
Abstract
This paper presents a novel deep learning based approach to solving arithmetic word problems. Solving different types of mathematical (math) word problems (MWP) is a very complex and challenging task as it requires Natural Language Understanding (NLU) and Commonsense knowledge. An application on this can benefit learning (education) technologies such as E-learning systems, Intelligent tutoring, Learning Management Systems (LMS), Innovative teaching/learning, etc. We propose Deep Learning based Arithmetic Word Problem Solver, DLAWPS, an intelligent MWP solver system. DLAWPS consists of a Recurrent Neural Network (RNN) based Bi-directional Long Short-Term Memory (BiLSTM) to classify operation among four basic operations {+ , - , * , /}, and a knowledge-based irrelevant information removal unit (IIRU) to identify the relevant quantities to form an equation to solve arithmetic MWPs. Our system generates state-of-the-art results on the standard arithmetic word problem datasets –AddSub, SingleOp, and a Combined dataset.
Keywords
Introduction
Researchers in the field of MWP applied various Artificial Intelligence (AI) based techniques such as Natural Language Processing (NLP), Natural Language Understanding (NLU) using Information Extraction (IE), Machine Learning (ML) and Deep Learning (DL), Learning (Education) Technologies, etc., in solving word problems. Parallel research have been carried out by the researchers of others fields like Cognitive Science, Psychology, Education, etc [18]. Therefore, this research field is interdisciplinary in characteristics that has attracted researchers from different domains from the decades of 1960 starting with [2].
[32] described word problems as a mathematical query where the background information is presented in natural language texts rather than mathematical notations. Researchers have worked on standard datasets consisting of arithmetic word problems of elementary level school education with the basic arithmetic operations - addition (‘+’), subtraction (‘-’), division (‘/’) and multiplication (‘*’). However, a math word problem can be any numerical problem consisting of numbers and operations following mathematical theories like geometry, number word problem, algebra, probability, etc. [23]. Table 1 shows a simple word problem taken from a standard dataset. Challenges in solving arithmetic word problems can be found in Section 1 of [18].
A sample word problem from the AddSub dataset
A sample word problem from the AddSub dataset
Researchers in this field have generally employed various rule-based approaches and machine learning techniques to solve simple arithmetic MWPs. Recently, motivated by the success of deep learning in NLP and IE, various deep learning techniques such as sequence to sequence (seq2seq) RNN, Reinforcement Learning, etc., are being proposed by various researchers for solving MWPs. We propose an RNN based BiLSTM network to classify operations. We also developed a Knowledge Based IIRU, a relevance classifier, to identify the relevant quantities (RQ) required to solve MWPs. We propose a single equation schema, as in Equation 1, where the relevant quantities along with the predicated operation fit into and the equation is evaluated to generate final answer.
The proposed work contributes in various aspects of solving word problems as given in the list below. A bi-directional LSTM based deep learning technique to classify operations An intelligent Irrelevant information removal unit (IIRU) to identify the relevant quantities A template-free solution to generate the final answer A new state-of-the-art results on two standard datasets
We propose a simple approach to form the final equation without using any templates as used in some existing DL based math solvers. Additionally, the code will be published after the publication of the paper. Next, in Section 2, we describe some specifically related works in solving arithmetic word problems. Later we explain our system in details with all important components in Section 3. Section 4 contains a description about datasets, dataset variants, and results with critical discussions followed by some conclusions in Section 5.
Related work
Arithmetic MWPs, its ambiguities, and varieties, and how a child in elementary school is able to solve them by their coherent learning and understanding, is always an interesting research problem for the researchers of cognitive science, education, children psychology and problem-solving, etc. The works of [3, 33] were based on cognitive science and psychology which simulated human cognition of problem solving to solve word problems. However, these works supplied important clues towards automatically solving word problems, especially in categorizing word problems or problem schema. This research deals with the human natural intelligence of problem understanding and solving through learning. Therefore, it attracts the attention of the researchers in the domain of AI such as NLU, Machine learning, etc., who have been developing computer algorithms to solve this problem automatically since the 1960s [2, 5]. Reviews on solving various word problems are available in [18, 41].
