
Abstract
Automatic text summarization is the task of creating concise and fluent summaries without human intervention while preserving the meaning of the original text document. To increase the readability of the languages, a summary should be generated. In this paper, a novel Nesterov-accelerated Adaptive Moment Estimation Optimization based on Long Short-Term Memory [NADAM-LSTM] has been proposed to summarize the text. The proposed NADAM-LSTM model involves three stages namely pre-processing, summary generation, and parameter tuning. Initially, the Giga word Corpus dataset is pre-processed using Tokenization, Word Removal, Stemming, Lemmatization, and Normalization for removing irrelevant data. In the summary generation phase, the text is converted to the word-to-vector method. Further, the text is fed to LSTM to summarize the text. The parameter of the LSTM is then tuned using NADAM Optimization. The performance analysis of the proposed NADAM-LSTM is calculated based on parameters like accuracy, specificity, Recall, Precision, and F1 score. The suggested NADAM-LSTM achieves an accuracy range of 99.5%. The result illustrates that the proposed NADAM-LSTM enhances the overall accuracy better than 12%, 2.5%, and 1.5% in BERT, CNN-LSTM, and RNN respectively.
Keywords
Introduction
In Text Summarization, web resources like user reviews, websites, current news, blogs, social media, and many other sources are available on the Internet and developed rapidly which is considered to be the major source of textual content, and after that came textual data proliferation does on many media, including news reports and magazines, legal records, biomedical files, research articles, etc. [1]. Consequently, the data retrieving process is time-consuming and highly complicated. It is not applicable for reading and understanding the text data of search outcomes [2].
Uncertainty leads to irregular data in the absolute context. Hence, summarizing the text is highly essential significant for better understanding. Generally, manual summarization is complicated and time-consuming due to the application of enormous textual content [3]. ATS is one of the best solutions to overcome predefined issues. The major responsibility of the ATS model is to generate a summary with effective suggestions and opinions for input documents with limited storage space and the reputation of a method has to be retained [4].
The ATS technique is quite helpful for people to extract the necessary and important information from background papers without having to read the entire document. Furthermore, an automatically created summary greatly benefits users as it consumes minimum time and work [5]. An automated summary is depicted as: ”The productive summary purifies an essential content from an original document and generates a compact version of significant details for a specific user(s) and operation (s)” [6].
A summary is simply called a text generated from maxi-mum texts, that represents the essential data as same as actual text(s). Here, the text involved can be applied to speech, multimedia documents, hypertext, and so on [7]. Therefore, the emulated summary is too small when compared to the input text and is composed of vital content [8, 9]. Single Document Summary (SDS) and Multiple Document Summary (MDS) ATS models are classified. The first model generates a synopsis from a single document, whereas the second generates a synopsis from a group of papers. [10].
An ATS contains three types they are Extractive, abstractive, and Hybrid. Initially, an extractive model is used for selecting significant sentences from the input documents and a summary has been generated [11, 12]. Secondly, the abstractive framework shows the input text in in-between for-mat and summarizes effectively with the drastic difference among the original text [13]. Finally, a combination of extractive and abstractive approaches is defined as a hybrid method. The typical structure of the ATS method is depicted in Fig. 1 and the different components are listed below [14, 15].

Structure of ATS model.
The main contributions of the proposed NADAM-LSTM-based ATS technique are given asfollows. Initially, the Giga word Corpus dataset is pre-processed utilizing Tokenization, Word Removal, Stemming, Lemmatization, and Normalization. In the summary generation phase, the text is converted to the word-to-vector method. Further, the text is fed to LSTM to summarize the text. The parameter of the LSTM is then tuned using NADAM Optimization. The performance analysis of the proposed NADAM-LSTM is calculated based on parameters like accuracy, specificity, Recall, Precision, and F1 score.
The remaining portion of the work has been followed by, Section 2, which discusses the literature review. Section 3 illustrates the proposed NADAM-LSTM-based TS method. Section 4 illustrates the Results and Discussion of the proposed technique. Section 5 discusses the conclusion.
ATS is a technique for condensing long texts so that the summary contains all of the important points from the original document. This section discusses several text summarization methods that have been performed in this area due to the importance of Automatic text summarization.
In 2020 Mansoor, M., et al., [16] presented a deep-learning method for predicting duplicate question pairs. This method used CNN and LSTM networks, which are suitable for storing long-term dependencies. This suggested method of finding duplicate questions utilized DL models worked very well and gave better results than existing techniques. The suggested model was computed using the Quora dataset and achieved an acc of 87.50%.
In 2022 Sharma, J., et al. [17] developed a long-term solar PV power forecasting method based on the LSTM technique with the Nadam optimizer. Because it retains information from more time steps, the LSTM technique works better with time series data. The Nadam optimizer outperforms the autoregressive integrated moving average by 30.56%, the seasonal autoregressive integrated moving average by 47.48%, and models employing the RMSprop, Ada-max, Adam, Ftrl optimizer, SGD, Adagrad, and Adadelta by 1.43%, 1.35%, 3.51%, 11.84%, 4.88%, 50.69%, and 58.29%.
