
Abstract
The hesitant fuzzy linguistic term set (HFLTS) is usually used in the uncertain decision situation. In order to solve the problem of multi-criteria decision-making (MCDM) with HFLTS, a new MCDM method based on the cloud model and evidence theory is proposed in this paper. A new envelope, whose representation is a synthetic cloud generated by the multiple linguistic term in the HFLTS, is presented for HFLTS to facilitate the computing processes and take both the randomness and fuzziness of linguistic variables into consideration. As to overcome the drawbacks of tradition aggregation operator, the criteria values in the form of the belief degrees are obtained from the synthetic clouds and aggregated using the evidential reasoning algorithm. An illustrative example, which is given to confirm the feasibility and validity, also shows that with the proposed method more reasonable and accurate ranking results can be obtained. Moreover, the belief degree of each linguistic term as well as the hesitant degree of the assessment can be obtained simultaneously.
Keywords
Introduction
Multi-criteria decision-making (MCDM) problems are commonly specified in complex and uncertain situations [1]. In such cases, the decision makers (DMs) usually feel more confident of providing linguistic assessments than providing exact numerical values because of the inherent vagueness of human preferences. This decision-making case is defined as a linguistic MCDM problem, that is, the alternative assessments with regard to criteria are given with linguistic variables [2].
The research on the linguistic MCDM problem has obtained rich achievements [3–6] since Zadeh [2] proposed the concept of linguistic variables. Herrera et al. [7] and Martínez et al. [8] survey that three main types of linguistic MCDM methods have been put forward: (1) The method on the basis of membership functions, which could convert the linguistic concept into some fuzzy numbers by membership functions [9–12]. (2) The method on the basis of symbols, which could convert the linguistic concept into some real numbers [13–16]. (3) The method on the basis of 2-tuple linguistic models, which could also transform the linguistic concept into some real numbers and introduce the uncertain decision-making into the precise domain [17–20].
However, the methods mentioned above have some serious limitations because that each linguistic variable is indicated by only one linguistic term. There may be doubt in decision-making, especially when DMs participated in a decision situation hesitate when educe their preference rather than a single value due to the complexity, time pressure, and insufficiency of information among different possible values [21]. Therefore, a single linguistic term is often insufficient for DMs to express their preferences in the uncertain decision situation. Rodríguez et al. [22] put forward the hesitant fuzzy linguistic term set (HFLTS) which permits DMs to evaluate a linguistic variable by a few linguistic terms.
Recently, more and more studies have been devoted on the linguistic MCDM problem with HFLTS [22–28]. Rodríguez et al. [22] use linguistic intervals generated by the envelope of HFLTS to facilitate the computing processes for HFLTS, but the results lose initial fuzzy representation. In Liu and Rodríguez’s work [1], the fuzziness of linguistic variables is considered, and a fuzzy representation for linguistic variables, in which the variables are represented by a fuzzy membership function generated from the multiple linguistic terms, is proposed based on a new fuzzy envelope for HFLTS. However, taking both the randomness and fuzziness into consideration simultaneously makes a representation of HFLTS more reasonable. As a new cognitive model of uncertainty, the cloud model is proposed by Li et al. [29] for the randomness of membership degree, which is founded on probability theory and fuzzy sets theory. The cloud model represents the linguistic concept with three numerical characteristics that reflect not only the average level of the linguistic concept but also the randomness and fuzziness. Some methods have successfully applied the cloud model to the linguistic MCDM problem, by transforming the linguistic concept into the cloud [30–33]. However, there is no study on transferring HFLTS to the cloud until now. In this paper, considering both the randomness and fuzziness of linguistic variables, we propose a new representation of HFLTS based on the cloud model.
