
Abstract
The intuitionistic fuzzy InterCriteria analysis (ICrA) is a new method for correlation analysis, which is based on the concepts of index matrices (IMs) and intuitionistic fuzzy sets (IFSs), aiming at detecting of the dependencies between pairs of rating criteria in both clear and uncertain environments. In the present paper, which is an extension of [39], our aim is to extend ICrA to multidimensional ICrA (n-D ICrA) under intuitionistic fuzzy environment for situations where the evaluations of the objects against multidimensional criteria are completely unknown and to show its efficiency through an application in identifying correlations between pairs of criteria when referred to actual data gathered through estimates of a restaurant’s kitchen staff over a three-year period in Bulgaria. We also present a comparative analysis of the correlations between the evaluated criteria of the kitchen staff, on the basis the application of the correlation methods of ICrA, Pearson (PCA), Spearman (SCA) and Kendall (KCA). The four-correlation analysis yielded very similar correlation coefficients, but only the ICrA can be applied to intuitionistic fuzzy evaluations. It is observed that considerable divergence of the ICrA results from those obtained by the other classical correlation analyzes, is only found when the input data contains mistakes.
Introduction
The correlation is an important statistical tool in desicion making. In real world data are often fuzzy [22] or intuitionistic fuzzy [10]. The measuring correlation coefficient between two variables involving fuzziness is a need and computational procedures are challenging. The concept of correlation coefficient of IFSs has been first studied by Gerstenkorn and Manko [29]. Using the statistical viewpoint, the IFS correlation coefficient was defined in [2, 43]. In [25], a positive and negative type of a correlation was proposed, but the hesitation margin of IFSs does not participate in the calcullations. The proposed correlation coefficient in [6] takes into account the membership and non-membership values, and the hesitation margin of IFSs. The ICrA is a new statistical method [16, 20] for calculating pairwise dependencies (correlations) between each pair of criteria for evaluation of objects. The complexity of the ICrA algorithm is O (m2n2), which is polynomial in mn [30].
The advantages of the ICrA over the three classic correlation analyses PCA, SCA and KCA are: It is only based on comparisons “<, > , =”, existing between the evaluations of the objects against the system of criteria, rather than on their numerical values, which makes computations faster than the other three correlation analysis methods. It can be applied not only to clear data but also to incomplete and uncertain one.
The ICrA method [20] is based on the concepts of IFSs and IMs. IFSs were first defined by Atanassov [10, 14] as an extension of the concept of fuzzy sets defined by Zadeh [22]. The concept of IMs is introduced in [11] and described in [16, 37]. The intuitionistic based method of ICrA was developed in [20] to handle cases of multicriteria decision making, where measuring according to some of the criteria is slower, more expensive or unclear, which results in delaying or raising the cost of the process of decision making [27]. The ICrA allows finding statistically meaningful relations between a lot of criteria which characterize multiple objects. Later the ICrA was extended theoretically and was further applied to two-dimensional interval-valued and three-dimensional intuitionistic fuzzy data [21, 40]. The approach has been discussed in a number of papers considering universities’ rankings [7, 32], electronics [23], neural networks [9, 27], metaheuristic algorithms [26], economic investigations [31, 39], medical and chemistry investigations [27, 28], etc.
The present paper, which is a continuation of [39], proposes for the first time a new form of ICrA (n-D ICrA) to be applied to n-dimensional intuitionistic fuzzy data in uncertain environments. Here, the ICrA approach is applied to the data over a three-year period with estimates of the kitchen staff at a fast food restaurant, part of a chain of restaurants in Burgas, Bulgaria. The staff assessment system in the restaurant is tested with four methods – ICrA, Pearson’s, Spearman’s and Kendall’s rank correlation analyzes to show the advantages of the proposed approach. The comparison of the results obtained shows that there is no comparative difference between those, obtained from the ICrA and the other three classic correlation analyzes. It is observed that considerable divergence of the ICrA results from those obtained by the other classical correlation analyzes, is only found when the input data contains mistakes. The originality of the paper comes from the proposed multidimensional ICrA over intuitionistic fuzzy evaluations of a set of objects by a set of criteria. The main contributions of the paper lie in its proposition for a new form of ICrA over n-dimensional intuitionistic fuzzy evaluations on the one hand, and its study of the effectiveness of the proposed hybrid method combining fuzzy logic with classic correlation analysis to optimize the kitchen staff rating system of the restaurant in Bulgaria on the other.