In 2022 Jain, A., et al. [18] devised a Hindi Health Data (HHD) corpus, an ATS method for the Hindi languages. ATS employs the Real Coded Genetic Algorithm (RCGA), which uses choice, designed to simulate Boolean Crossover (SBX), and Quadratic formula Mutation to optimize feature weights. The ATS extraction system reduces summary by 65% when compared to current summarizingtechniques.
In 2019 Thattinaphanich, S. and Prom-on, S., et al., [19] introduced a Bi-LSTM-CRF application with word. First, in this method prepare the text by symbolizing a sentence into a group of words. This model has been evaluated by the NER open-source corpus of the ThaiNLP Facebook group. The model results for precision, recall, and F1 score are 91.51%, 91.79%, and 91.65%, respectively.
In 2019 Song, S., et al., [20] created an ATS framework (ATSDL) built on LSTM-CNN that can build new sentences by finding pieces better than sentences, i.e., semantic sentences. Regarding semantic and syntactic structure, the ATSDL framework surpasses the state of the art and gets comparable results in terms of quality assessment, according to test findings on the CNN and Daily Mail datasets. Increase the use of written speaking.
In 2021 Jiang, J., et al. [21] suggested four new ATS models with sequence structure (Seq2Seq), using two-way attention-based LSTM, with additional improvements to increase the correlation between summary summaries generated and source text, solve out-of-vocabulary (OOV) problems, eliminate repetitive words, and prevent the propagation of errors that accumulate in generated text summaries.
In 2019 Rahman, M.M. and Siddiqui, F.H., et al., [22] presented an abstract text summarization model, LSTM (MAPCoL), a multilayer convolutional peephole ie automatically produces a summary from a long text. MAPCoL also outperforms traditional LSTM-based methods when it comes to semantic consistency in output summaries.
In 2023 Al Abdulwahid, A., et al., [23] presented a synthesis of short text with improved accuracy using a state-of-the-art algorithm called BERT. The suggested strategy, which aims to enhance the duration and accuracy of training data for short text summaries, using a confusion matrix to track and analyze results and enhance them, BERT+Transformer has been proven to be 97% accurate.
In 2019 Al Munzir, A., et al. [24] introduced an extracted text summarization technique based on a recurrent neural network (RNN) deep learning model to summarize a single document. Our method consists of classifying sentences as meaningful or not to the summary. We used an RNN based on short-term long-term memory (LSTM), and generalized repeat units (GRU). Overall, LSTM was found to be more promising, with average F1 scores of 0.63, 0.59, and 0.56 for Rouge-1, Rouge-2, and Rouge-3, respectively.
In 2018 Li, Y., et al. [25] suggested CS-GAN, a text-generation model that can capture sentence construction and to include categorization data helpful for supervised learning. Particularly with multi-category datasets, the proposed technique must be capable of supervised learning with produced phrases. The suggested working model was also tested exclusively on the sentiment classification task, where CS-GAN excelled with a range of phrase lengths, especially for a small labeled dataset containing brief sentences.
Review comparison
Summary of the literature review
According to the literature review, most approaches fail to achieve topic identification, interpretation, summary generation, and evaluation of the generated summary. To overcome these drawbacks, Nesterov-accelerated Adaptive Moment Estimation based Text Summarization (NADAM- LSTM) has been proposed, which increases the energy efficiency and network lifetime and eliminates redundant data.
Structure of the paper
In this paper, a novel Nesterov-accelerated Adaptive Moment Estimation Optimization based on Long Short-Term Memory [NADAM-LSTM] has been proposed to summarize the text. The proposed NADAM-LSTM model involves three stages namely pre-processing, summary generation, and parameter tuning.
