
Abstract
The methods of Automatic Extractive Summarization (AES) uses the features of the sentences of the original text to extract the most important information that will be considered in summary. It is known that the first sentences of the text are more relevant than the rest of the text (this heuristic is called baseline), so the position of the sentence (in reverse order) is used to determine its relevance, which means that the last sentences have practically no possibility of being selected. In this paper, we present a way to soften the importance of sentences according to the position. The comprehensive tests were done on one of the best AES methods using the bag of words and n-grams models with the with DUC02 and DUC01 data sets to determine the importance of sentences.
Keywords
Introduction
Currently, information is exponentially growing and thus, the necessary time available for processing. Therefore, it is essential to have methods that allow Automatic Extractive Summarization (AES). The purpose of the methods AES is to generate summaries more similar to those generated by the human. Presently, summaries can be used in different areas. There are employed to summarize information, for example, for videos [1], newspapers [2–4], scientific papers [5] and social networks as Twitter [6, 7] or blog [8], where information rapidly changes and technologies are required to access real-time information represented in reduced form.
According to Ladda Saunmali [9], the purpose of the text summary is to present the most important information in a shorter version of the original text, maintaining its main content and helping the user to quickly understand the large volume of information. According to Alfonseca, Berker, Da Cunha Fanego among others [9–17], the summaries are classified according to their strategy of condensation in abstractive and extractive summaries. The abstractive summaries are those summaries generated from understanding the document and describe the content with words or sentences that sometimes are not in the original text. Instead, extractive summaries are generated from the selection of key phrases, sentences, or paragraphs considered essential for the original text; so, they do not require the understanding of the document.
Among the methods proposed for AES are those that need a large number of language resources [18–23], so they have a high dependence on language or require sophisticated processes to generate a summary. There are also methods that only use the structure and distribution of the original text, so they are less dependent on language [2, 24–29]. The language-dependent methods may show better results than language-independent ones. However, research in language-independent methods has grown because of its possibility to apply to a wide range of languages. In this study, only language-independent extractive methods are considered.
The methods for the AES consider the structure and distribution of sentences to select the most important [2, 28]. The two most used characteristics are: the frequency of terms and sentence position in the text.
The frequency of terms depends on the text model used, for example, the bag of words or n-grams. The bag of word model is easily extracted since only the different words of the document are extracted. However, its terms (words) tend to lose their meaning. The n-gram model considers the document as a set of fixed-length sequence terms, which allows it to maintain the meaning of its terms (n-grams).
According to state-of-the-art methods, the importance of sentences can be determined according to their position in the original text, so this feature is one of the most used in the investigation of AES. The state-of-the-art method considers the hypothesis that from a text with n sentences, the sentence i is weighted as i/n (where i is considered in reverse order). For example, in a small text with 50 sentences, the first sentence is worth 1, while the last sentence is worth 0.02, this makes the last sentence have a very low possibility of appearing in summary, even when the sentence has other important features such as high similarity with the title, a great length, frequent terms, containing numerical data or names own among others. Some papers already propose other ways to calculate the position of sentences, as in [28] which attempts to soften the importance of sentences according to the position by using
Recently in the article by García-Hernández & Ledeneva [2] a new formula has been used to soften the relevance of sentences according to the position; so that of a document with n sentences, the sentence i will have the weighting t (i - x) + x, where x = 1 + (n - 1)/2, and m = slope ∈ [0, …, -1]. The research [28] and [2] have reported some of the best results for the AES with the DUC-2002 data set. However, in both works, they only show results obtained with this data set in a single experiment. Therefore, more than one test must be done in different data sets to guarantee that the results are robust and reliable since the genetic algorithms are random. It is also known that the text model n-grams can help to obtain better results [30] so in this paper, the method proposed by [2] is evaluated to determine the importance of sentences according to their position by the text models: a bag of words and n-grams. Also, adjustments are made to the parameters of the genetic algorithm used in [2], and a way to determine the population size of the genetic algorithm is proposed according to the size of the input document. Finally, different models proposed in the state-of-the-art are tested to calculate the importance of sentences and compared against the proposed model in this paper.
Background
The methods for GARE using genetic algorithms consider significant the features of the text to determine the importance of sentences. Among the most used are:
In addition to the features mentioned above, there are some others that are little used as, sentiment and similarity with the first sentence [32], word length, polysyllabic words and occurrence of nouns [34] pronoun, adjective, weekday/month and quotation [35], indicator of main concepts and occurrence of non-essential information [41], conjunctions [36] and synonym links [11]. The features used in the AES are approximately 28, of which the most used is the sentence position.
