
Abstract
English speech recognition system is affected by a variety of interference factors. Associating the algorithm with the support of modern computer technology can increase the model effect of speech recognition system. Based on the study of the current mainstream controlled natural language thesaurus, this paper proposes a controlled natural language vocabulary classification type. Moreover, this paper defines the domain thesaurus according to the WordNet knowledge description framework, and uses WordNet’s synonym, antisense, upper and lower, etc. In this way, the controlled natural language system can use the semantic relationship of WordNet to identify the words of the non-domain thesaurus input by the user and map the non-domain definition words to the words in the domain thesaurus, thereby improving the ease of use of controlled natural language systems. In addition, this paper designed a controlled experiment to analyze the performance of this system. The research results show that the model constructed in this paper has certain significant effects.
Introduction
Language is the essential tool of communication in the rapidly developing world, where countries and cultures exchange development in science, education and economy. Chinese society, having been recently achieving steady progress in education and economy, is taking a growing role in the international stage and sees a increasing need to mastering English, the mostly widely used non-native language across the world. Contrasting to the growing needs from students, the supplies of English teachers are limited. We thus turn our attention to computer-assisted learning of English [1]. More specifically, we focus on the scenario of evaluating students’ English speech, as English speech is the most important way to practice [2].
Evaluating students’ English speech can be a challenging problem for computers. On the one hand, it inherits the challenges from speech recognition, e.g. one needs to recognize and analyze both the language and the expression of ideas; On the other hand, it needs to deal with possibly erroneous expressions and with a degree of flexibility in natural language that is unseen in other controlled natural language applications. Evaluating English speech that can be partially broken requires the system to find a balance between identifying correct part of speeches and accurately spot broken parts [3].
Students are likely to make mistakes regarding grammar. Therefore, we focus on grammar error detection and correction. However, the difficulty of the problem we are facing does not necessarily goes down: natural language problems are roughly divided to grammatical, semantic and pragmatic hierarchy but the grammatical level of information may be insufficient to eliminate ambiguity and to detect errors [4]. For example, in this sentence: He stay in dorm and put the final touches to the speech. One must consider semantic level first before one can correct errors on grammar of the predicate. Meanwhile, many collocation errors appear correct when one only considers grammar or sentence structure while carrying semantic problems [5].
Related work
The first study of environmental sound recognition recorded must be retrospect to Welch [6] from the Massachusetts Institute of Technology (MIT). In order to classify environmental scenes, they use Hidden Markov Model (HMM) [7]. At the same time, researchers in the field of experimental psychology focus on the process of understanding and perceiving sound scenes. Cook [8] found that the speed and accuracy of identifying audio scenes are related to the stimulation and frequency of natural sounds. Lasheng Y. U. et al. [9] found that people recognize audio scenes that are affected by specific sound events, such as human voices, car engine roars, and so on. Moreover, 70% accuracy is obtained in distinguishing between 25 types of sound scenes, and the average response time is 20 seconds. Ovetz R. [10] and others analyzed the environmental scene of the railway station, and found that the sound source, human activity and spatial influence factors are important elements that constitute the acoustic category and the prior knowledge of the scene.
Under the influence of related psychoacoustic researches and MIT researchers, environmental sound recognition has received extensive attention [11]. At that time, many research methods for environmental sound recognition were based on the research of keyword detection, speech recognition, speaker recognition and music information retrieval, which led to the similarity of the features and classifiers used. Mel-Frequency Cepstral Coefficients (MFCCs) is a speech feature that is often used in speech recognition problems. This feature has also been introduced into environmental sound recognition. Goldhor used the MFCC feature to study a method used to identify very short sounds, such as barking, that exist in real life [12]. His research shows that the accuracy of the experimental results is related to the use of MFCCs characteristic dimension, and the accuracy is higher when the MFCCs feature dimension is between 12–16 [13]. Okoh E et al. [14] attempted to distinguish between various types of sounds in the kitchen. Steele J R et al. [15] focused on the scenes that appeared in life, and they all found that the most effective corpus for classification performance was 1–3 minutes. The researchers proposed the Independent Component Analysis (ICA) method, which was used to find a linear representation of non-Gaussian distribution data [16]. Moreover, the ICA method is widely used to improve MFCC performance. Ruolan L [17] et al. used the ICA method to take place of Discrete Cosine Transform (DCT) in order to obtain improved MFCC features, which is about 10% better than the unimproved MFCC features on the HMM model. In 2009, audio features that emphasized time domain characteristics rather than frequency domain features were often extracted using the Matching Pursuit (MP) method. Moreover, according to the research results in [18], the fusion of the audio features extracted by the MP method with the MFCC features can improve the recognition performance to some extent. In addition, the researcher also tries to find some replacing audio features.
