
Abstract
BP neural network method is provided by the outstanding characteristics of self-learning and non-linearity, and can obtain relatively satisfactory prediction results, which also can be used to forecast innovation output. The neural network toolbox function of Matlab can build a neural network prediction model to predict the innovation output from 2008 to 2017. Second, the dynamic SDM is used to empirically test the role of industrial cluster on the innovation efficiency and its space spillover effect by using of the panel data of Chinese cities. The results show the error comparison between the predicted value and real value of innovation efficiency, which explains the accuracy of BP neural network is higher. There is a spatial distribution pattern in which the innovation efficiency decreases from the east, the middle, and the west, which also has the characteristic of time inertia and positive spatial correlation. The producer service agglomeration has significantly improved the innovation efficiency in this city but has no significant role on the innovation efficiency in neighboring cities. The manufacturing cluster has a significant negative effect on the innovation efficiency in this city in the long and short term but produces a significant positive effect on innovation efficiency in neighboring cities in the long and short term.
Introduction
At present, China urgently needs industrial transformation, and the essence of industrial transformation is to improve the innovation efficiency (IE) of industrial enterprises, mainly driven by innovation and energy conservation and emission reduction. Existing research has been carried out at the provincial level to compare the differences in innovation efficiency between different provinces and the influencing factors behind them [1–3], but the potential important factor of industrial agglomeration has not yet attracted enough attention. The flow of factors and the division of industrial chain between different regions make the investment, production, R&D, and sales links separate and centralize in space, and there will be complex cooperation and competition between companies, which may affect the innovation atmosphere and Innovation performance. Therefore, it is of great research value to investigate the role of industrial agglomeration on the innovation efficiency of industrial enterprises.
Related work
At present, domestic and foreign studies on the relationship between industrial cluster and innovation have achieved certain results. Some studies suggested that industrial agglomeration could promote the information exchange and personnel flow in the agglomeration area through the effects of labor pools, technology diffusion, and personnel mobility, thereby accelerating the spillover and diffusion of technology in the agglomeration area, and the technology spillover will help accelerate the technological innovation of enterprises [4]. Krugman [5] believed that industrial agglomeration could increase technology trade in the agglomeration area, and technology trade could boost technological innovation activities and efficiency in the cluster area. Freeman [6] believed that industrial gatherings could ameliorate the investment environment in the cluster area by use of external effects and increased technological innovation activities in the agglomeration area. In terms of empirical research, Storper et al. [7] believed that industrial agglomeration could produce knowledge spillover effect, which was the fundamental driving force for the development of cluster innovation. Andersson et al. [8] used Swedish patent data to verify that industrial agglomeration could significantly promote innovation. Xie et al. [9] believed that the appropriate concentration of industries could improve the efficiency of technological innovation in enterprises through various mechanisms such as learning effects, knowledge spillover effects, economies of scale, competition effects, and cooperation effects. Zhang et al. [10] believed that industrial agglomeration affected the efficiency of technological innovation in industries, and that there were obvious regional differences in the effects.
In summary, this article takes the Chinese 251 cities as the research samples from 2008 to 2017 to explore the following points: (1) Exploring the prediction effect of neural network on innovation output and its role on innovation efficiency. (2) Exploring the relation between industrial cluster and innovation efficiency based on two perspectives of productive services and manufacturing. With the gradual transformation of China’s industry from manufacturing to producer service, the producer service industry has been separated from the traditional industry and developed rapidly, which has formed spatial agglomeration due to the characteristics of high industrial relevance and strong cross-border service. (3) Investigating whether the impact of cluster of producer services and manufacturing on the innovation efficiency of industrial enterprises can spill over to neighboring areas, that is, whether there is a significant space spillover effect. (4) Selecting urban data that better reflects the true level of industrial agglomeration and innovation efficiency as the research samples, rather than provincial data with large spatial scales and internal differences.