Related work
The method proposed by [2] is one of those that have obtained the best results. It is done through a genetic algorithm and uses the bag of word model. The fitness function takes two main features, which are mentioned below:
–
For a text with n sentences, if sentence i is selected for the summary (This is the chromosome |ci| = 1) then its relevance is defined as m (i - x) + x, where x = 1 + (n - 1)/2 and t is the slope for discovering. In order to normalize the sentence position measure (δ), it is calculated the relevance of the first k sentences, where k is the number of selected sentences.
Then the formula to calculate the importance of the first sentences would be as follows:
Finally, to obtain the value of the fitness function, the following formula is applied:
As shown in section 2, different features can be implemented in a method for AES. However, it has been shown that despite using more than two, it does not guarantee that the results will improve [28, 45]. Therefore, in this work, the method proposed by García-Hernández & Ledeneva (2013) is considered, which has shown to have competitive results about other researchers presented up to now in the state-of-the-art.
Next, we explain the proposed genetic algorithm and the modifications made to the method of [2] to perform an improvement based on the positional characteristic of the sentences.
According to Romyna Montiel [46], the models of representation of texts are a technique that is based on the extraction of the terms of a text or document. Text modeling consists of selecting the terms to be extracted and converting them into a pattern that can be analyzed later. The difference between models is the type of term that is extracted from the document. In this paper uses the bag of words and n-grams models. For the n-grams model the value of n = 2, 3, 4 and 5.
if bit = 1, selected sentence and if = 0, unselected sentence
Sentences 1,2,4 and 5 are selected

Graphical representation of the slope value of the line.
The values of the slope considered to calculate the importance of the sentences were m = -0.25, m = -0.3, m = -0.375, m = -0.45, m = -0.5, m = -0.55, m = -0.6, m = -0.625, m = -0.65, m = -0.65, m = -0.7, m = -0.75, m = -0.8., m = -0.85 y m = -0.9. These values are taken at random.
This section describes the experiments and the results obtained with the proposed method. As mentioned, the method is based on a genetic algorithm. The results of the genetic algorithms vary in each execution, so for this investigation, two executions are made for each experiment, and the average of said experiments is presented. In this paper, we use the data set provided in DUC 1 .
Data sets
The experiments were performed with DUC01 and DUC02 data sets. A description of each of them is shown in Table 1.
Description of the data sets
Description of the data sets
For the evaluation, the ROUGE tool is used which is an automatic system for the evaluation of summaries, proposed by Lin [45], which has the ability to measure the similarity and determine the quality of an automatic summary compared to the one created by a human. Our evaluation is done using n-gram (1, 1) setting of ROUGE, which was found to have the highest correlation with human judgments, namely, at a confidence level of 95%. ROUGE evaluates the f-measure that is a balance (not an average) of recall and precision results. The results are presented for ROUGE-1 and ROUGE-2 metrics to 100 words.
Text model
The text models that were used to carry out the experimentation are bag words and n-grams with n = 1, 2,3,4, and 5. The results obtained for each of them are described below with DUC01 and DUC02 data sets. The value of f-measure is presented with ROUGE-1.
Table 2 shows the results for different values of the slope (m) for the text models, bag words, and n-grams. From the results obtained for DUC01, the best result is with the bag words model with 0.45253. Based on the results obtained, it can be concluded that for this data set the first sentences are more important than those of the rest of the documents since the value of the slope on which the best results were obtained oscillates between –0.7 and 0.9.
Results of f-measure for DUC01 with ROUGE-1
Results of f-measure for DUC01 with ROUGE-1
In Fig. 2, the best results are shown by the text models, from which for the DUC01, bag words, and n-grams (with n = 2) is the one that obtains the best results. It can also be seen that the trend line shows that the larger the value of n, the lower the value of f-measure.