CNLNet part of speech type
Based on the study of the current mainstream controlled natural language thesaurus, this paper proposes a controlled natural language vocabulary classification type. The CNLNet thesaurus can be divided into two broad categories: functional words and content words. Functional words represent relationship rather than a specific meaning. The terms of functional words are finite and fixed. They are mainly composed of prepositions, quantifiers, qualifiers, special verbs, pronouns and so on. On the contrary, content words have specific semantics that can be described, which are mainly composed of nouns, verbs, adjectives and adverbs. In controlled natural language, the thesaurus can be defined by the following formula:
In the formula, FunctionWords represents function words; Content-Words means substantive words; N means nouns; V means verbs; ADJ means adjectives; ADV means adverbs. NN, NNS, NNP, and NNPS represent common nouns, plural nouns, singular proper nouns, and proper noun plural. VB, VBD, VBG, VBN, VBP, VBZ represent verb prototype, past tense, present participle, past participle, non-third person singular, third person singular respectively. JJ, JJR, and JJS represent the adjectives of absolute degree, comparative degree, and superlative degree respectively. RB, RBR, and RBS represent adverbs of absolute degree, comparison degree, and superlative degree respectively.
Nouns can be divided into proper nouns and common nouns. Proper nouns refer to nouns such as people, countries, companies, trademarks. Common nouns are nouns other than proper nouns, which are often used to define people, things, and so on. In English lexical terms, nouns have certain grammatical characteristics, such as number, case and gender. According to the characteristic of number in nouns can be further divided into countable nouns and uncountable nouns. In a controlled natural language thesaurus, nouns can be defined by the following formula:
In the formula, OntType represents the type of the ontology, class represents the category, and individual represents the individual noun. Type means noun type; sg means countable noun singular; pl means defining countable nouns; mass means material noun; prop means special noun; gender means noun’s linguistic gender; undef means no definition; neutr means neutral; human means human; masc means male; fem means female. According to the gender of the language, we need to use different pronouns to refer to nouns.
Semantically, verbs often describe an action, an event or a state. Verbs can be divided into three main types: auxiliary verbs, modal verbs, and active words. Auxiliary verbs are used to assist the active words to construct tenses, such as “be” and “have”. The modal verb itself has a certain meaning, which means the speaker’s emotion and attitude, and it must be used together with verbs. Except for auxiliary verbs and modal verbs, all of the verbs are active words, and the active words are divided into transitive verbs and intransitive verbs. In addition to the two characteristics of the number and the nature of the basic noun, the verb has three characteristics of tense, aspect and voice [19] when it is finite. Among them, the tense includes two categories: past tense and present tense. Aspect includes progressive aspect and perfective aspect. Voice includes passive voice and active voice. In total, there are 28 different predicate verbs in English, such as the present tense, the simple past tense, the simple present tense, present perfective tense, the present perfective tense, the progressive perfective tense, the past progressive tense, past future perfective tense, the past progressive tense, the future progressive tense, the present perfect progressive tense, the future perfect progressive tense, the past perfective progressive tense, and the like. If the verb acts as non-finite. It includes three types: infinitives, past participle and present participle. Except the above mentioned, the verbs in spoken English is involved in mood. The mood indicates the speaker’s expression: statement, imperative mood, interrogative mood, and subjunctive mood. In a controlled natural language thesaurus, verbs can be defined by the following formula:
In the formula, Type represents the verb type; tv represents the transitive verb; iv represents the intransitive verb; dv represents the double object verb; Subtype represents the subtype of the verb; vb denotes the basic form of the verb; vbi denotes the verb infinitive; vbd denotes the verb past tense; vbc denotes the verb or the present participle; vbn denotes the past participle of the verb; vbp denotes a non-third person singular; vbz denotes a third person singular.
An adjective is a class of words to modify a noun and to describe the characteristics of a modified noun. In English, adjectives can have internal structures (such as fall + ing, which can be used to modify stocks). In a controlled natural language thesaurus, adjectives can be defined by the following formula:
In the formula, ADJ means adjective. Type represents the type of the adjective; positive represents the absolute degree; comp represents the comparative degree super represents the superlative degree.
Adverbs are used to modify verbs, adjectives and adverbs, determining the time, manner, position or direction of the action. In a controlled natural language thesaurus, adverbs can be defined by the following formula:
In the formula, ADV means adverb. Type represents the type of the adverb; positive represents the absolute degree; comp represents the comparative degree; super represents the superlative degree.