In the MCDM problem, aggregating different criteria values is crucial. Since Yager [34] first proposed the ordered weighted averaging (OWA) operator, many aggregation operators have been studied, e.g., the ordered weighted geometric averaging (OWGA) operator [35], the linguistic weighted ordered weighted averaging (LOWA) operator [36] and the hesitant trapezoidal fuzzy aggregation (HTFA) operator [37]. However, using traditional aggregation operators in the existing methods for HFLTS may bring some problems: (1) the defined discrete linguistic variables might be extended to the field of continuous variables. (2) the union of two HFLTSs might cause a set involving inconsecutive linguistic terms. (3) the results using aggregation operators might be contrary to common sense, as discussed by Wei et al. [26]. The evidence theory, firstly proposed by Dempster’s work [38] and further developed by Shafer [39], is a generalization of traditional probability, which allows us to get a better handle on the imprecise and incomplete uncertainty. It is particularly useful for dealing with uncertain subjective judgments when multiple pieces of evidence must be simultaneously considered. In 1990s, an Evidential Reasoning (ER) algorithm based on the decision theory and evidence theory was proposed by Yang et al [40, 41] to handle the uncertain MCDM problem. So far, the evidence theory and its extensions have been widely used in many fields such as pattern recognition [42], software requirements prioritization [43], multi-sensor data fusion [44], fault diagnosis [45], forex market analysis [46] and group decision analysis [47]. In this paper, we suppose that the HFLTS consists of the linguistic terms of which only the belief degree is different. Moreover, we consider the performance of each criterion is a reasonable source and can be fused to get a comprehensive evaluation for the uncertain MCDM problem. On the basis of the evidence theory, we aggregate all criteria values to solve the aforementioned problems of aggregation operators.
In this paper, we focus on how to solve the MCDM problem with HFLTS, and propose a method which integrates both the cloud model and evidence theory. We represent linguistic variables through the clouds generated from the multiple linguistic terms which form the HFLTS, and aggregate the criteria values in the form of the belief degrees using the evidence theory. The major contributions of this paper are as followings. Firstly, a new representation of HFLTS based on the cloud model is proposed. Secondly, the conversion from the cloud to the belief degrees is developed. Finally, use the evidential reasoning algorithm to aggregate all criteria values. Different from other MCDM methods, the proposed method can deal with the problems caused by traditional HFLTS representation and aggregation operator.
The rest of this paper is organized as follows: Section 2 introduces some relative definitions. Section 3 proposes the MCDM method for HFLTS based on the cloud model and evidential theory. To validate the proposed method, a numerical example is examined in Section 4. Section 5 concludes this paper.
Preliminaries
This section involves some basic concepts of HFLTS, cloud model and evidence theory.
Define a linguistic term set S = {s
i
|i = 0, ⋯ g, g ∈ N}, where s
i
is referred to as a possible value of a linguistic variable, and satisfies the following conditions: The set is ordered: if α > β, then s
α
> s
β
; A negation operator exists: neg (s
α
) = sg-α; If s
α
> s
β
, then max {s
β
, s
α
} = s
α
, min {s
β
, s
α
} = s
β
.
Basics of HFLTS
A context-free grammar G H has been defined by Rodríguez et al. [22] to convert the comparative linguistic expressions into the HFLTS through the transformation function E G H .
The comparative linguistic expressions obtained by G
H
are transformed into the HFLTS through the following steps: E
G
H
(s
i
) = {s
i
|s
i
∈ S}; E
G
H
(lessthan s
i
) = {s
j
|s
j
∈ S and s
j
≤ s
i
}; E
G
H
(greater than s
i
) ={s
j
|s
j
∈S and s
j
≥ s
i
}; E
G
H
(between s
i
and s
j
) = {s
k
|s
k
∈ S and s
k
≥ s
i
and s
k
≤ s
j
}.
Define a qualitative concept T over a universe of discourse U = {u}. Then x ∈ U is defined as a random instantiation of T, and μ T (x) ∈ [0, 1] is the certainty degree that x belongs to T, which corresponds to a random number with a steady trend. Define a cloud that represents the distribution of x in the universe U, where x is known as a cloud drop. ∀x ∈ U, the mapping μ T (x), is essentially one-to-many mapping, which means the certainty degree that x belongs to T is a distribution of probability.
The cloud model can describe a concept with three numerical characteristics which are Expectation Ex, Entropy En and Hyper entropy He. In particularly, Ex is the mathematical expectation of the cloud drops that belongs to a concept in the universe. En is used to refer to the fuzziness measurement of a concept. He reflects the cloud drops dispersion. Suppose C is a cloud with three numerical characteristics Ex, En, and He, which can be represented as C (Ex, En, He).
