
Abstract
The resourceful mobile devices with augmented capabilities around human pave the way for utilizing it as delegators for resource-constrained devices to run compute-intensive applications. Such collaborative resource sharing policy among mobile devices throws challenges like identifying competent alternatives for offloading and diminishing time consumption of pre-offload process to accomplish remarkable offloading. This paper presents a Mobile Cloud Computing framework with Predictive Context-Aware Collaborative Offloading Process (PCA-COP) that fixes these challenges through conductive alternative discovery. This context-aware discovery adapts a multi-criteria decision making model of Analytic Hierarchy Process (AHP) accompanied with Fuzzy categorization to rank the alternatives and classify them into Highly, Fairly, Less offload-suitable devices. Moreover, to make alternative selection optimal, a Dataset Curtailment enabled Artificial Neural Network (DCANN) prediction is incorporated on AHP-Fuzzy model, which truncates training dataset using Conditioned Stratified Sampling (CSS). The prototype framework is evaluated with mobile applications in the classroom under dynamic context environments.
Keywords
Introduction
Due to the wide usage of wireless mobile devices, there occurs a demand for accessing them using wireless networks with persistent bandwidth and less communication delay. Such mobile devices behave very smartly that it may replace the PC in the next few years [16]. Mobile handsets are equipped with more powerful processors to satisfy the current requirements equivalent to cost-effective cloud servers. With Mobile Cloud Computing (MCC) technology, some parts of computation could even be migrated to these mobile devices [8]. Computational Offloading is the principle behind MCC. The challenge in offloading is the discovery of suitable alternatives to execute the computational tasks.
This pre-offload process of discovery and effective decision should not exceed the local execution time of an application [13, 29]. Hence, a decisive computational offloading framework is proposed to make the discovery process faster and more productive. This framework comprises of source-proximate mobile devices within a hop that exhibits a collaborative execution of tasks in an application. It does not stand in need of any major installation costs like pre-defined servers and warrants the high availability characteristics of cloud computing [3]. The effective mobile devices are chosen as alternatives by analyzing their performance metrics using a Multiple Criteria Decision Making (MCDM) approaches [10]. AHP is one such approach which is capable of arriving at the best solution from the complex criteria structure at various levels. It allows a decision-maker to specify the degree of preference to the performance metrics according to his personalized requirements and interests [4].
AHP acts a powerful and flexible tool when the complex problem possesses both qualitative and quantitative aspects [15]. It has been popularly used in ranking the cloud services of different cloud providers [7, 23]. AHP method does not take into account the uncertainty associated with the mapping. This risk is avoided by a fuzzy inclusion of AHP, which solves the hierarchical fuzzy problems. Hence, the proposed model adopts AHP along with Fuzzy model to categorize the alternatives for offloading.
Moreover, AHP-Fuzzy is incorporated with Neural Networks (NN) to add intelligence to the prediction of alternatives. NN seems to be uncommon in MCC since its prediction time may have a great impact on the offload execution time due to large dataset requirements. The massive dataset problem is overcome by Data Curtailment algorithm, which shrinks the dataset and retains only the prototypes of each fuzzy set for prediction purpose. The following are the major contributions made in this proposed work: A decisive MCC offloading framework with Predictive Context-Aware Collaborative Offloading Process (PCA-COP) that dynamically chooses the efficient alternatives and migrate the tasks on the fly. A resource efficiency calculation model using AHP-Fuzzy algorithm enumerates the rank of the alternatives. A Data Curtailment enabled Artificial Neural Network (DCANN) prediction model to enhance the performance of the pre-offload decision-making process. A Conditioned Stratified Sampling (CSS) algorithm to perform alternative dataset truncation during NN prediction.
The overview of the proposed framework with all necessary components has been depicted in Fig. 1.

Proposed system architecture.
Computational offloading of heavy tasks has become a familiar paradigm with MCC technology [29]. Most of the researches have contributed to the three sections in offloading. They are: Types of cloud resources to be considered for offloading [1–3, 5] several decision-making engines [12, 25] and application partitioning [3, 29]. These three processes are considered as the pre-offload processes that consume time along with remote execution of the application. However, the discovery process of finding the best alternatives has to be added to the pre-offload process to make offloading successful.
This proposed work considers efficient discovery process as it plays a significant role in pre-offloading. It helps in achieving the offloading principle of obtaining application running time to be lesser than its local execution time. The alternatives can be ranked based on the functional and non-functional requirements of a user. This process involves more than one performance metric, and thus, a multi-criteria decision-making model is necessary for it [9]. Each individual metric is associated with the alternative selection, and the overall impact of a set of parameters decides its priority among other alternatives.
There are several MCDM approaches like ELECTRE, PROMETHEE, ANP, TOPSIS and VIKOR. ELECTRE and PROMETHEE only determine whether one alternative is better than the rest of them rather than comparison among all alternatives. With ANP, a unidirectional relationship among the attributes can be determined instead of hierarchical relations [18]. Since its implementation is too complex, it is rarely used for practical decision making in organizations. The support for a large number of factors becomes unmanageable due to feedback loops in ANP [28]. [21] used VIKOR along with default backfilling algorithm to pick the best alternative offloading task among similar tasks.