The preposition is a kind of function word to represent the relationship between words and words, words and sentences. It cannot be used as a sentence component alone in a sentence. The preposition is usually followed by a noun or a pronoun. The preposition and its object constitute a prepositional phrase, which can function as an adverbial, a complement or a prepositional object. Prepositions have only one form of word. In controlled natural language thesaurus, prepositions can be defined by the following formula:
In controlled natural language, functional words are often used to associate with content words based on parsing and semantic processing in grammar in English sentence. Prepositions are used to mean the meaning of an entity, such as in, for, during; Boolean operator: not, and, either, or, neither, nor, if, then; Quantifier: a, an, some, something, someone, every, everything, everyone, no, nothing, no one; Special verbs: is, has, have, does; question words: who, what, when, where, which; relational pronoun: that; article: the; conjunction: and; fixed phrase: there is/are, such that, only if, if and only if, it is false that, it is true that; Other special words: none, others, nothing else, no one else and so on. In controlled natural language thesaurus, functional words can be defined by the following formula:
CNLNet Thesaurus Model
The CNLNet model is shown in Fig. 1. This model consists of four modules: the thesaurus, the thesaurus parser, the thesaurus common access interface, and the controlled natural language application system. The thesaurus consists of three parts, namely, content words (nouns, verbs, adjectives, adverbs), functional words (credits, qualifiers, prepositions, pronouns) and variants (non-regular variants of functional words). Among them, the content words are divided into two categories: WordNet content words and DomainNet content words. WordNet content words directly reference the WordNet thesaurus and can be imported into CNLNet via tools. DomainNet is a domain vocabulary defined on WordNet’s thesaurus structure that is extended according to the controlled natural language requirements and connects WordNet and DomainNet through a correlation model. The thesaurus parser performs a query on the thesaurus according to the rules to return the query results. The thesaurus universal access interface defines the CNLNet thesaurus model interface, which is convenient for different departments to query the CNLNet thesaurus. A controlled natural language system represents a specific controlled natural language application.
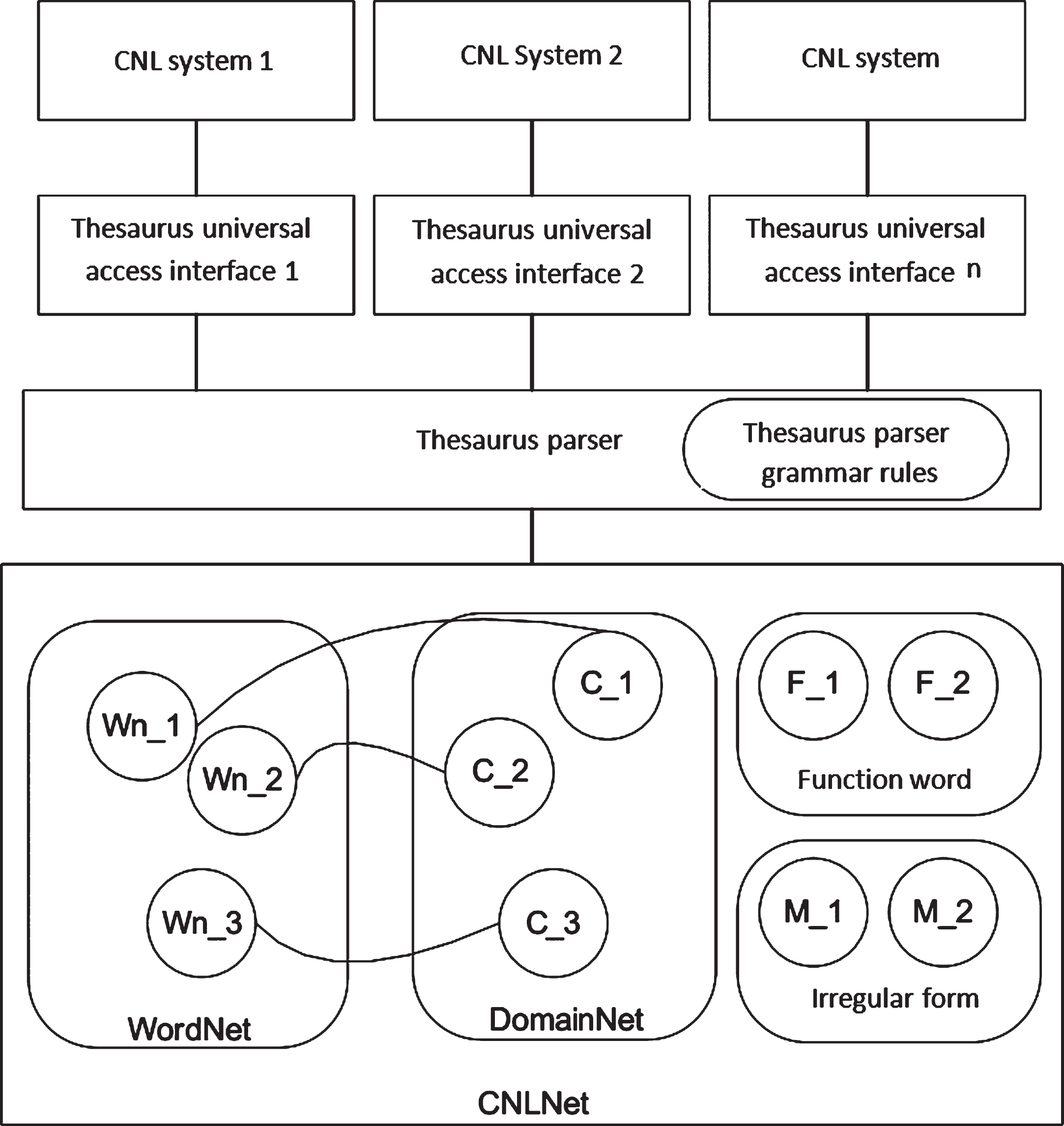
CNL thesaurus model based on WordNet.
This model framework has the following characteristics: It uses a WordNet-based dictionary and defines a domain dictionary in a WordNet structure. WordNet is a semantic-oriented English dictionary. Different from traditional dictionaries, it provides a rich lexical semantic hierarchy, including synonymous relations, antisense relations, overall and partial relation, upper and lower relations. These relationships associate words with words to form a semantic network. In the semantic