Empirical research model
Sample data and variable selection
After deleting cities with severe data missing, this paper selects the input and output data of 251 cities in China. The time span is from 2008 to 2017. The data mainly comes from China City Statistical Yearbook. The specific descriptions of the variables and their calculations are as follows: Innovation efficiency. This article uses the DEA-BCC model to calculate the innovation efficiency of industrial companies, and selects the proportion of technical service employees, R&D funding stock, new product development funding stock and industrial electricity as input indicators, and uses the number of invention patent applications as output indicators. Industrial agglomeration level. This article uses location entropy index to calculate the levels of producer service agglomeration (SA) and manufacturing agglomeration (MA). This article selects the proportion of the number of employees in the producer service industry or manufacturing industry in each city to the number of employees in the region / the ratio of the number of employees in producer services or manufacturing industry to the number of employees in the country:
Where E
ij
is the employees number of j industry in i city, E
i
is the number of employees in all industries in i city, E
j
s the number of employees in j industry in all cities, E is the total number of employees. Control variables. 1) Industrial Structure (IND), which is expressed by the increase of the tertiary industry as a percentage of GDP. 2) Innovation environment (INV), which is expressed by the proportion of the number of industrial companies conducting R&D activities to the total number of industrial enterprises. 3) Foreign direct investment (FDI), which is expressed by the actual use of foreign investment as a percentage of GDP. 4) Human capital level (HC), which is expressed by the number of college graduates and above per 100000 population.
DEA method uses the input and output variables of decision unit (DMU), and uses mathematical planning methods to measure the leading edge of the effective DMU, and then analyzes the degree of deviation of each DMU from the leading edge of the production to estimate the relative efficiency of each DMU [11, 12]. CCR model assumes that the scale benefits of production technology remain unchanged. However, in the actual production process, many production units do not reach the optimal scale, so the technical efficiency measured by CCR model includes scale efficiency. In 1984, Banker et al [13] proposed a DEA model for estimating scale efficiency, also known as the BCC model. Supposing there are n DMUs, each of which has m types of inputs and s types of outputs. For a specific DMU, the input-oriented CCR model is:
The production set corresponding to the above model is:
The input-oriented BCC model is as follows:
The basic BP algorithm includes 2 aspects: the forward propagation of the signal and the backward propagation of the error. The actual output is estimated in the direction from input to output, and the correction of weights and thresholds is performed in the direction from output to input in Fig. 1.
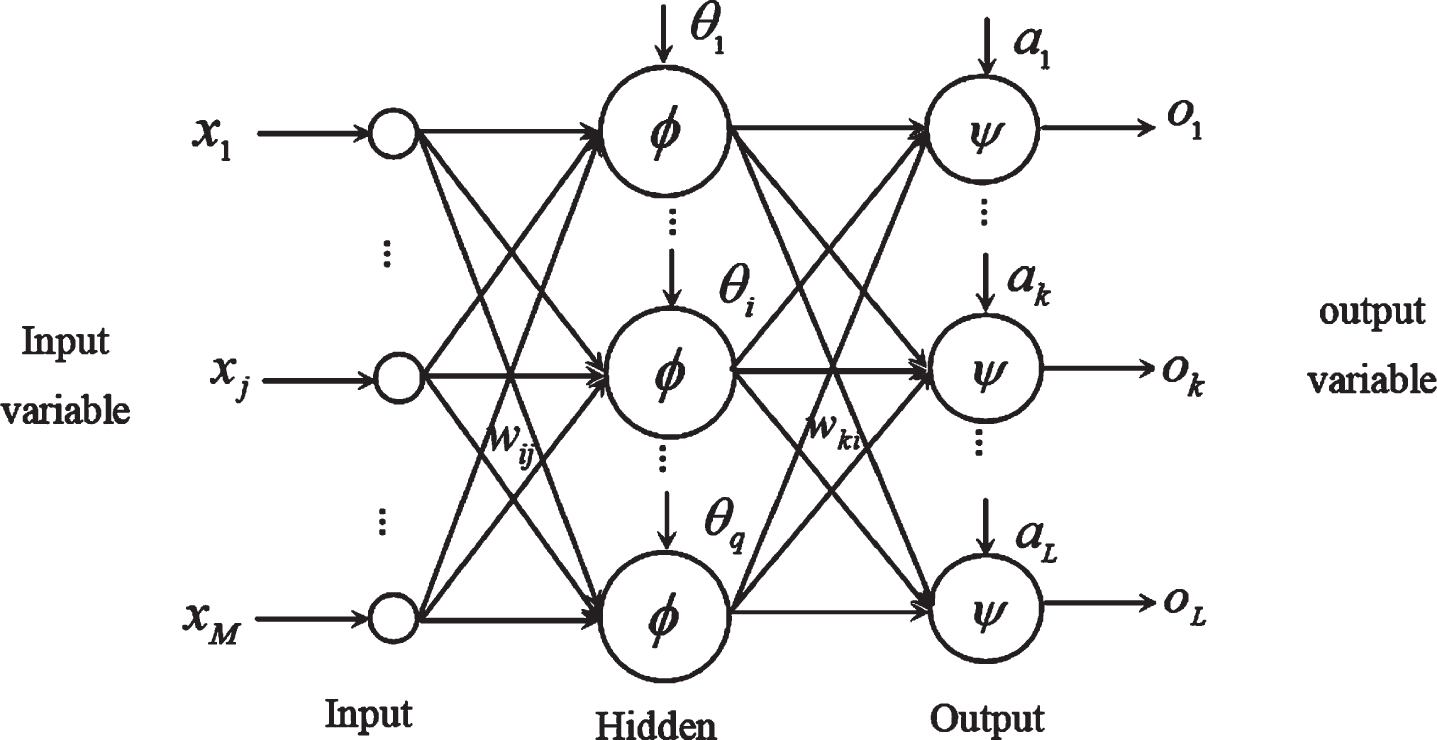
Structure of BP network.
