
Abstract
Neighborhood granulation is a classical granulation method. Although it is adequate for clustering and classification tasks, its granules are more complex, and the data representation is binary. This paper proposes a new granulation method based on the neighborhood granulation. Firstly, a detailed definition of the granular form is given with fuzzy rough set theory. Then, a modified fuzzy rough discriminant function is proposed based on neighborhood systems. The samples are globally granulated on single features to construct granules and on multiple features to construct granular vectors. Also, a feature selection technique based on the Chi-square, which strikingly reduces the complexity of the fuzzy rough granular vectors, is introduced to address the disadvantage of the fuzzy rough granular vectors. An ensemble model structure is also proposed in the paper for the mixed nature of fuzzy rough granular vectors. The paper makes a detailed comparison between the fuzzy rough granulation and the neighborhood granulation. The results show that fuzzy rough granulation has higher computational efficiency and classification performance. Finally, a detailed comparison is made between the fuzzy rough granular ensemble model and various classical ensemble algorithms. The final results show that the fuzzy rough granular ensemble model has better robustness and generalization.
Keywords
Introduction
Classification problems have been one of the most challenging problems all the time [1, 2]. Since codes are human-predefined processes, they do not do better than humans when faced with unexpected and complex situations [3, 4]. A typical feature of human problem-solving is splitting the problem into multiple sub-problems when encountering a complex task. Then they utilize strong memory and similarity comparison capabilities to handle these sub-problems [5]. Due to the rising complexity of the problem, a single classification system can no longer meet the requirements for classification accuracy. As a result, ensemble learning has become a popular research area in recent years [9]. The construction of the ensemble model can be divided into two categories. The first category is constructed by parallel methods in which the relationships between the individual base learners are parallels, such as the Bagging algorithm and the Random Forest algorithm [10, 11]. The second category is built from sequential methods, in which the base learners are constructed sequentially, represented by algorithms such as the Boosting algorithm [12, 13].
Zadeh’s paper "Fuzzy sets and information granularity" marked the birth of fuzzy set theory. Zadeh argues that the concept of information granularity exists in many fields, such as interval operations in interval theory, uncertainty in control theory, etc. are manifestations of information granularity [6, 7]. Based on fuzzy set theory, Lin et al. published a paper called "Granular computing" in 1998, detailing the model of granular computing under binary relations, which marked the birth of granular computing [8]. Granular computing is an emerging multidisciplinary intersection theory that considers granular computing as an amalgamation of fuzzy set and rough set theory [14, 15]. The granules are the most fundamental element in constructing a granular computational model. To construct various granules, people can use metrics such as similarity and distance between features as the basis of granulation. In [16], Hu et al. proposed a way of Neighborhood Granulation defined by neighborhood relations, thus enabling granularity calculation in real space. In [17], Chen et al. proposed a fuzzy granulation based on single features combined with convolutional operations to optimize the weights to obtain a good classification performance. A primary characteristic of granular computing is the ability to reconstruct input patterns at a higher level of abstraction [18, 19]. As a result, granular computing can obtain more in-depth information. Based on this characteristic, classification models incorporating granular computing have also become another research hotspot [17, 20-22]. Therefore, combining the robustness of ensemble learning with the abstract level feature mining ability of granular computing is a field worth studying.
In the field of the granular classifier, Neighborhood Granulation is a widely used granulation method [23-25]. But the Neighborhood Granulation often faces some challenges. Firstly, granules generated from sample features and neighborhood systems are often too complex and take up too many resources in the computational phase of the model [23]. Secondly, since the Neighborhood Granulation divides samples into the poles of the Euclidean space, it isn’t easy to distinguish between similar but different samples. Finally, the Neighborhood Granulation classification performance tends to be poor in the range of minimax neighborhoods [24, 25]. Therefore, the optimization of neighborhood algorithms and improving the effectiveness of granular ensemble models are worth investigating. To deal with the complex and indistinguishable characteristics of neighborhood granules, a feature selection algorithm can be used to select the required granular kernels [26, 35]. The complexity of neighborhood granules is mainly reflected in the repetitiveness and scale of granular characteristics. Filtering out irrelevant granular characteristics is a simple and intuitive way to reduce complexity. The chi-square test can be used for independence testing, which can effectively screen out irrelevant features that are independent of the label. Its computational efficiency also fits the theme of this study. To address the poor performance of granular decisions in minimax neighborhoods, the fuzzy membership function and the rough set theory are introduced in the granulation so that the features beyond the neighborhood are monotonically decreasing from 1 to 0 or vice versa. Experiments show that Fuzzy Rough Granulation performs far better than Neighborhood Granulation in minimax neighborhoods. The innovative nature innovation of the fuzzy rough granular ensemble learning is as follows: The Fuzzy Rough Granulation is proposed to improve the model’s performance in minimax neighborhoods. The introduction of a feature selection algorithm has dramatically improved the computational efficiency of the model. Combining the characteristics of granular computing and ensemble learning allows the robustness of the model to be further improved.
The rest of the article is organized as follows. Section 2 describes the feature selection algorithm and the ensemble learning in detail. A detailed description of the theory and process of Fuzzy Rough Granulation is given in Section 3. The Fuzzy Rough Granular Ensemble Learning (FRGEL) is elaborated in Section 4, focusing on the model structure and the use of the Fuzzy Rough Granulation in the model. Section 5 gives an experimental analysis to verify the model’s advantages in several aspects. All the work is summarized in Section 6.
Related works
Feature selection with chi-square
The Chi-square statistic is a non-parametric statistical method, similar to all non-parametric statistics, and the method does not lose robustness due to changes in the sample distribution [26-28]. In the calculation, the chi-square test provides not only information on the observed differences between samples but also detailed information on the significant differences between exact categories. Specifically, χ2 is calculated for all samples to discover the impact of features on the objective, which is then mapped to the relevance of the features on the decision according to the impact size [27, 28]. The formula of χ2 is shown in equation (1).
Due to the robustness of chi-square test, it is widely used in granular computing and machine learning. In [29], Xu et al. proposed a fuzzy priority discriminant made by an expert group, under which a cardinality test was used to obtain the priority vector of group decisions and finally obtained significant results. In [30, 31], the authors used the chi-square test as the basis for feature extraction. The method significantly reduced the complexity of the data, ultimately achieving better results on the target task.
Classical machine learning algorithms such as SVM and LR perform well in specific scenarios. However, with the increasing complexity of the data scenarios, individual learners can no longer meet high robustness requirements. Consequently, multi-learner systems are gaining popularity. Due to the integration of the performance of multiple learners, ensemble learning tends to perform better in the face of the complex. At the same time, ensemble learning has gradually become popular in the field of granular computing because it tends to do processing and decision-making variety of highly abstract data.