analysis, these relationships can be fully utilized to map the words input by the user to the concepts in the domain through the relationship, and improve the recognition rate of the words, thereby expanding the number of words that can be processed by the controlled natural language system and improving the applicability of the controlled natural language. It provides a unified thesaurus parsing algorithm. The independent thesaurus operates as a separate module that does not rely on a specific controlled natural language system to improve system portability. It defines a unified thesaurus access interface, implements the thesaurus access interface for different controlled natural language systems, and then connects the controlled natural language system and the thesaurus part through the interface. In the Prolog 3.0 release of WordNet, semantic relationships are represented by a set of Synset Ids. Each set of semantic relationships is maintained by a separate file. There are currently 21 thesaurus files: wn_s.pl, wn_sk.pl, wn_g.pl, wn_syntax.pl, wn_hyp.pl, wn_ins.pl, wn_ent.pl, wn_sim.pl, wn_mm.pl, wn_ms.pl, wn_mp.pl, wn_der.pl, wn_cls.pl, wn_cs.pl, wn_vgp.pl, wn_at.pl, wn_ant.pl, wn_sa.pl, wn_ppl.pl, wn_fr.pl, wn_exc.pl. When defining the domain thesaurus, according to WordNet’s thesaurus structure, we define separate files and WordNet files one-to-one correspondence, and define an associated file to associate the WordNet thesaurus with the DmainNet thesaurus.
The WordNet thesaurus is static data and will not change during use. It will only be generated directly by the Grid program when the WordNet version is upgraded. DomainNet belongs to the domain thesaurus, which is dynamically added or modified during use, so the DomainNet thesaurus should be stored and maintained in a better storage mode. Because the relational database technology is mature and there are many products that can be selected, choosing a relational database to store CNLNet is the best solution.
Considering that the actual application is based on WordNet and needs to expand WordNet data, and the development of WordNet itself, and the upgrade of the data in the WordNet part of the database after the new version is released, it is decided to use the WordNet database as a read-only database and clone the WordNet database structure as the extended database required by the application. In the extended database, SenseID is used instead of Offset, and SenseID and Offset are associated with each other through the wn_mapping table to interconnect the two parts of data.
This article focuses on the groups of entities and their relationships contained in WordNet: synonym sets and their part-of-speech and example sentences, the association of words, words and concepts, the association between concepts, the association between words, the types of associations and their part of speech. This article ignores the structure and usage of verbs and adjectives contained in WordNet, because the purpose of this study is to extract useful lexical semantic information and its relationships, rather than to study the structure and use of the language itself.