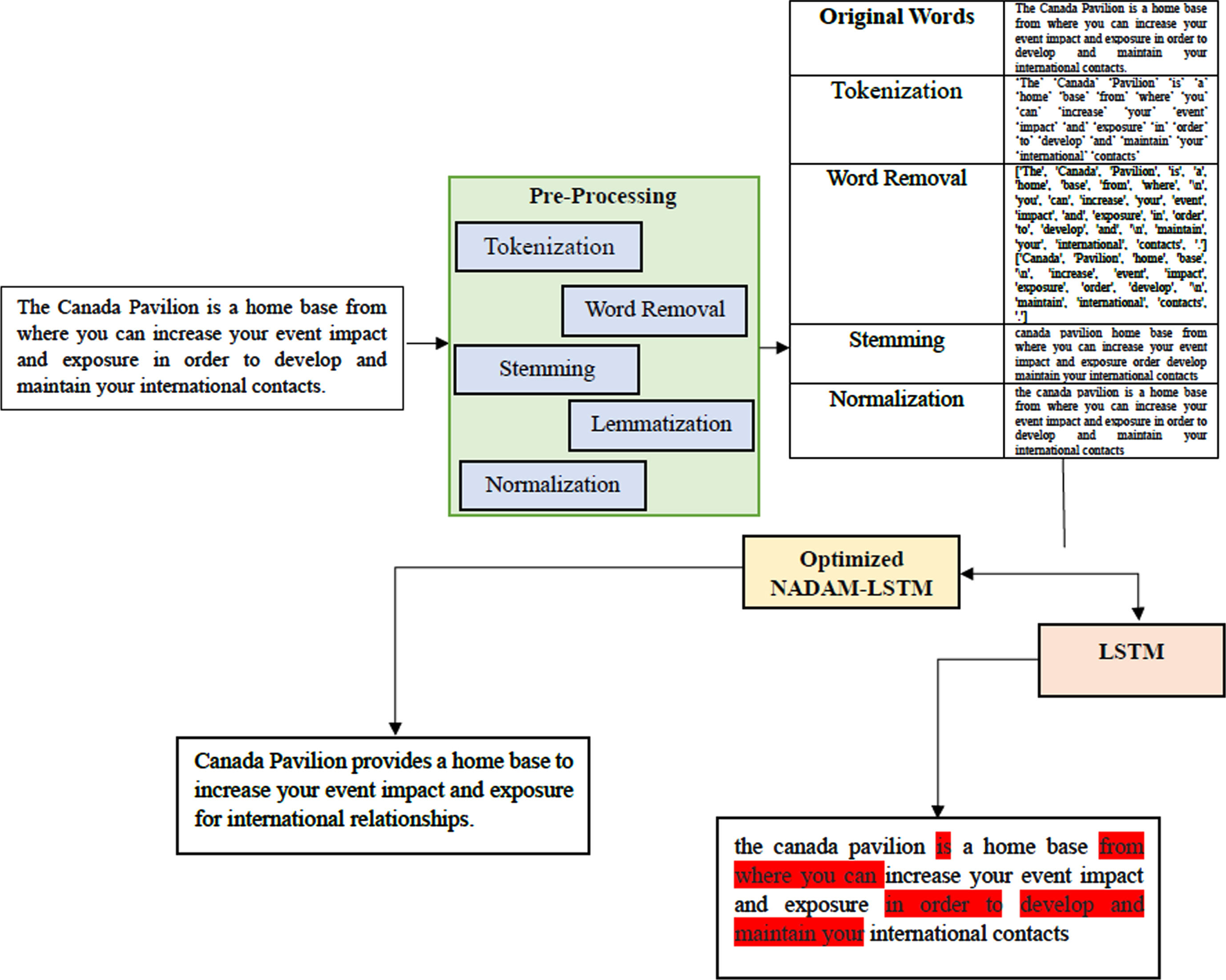
Initially, the Giga word dataset is pre-processed using Tokenization, Word Removal, Stemming, Lemmatization, and Normalization. In the summary generation phase, the text is converted to word vector method. Further, the text is fed to LSTM to summarize the text. The parameter of the LSTM is then tuned using NADAM Optimization. The architectural structure of the proposed technique is illustrated in Fig. 2.

Proposed NADAM-LSTM.
Comparative analysis with existing techniques
The modifying or removing of data before use to ensure or improve performance is known as data preprocessing, which is an important step in the data mining process. In the starting phase, noise from the data has been eliminated from the social media by applying the given procedures: Remove the URL through routine expression mapping. A regular expression is defined as a textual pattern that shows the exploring pattern of strings and text. Restore “@Username” with “usr” by applying regular expression matching. As “hash-tag (#)” offers helpful details, it eliminates # and retains the word as same. viz., “# Lee” is restored with “Lee”. Avoid forward slash (/), parenthesis, backward slash (∖), and – from Twitter context. Eliminate multiple white spaces by replacing single white spaces.
Pre-processing methods include tokenization, word Removal, Stemming, Lemmatization, and Normalization. The majority of these methods are typically applied during an ATS system’s pre-processing stage. Tokenization:
Tokenization preserves the sense of the text while breaking it up into useful data. In this step, long paragraphs also referred to as pieces of text or tokens are divided into individual phrases. These phrases can also be divided into individual words. Word Removal:
In this process, repeated words are removed from the text. There are several stop words, such as “are,” “of,” “the,” and “at.” As a result, these must be removed from the text. Stemming:
Through the process of stemming, words in several tenses are reduced to their most basic forms, eliminating needless computations. Lemmatization:
A lemmatization process combines two or more words into one single word. This process eliminates endings such as shocked to shock, caught to catch, etc based on the morphology of the word. Normalization:
Many actions are completed at once to accomplish normalization. In the process, all text will be converted to upper- or lowercase, punctuation will be removed, and numerals will be replaced with words. Consequently, each text will undergo more uniform pre-processing.
