
Abstract
For those key data in feature genes selection which the neighborhood of a sample is not completely contained in its decision equivalence class, most of existing models lack of advantages. Therefore, in this paper, we propose a new model to handle this problem: fuzzy neighborhood conditional entropy model. First, fuzzy neighborhood granule and fuzzy decision-making are introduced by using a parameterized fuzzy similarity relation between samples to depict the gene expression profile data more accurately. Then, we introduce the both into conditional entropy and propose the definitions of fuzzy neighborhood conditional entropy, whose strict proof of the monotonicity and other theorems are given. The strategy, which combines algebra definition with information theory definition about the importance of feature genes subset, makes the measurement mechanism more perfect. In the meantime, we set parameters and discuss the importance of its selection to tolerate the noise in the data. Finally, we employ the monotonicity principle of fuzzy neighborhood conditional entropy to evaluate the significance of a candidate feature gene, using which a feature genes selection algorithm is designed for proposed model. Comparing with the existing related algorithms through data sets selected from the public data sources, the experimental results show that the proposed algorithm selects relatively few feature genes and possess higher classification performance.
Keywords
Introduction
With the rapid development of science and technology, human beings’ life has been better and better. But at the same time, its side effects for human life have also become increasingly apparent, for instance, the rising incidence and mortality of cancers. Tumor, one of the major threats to human health, which has a great variety and complex pathogenesis, is a difficult research field. Therefore, the prevention and treatment of tumor have already become one of the focuses for researchers. Nowadays, machine learning and data mining have been applied extensively in the processing of gene expression profile, which, on the one hand, has played a significant role in the field of tumor generation and development, on the other hand, has a particularly important and practical significance in tumor molecular diagnosis [1].
Gene expression profile generates panoramic records of cells in gene expression messages, which can approximately embody the entire genome of a biological tissue and reflect the information of a large number of cells at different levels. In recent years, with the development of gene microarrays, the reliable acquisition of gene expression profiling data has become possible. However, the high dimensionality, small sample size, and noise redundancy of gene expression profiling data pose a challenge for data detection and feature selection [2]. From a biological point of view, there are only a few genes that are truly related to the sample category. Therefore, it is critical to select the most contributing features for the classification of the tumor through the correlation measure between the feature gene and the tumor sample during gene expression profiling.
At present, there are many research topics and solutions in feature genes selection. As a knowledge acquisition tool, rough set theory has been widely used in the analysis of gene expression profile and has achieved good results. The classical rough set model, proposed by Pawlak [3], has been successfully applied in feature selection [4-7]. However, the classical rough set can only deal with discrete data, so it is confronted with the problem of discretization of continuous attributes before the attribute reduction, which might lead to the loss of original data information. To solve this problem, neighborhood rough set and fuzzy rough set were proposed as two important models in succession, and have been constantly studied in depth. Lin generalized classical rough set and neighborhood operators [8]. Subsequently, Yao et al. studied the relationship between rough approximation operators and neighborhood operators and proposed the axiomatic property of the model [9]. Hu et al. constructed an attribute reduction algorithm based on the neighborhood rough set model, which took the positive domain as the heuristic information from the definition of algebra [10]. By using the neighborhood relations, the problem of classical rough set analysed above can be solved with the direct processing of continuous attributes. However, when the background is fuzzy, the fuzziness of the samples can not be accurately described. Dubois and Prade combined rough sets with fuzzy sets, defined the concept of fuzzy rough set [11]. Then, Jensen introduced the dependence function of classical rough set into fuzzy rough set, and presented a greedy algorithm for reducing redundant attributes [12]. Bhatt and Gopal proposed the concept of a compact computational domain, improving the computational efficiency greatly [13]. Hu et al. used kernel functions to define fuzzy similarity relation, and employed a greedy algorithm for dimensionality reduction [14]. For noise data analysis, Mieszkowicz Rolka constructed a variable-precision fuzzy rough set model to deal with noisy data [15]. However, among various fuzzy rough set models, the description of sample is usually performed by the calculation of the relationship with the nearest sample, so the existing of noise in the dataset may increase the risk of the calculation result. In view of the drawbacks analysed above, this paper adopt the combination of fuzzy and neighborhood concepts in the data characterization stage, describe the samples in the form of fuzzy neighborhood, construct the fuzzy decision-making based on the decision attributes, trying to keep the original information of the data as much as possible in the calculation process and reduce the misjudgment and the loss of data information.