In [32], Xia et al. proposed an ensemble learning combining the Naive Bayes, the maximum entropy algorithm, and the Support Vector Machine, combining the three ensemble methods and finally obtaining better classification results in the sentiment classification problem. In [33], the authors proposed a cosine similarity learner by learning the cosine similarity metric. Making a combination of multiple cosine similar learners ensures the diversity of the multi-classifier system and effectively improves the performance. The above works propose ensemble learning methods based on various metrics data for the high abstraction of data in their research areas, respectively, and use ensemble learning to achieve better results.
Fuzzy rough granulation
Granular representation
Let the sample space be IS = (X, A), where the sample set is X = {x1, x2, . . ., x n } and the feature set is A = {a1, a2, . . ., a m }. Given a sample x ∈ X, for any feature a ∈ A, v (x, a) ∈ [0, 1] denotes the value of sample x normalized over the feature a.
If we define r = s a , a ∈ A N , then r represents the similarity between samples x1 and x2 under feature a. The smaller s a ,the more significant the similarity.
After doing the computation for two samples, a fuzzy rough set F
s
x
between the samples is generated, which is defined as shown below.
Unlike the Neighborhood Granulation, the fuzzy rough affiliation function is introduced to the neighborhood discriminant stage to replace the original neighborhood discriminant function. The following section shows the construction process of the fuzzy rough affiliation function and the granular vector by example.
Traditional neighborhood algorithms assign 0 to values beyond the neighborhood size, which indicates that two samples are not adjacent to each other under a single feature; assign a value of 1 to the value less than or equal to the neighborhood threshold, which indicates that two samples are adjacent under a single feature [16]. As the traditional neighborhood algorithm has only two discriminant values, it will generate the same number of discriminant domain according to it. The discriminant formula is shown in equation (11) [23].
The general situation of the neighborhood discriminant function under the two features is shown in Fig. 1. The left figure shows the image of the discriminant function, the middle figure shows its value domain distribution, and the right figure shows the discriminant domain generated in the sample space for the two-dimensional sample neighborhood discriminant function. It can be seen that the neighborhood discriminant function divides a square discriminant domain around the sample.
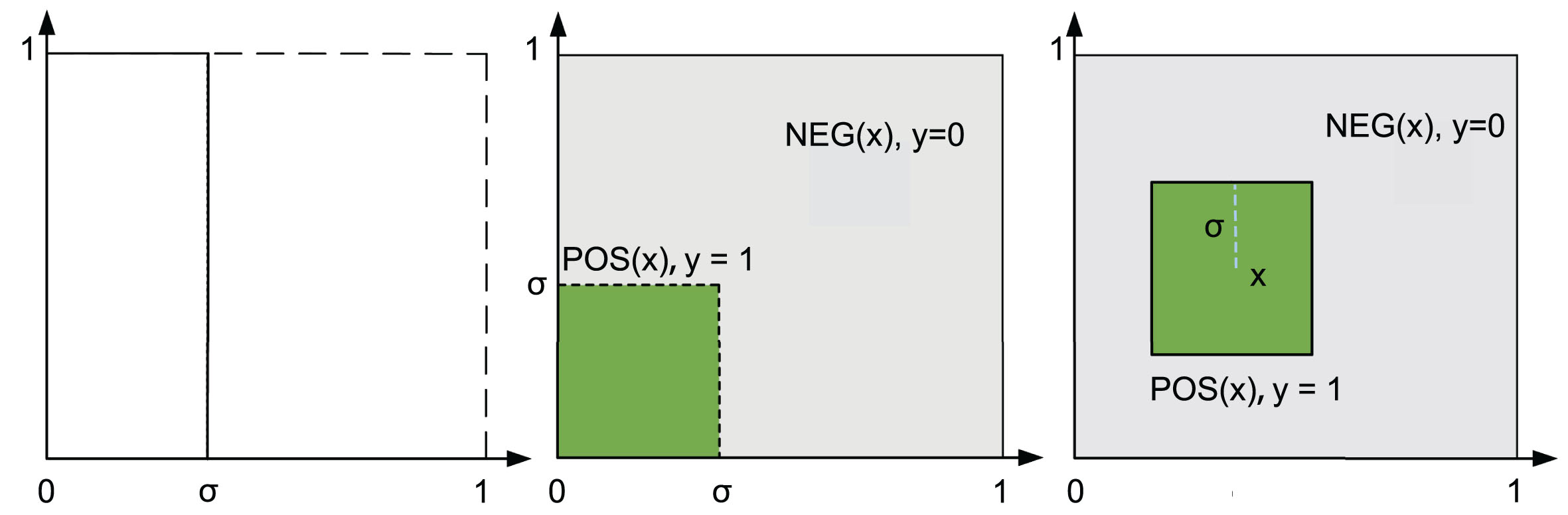
Neighborhood discriminant function.
Since the discriminant function will only produce discrete values of 0 and 1, the samples will be rigidly partitioned into two interval levels under a single feature. Suppose there is a sample set X = {x1, x2} in the sample space IS and the feature set is A = {a1, a2, a3}, where x1 = [0.2, 0.5, 0.7] and x2 = [0.4, 0.6, 0.4]. According to
Manhattan distances for the sample
Let the neighborhood parameter σ = 0.2, and according to
Neighborhood granular vectors
According to Table 2, it is easy to know that since 0.2 is chosen as the neighborhood discriminant parameter, the granulation results of the two samples for feature a3 are distributed to the poles of the interval. It is then possible to distinguish samples x1 and x2 based on the granular kernel r3 and the granular kernel r4. a feature that makes the Neighborhood Granulation perform better on linear classifiers. This property makes the Neighborhood Granulation will get better performance on linear classifiers. Correspondingly, for sample x1, the kernels {r1, r2, r3, r4, r5} are positive domain kernels and r6 are negative domain kernels. However, As the number and variety of samples are on the rise, there are many continuous and discrete values in the samples. Then it is difficult to satisfy the diversity by neighborhood division alone. This is because when the values under a certain feature are clustered in a certain interval, it can lead to difficulty in picking the appropriate neighborhood parameters to discriminate these values. If the neighborhood parameters are chosen to be minor, the diversity in the large interval is ignored, and vice versa.