The rest of this paper is structured as follows: In Section 2, are discussed n-dimensional extended IMs (n-D EIM, see [17]) and the concepts of intuitionistic fuzzy pairs (IFPs, see [15]). Section 3 describes the n-D ICrA method, which is based on intuitionistic fuzzy logic and n-D EIM. In Section 4, we research the kitchen staff assessment system in a fast food restaurant and apply the 3-D ICrA to optimize the assessment system in the surveyed company. Finally, in Section 5, the obtained results are compared with those obtained from Pearson’s, Spearman’s and Kendall’s rank correlation analyzes. Section 6 offers the conclusion and outlines aspects for future research.
Short remarks on IMs and IFPs
Short notes on intuitionistic fuzzy pairs
Let us start with some remarks on intuitionistic fuzzy logic from [14, 15].
To each proposition (sentence) of classical logic (e.g., [3]), we juxtapose its truth value: truth – denoted by 1, or falsity – denoted by 0. In fuzzy logic [22], the truth value, called “truth degree”, is a real number in the interval [0, 1]. In the intuitionistic fuzzy case (see [13]), one more value – “falsity degree” – is added. It is again in the interval [0, 1]. Thus, to the proposition p, two real numbers, μ (p) and ν (p), are assigned with the following constraint: μ (p) + ν (p) ≤1 .
The IFP is an object with the form 〈a, b〉, where a, b ∈ [0, 1] and a + b ≤ 1, that is used as an evaluation of some object or process. Its components (a and b) are interpreted as degrees of membership and non-membership. Let us have two IFPs x = 〈a, b〉 and y = 〈c, d〉. In [15, 38] were defined the relations:
A set of the following operations #
p
, (1 ≤ p ≤ 10) from [13] has been using for constructing a scale in [41], so that the index matrix elements are ordered:
Let for brevity
Definition of an n-dimensional extended IM (n-D EIM)
Let
Scaled aggregation operations over n-D IFIM
This subsection introduces for the first time some scaled aggregation operations extensions, following the ideas from [35, 41] over n-D EIM with elements IFPs. Let us denote this type of IM as n-D IFIM.
Let an n-D IFIM A = [K1, K2, . . . , K n , { ak1,s1,k2,s2,...,kn,s n }] be given, where K i = {ki,1, ki,2, . . . , ki,m i }, m i ≥ 1 and ak1,s1,k2,s2,...,kn,s n = 〈μk1,s1,k2,s2,...,kn,s n , νk1,s1,k2,s2,...,kn,s n 〉
(for 1 ≤ i ≤ n and 1 ≤ s i ≤ m i ), and let k1,0 ∉ K1, k2,0 ∉ K2, . . . , kn,0 ∉ K n .
Following [16, 36], let us start with the definition of the operation “transposition” of n-D IFIM.
