
Abstract
Similarity, correlation and association measures play an important role in statistics, information retrieval, data mining and data science, classification and machine learning, recommender systems and decision-making. They have numerous applications in ecology, social and behavioral sciences, biology and bioinformatics, social network and time series analysis, image and natural language processing. Often the measures with the same name introduced on different domains have different properties, and the measures with the same properties have different names. To unify analysis of measures defined on different domains, this paper considers these measures as functions defined on universal domain and satisfying some sets of properties. The general properties of similarity functions (SF) and dissimilarity functions (DF) under the joint name of resemblance functions (RF) studied on universal domain and illustrated by examples on specific domains. The known and the new methods of construction of similarity measures are considered. This paper discusses the following aspects of RF: relationship with fuzzy (valued) relations, T-transitivity and triangle inequality, Minkowski distance and data transformation, cosine SF, RF on domains with involution (negation), aggregation and transformations of RF, visualization of RF. The paper considers also the lattice of RF, composition and min-transitive transformations of SF (fuzzy proximity relations), applications to hierarchical clustering and non-probabilistic entropy of RF. In addition, the paper proposes the method of construction of correlation functions (association measures) using SF. Pearson correlation and Yule’s Q association coefficients obtained as particular cases of the general method. One can use the paper as a survey of works on similarity and dissimilarity measures on specific domains, as a guide for constructing new similarity and correlation measures, as a base for the study of mathematical properties of resemblance functions on universal and specific domains, and also as a part of the course on Data Science.
Keywords
Introduction
Since many decades the number of works on measures of similarity, resemblance, correlation, association, relationship, interestingness, comparison etc. has been dramatically increased [3, 68–71]. These measures play an important role in statistics, information retrieval, data mining and data science, classification and machine learning, recommender systems and decision-making. They have numerous applications in ecology, social and behavioral sciences, biology and bioinformatics, social network and time series analysis, image and natural language processing. Although similarity and association (correlation) measures often used for different tasks, for example for data classification [29, 63] and for analysis of relationships between variables [27, 57], in previous years they are often considered together as descriptive measures of relationship [27, 58].
There are several mutually related approaches to analysis of similarity and association measures:
Often the similarity, correlation or association measures introduced on different domains have the same name but different properties, and the measures with the same properties have different names. To avoid this terminological confusion existing in literature and to unify analysis of measures defined on different domains, this paper considers these measures as functions defined on universal domain and satisfying simple sets of properties. The general properties and methods of construction of such functions studied on universal domain and illustrated on specific domains. This paper uses a normative approach to analysis of similarity and association measures. Such approach was used in [12–14] for constructing association (correlation) measures by means of similarity measures when both types of measures were considered as functions satisfying some sets of properties. As a particular case of the general methods of construction of association measures from similarity measures proposed in [12, 15] one can obtain the Pearson’s product moment correlation coefficient. These results show an importance of similarity measures not only for analysis of similarity in data, but also for constructing measures of more sophisticated associations of data. For this reason, this paper studies in detail general concepts related with similarity measures that can serve as a part of the general theory of similarity, correlation and association measures.
The paper considers similarity measures as symmetric and reflexive similarity functions taking values in the interval [0, 1]. Such functions have been considered in the theory of fuzzy (valued) relations initiated by Lotfi Zadeh [1, 2] and later studied in many works, see for example [4, 69]. For this reason, some terminology, notations and results of valued relations used here for similarity functions. Generally, one can consider similarity functions as fuzzy (valued) proximity relations [36] and vice versa but there are some differences between them.
Fuzzy relations appeared as a generalization of crisp, non-fuzzy relations, and for them the property of transitivity is very important [2, 65]. Zadeh introduced [2] similarity relations as symmetric, reflexive and max-min transitive functions generalizing equivalence relations. The concept of equivalence relation plays a significant role in mathematics and applications. Such relation defines a partition of the relations domain on equivalence classes. Fuzzy similarity relation defines a hierarchy of partitions of the domain on equivalence classes, and a hierarchical clustering of a finite set can be considered as a transformation of the proximity relation given on this set into a similarity relation [7, 65]. Generally, the T-transitivity of fuzzy relations is studied [21, 36], where T is a t-norm [47].
The paper considers similarity functions defined on a universal domain as models of similarity measures defined on specific domains. For example, on the set of binary vectors with n dichotomous (Yes/No or 1/0) attribute values, dozens of similarity measures are introduced [5, 49]. Such measures are usually not max-min transitive [30]. For similarity measures (SM) on some specific domain, the following problems are important: the selection of SM suitable for considered task, construction of a new SM, comparison of SM, possible transformations of SM, visualization of SM etc.
The paper discusses similarity functions (SF) and dissimilarity functions (DF) easily obtained one from another. Generally, it is a reason to consider only similarity functions [49] but these two functions have different interpretations and methods of construction. Therefore, both considered here together under the joint name resemblance functions (RF) [5].
The paper studies the general properties of RF defined on universal domain and methods of their construction. Some results discussed in this paper are new, some introduced as extensions of properties and methods considered in different works on fuzzy relations and on similarity measures for specific domains [4, 65 etc.]. The paper surveys some important works studying the properties of RF.
The paper considers SF as a particular case of an association function that can have negative values. SF used also for construction of correlation functions (measures), see Section 13 and [13].
The paper has the following structure. Section 2 considers some popular domains of SF. Section 3 defines the main properties of SF, DF and RF and gives examples of these functions. Sections 4 and 5 compare RF with T-transitive fuzzy relations. Section 6 studies the methods of construction of DF by Minkowski distance and data transformation. Section 7 considers RF on domains with ordering and involution (negation). Section 8 studies transformations and aggregation of RF. Section 9 considers visualization of SF on 2 × 2 tables. Sections 10 and 11 describe the lattice of RF and non-probabilistic entropy of RF. Section 12 focuses on composition and min-transitive transformations of fuzzy relations with application to hierarchical clustering. Section 13 considers the method of constructing correlation functions using RF. Section 14 discusses related works and conclusions.
Similarity measures on universal set and on specific domains
The large number of measures introduced for measuring similarity, correlation or association between binary vectors, between measurements or observations of variables, between time series, between fuzzy sets etc. Often these measures use similar formulas with similar properties and this is a reason to consider these measures generally as functions defined on a universal domain. Such general approach to analysis of similarity measures can simplify the transfer of results obtained for such measures on one domain (for one type of data) on another domain (for another type of data). Other advantages in consideration of measures as functions satisfying some properties are the following. It gives possibility to analyze relationships between different types of functions describing measures, and to formulate the problem of development of general methods of construction of functions satisfying given properties [13]. Using these methods one can introduce new measures on specific domains without disadvantages or drawbacks of measures used before.
In this paper, similarity measures are considered as functions S : Ω × Ω → [0, 1] defined on a universal domain Ω, and taking values in the interval of real values [0,1] such that for any elements (objects) x and y in Ω the reasonable properties of symmetry: S (x, y) = S (y, x), and reflexivity: S (x, x) =1, are fulfilled. The first property says that if we compare x with y and y with x the similarity between them will be the same. The second means that the similarity of any element x with itself is maximal. Note that although the class of similarity functions can serve as a model of large number of similarity measures for different applications there is possible to consider the measures of relationship or association that do not satisfy these simple properties. For example, the measure of inclusion of one set in another is reflexive but not symmetric. Correlation coefficient is symmetric and reflexive but takes values in interval [–1,1], see Section 13. One can use the number of messages between the nodes of some social network as a measure of relationships between them. Such measure will not be reflexive because some nodes will not send messages to itself; the number of messages between two nodes in both directions can be different, i.e. non-symmetric; and the number of messages can have values greater than one. In some applications, it is reasonable to transform relationship measures into similarity functions by symmetrization, normalization and other transformations. However, these measures can be studied also as special classes of association functions [5, 61].
This paper considers similarity measures as functions defined on universal set Ω. The properties of these functions can be easily extended on specific domain. On such domains, these functions can have additional properties related with the structure of data from this domain. Below there are the examples of some popular specific domains Ω:
the set of membership or probability values Ω = [0, 1]; the set of real values Ω = R; the set of nonnegative real values Ω = R+; the rating scale Ω ={ 1, 2, 3, 4, 5 }; the rating scale with linguistic labels, e.g. Ω = {very bad, bad, not good not bad, good, very good}.
