
Abstract
Like many open-source technologies such as UNIX or TCP/IP, Hadoop was not created with Security in mind. Hadoop however evolved from the other tools over time and got widely adopted across large enterprises. Some of Hadoop’s architectural features present Hadoop its unique security issues. Given this security vulnerability and potential invasion of confidentiality due to malicious attackers or internal customers, organizations face challenges in implementing a strong security framework for Hadoop. Furthermore, given the method in which data is placed in Hadoop Cluster adds to the only growing list of these potential security vulnerabilities. Data privacy is compromised when these critical and data-sensitive blocks are accessed either by unauthorized users or for that matter even misuse by authorized users. In this paper, we intend to address the strategy of data block placement across the allotted DataNodes. Prescriptive analytics algorithms are used to determine the Sensitivity Index of the Data and thereby decide on data placement allocation to provide impenetrable access to an unauthorized user. This data block placement strategy aims to adaptively distribute the data across the cluster using innovative ML techniques to make the data infrastructure extra secured.
Keywords
Introduction
A distributed system is a system that includes multiple components that are located on different machines in such a way that they can communicate and coordinate their actions to appear as one single system or machine. Finding solutions to advanced issues is achieved by the divide and conquer approach (subdividing the bigger issue into small issues and solving them in parallel) which is hidden from outside the network. This outlook towards big data analytics has paved the way to several compute-intensive processing tasks. Big data is a term that describes the large volume of data – both structured and unstructured. It is commonly referred for as a group of information sets that are massive and troublesome for analyses to be performed using traditional processing tools. This is where the role of distributed processing comes into play for performing big-information management and analytics.
Hadoop is an open-source implementation software framework that is used for running applications and also storing data on clusters using reliable and scalable distributed processing. The most important infrastructure in Hadoop comprises of Master nodes and Slave nodes. Supervision of information storage is handled by processes running in master node and computations on the data stored in Hadoop are handled by processes running in slave nodes. A typical HDFS cluster can have up to 5 daemons namely NamNode, DataNode, Secondary NameNode, Job Tracker, and Task Tracker. However, the 2 most important daemons (which operate in a master-slave pattern) are a) NameNode daemon which is used to hold the “metadata” which is typically stored on the RAM or the Hard-Disk. NameNode is the single mode of failure in Hadoop. NameNode also performs the task of managing the storage system namespace and storage system tree. It also serves as the Node for all the files and directories within the storage system trees. The massive Hadoop Distributed File System takes replicas of files constantly and is created to satisfy performance and handiness needs b) DataNode: While the NameNode stores Metadata, the actual data is stored on DataNode. The size of the data defines the number of DataNodes.
A standard concern while using such a distributed system is that the security related to these clusters. Moreover, differing types of information have their own set of associated issues with relevancy the structure of these files. Here we describe a prescriptive, adaptive, and intelligent system that identifies patterns in these data to group them with similar structure and security concerns together so that they can be handled appropriately. Specifically, we use the Doc2Vec algorithm to convert the representation of each file to be stored into a vector, which can then be quantitatively analyzed. Section II of this paper talks about the default block placement algorithm of Hadoop; Section III talks about the machine learning models. Section IV converses about the related research; Section V discusses the proposed semi-supervised/unsupervised learning-based Secure Data Placement Strategy for Hadoop (HadoopSec). Section VI concludes and discusses the future scope of this work.
Default data-block placement strategy for HDFS
Place the file in any of the directories where MS.
In the Hadoop file system, a file is divided into many splits based on a fixed size of either 64 mb or 128 mb configured in the config file (using config parameter: dfs.block.size). Also, in HDFS, all these information chunks are replicated and stored into many datanodes. This number is also configured in the same config file (Config parameter: dfs.replication). In this way fault tolerance is achieved in Hadoop. HDFS uses default block placement strategy which is rack-aware in the sense that if a block is assigned to one rack then other copies of the block will be assigned to other racks which help in achieving fault tolerance in case of any failure.