The construction of the feature evaluation function plays a crucial role in the performance of the final selected feature subset for feature selection. In general, effective feature evaluation methods can improve the classification performance. Methods for measuring the quality of candidate subsets have been proposed, including those based on positive region and dependence [16-18], information volume [19] and information entropy [20-21], etc. At present, some scholars have integrated information entropy with rough sets, such as conditional entropy [21-22], mixed entropy [23] and so on. It has been mentioned in these papers [24-25] that the algebraic definition of attribute importance focuses on the significance of attributes on the determination of categorical subsets in the universe of discourse, while the definition of information theory considers the significance of attributes on the subset of uncertain classes in the universe of discourse. Both are highly complementary with each other, so the combination of the two will make the measurement mechanism more comprehensive. Chen et al. proposed an entropy measure based on a neighborhood rough set, which can process real-valued data and reduce the impact of data noise [26]. For mixed data sets, Zhang et al. proposed a fuzzy rough set information entropy in feature selection [27]. The neighborhood similarity is used to approximately describe the decision equivalence class [18]. The fuzzy relation can express the original information of the data more accurately. In the analysis of gene expression profiling data, there always be such data that the neighborhood of the sample is not completely contained in the sample decision equivalence class, which is often the key to improve the classification performance of the subset of selected feature genes. Therefore, aiming at this problem, basing on the fuzzy neighborhoods studied in paper of C.Wang [18], we redefine it and introduce it into the conditional entropy. Thus, A new model is proposed, which is named the fuzzy neighborhood conditional entropy model (FNCE).
This model combines the advantages of neighborhood rough set with fuzzy rough set, which makes the data more clearly described, maximizes the use of data information contained in the computation of conditional entropy, and makes the research on the uncertainty of the data more accurate. In this model, the fuzzy similarity relation which is employed in the feature space to parameterize the degree of association between the samples, combines with the sample’s decision equivalence class to obtain the fuzzy decision-making. Meanwhile, the fuzzy neighborhood granule of sample is described by using the neighborhood radius. The intersection between them is used to calculate the conditional entropy of the corresponding attribute, and a new model is proposed. Then, we define the significance between feature genes and decision and design an algorithm for feature genes selection. In order to get fewer and more effective feature genes subset, we introduce a variable-precision method to tolerate noises in data. Ultimately, the experimental results, which are obtained by the designed algorithm, demonstrate the effectiveness of the proposed model.
The remainder of this paper is organized as follows. In the second section, we review some basic theoretical knowledge about fuzzy and neighborhood. In the third section, we establish a new model: fuzzy neighborhood conditional entropy model, and design a feature genes selection algorithm for this model. In the fourth section, we verify the effectiveness of the proposed algorithm by comparing the experimental results with other similar algorithms. The fifth section is a summary of our study.
Related theoretical knowledge
In this section, we briefly review some basic concepts in rough set theory such as equivalence relation, neighborhood relation and fuzzy relation.
During data processing, the classical rough set uses the equivalence relation to granulate the domain into several equivalence classes. Its measurement method for data is mainly based on equivalence relation, so it is only suitable for processing data with discrete attributes.
The neighborhood rough set uses the neighborhood relation to granulate the domain mainly by neighborhood radius. It solves some information loss caused by discretized data and can effectively process numerical data.
In the fuzzy rough set, the fuzzy relation can describe the degree of association between elements and parameterize the relationship between them. It is a relatively basic concept in fuzzy sets.
Therefore, for ∀x⊆U, the fuzzy neighborhood of sample x with respect to R B can be expressed as: [x] R B =R B (x, y) , y∈U, which is a fuzzy set on U.