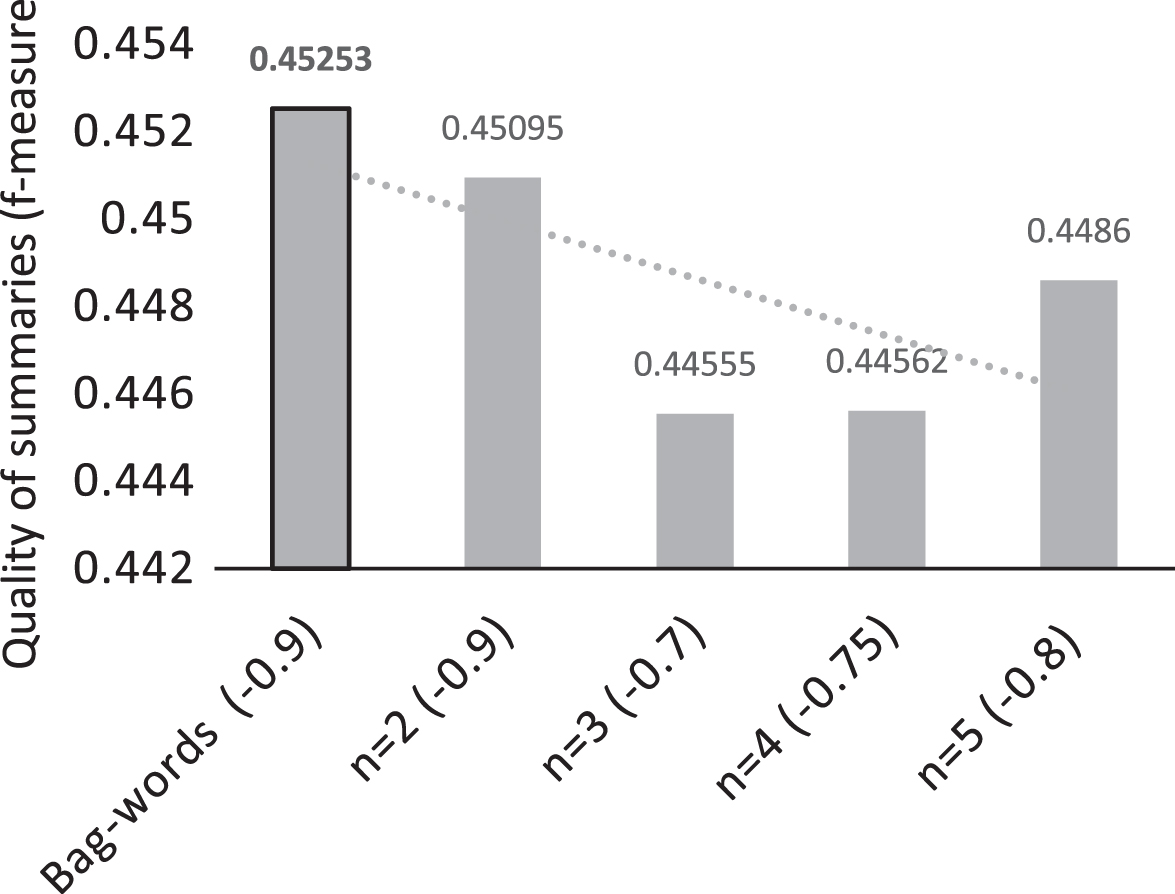
Graph of the best result by text model with DUC01.
In the same way, the experiment was done for the DUC02 data set. The results are shown in Table 3. For DUC02, the best text model is bag words with an f-measure of 0.48183. Based on the results obtained it can be concluded that for this data set the first sentences are more important than those of the rest of the documents since the value of the slope in which the best results were obtained ranges from –0.75 and 0.9.
Results of f-measure for DUC02 with ROUGE-1
For DUC02, it is clearer to see that the trend towards the best results is between the text models bag of words and n-gram with n = 2 (see Fig. 3).
