
Abstract
In the study of intuitionistic fuzzy clustering, the construction of an intuitionistic fuzzy similarity matrix (IFSM) is a fundamental and important issue in the direct clustering analysis, since it determines clustering results and computational efforts. Many methods based on the axioms of intuitionistic fuzzy similarity relations are applicable to IFSM construction. However, most of existing methods may yield a “counterintuitive result” in some cases and consume much computational time. In this paper, we propose a novel intuitionistic fuzzy clustering method to deal with such problems. First, based on the normalized Hamming distance, we define a similarity measure between intuitionistic fuzzy numbers (IFNs), by which a similarity measure between intuitionistic fuzzy sets (IFSs) is induced. Second, a divergence measure between IFSs is obtained by extending the dissimilarity of IFNs. Third, we construct an IFSM by using together the similarity and divergence measures so as to cluster the intuitionistic fuzzy information. Finally, two examples are presented to show the effectiveness and advantages of our method.
Keywords
Introduction
Cluster analysis or clustering is to divide a family of objects into several different clusters, in which the objects in the same cluster are of some similar properties [1]. Clustering analysis is a core tool which plays the important role in various fields, such as decision making [2, 3], data minning [4, 5], knowledge discovery [6, 7], clustering ensembles [8], medical diagnosis [9], etc. In classical clustering analysis, we know that an object belongs exactly to one cluster, i.e., the so-called “hard" cluster [10]. In practice, however, it is usually very fuzzy for that whether or not an object belongs exactly to one cluster, i.e., the so-called “soft" cluster or fuzzy cluster, due to the incompleteness of information. In order to improve that, Bezdek [11] introduced the notion of fuzzy clustering that means a beginning of fuzzy clustering theory. Fuzzy sets, as important objects of study, are applied to explore the problems of fuzzy clustering. However, it is not very precise to reveal the fuzziness of objects under the complex and volatile environment since that fuzzy sets characterize the fuzziness just by the membership degree. So later, Atanassov [12] introduced again the notion of intuitionistic fuzzy set (IFS) which adds a hesitancy degree to fuzzy sets. Since then, IFS theory began to be focused on and applied to directions such as three-way decisions (3WD) [13–16], rough sets [17, 18], information systems [19–23], pattern recognition [24, 25] and image processing [26].
In the field of intuitionistic fuzzy set analysis, intuitionistic fuzzy clustering is a significant topic, has been studied for decades and plentiful results have been obtained [27–32]. For example, an early survey is due to Zhang et al. [27] who constructed an intuitionistic fuzzy equivalence matrix by using transitive closure of an intuitionistic fuzzy similarity matrix (IFSM) and finally gave an effective method of clustering samples. For instance again, Thong and Son [32] who, recently, first calculated the most proper number of clusters by using techniques of particle swarm optimization, and then gave a method of automatic picture intuitionistic fuzzy clustering. Although the previous results obtained show respectively their own advantages in clustering intuitionistic fuzzy information, they usually lead to time-consuming in computation or loss of information for that all of them are just based on an intuitionistic fuzzy equivalence matrix, the transitive closure technique or optimization methods [33]. Thus in recent years, many authors [33–37] proposed a novel technique by constructing an IFSM to cluster intuitionistic fuzzy information directly. It is pointed [33] out that this technique reduces time-consuming in computation since the clustering efforts and time are mainly determined by the IFSM calculation.
How to reduce clustering efforts and thus save the time in computation? Many authors [33–37] did lots of work on this aspect, e.g., Wang et al. [33] reduced clustering efforts by constructing an IFSM that is obtained from intuitionistic fuzzy similarity degree. It’s certain that these approaches, to some extent, save the time by reducing clustering efforts, however, it leads to a “counterintuitive result” in some cases. So how to improve the methods so that it not only saves the time but also avoids “counterintuitive results”. Thus in this paper we present a new intuitionistic fuzzy clustering approach which is based on IFSM construction.
This paper is organized as follows: In Section 2, we recall the knowledge and classical methods of IFSM construction, and analyze briefly some of their disadvantages. Section 3 gives a similarity measure between intuitionistic fuzzy numbers, the similarity and divergence measures between IFSs. Then based on that, we construct an IFSM. In Section 4, an intuitionistic fuzzy clustering method is presented by IFSM construction. In Section 5, some examples are given to illustrate the advantages of our method. Finally we end with this paper in Section 6.