Where x j represents the input of j node of input layer, j = 1, 2, . . . , M. w ij represents the weight between the i-th node in the hidden layer and the j-th node in the input layer. θ i represents the threshold of the i-th node of the hidden layer. ϕ (x) represents the excitation function of the hidden layer. w ki represents the weight between the first node in the output layer and the i-th node in the hidden layer, i = 1, 2, . . . , q. α k represents the threshold of the k-th node of the output layer, k = 1, 2, . . . , L. Ψ (x) represents the excitation function of the output layer. o k represents the output of first node of output layer.
(1) Forward propagation of the signal
Input net
i
of the i-th node of the hidden layer:
The output y
i
of the i-th node of the hidden layer:
The input net
i
of the k-th node of the output layer:
The output ok of the k-th node of the output layer:
(2) Back propagation process of errors
Back propagation of errors starts from the output layer to calculate the output error of each layer of neurons layer by layer, and then adjusts the weights and thresholds of each layer according to the error gradient descent method, so that the final output of the modified network can approach the expected value.
The quadratic error criterion function for each sample p is E
p
:
Based on error gradient descent method, the correction amount Δw
ki
of the output layer weight, the correction amount Δα
k
of the output layer threshold, the correction amount Δw
ij
of the hidden layer weight, and the correction amount Δθ
i
of the hidden layer threshold are sequentially revised.
Output layer weight adjustment formula:
Output layer threshold adjustment formula:
Hidden layer weight adjustment formula:
Hidden layer threshold adjustment formula:
Also due to:
So in the end we get the following formula:
According to the classification process, it can be divided into three methods: K-means clustering, system clustering, and two-step clustering. The basic idea of systematic cluster analysis is: samples (or variables) that are close to each other are clustered into a class first, and clusters that are far away are clustered into a class. The process continues, and each sample (or variable) can always be clustered into the appropriate class. Before systematic clustering, the distance between classes must be defined. The difference in the definition of distance between classes leads to different systematic clustering methods. Their classification steps are basically the same, but the main difference is the calculation method of the distance between classes.
This paper uses d
ij
to represent the distance of sample X
i
and X
j
, and uses D
ij
to represent Z
i
and Z
j
. This paper uses the center of gravity method to define the distance between classes. Supposing Z
p
and Z
q
haven
p
and n
q
respectively, and there centers of gravity are
Supposing Z
p
and Z
q
are combined into Z
r
, then the sample number of Z
r
is n
r
= n
p
+ n
q
, and the center of gravity is
In fact, the distance between the class and the new class represented by formula (26) is:
Put
The Moran’s I index was first presented by Moran in 1948 [14], and its expression is as follows:
Where
(1) Geographic distance weight matrix (W
g
). The geographic distance weight matrix is found by using of the inverse of the spherical distance based on the geographic unit, which is specifically expressed as:
Where d ij is the distance between the 2 cities measured by the latitude and longitude data.