In this section, in order to reduce the loss of the original data information during the calculation process, a parameterized fuzzy similarity relation is introduced to characterize fuzzy neighborhood granule and fuzzy decision-making for analysis of gene expression profile data. Then, the definitions of fuzzy neighborhood conditional entropy are proposed, and its strict proof of the monotonicity and other theorems are given. Ultimately, based on proposed model, we design a feature genes selection algorithm.
Fuzzy neighborhood granule and fuzzy decision-making
By using fuzzy similarity relation, the degree of association between the samples is parameterized to form a relation matrix that satisfies the reflexivity and symmetry. Each row or column represents the relevance value of one sample to the remaining samples. In order to avoid the impact of data noise, we need to set a parameter α as the neighborhood radius to describe the similarity of the samples, which is beneficial to the study of feature genes classification under different information granularity.
When it satisfies that α1≤α2, for ∀x⊆U, α2 B (x) ⊆ α1 B (x).
The values in Table 1 are normalized to [0,1] by the formula f (x i ) = (x i - xmin)/(xmax - xmin) as shown in Table 2:
Decision table
Normalized data
The fuzzy similarity relation R
a
k
between samples x
i
and x
j
is calculated relative to attribute a
k
as:
So we can get the fuzzy similarity matrix [x]
a
k
(y) about the attribute a
k
, and in conjunction with Definition 4, [x]
A
(y)=
Table 1 is apparent to find U/D={D1, D2, D3}, D1={x1}, D2={x2, x3}, D3={x4}. According to Definition 6 we can get:
So the final fuzzy decision-making is:
Based on fuzzy neighborhood granule and fuzzy decision-making, we propose the fuzzy neighborhood conditional entropy. In addition, those strict proof of other theorems are given.
|M ∩ N| = | {x1, x2, x4, x5, x8, x9, x10} |=7,
|N ∩ M| = | {x2, x3, x6, x7, x9} |=5.
E
fr
(D|B) = E
fr
(D|A); For ∀b ∈ B, E
fr
(D|B - {b}) > E
fr
(D|B).
To obtain a relative reduction subset, two conditions must be satisfied according to Definition 10. However, due to the inconsistence of datasets and the existence of noise [29-30], and finding the minimum reduction is NP-complete [31], small deviation need to be allowed. In this model, the difference of the conditional entropy between the reduced subset and the original condition subset relative to the decision attribute is not greater than the parameter β as the constraint condition, and the relative approximate reduced subset red is selected, that is, red need satisfies:
Then the attribute significance for r ∈ A - red relative to D is defined as:
According to the above definitions, this paper designs a feature genes selection algorithm for fuzzy neighborhood conditional entropy model. The significance of candidate gene was calculated by using the monotonicity principle of fuzzy neighborhood conditional entropy. The specific calculation process is illustrated by Example 3 and the detailed design flow is shown in Algorithm 1.
According to example 1, we have got fuzzy similarity matrix [x]
a
(y) and fuzzy decision-making FD, and because of α = 0, so the fuzzy neighborhood granule is: α
A
(x) = [x]
A
(y). Then we can get:
So the attribute significance for a ∈ A relative to D are:
Then we get E
fr
(D|red) =0.8412, apparently, E
fr
(D|red) - E
fr
(D|A) >0, we need to calculate:
The attribute significance for r ∈ B relative to D are:
Then we get E
fr
(D|red) =0.2642, apparently, E
fr
(D|red) - E
fr
(D|A) >0, so we need to continue to calculate:
The attribute significance for r ∈ B relative to D are:
Feature genes selection based on fuzzy neighborhood conditional entropy (FNCE)
Feature genes selection based on fuzzy neighborhood conditional entropy (FNCE)
We can see that SIG (a1, red, D) = max {r|SIG (r, red, D)}, so red = {a3, a2, a1}, B = {a4}.
Then we get E fr (D|red) =0.25, apparently, E fr (D|red) - E fr (D|A) =0, so finally return red = {a3, a2, a1}.
In this section, we select four data sets from public data sources, compare our designed algorithm with other existing related algorithms by the classification accuracy and number of selected feature genes and discuss the selection of suitable parameters for different data sets.