Therefore, a new discriminant method is needed to preserve the neighborhood system’s properties while keeping the values outside the neighborhood from being rigidly classified to zero. Here the fuzzy rough slope affiliation function is introduced to discriminate the points outside the neighborhood. The points at the neighborhood boundary and inside are classified as 1. The decreasing slope affiliation function judges the points outside the neighborhood to the sample space boundary. When σ > 0, a line through (σ, 1) and (1, 0) is used as the basis for judgment. The discriminant is shown in Equation (12). The unidirectional fuzzy rough affiliation function is shown in Fig. 4.
According to Fig. 2, a smaller neighborhood can be chosen because of the monotonically decreasing nature of the value of the affiliation function outside the neighborhood. This way, it is possible to preserve the properties within the neighborhood and assign different values to objects beyond the scope of the neighborhood. Then, according to the properties within the neighborhood, the discriminative domain can be categorized into three parts, which are the positive domain belonging to the neighborhood, the boundary domain outside the neighborhood to the boundary of the sample space, and the boundary of the sample space, i.e., the negative boundary. In other words, the fuzzy rough affiliation function divides the neighborhood discriminant domain from the original fuzzy positive and negative domains into positive, boundary, and negative domains with rough properties. Where the values in the positive domain are considered to be perfectly similar, the values in the boundary domain are considered to have different degrees of similarity, and the values in the negative boundary are considered entirely dissimilar [16]. For example, x2 and x3 in the right figure, are both in the boundary domain of the sample x and have affiliations of 0.8 and 0.7, respectively.
Let the neighborhood parameter σ = 0.1, and according to

The unidirectional fuzzy rough membership function.
Unidirectional fuzzy rough grain vectors
However, it is not enough to introduce only a unidirectional affiliation function. As the values of the neighborhood parameters increase, the gradient of the affiliation function derived from the boundary points also becomes larger. This means that the affiliation function becomes steeper and steeper. As shown in Fig. 3, when the neighborhood parameters are increased to within the huge point region, the values within the huge neighborhood will change too fast due to the excessive gradient of the affiliation function. Let the σ = 0.8, and according to
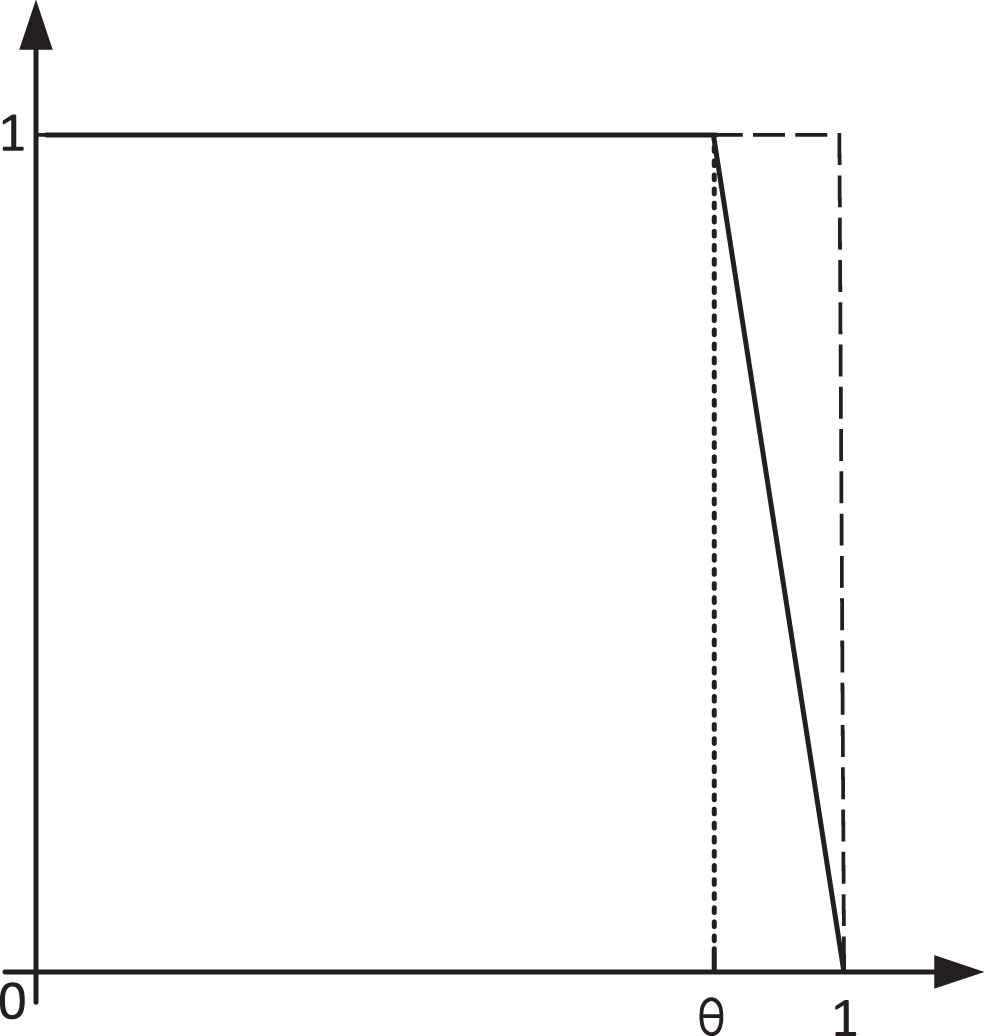
Decreasing fuzzy rough discriminant function.
Unidirectional fuzzy rough grain vectors in the extreme area
As can be seen from Table 4, the unidirectional affiliation function degenerates into a neighborhood discriminant function when the parameters fall into a extreme area.
According to the neighborhood property, the neighborhood will divide the grain kernels with similar values into one set, and those outside the neighborhood belong to another set. Therefore, the granular kernels outside the neighborhood can be set to 1, and the granular kernels inside the neighborhood are assigned with a monotonically increasing affiliation function. The slope function is determined by the origin point (0,0) and the boundary point (σ,1). The discriminant is shown in equation (13), and the function image is shown in Fig. 4.