The set of n-tuples
In this paper, special attention will be given to similarity functions defined on the set Ω of n-tuples x = (x1, …, x n ), such that for all i = 1, …, n, the elements x i take values in some set L. Depending on application, L can be the set of binary values {0,1}, the interval [0,1], the set of real values, the set of nonnegative real values, a rating scale etc.
In different applications, the n-tuple x = (x1, …, x
n
) can have the following interpretations:
the vector of n attribute values of the object x; the results of n measurements (observations) of the variable x for n sampling units; the time series values ordered in time with a fixed step between time points; the ranking of n objects such that all x
i
obtain different values from the set of ranks {1, …, n}; the ranking of n objects such that all values x
i
in x are unique; the rating profile of a user that evaluates n items in a rating scale, e.g. in {1,2,3,4,5}; the rating utility profile such that x
i
is the real valued utility of the rating of the item i; the membership values (in [0,1]) of n elements of discrete fuzzy set; the finite probabilistic distribution such that
Generally, it is possible to consider n-tuples where x i are the sets of membership values of element i in intuitionistic, hesitant and other fuzzy sets.
In many cases, the measure defined on the set of n-tuples with one interpretation can be used on the set of n-tuples with another interpretation. For example, the Pearson’s product moment correlation coefficient initially introduced as a measure of correlation of two variables given by n measurements for n units of a sample or a population often used as a measure of similarity or correlation between vectors, time series, rating profiles etc. Note that sometimes a measure having good interpretation on one type of data can be misleading or can have drawbacks when it is used for another type of data due to specific properties of the new domain. For example, the Pearson correlation coefficient can be misleading on the set of time series or on the set of bipolar rating profiles [16, 18].
Binary n-tuples and 2×2 tables
As a special case of the set of n-tuples the paper considers the set Ω of all binary n-tuples x = (x1, …, x
n
), x
i
∈ {0, 1}, i = 1, …, n, of the length n > 1. An n-tuple x represents the object x described by n binary features, attributes or properties such that x
k
= 1 if the object x possesses the attribute k, and x
k
= 0 in the opposite case. Denote by U the set of all n attributes. For two objects x = (x1, …, x
n
) and y = (y1, …, y
n
) denote by X and Y the sets of attributes possessed by x and y, respectively.
Another source for binary n-tuples are dichotomous (Yes/No) variables x and y measured for n sampling units. For example, the values 1 and 0 of x k can denote presence or absence of lung cancer in k-th patient, respectively, and y k will have values 1 or 0 if this patient smokes or does not, respectively. In this case, X is the set of patients with lung cancer and Y is the set of smoking patients.
The first type of data appears in classification tasks and dozens of similarity measures for such data have been introduced [29, 63]. The second type of data appears usually in statistics where different association measures between variables defined [27]. Latterly both types of data are considered together because presented by 2 × 2 tables and both types of measures constructed similarly [28, 42]. Below, for definiteness, we will refer to the first interpretation of data.
Generally, one can use similarity or association measures on 2 × 2 tables as measures of similarity or association between any subsets X and Y of finite universal set.
The following four numbers are calculated for two binary n-tuples x = (x1, …, x n ) and y = (y1, …, y n ):
a = |X ∩ Y|, the number of attributes k possessed both by x and y (such that x k = 1, y k = 1);
It fulfills: a + b + c + d = n, |U| = n, |X| = a + b, |Y| = a + c,
The numbers a and d give the numbers of positive and negative matches, respectively [29, 63]. Usually the numbers a, b, c, d are organized as a 2×2 table called a contingency table, see Table 1.
2×2 table
2×2 table
The following sections consider some popular similarity measures on 2×2 tables for illustrating general properties of similarity measures, the methods of their transformation and construction.
Similarity functions
Let Ω be a universal set. A function S : Ω × Ω → [0, 1] is called a similarity function on Ω if for all x, y in Ω it is symmetric:
and reflexive:
A similarity function S is strictly reflexive if
A similarity function S is 0-normal on Ω if
Such elements x and y will be called 0-opposite in Ω for function S.
This paper uses for similarity functions the terminology and notations from the theory of fuzzy (or valued) relations where the similarity function called a symmetric and reflexive fuzzy relation [2], a fuzzy similitude relation [4] or a valued proximity (tolerance) relation [36]. The properties of symmetry and reflexivity are considered in many works, e.g. in [5, 44]. In [44] it is considered symmetric and reflexive E-coefficient that satisfies also the transitivity property: if S (x, y) =1 and S (y, z) =1 then S (x, z) =1.
Generally, we use the term similarity function when defined on a universal set Ω that can represent some specific domain, e.g. the set of all real valued n-tuples. For specific domain Ω, the similarity function can have some additional properties depending on the properties of Ω.
If a similarity function is used for measuring similarity between objects of a specific domain Ω then it can serve as a similarity measure. Note that the inverse assertion is not always true. The term similarity measure sometimes used for functions which are not reflexive or not symmetric or take values out of the interval [0,1]. Such functions will not be similarity functions. On the contrary, a “correlation measure” satisfying symmetry, reflexivity and taking values in [0,1] will be a similarity function [71].
When the values of similarity function (or similarity measure) calculated between objects of some finite set X then this function defines a valued proximity relation between the elements of the set X [36]. In this case, if not misleading, we denote the set X by Ω.
Dissimilarity functions
A function D : Ω × Ω → [0, 1] satisfying for all x, y in Ω the properties of symmetry:
and irreflexivity:
will be called a dissimilarity function on Ω. A dissimilarity function D is strictly irreflexive if it is fulfilled: D (x, y) >0 for all x, y in Ω such that x ≠ y. A dissimilarity function D is 1-normal on Ω if for some x, y in Ω it fulfills: D (x, y) =1. Such elements x and y will be called 1-opposite in Ω for the function D.
Dissimilarity functions are dual to similarity functions. These functions will be called complementary one to another if for all x, y in Ω it fulfills:
From Equation (3) it follows for all x, y in Ω:
A similarity function is strictly reflexive or 0-normal if and only if its complementary dissimilarity function is strictly irreflexive or 1-normal, respectively.
Due to duality of similarity and dissimilarity functions one can consider only one of these functions, but these measures have different interpretations and methods of construction. For this reason, it is useful to consider these functions together as resemblance functions.
A resemblance function is a symmetric function R : Ω × Ω → [0, 1] that is reflexive or irreflexive. Two resemblance functions R1 and R2 are called resemblance functions of the same type if both are reflexive or both are irreflexive.
Denote P (S) and P (D) the sets of all similarity and all dissimilarity functions, respectively, defined on the set Ω. Then P (R) = P (S) ∪ P (D) is the set of all resemblance functions defined on Ω. Section 10 considers the lattice of resemblance functions.
Examples of resemblance functions
Resemblance functions on 2 × 2 tables
Consider some popular similarity measures on 2×2 tables [28, 42] together with their complementary dissimilarity functions. Such measures usually used in classification of objects described by n binary attributes or features. These measures can be used also for measuring similarity and dissimilarity between sets and between n measurements of two dichotomous variables.
In this paper to simplify notations, the same similarity measures S on 2 × 2 tables denoted as:
functions S (x, y), where x = (x1, …, x
n
) and y = (y1, …, y
n
) are n-tuples with binary components, functions S (X, Y), where X and Y are the sets of attributes possessed by n-tuples x and y, functions S (a, b, c, d) with elements of 2 × 2 tables defined by x and y, such that a + b + c + d = n, functions S (a, d), when it is possible, due to b + c = n - (a + d). Such representation is used in visualization of these measures as functions of arguments a and d in Section 9. See also [17].
To avoid confusions, the reader can use different notations for these functions.
Jaccard:
Simple Matching:
The complementary dissimilarity function for Simple Matching has also another form:
Hence, the Simple Matching similarity measure is nothing else but the complementary measure of the normalized Manhattan distance.
Ochiai (cosine):
Ochiai (cosine) similarity measure is the complementary similarity function of the dissimilarity function obtained from the Euclidean distance between normalized n-tuples, see the next section and Section 6.
Note, that when the denominator in the formulas of Jaccard and Ochiai similarity measures equals to 0 due to the reflexivity of similarity functions they can be evaluated as 1, see Section 9.2.
The properties of similarity functions as functions S (X, Y) of the sets of attributes X and Y and as functions S (a, b, c, d) of parameters a, b, c, d, will have the following forms:
symmetry:
reflexivity:
strict reflexivity:
0-normality:
The Jaccard, Simple Matching and Ochiai similarity measures are strictly reflexive and 0-normal similarity functions.