Preliminary
Let us recall briefly some basic concepts concerning intuitionistic fuzzy theory and some classical approaches to IFSM construction.
Intuitionistic fuzzy set
Let X = {x1, x2, …, x
n
} be fixed. An intuitionistic fuzzy set (IFS) A in X is defined as [12]:
Let us now state some operations about the IFSs (referred to [12]). Assume A and B are two IFSs, then
We introduce a similarity measure S (A, B) between the IFSs A and B, which is given respectively in [40, 41], such similarity is of axiomatic properties as follows:
Later, Montes et al. [42] proposed the notion of divergence measure between IFSs, which can be viewed as a particular case of the dissimilarity of IFSs and is of the following properties:
Let us proceed to introduce the notion of intuitionistic fuzzy similarity degree (see [27, 43]). Given the IFSs A, B, C and R (A, B) denotes the relation between A and B. We call R (A, B) the intuitionistic fuzzy similarity degree if satisfying the following conditions:
Szmidt et al. [44] and Li [45] gave respectively the normalized Hamming distance and the dissimilarity between IFNs as follows:
In order to facilitate this work, the concept of an intuitionistic fuzzy similarity matrix (IFSM) is given as follows:
Existing approaches to IFSM construction
This section mainly reviews some classical approaches to IFSM construction based on the IFSs [27, 33–37]. For the problems of multi-attribute decision making, assume that there is a discrete set of alternatives (or objects) denoted by A = {A1, A2, …, A
m
}, and a discrete set of attributes denoted by X = {x1, x2, …, x
n
}. Then the characteristic of each alternative (object) on the attributes x
k
(k = 1, 2, …, n) is assumed as:
Existing methods on IFSM construction in recent years are recalled as below:
(1) (Zhang et al., 2007 [27])
(2) (Wang and Xu, 2011 [33])
(3) (Viattchenin, 2012 [34])
(4) (Feng et al.’, 2014 [35])
(5) (Wang et al., 2014 [36])
(6) (Li et al., 2014 [43])
where w k is the weight of element x k in the universe of discourse X for x k ∈ X.
(7) (Kacprzyk et al., 2016 [37])
Recall the previous approaches regarding IFSM construction, we find that the unreasonable phenomenon may happen, e.g., Kacprzyk et al.’s approach in some cases. Taking IFSs A1 = {(x, 0.1, 0.9) |x ∈ X}, A2 = {(x, 0.5, 0.3) |x ∈ X} and A3 = {(x, 0.6, 0.3) |x ∈ X}, where X = {x1} is a domain of discourse. It is obvious to get A1 ⊂ A2 ⊂ A3. By (10), we obtain z12 = (0.6838, 0.3) and z13 = (0.6959, 0.3). That is z12 ⊂ z13, which indicates that the similarity between A1 and A2 is lower than the one between A1 and A3 under the circumstance of A1 ⊂ A2 ⊂ A3, which does not coincide with human’s intuition. The same phenomenons may happen in the other approaches ([27, 36]). The reason why these approaches lead to “counterintuitive results” is that the fourth property of intuitionistic fuzzy similarity degree (IFSD) is not satisfied in some cases, which is pointed out in [43]. In next section we propose an approach to constructing an intuitionistic fuzzy similarity matrix based on the new IFSD, satisfying these properties (R1-R4), which can overcome such shortcomings.
In this section, we propose an approach to constructing an intuitionistic fuzzy similarity matrix. A similarity measure between intuitionistic fuzzy numbers (IFNs) is first given as:
From (109), we know that s (a1, a2) is a real number between 0 and 1 (see Property 1). The bigger (smaller) the value of s (a1, a2) is, the higher (lower) similarity is between a1 and a2; if s (a1, a2) =1, the similarity reaches the maximum between them, namely, a1 = a2, which implies their identity.
As is analyzed above, some properties of the similarity of IFNs are further obtained.