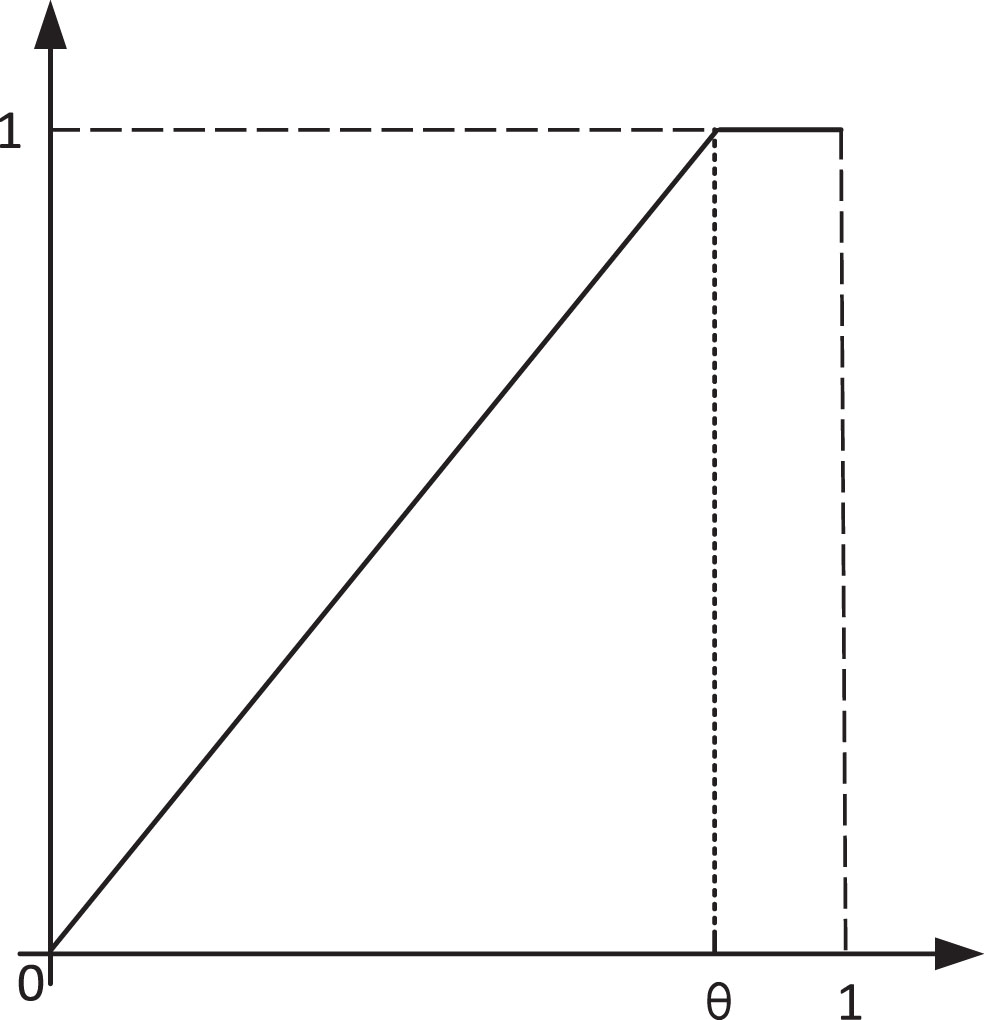
Increasing fuzzy rough discriminant function.
Let the σ = 0.8, and according to
Fuzzy rough granular vectors in the extreme area
As can be seen from Table 5, the granular kernels can still maintain diversity when the neighborhood parameters are large, which is the opposite of the results in Table 4.
According to Fig. 4, the values outside the great neighborhood are assigned to 1. The values inside the great neighborhood are assigned with an increasing affiliation function whose slope is much smaller than before. This preserves the properties of the Neighborhood Granulation while giving the kernels diversity within the neighborhood. Combining the fuzzy affiliation function of the minimax neighborhood and setting the intermittent parameter θ as the junction point between the minimax neighborhood, the final obtained fuzzy rough discriminant function is shown in Equation (14), and the function is shown in Fig. 5.
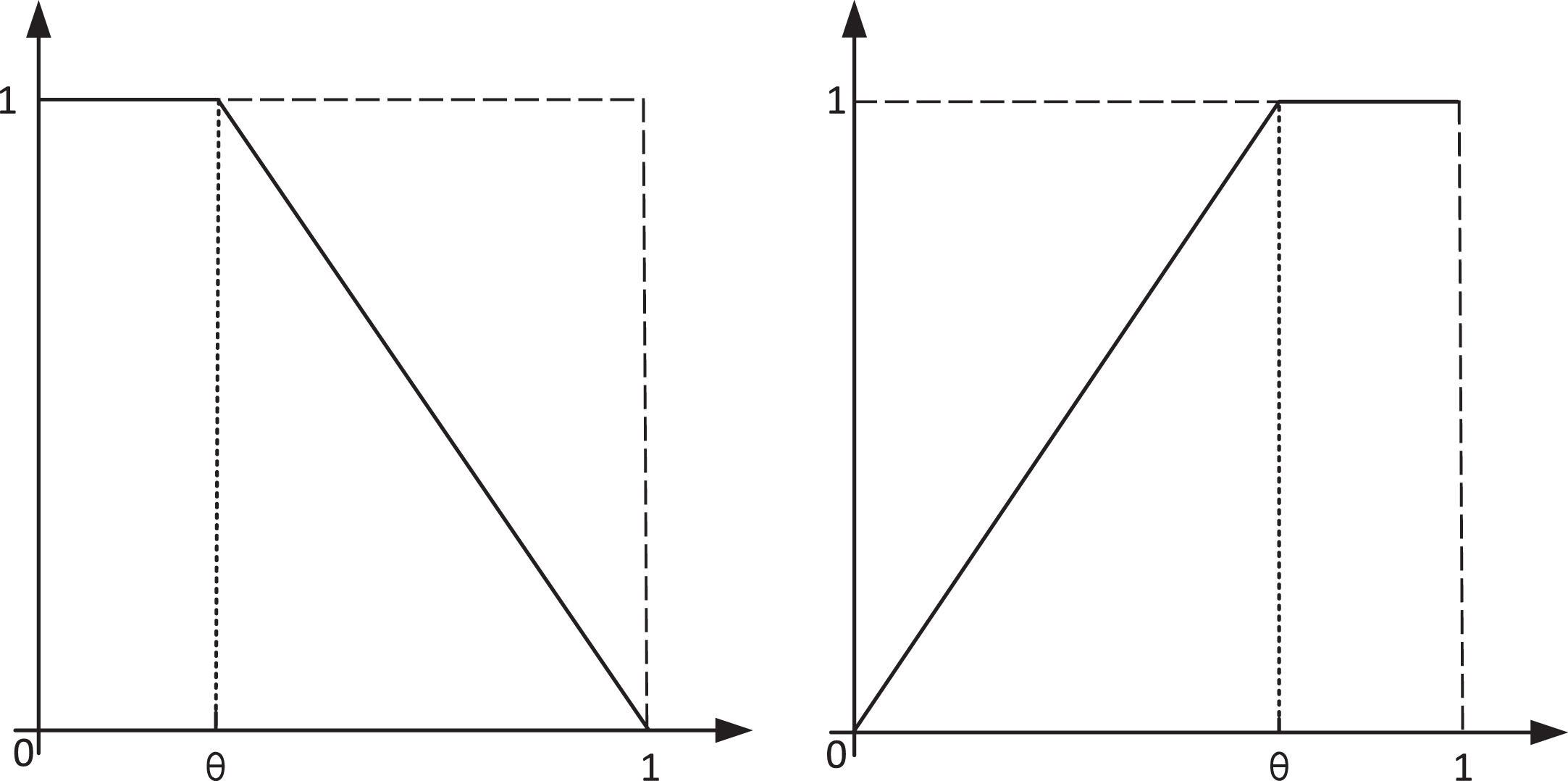
The fuzzy rough discriminant function.