DL-based summary generation
The Nesterov-accelerated Adaptive Moment Estimation (NAdam) technique augments the Adaptive Movement Estimation (Adam) optimization process with Nesterov’s Accelerated Gradient (NAG) or Nesterov momentum, which is an upgraded kind of momentum.
GloVe
GloVe, which stands for Global Vectors, is a distributed word representation approach. This model produces vector representations of words using an unsupervised learning process. GloVe stands for Global Vector, and GloVe Embedding is a distributed word representation method for text extracted from web pages that use unsupervised learning. Because GloVe is implemented in parallel, training on data is made simpler. It displays, in vector space, the semantic relationships between words. A global co-occurrence matrix X was built to train the GloVe word embedding model with words from the Wikipedia dataset. This post makes use of vectors with an embedding layer of size 100 that were generated using a vocabulary of 400,000 words, as well as pre-trained word vector data called glove6b.zip.
In the co-occurrence matrix, X: Xij represents the number of context words i that occur with word j. The GloVe model minimizes the following objective function:
The LSTM network is a deep learning-related recurrent neural network (RNN) network development. LSTMs, as opposed to feature feedback links, are standard feed-forward networks. Since 1997, Juergen Schmidhuber and Sepp Hochreiter have been developing the LSTM to address the vanishing gradient problem with RNN. Nowadays, LSTM has a wide variety of applications because of the organization and popularization it underwent in the past by multiple people. LSTM networks are highly suited to categorize, analyze, and predict utilizing time series data since significant events in a time series may occur at unpredictable times apart. Output to determine what has to be remembered and what can be disregarded. The LSTM cell also has cell update, commonly known as the tanh layer, which is typically a component of the cell state, in addition to the three gates. There are three variables assigned to each LSTM cell: Xt, current input, ht–1, previous output, Ct–1 previous cell status. In contrast, two variables emerge from the cell: ht current output, and Ct current cell status Fig. 3 depicts the LSTM model’s structure. The LSTM cell must first be used before implementing the LSTM repetitive network.
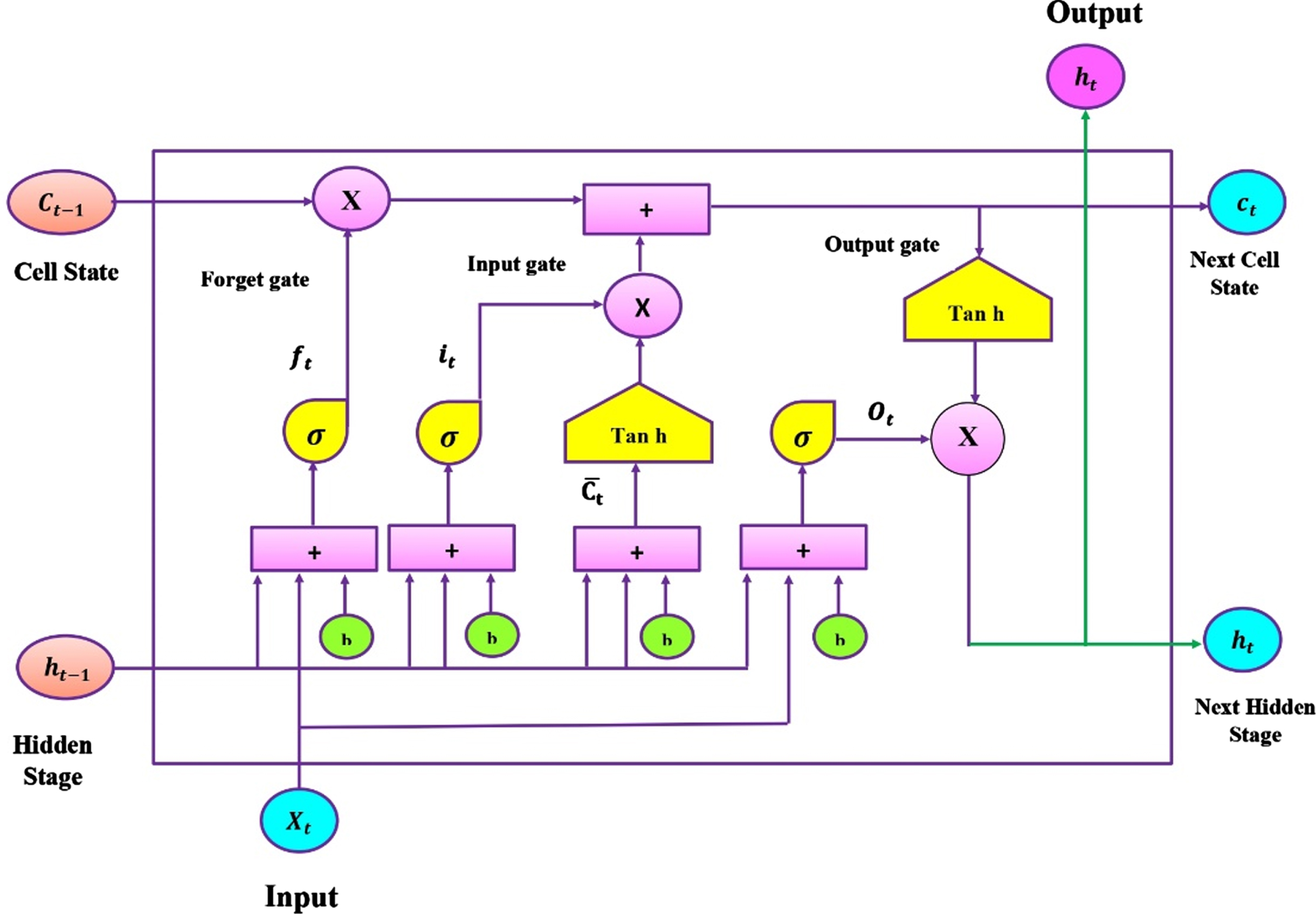
Architecture of LSTM.