(2) Economic distance weight matrix (W
e
). Considering that the correlation effects of the mutual influences caused by the differences in economic development between different cities are not the same, this article uses the actual per capita GDP as a measure of the urban economic development level, and constructs a matrix of economic distance weights as follows:
Where
Space econometric models mainly include space lag model (SAR) and space error model (SEM) [15]. Lesage et al. [16] proposed a more extensive spatial econometric model than SAR and SEM, taking into account exogenous and endogenous variables of spatial lag, which is the spatial Durbin model (SDM), and the expression is:
Where ρ is the space autoregressive coefficient, β and θ respectively represent the coefficient of the exogenous variable and its space lag term. μ
i
and v
t
represent regional and time effects, respectively. ɛ
it
is random perturbations. The dynamic spatial Durbin model expression is as follows:
Regarding the estimation of the dynamic SDM model, Yu et al. [17] constructed the corrective estimator of dynamic SLM after analyzing the asymptotic properties of their maximum likelihood estimators. The estimation methods of dynamic spatial Durbin model and dynamic SAR model are basically similar. Elhorst [18] believed that the maximum likelihood estimation method with bias correction for estimation had a good small sample property and could solve the bias problem of the ordinary maximum likelihood method.
Analysis of innovation efficiency
The average value of innovation efficiency from 2008 to 2017 is shown in Table 1. It can be seen that China’s innovation efficiency is on the rise as a whole, with an average annual growth rate of 1.89%, reaching 0.8199 in 2017. The main factors affecting innovation output are the proportion of technical service employees, R&D funding stock, new product development funding stock and industrial electricity as input indicators. Therefore, this paper uses these input indicators to predict the innovation output based on BP neural network. It is easy to discover from Table 1 that the predicted innovation output is brought into the DEA model and new innovation efficiency is obtained. Judging from the prediction results, except for individual years, the prediction error using the BP network is relatively small. Therefore, the prediction effect using the BP neural network is satisfactory. In addition, this article used SPSS22.0 software to perform a systematic clustering analysis on the innovation efficiency of 251 cities in mainland China over the years. All data are divided into innovation efficiency high efficiency area, medium efficiency area, and low efficiency area (limited to space, clustering results are omitted). It can be discovered that, in general, the cities in the area of high innovation efficiency are mainly located in the eastern coastal areas, the cities in the area of medium innovation efficiency are mainly in the central and western regions, and the cities in the area of innovation efficiency are mainly in the western area. This shows that China’s regional innovation efficiency presents certain regional characteristics.
Average value of China’s innovation efficiency from 2008 to 2017
Average value of China’s innovation efficiency from 2008 to 2017
Moran’s I index was used to test the space autocorrelation of innovation efficiency (limited in length, the calculation results are omitted). The test results indicate the Moran’s I index passes the significance level test of 1% or 5% from 2008 to 2017, which indicates that the IE of industrial enterprises is not completely random and there is a certain positive spatial correlation. Therefore, it is obliged to carry out a quantitative analysis of the influencing factors of innovation efficiency of industrial enterprises from the spatial dimension. In addition, compared with the geographic distance weight matrix, the Moran statistics under the economic distance weight matrix are generally higher, which means the economic distance characteristics have a greater impact on the spatial correlation of urban innovation efficiency. This further illustrates that cities with similar economic characteristics are more likely to have a spatial interaction effect on innovation efficiency.
Estimate results and analysis
First, the LM statistic test and Robust LM statistic test are performed on the non-spatial interaction model in four forms. The calculation results are shown in Tables 2-3. it can be discovered that the LR test rejected the null hypothesis at 1% level, indicating the model should include both space and time fixed effects. Consequently, the LM test results must be estimated on the basis of the space and time dual fixed effect model. The LM statistics tests in Tables 2-3 both reject the null hypothesis at a significance level of 1%, indicating that SAR and SEM should be established at the same time, also indicating that the SDM needs to be further estimated. In all the tables below, ***, **, * indicate that they passed the significance test at the levels of 1%, 5%, 10% respectively.
Test results of spatial effects under static conditions (geographic distance weight)
Test results of spatial effects under static conditions (geographic distance weight)
Test results of spatial effects under static conditions (economic distance weight)
On account of the above analysis, this article conducted a Ward test and an LR test on the conversion of the static spatial Durbin model into SAR and SEM models. The test results show that the static SDM cannot be degraded into SAR and SEM models. This means that it is more effective to select a more generalized form of SDM model for empirical analysis than SAR and SEM models. In the end, the Hausman test is used to test whether the model chooses a fixed effect or a random effect. The results show that the fixed effect of the dynamic SDM passes the significance test at 1% level. Therefore, this paper chooses the dynamic SDM with fixed effects of space and time. The estimation results are shown in Tables 4-5. In addition, it is found that the coefficient estimates under the economic distance weight are significantly different from the coefficient estimates under the geographic weight matrix.
