
Abstract
It is of great research value and practical significance to use new technology to improve the accuracy of English speech recognition and apply the system to mobile platforms for users to use. The main content of this paper is the long-term and short-term memory, and the current decoding part is applied to the Android platform, and the performance of the program is analyzed. Neural networks converge slowly, making learning long-term memory difficult. In the experiment, the BPTT algorithm is used to analyze the problem of error elimination in traditional recursive networks. Combining BPTT algorithm in LSTM network to solve the problem of traditional error elimination and improve speech recognition rate. In addition, this paper uses a new LSTM recurrent neural network to study the implementation of LSTM network on Android platform. Finally, this paper designs a comparative experiment to analyze the efficiency of oral English recognition. The results show that the research algorithm of this paper has certain effects.
Keywords
Introduction
The study of oral English in colleges is more about coping with exams. But financial speaking is different, it pays more attention to practicality. If students learn relevant knowledge points according to the teaching plan arranged by them, and test to understand their own understanding of the situation, so as to reasonably arrange the study and review plan [1].
Although the current English teaching system can meet the needs of use to a certain extent, there are also many problems, and the most prominent problem is the selection of English test questions. Some platforms use the question bank design pattern, that is, it classifies the questions according to different types and contents and extracts according to certain rules when the test papers are generated [2]. Because students’ learning abilities are different and students have different levels of knowledge, the difficulty and content organization requirements of the questions are different. Therefore, the test paper generated by the fixed mode obviously cannot meet the needs of use, and the test paper generation method based on the test bank cannot be adaptively adjusted for the student’s learning situation due to the lack of relevant strategy guidance [3]. It needs to build a common English learning system and use the record and analysis of student learning data to achieve targeted teaching content arrangement, so that students have higher learning enthusiasm and initiative. It needs to analyze the results of the students’ practice and test, analyze the defects in the knowledge point, and give scientific guidance to promote the improvement of students’ performance [4]. In the process of introducing the project response theory into the selection process of English test questions, the test questions can be organized according to the actual situation of the students, so that students have a more objective evaluation of their own knowledge points.
Aiming at the shortcomings of English speaking learners in financial English learning, this paper proposes an intelligent learning model of financial English speaking based on BPTT algorithm and LSTM network model. Combining BPTT algorithm in LSTM network to solve the problem of traditional error elimination and improve speech recognition rate. This paper designs a comparative experiment to analyze the efficiency of spoken English recognition, and the results show that the research algorithm has a certain effect.
Related work
Hujiang network school teaching platform. The teaching platform is a comprehensive online teaching platform, including English, Japanese, Korean, French, all kinds of small languages, foreign language application language, accounting and other professional English and other professional channels [5]. Multiple sub-categories are included in each channel. The teaching platform is characterized by rich teaching resources, distinct levels, and more registered users. However, the English teaching materials in this platform are all charged, and the price is higher, which is more burdensome for ordinary students. At the same time, because it is aimed at the English teaching services provided by the public, the different characteristics of students are not taken into account in the setting of teaching content.
Tencent classroom. Tencent classroom is a comprehensive network teaching level developed by Tencent Company [6, 14]. The platform system provides users with rich learning resources. Taking English teaching as an example, according to the learning direction, it can be divided into English speaking, English test, English study, business English and so on. Moreover, according to the content of learning, it can be divided into primary entry, English grammar, phonetic vocabulary, oral advanced, travel English, etc. [7, 15]. Most of these resources are free, which is one of the important advantages of Tencent’s classroom. However, the various types of English teaching services provided by the platform are relatively difficult, and most of them are directed at teaching in a certain field, which is not enough for college students.
The intelligent English learning system developed by Siang Education, a subsidiary of Beijing Lingshengxin Voice Technology Co., Ltd., mainly starts with oral English and focuses on cultivating students’ ability to speak English. The English intelligent operating system developed by it has been used in many regions [8, 16]. The platform implements a teaching model that combines teachers, parents and students. It implements the correction and evaluation of the work through the network, establishes a communication platform between the teacher and the parents, and provides the students with an interactive listening and reading operation completion module. This platform effectively improves the training level of English listening and speaking ability of lower grade students, but the shortcoming is that the content is not rich enough, and it is not suitable for the study of English knowledge by upper grade students [9].