For the standard 2-D IFIM, there are 2 (= 2!) IFIM, related to this operation: the standard IFIM and its transposed IFIM, while for n-D IFIM, there are (=n!) cases: the standard n-D IFIM and (n ! -1) different transposed n-D IFIM. Two of these analytical forms of the separate transposed n-D IFIMs are as follows: [K1, K2, . . . , K
n
, { ak1,s1,k2,s2,...,kn,s
n
}] [1,2,...n] = [K1, K2, . . . , K
n
, { ak1,s1,k2,s2,...,kn,s
n
}] ;
Let us define for the first time the scaled aggregation operations over this type of IMs by one dimension K
i
(for i = 1, . . . , n) and for
The operations
Let be given index set K* = {K
d
1
, . . . , K
d
x
, . . . , K
d
u
} and V* = {kd1,0, …, kd
x
,0, …, kd
u
,0}, where kd
x
,0 ∉ K
d
x
for x = 1, . . . , u. The definition of the aggregation operation by the dimensions, belong to K* is:
In this section, a new extension of ICrA (n-D ICrA), based on n-dimensional intuitionistic fuzzy evaluations is introduced for the first time. Let us have an n-D EIM A [K1, K2, . . . , K
n
, {ak1,s1,k2,s2,...,kn,s
n
〉}] and
C1,p is a criterion, O2,q is an object, a
C
C1,p,O2,q,k3,s3,...,kn,s
n
is an evaluation of an object O2,q (1 ≤ q ≤ m2) against a criterion C1,p (1 ≤ p ≤ m1) in the conditions of other (n - 2) factors (time, location, etc.) and can be a real number, IFP or another object, including the empty place in the matrix, marked by ⊥, that is comparable about relation R with the other a-objects, so that for each x, y, i, k3,s3, . . . , kn,s
n
: R (aC1,i,O2,x,k3,s3,...,kn,s
n
, aC1,i,O2,y,k3,s3,...,kn,s
n
) is defined.
Let
Let for each fixed ordered (n - 2)-index set 〈k3,s3, . . . , kd,s
d
, . . . , kn,s
n
〉(1 ≤ d ≤ m
d
)
Let
Let
Now, for every k, l, such that 1 ≤ k < l ≤ m1 and for m2 ≥ 2, we define
Hence,
In the simple form of the optimistic approach the α- and β-constants are α o = 1, α⊥ = 1, β o = 0, β⊥ = 0 .
Then μC1,k,C1,l,k3,s3,...,kd,s
d
,...,kn,s
n
In the simple form of the pessimistic approach the α- and β-constants are α o = 0, α⊥ = 0, β o = 1, β⊥ = 1 .
Then μC1,k,C1,l,k3,s3,...,kd,s
d
,...,kn,s
n
Follow the ideas from [21], let us propose the uniform (α - β)-approach as follows: let
Then
We can construct the IM R that determines the degrees of correspondence between criteria C1,1, . . . , C1,m1 using the values for pairs (5)
〈μC1,k,C1,l,k3,s3,...,kd,s d ,...,kn,s n , νC1,k,C1,l,k3,s3,...,kd,s d ,...,kn,s n 〉:
Let be given index set V* = {k3,0, …, kd
x
,0, …, kn,0} , where kd
x
,0 ∉ K
d
x
for 1 ≤ x ≤ u . Let us apply the following (scaled) aggregation operation (3) to the n-D IM R by the dimensions k3,s3, . . . , kn,s
n
where 1 ≤ p ≤ 10. If we use the operation
The last step of the algorithm is to determine the degrees of correlation between groups of indicators depending of the chosen thresholds for μ and ν from the user. We call that criteria C1,k and C1,l are in (γ, δ)-positive consonance, if μC1,k,C1,l,k3,s3,...,kd,s
d
,...,kn,s
n
> γ and νC1,k,C1,l,k3,s3,...,kd,s
d
,...,kn,s
n
< δ ; (γ, δ)-negative consonance, if μC1,k,C1,l,k3,s3,...,kd,s
d
,...,kn,s
n
< γ and μC1,k,C1,l,k3,s3,...,kd,s
d
,...,kn,s
n
> δ ; (γ, δ)-dissonance, otherwise.
The ICrA pairs are calculated using the software described in [24]. The n-D ICrA works with two IMs
In this section, the ICrA method is applied to data containing values of the kitchen staff’s evaluation criteria at a fast food restaurant over a three year period. The evaluation system contains the following criteria: – Criterion C1 – Knows all the dishes; – Criterion C2 – Complies with product weights; – Criterion C3 – Respects ways to prepare; – Criterion C4 – Follows the process; – Criterion C5 – Rotational principle; – Criterion C6 – Performs activities outside his duties; – Criterion C7 – Hygiene, cleaning; – Criterion C8 – Works with machines and equipment; – Criterion C9 – Filing sheets; – Criterion C10 – Adheres to the restaurant rules; – Criterion C11 – Working spirit; – Criterion C12 – Skills for correct presentation of information; – Criterion C13 – Positivism towards the working environment.