Automatically solving word problems was first proposed by [2] with the accompanied system –STUDENT. Based on the works of [3, 31], [6] developed WORDPRO which implemented the theory of comprehension. [4] developed ARITHPRO which represented word problems by a lexicon of knowledge. [1] simulated ROBUST capable of solving multi-step (i.e., multiple equation) arithmetic word problems. With the advances of AI, NLP, ML, DL techniques, the research gains momentum in recent years. [15] learns to solve word problems statistically with predefined equation templates along with the answers. [14] developed ALGES representing MWPs into a set of possible expression trees and learned to choose the ‘best’ equation expression tree. [27–29] proposed various methods to understand a word problem and developed algorithms to form expression tree (representing a word problem) with relevant quantities. [30] prepared a dataset containing 1878 number word problems and developed DOL language to solve them. [9] developed ARIS that solved addition-subtraction type word problems. [19] proposed a system to automatically create executable computer program (in JAVA) from a subset of same addition-subtraction word problems of [9] which generates the final answer when executed. [21] categorized addition-subtraction word problems into separate problem categories and proposed mathematical formulas with respect to the categories to fit them in to solve. [16, 17] developed meaning-based (referred as ‘Tag’) word problem solver with a pipeline of sub-processes.
[10] prepared a huge dataset consisting of problems (Dolphin18k 1 –18,711 problems) with a large number of algebraic operations in addition to the basic operations. It requires knowledge about algebraic and mathematical concepts related to number word problems, scale, ratio, percentage, exponential, unit conversion, etc., to solve them. This dataset contains word problems to output answers generated from multiple equations. Our objective in this work is to solve standard datasets of different types (single equation) and our proposed system presently cannot solve such a robust and complex dataset; it can solve a subset of similar problems from that dataset. [10, 38] proposed an RNN-based LSTM network to map word problem text to math equation templates with the capabilities of mapping the relevant numbers. The main drawback of the method is that it demands a huge training sample that may not be available in many cases (such as the dataset used in our case). Very recently, [12] used sequence-to-equation mapping based on RNN and attention regularization technique to represent the intermediate meaning of a word problem specifically involving multiple equations to solve. They used 10,664 math word problems, a subset of the Dolphin18k dataset, paired with equation templates. [34] proposed a BiLSTM architecture to translate (i.e., map) a math word problem to an equation (expression) tree. Their objective was not exactly to solve math word problems, rather normalize duplicated equation templates to the desired expression tree in order to improve the performance of the system such as [39]. Recent progress in computation hardware and machine learning techniques enables natural language understanding easier. [11, 36] proposed deep reinforcement-based learning methods in solving math word problems. [11] proposed a mechanism related to copying numbers and aligning them to an equation using seq2seq RNN based model and their system was able to address some shortcomings found in the RNN based model [10, 38] for solving word problems. [36] used a reward-based operation classifier and a re-ordering mechanism to align numbers in the desired order in the final equation. They used the same AddSub and SingleOp datasets as ours along with a multiple arithmetic dataset, CC [27], and two variants based on these datasets.
Although BiLSTM has been used successfully in many NLP tasks including word problem solving, to the best of our knowledge, no other work has yet used BiLSTM to predict operations in solving math word problems. Some very recent works made use of LSTM [10, 38] and BiLSTM [34] to map an input word problem to an equation system, but not exactly to predict operation. Comparisons of DLAWPS with some of the most relevant systems are given in the Section 4.3 with critical discussions in Section 4.4.
System description
The proposed method for solving arithmetic word problems consists of three modules. First, an input word problem is passed through a BiLSTM to predict the desired operation. In parallel, irrelevant quantities (if any) are removed using a knowledge-based system. Finally, the answer is generated by forming an equation from the identified relevant quantities (cf. Equation 1). The procedure is presented in Fig. 1 where our contributions are marked with the circles. The following subsections describe the system components in detail.