Adaptive testing is the main functional module in the English learning system, and it is also an important part of English knowledge mastery. Adaptive testing originated from the intrinsic intelligence test and appeared in the initial stages of the last century. For the testees of different age levels, the adaptive test prepares different test questions separately, and adjusts the selected questions for the next test according to the score of the testee [10]. This is one of the most primitive adaptive test methods, basically controlled by humans, and its branches are fixed, its test entry is variable, and the exit at the end is also variable [11].
Based on the basic flow of the Binet intelligence test, many scholars in the education field began to study the theory of non-adaptive testing. Amant S [12] invented a flexible test method that uses a set of test papers that include multiple questions from extremely easy to extremely difficult. When conducting a test, start with a medium-difficult question and judge whether to select a more difficult or easier problem based on the respondent’s answer. The biggest feature of this test method is to generate test papers according to the ability of the test subject through flexible topic branch selection [13].
Theoretical analysis
Backpropagation Through Time (BPTT) algorithm
The recurrent neural network uses a feedback connection to store data, has a memory function, and has a wide range of applications in the fields of biology, images, and voice. After the speech signal processing, it is represented by a time-ordered observation sequence. When the network is trained, the error signal will propagate backward with time, which will cause the error signal to die. The disappearance of the error signal can be understood as: in the process of backward propagation of the error signal, as the number of propagation layers increases, changing the weight of neurons has little effect on the network output, which leads to a particularly slow network convergence and makes the learning of long-term memory of the network difficult. In this section we use the BPTT algorithm to analyze the problem of traditional recursive network error demise. The BPTT algorithm stores the output error gradient at each time step and expands the network along time to transform the dynamic network into a static network.
The purpose of training the network is to obtain a set of weights so that the mean square error and the minimum, that is, adjust the connection weights W
ij
so that
For the layers before the temporal layer, the output layer and hidden layer neurons are:
Let the learning rate be α, then the modified form of the weights can be expressed as:
The problem of the extinction of the error signal in the traditional recurrent neural network makes the network unable to learn the data with too long-time delay, and the network is lacking in dealing with long-term dependence problems, and it is difficult to train the network model to complete the specific task. In order to make the network long enough to rely on the above input, in 1997, SeppHochreiter and Jurgen Schmidhuber proposed a new type of recurrent neural network structure – Long Short Term Memory (LSTM). The network was later improved by Alex Graves, adding forgetting doors and peepholes to better leverage the features of the LSTM network. The LSTM network not only has the function of the traditional recurrent neural network, but also the LSTM network uses a special control unit to solve the problem of the disappearance of the error signal. The LSTM network is suitable for learning from experience and is suitable for classifying, processing and predicting time series of unknown time delays. This is one of the main reasons why LSTM is superior to other models such as traditional neural networks and hidden Markov.
The LSTM network controls the input information through the self-feedback (CEC unit) of the internal state of the memory unit and the input gate unit and the output gate unit, so that the error signal does not gradually disappear as the number of network layers increases during the backward propagation. Experiments show that the LSTM neural network can learn more than 1000 consecutive discrete time input data, so that it can realize long-term context-dependent memory.
The basic components of the LSTM network are memory blocks that connect the input gate, output gate, and forgetting gate. There are also feedback connections between the memory blocks, as shown in Fig. 1. As can be seen from the figure, the LSTM network is similar to the traditional recurrent neural network except that the hidden layer nonlinear unit of the LSTM network is implemented by the memory block unit.

The left side shows the traditional RNN structure, and the right side shows the LSTM network structure with memory blocks.