The input data for the ICrA are presented in a 3-D IFIM A [C, O, H] with a structure such as (4), where its elements are assessments of the employees O = {O1, O2, …, O m } by criteria from the set C = {C1, C2, …, C13} in a time-moment h g ∈ H for g = 1, 2, 3. The initial data deviation is equal to 0,70. The results, obtained from the application of the software that implements ICrA [24], are in the form of two IMs (see Figs. 1, 2), containing, respectively, the membership and the nonmembership parts of the intuitionistic fuzzy correlations detected between each pair of criteria. The all cells of the matrix are coloured in the greyscale, with the highest values coloured in the darkest shade of grey, while the lowest ones are coloured in white. Of course, every criteria perfectly correlates with itself, so for any i (1 ≤ i ≤ 13) the value μC i ,C i = 1, and νC i ,C i = πC i ,C i = 0 . The two IMs are obviously symmetrical according to the main diagonals.
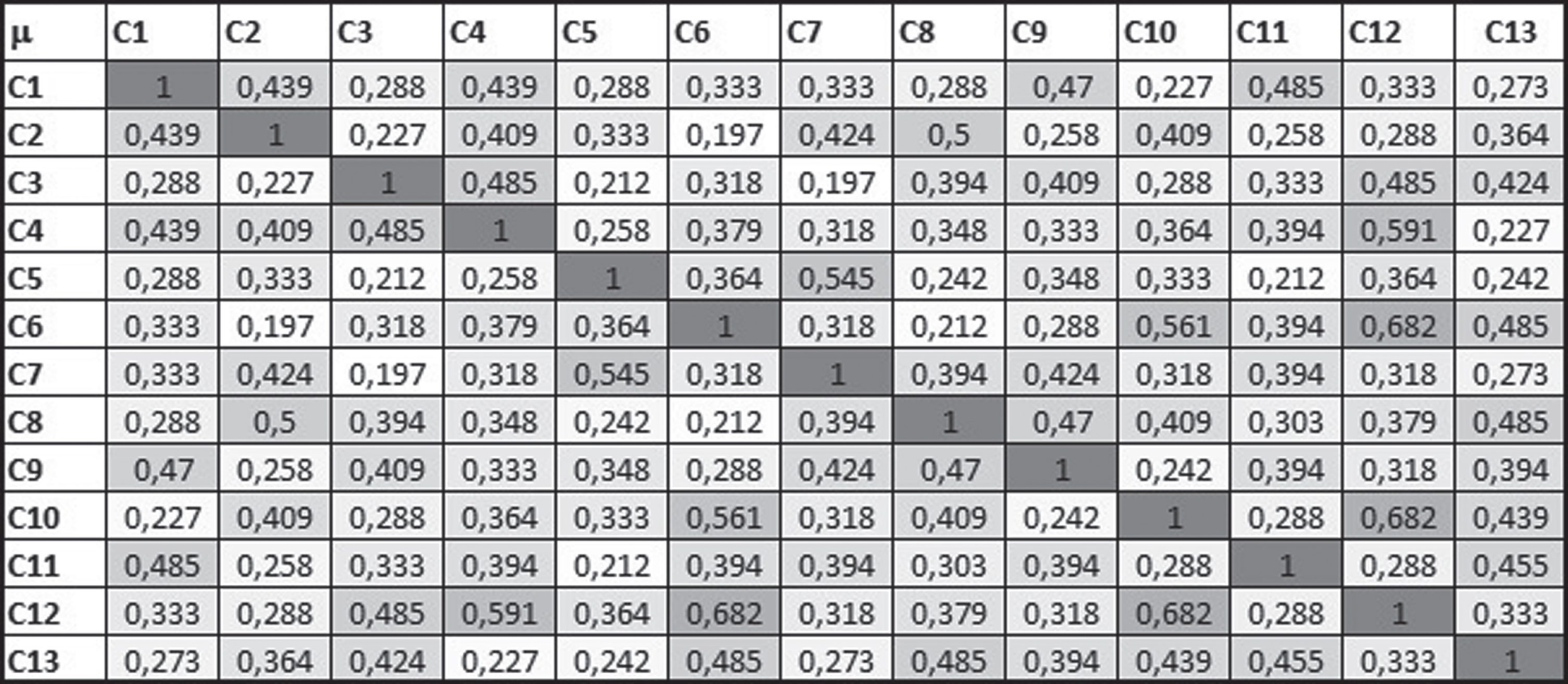
Membership parts of the IFPs, giving the InterCriteria correlations.