Model structure
Unlike the discrete binary values that the neighborhood discriminant function will only produce, the fuzzy rough discriminant function will produce a series of mixed data. One part of the data will inherit the properties of the neighborhood discriminant function, producing a set of discrete values with small variations, while the other part will be continuous values with diversity. For the Neighborhood Granulation, linear classifiers tend to have better results because the final granular vectors are distributed across the vertices of the high-dimensional space. However, the linear classifier cannot meet the requirement of high classification accuracy for continuous values that will generate category crossover in the sample space. Therefore, for fuzzy rough granules with mixed data, both linear classifiers are needed for their powerful classification of discrete values, and nonlinear classifiers are needed to handle continuous values that tend to produce data crossover. In summary, Ensemble Learning (EL) is an excellent idea for solving the problem. A series of linear and nonlinear classifiers can be an ensemble for linear and nonlinear data, and a decision fusion mechanism can be introduced to make the final decision. The basic structure of the model is shown in Fig. 6.
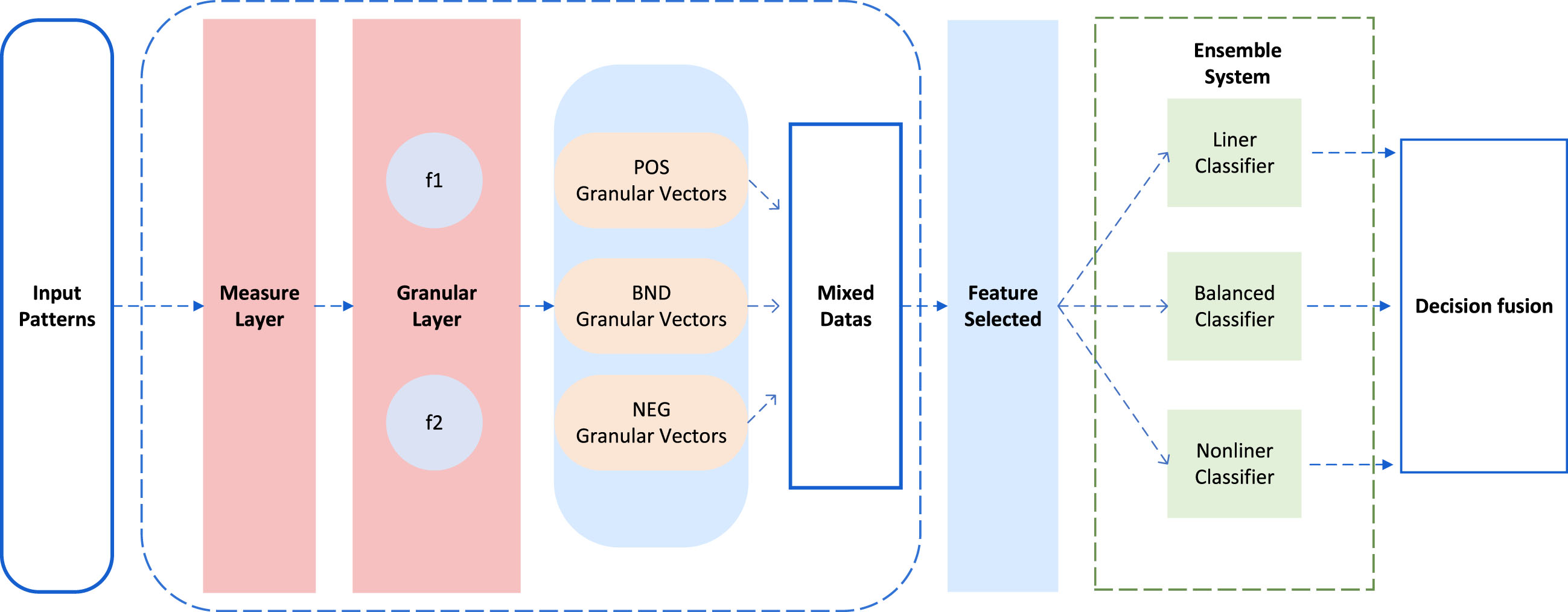
The granular ensemble learning model.
First, the normalized sample is input to the measure layer to generate the measure matrix M. The measure matrix M represents the variability of each sample. According to equation (4), the sample under a certain characteristic is greater in case of the value of the M is larger. Next, the measurement matrix is fed to the granulation layer. The granulation layer selects the appropriate discriminator for the measurement matrix based on the neighborhood parameters and intermittent parameters that enter along with the measured matrix. The output of this layer is three set vectors: the positive domain granular vectors posGs, the boundary domain granular vectors bndGs, and the negative domain granular vectors negGs. These granular vectors are stitched and combined to form fuzzy rough granular vector FRGs which contain mixed data.
After the FRGs are input to the feature selection layer, the correlation χ2 between each granular kernel and the decision is first calculated according to
For the FRGNs with mixed data, a combination of linear classifier, nonlinear classifier, and balanced classifier is proposed in this paper in the ensemble system module. Since both posGs and negGs are discrete data of 1 and 0, the samples will be distributed across the vertices of the high-dimensional space. Aiming at the characteristic, linear classifiers such as Linear Regression (LR), Support Vector Machines (SVM), etc., with better performance and faster computational efficiency, are used. On the contrary, in the bndGs, the data are all continuous values that do not contain 0 and 1. Since these continuous values are divided by neighborhood parameters, these values produce category stacking or crossover in the sample space. For these values, linear classifiers no longer obtain sufficiently good decision performance, so nonlinear classifiers such as the Gaussian Mixture Model (GMM) are used for decision discrimination. Finally, a balancer is combined, usually choosing an ensemble algorithm such as the Random Forest (RF), Boosting, etc. In this way, the classification results of linear or nonlinear classifiers can be augmented according to the powerful performance of the balancer on nonlinear data versus linear data. Finally, the decision granules output from each base learner is fused to discriminate.