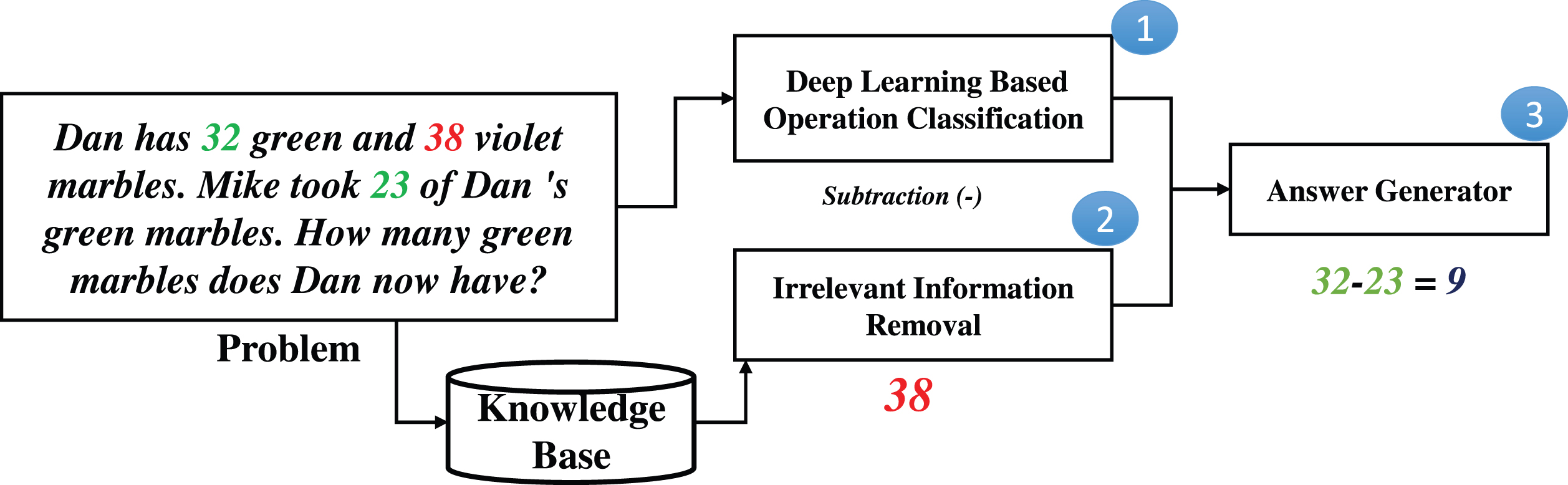
The complete pipeline of the proposed arithmetic word problem solver, Deep Learning-based Arithmetic Word Problem Solver aka DLAWPS. The major components are marked with circles.
We adapted and modified the concept of an object-oriented modeling approach of arithmetic word problems from the work of [19] which reported entity role labeling for math word problems based on Semantic Role Labelling (SRL) and FrameNet. Our work requires the extraction of the desired pieces of information to identify global cue (G). The global cue G –{‘owner’, ‘item’, ‘attribute’, ‘location’, ‘verb’} are extracted using a rule-based approach similar to [20].
Various case studies are given in Table 2 based on word problem examples to demonstrate preprocessing, IE tasks related to different system components such as G, Q, μ, κ, etc.
Case studies of categorically different word problems from the datasets
Case studies of categorically different word problems from the datasets
The BiLSTM architecture [7] consists of a set of recurrently connected network modules, known as memory blocks or LSTM cells. In this work, we used bi-directional memory blocks to classify the four basic operations. Unlike the state-of-the-art equation template-based method [15, 42], we propose a template-free framework for the operation classification task.
Firstly, the word problem is converted into a vector using pre-trained word vectors. We considered an input dimension of 1000. Widely used Glove word embedding [25] is used to generate the sequence of input from the word problem (M). Given an input sequence x = x1 . . . x T , a standard BiLSTM classifier computes the hidden vector sequence h = h1 . . . h T and the output class y. The model is defined using the following equations.
We used T + 100 layer model is used for the classification task following the state-of-the-art BiLSTM reported in [7]. Finally, we added a 4 class classifier as a softmax layer is added to classify the operation.