Without loss of generality, we only prove 0 ≤ s (a1, a2) ≤1 under the first case, and the same for the others. It is well known that an IFN can be explained by two-dimensional coordinates [47], shown in the case (i) of Fig. 1. The membership degree (μ), non-membership degree (ν) and hesitation degree (π) are denoted by a point inside the triangle FOE, thus the point D and C are represented by D = (μ1, ν1, π1) and C = (μ2, ν2, π2), respectively. For convenience, assume that h = |μ1 - μ2|, l1 = |ν1 - ν2| and l2 = |π1 - π2|, let S be the area of the right trapezoid CHDG, then |DH| = l1, |GC| = l2, |CH| = h. It follows
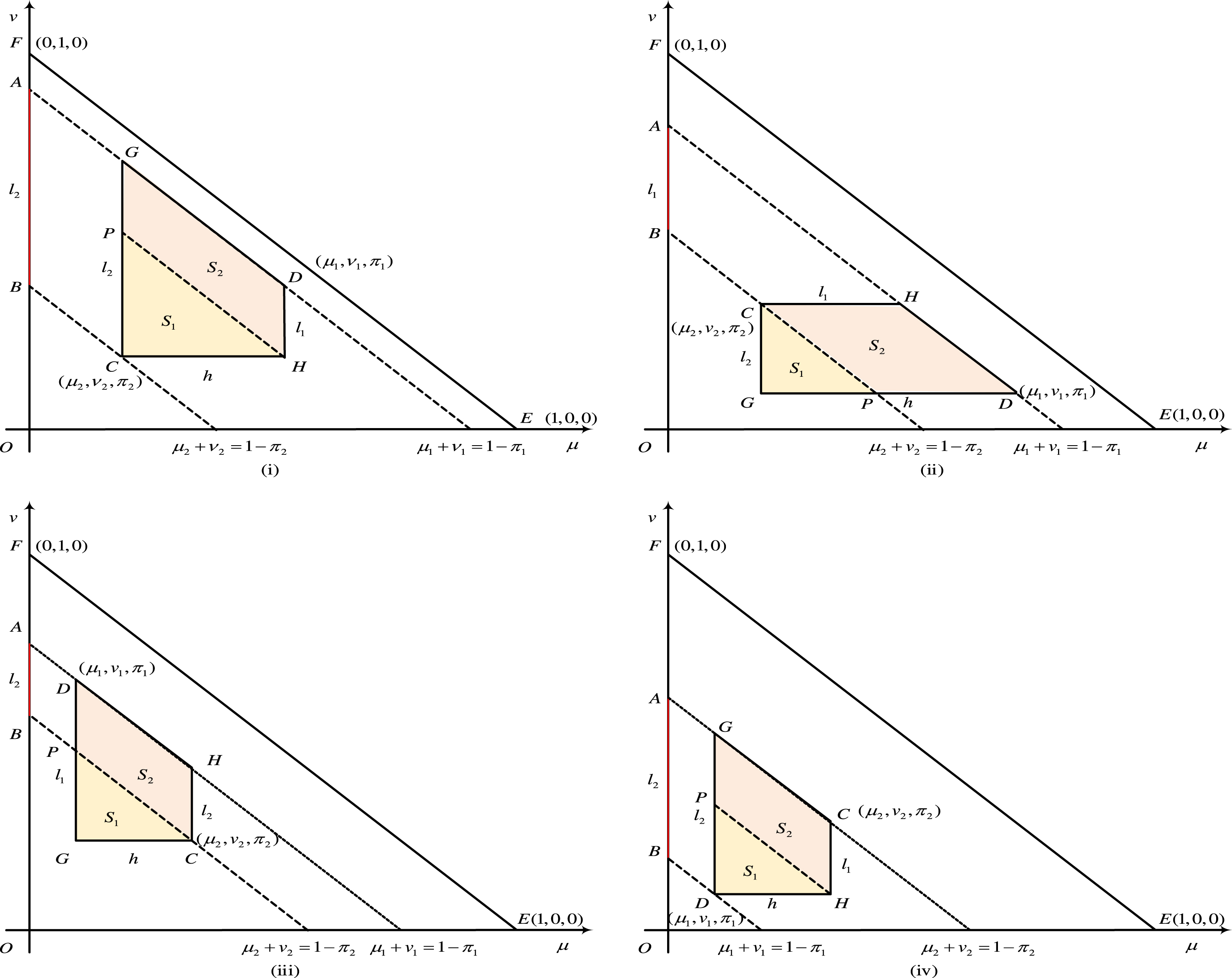
Geometrical representation of IFNs.