In contrast to traditional Ensemble Learning (EL), Fuzzy Rough Granular Ensemble Learning (FRGEL) requires a granulation and feature selection step before construction, and the granular decisions need to be fused in the final decision.The specific flow of the algorithm is as follows.
1: X is the input to the measure layer, and M is the output according to the measure formula, then go to 2;
2: M is the input granulation layer, go to 3;
3:
4: M is input to discriminator f1 to calculate fuzzy rough set FRSs, go to 8;
5:
6: M is input to discriminator f2 to calculate fuzzy rough set FRSs, go to 8;
7:
8: FRSs are spliced to construct the fuzzy rough granular vectors FRGs, go to 9;
9: FRGs are input to the selection layer, and the granular kernel is calculated according to r and k. The new fuzzy rough granular vectors FRGNs are output, go to 10;
10:
11: Construct the i-th base classifier based on FRGNs, go to 12;
12: Construct the decision granule g base on the i-th base classifier;
13:
14: All decision granules are input to the fusion module to construct the final decision d, go to 15;
15: Compare the final decision d with the label y and outputting Evaluated Set;
In the construction process of FRGEL, time consumption is mainly concentrated in two parts: granulation process and integration processing. In the granulation process, since it is necessary to perform feature-level global fuzzy rough granulation on the original data, the time efficiency in this process is O (n2). Correspondingly, the space complexity at this time is also O (n2). Then, the granulated data is subjected to granule selection. Assuming that the proportion of granule selection is k, the space complexity of the particles after selection is O (kn2). Although in most cases O (kn2) is greater than O (n), after reasonable selection, the data size after granule selection will be much smaller than before. In the integration processing stage, due to parallel operation of three basic classifiers, the calculation time efficiency is determined by the basic classifier with the highest time complexity, that is, MAX {O (c) , c ∈ C}.
Experiment analysis
In this chapter, experiments adopt twenty Kaggle and UCI datasets, which the specific information of the datasets is shown in Table 6. Three experiments were implemented on the model to test the effectiveness of the algorithm.The experiment section verifies the three innovative points proposed in the first section. Section 5.1 conducted a comparative experiment between NG and FRG, which verified the effectiveness of fuzzy rough granulation in minimax neighborhoods. Section 5.2 compared the effect before and after granular selection, verifying the efficiency of the method. Section 5.3 conducted a comprehensive comparison of fuzzy rough granular ensemble learning, verifying the superiority of the model.
This section covers various comparison algorithms, including Random Forests (RF), AdaBoost [37], Bagging, HistGradientBoosting (HGB) [38], GradientBoosting (GB) [39], and XGBoost [40]. Their parameter settings are as follows. Among them, the tree of RF is constructed based on entropy, and the number of base estimators is 100; the estimator category of AdaBoost is decision tree, the learning rate is 1.0, the construction algorithm is SAMME.R, and the number of base estimators is 50; the base estimator of Bagging is a decision tree, and the number of base estimators is 10; the loss function of HGB is cross-entropy loss, the learning rate is 1.0, and the maximum number of iterations is 100 times; the loss function of GB is log loss, the learning rate is 1.0, there are 100 estimators, and the loss function is mse; XGBoost’s feature sampling ratio is 0.7, the objective function is softmax, the learning rate is 0.3, and the number of base estimators is 100. All experimental results from this chapter are achieved by ten-fold cross-validation with four decimal places retained.
Datasets
Datasets
On the basis of the above analysis and study, the effects of the fuzzy rough granulation and the neighborhood granulation on sample distribution and classification are further compared, where the sample distributions were compared on the gender, mobile and seed datasets with different neighborhood parameters.
The classification effects of the two granulation methods were compared on six datasets, such as breast cancer and mobile. The specific classification effects are shown in Table 7 and Fig. 7. where σ is the neighborhood parameter, Origin is the original data in Table 7, FRG is the fuzzy rough granular vector, and NG is the neighborhood granular vector. The experimental results are obtained by the Random Forest.
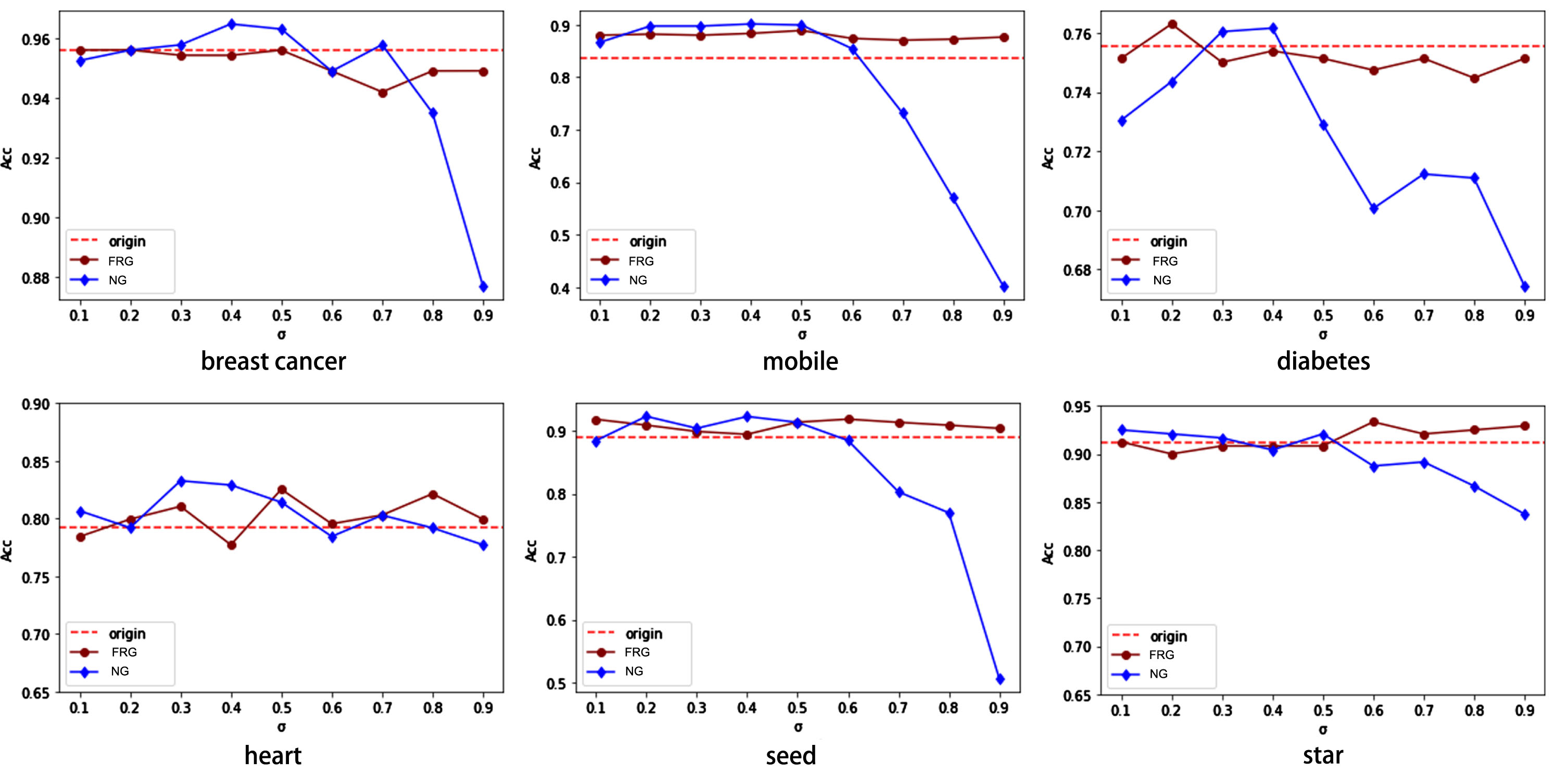
Comparison of classification effects between FRG and NG.