The strategy of the HDFS default block placement policy is as below [8]: The first block is placed on a datanode either where the client is located or in other cases randomly Then the second copy is placed on a datanode that is residing in different rack compared to the first one The Third copy is placed on other datanode in the same rack as the second one. Remaining copies are distributed randomly such that there are no more than 2 blocks assigned to the same rack.
To minimize network traffic in the master node (name node daemon) HDFS uses a method called pipelining. When a job/client writes the first block replica to a node, the further writing the second replica to a random off-rack node is the responsibility of that data node. Further, the other second node is itself responsible for writing the third replica to a random node. The pipelining result is that network traffic between client and cluster is reduced because the client or the job writes only one replica, instead of all other replicas
Doc2Vec and k-means algorithm
Doc2Vec
Word2Vec is a shallow, two-layer neural network which is trained to reconstruct linguistic contexts of words. As an input, it typically takes a large blob or corpus of words as its input and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space.
Word vectors are positioned in the vector space such that words that share common contexts in the corpus are in proximity to one another in the space. Word2Vec is a particularly computationally-efficient predictive model for learning word embeddings from raw text.
It comes in two flavors, the Continuous Bag-of-Words (CBOW) model and the Skip-Gram model. Algorithmically, these models are similar.
CBOW predicts target words (e.g. ‘mat’) from the surrounding context words (‘the cat sits on the’). Statistically, it affects that CBOW smoothens over a lot of the distributional information (by treating an entire context as one observation). For the most part, this turns out to be a useful thing for smaller datasets.
Skip-gram on the other hand, predicts surrounding context words from the target words (inverse of CBOW).
Statistically, skip-gram treats each context-target pair as a new observation, and this tends to do better when we have larger datasets.
The architecture is similar to an autoencoder’s one, you take a large input vector, compress it down to a smaller dense vector and then instead of decompressing it back to the original input vector as you do with autoencoders, you output probabilities of target words. Words are fed as one-hot vectors, which is a vector of the same length as the vocabulary, filled with zeros except at the index that represents the word we want to represent, which is assigned “1”. The hidden layer is a standard fully connected (Dense) layer whose weights are the word embeddings. The output layer outputs probabilities for the target words from the vocabulary.
k-Means clustering
K-Means starts by randomly defining k centroids. From there, it works in iterative (repetitive) steps to perform two tasks: Assign each data point to the closest corresponding centroid, using the standard Euclidean distance. In layman’s terms: the straight-line distance between the data point and the centroid. For each centroid, calculate the mean of the values of all the points belonging to it. The mean value becomes the new value of the centroid.
Once step 2 is complete, all the centroids have new values that correspond to the means of all of their corresponding points. These new points are put through steps one and two producing yet another set of centroid values. This process is repeated over and over until there is no change in the centroid values, meaning that they have been accurately grouped. Or, the process can be stopped when a previously determined maximum number of steps has been met. Simply put, the clustering algorithm can be explained as in the below pseudo-code:
Compute pairwise co-relations between all vectors in F
sub
Find the vector with the largest number of “close” neighbors, with “close” defined as correlation> γ
Add this vector to the list of cluster centers, and remove it and all its close neighbors from F
sub
Choose new F
sub
, a subset of vectors from F
Compare F
sub
, vectors to all previously found clusters:
Compute correlation with all cluster centers Identify any vectors in F
sub
that are “close” to previously found centers (correlation> γ)
Remove these vectors from F
sub
Continue clustering logic from:
//clustering step from F
sub
Limitations
There are primarily 2 major limitations of this approach used in HadoopSec: The HadoopSec algorithm assumes the input data to be either textual or numeric. The Doc2Vec algorithm which is used to translate this input data into a vector cannot do the same for other input source formats like speech, image, music, or video formats. With the same approach retained, we can however introduce an ensemble approach of multitude algorithms to tackle this problem. The Doc2Vec algorithm could be very difficult to train as it uses the softmax function in the output layer given the fact that the number of categories is too large (the size of vocabulary). Though approximation algorithms like negative sampling (NEG) and hierarchical softmax (HS) are proposed to address the issue, other problems creep in. For example, the word vectors by NEG are not distributed uniformly, they are located within a cone in the vector space hence the vector space is not sufficiently utilized.