CNLNet thesaurus retrieval algorithm
Word retrieval is a pre-work of subsequent syntactic parsing, which finds valid words from the thesaurus and labels the words. Because words in English have morphological characteristics, homomorphic polymorphism, synonymous polymorphism, etc., a word has ambiguity between multiple marks, and the word mark has uncertainty. In this case, we can’t simply query a word from the vocabulary and mark it. In order to improve the accuracy of word labeling, the labeling algorithm proposed in this paper is completed on two stages.
The first stage is the word retrieval phase. At this stage, a temporary memory model vocabulary is constructed for each controlled natural language sentence, called MemNet. Then, according to a certain algorithm, all possible related words in the sentence are extracted from CNLNet and placed in the temporary memory model thesaurus MemNet. The construction algorithm of the temporary memory mode thesaurus MemNet is shown in Fig. 3.
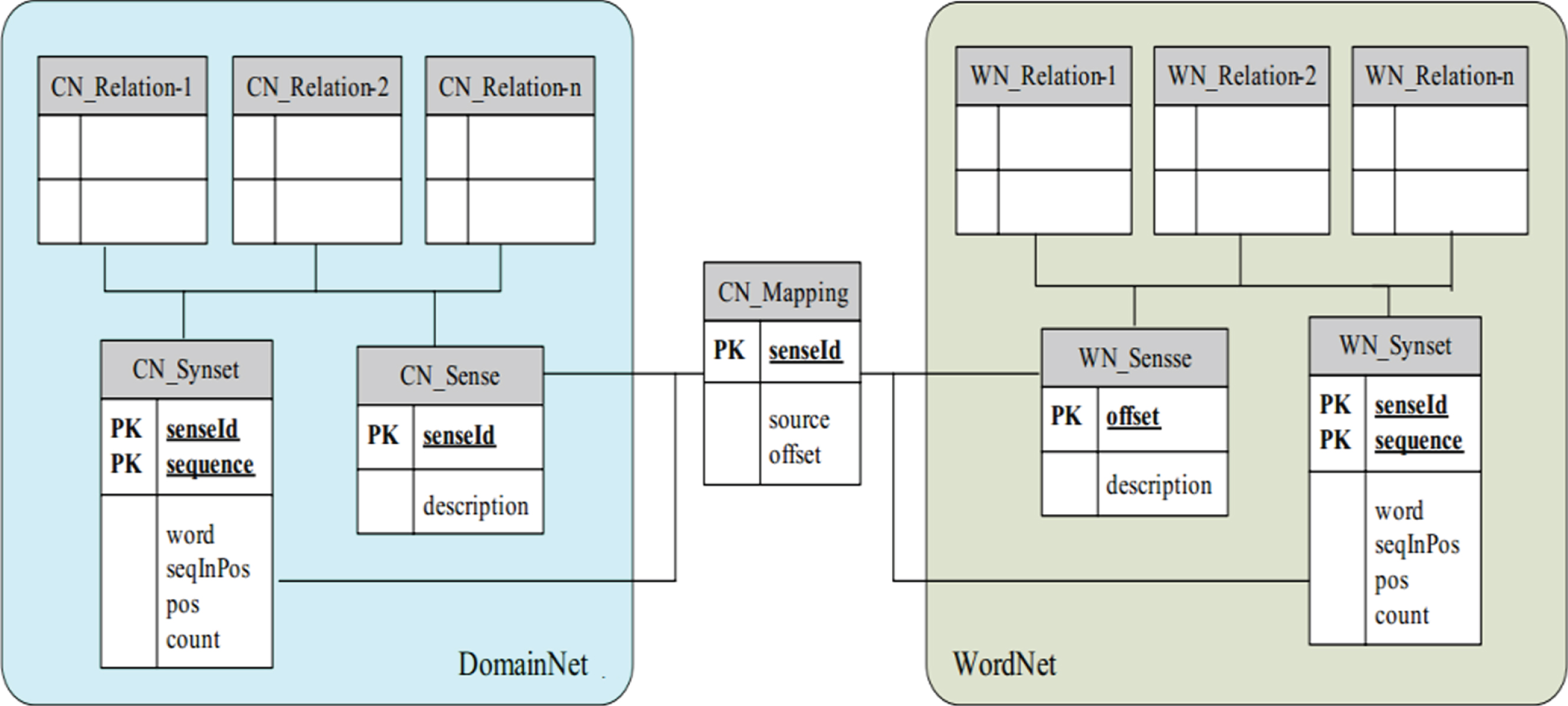
CNLNet database model.

CNLNet thesaurus retrieval algorithm.
The second stage is completed during the parsing phase. At this stage, words are disambiguated according to defined grammatical rules, and syntactically compliant words are identified from MemNet.