The result of FRG and NG
From Fig. 7 and Table 7, it can be seen that both FRG and NG have better classification effects on the optimal neighborhood than the original data, with an average improvement of about 0.025. Especially, the classification results of FRG on all neighborhood parameters are symmetrically distributed and have no significant decreasing trend. However, the classification results of NG mostly decrease with the increase of neighborhood parameters. The results revealed that the variation on the neighborhood parameters is subtly less effective on FRG, which makes FRG perform better than NG in the minimax neighborhood.
Figure 8 shows the data distribution of NG and FRG on the Gender and Mobile datasets. The left figure shows the distribution result of NG, and the right figure shows the distribution result of FRG. The decimal on the left side of the figure represents the value of the neighborhood parameter σ. As can be seen from the figure, the distribution of NG changes considerably with the expansion of the neighborhood parameters on these datasets. In contrast, FRG will maintain a similar distribution, and its distribution will not respond significantly to changes in the neighborhood parameters. Therefore, FRG are insensitive to the changes in the neighborhood parameters and have stronger robustness.

Comparison of the distribution of FRG and NG.
A major drawback of the neighborhood algorithm is that it will expand the latitude of the sample with high complexity, which will cause the algorithm to end up spending a lot of computational cost on decision-making. According to Tables 2-5, it can be seen that in the process of granulation, many refuted features are generated, such as: {r1, r2, r4, r5} in Table 2 and {r2, r4} in Table 3. According to these granular kernels, there is no way for the algorithm to calculate which one the final decision actually belongs to.
Since the distribution of the samples depends mainly on its feature set, too many granular kernels will not only increase the computational burden of the model but also interfere with the model’s decision-making. Too many features can make it difficult for the model to find the appropriate decision boundary, producing overfitting. Therefore, it is necessary to make a feature selection on the granular vectors, which is beneficial to combine the properties of the granular calculation with the advantages of the feature selection algorithm.
This experiment is based on the Chi-square algorithm, which calculates the correlation between the FRGs and the decision based on

Effect of feature selection of FRG on mobile.
Based on the above experiments, a detailed comparison of the original data as well as the NG and the FRG after feature selection was made on six datasets, such as Glass, Blood, and Leaf, respectively. The underlying model for the experiments is the FRGES model proposed in this paper. The comparison results are shown in Fig. 10 and Table 8. Among them, Table 8 shows the comparison results before and after feature selection. Figure 10 shows the effect of the two granulation methods on each neighborhood parameter.
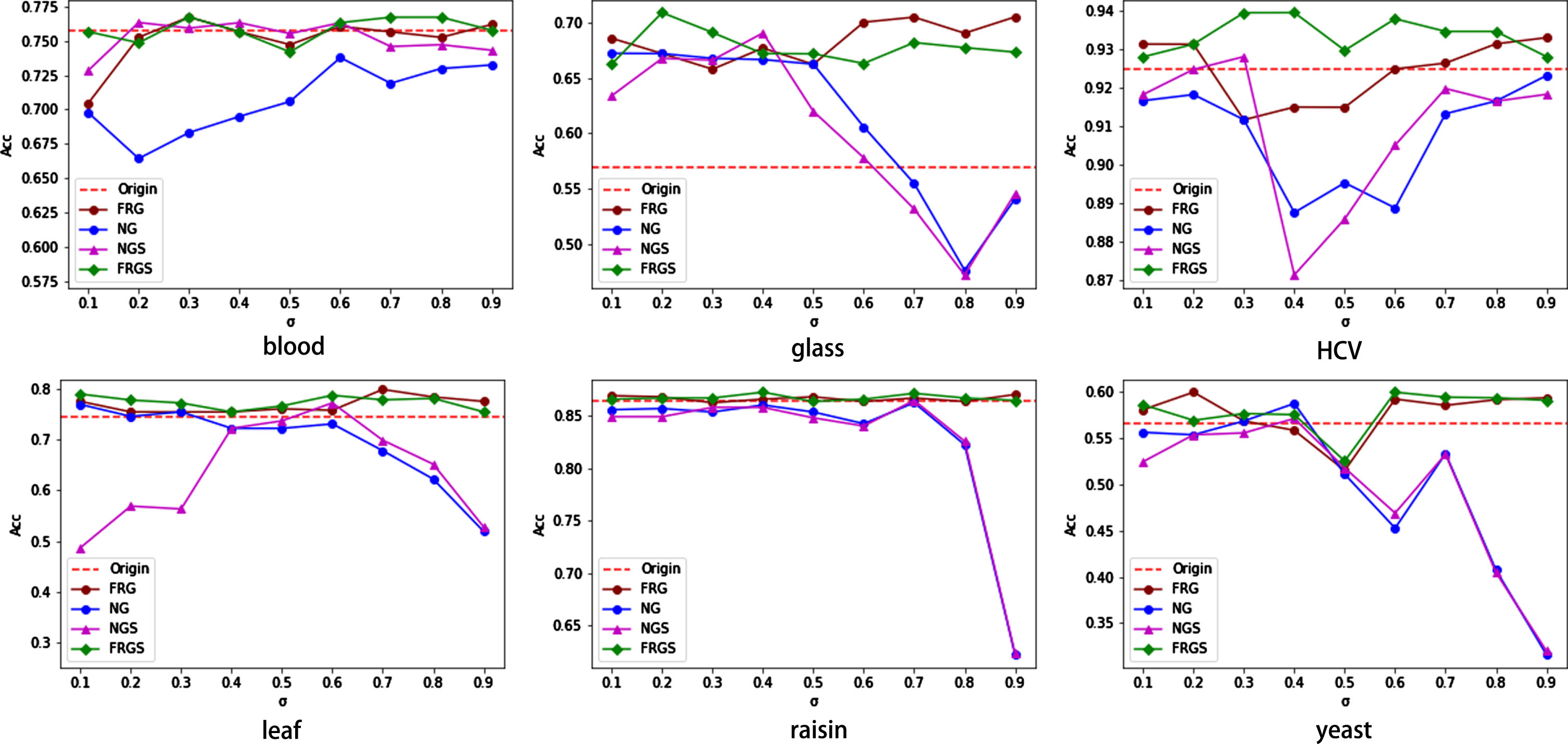
Comparison of multi-neighborhood feature selection.