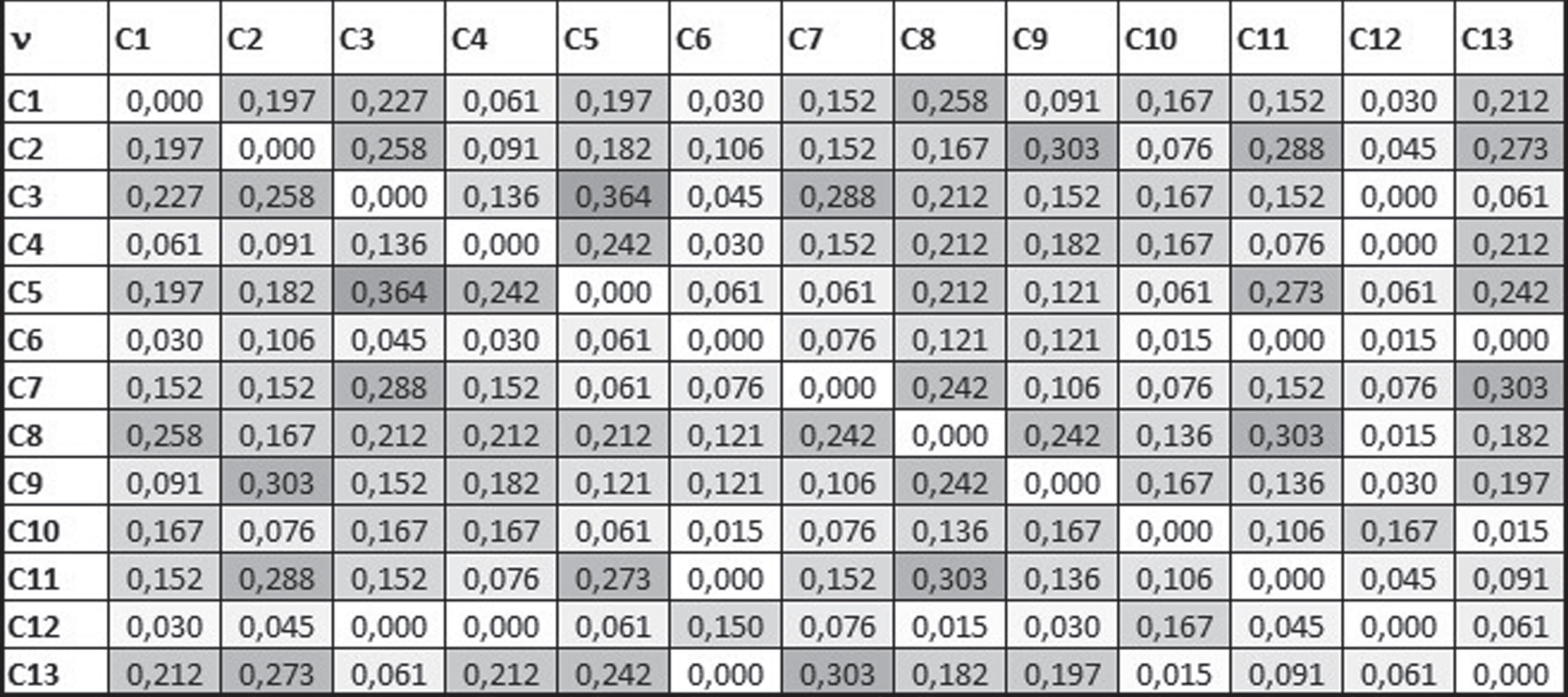
Non-membership parts of the IFPs, giving the InterCriteria correlations.