It is surprising that the Russel & Rao measure mentioned in many works as a similarity measure is symmetric but not reflexive, hence it is not a similarity function:
Russel & Rao:
The popular coefficient of association:
Yule’s Q:
is a symmetric and reflexive function but it is not a similarity function because it can be negative. It is an example of correlation function (see Section 13).
Cosine similarity measure
On the set of non-negative real valued n-tuples x = (x1, …, x n ) such that x ≠ (0, …, 0), it is often used
Cosine similarity measure:
It is symmetric, reflexive and takes values in [0,1] hence it is the similarity function. It is the 0-normal similarity function: two n-tuples x and y are opposite, i.e. S (x, y) =0, if and only if they are orthogonal.
Note that on the set of real valued n-tuples cosine measure will not be a similarity function because it can be negative.
The cosine similarity function has the following complementary dissimilarity function:
defined by Euclidean distance between normalized n-tuples. Section 6 considers the general class of such dissimilarity functions.
For binary n-tuples, cosine similarity measure coincides with Ochiai similarity measure.
Non-negative n-tuples appear, for example, in text processing, when the text is represented by a vector x of n linguistic features and x i equal to the number of appearances of the i-th feature in the text [59]. In such n-tuples n can be greater than 1000.
Min-transitivity and ultrametric inequality
A similarity function S is min-transitive if for all x, y, z in Ω it is fulfilled:
For similarity functions min-transitivity is equivalent to the following condition fulfilled for all x, y, z in Ω:
The last condition means that if S is min-transitive then for any three objects x, y, z in Ω at least two of three values S (x, y), S (y, z) and S (x, z) are equal.
Zadeh introduced the property of min-transitivity under the name of max-min transitivity for fuzzy similarity relations [2].
A similarity function S is min-transitive if and only if its complementary dissimilarity function D is ultrametric, i.e. for all x, y, z in Ω it fulfills the ultrametric inequality:
An ultrametric dissimilarity function D on Ω defines a hierarchy of nested partitions of the set Ω and used in hierarchical clustering [45]. The min-transitive similarity function is the valued equivalence (similarity) relation defining hierarchy of partitions of the set Ω on equivalence classes of this relation that gives natural interpretation for these partitions [2, 65]. See the next section and Section 12.
A fuzzy relation S on the set Ω is introduced by Lotfi Zadeh [1, 2] as an extension of the characteristic function of a binary non-fuzzy relation and is defined for all x, y in Ω by its membership function μ
S
(x, y) taking values in [0,1]. The value μ
S
(x, y) denotes the grade of membership of the ordered pair (x, y) in S or the strength of the relation S between x and y. A fuzzy relation S on a finite set Ω which is symmetric, reflexive and max-min transitive, i.e.
Usually, from similarity measures, the min-transitivity is not required; for this reason, this property is not required also from similarity functions. Moreover, as De Baets et al. [30] showed, the wide class of parametric similarity measures does not contain min-transitive measures, see Section 5.5.
Non-fuzzy equivalence relations
A binary (given by pairs of objects) non-fuzzy (crisp) proximity relationR on a set Ω is defined as a set of ordered pairs: R ⊆ {(x, y) |x, y ∈ Ω}, satisfying for all x, y in Ω the properties:
The proximity relation R on Ω can be represented by its characteristic (indicator) function:
A non-fuzzy equivalence relationR on Ω is a transitive proximity relation, i.e. for all x, y, z in Ω it is fulfilled:
This transitivity condition is equivalent to the min-transitivity Equation (5) of the similarity function S (x, y) =
T-transitivity and triangle inequality
Distance functions and metrics
A symmetric and irreflexive function d (x, y) taking values in the set of non-negative real values is referred to as a distance function. A pseudo-metric is a dissimilarity or distance function satisfying for all x, y, z in Ω the triangle inequality:
A strictly irreflexive pseudo-metric is called a metric.
Note that the ultrametric inequality is stronger than the triangle inequality.
If d is a distance function and g is a non-negative non-increasing function such that g (0) =1 then S (x, y) = g (d (x, y)) is the similarity function. Below are examples of similarity and complementary dissimilarity functions obtained from distance function d:
If for all x, y in Ω it is fulfilled d (x, y) ≤ M for some positive number M, then these functions:
are complementary dissimilarity and similarity functions. If d (x, y) = M for some x, y in Ω then S and D will be 0- and 1-normal functions, respectively.
Below there are the most popular metrics on the set Ω of real n-tuples. Denote: x = (x1, …, x n ), y = (y1, …, y n ).
Minkowski distance of order p ⩾ 1:
For p = 2 we obtain Euclidean distance:
Manhattan (taxicab) distance (for p = 1):
The book [33] gives more examples of distances.
T-transitive similarity functions
A similarity function S is T-transitive if for all x, y, z in Ω it is fulfilled:
where T is a t-norm, i.e. commutative, associative, and monotonic binary operation on [0, 1] satisfying for all a in [0,1] the boundary condition: T (a, 1) = a. Below there are examples of basic t-norms [47] defined for all a, b in [0,1]:
In this notation, min-transitive similarity function is T M -transitive.
T-transitivity and metrics
Menger [51] considered probabilistic relationE such that E (a, b) denotes the probability that a and b are equal. This function satisfies symmetry, reflexivity and property: E (a, c) ⩾ E (a, b) E (b, c). This probabilistic relation is the similarity function satisfying product-transitivity: E (a, c) ⩾ T p (E (a, b), E (b, c)). The function d (a, b) = - log(E (a, b)) is the metric.
Bezdek and Harris [21] studied different types of transitivity of symmetric and reflexive fuzzy relations. It was shown, for example, that if fuzzy relation R is T L – transitive (called max-Δtransitive) then the function D = 1 - R will be a pseudo-metric.
Transitivity of parametric families of similarity measures on 2×2 tables
T-transitivity of cardinality-based parametric similarity measures and their possible relationship with triangle inequality studied in [30]. Using the notation considered before these similarity measures on 2 × 2 tables represented as follows:
where K3 > K4 ⩾ 0 and K i , i = 1, 2, are positive real parameters.
The paper [30] notes that this family does not contain min-transitive similarity measures. It is proved that a similarity measure from this family is T L -transitive if and only if K3 ⩾ max(K1, K2), where T L -transitivity is given in the form: S (x, z) ⩾ S (x, y) + S (y, z) -1. Its complementary dissimilarity measure is pseudo-metric satisfying triangle inequality.
[30] proved also that a similarity measure from this family is T P -transitive if and only if
It should be noted that for the consistent similarity measures on 2 × 2 tables it should be S (x, y) =0 if x i ≠ y i for all i = 1, …, n, i.e. if x and y have neither positive (a = 0) nor negative (d = 0) matches. For such similarity measures, it should be K4 = 0, in Equation (8), hence Equation (9) does not fulfill, and consistent similarity measures cannot be T P -transitive.
It is surprising that the consistent similarity measures on 2 × 2 tables from the parametric family Equation (8) including most of popular similarity measures can be neither min-transitive nor T P -transitive. If such similarity measures are T L -transitive then they are complementary to pseudo-metrics.
Gower and Legendre [40] considered the following parametric families of similarity measures for 2 × 2 tables:
where θ > 0 that will be also referred to as (a)-family and (a + d)-family of similarity measures, respectively. Batyrshin et al. [17] introduced the following parametric (a + pd)-family of similarity measures:
where θ > 0 and p belongs to [0,1]. This formula gives (a)-family T θ when p = 0 and (a + d)-family S θ when p = 1.
These three parametric measures belong to the class of parametric measures Equation (8), hence these measures do not satisfy the min-transitivity and T P -transitivity properties.
For consistent similarity measures Equation (8) with K4 = 0 dividing nominator and denominator of Equation (8) on positive value K1 we obtain:
where p2 = K2/K1 and p3 = K3/K1. The condition of T L -transitivity will have the form: p3 ⩾ max(1, p2). Thus, T L -transitive similarity measures from the families of similarity measures T θ , S θ and Sa+pd are characterized by condition: θ ⩾ 1.
Data transformation
Transformations on universal domain
Consider the general method of construction of resemblance functions based on data transformation.
is the resemblance function R : Ω × Ω → [0, 1] on the set Ω of the same type as R1.
The proof is straightforward.
A typical example of data transformation F is a data normalization. In this case, Proposition 1 says: normalize data and apply some resemblance function to normalized data. However, for specific domains Ω and Ω1 the transformation F can have a variety of forms. For example, Sections 6.3–6.7 introduce p-transformation of data applied together with Minkowski distance of order p for constructing dissimilarity functions on a domain Ω.