Experiment preparation
In order to ensure the reliability of experimental results, the data sets are all selected from public data sources. Among them, the first three sets of data are common standard data sets selected from the UCI Machine Learning Repository, with the last set selected from http://datam.i2r.a-star.edu.sg/datasets/krbd/ as experimental data. Specifically see information in detail from Table 3. In order to calculate correlation between the data more conveniently, the experimental data are all normalized to [0,1] by the formula f (x i ) = (x i - xmin)/(xmax - xmin).
Description of data sets
Description of data sets
In order to validate the validity of the proposed algorithm (FNCE), data that has not been processed by any algorithm (Raw data) will be used as a comparison. In addition, FNCE also will be compared with existing related algorithms in the experiment, including the algorithm bases on fuzzy entropy (FISEN) [32] and the algorithm bases on fuzzy neighborhood rough set(FNRS) [18]. The numbers of features selected from different algorithms are listed in Table 4. We respectively use two different classification learning algorithms: Support Vector Machine (Liner-SVM) and K-Nearest Neighbor (KNN, K = 3) to evaluate the performance of different algorithms. In order to make the classification accuracy of classifier more representative, the 10-fold cross validation is employed. Finally, the classification accuracy obtained from different algorithms are shown in Tables 5-6.
Number of selected feature genes
Number of selected feature genes
Classification accuracy for reduced data with Liner-SVM
Classification accuracy for reduced data with 3NN
From Table 4, we can obviously see the number of feature genes selected by the three algorithms are less than the number of feature genes in the original data set, indicating that those algorithms can eliminate redundant genes to a certain extent. According to the average of the number of feature genes after reduction, the FNCE algorithm proposed in this paper is superior to the other two algorithms, for resulting in relatively fewer feature genes.
Table 5 shows the classification accuracy of the Raw data and reduced feature genes subset obtained by different algorithms under the Liner-SVM classifier. The classification accuracy of the FNCE algorithm on the four data sets is higher than that of the Raw data and the FISEN algorithm. It is higher than the FNRS algorithm on WPBC, WDBC and Heart-Cle data sets and the same as FNRS algorithm on Colon data set. By means of the average of classification accuracy, the average classification accuracy obtained by FNCE algorithm is the highest. Table 6 shows the classification accuracy of the Raw data and reduced feature genes subset obtained by different algorithms under the 3NN classifier. The accuracy of the FNCE algorithm on four data sets is higher than that of the Raw data and the other two algorithms, where about 7 - 8 percent higher than the FISEN and FNRS algorithms on the WPBC and Colon data sets.
It is not difficult to find from this experiment that the FNCE algorithm can not only remove redundant features to obtain a smaller subset of feature genes, but also obtain higher classification accuracy. Especially in the WPBC and WDBC data sets, the number of feature genes obtained by FNCE is less than half of the FNRS algorithm, while the classification accuracy is higher than the other two algorithms. Therefore, it is proved that the FNCE algorithm proposed in this paper can extract the most effective feature genes subset.
In this algorithm, there are two parameters α and β. α is the fuzzy neighborhood radius. In order to reduce the noise and the unwanted computation cost caused by the weak correlation between samples, an appropriate fuzzy neighborhood radius should be selected during the calculation of the fuzzy neighborhood granule. β controls the selection of feature genes subset. Due to the inconsistency and redundant noise of data sets, the deviation of conditional entropy between the resulting reduction subset and the original condition subset relative to the decision attributes need to be allowed. Different data sets have different strength of relationship, so we need to select the most suitable parameters for different data sets.
We set α and β to vary from 0 to 0.5, respectively, with interval of 0.05. The number of feature genes selected by different parameters, combined with their classification accuracy under Liner-SVM classifier (the experimental results using 3NN classifier are roughly the same), is shown in Figs.1-4. Final parameters used for different data sets are shown in Table 7.