The specific processing steps of the word retrieval algorithm are as follows: The word first needs to be processed by morphological analysis, and the prototypes of possible words can be found according to the inflection change library or the inflection change rule, and then a set of possible prototype thesauruses is obtained;
Each word w
i
in W
m
is selected to look up DomainNet and determine if w
i
exists. Since the word has a polysemy, the result of the query may be a set of semantic lists S
n
. If the semantic list S
n
is not empty, it means that there is semantics, and the semantic list obtained by the query is placed in MemNet. If the semantic list S
n
is empty, it means that CNLNet does not define a word and w
i
does not exist, and the following steps need to be continued.
Each word w
i
in W
m
is selected to look up WordNet. Because the word has a polysemy, the result of the query may be a set of semantic lists S
k
.
Each semantic s
i
in S
k
is selected to find the association table of WordNet and DomainNet to determine whether s
i
exists. If it exists, the semantics of the corresponding DomainNet are found through the association table, and s
j
is placed in MemNet. If it does not exist, the following steps are continued.
If the semantics associated with s
i
are not defined in the association table, the similarity between s
i
and the semantics of s
j
in DomainNet is calculated according to the definition of s
i
in WordNet, by the upper and lower positions and the implication relationship of s
i
. If it is greater than a given threshold, s
i
is considered synonymous with s
j
, and the corresponding s
j
is added to MemNet.
If the corresponding semantic information cannot be found in DomainNet through the above steps, this semantics s
i
is discarded. On the above steps, the temporary memory model thesaurus MemNet is obtained, and all possible semantic information of the word word is extracted.
Since this article uses a controlled ontology thesaurus and any meaningful words must be defined in the thesaurus, this article does not consider the derived form and it only analyzes the inflection changes. English has a relatively simple inflection system. Only nouns, verbs, and partial adjectives have inflection, and the number of possible inflection affixes is small. English nouns only have two inflections, plural and subordinate. The inflection of English verbs is relatively complicated, and is related to the person, tense and voice of the verb. The inflection of English adjectives is mainly the comparative and superlative form of adjectives.
For regular variants, such as the word “harder” consisting of two morphemes, hard and -er, we need to convert according to the variant rules to find the prototype of the word. There are many rules like this in English words. In the process of parsing, all the rules need to be described, and the words are parsed separately to judge the possible prototypes of the words. For example, for the English harder, the first possible word in English is [harder], the second possible word is [harde, - er, ADJ], and the third possible word is [hard, - er, ADJ], which can be expressed in the following form:
For variants without rules, such as the superlative degree of the word good, we need to maintain it with the variant library. We need to confirm the meaning of the prototype and variant of the word by using the query variant library. If there are multiple prototypes for the same variant, we need to list all possible prototypes, which can be expressed in the following form:
Homomorphic polysemy means that the same form has multiple different meanings. In DomainNet and WordNet, it means that the same Word corresponds to multiple semantics. The homomorphic polysemy problem has no way to disambiguate in the lexical analysis stage. The only thing that can be done is to extract all relevant meanings and determine whether it can be mapped into the DomainNet domain thesaurus. If the corresponding definition can be found in DomainNet, it is added to the temporary thesaurus MemNet, and subsequent parsing will determine which semantics the word is selected to have based on the syntax rules. If it does not exist, it is discarded.
For example, the English word OK is defined in WordNet as follows: noun, Oklahoma, Sooner State, OK – (a state in south central United States) noun, O.K., OK, okay, okey, okeh – (an endorsement; “they gave us the O.K. togo ahead") adj, all right, fine, o.k., ok, okay, hunky-dory – (being satisfied or in satisfactory condition;) adv, very well, fine, alright, all right, OK – (an expression of agreement normally occurring at the beginning of a sentence)
If it is in a related application in the United States, OK may be more likely to represent Oklahoma State, or it may be an endorsement, or a window button labeled OK. By defining the thesaurus in the domain by DomainNet, several other meanings can be excluded, and then through syntactic analysis, which word meaning used is judged according to the content of the sentence.
Synonymous polymorphism processing
Synonymous polymorphisms mean that words with different forms have the same meaning. In DmainNet and WordNet, it refers to that the same semantics correspond to multiple Words. For example, car, auto, automobile, machine, and motorcar all have the meaning of “a motor vehicle with four wheels”. If only the car word is defined in the domain thesaurus DomainNet and the user enters the word for motorcar, the car is retrieved through the synonymous relationship of the CNLNet thesaurus model and the car is added to the temporary thesaurus MemNet.