In the memory block shown in Fig. 1, it includes one or more self-connected memory cells (referred to as CEC) and three gate cells connected thereto, which are an input gate, an output gate, and a forgotten gate, respectively. These gate units control the flow of memory unit information such as read, write, reset, and the like. Figure 2 provides a detailed structure of a memory block with memory cells:
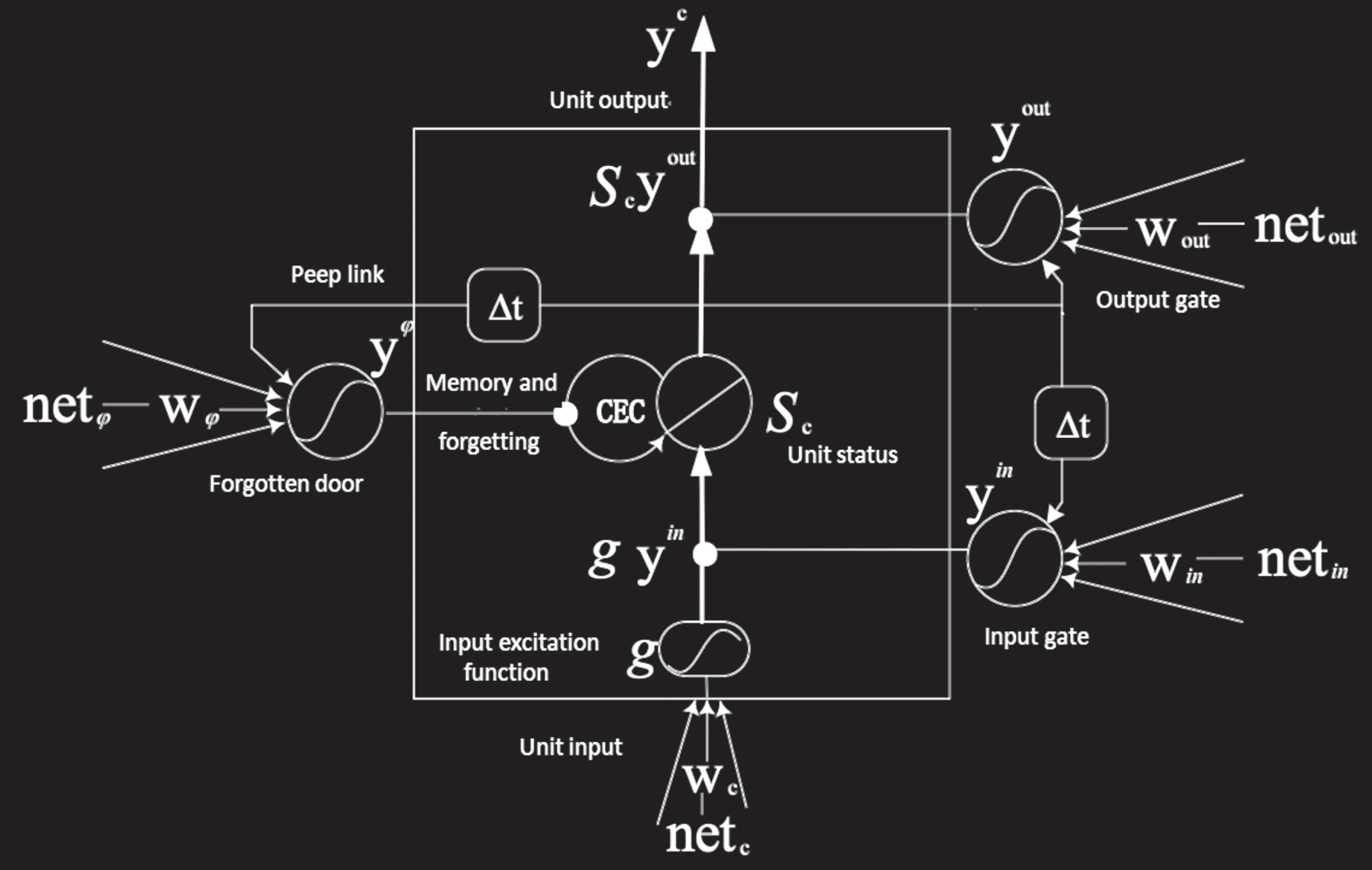
Internal structure of the memory block.