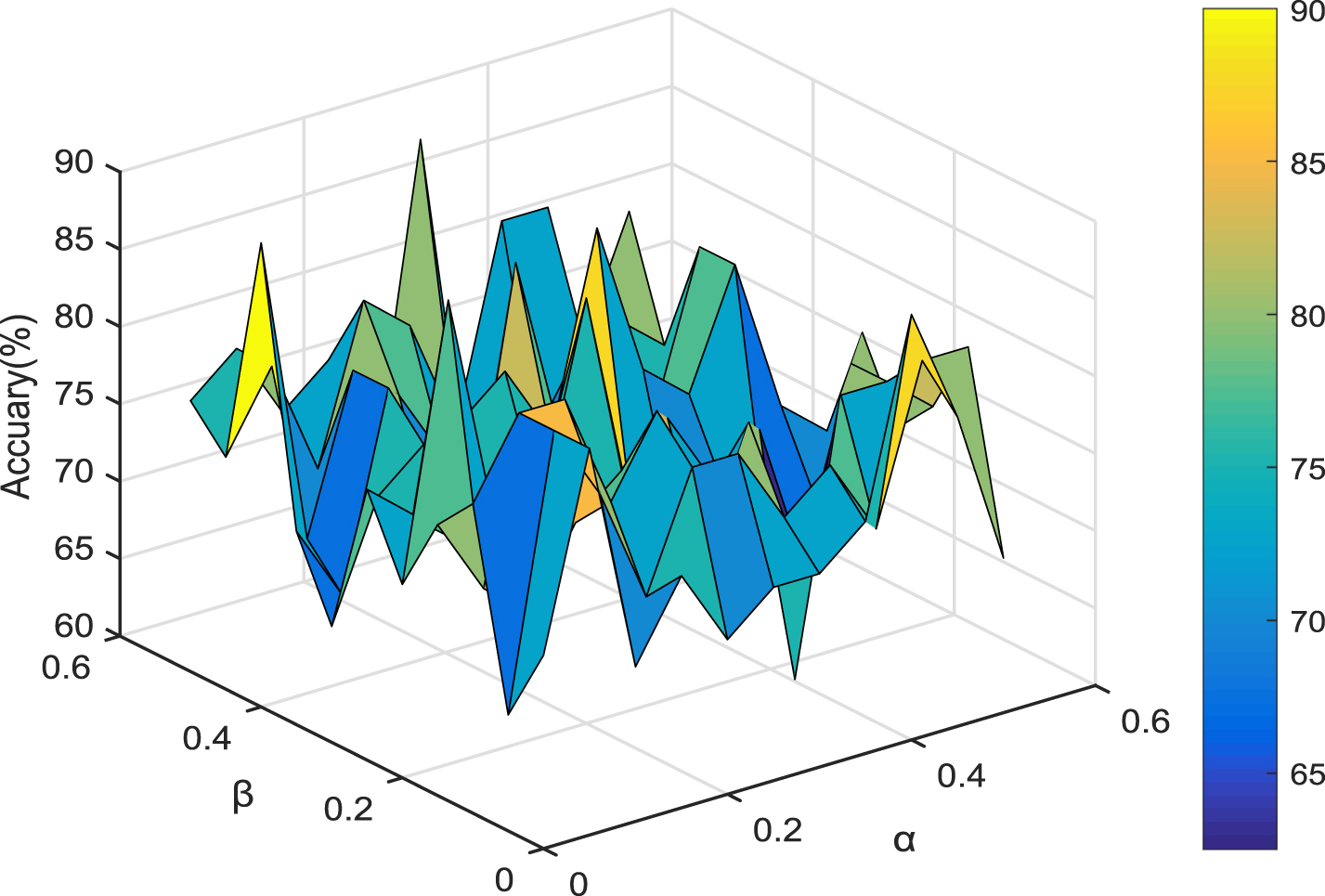
The classification accuracy varying with parameters α and β (WPBC).