In [1], Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) decision is used as the optimal Foglet ranking technique for categorizing the networks based on different parameters, and Fuzzy rule-based scheme is used to reject the inappropriate networks. TOPSIS is used as the wireless medium ranking technique in [5], which proposes a context-aware offloading framework that considers the context of the mobile device. Optimization techniques like genetic algorithms are incapable of handling mixed qualitative and quantitative criteria. However, such criteria are managed by AHP and is referred to as one of the efficient method in MCDM for resource allocation [11]. The importance factor of a benchmark parameter with respect to the other can be assigned according to the type of application. The importance level varies for a compute-intensive, data-intensive, latency-sensitive or deadline-sensitive applications. SMICloud is a framework that uses AHP for comparing different public cloud providers such as IBM, Microsoft, Google, and Amazon [22]. [7] considered AHP to find the best SaaS vendors by evaluating their qualitative and quantitative attributes corresponding to each vendor. The parameters that most affect the application can be given higher preference in AHP. A suitable cloud computing deployment model is preferred among the private cloud (PRC), public cloud, community cloud and hybrid cloud to be implemented in an educational institute by [20]. In our proposed work, an AHP-Fuzzy model is used to select the efficient alternatives for collaborative learning in a smart classroom within an educational campus. Further, the complexity of AHP-Fuzzy is reduced using the proposed DCANN algorithm.
Motivation behind the proposed work
The practice of using smart handsets and mobile data has been increased in the past few years, more eminently in the Asia Pacific, Middle East, and Africa [27]. Therefore, choosing these handheld devices as alternatives for offloading will be profitable in those regions and thus cutting the upfront and infrastructure costs. Running a compute-intensive application, say Mandelbrot set generation or N-Queens problem with larger N in an underprivileged classroom is possible with the proposed framework which makes use of the efficient adjacent devices as alternatives for offloading heavier tasks in those applications. The entire Predictive Context-Aware Collaborative Offloading Process (PCA-COP) is given in Fig. 2.

Overview of PCA-COP.
In general, the pre-offload time involves computation and communication time [13]. Since the type of cloud resources that we choose is the available re-sources rather than the prepared or predefined server, the offloading process must satisfy the following criteria [29]:
The time taken for executing the application task in the local device is denoted as T local whereas the time taken to migrate the same process to a remote machine is termed as T offload . The offload time mainly comprises of the computation time as well as the communication time between the source and the remote device [13]. T offload in the proposed work additionally includes the efficient device discovery time, T discovery as shown in Equation (2). The essential idea behind our model is to diminish the discovery time taken to find efficient cloud resources for offloading. It has to be very low since it takes adds overhead to the overall offloading time and may degrade the offloading performance [12].
In the proposed work, the PCA-COP considers available cloud resources as alternatives and their performance parameters as benchmark parameters to rank those alternatives. They are Communication Cost (CC), data Transportation Cost (TC), Battery Level (BL), Processor Type (PT), Logical Cores (LC), CPU Utilization (CU) and RAM Usage (RU).
Before the offloading process is outset, there are few necessary preliminary operations need to be carried out. It includes diagnosing the heartbeat of the available devices, analyzing the complex nature of each task in the application and the time to establish connections between local and alternate nodes which are declared as PCA-COP.
Program profiling
The necessary conditions for which the optimal execution should migrate forward to the cloud has been determined using Equation (3) which says that the remote execution of a method in the application should not exceed its local execution time.
The offload decision engine in this work also takes into account the discovery time as in Equation (2) to determine which method can be labeled as ’offloadable’ and also the offload conditions from [17].
A predictive AHP-Fuzzy with DCANN prediction to determine the optimal alternative cloud resources comprises of following sub-processes.
Proximate resource discovery
The root server searches for the source-proximate resources when the offload request is generated by the offload decision engine. All the devices are connected to the same access point through Wi-Fi. The root server identifies the available devices which are one-hop distance to the source device and also checks whether their statuses are active at that moment. The list of such devices is then ranked and categorized using PCA-COP.
Ranking of alternatives using analytic hierarchy process