We also explored two other deep learning frameworks, Convolutional Neural Network (CNN) [37] and Hierarchical Attention Network (HAN) [40], for solving arithmetic word problems and to compare them with our proposed BiLSTM based method. We used a 3 layered convolutional architecture consisting of 128 filters (size 5) and max-pooling of 5 × 5. A HAN consisting of a hierarchically connected time distribution layer and an LSTM layer is also experimented along with the word embedding layer. In each case, Rectified Linear Unit (ReLU) is used as the activation function.
Irrelevant information removal by identifying relevant quantities is one of the important tasks in solving arithmetic MWPs. We developed IIRU, a relevance classifier, and propose a set theory-based approach to find the desired cues from the question sentence and the relevant micro statements (s i ) of a word problem. We categorized word problems as discussed by analyzing various word problem categories proposed by various researchers in the literature [6, 27] and set miscellaneous rules to identify them categorically. Table 2 shows one example from each of the categories. The problems belonging to these categories have some basic differences in characteristics.
Initially, the word problems are categorized as - Change (Cha), Compare (Com), Combine (Cob), and Division-Multiplication (Div-Mul), as in Equation 12. The set of quantities, Q is extracted from M as defined in equation 6.
Next, we describe the generic procedure to identify the relevant quantities (RQ) for all the categories (cf. Table 2 with examples from each category). Firstly, the knowledge base (β) is taken as input. We define the rules to identify the relevant micro statements as in Equations 13 and 14, where at first Equation 13 is tested and if it fails to retrieve at least two such statements, each with a single quantity, the second condition presented in Equation 14 is tested to retrieve two quantities according to a set of precedence. We set precedence as {location, attribute, item, owner} to match (γ ! = ϕ) (cf. Table 2) and find at least two quantities from the word problem following the (γ) in Equation 14. In Equation 13, R and I denote the relevant and irrelevant information (quantities) respectively.
Some category-specific and problem-specific rules are also applied to identify relevant quantities for different categories. E.g., we separately set up rules to identify relevant quantities for ‘money word problems’ (consisting of ‘$’ or dollar in case of our dataset) by grouping the verbs related to monetary transaction sense (using VerbNet) such as ‘pay’, ‘spend’, ‘buy’, ‘purchase’, etc. We select the corresponding micro statements containing these verbs as relevant micro statements. For Div-Mul type problems, owner is not considered as part of G, since it has no importance to identify relevant quantities as observed in the datasets (cf. last example of Table 2). It is to be noted that if a word problem contains only 2 quantities, these quantities are automatically relevant, otherwise, the word problem is incomplete, as noticed in the datasets.
Answer generation is the final task in the pipeline. This task combines the predicted operation and the relevant quantities to form the desired equation (cf. Equation 1) which is further evaluated to generate the answer to the input word problem. Algorithm 3 presents the pipeline of the proposed DLAWPS.
DLAWPS –the Complete Pipeline
DLAWPS –the Complete Pipeline

Datasets
[14] proposed a framework which can check grammatical errors, reduces arithmetic MWP datasets (or extend them) by minimizing template overlaps and lexical overlaps among the word problems. [14] also categorized all such datasets (cf Table 1 of [14]) with characteristically similar word problems to motivate researchers to solve any one or more of such arithmetic MWP datasets. We carried out our experiments on two such datasets available in the MAWPS [14] word problems repository –AddSub (MWP
AddSub
) dataset consisting of a reduced addition-subtraction word problems [9] and SingleOp (MWP
SingleOp
) [27] dataset consisting of single operation word problems. [14]) published a reduced AddSub dataset which is reduced in the sense of numbers of problems, not in the sense of types of problems. They eliminated similar (redundant) problems examples of which are given below. In the original AddSub dataset, we found two such problems. “There are 7 crayons in the drawer. Mary took 3 crayons out of the drawer. How many crayons are there now?” “There are 46 rulers in the drawer. Tim took 25 rulers from the drawer. How many rulers are now in the drawer?”
In the reduced AddSub dataset, only the 1st-word problem from the above list is kept.