Related work
Authors of paper [4] propose Sensitive Data Detection [SDD] Framework which objectives at identifying facts that define privacy in a Hadoop dataset. This paper mechanizes the locating of sensitive data defined totally on the whole dataset and its associated datasets. Data Similarity Analyzer (DSA) developed using Markov’s set of rules calculates the similarity among datasets by combining the context similarity and usage design similarity. The benefit is that sensitive data can be treated as in keeping with the requirements. The downside is that this paper does not consider the core hdfs replication of data and the average processing time in Hadoop as this approach will add a further overhead concerning the typical execution time.
Authors of [5], describes the need for Hadoop for heterogeneous clusters that processes data intensively like data mining systems. The key reason for MapReduce performance is because of data-locality. In a cluster that contains a combination of low to high computing nodes, there will be always data movement from a low node to the high node. This will in turn reduce the performance of the cluster and will also lead to higher data balancing runs. The author of this paper proposes an algorithm for data reorganization which will support data placement in the cluster and help in reducing this issue. Based on the ratio of the computing power of the cluster nodes, splits of a file are distributed so that processing of data local to the node in discussion completes around the same time in all nodes. The benefit of this work is a better computing power utilization of the cluster. The disadvantage is that the paper does not talk about the cascading effects on data replication.
Sensitivity-aware secure block placement strategy for Hadoop (HadoopSec)
HadoopSec architecture and dataflow
Hadoop Sensitive-Aware Secure Block Placement Strategy (HadoopSec) attempts to provide resolution to the following two issues concerning sensitivity zone implementation on Hadoop. One, it attempts to distribute blocks to respective sensitivity zones deployed across cluster nodes based on a sensitive index of the file or directory. It uses a prescriptive analytical algorithm to compute the sensitivity level (SI) if not provided by the client. This approach will help to resolve the “Chinese-wall” security problem. Two, it also performs check on the disk usage of different sensitive zones and rebalances them based on the threshold configured by the admin. It uses another prescriptive based analytical approach to revisit the sensitive index calculated.
Figure 1 shows the process flow for Module-I (HadoopSec Multi-Model Sensitivity Labelling Engine). Figure 2 shows the overall architecture of HadoopSec. Figure 3 shows the design and workflow of the HadoopSec Module-II (HadoopSec Rebalancing Analytics Engine) in Hadoop.
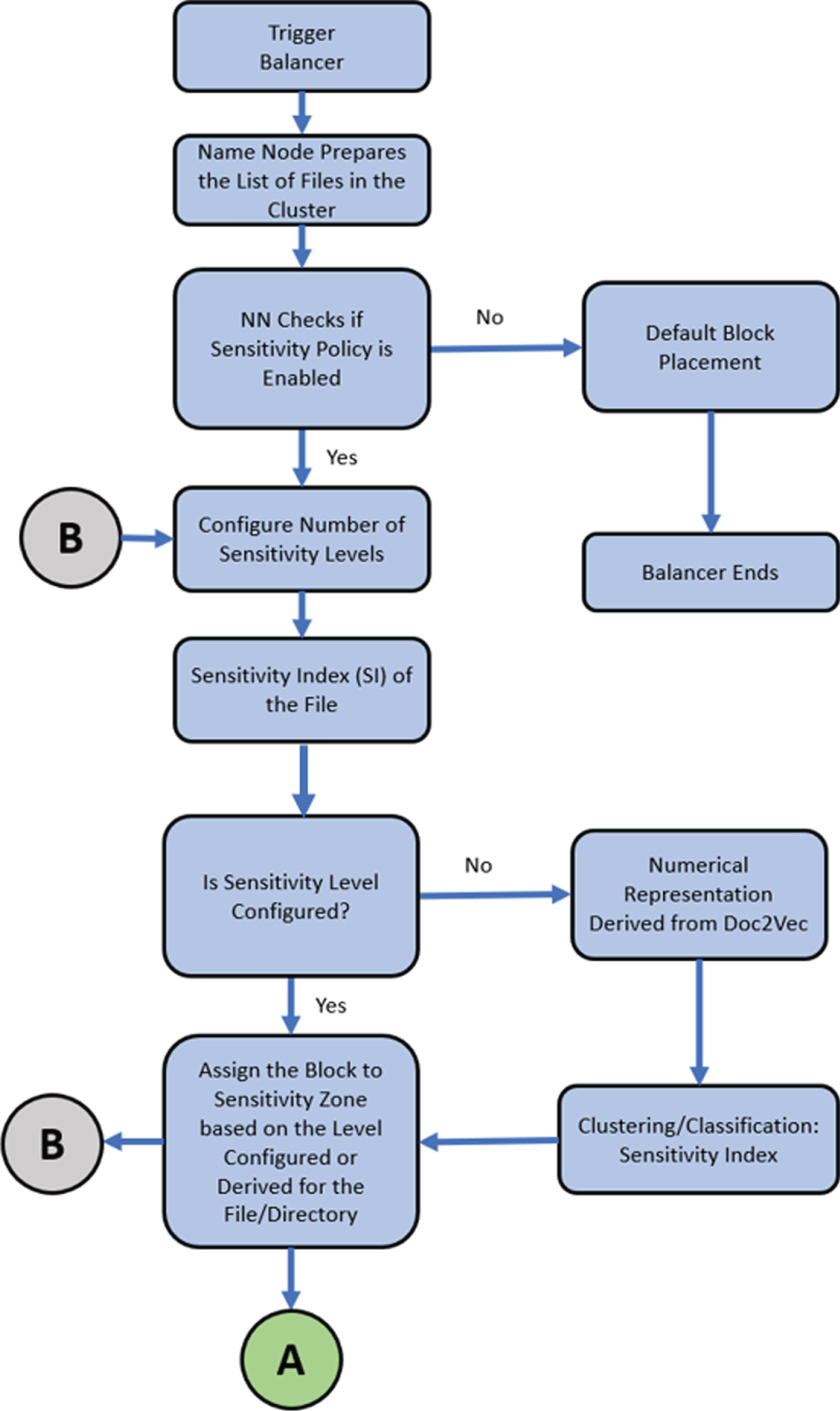
HadoopSec-Module 1: Process Flow.

HadoopSec-Module II: Process Flow.
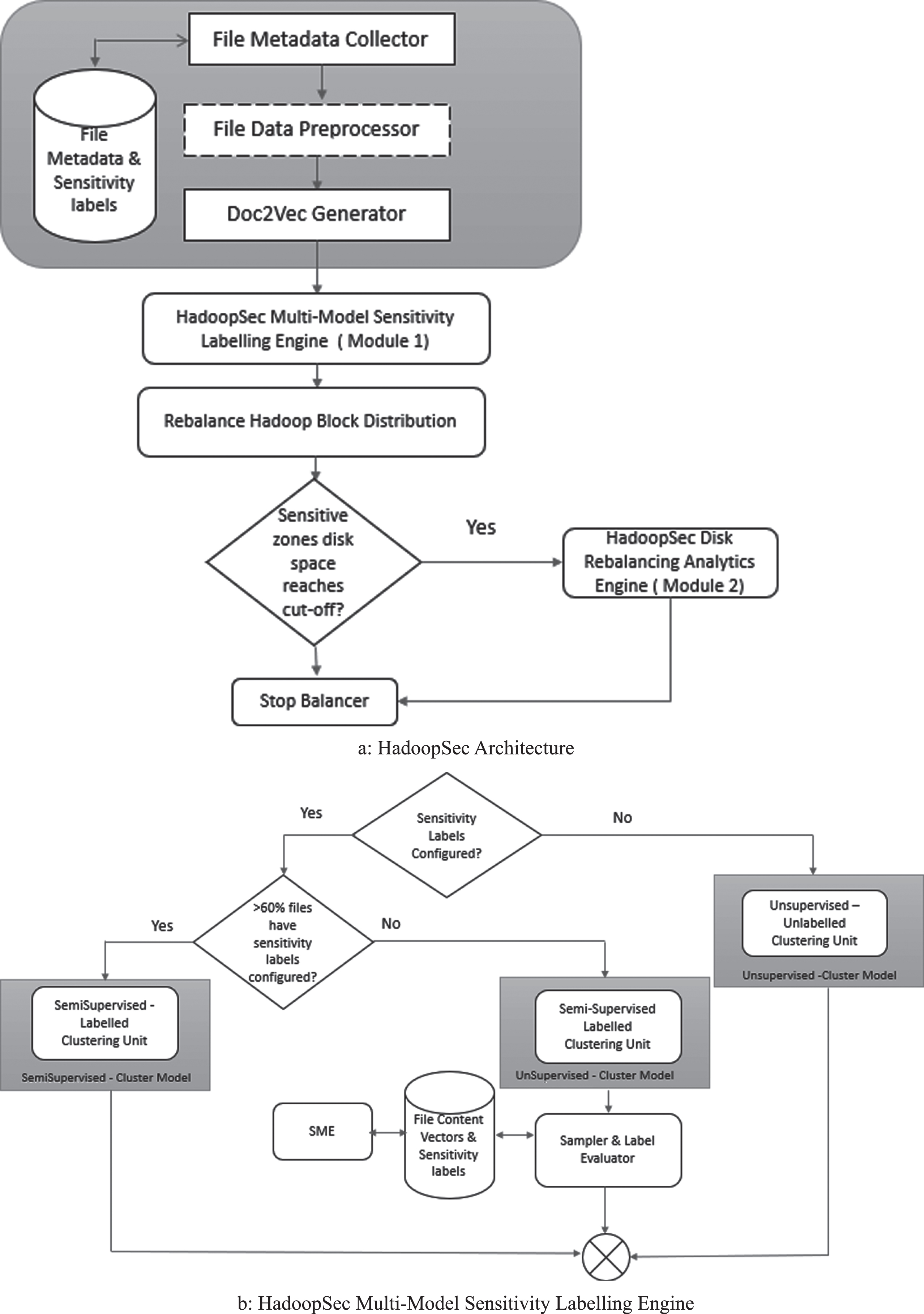
a. HadoopSec Architecture. b. HadoopSec Multi-Model Sensitivity Labelling Engine.
HadoopSec Module I – HadoopSec Multi-Model Sensitivity Labelling Engine