Taking the results produced by the 3-D ICrA, we plot them onto the intuitionistic fuzzy (IF) interpretational triangle in Fig. 3.

The results of ICrA, plotted onto the IF interpretational triangle.
Table 1 describes the type of correlations, obtained between the pairs of criteria follow the scale from [19]:
Correlations between the pairs of criteria
Calculating the distances [5] of the intercriteria IFPs to the pair 〈1, 0〉 using
Ordering of the correlating pairs, with respect to the distance from 〈1, 0〉
The following conclusions can be obtained after the application of the ICrA: There is no pair of criteria that are in a strong positive, a positive and a weak positive consonance, a negative and a strong negative consonance. The lowest detected correlations are between the pairs of criteria C1 - C10, C2 - C3, C3 - C5, C2 - C6, C3 - C7, C5 - C11, C5 - C13 and C2 - C6 . The highest correlation has been observed between pairs C12 “skills for correct presentation of information” and C6 “performs activities outside his duties”, and C10 “adheres to the restaurant rules”. The other observed dissonance is between the criteria pairs C12 and C4 “follows the process”. The open dependencies between the criteria help the manager in the efficient management of kitchen staff in the restaurant. The positivism towards the working environment is related to the willingness of the kitchen workers to perform activities outside its duties, to follow the restaurant rules and to present correct the information. The indicators C1 “know all the dishes” is in strong dissonance with C11 “working spirit”, C3 “respects preparation rules” is in a strong dissonance with C12 “skills for correct presentation of information”. The criteria C10 “adheres to the restaurant rules” and C11 “working spirit” are related with C13 “positivism towards the working environment”. No correlation dependencies of a strong positive and a positive consonance between the pairs of criteria after the application of the ICrA, which means that the assessment system in the fast food restaurant is optimized.
In this section is shown that the ICrA, PCA, SCA and KCA can be helpful for the in-depth analysis of data sets with kitchen staff evaluations in a restaurant in Bulgaria. These four approaches complement each other, but only ICrA can be applied to vague and incomplete data. The section has compared the results obtained by the classical Pearson’s, Spearman’s and Kendall’s rank correlation [1] analyzes with these from ICrA after their applying to the real dataset, containing the kitchen staff evalutions against criteria in a fast food restaurant. Let the confdence interval for correlation is 95% and p-value indicates the risk of concluding that a correlation exists - when actually, no correlation exists - is 5%.
The Table 3 describes the strongest correlations between the criteria obtained after the application of ICrA, PCA, SCA and KCA.
The strongest correlations between the pairs of criteria according ICrA, PCA, SCA and KCA
The strongest correlations between the pairs of criteria according ICrA, PCA, SCA and KCA
The following minor differences are observed between these four methods of correlation analysis: according to the ICrA, the criterion C6 “performs activities outside his duties” is in the strongest correlation with the criterion C12 “skills for correct presentation of information” (〈μ (C6, C12) , ν (C6, C12) 〉 = 〈0, 68 ; 0, 02〉); according to the PCA, SCA and KCA, C6 is in the strongest correlation relation 0,43 with the criterion C11 “working spirit”, and the correlation coefficient between C6 and C12 is equal to -0,09; -0,09 and -0,09 respectively according to the method PCA, SCA and KCA; according to the ICrA, the criterion C11 “working spirit” is in the strongest correlation relation with the criterion C1 “know all the dishes” (〈μ (C11, C1) , ν (C11, C1) 〉 = 〈0, 49 ; 0, 15〉; according to the PCA, SCA and KCA, the criterion C11 is in the strongest correlation relation 0,43 with the criterion C6 “performs activities outside his duties”; the correlation coefficient between C11 and C1 is equal respectively to 0,27; 0,34 and 0,31 according to the method PCA, SCA and KCA.