The bias vector restrictions must be acquired during training. The integers d and h reflect the number of input features and hidden units, respectively.
The network learns new information by contrasting it with prior states while choosing whether to maintain the current input. The prior state vector, ht-1, contains the modifications to the previous input and output. Based on this, the first input gate’s sigmoid function range is a number between 0 and 1, which represents the range of new information accessible at the current input. The value produced is equal to the input value times 1. Become. As a result of the input gate values’ range of [0,+], the input vector stays clear of vanishing gradients for values in the same range, enabling the network to gain knowledge from each input.
For the candidate vector
The current hidden state (hs) and current memory state (Cs) are the LSTM’s memory cell outputs. Equations (3) and (4) reflect the LSTM neural network’s output gates and hidden states, respectively.
The LSTM cell’s first stage is to determine which information should be removed from the cell status. A SiLU layer also called the “Forget Gate Layer” makes this choice. (f t ). It checks the X t and ht-1, then assigns Ct-1 a cell status between 0 and 1 representing an output value. The expression “Forget This Fully” is expressed by the output value of 1, and the phrase “Get Rid of This Fully” is conveyed by the output value of 0.
Choosing what additional data should be added to the cell state is the next stage. There are two components to it. The “input layer,” a SiLU layer, chooses which values should be updated first. Next, a tan h layer generates a new applicant value vector,
In the next level, to update the state, i
t
and
Finally, a decision is taken about what will be produced. The output is influenced by the condition of the cell. It could, however, be a filter version. A SiLU layer is first conducted to decide where the output will be delivered in the cell state. The new value is multiplied by the output of the SiLU between (+1) and (–1) generated from the cell state C t by the o t tan h layer.
NADAM is constructed with a combination of ADAM and Nesterov Accelerated Gradient (NAG). NADAM is better than ADAM because NAG could achieve better results than classic momentum. The proposed NADAM-LSTM model involves three stages namely preprocessing, LSTM-based summary generation, and NADAM-based parameter tuning. The classical LSTM method is not applicable to capture longer distance semantic connections; even if it is capable of transferring semantic data among words. In the case of parameter training, a gradient is reduced slowly until it gets diminished. Finally, the length of the series data is mitigated. Figure 4 illustrates the performance ofNADAM-LSTM.
Performance of NADAM-LSTM.
LSTM is a well-known model applied in resolving the gradient diminishing by using Input gate j, Output gate 0, Forget gate g as well as Memory cell. Here,
Forget gate g estimates the data to be forgotten in the Memory cell at the consequent moment. The input is f (s-1) and y (t). Hence, output values among and 1. The estimation model is depicted as:
Followed by, fs-1 and Y
s
shows the inputs of the LSTM unit. V
g
denotes a connecting weight of Y
s
and forget gate g. Q
g
implies connecting the weight of fs-1 as well as forget gate g. means a state of a Memory cell at the final moment. W
g
depicts a connecting weight of Ds-1 and forget gate g. C
g
refers to a bias term. 0 represents a SiLU activation function. The input gate computes the data to be upgraded in the Memory cell recently. The calculation approach is depicted as:
Hence, V
j
signifies a connecting weight of Y
s
and j
s
, Q
j
denotes a connecting weight of fs-1 and j
s
, W
j
implies a connecting weight of Ds-1 and j
s
. V
d
refers a connecting weight of Y
s
and D
i
n
s
shows a connecting weight of D
i
n
s
and Fs-1. tan f defines a tan f activation function. g
t
and j
s
refers to the weights of Ds-1 and D
i
n
s
. C
j
and C
D
indicates the bias terms. The output gate computes the final value of the LSTM unit. Henceforth, the calculation mechanism is illustrated as,
Where denotes the connecting weight of Y s and P s . Q p means the connecting weight of fs-1 and P s W p showcases a connecting weight of Ds-1 and P s . C p implies a bias term.