The function of each unit and the flow direction of the information data are explained in detail in the figure. Then, we will describe the picture from bottom to top according to the direction of information flow. First, the input data net c of the network enters the network, and w c represents the weight, and the input data is processed by the weighting and processed by the excitation function g to obtain an input result. On the right is the input net in of the input gate, and it is also the weighted summation and uses the excitation function to get the output y in of the input gate. The output results of y in and net c are multiplied. The black dots in the figure indicate multiplication, and the result of multiplication is used as the input of CEC. The CEC has a self-looping connection so it can maintain a constant effect on the signal data. There is a forgotten door on the left, and net ψ stands for the input of the forgotten. The result obtained after processing similar to the input gate is multiplied by the input result of the CEC as its new data. The output of the general forgetting gate is 0 or 1. If it is 0, the new data of CEC is 0, the data is reset, and the previous data is forgotten. If the output is 1, the new data of CEC is still the original data, thus maintaining the original data, that is, long-term memory function. In the upper right side of the figure, there is an output gate unit, which is also processed by conventional neurons to obtain an output y out . The result of multiplying y out by the output of CEC is the output y c of this memory block unit.
We noticed that the output of the output gate will directly affect the output of the memory unit. If the output gate is closed and the output is 0, the unit output will be 0, which will lose important information and affect the performance of the network. In order to avoid this problem, we have added a connection from CEC to each door unit, which is the peep connection. The connection between the CEC and each door will have a corresponding weight, so there will be CEC participation in the input data of the input gate, output gate and forgetting gate. Through continuous training on the network, the door unit enables the CEC unit to automatically avoid unwanted inputs or error signals, which is something that traditional recurrent neural networks cannot achieve.
In general, in each memory unit, the input gate controls the input of information and output gate controls the output of information, and the forgetting gate can reset the information inside the memory unit. The control of these three gate units enables the LSTM memory unit to store and access information over a relatively long period of time and achieve long-term dependency on the context. For example, the input gate output value is 0 as long as the input gate remains closed. At this time, the value of the memory unit will not be rewritten when the new input arrives at the network, and the memory unit can maintain the original information, thus keeping the error signal of the network unchanged.
When the recurrent neural network performs network training, it can only rely on the data before the t time and cannot apply the data after the t time. If the recursive network can process with future data, the recognition rate will increase, which requires that the future data is entered into the network. In speech recognition, the speech to be recognized is delivered to the network in a sentence. Then, we can use the above ideas to use future speech data to predict current behavior. According to this idea, a bidirectional recurrent neural network (BRNNs) is generated, and the structure is shown in Fig. 3:

Structure diagram of BRNNs.
It uses two different hidden layers to process data in both forward and backward directions. The hidden sequence of forward calculation is
The learning process of the LSTM network can be divided into two parts: the forward transmission process of data and the backward propagation process of error signals.
Forward calculation of LSTM networks
In the simplest way, this requires a two-stage learning process, and the first phase of the calculation is divided into three steps.: Input gate calculation y
in
Forgetting door calculation y
φ
Memory unit input and unit status s
c
Output gate calculation y out and memory unit output y c .