This model considers a set of available cloud resources and various device and network performance parameters to sort the best resources in the order of their ranks to carry out the offloading process. AHP method is aimed at setting up priorities or weights to be ascribed to various benchmark criteria and alternatives and is represented as a hierarchy as given in Fig. 3. This process includes a decision, and its outcome facilitates the choice of the most desirable alternative.
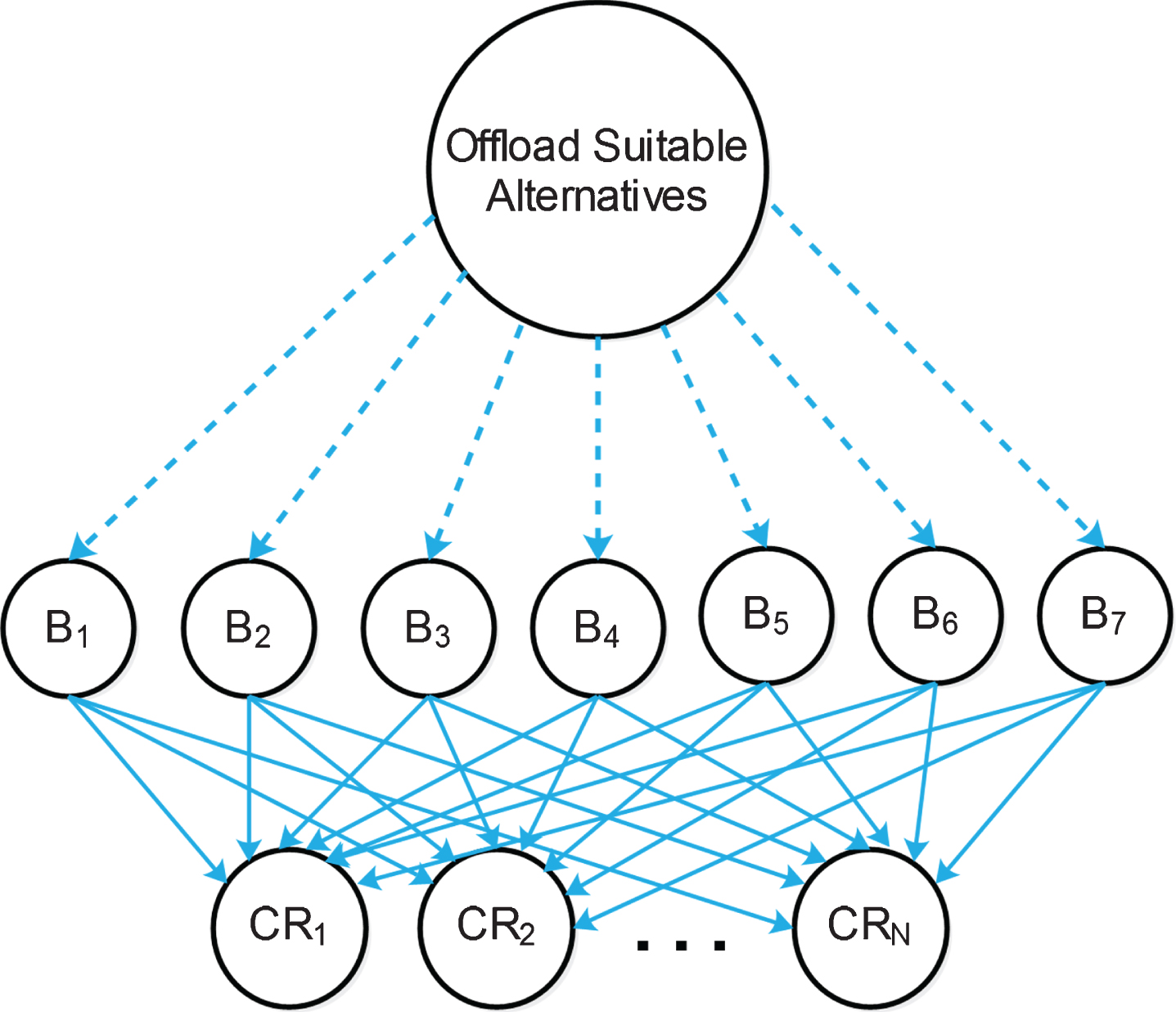
Hierarchy of alternatives selection.
The proposed model categorizes the alternatives as “Highly suitable”, “Fairly suitable” or “Less suitable” for offloading. The steps for actualizing the AHP-Fuzzy process are delineated as follows.
AHP method starts with aligning the parameters of different resources into a decision matrix. The different cloud resources constitute each row in the matrix, and the device and network parameters constitute the column of the matrix. Let CR1, . . . , CR n are the competing cloud resources currently available closer to the source and CC, TC, BL, PT, LC, CU, RU are the benchmark parameters with which the decision has to be made. The initial matrix is given by D (i, j) as
The sensitivity of each parameter over another parameter completely depends on the different traffic classes defined by ITU. The delay-sensitive applications have been dealt here, and the relative weights are assigned according to the association among the benchmark parameters B1, B2, . . . , B7. Thus the decision matrix derived from the relative weights is a n × n matrix.
The pairwise comparison is the principle behind AHP in which the alternatives are tested by considering the first benchmark parameter and specify a preference. The weights are assigned with various levels of preference based on the standard preference scale as given in Table 1.
Standard Preference Scale for AHP [5]
Standard Preference Scale for AHP [5]
The priority vector calculation of the pairwise comparison matrix is the next vital step in the AHP process. Since the values of a ij in comparison matrix have been obtained as the ratio of two benchmark parameters B i and B j , the columns of the matrix
A(n,B) will be proportional to one another. Also, every value of the matrix A(n,B) will be in normalized form irrespective of its units. It ensures that the information contained in the matrix D (i, j) is not lost after assigning weights and normalization. A weight vector is formed from A(n,B) which incorporates the information from that matrix.
AHP utilizes this weight vector to arrive at a good priority vector that best suits the proportionality among the benchmark parameters using the normalized columns method [26]. The normalized relative weight (A*) is determined to make the values fall between 0 and 1. Therefore, the sum of the values in a column equals the highest probability value, which is 1. It is obtained using Equation (4).
Once the normalization is done, Perron-Frobenius Eigenvector method is applied to find the normalized principal Eigenvector or the relative weight matrix W
A
*
by averaging across the rows.
The weight matrix has been calculated for each alternative with respect to their vitality in satisfying the benchmark parameters. There will be
The needs of the alternatives are computed for the goal as CR
priority
(B
N
) which yields the priority of an alternative with respect to a particular benchmark parameter.
After the calculation of the priorities of all available alternatives in accordance with each criterion using Equation (7), the resources are classified as “highly suitable”, “fairly suitable” and “less suitable” for offloading using the fuzzy rule-based method rather than taking a weighted sum of priorities obtained for each criterion. The uncertainty in the preferences of parameters involved in the decision process may create uncertainty in the ranking of alternatives and is solved using consistency verification.
AHP calculates a consistency ratio (CR) comparing the consistency index (CI) of the matrix CR priority (B N ) versus the consistency index of a random-like matrix (RI) from [26]. If the CR is less than or equal to 0.1, then the weight vector is said to be consistent. If the CR is zero, the vector is said to be absolutely consistent [24]. Otherwise, the vector seems to be inconsistent, and it requires a reassignment of weights. The ranked alternatives are grouped using fuzzy rule-based classification into different levels of suitability for offloading complex tasks.
Fuzzy cloud resource categorization (FCRC)
The threshold values of the parameters obtained from the theoretical calculation of each criterion are verified against the observed values using the fuzzy method. The FCRC module categorizes the alternatives into three different fuzzy sets for offloading as
The major characteristic of fuzzy sets is that there exists Fuzziness in their boundaries. In other words, there is not always a clear boundary between one fuzzy set and another, which is totally unacceptable in a traditional crisp set. Tsukamoto fuzzy model represents the consequences of each fuzzy if-then rule as a monotonical Member Function (MF) given as If X is v1, then Y is HS
If X is v2, then Y is FS
If X is v3, then Y is LS
The variables v1, v2 and v3 are the comparisons of priorities of each cloud resource from Equation (7) with the threshold value from Equation (5). The average of the overall priorities of all the alternatives is considered as the threshold value v Th to categorize the resources into three classes and is given by
The representation of the category of cloud re-sources is shown in Fig. 4.