The model uses the pseudo-code of optimization algorithm Nadam, as shown in Algorithm.
Nesterov-accelerated adaptive moment estimation is attempted by the Nadam optimizer in the Adam. The major benefit of this integrative manner is that the adaptive moment estimation used allows for highly accurate steps in the transformed data via notifications of design variables with the momentum growth and developmental to gradient computation.
Sentences are rated and sorted according to the weights that have been given to them. The input material is parsed into its high-level paragraphs, a thorough summary is produced, and the summary is then recorded as audio. A significant variety of information retrieval tasks, including categorization, sentiment classification, and others, heavily rely on ranking. Sentence rating is a technique used by researchers to identify suspicious and original sentence pairings in texts that contain both original and suspicious sentences. The strategy is based on how similarly related the sentences are. Using this method, which eliminates superfluous words and streamlines execution, a list of source and suspect sentence pairings is generated. The idea of sentence ranking is discussed in this study. A dataset from the original with “n” unique words is kept as a starting point. Then, each sentence in the suspect document is compared to each sentence in the original document using a vector-matching technique. They determine the cosine angle between two words using a cosine similarity metric. The question and sentence vectors are increasingly similar the closer the cosine angle is near 1.0, which has a value between 0 and 1. As a consequence, they amass a collection of similarity measure values between each suspect paragraph and the phrases in the original text. We choose the paragraph pairings from the collection with the best accuracy value.
Result and discussion
The experimental arrangement of the proposed NADAM -LSTM-based TS was implemented utilizing MATLAB to identify Automatic Text Summarization. Accuracy, specificity, precision, and recall are the different metrics used to evaluate it. Several text summarizations are used to evaluate the suggested model’s effectiveness. A comparison of the suggested NADAM-LSTM Performance with BERT, CNN-LSTM, and RNN, is made. Regarding Recall, Precision, Accuracy, and F-Measure. MATLAB is used to run the simulation.
Dataset description
The Giga Word Dataset contains headline generation on a corpus of article pairs from Giga Word, which contains approximately 4 million articles in English. Text file with a size of 4M. The dataset contains just over one billion words drawn from a variety of sources dating back to 1950. It is intended to be representative of text summarization, which includes texts published between the 1950 s and the present. The most recent significant change in written summarization was the gradual elimination of subject-verb agreement. Even though most spoken varieties had lacked this distinction for centuries, the written standard required the use of distinct singular and plural forms of verbs.
Performance analysis