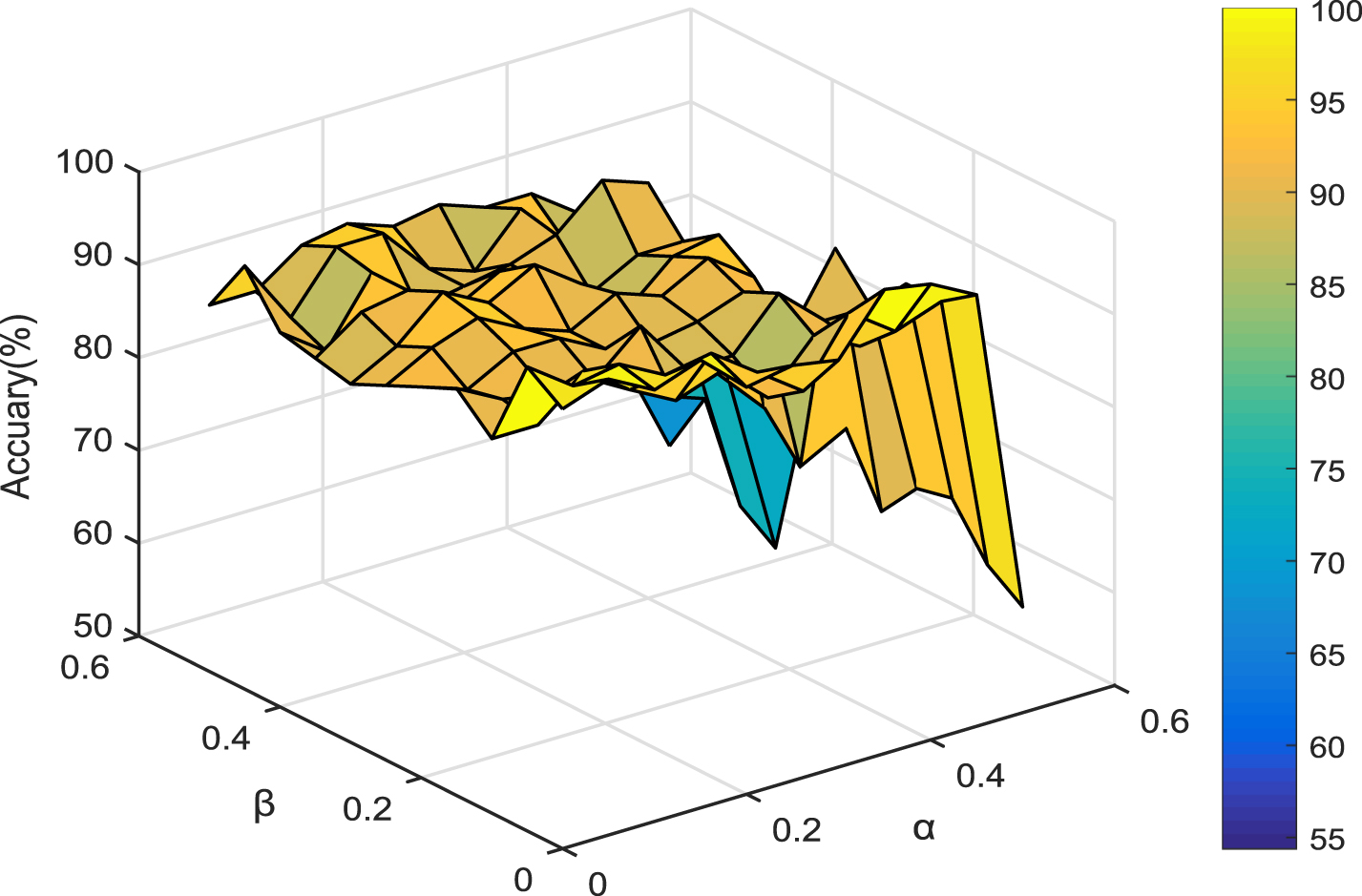
The classification accuracy varying with parameters α and β (WDBC).