Vocabulary similarity calculation
Definition 1: For two words w
i
and w
j
, the similarity function is expressed as sim (w
i
, w
j
), and the distance between words is expressed as dis (w
i
, w
j
). The relationship between lexical similarity and distance between words can be expressed as the following formula:
At present, relevant scholars have proposed some principles for judging the semantic similarity between two arbitrary words based on the similarity calculation between WordNet’s own concepts. These principles help to analyze the common features between vocabulary. In order to find out the corresponding similar vocabulary in DomainNet more accurately according to a WordNet vocabulary, the formal definition of lexical similarity function is proposed based on CNLNet thesaurus.
Definition 2: The WordNet thesaurus is defined as a collection W, and the Do-mainNet thesaurus is defined as a collection C. w
i
is an element in W, c
j
is an element in C, and the similarity function of w
i
and c
j
is:
∂ is an adjustable parameter and the dis (w
i
, c
j
) function can be further defined as:
In the formula, n denotes the relationship between the concepts c1 and c2 in the ontology thesaurus, and the value of δ
i
(w
i
, c
j
) is defined as:
The machine learning-based spoken English system model structure used in this study is shown in Fig. 4.

Model of spoken English language system based on machine learning.
The cross-language robust mapping method based on word alignment can naturally extend to the case of multiple languages. As shown in Fig. 5, we first use English as the public source language and learn the monolingual lexical distribution representation of the language. After that, we use the “cross-language mapping + monolingual propagation” method to map the distributed representation matrix of the language to other languages. The mapping process for each language is independent of each other.

Schematic diagram of multilingual robust mapping method.
Considering the extensiveness of English resources, we still use English to connect other different languages, as shown in Fig. 6.
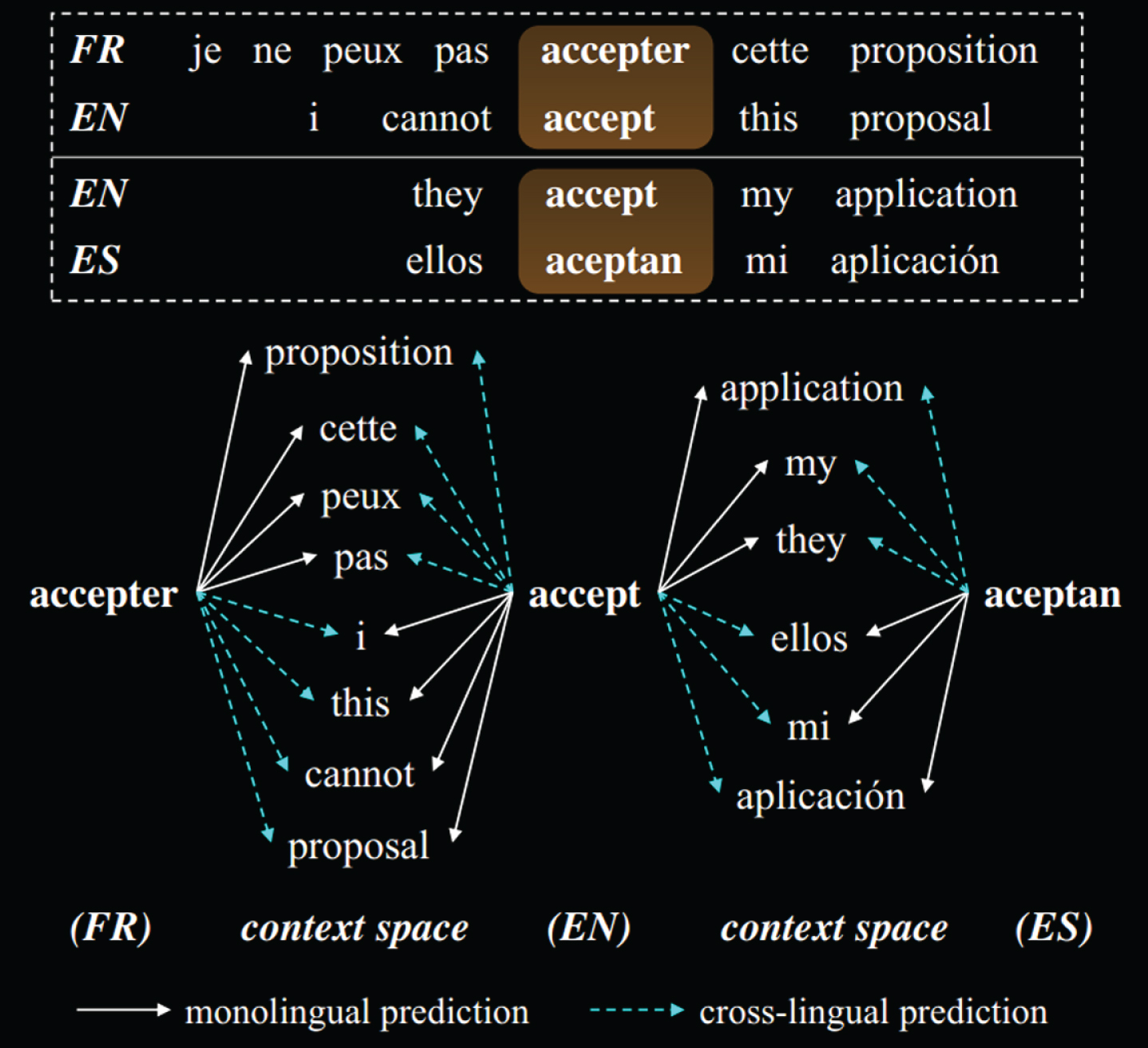
Multilingual Skip-gram model.