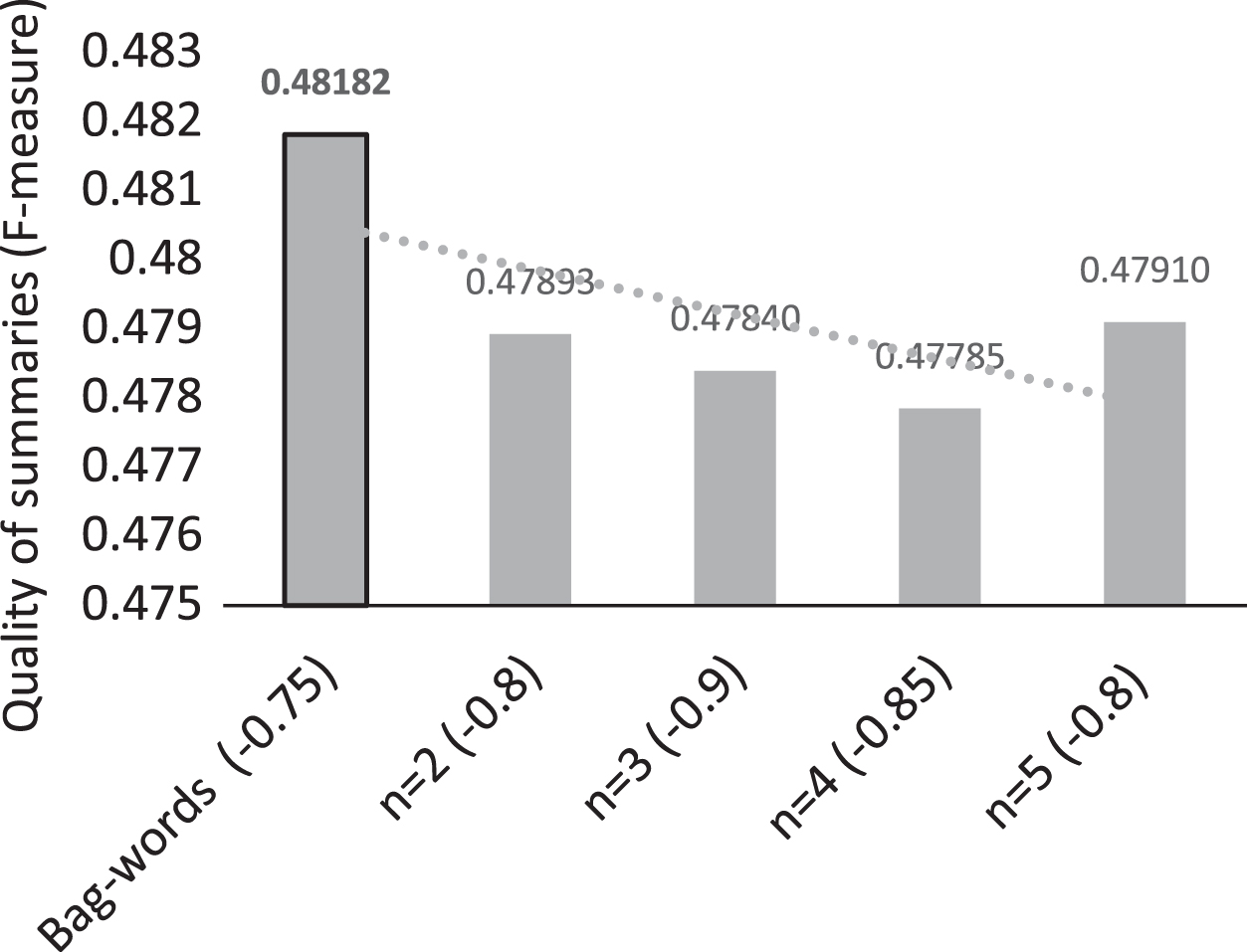
Graph of the best result by text model with DUC02.
The proposed method was tested with the different models proposed in the state-of-the-art (MSA) to calculate the importance of the position of the sentences, described below.
MSA1. Proposed in [47], used a discrete function which gives the value zero (0) in case the sentence is not the first in the text and one (1) otherwise.
MSA2. Proposed in the works of [32] and [28].
MSA3. In the work of [33], two ways of calculating the importance of sentences are proposed (see Equations 7 and 8).
MSA4. In the work of [35] assigns higher scores for terms in the first 4 paragraphs.
MSA5. In the works of [11, 40] and [48] consider up to 5 positions from the top of the document. For instance, the first sentence in a paragraph has a score value of 5/5; the second sentence has a score 4/5, and so on. For example, Equation 9.
MSA6. In [27] three models are proposed to calculate the importance of sentences (see Equation 10, Equations 11 and 12). The results shown in this work are considering the Equation 12.
The sentence score is proportional to its closeness to the end of the document: where i is the sequential number of the sentence in the document.
As in [33] sentence score is proportional to its closeness to the beginning of the document
Finally, the sentence score is proportional to its closeness to the borders of the document where n is the total number of sentences.
MSA7. In [49] a specialized study is made for the corpus DUC01 and DUC02, to determine the best way to calculate the importance of the sentences of these data sets. By DUC01 the Equation 13 and DUC02 the Equation 14.
In addition to the state-of-the-art model to determine the importance of sentences, there is a heuristic that is based on the task of automatic generation of summaries, baseline: first. Baseline:first consists of taking the first n sentences to make up the summary [23]. For state-of-the-art methods and systems, the goal is to overcome this heuristic. Mainly, for the news, it turns out to be very high, since this type of texts contains the most important information at the beginning of the document, for this reason, the importance of comparing with this heuristic.