Since the connection of the peephole affects the value s c of the memory cell and the value y φ of the forgetting gate, the calculation of the output gate is after the calculation of the memory cell. In the following calculation process, we agree that in, φ, out denotes the input gate, the forgetting gate and the output gate, respectively. denotes any memory unit, s c denotes the state of the memory cell, f denotes an excitation function of each gate, and g and h denote excitation functions of the input and output of the memory cell, respectively. The output value of the first stage is calculated first. It can be seen from Fig. 2 that at time t, the output of the input gate y in j (t) and the output of the forgetting gate y φ j (t) can be expressed by the following formula:
In the formula, net
in
j
(t) represents the input of memory block j at time t, and w
in
j
m
represents the weight of the connection of two units. f
in
j
represents the input function of the input gate, it is a Sigmoid function, the range is [0, 1], and the specific expression is:
Memory unit input and state calculation: When t = 0, the state s
c
(t) of the memory unit is initialized to 0. When t > 0, s
c
is calculated by the product of s
c
(t - 1) and the forgetting gate output and the previous network state, and the specific formula is as follows:
In the formula (14) represents the excitation function of the network input, it is also a sigmoid function, and the range is [- 2, 2]. The specific formula is as follows:
The calculation formula for the output gate is as follows:
The output y
c
of the memory unit is related to the output of the output gate and the state of the memory unit. As shown in Fig. 2, the specific calculation formula can be seen as follows:
In the formula, [- 1, 1] is a Sigmoid function with a range of m. The specific formula is as follows:
Finally, considering that the LSTM topology network consists of a standard input layer, a hidden layer of memory cells, and a standard output layer, the output equation of unit k is as follows:
The backward calculation of the LSTM network uses the idea of the steepest descent, and the algorithm used is a mixture of the BPTT algorithm and the RTRL algorithm. We use the general mean square error function and assume that the objective function is t
k
. Then, the error function
Therefore, we obtain Δw lm = aδ k (t) y m (t - 1),
where
Among them,
For an output unit, the expression for the change value of standard backpropagation is
The internal state error is:
Finally, the weight formula is updated to:
In order to produce a fast and smooth sound, the human pronunciation system will blur the boundaries of the pronunciation before and after. In some cases, if we do not know the context information, it is difficult to correctly identify the pronunciation phoneme. The degree to which the network model relies on context information has an important influence on the recognition rate of speech, especially in the case of coordinated pronunciation. Frame-level classification tests the ability of the network to segment and recognize speech. Therefore, we use frame-level classification experiments to test the LSTM network’s ability to rely on context.
In order to facilitate comparison, we use different network structures. In order to ensure the fairness of comparison, the number of nodes in the hidden layer is selected as follows, so that the weights used by all networks are basically the same. There are five network topologies used in this article: BLSTM network: It contains two LSTM hidden layers, and each hidden layer consists of 93 memory blocks. LSTM network: It contains a hidden layer and contains 140 memory blocks. There is no time dependency on backward training, and forward training can have a dependency of 0-10 frames. It has two hidden layers and includes 185 neuron nodes and uses the Sigmoid excitation function. RNN network: It contains a hidden layer and contains 275 neural processing units, and uses the Sigmoid excitation function, and can have a context dependency of 0–10 frames during training. MLP network: It contains a hidden layer and includes 250 neuron nodes using Sigmoid excitation functions, and the time window is uniformly moved from 1–10 frames.
The TIMIT speech library is used in the experiment, and TIMIT is a recognized training test data set in the field of speech recognition. In the experiment, the Hamming window was used for framing, and the MFCC technique was used to extract the 26-dimensional feature vector. The input layer of the network has 26 nodes, the output layer has 61 nodes, the input layer is connected by a full connection and the hidden layer, and the hidden layer is also fully connected to the output layer. For feedback networks, hidden layer nodes also need to take a self-loop connection.
Network training is performed using a gradient-based approach by using the BPTT algorithm. The excitation function at the input layer of the LSTM network uses the Logistic function, the range is [- 2, 2], and the nodes of the non-LSTM layer use the excitation function of the range [01]. A mean square error function and a softmax excitation function are used at the output layer. The softmax excitation function ensures that the output of the network is between 0 and 1, and the sum of the output values of each time step is 1. The output value can be considered as the probability of the phoneme corresponding to a given frame.
In the experiment, each network uses a similar parameter, the weight is initialized to a floating point number of [- 0.1, 0.1], the learning rate is set to 10-5, and the update of the weight is performed after each sequence training is completed. The error rate of the training set, the error rate of the test set, and the number of iterations obtained after the final training is completed are shown in Table 1.