The normal cloud model, which we discuss only in this paper, is founded on the normal distribution and normal membership function. The normal cloud model is generally applicable.
The cloud model is transformed from its qualitative representation to its quantitative representation by the forward cloud generator which generates cloud drops according to the three numerical characteristics, (Ex, En, He). Definition 4 details the generating procedure of the algorithm for the normal cloud as follows:
Input: Three parameters, Ex, En, He, and the number of cloud drops N.
Output: N cloud drops.
Steps: Generate a random number Generate a random number x
i
which follows normal distribution, with expectation Ex and variance Calculate x
i
presented as drop (x
i
, μ
i
) is a cloud drop, whose certainty degree is μ
i
; Repeat steps 1 to 4 until N cloud drops have been generated.
Basics of evidence theory
The basic concepts of the evidence theory relevant to this paper are described briefly below:
where Φ is empty, and A is any subset of Θ. The assigned probability m (A), which is also named probability mass, evaluates the belief assigned to A and indicates the support degree of the evidence to A accurately. It does not include the belief in any particular subset of A. Each subset A ⊆ Θ such that m (A) >0 is referred to as a focal element of m. When a mass value is committed to a subset that has more than one element, it explicitly states that there is not enough information for assigning this belief exactly to each individual element in the subset. Especially when there is no evidence about Θ at all, the total belief is assigned to the whole frame of discernment m (Θ) =1, where m (Θ) is called the ignorance degree.
A new representation of HFLTS based on the cloud model
As a powerful transformation model of qualitative and quantitative, the cloud model makes it possible to address the potential randomness and fuzziness inherent in the linguistic concept. A proposal to get the envelope for HFLTS based on the cloud model is presented here. As using all the information included in the HFLTS is reasonable, every linguistic term in the HFLTS should be considered in the computing processes. At first, all the linguistic terms in the linguistic term set s i ∈ S are transformed into the clouds.