Estimation results of static and dynamic spatial Durbin models (geographic distance weights)
Estimation results of static and dynamic spatial Durbin models (economic distance weights)
In order to further explain whether the dynamic SDM will increase the interpretation of the model, this paper uses LR test to analyze the joint significance of IEt - 1 and W * IEt - 1. The results show that the LR statistics under both weight matrices pass the 1% level of significance test. It should be pointed out that, whether it is a static SDM or a dynamic SDM, the estimated Log-L value and R2 value under economic distance weight are better than that under the geographical distance weight. Therefore, the following analysis focuses on the double-fixed-effect dynamic space Durbin model under the economic distance weight matrix.
The direct and indirect effects are further decomposed into short-term effects and long-term effects in the time dimension to reflect the short-term immediate impact of industrial cluster on innovation efficiency and the long-term impact of considering time lag. The results are shown in Tables 6-7. Figs. 2–5 show the estimated coefficients of the short-term direct effects, short-term indirect effects, long-term direct effects, and long-term indirect effects under two weights. After comparison, it is found that no matter what kind of effect, the coefficient estimates under the economic distance weight are significant differences in the estimated coefficients under the geographic distance weighting.
Effect decomposition of each variable on innovation efficiency (geographic distance weighting)
Effect decomposition of each variable on innovation efficiency (geographic distance weighting)
Effect decomposition of each variable on innovation efficiency (economic distance weighting)

Coefficient estimation of short-term direct effects.
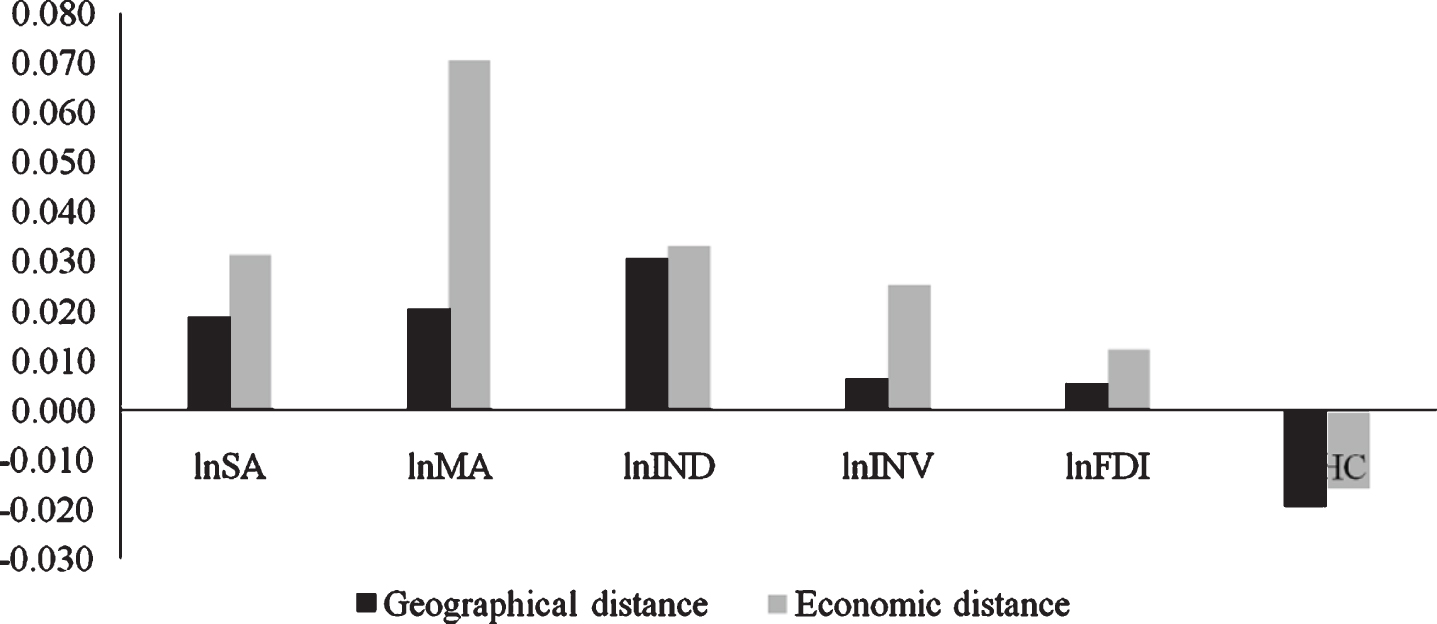
Coefficient estimation of short-term indirect effects.