The balancer is triggered to perform rebalancing the cluster Namenode prepares the list of files in the cluster and the metadata is refreshed Namenode checks if any custom block placement policy is configured. If no custom block placement policy, the namenode continues the default cluster rebalancing activity. If a sensitive-aware block placement policy is configured, the namenode gets the number of security zones configured. Then it validates the blocks of all files. Namenode fetches the sensitive index (SI) metadata property configured for each file/directory and based on the value, computes, and tags the sensitive zone for all the blocks of each file. If the SI factor is not set, HadoopSec runs the prescriptive module to compute the sensitive zone suitable for the file. After computing/fetching the sensitive zone index, namenode moves the block to the respective zone if the block is present in other zones
HadoopSec Module II – Rebalancing the sensitive zones
After HadoopSec Module 1 is completed, Namenode gets the disk utilization of all sensitive zones configured Namenode computes the difference in utilization between sensitive zones. If the difference is greater than the threshold configured, HadoopSec runs the prescriptive analytical model 2 which analyses the higher utilized zone and rebalances the zone by moving blocks to other zones based on the outcome of the algorithm
The HadoopSec Module 1 (Prescriptive Analytics Layer) is the most critical component in the overall framework. It is used to compute the sensitivity level depending on the metadata and contents of the file. It uses (k-means) unsupervised machine-learning algorithm to predict the sensitive zone level which can host the data block. Unsupervised Algorithm takes the following configurations as input.