Transformations of binary n-tuples
The method of construction of similarity measures on 2 × 2 tables can be represented in a general form as the composition of two mappings: F : Ω × Ω → Ω1 and F1 : Ω1 → [0, 1], such that
where Ω is the set of binary n-tuples, Ω1 is the set of non-negative integer 4-tuples (a, b, c, d) such that a + b + c + d = n and F1 satisfies the properties: F1 (a, 0, 0, d) =1 (for reflexivity), and F1 (a, b, c, d) = F1 (a, c, b, d) (for symmetry). Here F1 (a, b, c, d) denotes F1 ((a, b, c, d)). The transformation F is given by a 2 × 2 table, see Section 2.2, transforming the pair of n-tuples (x, y) into 4-tuple (a, b, c, d). The transformation F1 is defined by a specific similarity measure transforming four values a, b, c, d into a similarity value from [0,1].
P-transformations in constructing dissimilarity functions by Minkowski distance of order p
Consider data transformations partially based on results of [12]. A real valued n-tuple z = (z1, …, z n ) satisfying for some real p ⩾ 1 the property:
is called p-normalized (or p-standardized). Denote
A function
is called p-transformation (p-normalization or p-standardization) of elements of Ω.
is the dissimilarity function (metric) on Ω.
From Proposition 2 it follows that the function:
is also the dissimilarity function on Ω. For Euclidean (p = 2) and Manhattan (p = 1) distances it gives the following dissimilarity functions:
The considered method of construction of dissimilarity functions uses the description of objects of the set Ω by n features (attributes, properties or measurements) obtained in two ways:
The function F is a feature function assigning to each object from Ω a n-tuple of n feature values F (x) = (F (x) 1, …, F (x)
n
). The elements of the set Ω are given by m-tuples of real values x = (x1, …, x
m
) and F (x) = (F (x) 1, …, F (x)
n
) is a transformation of m-tuple x = (x1, …, x
m
) into a real valued n-tuple F (x). Often, n = m, but generally these two numbers can be different. For example in [12, 16] the moving approximation transform replaces the sequence of m time series values by a sequence of n local trends, where n < m.
From dissimilarity function obtain complementary similarity function by: S (x, y) =1 - D (x, y).
Dissimilarity functions for non-negative n-tuples
are dissimilarity functions on Ω.
that gives for Equations (15), (16): 0 ≤ D (x, y) ≤1. The similarity and irreflexivity of D are evident ■
From Equation (16) for p = 2 we obtain that:
is a dissimilarity function. Compare it with Equation (13). For p = 1 from Equation (16) we obtain Equation (14).
is a p-transformation on Ω ∖ Ωf=0 for any p ⩾ 1.
The proof is straightforward.
This proposition together with previous propositions give a possibility to construct dozens of dissimilarity and complementary similarity functions.
For a non-negative 2-transformation F (x) from Equation (17) and
On the set Ω of non-negative n-tuples x = (x1, …, x n ) using in Equation (18)f (x) i = x i and p = 2 obtain:
that gives the cosine similarity measure:
From Equation (17) obtain the dissimilarity function Equation (4) complementary to cosine similarity measure and considered in Section 3.4.2.
Soft cosine similarity measure including similarity between features considered in [62].
P-transformations with aggregation functions
The general methods of p-normalization (p-standardization) using aggregation functions [20, 41] are considered in [12]. For example on the set Ω of n-tuples x = (x1, …, x n ) define in Equation (18):
where g (x) is an aggregation function, e.g. mean, median, maximum or minimum of n values of n-tuple x = (x1, …, x n ). For example, for arithmetic mean:
and for p = 2, Equation (18) gives the following popular transformation of data:
and Equation (13) gives the dissimilarity function:
This function used in Section 13 for constructing Pearson’s correlation coefficient [12, 15].
Similarity functions for real n-tuples
From Equation (13) for 2-normalized F (x) it follows:
Note that here cosine takes values in [– 1,1] and hence it is not a similarity function !
Resemblance functions for finite probabilistic distributions
From Propositions 3 and 5 it follows
are the dissimilarity functions.
If a 1-normalized data is non-negative, i.e.:
then one can use the following dissimilarity function obtained from Equation (19)
and for p = 2:
When x = (x1, …, x n ) and y = (y1, …, y n ) are probability distributions (1-normalized) then the function:
is called Hellinger discrimination, Matusita measure [32] or Squared-Chord distance [26]. Note that the last measure is not a dissimilarity function because it takes values in [0,2].
If x = (x1, …, x n ) and y = (y1, …, y n ) are probability distributions then the dissimilarity function Equation (20) has the following complementary similarity function:
called Bhattacharyya coefficient [3, 32] and equal to the cosine between the vectors
Resemblance functions on ordered domain
A similarity function S on a set Ω with a partial ordering ≤ is called monotone on Ω if for all x, y, z in Ω it is fulfilled:
This property considered together with min-transitivity Equation (5) of S will give very strong restrictions on possible values of S:
Dually, for a dissimilarity function the monotonicity property has the form:
The monotonicity property for distances on partially ordered set was considered in [7] and for valued relations in [36].
Involution (negation) on Ω
Consider the properties of resemblance functions related with an involution (negation, complement, reflection) operation introduced on the domain. For example, in [13] involution (reflection) is used in definition and construction of association (correlation) measures.
A function N : Ω → Ω is called an involution on Ω if for all x in Ω it fulfills:
A non-trivial involution N (which is not the identity function) such that N (x) ≠ x for some x in Ω will be called an (involutive) negation on Ω. Denote a negation on Ω also as N Ω . Generally, the terms negation and non-trivial involution one can use as interchangeable but negation is more common.
From the definition of the negation, it follows that it is a bijective mapping of Ω onto Ω and N-1 (x) = N (x) for all x in Ω.
An element x of Ω such that N (x) = x will be called a fixed point ofN in Ω and denoted by x FP . The set of all fixed points of N in Ω will be denoted FP (N, Ω). For specific domains Ω, this set can be empty, finite or infinite. Denote Ω N = Ω ∖ FP (N, Ω). This set is used in definition of association (correlation) measures [13], see also Section 13.
Negation on ordered domain
A negation N on a set Ω with a partial ordering ≤ will be called antitone if for all x, y in Ω it is fulfilled:
Examples of negations
Let Ω be the set of all n-tuples x = (x1, …, x n ) of the length n > 1, and x i , for all i = 1, …, n, takes values in some set L. Let N L be a negation on L. Define negation N Ω on Ω by: N Ω (x) = (N L (x1), …, N L (x n )). From the involutivity of N L it follows the involutivity of N Ω . If not misleading, denote the negation of n-tuples and the negation of their elements by the same letter N, i.e. N (x) = (N (x1), …, N (x n )).
If L is the set of real numbers, define N (x) = - x = (- x1, …, - x n ). n-tuple x FP = (0, …, 0) is the unique fixed point of this negation.
If L = {0, 1} then n-tuple x = (x1, …, x n ) is a vector of binary attributes or the sequence of n measurements of dichotomous variable. Define negation on Ω by: N (x) = (1 - x1, …, 1 - x n ). This negation has not fixed points and FP (N, Ω) =∅.
If L = [0, 1] and x = (x1, …, x n ) is a list of membership values (membership function) of a finite fuzzy set u = {u1, …, u n } then N (x) = (1 - x1, …, 1 - x n ) is the negation of the fuzzy set x [1]. The n-tuple x FP = (0.5, …, 0.5) is the unique fixed point of this negation. Generally, on [0,1] the involutive negation is defined as a strictly decreasing function that can differ from N (x) =1 - x [10, 67].
Let L = {1, 2, …, m} be a bipolar scale [18] with the negation N L (k) = m - k + 1, and x = (x1, …, x n ) be a rating profile of the user x evaluating n items in the rating scale L. Then this negation and corresponding negation N Ω have no fixed points if m is even. If m is odd, i.e. m = 2r + 1 for some integer r, then N L has the fixed point C = r + 1 and N Ω has the unique fixed point: x FP = (C, …, C).
On all considered above domains of n-tuples define the partial ordering as follows:
Then the considered negations will be antitone.
Consistent resemblance functions
A similarity function S on the set Ω with a negation N is non-contradictive or consistent if for all x in Ω it is fulfilled:
Dually we have for consistent dissimilarity function:
If a similarity function on the set Ω is consistent then any element of Ω is opposite to its negation.