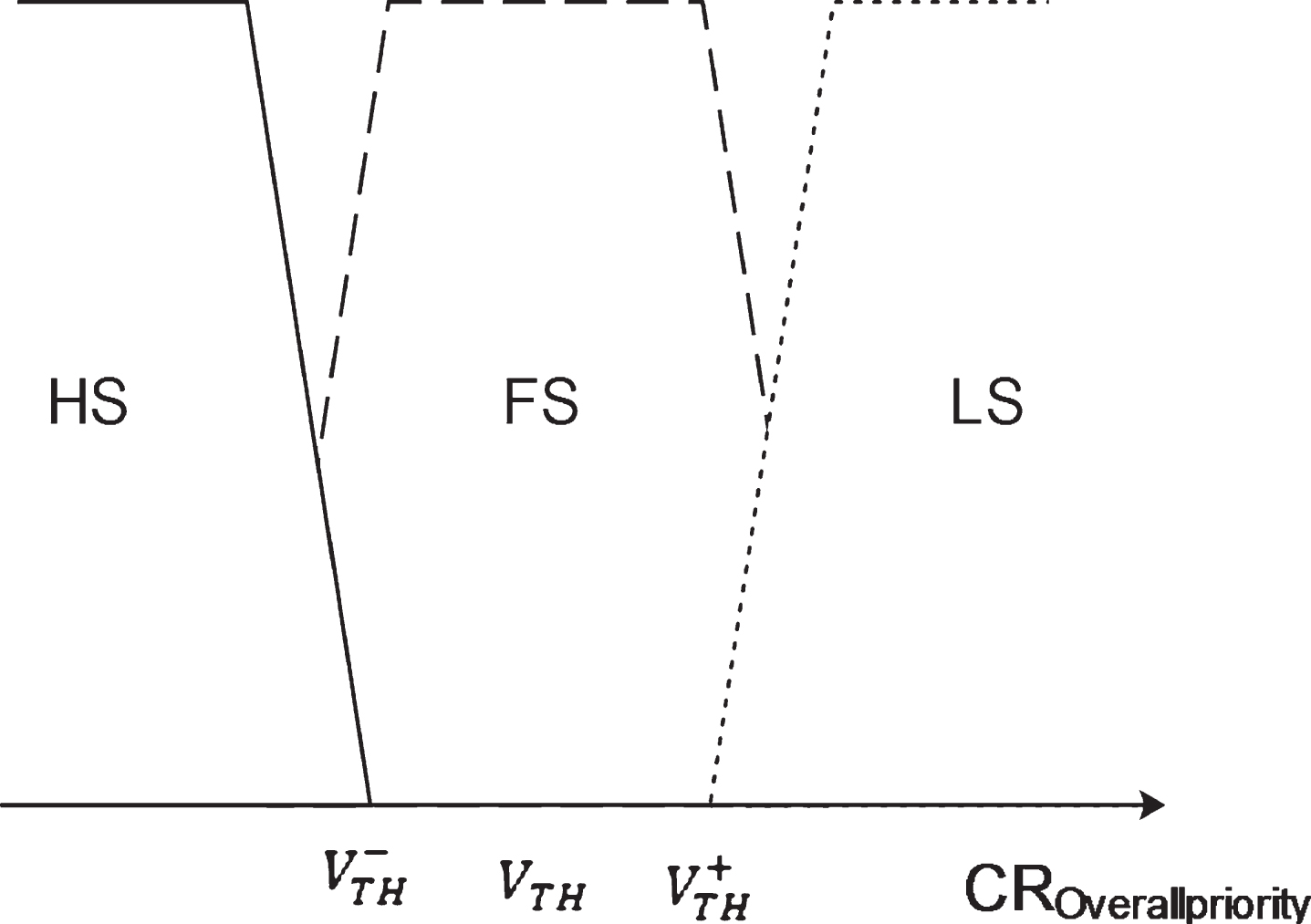
Categorization of Resources based on its CR OverallPriority .
Therefore v
i
can be written as
By viewing AHP as a model of the decision-making process, we present a neural model for the decision-making process to optimize the prediction, as shown in Fig. 5. The heuristic comparison helps in arriving at the classification of cloud resource at the earliest time by considering the weights and average of the threshold values from previous runs performed at the same time as the current one.