The cloud model uses three numerical characteristics to describe a linguistic term. These characteristics realize the conversion of objective and its interchangeable between a qualitative linguistic concept and its quantitative value. The algorithm for computing the three numerical characteristics can be illustrated as shown below. Ex expresses the expectation of the linguistic concept. Thus, it is natural to use the median of the interval, where Interval [Ex-3En, Ex+3En] best describes the qualitative linguistic concept (99.74%, 6En rule). Therefore, 6En can be used to represent the fuzziness and bound of the linguistic concept. He is set to θ which can be adjusted according to actual conditions.
1000 cloud drops can be generated for each cloud using the forward cloud generator, and the predefined linguistic term set can be explicitly presented by clouds, as shown in Fig. 1.
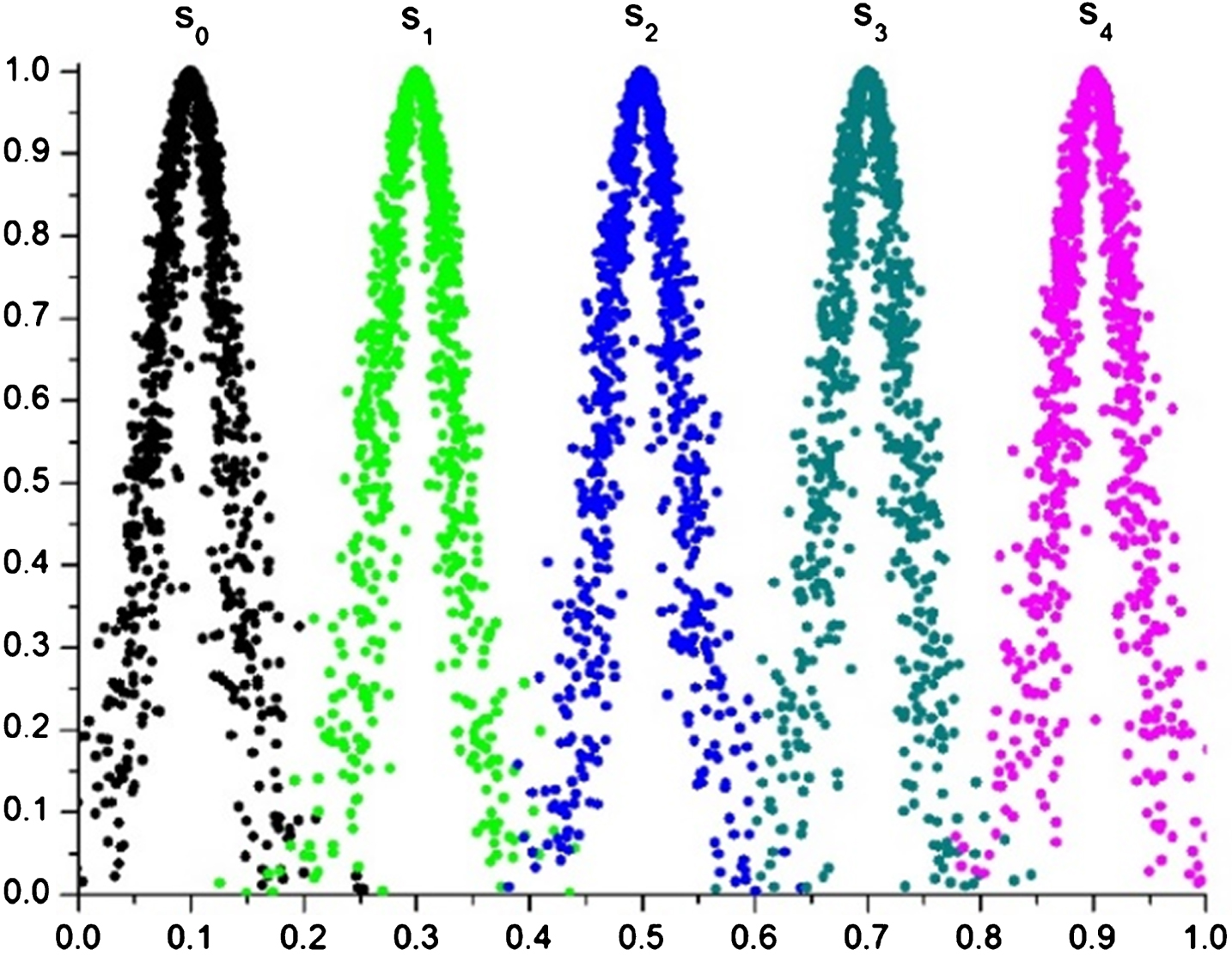
Clouds of the linguistic terms.
For an HFLTS H
S
, its fuzzy envelope env (H
S
) can be defined as an synthetic cloud
Because of the hesitation among {s i , si+1, ⋯ s k ⋯, s j }, such terms might have different importance. We believe the middle term might have more importance. Thus, Ex H S is the average of all clouds. The definition domain of the synthetic cloud should be the same as the collection of clouds c s k (Ex s k , En s k , He s k ), i ≤ k ≤ j. Thus, En H S is greater than En s k of each individual cloud, and its value ensures that the synthetic cloud covers the domain of all original clouds without covering the domain of the irrelevant cloud.

Synthetic cloud.
We suppose that the HFLTS consists of the linguistic terms, just the belief degree of each linguistic term is different. A cloud is composed of cloud drops. Given a cloud drop (x, μ), its certainty degree that x belongs to the concept is μ. If
where β (s i ) denotes a belief degree of the assessment which is confirmed to s i .
Consider the hesitation of the assessment, the discounting coefficient is used. The discounting coefficient can be regarded as a reliability coefficient. The more linguistic terms in the HFLTS, the less reliable the information source is. We use the discounting coefficient to modify the belief degrees.
Based on the evidence theory, an ER algorithm which we used to aggregate the criteria values has been developed for the uncertain MCDM problem [40, 49]. The assessment on each criterion and the linguistic term set S are respectively treated as the evidence and the frame of discernment Θ. The assessments of each criterion can be fused to get the overall evaluation.
Firstly, the belief degrees are transformed into the BPA.
where
Next, the BPAs on all criteria are aggregated into the combined probability assignment.
where
Finally, normalize the combined probability assignment into the overall belief degrees.
β all (s i ) denotes a belief degree to which the alternative is evaluated with s I . β all (Θ) is the hesitant degree of the assessment.