A similarity function S cannot be consistent on Ω if negation N has a fixed point in Ω. Indeed, in this case due to reflexivity of S it should be:
Some domains Ω with a negation N having fixed points and non-consistent similarity function S can be converted to the domains with consistent similarity function S after elimination of fixed points from Ω, i.e. after replacing Ω by Ω N = Ω ∖ FP (N, Ω).
Note that the consistency of similarity functions (similarity measures) defined on 2 × 2 tables considered in Section 5.5 coincides with the consistency defined here.
Co-symmetric resemblance functions
A resemblance function R on the set Ω with negation N is called co-symmetric if
A resemblance function is co-symmetric if and only if its complementary resemblance function is also co-symmetric.
As shown in [13], a resemblance function R on the set Ω with negation N is co-symmetric if and only if it satisfies the property:
Remark
Co-symmetric metrics on the set of fuzzy sets with the fuzzy complementN considered in 1978 in [6] under the name symmetric metrics. In [9], such metrics studied on Kleene algebras. In [5], a co-symmetric resemblance measure on binary vectors called self-complementary. In [35], a co-symmetric similarity measure called a proximity measure. In [25], this property used in the definition of a restricted equivalence function. Co-symmetric similarity measures used in construction of association (correlation) measures in [13]. Furthermore, we consider the co-symmetrization of resemblance functions.
Examples of consistent and co-symmetric similarity measures on 2×2 tables
The properties of consistency and co-symmetry for similarity measures on 2×2 tables have the form:
consistency:
co-symmetry:
The last relation means that if we replace in the formula S (a, b, c, d) the variables a, b, c, d by variables d, c, b, a, respectively, we obtain the formula equivalent to S (a, b, c, d).
Any reasonable similarity function on the set of binary n-tuples x = (x1, …, x n ) should be consistent. From N (0) =1, N (1) =0, it follows: N (x i ) ≠ x i , for all i = 1, …, n, hence, any n-tuple x has nor positive (a = 0) nor negative (d = 0) matches with its negation N (x). The consistency of similarity measures on 2×2 tables is as follows:
For example, Jaccard, Simple Matching and Ochiai similarity measures are consistent
The Simple Matching similarity measure is co-symmetric but Jaccard and Ochiai similarity measures are not co-symmetric.
Transformation of negations
is a negation on Ω1.
From Proposition 7 it follows
defined for all x in Ω, is a negation on Ω.
The proof of both propositions is straightforward.
Proposition 7 generalizes the method of constructing negation on bipolar scale where N defines negation on the set of indexes of gradations of the scale and φ defines the mapping of this set on another set of indexes, or on the set of linguistic labels of the scale, or on the set of utility values [18].
Proposition 8 generalizes the method of constructing involutive negations on [0,1] proposed in [67] where the fuzzy negation N (x) =1 - x was used.
Transformations of resemblance functions
Equivalent transformations of resemblance functions
Two resemblance functions R1 and R2 of the same type defined on the set Ω called equivalent (by ordering) if for all x, y, u, v in Ω it fulfills:
It is clear that two equivalent resemblance functions should have the same type.
A continuous, strictly increasing function φ : [0, 1] → [0, 1] such that φ (0) =0 and φ (1) =1 is called an automorphism of the interval [0,1].
defined for all x, y in Ω will be a resemblance function equivalent to R. If R is 0-normal (1-normal) then R1 is 0-normal (1-normal). If R is strictly reflexive (strictly irreflexive) then R1 is strictly reflexive (strictly irreflexive).
min-transitivity, ultrametric inequality, monotonicity, co-symmetry, consistency,
then R1 also satisfies this property.
Below there are examples of simplest equivalent transformations of resemblance functions defined by the parametric family of automorphisms of [0,1] φ (x) = x k , k > 0:
Remark
Due to the limitations on the size of the paper, the proofs of all statements of propositions of this and the following sections are not included. Some proofs are straightforward, some of them and other types of transformations of resemblance functions can be found in [5, 50].
0-(1-)normality transformations
is a 0-normal similarity function. If f is a bijection then S and S1 are equivalent.
Such function f called 0-normality transformation. Below there is the linear 0-normality transformation:
Dually, we have
is a 1-normal dissimilarity function. If g is a bijection then D and D1 are equivalent.
Such function g called 1-normality transformation. Below there is the linear 1-normality transformation:
Negation based transformation
defined for all x, y in Ω, will the resemblance function of the same type as R. If R is 0-normal (1-normal) then R1 is 0-normal (1-normal). If R is consistent then R1 is consistent. If R is co-symmetric then R1 = R.
Aggregation of resemblance functions
A function g (a1, …, a m ) of m arguments a i ∈ [0, 1], i = 1, …, m, taking values in [0,1], satisfying the properties: g (0, …, 0) =0, g (1, …, 1) =1, and strictly increasing in each variable is called an aggregation function [41]. It will be called conjunctive if g (a1, …, a m ) =0 when a i = 0, for some i = 1, …, m, and g will be called disjunctive if g (a1, …, a m ) =1 when a i = 1, for some i = 1, …, m.
defined for all x, y in Ω is a resemblance function of the same type satisfying the following properties:
If all R
i
are strictly reflexive (strictly irreflexive) then R is strictly reflexive (strictly irreflexive). If all R
i
are 0-normal similarity functions such that for some x and y in Ω it is fulfilled R
i
(x, y) =0 for all i = 1, …, m, then R is 0-normal. If all R
i
are 1-normal dissimilarity functions such that for some x and y in Ω it is fulfilled R
i
(x, y) =1 for all i = 1, …, m, then R is 1-normal. If all R
i
are similarity functions, one of R
i
is 0-normal and g is conjunctive then R is 0-normal. If all R
i
are dissimilarity functions, one of R
i
is 1-normal and g is disjunctive then R is 1-normal. If Ω has a negation and all R
i
are consistent then R is consistent. If Ω has a negation and all R
i
are co-symmetric then R is co-symmetric.
The proof of the proposition is straightforward.
Below there are examples of aggregation of resemblance functions:
Mean aggregation:
Weighted aggregation:
Convex combination:
where w1 + w2 = 1.
Conjunctive aggregations:
Disjunctive aggregation:
Symmetrization of functions
From some reflexive or irreflexive association measure that is not symmetric, it is possible to construct a symmetric resemblance measure.
is a symmetric function. If A is reflexive then R is a similarity function. If A is irreflexive then R is a dissimilarity function.
Examples of simplest symmetrizations:
Co-symmetrization of resemblance functions
is a co-symmetric resemblance function of the same type as R. If R is consistent then R1 is consistent. If R is co-symmetric and g satisfies the property g (a, a) = a for all a in [0,1] then R1 = R.
Below are the simplest co-symmetrizations:
If in these formulas R is co-symmetric then R1 = R2 = R3 = R.
Examples of transformations of similarity measures on 2×2 tables
Equivalent transformations
From Ochiai similarity measure:
one can obtain an equivalent similarity measure:
Symmetrization
Consider the inclusion association measure:
It is reflexive but not symmetric. By symmetrization one can obtain, for example, the following similarity functions (measures):
The first function called Sorgenfrei similarity measure [28] and the second Kulczynski similarity measure [5].
Similarity measure using negative matching
Most of all known similarity measures use in formulas the number of positive matches a or both numbers of positive and negative matches a and d. However, it is reasonable to introduce also the similarity measure using only negative matches.
Negative Matching:
The function S is reflexive and symmetric hence it is the similarity function. This similarity measure obtained from Jaccard similarity measure replacing attributes by their negations. Similarly, one can construct negative matching similarity measures from any non-co-symmetric positive matching similarity measures. See also [5] for “complementary” measures, where the term “complementary” has another meaning than in this paper.
The introduced similarity measure can be used when there exists the sets of “permissions” (“recommendations”) and “restrictions” (“prohibitions”) on the attributes (properties) that can possess the objects x and y from the domain Ω. Similarity between the sets of permissions in x and y can be calculated by the Jaccard similarity measure. Similarity between the sets of restrictions in x and y can be calculated by the negative matching measure.
The examples of such data are dietetic, religious and custom prescriptions for different countries or societies. Comparing two diets x and y one can measure similarity between recommendations “what to eat” by Jaccard similarity measure and similarity between recommendations “what not to eat” by the negative matching similarity measure.