Table 4 shows a comparison of the different models proposed in the state-of-the-art to determine the importance of the sentences for the corpus DUC01, for this data set it can be observed that the proposed method where the value of the pending obtains the best result. It is worth mentioning that the model proposed in EA7 was built especially for DUC01 and even then, the proposed method obtains better results. It can also be observed that three of the models proposed in the state-of-the-art do not surpass the baseline heuristic: first.
Comparison with different models to determine the importance of sentences with DUC01
In Table 5 a comparison of the different models of the state-of-the-art is made to calculate the position of the sentences for the DUC02 data set. The proposed method is second for this data set. However, the model proposed in EA7 is specially built for DUC02, besides the difference between the proposed method and the first is not relevant. For DUC02, only one model fails to overcome the baseline heuristic: first.
Comparison with different models to determine the importance of sentences with DUC02
The proposed method is compared to other approaches that have used DUC01 and DUC02 collections, and ROUGE-1 and ROUGE-2 evaluations. Such approaches are briefly described in the next: GA-4feature [45] proposes four features, similarity with the title (δ), the position of sentences (β), length of the sentence (γ) and coverture (α), also calculates the weight that each one must-have. The research Vázquez is based on a genetic algorithm. UnifiedRank [50] is a method that proposes a novel unified approach to simultaneous single-document and multi-document summarization, which uses a graph-based representation. DE [51] is a summarization approach based on clustering sentences. Use a discrete Differential Evolution algorithm to optimize the objective function, selecting representative sentences of each cluster. Selection of the summary sentences is done under a recursive scheme, which takes into account the degree of membership of each sentence to the corresponding group, measuring the centrality of each sentence to the group it belongs to, based on normalized google distance. FEOM [52] proposes a Fuzzy Evolutionary Optimization Model. In this approach, sentences are categorized in terms of their content, and after the most important sentence are selected for each cluster. FEOM uses genetic algorithms for the generation of the solution vectors with the groups and applies three control parameters to regulate the probability of crossover and mutation of each solution. NetSum [53] is an approach that use the RankNet learning algorithm to train a pair-based sentence ranker and score every sentence in the document and so identify the most important sentences. This method realizes automatic summarization based on neural nets. CRF [54] proposes a framework that takes the output of previous methods as features and seamlessly integrates them. Treat the summarization task as a sequence of labeling problem. The framework is based on Conditional Random Fields. GA-2feature [2] proposes a Genetic Algorithm to extractive summarization through 2 sentence features sentence position (slope based linear equation) and term frequency (precision-recall).
It is worth mentioning that more state-of-the-art methods test with data sets DUC01 and DUC02. However, they perform a division of sentences different from that stipulated in the data sets. So, they are not considered in this paper.
Below are the results corresponding to ROUGE 1 and ROUGE 2 obtained in each data set for the state-of-the-art methods and the proposed method. In Table 6, the results of data set DUC01 are presented and in Table 7, the results of data set DUC02.
F-measure score ROUGE-1 and ROUGE-2 of the related works with the DUC01
F-measure score ROUGE-1 and ROUGE-2 of the related works with the DUC01
F-measure score ROUGE-1 and ROUGE-2 of the related works with the DUC02
Table 8 shows the position of each method and system with respect to the results obtained by each measure. The resulting ranking matrix was calculated as proposed in [55] as follows (see Equation 15):
Global ranking estimated by the partial rakings obtained in each evaluation of ROUGE-1 and ROUGE-2 in the DUC01 and DUC02 data sets
where n is the number of methods and systems involved for the comparison, and R r refers to the number of times that the method or system affects the r-th position.
The ranking matrix allows us to determine which is the best method; in this case, the AG-4feaure method and the proposed method are the ones with the best results.
In this paper, it was possible to determine the importance of the position of the sentences for the corpus in English DUC01 and DUC02. In addition to determining the appropriate text model for the AES in these two data sets.
For DUC01 the best result was with the text model n-grams with n = 2 and a slope of –0.9. For DUC02, the best result was with the bag of words text model with a slope of –0.75. For both data sets, the bag of words text model obtains good results and the trend observed is that the larger the number of n (n-grams) the quality of the summaries decreases. The positional feature of the sentences for the AES is one of the most used by the importance and the contribution it offers to the state-of-the-art methods. In this paper different models proposed in the state of the art were tested to calculate the importance of the sentences and it could be determined that the model that uses the slope of a line is the best one, which is independent of the language and the domain. To be able to adjust the slope can be implemented in any method and with any data set.
Additionally, a comparison of the proposed method with the state-of-the-art methods was made. The proposed method is positioned first together with the method proposed by [45].