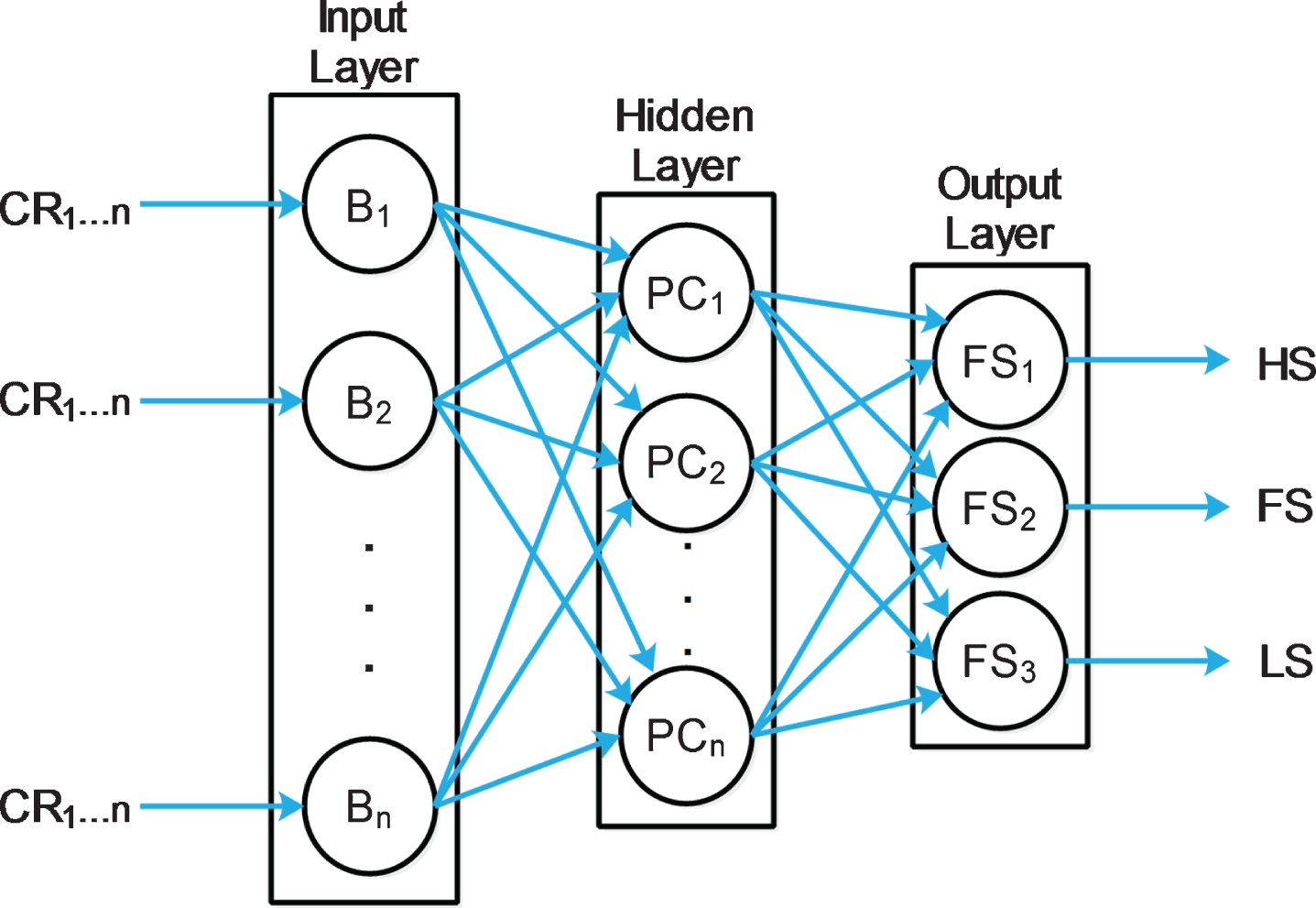
AHP with ANN.
CR OverallPriority belonging to heuristics dataset SelectList F , SelectList M is used as the weights of the first internal layer of the neural network. The alternatives in SelectList F , SelectList M are chosen using Conditioned Stratified Sampling algorithm (CSS) given in Algorithm 3. The inputs in the first layer are the values given using the selection scale of the cloud resources. If CR (i, j) is the input to the nodes in the first layer, then i represents the i th CR for the j th benchmark parameter on the scales. The next layer performs the pairwise comparisons of the cloud resources which gives with the priorities of the resources with respect to each criterion as in Equation (5).
Then the output of these nodes from the middle layer will be multiplied with the weights of the relative importance of each benchmark parameter to the resource selection process and their sum of the products is fed as input to the next layer as in Equation (7). The FCRC module has been used for the classification of cloud resources in the last layer as in Equation (8). The threshold value v th is used as the trigger function for mapping the cloud resources with the fuzzy sets. Therefore, according to the fuzzy categorization, the cloud resources are mapped to the sets HS, FS or LS. The algorithm for neural network prediction of AHP-Fuzzy model is given in Algorithm 2.
During every offloading, the dataset has been ob-served and stored in cloudlet for prediction. Its size and time taken for categorizing during offloading tends to be high degrading the offload performance. Thus, to bring down the model size and prediction time complexity of the neural network combined AHP-Fuzzy system, the prototypes of each fuzzy set are selected from the entire dataset. The cloudlet embraces two-level databases; one with an entire dataset and the other acting as a cache storing only the frequently available and competent devices as shown in Fig. 6.

Dataset Curtailment of Alternatives for NN prediction.
The small dataset in the cloudlet takes less learning time for resource prediction and thus saves the time for proximate device discovery during offloading. In the idle time, when no offloading jobs are in progress, the process of sinking the updated dataset from cloudlet cache to the plenary dataset is done. This avoids extra time in updating the plenary database at the time of offloading.
The neural network alternative prediction result will be a permutation for the ranking problem with more than two fuzzy sets [6]. The heuristic information in the cloudlet about the priority values determining the fuzzy set of the already existing cloud resources slightly reduces the prediction time. The static benchmark parameters are maintained constant in the database, and the dynamic parameters are updated every time. Only the available and active resources are passed as test inputs to the prediction model for classification. Moreover, in the selection process, a stratified sampling technique with Most Often Utilized Selection (MOUS) algorithm has been used to choose the prototypes of each fuzzy set that represents the entire heuristic dataset. This dataset curtailment process occurs in the cloudlet periodically.
In a sampling technique, as shown in Fig. 7, the entire dataset is considered as the Target population. From the target population, the preferred device study population has to be drawn as the set of resources to be considered for the prediction process. The stratified sampling technique has been used to pick the training data set for neural network prediction.