Similarly to parametric family of (a)-similarity functions T θ introduce the parametric family of (d)-similarity functions:
New co-symmetric similarity measure
The co-symmetrization of the Jaccard similarity measure equals to the aggregation of the positive and negative matching similarity measures. Below the co-symmetric similarity measure is obtained as the product of the Jaccard and Negative Matching similarity functions:
Similarly, it is possible to co-symmetrize parametric (a)-family of similarity measures T θ aggregating it by (d)-family using some aggregation function g:
Visualization of similarity measures
Visualization of resemblance functions gives new looks to these measures and often helps to understand their properties. Unfortunately, it is not simple to visualize similarity measures defined on any domain.
Visualization of similarity measures on 2 × 2 tables
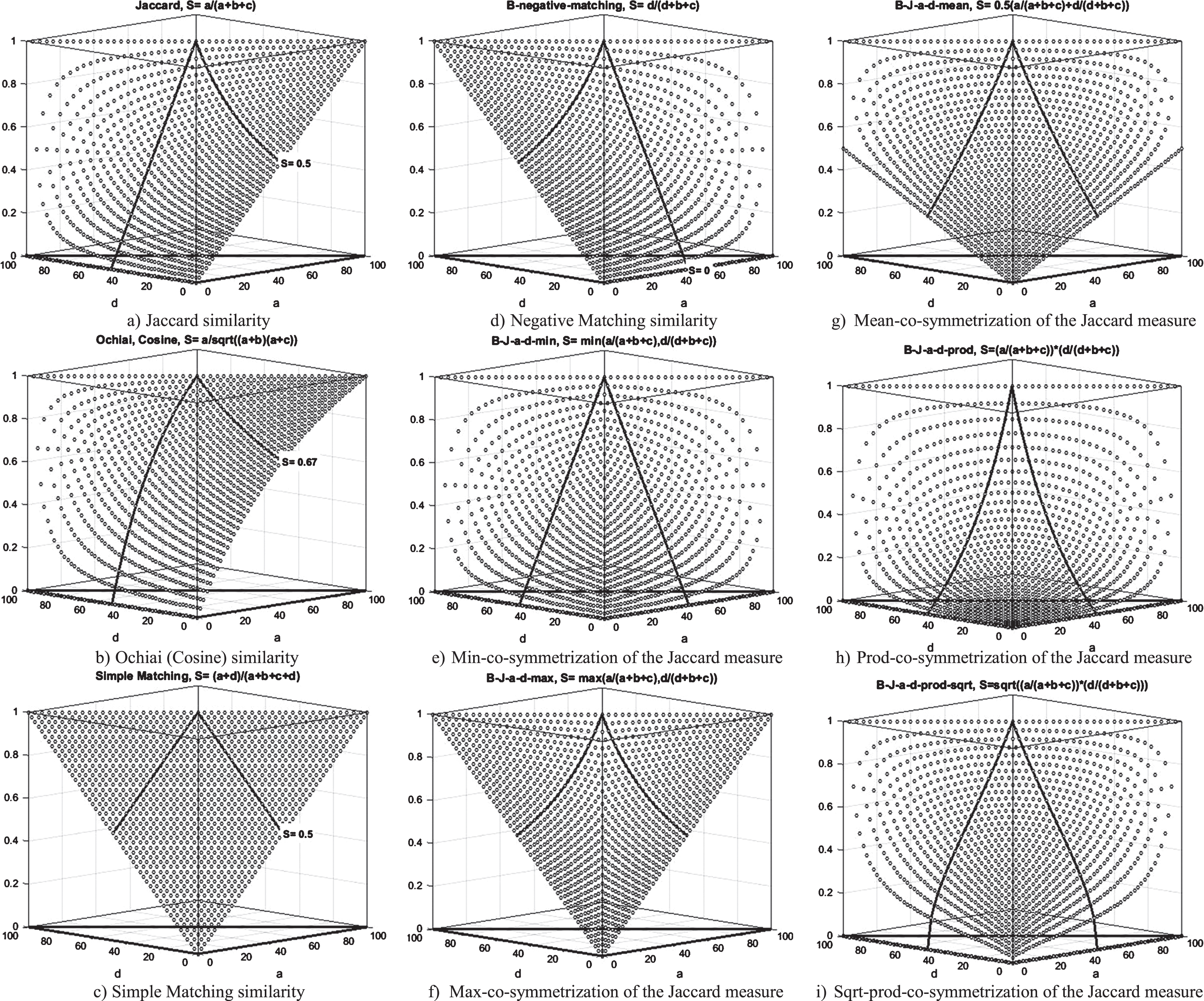
Batyrshin et al. in [17] propose the method of 3D visualization of similarity measures for binary data (on 2 × 2 tables). From a + b + c + d = n, it follows: b + c = n - (a + d), and hence some similarity measures can be represented as functions S (a, d) of two arguments a and d subject to a + d ≤ n with the domain located within the triangle a + d ≤ n. Instead of a, b, c, d one can use relative frequencies dividing these values by n and converting them into percentages multiplying frequencies by 100%.
For example the parametric family of (a)-similarity measures
represented as a function of a and d:
When θ = 1 we obtain the Jaccard similarity measure
presented in Fig. 1a). If in the formula of some similarity measure the parameters b and c cannot be grouped into sub-formulas (b + c), the visualization can be made for different proportions of b and c in the sum b + c. Figure 1b) depicts the surface of the Ochiai similarity measure when b = s(b + c), with s = 0.5. For other values of s in [0,1] the surfaces will be similar.
Visualization of similarity measures.
It is surprising that the surfaces of the similarity measures depend mainly on their properties. Due to the reflexivity all surfaces include the horizontal line with the value S (a, d) =1 over the diagonal of the domain where a + d = n, and b = c = 0. The surfaces of all similarity functions with single a in nominator include the line S (a, d) =0 when a = 0.
For example, the Jaccard and Ochiai (cosine) similarity measures have different formulas, but as one can see from Fig. 1a) and 1b) the surfaces of the corresponding functions are very similar if we compare them with the surfaces of other similarity measures. This explains why in some works, where hierarchical clustering of similarity measures is considered, the Jaccard and Ochiai similarity measures are classified together as similar measures [5, 52].
Generally, the parametric (a)-family of similarity functions (measures) T θ can be used for approximating similarity measures containing single parameter a in the nominator of the formula of these measures. For example, when θ = 0.59 the surface of T θ similarity measure almost coincides with the surface of the Ochiai (cosine) similarity measure and, hence, T0.59 can be used instead of this popular measure.
The surfaces of Simple Matching and all similarity measures of the (a + d)-family S θ (see Section 5.6) contain the line S (a, d) =1 when a + d = n, and the point S (a, d) =0 when a = d = 0 (see Fig. 1c). A change of the parameter θ causes the transformation of the plane triangle in Fig. 1c) into convex or concave triangles [17] having as limits the triangles of the values near 0 or near 1 in almost all points. Hence, this transformation can be very drastic.
The Fig. 1e)-1i) depict the surfaces of the similarity measures obtained as an aggregation of the Jaccard similarity measure presented in Fig. 1a) and the Negative Matching similarity measure depicted in Fig. 1d) by different aggregation operators. The obtained measures can be considered also as results of co-symmetrization of the Jaccard similarity measure using different aggregation functions, because the Negative Matching S NM and the Jaccard S J similarity functions are related for all binary n-tuples x and y as follows:
Using formulas: a + b + c = n - d and d + b + c = n - a the following representations of aggregated measures can be considered:
Min-aggregation, Fig. 1e):
Max-aggregation, Fig. 1f):
Mean-aggregation, Fig. 1g):
Product-aggregation, Fig. 1h):
Square root-product-aggregation, Fig. 1i):
Co-symmetric similarity functions have the surfaces symmetric with respect to the diagonal a = d : S (a, d) = S (d, a).
Based on the properties of formulas and on visualization of similarity functions consider the following classes of (reflexive) similarity functions on 2 × 2 tables (examples are given in parenthesis):
Co-symmetric (Simple Matching). Non-cosymmetric (Jaccard). S (a, d) =0 if and only if (iff) a = 0 (Jaccard). S (a, d) =0 iff d = 0 (Negative Matching). S (a, d) =0 iff a = d = 0 (Simple Matching). S (a, d) =0 iff a = 0 or d = 0 (Min-co-symmetrization of the Jaccard measure).
Some of these classes considered also in [42].