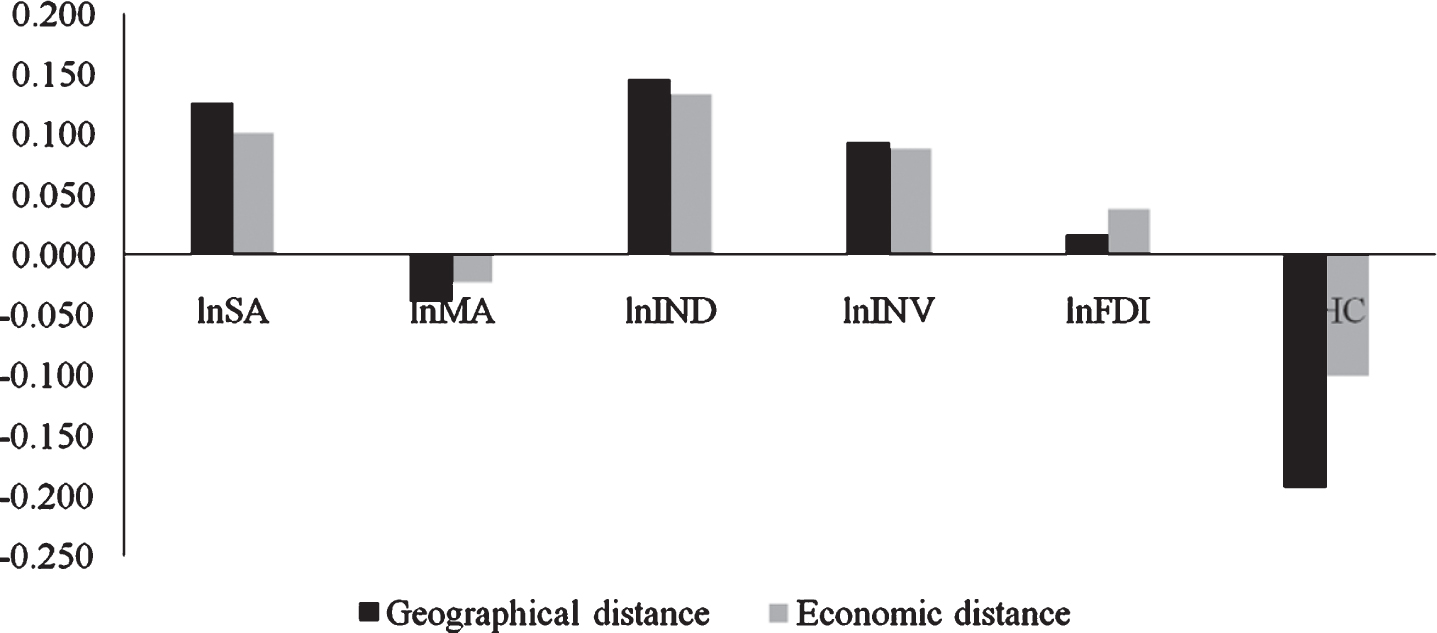
Coefficient estimation of long-term direct effects.