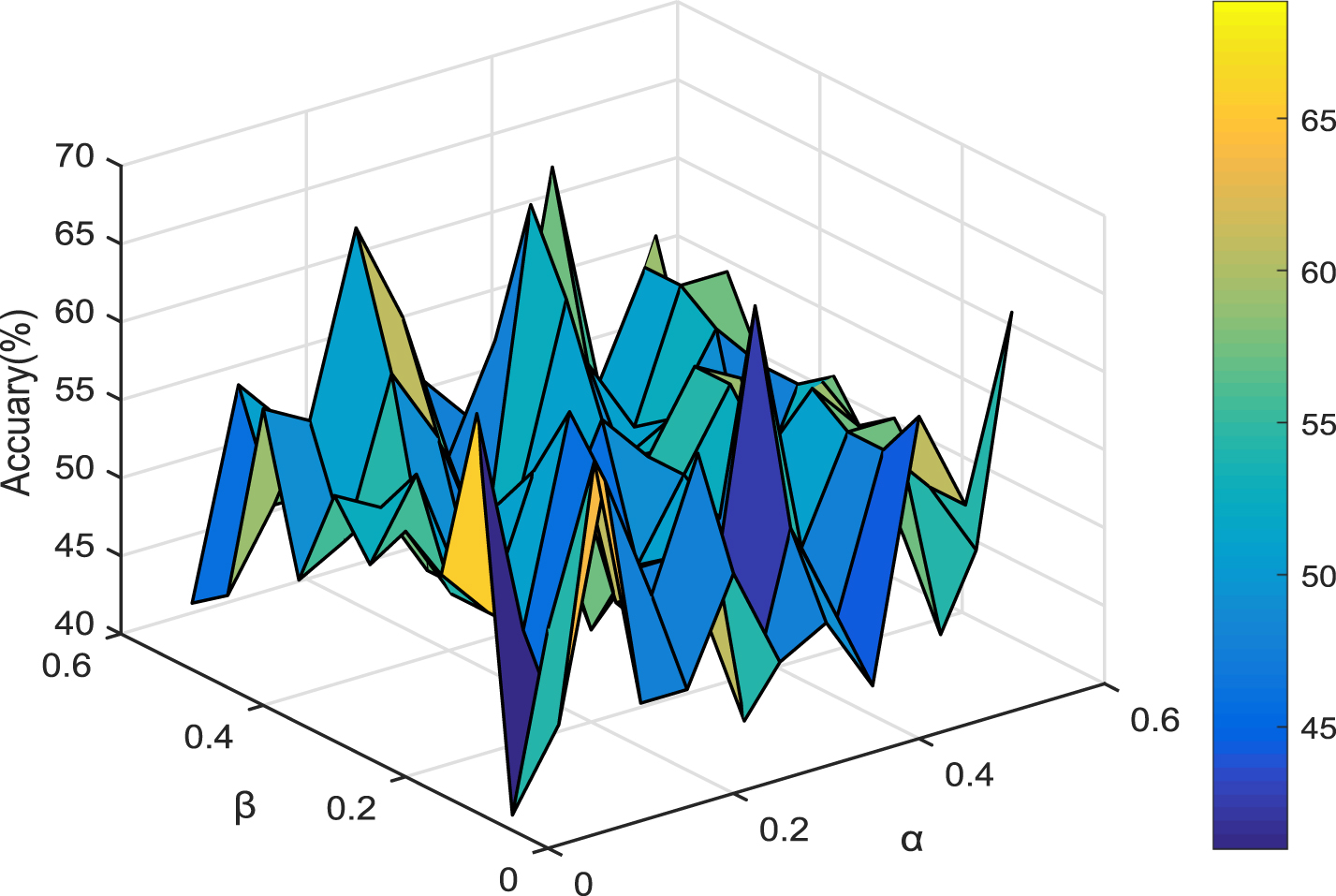
The classification accuracy varying with parameters α and β (Heart-Cle).