From Property 1, we can see that the definition of the similarity measure of IFNs coincides with human’s cognition. Using Definition 4 and Definition 2, we extend the similarity and dissimilarity measures of IFNs to the IFSs and give some new definitions.
As is discussed above, it follows Q (A, C) (x
k
) ≥ Q (A, B) (x
k
) for all x
k
∈ X, which deduces
In Property 2, we note that S (A, B) satisfies (S1)-(S4). Whence, we have the corresponding definition of divergence measure.
Similarly, as a divergence measure of IFSs, this measure should meet (D1)-(D4). Before verifying them, we first obtain the following Lemma.
On the basis of Lemma 1, the following property is further obtained:
(4) Since
In Property 3, it shows that the new definition of divergence measure of IFSs meets (D1)-(D4). Therefore based on the similarity and divergence measures, some relations of both measures are revealed as follows:
In Theorem 1, the relations between similarity and divergence measures of IFSs are characterized, which are of the practical semantics of similarity and divergence features and also coincides with human’s cognition. In what follows we construct a tuple called a closeness degree of IFSs.
It is found that the new definition of intuitionistic fuzzy similarity degree can deal with the shortcomings of “counterintuitive results” in some cases. For example, returning to the question in section 2: Let A1 = {(x, 0.1, 0.9) |x ∈ X}, A2 = {(x, 0.5, 0.3) |x ∈ X} and A3 = {(x, 0.6, 0.3) |x ∈ X}, where X = {x1}. We have A1 ⊂ A2 ⊂ A3. Based on (112), it follows R (A1, A2) = (0.4, 0.5) and R (A1, A3) = (0.4, 0.55). From the semantics viewpoint of both degrees, the similarity degree between A1 and A2 is the same as the one between A1 and A3, while the divergence degree between A1 and A2 is lower than the one between A1 and A3. It leads to R (A1, A2) ⊃ R (A1, A3), which indicates that the closeness degree between A1 and A2 is bigger than the one between A1 and A3 under the condition of A1 ⊂ A2 ⊂ A3, which is consistent with human’s intuition.
In this section, we observe that an intuitionistic fuzzy similarity matrix is well constructed on the basis of the proposed similarity and divergence measure of IFSs, which is of the practical semantics of the similarity and divergence. Based on this matrix, the notion of (α, β)-level cut-sets of an intuitionistic fuzzy similarity degree and its similarity class are given so as to do clustering analysis directly.
This section aims to propose a novel method for intuitionistic fuzzy information clustering directly, which is based on the similarity class under intuitionistic fuzzy (α, β)-level cut-sets. Thus the detailed steps are as follows:
Note that the proposed method can realize the intuitionistic fuzzy clustering analysis based on the intuitionistic fuzzy similarity matrix, which can be well established with the aid of the definitions of the similarity and divergence measures of IFSs.
The following numerical examples show the effectiveness and advantages of our method compared to the previous methods.
Evaluating values of each car with respect to these six factors
Evaluating values of each car with respect to these six factors
The proposed clustering method is used to classify five cars, which involves the following steps:
(1) When 0.8333 < α ≤ 1, there is no similar class such that S
ij
≥ α (1 ≤ i, j ≤ 5) in
(2) When 0.8167 < α ≤ 0.8333, (a) if 0 ≤ β < 0.1167, similarly, each car is classified clearly as one class: {A1}, {A2}, {A3}, {A4}, {A5}; (b) if 0.1167 ≤ β < 1, the cars A2 and A3 are, in this case, clustered into one class and the following form is obtained. Hence, all cars are classified as four classes: {A1}, {A2, A3}, {A4}, {A5}.
(3) When 0.7833 < α ≤ 0.8167, (a) if 0 ≤ β < 0.1167, each car is classified as one class: {A1}, {A2}, {A3}, {A4}, {A5}; (b) if 0.1167 ≤ β < 0.1333, both cars A2 and A3 are clustered into one class. Namely, all cars are clustered into four classes: {A1}, {A2, A3}, {A4}, {A5}; (c) if 0.1333 ≤ β < 1, all cars are classified into three classes: {A1, A2, A3}, {A4}, {A5}.