Finally, using Definition 13, the distribution of the overall belief degrees can be calculated:
With respect to a MCDM problem, suppose there are n alternatives A = {a1, a2 … a
t
… a
n
} and m criteria C = {c1, c2 … c
j
… c
m
} with the weight vector W = {w1, w2 … w
j
… w
m
} associated with C, where w
j
∈ [0, 1] and
As a result of the discussion above, we are now in a position to describe a procedure for solving the MCDM problem with HFLTS. The procedure comprises the following steps:
After transforming all the linguistic terms in the linguistic term set into the corresponding clouds using Definition 7 in Section 3.1, the fuzzy envelopes of HFLTS
First, convert the synthetic cloud into the belief degrees using Definition 9 in Section 3.2, then use the discounting coefficient to modify the belief degrees according to Definition 10 in the same section. The distribution of the discounted belief degrees for alternative a
t
on criterion c
j
is denoted as
The criteria values are aggregated and the overall belief degrees of alternative a t are acquired by the ER algorithm given in Definitions 11–13 in Section 3.3.
Rank the alternatives on the basis of β all (a t ), and then, obtain the best one.
Illustrative example
This section demonstrates the implementation process of the proposed method with a numerical example. Let us consider the problem of evaluating three anti-air information warfare systems A = {a1, a2, a3} (adapted from [25]). It is necessary to make a decision according to the following four criteria C = {c1, c2, c3, c4}: Information suppression c1, Hard destruction c2, Network resistance c3, Psychological resistance c4, with the associated weight vector W = {0.3, 0.2, 0.4, 0.1}. In addition, comparative linguistic expressions near the natural language are preferred by DMs. Therefore, the context-free grammar G H and the linguistic term set S = {s0 = " VeryPoor " , s1 = " Poor " , s2 = " MediumPoor " , s3 = " Fair " , s4 = " MediumGood " , s5 = " Good " , s6 = " VeryGood "} are used. The assessments given by the DMs in linguistic expressions for this problem are illustrated in Table 1. The linguistic expressions are transformed into the HFLTSs according to Definition 2, as shown in Table 2.
Evaluation information
Evaluation information
HFLTSs generated from the linguistic expressions
Given the universe [Umin, Umax] = [0, 1] and He = 0.01, by Definition 7, the linguistic terms in the linguistic term set can be converted into 7 clouds as c
s
0
(0.071, 0.024, 0.01), c
s
1
(0.214, 0.024, 0.01), c
s
2
(0.357, 0.024, 0.01), c
s
3
(0.5, 0.024, 0.01), c
s
4
(0.643, 0.024, 0.01), c
s
5
(0.786, 0.024, 0.01), c
s
6
(0.929, 0.024, 0.01). Then, the fuzzy envelope of HFLTS env (H
S
) =
Synthetic clouds generated from HFLTSs (
)
Synthetic clouds generated from HFLTSs (
For each synthetic cloud, use Definition 9 and Definition 10 to obtain the distribution of the discounted belief degrees. The result is shown in Table 4.
Distribution of the discounted belief degrees (
Firstly, as shown in Table 5, the distribution of the discounted belief degrees of each criterion is transformed into the BPA by Definition 11. Next, the BPAs of all four criteria are aggregated into the combined probability assignment for each alternative by Definition 12. The result is shown in Table 6. Finally, by Definition 13, the combined probability assignment is normalized into the overall belief degrees, as described in Table 7.
Basic probability assignment (
Combined probability assignment
Distribution of the overall belief degrees
The distributed assessment and their hesitation for three alternatives can be shown graphically as in Figs. 3 and 4. From Fig. 3, the differences among three alternatives can be identified and be used to rank them. For example, a3 is apparently preferred to a2 as the former is assessed to be Medium Good at a high degree and assessed to be Fair at a certain degree while the latter is assessed to be Fair at a high degree and assessed to be Medium Poor at a certain degree. It can be seen from Fig. 3 that among three alternatives only a1 is to a high degree assessed to Poor and also it is to a certain extent assessed to Medium Poor. Furthermore, it can be seen from Figs. 3 and 4 that the evaluation of a1 is more distributed and hesitant. Therefore, a1 should be the worst in performance. We can obtain the following intuitive ranking order based on the above observations: a3 > a2 > a1.