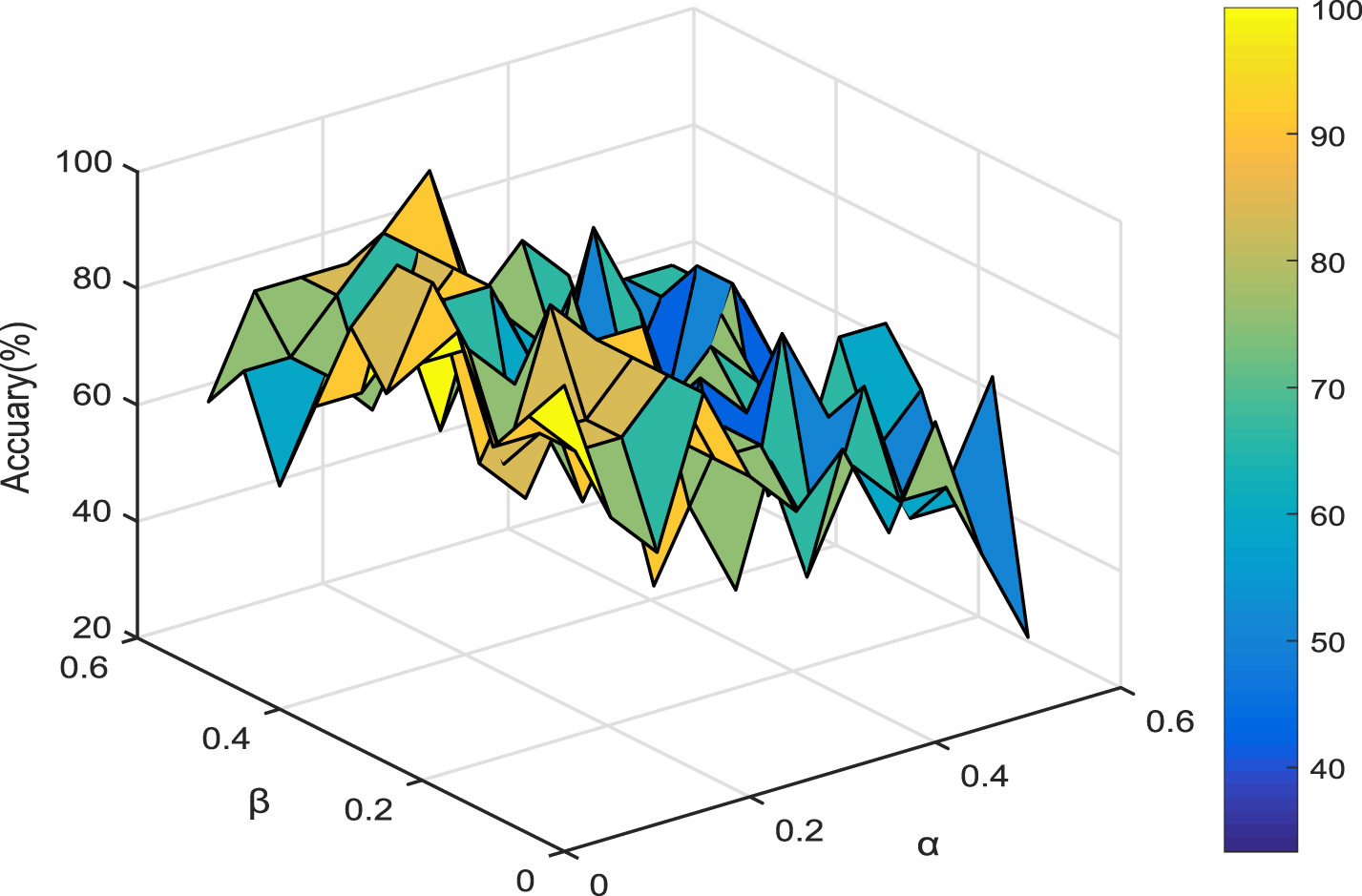
The classification accuracy varying with parameters α and β (Colon).
Suitable parameters for different data sets
In the gene expression profiling, this paper mainly focus on the key data which the neighborhood of the sample is not completely included in the sample decision equivalence class, and proposes a feature genes selection algorithm based on the fuzzy neighborhood conditional entropy model. Through the fuzzy neighborhood granule and fuzzy decision-making, the information contained in the original data can be more accurately described. According to the fuzzy neighborhood conditional entropy model, the best feature genes subset is obtained by basing on tolerating a little noise. Finally, we achieve a higher classification accuracy with a smaller number of feature genes and the experimental results, which are obtained by the designed algorithm, verify the effectiveness of proposed model. This study is based on a complete information decision-making system. Therefore, in the next step, we will supplement and verify the validity of this model under the incomplete information decision-making system, and further optimize the parameter selection to find the appropriate generalized parameters.
Footnotes
Acknowledgements
This work is supported by National Natural Science Foundation of China (Nos.61370169, 61402153, 61772176), Key Project of Science and Technology Department of Henan Province (Nos.162102210261).