Error rate of frame classification
Error rate of frame classification
The table summarizes the performance of different network structures. As can be seen from the table, the performance of the two-way network structure is better than that of the one-way network, and for the two-way network, the LSTM is better than the RNN in terms of long-term target delay. The number of iterations during LSTM network training is significantly less, and the LSTM network has the same forward and backward results in time-independent training, which indicates that bidirectional context dependencies are important.
With the development of mobile communication technology, intelligent terminals now occupy more and more market share. Now, mobile communication has entered the 4 G era, and 4 G smartphones have become the mainstream of the entire mobile phone market. The architecture of the intelligent terminal is shown in Fig. 4. It has an open operating system, and the entire system is generally divided into four layers from top to bottom: application layer, user interface layer, software platform layer and hardware driver layer.
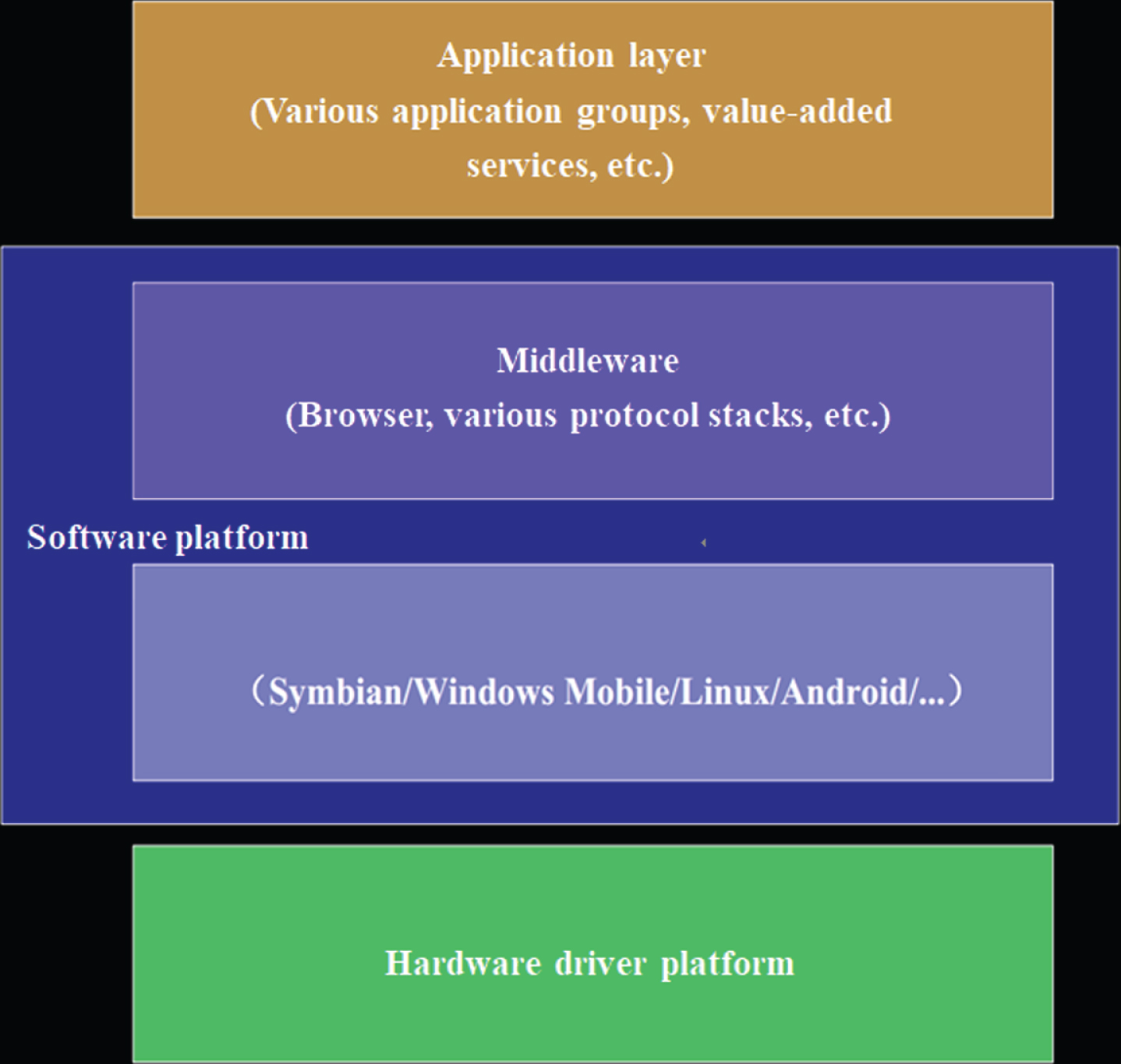
Layered structure of the terminal.