Note that for arguments values (a = n, d = 0), and (a = 0, d = n) from a + b + c + d = n, it follows: b = c = 0, and in some formulas of similarity measures the denominators will be equal to zero. In such cases due to the reflexivity of all similarity functions, the values of these functions evaluated as 1:
Lattice of resemblance functions
Define the operations intersection ∩ and union ∪ of resemblance functions R1 and R2 on a set Ω for all x, y in Ω as follows:
These operations define the partial ordering of resemblance functions by:
or, equivalently, by:
We write R2 ⊇ R1 if and only if R1 ⊆ R2.
Denote, R1 ⊂ R2 if R1 ⊆ R2 and R1 ≠ R2.
Denote, P (R), P (S) and P (D) the sets of all resemblance, similarity and dissimilarity functions, respectively, on Ω with operations ∩ and ∪ defined above. For any similarity functions S1, S2 ∈ P (S) and dissimilarity functions D1, D2 ∈ P (D) it follows:
P (R) is a distributive lattice [23] with sublattices P (S) and P (D).
Consider the following similarity and dissimilarity functions defined for all x, y in Ω:
The functions S0 and S I are the minimal and the maximal elements in the lattice P (S), respectively. The functions D0 and D I are the minimal and the maximal elements in P (D), respectively. The functions D0 and S I are the minimal and the maximal elements in P (R), respectively.
If A : Ω × Ω → [0, 1] is a symmetric function then
are similarity and dissimilarity functions, respectively.
A complementN (R) of a resemblance function R on Ω defined for all x, y in Ω by:
It is clear that N is involution (negation):
The negation of the similarity and dissimilarity functions will be equal to their complementary dissimilarity and similarity functions, respectively:
The lattice P (R) with negation N will be a Kleene (a normal De Morgan) algebra [9] where for any resemblance functions R1 and R2 in P (R) the following properties fulfill:
De Morgan Laws:
Normality:
From Equations (21–23) and De Morgan Laws for any resemblance function R in P (R) it fulfills: R ∩ N (R) = D and R ∪ N (R) = S for some complementary dissimilarity D and similarity S functions.
Set theoretic operations are considered for fuzzy relations in fuzzy set theory [2, 65]. The negation of resemblance functions defined as fuzzy negation introduced by Zadeh [1].
For the Jaccard S J and Simple Matching S SM similarity measures it fulfills: S J ⊆ S SM .
Min-aggregation and max-aggregation of the Jaccard S J and Negative Matching S NM similarity measures represented, respectively, as follows:
Non-probabilistic entropy
Entropy of resemblance functions
A non-negative real function H defined on the lattice P (R) of resemblance functions on Ω called a non-probabilistic measure of entropy if for all R1 and R2 in P (R) it fulfills:
P1. H (D0) =0. P2. H (R1) = H (N (R1)). P3. If R1 ∩ N (R1) ⊂ R2 ∩ N (R2) then H (R1) < H (R2). P4. H (R1 ∪ R2) + H (R1 ∩ R2) = H (R1) + H (R2). P2 says that the complementary similarity and dissimilarity functions have equal entropy values.
Such measure of entropy can be defined by:
where d is the co-symmetric positive metric defined on P (R) [9]. This formula says that the entropy of a resemblance function R increases when the distance d between R and the complementary function N (R) decreases. If R is a similarity (dissimilarity) function then N (R) is its complementary dissimilarity (similarity) function, hence from Equation (24) it follows for the complementary similarity S and dissimilarity D functions:
The normalized entropy of a similarity function S represented as follows:
or
where
Entropy of similarity measure S equals to similarity S R between S and its complementary dissimilarity measure D. The more similar a similarity measure S to its negation the higher the entropy of S.
The following complementary similarity and dissimilarity measures have the maximal entropy values:
The entropy of resemblance function can be considered as a measure of indiscernibility of objects with respect to the similarity measureS: the larger the entropy of similarity measure S the more indiscernible the similarity values between different pairs of objects S (x, y) and S (u, v) from the domain Ω. For S M it is fulfilled: S (x, y) = S(u, v) for all x, y, u, v from Ω such that x ≠ y and u ≠ v. It can be considered the problem of equivalent transformation of a similarity measure S into the similarity measure S* with minimal entropy value.
Another interpretation of the entropy of the resemblance function related with the interpretation of the entropy of fuzzy set [31]: H (S) is a global measure of uncertainty in classification of pairs of objects of Ω into the same or different classes based on information about similarity (dissimilarity) between them. The maximal uncertainty appears for the similarity function S M when the similarity between all different objects equals 0.5. In this case, the uncertainty of the decision to classify or not different objects in the same class is maximal.
The concept of the non-probabilistic measure of entropy of fuzzy sets introduced in [31] where different interpretations of the measure of entropy of fuzzy sets are given. A strict monotonic (P3) measure of entropy of fuzzy sets considered in [6] and further extended on Kleene algebras in [9]. This paper extends the non-probabilistic measure of entropy of the elements of the Kleene algebra on resemblance functions. The relationships between entropy and distance are studied for example in [4, 72].
Entropy of elements of the domain
One can use the formula of the non-probabilistic entropy of resemblance functions Equation (25) also for the entropy of the elements of the setΩassociated with similarity functionS:
where S is a co-symmetric similarity function defined on the set Ω with a negation N. For consistent similarity function S it fulfills: S (x, N (x)) =0, and the entropy of all elements of the set Ω equals to zero: H S (x) =0. For non-consistent similarity function S, the entropy equals to similarity between the element and its negation. The entropy of fixed points has the maximal value: H S (x FP ) =1.
For example, all reasonable similarity functions on the set Ω of binary n-tuples x = (x1, …, x n ) (on 2 × 2 tables) are consistent and all elements x of Ω have the entropy value H S (x) =0. Because the similarity functions on 2 × 2 tables can be considered also as similarity functions on the sets of attributes X possessed by n-tuples x, the entropy of these sets also will have the value zero: H S (X) =0. This situation is similar to the entropy of fuzzy sets when the entropy of crisp sets equals to zero.
On the set [0,1] the negation N (x) =1 - x has the fixed point x FP = 0.5. The similarity measure S (x, y) =1 - |x - y| will define the following measure of entropy: H S (x) = S (x, N (x)) =1 - |2x - 1| with H (0.5) =1 and H (0) = H (1) =0.
On the set of real numbers the negation N (x) = - x has the fixed point x
FP
= 0. The similarity measure
Composition and transitive transformation of proximity relations in hierarchical clustering
Composition of proximity relations
Consider proximity relations (similarity functions) S1 and S2 on a finite set Ω. We use here the terms proximity relation and similarity function as interchangeable. The max-min compositionS1 ∘ S2 of proximity relations is defined [1, 2] (see also [4, 65]) for all x, y, z in Ω as follows:
Denote S1 ⊇ S2 if S1 (x, y) ⩾ S2 (x, y) for all x, y in Ω. For all x, z in Ω it fulfills:
i.e. S1 ∘ S2 ⊇ S1. Similarly: S1 ∘ S2 ⊇ S2. Max-min composition of proximity relations is reflexive but generally, it is not symmetric. It can be converted to proximity relation (to similarity function on Ω) by the symmetrization method considered in Section 8.5.
Min-transitive closure of proximity relations
The composition of proximity relation defined on Ω with itself will give a new symmetric and reflexive proximity relation S ∘ S defined on Ω such that S ∘ S ⊇ S. If S is a valued equivalence relation, then from min-transitivity of S it follows S ⊇ S ∘ S. Hence, S is an equivalence relation if and only if S ∘ S = S. Denote Sk+1 = S
k
∘ S, k = 1, 2, …, where S1 = S. All S
k
are proximity relations and Sk+1 ⊇ S
k
for all k = 1, 2, …. The transitive closure
A min-transitive closure of proximity relations is a closure operation on the lattice P (S) of all proximity relations (similarity functions) defined on Ω satisfying the following properties [7, 23]:
Because all S
k
, k = 1, 2, …, and transitive closure
Transitive closure and hierarchical clustering
Tamura et al. [65] proposed the hierarchical clustering algorithm transforming non-transitive proximity relation S given on a set X into its transitive closure
Hubert and Baker [43] used min-max composition D r = Dr-1 ∘ D of a dissimilarity function D and applied the complete linkage clustering to D r . Dually, it is possible to apply the single linkage clustering to max-min composition S k of a proximity relation S.
Min-transitive transformation of proximity relation and invariant hierarchical clustering
Batyrshin [7] proposed the general scheme of hierarchical clustering algorithms invariant under monotone transformation of similarity values and under initial numeration of objects based on min-transitive transformation of given proximity relation S into valued equivalence relation E. Some versions of these algorithms published in [8, 11].