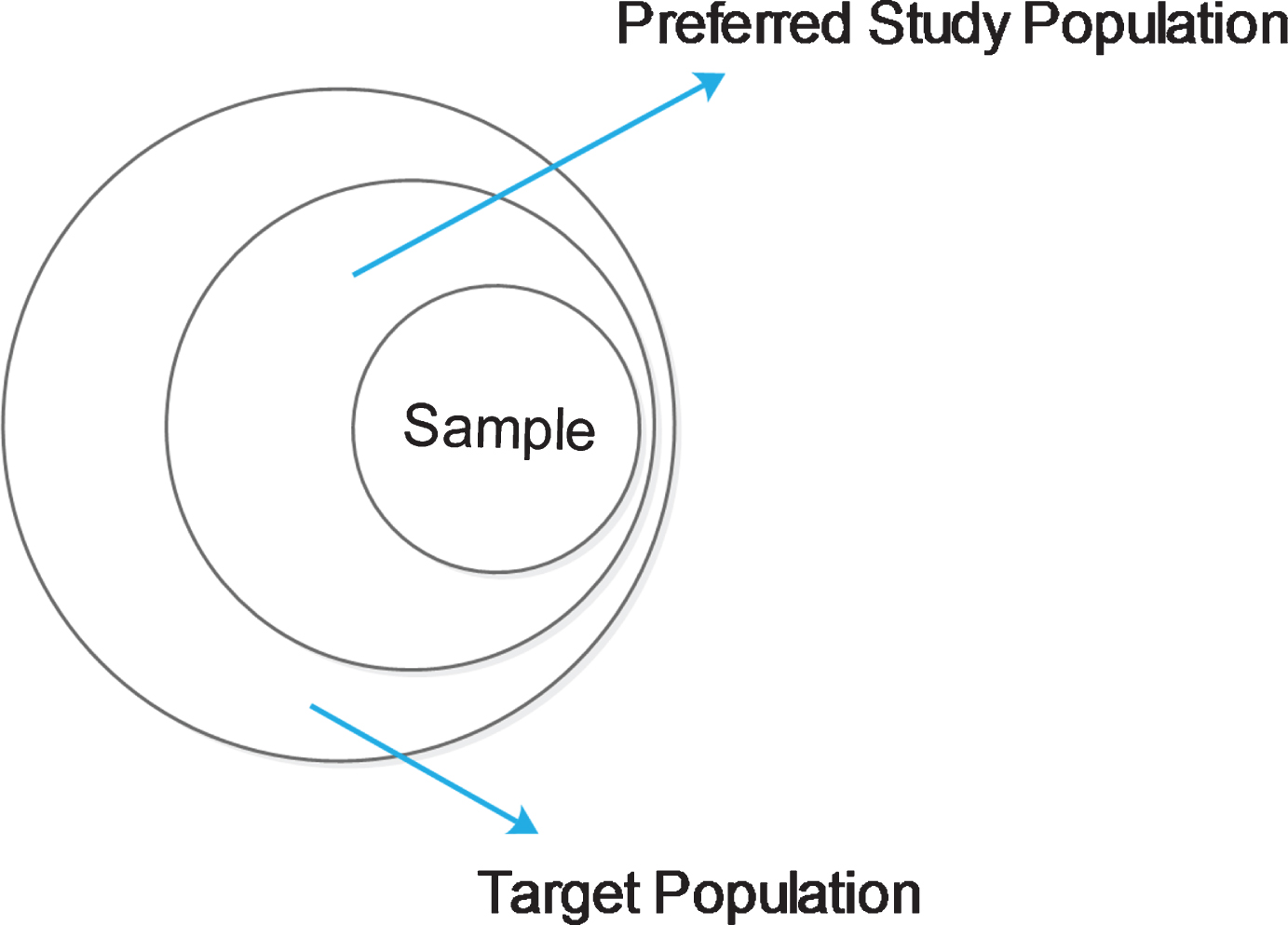
Sampling of the entire Alternative dataset.
Stratified Sampling branches off the number of distinct categories of alternatives into several non-overlapping and similar characteristics groups called strata using the proposed DCANN prediction. Each stratum is sampled as an independent sub-population of fuzzy sets with a bunch of homogeneous alternatives. Later, the CSS algorithm extracts the prototypes of each fuzzy set using the following conditions (1) Status of the element should be active or recently active from the current moment; (2) The resource should be a more frequently used one in the previous offloading processes, MOUS algorithm.
Furthermore, the CPU utilization rate is also considered as the criteria to pick the element from the study population, along with the above two conditions. The stratified sampling is made into an Event Sampling methodology by recording the data once a new element is added or removed from the mobile device network. It includes or expels a new device whenever it becomes active or inactive in the offloading network.
In order to evaluate the performance of the proposed work, a range of 1 to 10 alternatives are considered for offloading. These alternatives are located in proximate distances within a classroom in the university campus. The order of importance for the seven criteria under consideration is given as: CC > TC > BL > PT > LC > CU > RU.
Performance improvement using DCANN prediction
The entire dataset comprises of alternatives found during the offloading of the same application across several times of the day. This is used as the training dataset for the decision making in the neural network process. The learning algorithm is applied to the training dataset. Once the dataset is trained, it is used to predict the test dataset. The active alternatives at that location are considered as the test data set and classified into different categories of offload suitable alternatives.
Table 3 shows the total decision time for 95% confidence level and DCANN prediction for the different numbers of active alternatives. Since the pre-offload process uses the NN enabled prediction, the decision time becomes a little higher. But the offloading process gains improvement through the NN determined result. The decision time with and without NN are compared and plotted in Fig. 8.
Priority Vector matrix of Benchmark parameters
Priority Vector matrix of Benchmark parameters
Overall Decision time for pre-offload process without and with DCANN prediction and Confidence level = 95%
TDD = Device Discovery, TAHP = AHP, TFC = Fuzzy Classification, TDT =Total Decision Time, TDC =Time taken for DCANN prediction, TNN =Time taken for NN Prediction, T (DT + NN) =Total Decision Time with NN.