Distributed assessment for three alternatives.

Hesitation for three alternatives.
By calculating the utilities, ranking order which is more precise can be obtained. Suppose the utilities of linguistic terms are U = {u (s0) = 0, u (s1) = 0.167, u (s2) = 0.333, u (s3) =0.5, u (s4) = 0.667, u (s5) = 0.833, u (s6) = 1}. Then we can calculate the maximum, minimum and average utilities of the alternative as follows [49]:
We can rank the alternatives according to their average utilities, which are calculated as u avg (a1) = 0.423, u avg (a2) = 0.503, u avg (a3) = 0.606. It can be known that a3 > a2 > a1, which is the same as the ranking result got previously by intuitive analysis.
For validation of the feasibility of the proposed method, a comparative analysis is conducted by another four linguistic MCDM methods. This analysis is based on the same numerical example mentioned above. A comparison of four methods is shown in Table 8.
Comparison with different methods
Comparison with different methods
As Table 8 shows, the ranking of alternatives obtained by the proposed method is identical to the results of the methods in [1] and [25], but is different from the results of the methods in [22] and [26]. These results indicate: (1) The multi-criteria linguistic decision-making model [22] considers the hesitance among the linguistic variables to produce a range directly, but distort the fuzziness of the information. Therefore, it’s not reliable to conclude that a2 > a3. (2) A total order can not be provided by the MCDM method based on the HLWA operator [26], so a2 and a3 can not be ranked. (3) The result obtained by the MCDM outranking approach based on HFLTS [25] is consistent with the proposed method, but the basis is not similar. The outranking approach involves systematic comparisons of the assessments of alternatives for each criterion, and the calculation process is complex. (4) The result obtained by the MCDM method based on the fuzzy envelope [1] is also the same as the proposed method. The fuzzy envelope of an HFLTS is expressed by a fuzzy membership function and then integrated with the fuzzy TOPSIS model. However, the randomness of linguistic variables is not considered.
In contrast, considering both the randomness and fuzziness of linguistic variables, the proposed method transforms the HFLTS to the synthetic cloud. Considering that the HFLTS consists of the linguistic terms each of which only the belief degree varies, the proposed method converts the synthetic cloud into the belief degrees. Considering the hesitation of the assessment, the proposed method aggregates the criteria values with the evidential reasoning algorithm. Furthermore, compared to the considered methods, the result of the proposed method shows not only the ranking order but also the belief degree of each linguistic term and the hesitant degree of the assessment using percentage values.
HFLTS is more appropriate for the linguistic MCDM problem than traditional linguistic set. In this paper, a new MCDM method for HFLTS is proposed, which takes advantages of both the cloud model and evidence theory. To facilitate the computing processes and take both the randomness and fuzziness of linguistic variables into consideration, the envelope for HFLTS is obtained based on the cloud model. To overcome the drawbacks of tradition aggregation operators, the criteria values are aggregated based on the evidence theory. The contributions of this paper are threefold. First, a new envelope for HFLTS is proposed, in which a synthetic cloud is generated by aggregating the clouds of the linguistic terms in the HFLTS. Second, a method for converting the synthetic cloud into the belief degrees is developed, according to the distribution of cloud drops and the discounting coefficient. Last but not the least, we use the ER algorithm to aggregate different criteria values and rank the alternatives based on the belief degrees. A numerical example together with the corresponding comparison analysis with other methods is used to demonstrate the feasibility and validity of the proposed method. The results show that more reasonable and accurate ranking outcomes can be obtained by the new method. Moreover, the belief degree of each linguistic term and the hesitant degree of the assessment can be obtained simultaneously. Therefore, the new method has much application potential. In future research, we will apply our method in resolution of the problems that may include different types of evaluation information such as numerical, linguistic and interval-valued information.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China (No. 71301081, 61373139, 61572261), Natural Science Foundation of Jiangsu Province (No. BK20130877, BK20150868), Natural Science Foundation of the Higher Education Institutions of Jiangsu Province (No.17KJB520027), Natural Science Foundation of Nanjing University of Posts and Telecommunications (No. NY218073).