The last two differences between the criteria correlations are due to high hesitancy degree π of the IFPs 〈μ (C6, C12) , ν (C6, C12) 〉 (π (C6, C12) =0, 30) and 〈μ (C11, C1) , ν (C11, C1) 〉 (π (C11, C1) =0, 36).
The Table 4 describes the strongest correlations between the criteria obtained after the application of ICrA, PCA, SCA and KCA above the original data and the data with mistakes. The columns with labels “ICrA1”, “PCA1”, “SCA1” and “KCA1” contain the criteria with the strongest correlations after applying these analyzes above the original data. The comparison of the results obtained shows that there is no comparative difference between those, obtained from the ICrA and the other three classic correlation analyzes.
The strongest correlations (CORs) between the pairs of criteria according ICrA, PCA, SCA and KCA
With a view to compare the results of ICrA with those obtained by the other classical correlation analyzes on the input data containing the errors (for example, shifting the decimal separator) let us simulate mistakes in the initial data as a result of misplacing the decimal separator with one position to the right in the estimates by the first two criteria to all the kitchen staff of the restaurant. The data deviation is equal to 17,20. We apply the four statistical analyzes to the data to determine that the differences in results between ICrA and the other statistical analyzes are due to data mistakes. The columns in the Table 4 with labels “ICrA2”, “PCA2”, “SCA2” and “KCA2” contain the criteria with the strongest correlations after applying these analyzes above the data with mistakes.
With a view to compare the results of ICrA with those obtained by other classical correlation analyzes on the input data, let us change the accuracy of the estimates of the first three kitchen workers against the evaluation criteria to a second digit after the decimal point. The data deviation is 0,50. The columns with labels “ICrA3”, “PCA3”, “SCA3” and “KCA3” in the Table 4 contain the criteria with the strongest correlations after applying these analyzes above the data with diffrent accuracy.
Comparing the results of ICrA, PCA, SCA and KCA on the initial data and these with mistakes and different accuracy, it is observed that considerable divergence of the ICrA results from those obtained by the other classical correlation analyzes, defined in [1, 4], is only found when the input data contain mistakes. So the use of them together can be taken as a way of detecting errors in the input data (e.g., shift of the decimal separator) or the information noise. Although the volume of testing data is small and its numerical interval is small, differences between the four statistical analyses were still obtained. In the future, we plan to perform similar tests on a larger volume of data belonging to a wider numerical range.
In this paper it is proposed for the first time to extend the ICrA to multidimensional over intuitionistic fuzzy evaluations against n - dimensional criteria in uncertain environments. The n-D ICrA approach is applied to establish relations and dependencies between staff’s evaluation criteria over a three-year period at a fast food chain of restaurants in Bulgaria and optimize its rating system. No correlation dependencies of positive consonance between the pairs of criteria were found after the application of 3-D ICrA, which means that the kitchen staff assessment system in the fast food restaurant is optimized. The comparison of the results obtained after the application of the classic statistical rank correlation analyses to the real data, containing the evaluation of the kitchen staff against the criteria of the evaluation system, shows that there is no comparative difference between those, obtained from the ICrA and the other three classical correlation analyses, but only the ICrA can be applied to retrieve information of other types of multidimensional fuzzy data. It is observed that considerable divergence of the ICrA results from those obtained by the other classical correlation analyzes, is only found when the input data contains mistakes. So the use of them together can be taken as a way of detecting errors in the input data (e.g., shift of the decimal separator) or the information noise.
In our next piece of research, we will describe ICrA with n-dimensional interval-valued intuitionistic fuzzy evaluations [12, 18]. In the future, new types of ICrA method will be applied in different areas.