In Table 8, NGS and FRGS indicate the classification accuracy (mean ± var) of the NG and the FRG after optimal feature selection, respectively, and k indicates the proportion of feature selection. Enhanced classification results of FRG demonstrate feature selection is an advisable method. Among them, the improvement was more obvious in HCV, with an improvement of about 1.47% in classification accuracy. Also, there is an improvement of about 0.5% on glass and raisin. A significant improvement of FRGS over FRG is the reduction of variance. The variance of FRGS was, on average, about 0.26% lower than FRG on the six data sets in the table. Overall, both the NG and the FRG are better than the original data, with an average of about 1.62% and 3.63% higher, respectively. Relatively, the FRG improves the classification accuracy by about 1.75% on average over the NG and also has a lower mean squared error. In summary, it can be seen that the FRG has higher classification accuracy and robustness than the NG.
The result of FRG and NG
Figure 10 shows the classification effects of the FRG and the NG before and after the feature selection exercise and compares them with the original data. It can be seen that the FRG has a clear advantage in blood, glass, HCV, and raisin datasets, and the classification results are superior to other algorithms under most neighborhood parameters. In contrast, the NG performs better in certain neighborhoods, locally obtaining a performance that exceeds that of other algorithms, as in the case of σ = 0.4 in glass and σ = [0.2,0.4] in blood. However, on most data sets, the results of the NG show a monotonically decreasing trend with increasing neighborhood parameters. So, the algorithm is sensitive to parameters, and the variation of parameters makes the classification effect of the NG less stable than that of the FRG. The FRGS has more efficient computational efficiency and more significant and stable classification results than the NG and NGS.
In this section, the classification results of the Fuzzy Rough Granular Ensemble Learning (FRGEL) are compared in detail with those of the traditional ensemble algorithm on 16 datasets. The specific algorithms compared are RF, Adaboost, Bagging, HGB, GB, and XGBoost. The specific results are shown in Table 9.
Results of FRGEL and EL on 20 datasets
Results of FRGEL and EL on 20 datasets
According to the table, it can be seen that the FRGEL algorithm obtained the optimal solution on 13 data sets. Among them, FRGEL has a more obvious lead on diabetes, heart, leaf, ILPD, and Debrecen, with a higher classification accuracy than RF, HGB, and XGBoost by about 4% to 6% on average. Moreover, on other datasets, FRGEL also obtained results similar to the highest classification accuracy. In general, the Adaboost and GB algorithms are not stable enough, and they cannot get enough correct segmentation results on the leaf and yeast datasets. And on the blood dataset, Adaboost obtained the optimal classification results with a classification accuracy of 78.73%, which is about 2.1% higher than FRGEL. Overall, the FRGEL algorithm has the highest average classification accuracy, about 3.27%, 12.52%, 3.16%, 2.73%, 7.61%, and 2.14% higher than the other algorithms, respectively. Secondly, FRGEL also has the lowest variance, about 0.0012, 0.0028, 0.0005, 0.0017, 0.0041, and 0.0014, lower than the other algorithms, respectively. In summary, the FRGEL has better generalizability, while it can reduce the variance of the accuracy score and improve the robustness of the model.
For a more detailed metric comparison, the XGBoost algorithm, which has a classification accuracy similar to FRGEL, was chosen as the control algorithm for evaluation. The two algorithms were compared in detail on five evaluation metrics, including Jaccard, F1, Precision, Recall, Accuracy, and 16 datasets. The comparison results are shown in Table 10.
Multi-indicator evaluation
As seen from Table 10, the evaluation metrics of FRGEL and XGBoost on most of the datasets, and this phenomenon is particularly evident for blood and leaf, where the metrics are, on average, about 0.05 and 0.08 higher, respectively. Meanwhile, on the glass and shill datasets, FRGEL is inferior to XGBoost in Recall scores, despite its advantages in several metrics. Overall, the average evaluation scores of FRGEL are better than those of XGBoost, with a difference of about 0.025 for each score. This indicates that the generalization and robustness of FRGEL are better than that of XGBoost.
Compared with the classical ensemble algorithm, FRGEL extends the abstract properties of the samples so that the samples are no longer monotonically related to each other as 0 and 1. The abstract relationship between samples is used as the basis for decision-making, making it easier for the classifier to identify the abstract features of the samples and therefore improves the classifier’s performance.
This paper presents a new granulation method, which is in line with the idea of neighborhood granulation and also introduces the slope affiliation function with the feature selection technique based on cardinality verification to construct FRGs. The FRG extends the abstract attributes and enables the model to make more effective decisions based on higher-level abstract features. Based on the characteristics of mixed data, this granulation method is combined with ensemble learning to construct the FRGEL. Next, the model is analyzed experimentally. First, the feasibility and superiority of FRG in the minimax neighborhoods are explored. Compared with NG, the FRG’s classification performance and computational efficiency significantly improve. Finally, a comprehensive comparison is made between the FRGEL and classical EL algorithms in terms of various metrics. The results show that the FRGEL has better generalization performance and robustness. In future work, we will focus on exploring the application ability of this method in the field of image and graph data, such as feature enhancement of images, node feature enhancement, etc. Secondly, it is also worth exploring the application of fuzzy rough granulation in various models.