These datasets consist of MWPs that require single equation with single operation in order to be solved; this inspired us to formulate the single final equation as in Equation 1. We combined these 2 datasets into a Combined dataset, i.e., MWP Combined = MWP AddSub ∪ MWP SingleOp , with 917 word problems comprising of all four basic operations.
We prepared 4
Experiments and results
All the experiments were evaluated using a 10-fold cross validation framework taking validation size 20%. We used categorical cross entropy loss, RMSprop optimizer, batch size 2, word embedding vector of 100 dimension, and used 40 epochs in each case. Table 3 summarizes the results of our experiments with RNN, CNN and HAN, on each of the 4 variants (DV1, DV2, DV3 and DV4) for each of the 3 datasets (AddSub, SingleOp and Combined). Dataset variant-specific best scores are shown in Table 3 in italics and the dataset-specific best scores are shown in bold. The overall best score is underlined in Table 3. It can be observed from the results that our RNN based BiLSTM method performs better than CNN and HAN on most of the dataset variants. It can also be observed from the results in Table 3 that the DV1 is the most effective dataset for solving word problems for AddSub and SingleOp, while DV2 and DV3 for the Combined dataset produce better accuracies than DV1. The performances on DV4 are mixed, however, DV4 performances are steadier (for proposed BiLSTM) than the other variants. It was expected that on DV4 the system should produce better results, but eventually, that does not happen. Possibly, since the structure of the input problems is changed due to preprocessing, it may lead to some information loss when training the models. Also, preprocessing is not completely accurate for all cases.
Comparative results of the different deep learning methods on different datasets and variants
Comparative results of the different deep learning methods on different datasets and variants
Figure 3 presents the training and validation accuracy and Fig. 4 presents the loss, both on the DV1 variant of the Combined dataset for the BiLSTM model. It is observed that the proposed network does not over-fit with the limited amount of training data. Figure 5 presents the confusion matrix for classifying the four operations (‘+’,‘-’,‘*’, and ‘/’).

Framework of the arithmetic MWP operation classifier consisting of BiLSTM with 4 softmax layer to classify operation (‘+’, ‘-’, ‘*’, and ‘/’).

Training and validation accuracy of the proposed architecture for DV1 of Combined dataset.
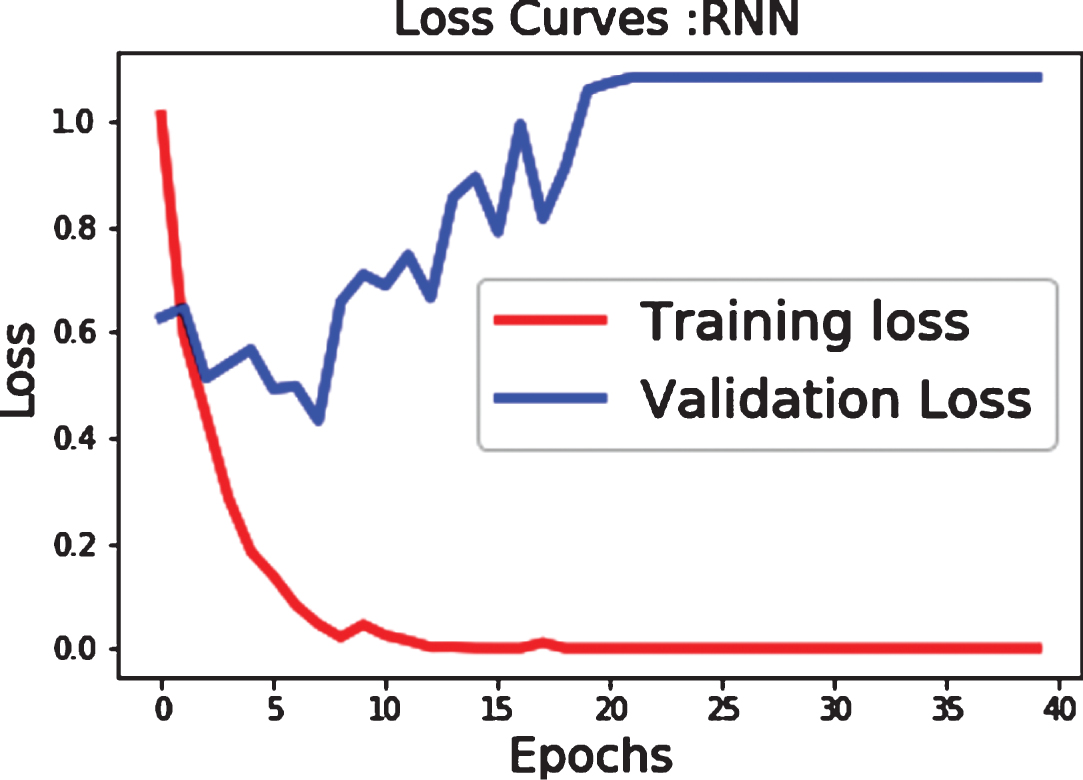
Training and validation loss of the proposed architecture for DV1 of Combined dataset.