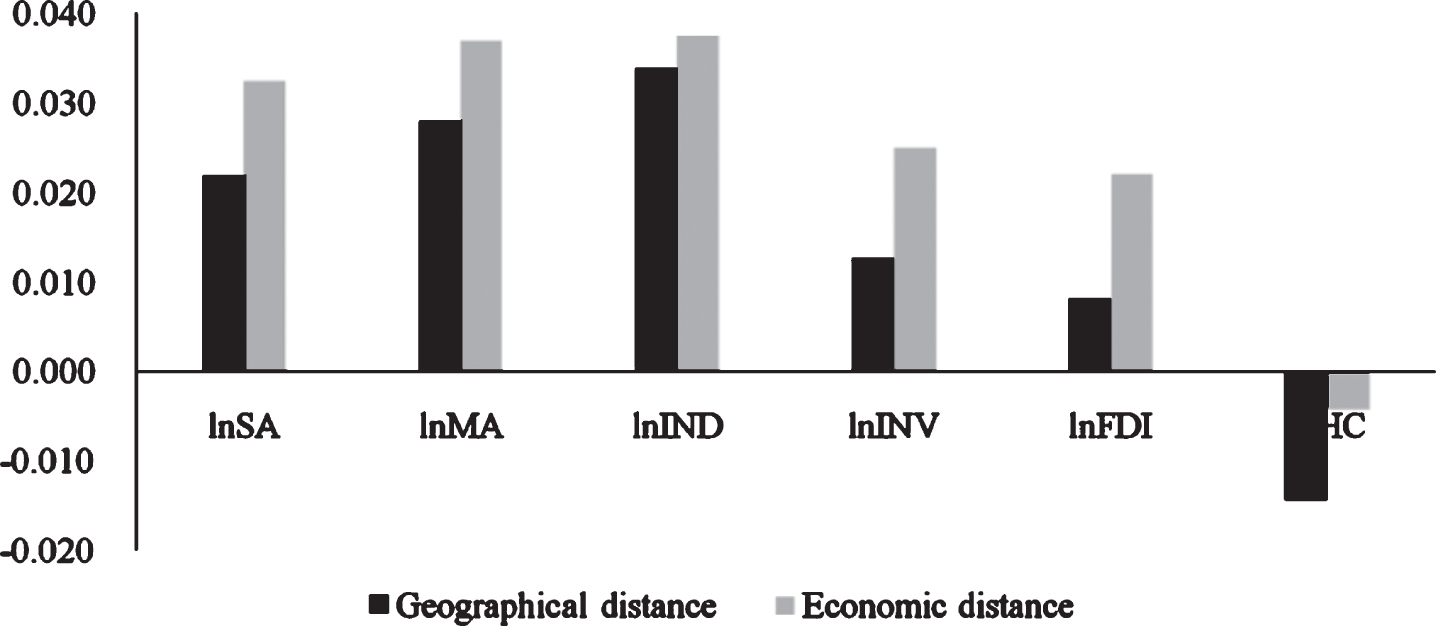
Coefficient estimation of long-term indirect effects.
According to Tables 6-7, it can be found that, whether in the long or short term, the direct effect of agglomeration of productive service industries is positive, passing the test of 1% level. However, the indirect effect of the of producer service cluster is positive but not significant, which indicates an increase in the level of producer service cluster can significantly improve the innovation efficiency in this city, but it has no significant role in promoting the improvement of innovation efficiency in neighboring cities. The producer service agglomeration can speed up the construction of industrial enterprise innovation platforms, provide technical personnel from different regions and enterprises with opportunities for cooperation and exchange, and help to share first-class skills and managerial experiences in innovation. From the estimation results of manufacturing cluster, manufacturing cluster has a significant inhibitory role on the innovation efficiency of industrial enterprises in this city, but it has a positive role in boosting the innovation efficiency of industrial enterprises in neighboring cities. China’s manufacturing industry mainly relies on industrial parks to agglomerate, mostly horizontal or simple vertical agglomeration, which makes imitative innovation more common, leading to the positive effect of positive knowledge spillovers brought by agglomeration on innovation efficiency. The recent suppression effect surpassed, hindering the promotion of innovation efficiency in the entire agglomeration area. Nevertheless, with the further deepening of the division of labor between the industrial chains of cities, the promotion of innovation efficiency by manufacturing agglomeration is passed on to neighboring cities through the industrial chain, thereby significantly improving the innovation efficiency of neighboring cities.
This paper uses Chinese urban data to empirically test the role of industrial cluster on the innovation efficiency and its spatial spillover effects. The results prove that the effect of prediction using BP neural network is satisfactory. There is a significant regional distribution pattern of innovation efficiency, and there is significant ‘time inertia’ and positive spatial correlation. Whether in the geographic distance weight matrix or economic distance weight matrix, the producer service agglomeration has significantly improved the innovation efficiency in this city, but has no significant role on the innovation efficiency of industrial enterprises in neighboring cities. Manufacturing cluster presents a significant inhibitory role on innovation efficiency in this city, and presents a significant promotion effect on innovation efficiency in neighboring cities. Moreover, the long-term impact is higher than the short-term impact. On the premise of incorporating spatial factors, industrial structure, innovation environment and foreign direct investment are all important factors affecting the innovation efficiency of industrial enterprises.