These algorithms transform the given proximity relation S into valued equivalence relation E by:
where TC is the max-min transitive closure of the proximity relation F (S) obtained as a correction of the proximity relation S such that F (S) ⊆ S. The resulting equivalence relation defines the hierarchy of partitions of the set Ω on equivalence classes. Since the transitive close TC is invariant under both types of data transformation mentioned above, the resulting clustering algorithm will be also invariant if the data correction procedure F is invariant.
The proposed method of hierarchical clustering based on the general solution Equation (26) of the problem of optimal approximation of proximity relation in the lattice of proximity relations (similarity functions) with closure operation [7, 11].
Invariant correction procedure F is based on analysis of neighborhoods of elements x and y. Denote Ωx,y = Ω ∖ {x, y}. One version of this algorithm calculates the following sets of “neighbors” of x and y:
where Vx,y is the set of “all” neighbors of x and y, while Wx,y is the set of “common” neighbors of x and y. The correction F (S (x, y)) of the value S (x, y) depends on the relative part of W xy in the set Vx,y “supporting” the similarity value S (x, y). On many real problems of hierarchical clustering the proposed scheme of clustering algorithms based on correction procedure F showed a good approximation of the optimal hierarchical clustering [7, 11].
Let N be a negation on a set Ω, and V be a subset of Ω
N
= Ω ∖ FP (N, Ω) closed under negation N. A function A : V × V → [-1, 1] satisfying for all x, y ∈ V the following properties:
A (x, y) = A (y, x), (symmetry) A (x, x) =1, (reflexivity) A (x, N (y)) = - A (x, y), (inverse relationship)
will be called a correlation function on V. These properties considered in [13] as the properties of association measure generalizing the Pearson’s product-moment correlation coefficient:
The following theorem is a particular case of the general method of construction of correlation functions using co-symmetric similarity functions (similarity measures) considered in [12, 13].
for all x, y in V, is a correlation function on V.
Reflexivity of A follows from the reflexivity and consistency of S : A (x, x) = S (x, x) - S (x, N (x)) =1 - 0 =1.
Inverse relationship follows from the involutivity of N: A (x, N (y)) = S (x, N (y)) - S (x, N (N (y))) = S (x, N (y)) - S (x, y) = - (S (x, y) - S (x, N (y))) = - A (x, y). ■
The formula Equation (28) has simple interpretation: the correlation betweenxandyis positive ifxis more similar toythan to the negation ofyand the correlation is negative in the opposite case.
From Equation (28) it follows the formula for complementary dissimilarity function:
This dissimilarity function considered in Section 6.7. One can check that it is the co-symmetric and consistent dissimilarity function and the Pearson’s correlation coefficient is the correlation function. The simple proof of Proposition 17 find in [15].
be the similarity measure on 2 × 2 table then by Equation (28) it defines the Yule’s Q association coefficient:
One can easy check that S is the consistent co-symmetric similarity function and the popular A YuleQ coefficient of association is the correlation function.
The papers [12–14] give more general methods of constructing correlation functions on almost any domain where a negation and co-symmetric similarity function are defined. Note, that in these works the negation, co-symmetry and consistency are called reflection, cancellation of reflections and non-similarity of reflections, respectively.
It is impossible to survey hundreds of works related with the topics discussed in this paper. Some given in the list of references.
The concept of fuzzy relation proposed by Lotfi Zadeh [1, 2] and studied in many works on fuzzy sets and relations [4, 65, etc.] was used in this paper as the basis for consideration of similarity measures as functions defined on universal domain and satisfying some sets of properties.
Sup-min-transitivity (or min-transitivity) of fuzzy similarity relations was introduced by Lotfi Zadeh in 1971 in [2]. Later, T-transitivity of fuzzy relations studied in many works [21, 36]. From the results obtained by De Baets et al. [30] it follows (see Section 5.5 above) that the wide parametric class of consistent similarity measures on 2 × 2 tables satisfies neither min-transitivity nor product-transitivity. Only T L -transitivity that is dual to triangle inequality of metrics can be fulfilled. These considerations say that although there is a large intersection between the properties of fuzzy similarity relations and similarity measures (similarity functions) they have differences both in properties and in applications. Roughly speaking the theory of valued (fuzzy) proximity and similarity relations study relationships between proximity values (S(x,y), S(y,z) etc) of different pairs of objects. The works on similarity measures consider mainly the methods of construction and transformation of similarity measures. This paper defining similarity functions as fuzzy (valued) relations and considering the methods of construction and transformation of these functions paves the way for integration of methods developed in the theory of fuzzy relations, and in the works on similarity or resemblance measures. The last chapters consider the concepts of lattice, entropy and transitive transformations of resemblance functions developed in the theory of fuzzy sets and relations.
Due to the difference in methods of construction of similarity and dissimilarity measures these measures considered in this paper together as similarity functions (SF) and dissimilarity functions (DF) and under the general name of resemblance functions (RF). This paper is related also with [5] using general definition of resemblance measures as symmetric real valued functions that are reflexive or irreflexive. The work [5] studies the transformations of resemblance measures, some of them extended here on RF on universal domain. The work [33] describes many distances on different domains. One can use them for defining new similarity measures in various tasks.
The paper proposes new methods (partially based on [12]) of constructing DF based on Minkowski distance and p-transformation of data.
Several dozens of similarity measures on 2 × 2 tables are considered in the works on classification and data analysis [5, 49 etc.]. Some of them used in this paper for illustrating the properties of RF and their transformations. The new RF proposed here as the result of aggregation or co-symmetrization of known RF. The methods of visualization of similarity measures on 2 × 2 tables proposed in [17] used here to demonstrate the classes of these measures.
The new important concept explicitly introduced in the analysis of similarity and association measures here and in [13] is an involution (reflection, negation) operation defined on the domain of these measures. The involutive negation widely used in the theory of fuzzy sets, but in statistics, in analysis of similarity and association measures, the involution or negation usually are not explicitly considered. The concepts of the consistency and co-symmetry of similarity functions related with an involution (reflection) are called in [13] as non-similarity of reflections and cancellation (or permutation) of reflections, respectively.
This paper is a sequel of the works [12–14] where association measures (called here correlation functions (CF)) and similarity measures considered as functions with given properties, and association measures constructed by means of similarity measures and pseudo-difference operations studied in the theory of aggregation functions [41]. Section 13 considers a particular case of more general methods of constructing CF from [13] that one can use for obtaining CF on almost any domain with negation and co-symmetric SF. Due to the limitations and drawbacks of Pearson correlation coefficient used as a similarity or correlation measure on different domains [16, 18] the new correlation coefficients more suitable for specific domains can be introduced.
Generally, any real valued function of two or more arguments establishes some relationship between them and can be considered as an association function (AF). Similarity and dissimilarity functions are special types of symmetric AF taking values in [0,1]. Section 13 considers symmetric and reflexive correlation functions taking values in [– 1,1]. Sections 8.7.2 and 10 consider the methods of construction of RF from AF that can be non-symmetric or non-reflexive. As a sequel of this work, it is supposed to extend the approach developed in this paper on other types of association functions.
The results obtained in this paper for resemblance functions on universal domain one can transfer on specific domains. On some domains, resemblance functions can have additional properties related with the properties of these domains. The consideration of RF on universal domain serves as a bridge in transferring these functions from one to another domain. However, in this case the similarity measure on a new domain can have drawbacks due to differences in the properties of these domains.
Due to the limitations on the size of the paper it does not consider the similarity measures on many specific domains, for example, on interval [0,1], on the sets of fuzzy sets of different types (intuitionistic, hesitant, soft fuzzy sets etc.), on the sets of time series, graphs, images, texts and so on. Some similarity measures on these sets one can find in the works included in the list of references or can construct with the methods considered in this paper. Vice versa, the methods of analysis and construction of similarity measures on specific domains the reader can extend on universal domain as proposed in this paper.
The paper includes many examples illustrating properties and methods of transformation or construction of similarity, dissimilarity and correlation functions. The author hopes that these examples will be helpful for researchers applying similarity and association measures in ecology, social and behavioral sciences, bioinformatics, time series analysis, natural language processing etc. The results of the paper one can use as a part of the course on Data Analysis, Data Mining or Data Science.
Footnotes
Acknowledgments
The author would like to thank the Editor-in-Chief Dr. Reza Langari for the opportunity to publish the paper in the presented form is this journal. The research partially supported by projects SIP 20181315, IPN, and A1-S-43766, FSSEP02-C-2018-1, CONACYT, Mexico.