In the study of terminal equipment selection, by using the statistics of smart terminal usage in recent years, it was found that the use of smartphones accounted for the highest proportion. Therefore, we conduct statistics on the mobile phone system, and the statistical results are shown in Fig. 5.

Market share distribution of intelligent systems.
When introducing the Windows Phone development environment, I have to mention the simulator. As a mobile application developer, whether it is debugging the code or detecting the user experience, it is inseparable from the simulator. The Windows Phone 7 emulator provides the same user experience as a real machine, and it also provides touch functionality, and its performance is comparable to that of a real machine. Therefore, we can use the simulator to test games and applications. Figure 6 shows the rendering of the Windows Phone simulator.

Windows Phone Simulator.
As we can see from Fig. 7, the bottom layer is the.NET Compact Framework, which is a core component. The third layer is some general-purpose services such as sensor APIs, location APIs, Windows Live services, web services, multimedia and more. The second layer is something that is unique to Silverlight or XNA. The top layer is an application written based on these two different architectures.

Windows Phone system architecture.
As can be seen from Fig. 8, the application framework layer provides a view framework, content provider, resource manager, notification manager, activity manager, window manager, and package manager. Application developers of ANDROID can directly use these frameworks already provided by the operating system.

System architecture diagram.
The performance bottleneck of the online word search module may appear: A. The speed of the real-time prompt when inputting some words in the input box; B. When the user presses the “OK” button, the time problem of reading the corresponding word information is read. For the performance test of the online word search module, the following test steps are used:
The first step: We use a smart terminal with Android operating system to install this software, enter the words beginning with different letters, record the time when the software displays the prompt information when entering a letter. When the entire word is recorded, we record the time the software displays the word information.
Step 2: The steps of the first step are repeated 10 times. In this process, 10 different words are selected. The test cases used here are license, deposit, produce, reserve, interest, tax, quit, zone, yard, currency.
Figure 9 shows a delay comparison of the software displaying the prompt information for the 10 words when the i-th letter is entered. In the figure, the ordinate represents time, its unit is seconds, and the abscissa represents the order in which words are entered.

Comparison of information delays.
Figure 10 shows the comparison of delay time when the software displays different words.

Comparison of delay time when the software displays different words.
Through the above comparison test, it can be seen that the research system has a certain English oral recognition effect, which can be applied to the intelligent terminal, and has certain support effects for English learning.
Conclusion
This study investigated the oral English learning, analyzed the current situation of oral English learning, and analyzed the background of system development. Moreover, this paper analyzes the current situation of the English oral learning system by comparing the status quo at home and abroad. At the same time, this study defines the requirements of the English oral learning system, analyzes the overall business process of the system, and outlines the system, including overall architecture design, technical architecture design, package structure design and functional architecture design. Then, this study carried out a detailed design analysis of the English oral learning system through system class structure design, system dynamic structure design and database design. Finally, this study elaborates on the implementation and testing of the system and demonstrates the actual development of the system in the form of a combination of screenshots and code in the implementation. In addition, the study used test tables to demonstrate system functional test results and tested non-functional requirements. The research results show that the research system has a certain oral recognition effect and has a certain promotion effect on financial oral English learning.