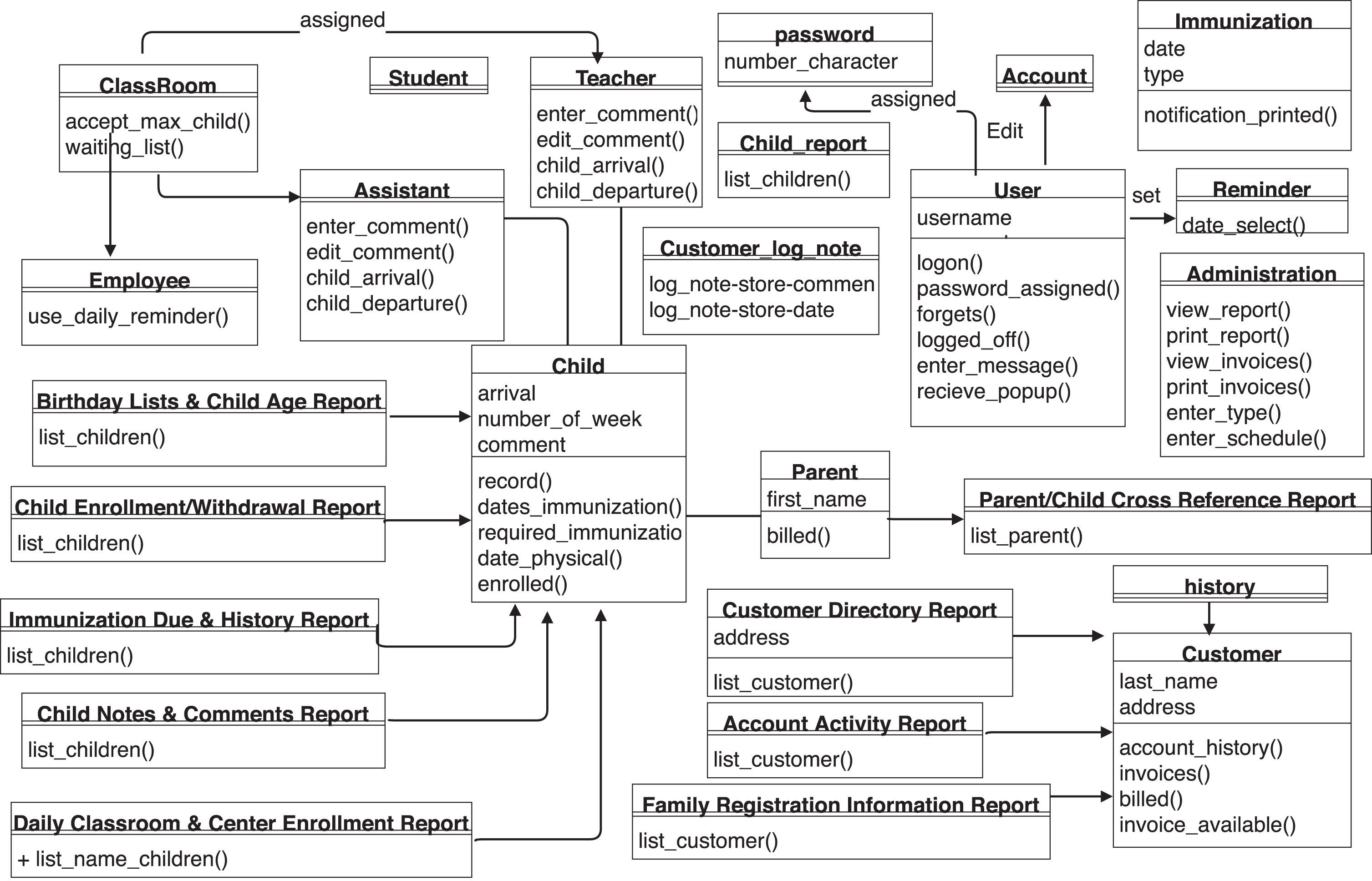
Extracted class diagram for industrial case study i.e. Neńios child care center system software.
As the negative sentences and passive voice are more often occurs in large text document, thus our methodology performed extremely well in these cases such as Neńios Child Care Center software requirement [12] and course registration requirement (CRR) [6].
We have formulated new rules for automatic selection of class diagram elements from functional requirements of the software requirement documents. Application of these NLP based newly formulated rules (for passive voice sentences and negative sentences) give more accuracy in automated selection of the class diagram elements. This is obvious that even all rules (counting already existing and novel rules) are not sufficient for extraction of the class diagram elements and thus work can be enhanced in different domains as Work can be improved by inferring more distinctive arrangement of rules and patterns for various sorts of sentence arrangement. Additionally, work can be extended by elicitation and documentation of non-functional requirement similar as a functional requirement, with the assistance of IR techniques in combination with NLP. The anaphora resolution is also a challenging task in NLP. If anaphora resolution can be enhanced than it will lead to more accuracy in automatic extraction of UML models.