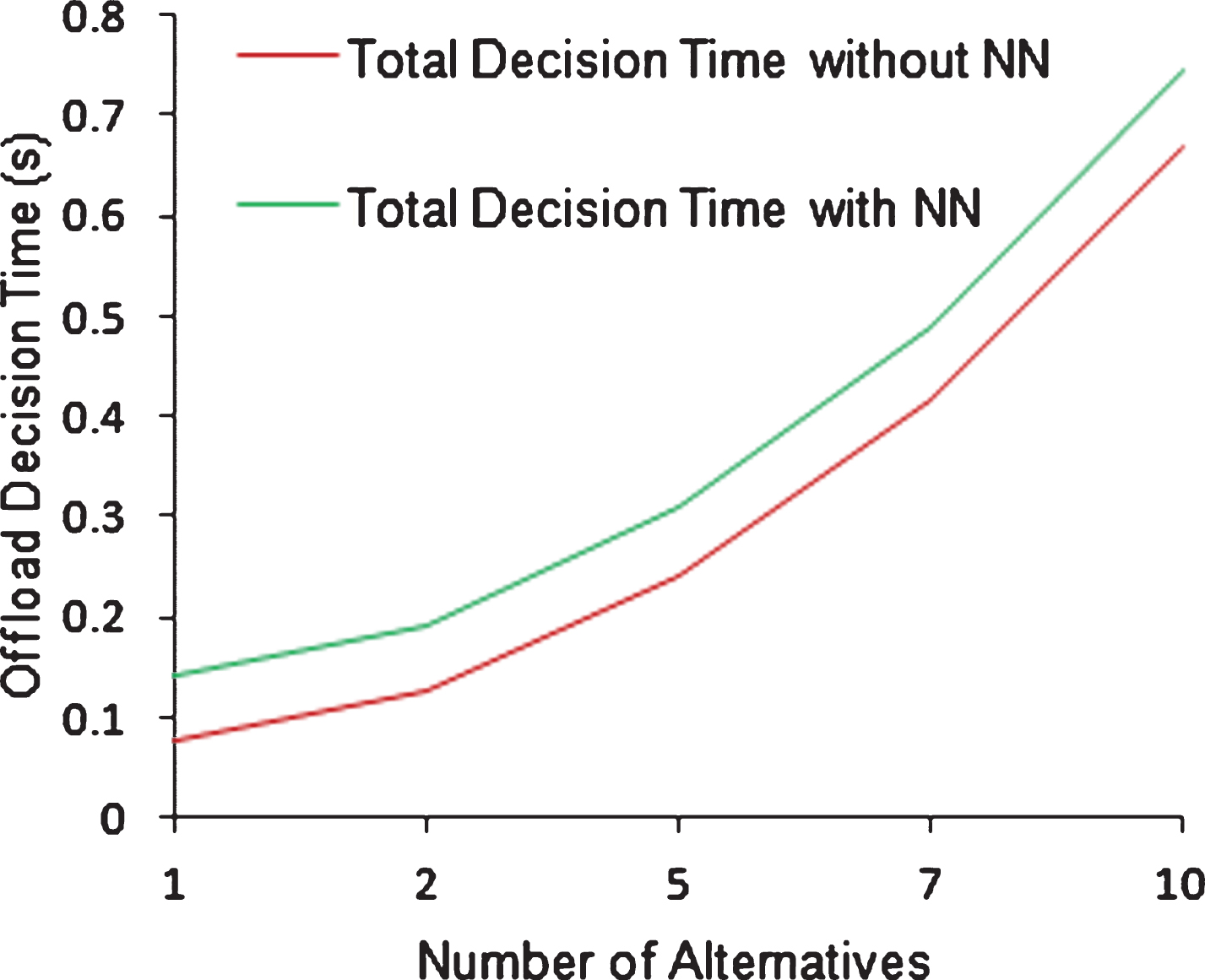
Comparison of Overall Offload Decision time with and without DCANN.
In order to prove the improved performance of our framework, two applications are tested with a fixed number of tasks by varying the number of devices. The experiments are repeated three times, and their average speedups and execution times are observed.
The testing with Mandelbrot Set generation application is conducted inside a smart classroom, and it is examined each time with a variation in the number of devices. The speedup of proposed work is compared with Honeybee [19], and standard AHP technique. The performance of our proposed work has improved since the efficient devices are chosen as alternatives from the available devices for offloading. Instead of sharing the tasks to all available devices, the performance may increase if the task is shared only among the effective devices among all available mobile devices.
The average speedup proves that the execution time in local is more than in the remote devices as given in Equation (1). The speedup for a varying number of devices is plotted for Honeybee, AHP technique, and the proposed work in Fig. 9.