The effectiveness of the categorization strategy is assessed utilizing the following statistical parameters such as accuracy, recall, precision, and F1 score.
Where TN, FN depicts the true negative and false negatives and TP, FP depicts the true and false of the sample.
The proposed model exhibits good accuracy in both training and testing, as shown in Fig. 5. Raising the epoch value enhances the model’s performance. To demonstrate how the model loss lowers as the period size grows, the loss curve and epochs are displayed in Fig. 6. As a result, the model’s predictions of the outcomes were very precise.

Training and Testing accuracy curve of NADAM-LSTM.

Training and Testing accuracy curve of NADAM-LSTM.
For example, the recommended abstract size ratio should be 33–40%, but some abstracts have a size ratio of up to 80% of the specified text. About 40 items are divided into various sections, as shown in Fig. 7.
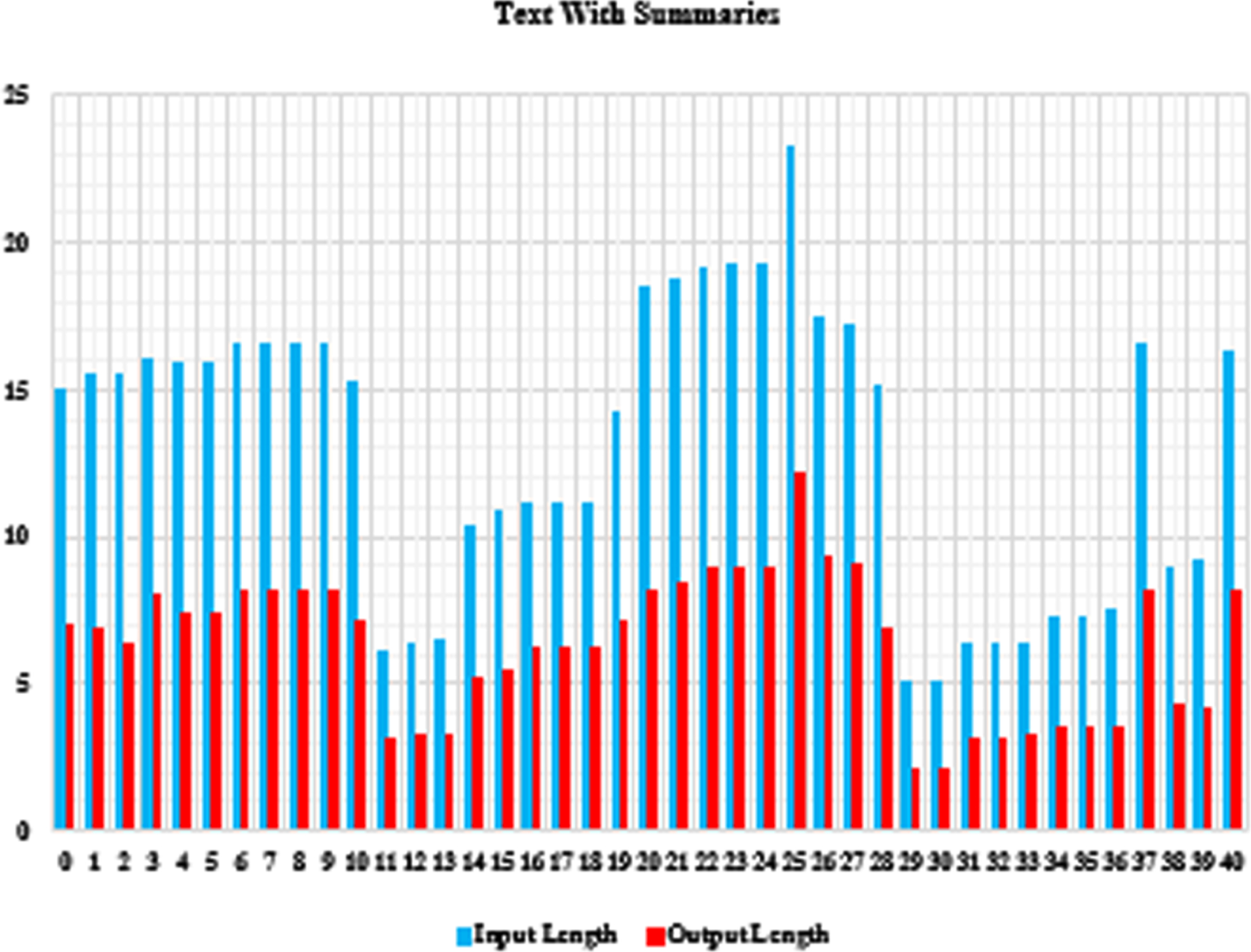
Raw text line counts with line count output summaries.
Figure 8 shows the Sentence via Text Rank Score. The graph-based ranking method forms the foundation of the Text Rank algorithm. Google’s web searches are where it is most commonly utilized, but it has numerous other uses as well. To determine a vertex’s relevance, graph-based ranking algorithms consider data about the entire graph rather than just vertex-specific data.

Sentence via Text Rank Score.
The knowledge of the connections (edges) between the vertices would be a typical piece of information. they must specify the vertices and edges we intend to use in the NLP scenario. In this instance, sentences will serve as the vertices and words as the edges of the connections. As a result, sentences containing words that are used in numerous other sentences are given more weight.
Figure 9 demonstrates the gradual reduction in training and test errors as well as the strong generalization of the qualified AE. Small quantities of random noise were added to the input representation to get rid of zeros and make ensembles easier. The outcomes show that simply eliminating ze-roes is ineffective; AE (Ltf) consistently outperforms Ltf-NAE. SKE data is included in the comparison because it is bigger and more varied. The average squared reconstruction error of the train and test sets for Ltf-NAE (Uniform) and AE(Ltf) for the SKE corpus, plotted against the number of epochs(iterations).
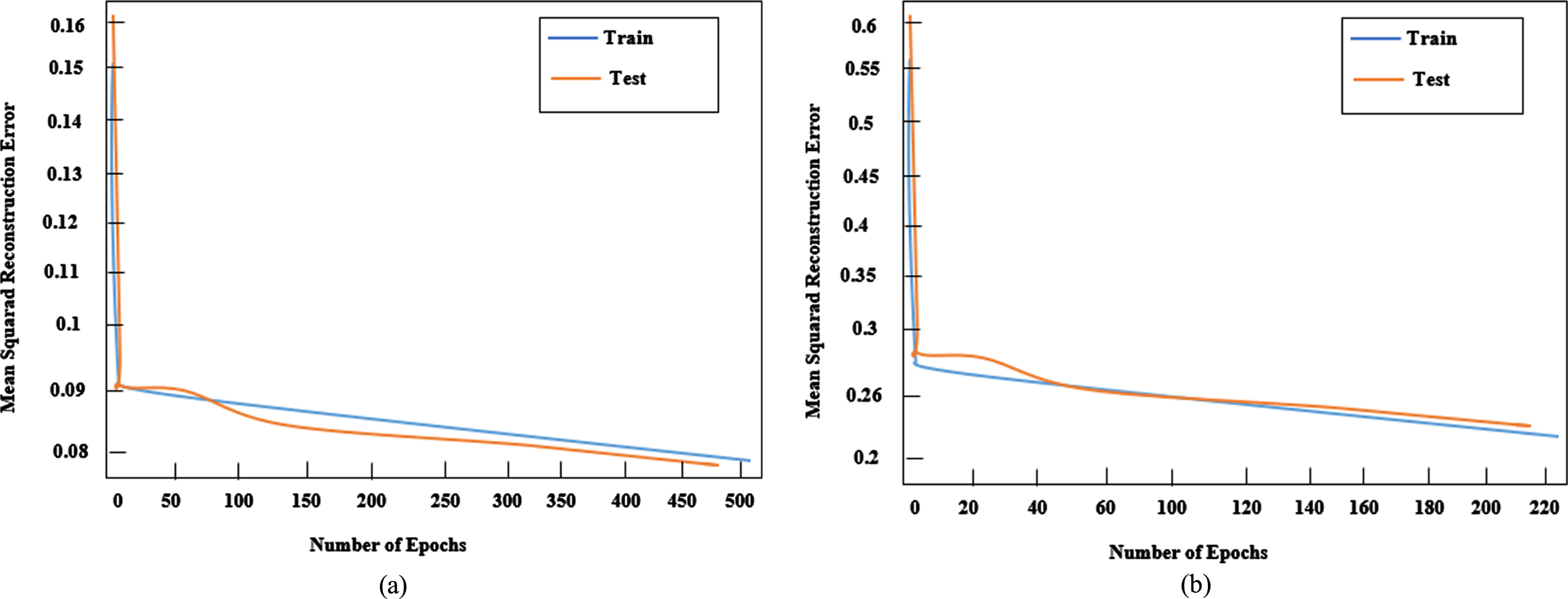
Mean squared reconstruction error via the number of epochs.
A comparison of the suggested model and the present DL model is done in this part. We used accuracy, recall, F1 score, and performance comparisons of current approaches to demonstrate that the outcomes of the suggested strategy are more successful.
Figure 10 (a) shows the training and testing of Standard Input with the overall accuracy of the proposed method is 99.5%. A small paragraph is given to train the overall accuracy.

(a) Case Study I Standard Input.
Figure 11 (a) shows the training and testing of Standard Input with the overall accuracy of the proposed method is 89.5%. A small paragraph is given to train the overall accuracy.

(b) Case II Customized training and testing.