In this study, we consider the learning process of each tree library as a separate task and propose a framework for deep multi-task learning to achieve information interaction between different tasks, as shown in Fig. 7. We take the learning on the target tree library as the primary task and the learning on the source tree library as related tasks.

Tree library fusion framework based on deep multi-task learning.
For the WordNet-based controlled natural language ontology thesaurus model established in this paper, the correct recognition rate of controlled natural language sentences can be selected as the evaluation index. The evaluation of the thesaurus model refers to whether the system function is complete and whether it can be used for specific applications. This article collects 1421 test sentences from the telecom field requirements document and conducts experiments on two prototype implementations of ACENet and ACEXEx. The experimental results are shown in Table 1:
Experimental results of ACEExt and ACENet
As shown in Fig. 8, the experimental results show that in the case of defining only 100 domain thesauruses, the recognition rate based on ACENet is 63.55%, while the recognition rate of ACEExt is only 21.25%. With the definition of the domain thesaurus, the recognition rate has increased, but the ACEExt recognition rate is much lower than that of ACENet. ACEExt needs to define a large number of domain thesauruses to achieve recognition rates of ACENet.

Comparison of test accuracy.
Sentences of different lengths between 4 and 30 are taken. Each sentence is taken from three test sentences. Through the supplemental domain thesaurus, it is ensured that each test sentence must be a sentence that ACENet and ACEExt can handle. Each sentence is processed in the same hardware environment with ACENet and ACExt, and each sentence runs 10 times. After that, the average value of the processing of each sentence is taken as the processing time required for the sentence, and then the average of the processing time of the long sentence of the same sentence is taken. The experimental results are shown in Fig. 9. As can be seen from the figure, ACENet introduces WordNet, so the thesaurus retrieval time is longer than ACEExt. However, since the search algorithm first checks Domain-Net, if it does not exist, it looks for WordNe t and the test sentence DomainNet in the domain has a high hit rate, and its impact on overall performance is acceptable.

Comparison of test aging.
The WordNet-based thesaurus model proposed in this paper has the relevant characteristics of ontology, including the main concepts in the domain, the relationships between concepts, the basic properties of concepts, synonyms and other related contents. Based on the words entered by the user, the synonym set is searched, and the WordNet and DomainNet mappings are used to accurately locate the words defined in DomainNet and use this word to replace the words entered by the user. In this way, we can take advantage of the synonymous relationship in WordNet. Moreover, in the field, we only need to define a few thesauruss to accept other synonyms input by the user and reduce the difficulty of constructing and maintaining the domain thesaurus. This article uses a WordNet-based ontology vocabulary and uses a conceptual hierarchy to define the DomainNet thesaurus. The extended DomainNet thesaurus usually defines only some domain concept vocabulary, and other related concepts can enrich the expression of the DomainNet thesaurus by mapping with WordNet concept vocabulary. Therefore, finding the DomainNet domain concept vocabulary through lexical similarity is a process of finding domain semantic related words through WordNet. In this paper, we use a semantic dictionary-based approach to measure the similarity between two words. The semantic dictionary-based approach considers that there is a close relationship between the distance between words and the similarity between words: The distance between two words and their similarity are monotonically decreasing, that is, the greater the distance between words, the lower the similarity. Conversely, the smaller the distance between two words, the greater the similarity.
Footnotes
Acknowledgments
This research was supported by China Humanity and Social Science Program Foundation of the Ministry of Education of People’s Republic of China under Grant No. (in progress), with the name of “English Teachers’ Interactional Competence Development”.