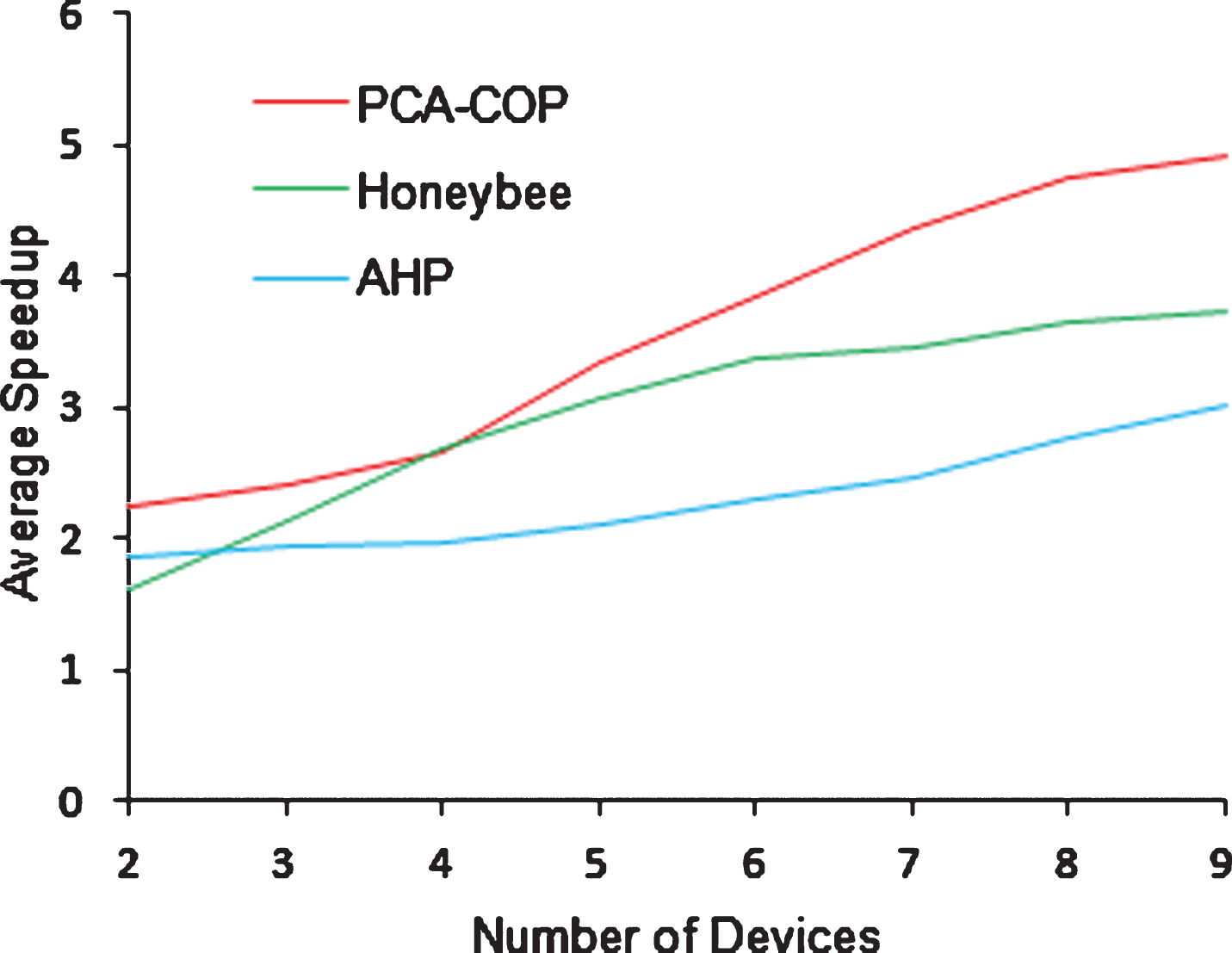
Comparison of Average Speedup for PCA-COP, Honeybee and AHP.
The speedup is directly proportional to the number of devices. The average time saved by offloading the compute-intensive tasks of the application to the proximate devices has been observed and shown in Fig. 10. The time saved by the proposed framework is higher for a maximum number of times when compared to Honeybee and traditional AHP models. There is little delay sometimes occurring due to the pre-offload overhead, which takes additional time for the remote execution of the task. At such times, Honeybee leads the proposed work by a few seconds, as shown in Fig. 10. It happens when the alternatives are efficient luckily by chance without performing ranking and neural network prediction over it.

Comparison of Average Time Saved for PCA-COP, Honeybee and AHP.
Fig. 11 shows the performance obtained for different confidence levels of dataset curtailment. The values are obtained while selecting five devices from the available alternatives. The accuracy of the prediction is measured through speedup observed during each confidence level. The decrease in the confidence level has a negligible effect over the speedup till it is 70%.

Accuracy in selection of Alternatives for different Confidence Levels.
N-Queens application solved using Recursion is considered as the benchmark application where a single heavy task requires offloading. The process of placing the queen to find the possible solutions for a particular N value is the heavier task. From the discovery process enhanced by DCANN prediction of potential resources, the mobile device having the highest rank is considered for offloading. The tested application is compared with ThinkAir [23], and the results are plotted in Fig. 12.

Comparison of Execution time for N-Queens application.
The result shows that the proposed offloading framework gives better results when the number of queens starts increasing from N=8. The execution time seems to be directly proportional to the number of arrangements to arrive at the possible solutions obtained. It is noted that ThinkAir has limited its results till N=8 since the local execution becomes very computationally expensive. But PCA-COP has been executed for 4 ≤ N ≤ 13 because it achieves a better result until the value of N becomes 13 through offloading, as shown in Fig. 13.

Execution time for N-Queens application with 9 ≤ N ≤ 13 using PCA-COP.
The performance loss may occur only when the selected alternative suffers from hardware issue like quick battery drain, unusual shutting down due to system failure while executing the offloaded tasks. The random disconnections of the chosen alternative are predicted using NN where they are selected only if the devices have been already picked and also have a history of completing the offloaded tasks more times in the recent past. Sometimes, the offloading using the randomly selected devices can outperform the offloading using proposed PCA-COP process when the devices picked in the former case are efficient by chance as discussed in the graph shown in Fig. 10 when N is 4.
Conclusion and future work
A decisive offloading framework with predictive context-aware collaborative offloading has been proposed. It considers dynamic device and network contexts to pick the alternatives and yields a successful and profitable offloading. A predictive neural network incorporated AHP-Fuzzy algorithm identifies the efficient alternatives from the available devices within proximity. In order to reduce the neural network prediction time, an alternative dataset truncation called DCANN prediction is conducted using CSS algorithm. This dataset reduction helps the offloading to undergo effective prediction with minimum pre-offload overhead time for the application. The proposed framework shows an improved average speedup of 3.57 for Mandelbrot set generation and an increased average execution time of 9.54s for N-Queens problem by offloading to powerful neighbourhood alternatives.
In future work, this framework can be extended to support complex applications having dependent tasks. A probabilistic model can be designed to conduct a complexity analysis of the application code and find the compute-intensive methods.
Footnotes
Acknowledgment
This research is supported by Visvesvaraya PhD Scheme for Electronics & IT (VISPHD-MEITY-2560), Ministry of Electronics and Information Technology, Government of India. The authors also want to thank the editor and reviewers for their valuable comments and suggestions.