Figure 12 depicts a ROUGE point with different epoch values. The epoch number specifies how many times the same data was utilized to train the algorithm. The number of epochs in this event ranges from 100 to 250. As the number of epochs grows, the efficacy of NADAM-LSTM improves. However, the efficiency increase from 100 to 200 epochs is significant and continues after that. When the number of epochs exceeds 200, the issue of overfitting arises. As a result, when the methods are trained for more than 200 epochs, their efficiency does not increase.

Average performance of the proposed method on various epoch numbers.
An ablation study was made to assess the efficiency of the NADAM employed in the optimization stage. This experiment, with NADAM Optimization and without NADAM Optimization was illustrated in Fig. 13 according to a comparison of the optimization process of the accuracy, precision, and specificity. According to our findings, optimization utilizing ablation methods was typically less accurate than optimization using the NADAM method, which proves the usefulness of the NADAM method in the optimization process.

Performance comparison in ablation study when removing optimization.
Initially, evaluated the effectiveness of the proposed NADAM-LSTM method and the ablation study was performed with and without NADAM. There is a possibility that the model without NADAM had the lowest accuracy in optimization. The optimization model the text summarization uses high-level optimization.
Figure 14 illustrates the Performance comparison in the ablation study. Evaluated the effectiveness of the proposed NADAM-LSTM technique and the ablation study is performed with and without Activation Layer. There is a possibility that the technique without sigmoid had the lowest accuracy in optimization. The technique for activation the text summarization uses a high-level Activation layer.

Performance comparison in ablation study.
In this paper, a novel Nesterov-accelerated Adaptive Moment Estimation Optimization based on Long Short-Term Memory [NADAM-LSTM] has been proposed to summarize the text. The proposed NADAM-LSTM model involves three stages namely pre-processing, summary generation, and parameter tuning. Initially, the Giga word Corpus dataset is pre-processed using Tokenization, Word Removal, Stemming, Lemmatization, and Normalization. In the summary generation phase, the text is converted to the word-to-vector method. Further, the text is fed to LSTM to summarize the text. The parameter of the LSTM is then tuned using NADAM Optimization. The performance analysis of the proposed NADAM-LSTM is calculated based on parameters like accuracy, specificity, Recall, Precision, and F1 score. The suggested NADAM-LSTM achieves an accuracy range of 99.5%. The experimental result shows that the proposed NADAM-LSTM enhances the overall accuracy better than 12%, 2.5%, and 1.5% in CNN-LSTM, BERT, and RNN respectively. In the future consequences of expanding the extent of the model’s training data may be examined in further research. Using data from the same domain as the training data to train the fast Text shallow neural network and produce word embeddings for the same is another option that may be taken into account.