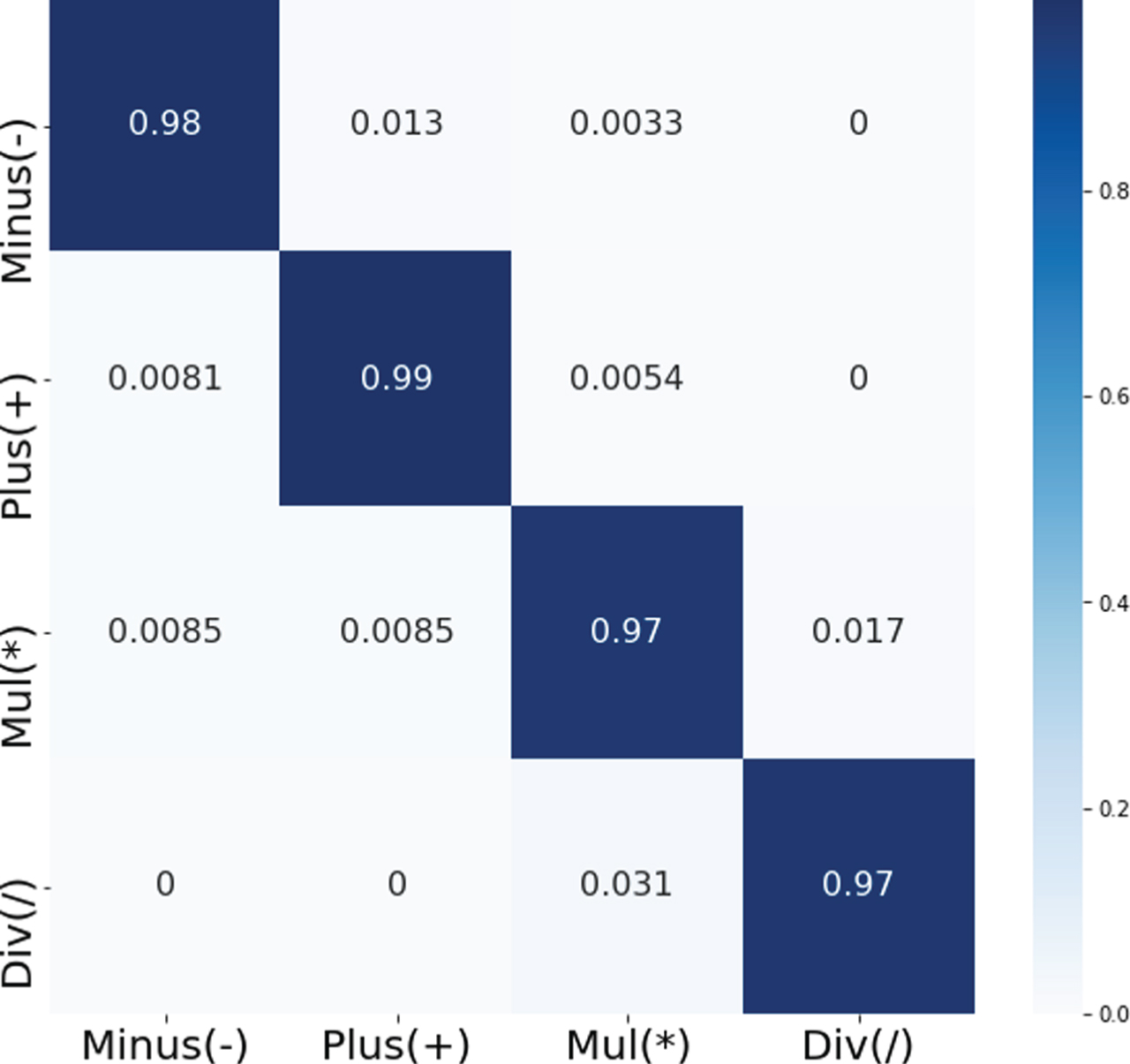
Confusion matrix of the proposed operation classifier for DV1 of the Combined dataset.