(4) When 0.7667 < α ≤ 0.7833, (a) if 0 ≤ β < 0.1167, each car is classified as one class: {A1}, {A2}, {A3}, {A4}, {A5}; (b) if 0.1167 ≤ β < 0.1333, the cars A2 and A3 are clustered into one class, thus all cars are divided into four classes: {A1}, {A2, A3}, {A4}, {A5}; (c) if 0.1333 ≤ β < 0.1500, all cars are analogous to classify as three classes: {A1, A2, A3}, {A4}, {A5}; (d) if 0.1500 ≤ β < 0.1583, all cars are classified as two classes: {A1, A2, A3, A5}, {A4}. (e) if 0.1583 ≤ β < 1, all cars are clustered into one class: {A1, A2, A3, A4, A5}.
(5) When 0.7500 < α ≤ 0.7667, (a) if 0 ≤ β < 0.1167, obviously, all cars are clustered into five classes: {A1}, {A2}, {A3}, {A4}, {A5}; (b) if 0.1167 ≤ β < 0.1333, the cars A2 and A3 are clustered into one class. Therefore all cars are classified four classes: {A1}, {A2, A3}, {A4}, {A5}; (c) if 0.1333 ≤ β < 0.1500, all cars are analogous to classify as two classes: {A1, A2, A3}, {A4, A5}; (d) if 0.1500 ≤ β < 1, all cars are still clustered into two classes: {A1, A2, A3, A5}, {A4}. (e) if 0.1583 ≤ β < 1, all cars are clustered into one class: {A1, A2, A3, A4, A5}.
(6) When 0.7167 < α ≤ 0.7500, (a) if 0 ≤ β < 0.1167, all cars are clustered into five classes: {A1}, {A2}, {A3}, {A4}, {A5}; (b) if 0.1167 ≤ β < 0.1333, both cars A2 and A3 are clustered into one class. Hence all cars are classified as four classes: {A1}, {A2, A3}, {A4}, {A5}; (c) if 0.1333 ≤ β < 0.1500, all cars are analogous to cluster into two classes: {A1, A2, A3}, {A4, A5}; (d) if 0.1500 ≤ β < 0.1583, all cars are divided into two classes: {A1, A2, A3, A5}, {A4}. (e) if 0.1583 ≤ β < 1, all cars are classified as one class: {A1, A2, A3, A4, A5}.
(7) When 0.7000 < α ≤ 0.7167, (a) if 0 ≤ β < 0.1167, all cars are clustered into five classes: {A1}, {A2}, {A3}, {A4}, {A5}; (b) if 0.1167 ≤ β < 0.1333, the cars A2 and A3 are divided into one class and thus all cars are classified as four classes: {A1}, {A2, A3}, {A4}, {A5}; (c) if 0.1333 ≤ β < 0.1500, all cars are analogous to classify as two classes: {A1, A2, A3}, {A4, A5}; (d) if 0.1500 ≤ β < 0.1583, all cars are clustered into two classes: {A1, A2, A3, A5}, {A4}. (e) if 0.1583 ≤ β < 1, all cars are to cluster into one class: {A1, A2, A3, A4, A5}.
(8) When 0 < α ≤ 0.7000, (a) if 0 ≤ β < 0.1167, each car is divided clearly into one class: {A1}, {A2}, {A3}, {A4}, {A5}; (b) if 0.1167 ≤ β < 0.1333, both cars A2 and A3 are clustered into one class. Therefore all cars are classified four classes: {A1}, {A2, A3}, {A4}, {A5}; (c) if 0.1333 ≤ β < 0.1500, all cars are clustered into two classes: {A1, A2, A3}, {A4, A5}; (d) if 0.1500 ≤ β < 0.1583, all cars are classified as two classes: {A1, A2, A3, A5}, {A4}. (e) if 0.1583 ≤ β < 1, all cars are clustered into one class: {A1, A2, A3, A4, A5}.
As is discussed above, it is known that there are diverse clustering results of the cars A i (1 ≤ i ≤ 5) under different thresholds α and β, which is refered to Table 2. The thresholds α and β, however, are determined by the constructed IFSM. Therefore, the IFSM construction is a pivotal issue to determine clustering results and computational efforts. On the other hand, it is pointed out [25, 31] that the computation complexity in direct clustering analysis comes mainly from the IFSM computation. Thus, we can compare the elapse time of calculating IFSM to show its computational complexity to a certain extent. To do so, we further conduct experiments with simulated data by comparing with some previous methods in Example 2, which is shown in Table 3 and Fig. 2 for experimental results.
Clustering alternatives of the proposed method under different thresholds a and ß
Example 2. As is stated above, the computational complexity in the process of direct clustering analysis is mainly related with the computations of an IFSM, so we show the computational complexity of clustering analysis directly from consideration of computations of an IFSM using simulated experiments. In the following, we first introduce experimental tool, experimental datasets and comparation with Zhang et al.’s method [27], Feng et al.’s method [35], Wang et al.’s method [36], Li et al.’s method [43] and Kacprzyk et al’s method [37].
(1) Experimental tool: The proposed method in this paper is used to obtain the elapsed time for calculating an IFSM by MATLAB.
(2) Experimental datasets: Datasets, generated by MATLAB at random, are regarded as intuitionistic fuzzy evaluating results of cars on six attributes. Let A = {A1, A2, …, A m } be m cars, each car is described by six attributes: (a) x1-fuel economy; (b) x2-coefficient of friction; (c) x3-price; (d) x4-comfort degree; (e) x5-design; (f) x6-safety coefficient. Evaluating values of each car are represented by IFSs.
Simulated datasets are utilized to achieve purpose of comparison. Suppose the number m of alternatives (cars) is considered fron both sides, which means that m takes discrete poins (i.e., m = 25, 50, 200, 400, 800, 1200, 1600, 2000) and continuous points in different interval of alternatives (i.e., m ∈ [5, 55], [60, 110], [115, 165], [170, 220], [225, 275], [280, 330], [335, 385], [390, 440], [445, 495]). Elapsed time of deriving the corresponding IFSM is measured for each method and the simulated results are shown in Table 3 and Fig. 2.
Comparison of elapsed time of calculating the IFSM with some methods
From Table 3 and Fig. 2, we can see that the proposed method in this paper, to some extent, has some advantages over existing methods as follows:
(1) The proposed method can reduce effectively computational efforts and time by comparation with Zhang et al.’s method (2007), Feng et al.’s method (2014), Wang et al.’s method (2014), Li et al.’s method (2014) and Kacprzyk et al’s method (2016). In particular Wang et al.’s method. Moreover, the disparity of elapsed time is gradually increasing between the proposed method and Wang et al.’s method as numbers of alternatives increase in a certain range. Therefore the proposed method can reduce time-consuming in computation for practical applications.
(2) The proposed method mainly focuses on the practical semantics of membership and non-membership degrees of the intuitionistic fuzzy similarity measure z ij with similarity and divergence features. Based on the proposed similarity and divergence measures, it can overcome the drawbacks of “counterintuitive results” of the existing intuitionistic fuzzy similarity measures in some cases, when the IFSM is constructed to do direct clustering analysis.
It is clear that an approach to IFSM construction in this paper can save the time in computation compared with existing methods [27, 43]. In light of the conclusions presented in [27, 33], it shows the reduction in computational complexity of clustering analysis directly to some extent.

Comparison of elapsed time of calculating the IFSM with some methods.
By employing similarity and divergence measures of IFSs defined in this paper, we provide the construction of intuitionistic fuzzy similarity degree with a new method, which gives the practical semantics meaning in the membership and non-membership degrees with similarity and divergence properties respectively. Due to our method, we can deal with the “counterintuitive problem” well. Based on that, we further establish an intuitionistic fuzzy similarity matrix and thus propose a method for intuitionistic fuzzy information clustering directly. Finally, two examples are analyzed by computation experiment to illustrate the effectiveness and advantages of the proposed method. The experimental results show that the proposed method, to some extent, can reduce computation efforts and time compared to some previous methods. In the future, we will mainly focus on the applications of the clustering method and results of this paper in practice and its extension to interval type-2 fuzzy clustering [49].
Footnotes
Acknowledgments
The authors appreciate receiving helpful suggestions from anonymous referees which improve the quality of the paper. This work was supported by the Natural Science Foundation of China (Nos. 71671086, 61773208, 61473157, 71732003, 61876157 and 61876079), the National Key Research and Development Program of China (No.2016YFD0702100), the Fundamental Research Funds for the Central Universities (No. 011814380021), the Central military equipment development of the “13th Five-Year” pre research project (No. 315050202) and Nanjing University Innovation and Creative Program for PhD candidate (No. CXCY17-08).