It was noticed that 17.34% of the word problems (i.e., 159 out of 917 problems) in the Combined dataset contain irrelevant quantities. It is obvious that, without IIRU, we will not get correct results for any of these 159 problems which will reduce the accuracy to 77.43% from 94.77% for Combined - DV1 (cf. Table 3). This is true for all variants. Therefore, the identification of such quantities is important. Figure 6 presents the confusion matrix for our relevancy classifier, IIRU, where the labels ‘R’ and ‘I’ refer to Equation 13.
Table 4 presents the performance comparison of our system with respect to other similar systems, on the AddSub and SingleOp datasets. Table 4 clearly indicates that our system outperforms the current state-of-the art systems on the same datasets (as available in the literature.) Our BiLSTM based system provides accuracy of 94.08% and 97.15% on the AddSub and SingleOp datasets, respectively, on which the previous state-of-the-art results were 86.07% [21] and 79.5% [17]. It is to be noted that we used a reduced AddSub dataset consisting of 355 problems instead of 395 problems in the AddSub dataset on which the results of other systems are reported. All the results on SingleOp dataset are on 562 problems for all the systems including ours.
Comparison of our system performance with the similar systems on the same dataset(s)
Comparison of our system performance with the similar systems on the same dataset(s)
The existing state-of-the-art systems generally used supervised learning approach to learn various system components such as equation template [15], verb categories [9], equation tree [27, 29], equation formulation [21], etc. [17] used a rule-based approach to identify the desired operation and used Tags (cf. Section 2) to identify the relevant quantities. Therefore, our system is critically different as we used deep learning based approach which helps us get rid of manual feature engineering. [27] used supervised relevance classifier trained on a dataset with very few problems with irrelevant quantities. Rather, we used a more realistic approach to identify the relevant quantities (cf. Section 2). [35] used a reinforcement learning approach to classify the operations and tested their performance on the same datasets.
Our system generates outstanding results and beats other similar systems mainly for two reasons as given below. To the best of our knowledge, this is the first use of BiLSTM in classifying operations in solving word problems from AddSub and SingleOp datasets and the BiLSTM model outperforms other state-of-the-art systems. The proposed IIRU successfully identifies most of the relevant and irrelevant quantities (cf. Fig. 6) from the word problems in the datasets. This leads to such high accuracies.

Confusion matrix of the proposed relevance classifier (IIRU) for DV1 of the Combined dataset.
Our system resulted in 47 errors overall on the Combined actual (i.e., DV1) dataset, out of which 24 errors are in the AddSub dataset and 23 errors are in the SingleOp dataset. The sources of errors are given below.
Conclusion
Our system, DLAWPS, generates state-of-the-art results with RNN based bi-directional LSTM approach in solving arithmetic word problems. The proposed irrelevant information removal unit performs well in identifying and removing irrelevant quantities from the input word problems based on innovative rules using an object-oriented approach. Although presently it is rule-based and problem-specific, however, it can be scaled up with more rules for more problem types. The hand-generated rules can later be used for feature extraction for supervised learning.
As an immediate extension, we would like to explore a deep learning-based relevance classifier. We would also like to try the proposed BiLSTM method on other standard datasets of different characteristics.