HadoopSec uses the Sensitivity zones configured as input for the prescriptive analytics module.
Using these, it deduces the sensitive zones affinity levels for the block which needs to be written into HDFS. The zones are formed into different clusters and the best zones are selected as the preferred location for the data block to be written.
HadoopSec uses the below algorithm which takes Sensitivity CFG and the file blocks as input and outputs the best suitable sensitive zones nodes for data block placement.
The HadoopSec algorithm consists of two modules. The first generates a numeric representation for each file, be it a typical columnar table or unstructured text files. This numeric representation can then be analyzed both in an unsupervised or a supervised manner. The details of the approach are as follows:
Life cycle of a file:
Each file comes into HDFS environment with a sensitivity label based on the file content. This can be captured in file metadata as another attribute alongside file size and others. This sensitivity label can take multiple values based on how sensitive the file contents are, e.g., unrestricted, confidential, restricted, etc. Our implementation divides the HDFS cluster into five zones based on the sensitivity of the information stored on the corresponding compute/storage nodes present in those zones. These zones are named S0, S1, S2, S3 & S4. S0 indicates no sensitive zone and the remaining others indicate increasing levels of sensitivity i.e., S2 is more sensitive than S1 and likewise. The zones’ sensitivity increases as the number increases. If in case this information is not provided beforehand for each file, then later in the block evaluation and distribution process the SME must sample the files from different clusters and evaluate the tags for each cluster. These tags are implicitly applicable to each document and its blocks. Our solution recommends beforehand tagging information as it can be used to improve the accuracy of the clustering models. The business/process SME has a role to play here, we rely on the knowledge of the SME while generating sensitivity labels/tags for these files or the clusters. Now we have all the files with sensitivity labels, first, we will identify the largest sensitive file and use that as reference for evaluating the no of nodes required to create a sensitive zone within the Hadoop cluster
While evaluating the required no of nodes for multiple sensitivity levels, we estimate the nodes required by each sensitive zone separately and add them up with the no of nodes required for the non-sensitive zone.
Once the number of required nodes is evaluated, and sensitive and non-sensitive zones/clusters are created then the HadoopSec block placement strategy is implemented.
Each file is broken down into blocks of 128 MB file size and stored according to its HDFS block sensitivity evaluation
HDFS block sensitivity evaluation
As mentioned earlier, the HadoopSec algorithm’s analytical module consists of two components – generation of a numeric representation and supervised/unsupervised analysis of this representation. Both components are described below:
Here we use the Doc2Vec algorithm to convert the representation of each file into a vector of numbers.
Once we create content vectors for all docs, we use a supervised/unsupervised machine learning algorithm like classification or the k-means algorithm to form sensitive and non-sensitive clusters.
If we have beforehand information about the sensitivity labels, either complete or partial label data, then it can be used to improve the accuracy of the clustering model. Then the model becomes more of a semi-supervised model. The sensitivity labels are finally evaluated after the formation of clusters. Those final sensitivity labels per cluster are forwarded to each file and its blocks in the given cluster.
If a-priori information is not available, then after clustering the SME must sample each cluster and evaluate the sensitivity label for each cluster. These final sensitivity labels are forwarded to each file and its blocks present in the given cluster.
In case of no SME information (not recommended of course) the clusters are created, labeled and file contents of the clusters are split into blocks. These blocks are distributed and stored under different zones accordingly. This way without exact knowledge of which file is sensitive and which is not, we still can manage segregation of file blocks and keep the restricted data away from unrestricted data.
Lastly, the core HadoopSec code was tested on all types of input data scenarios, all types of sensitive labels, data distribution scenarios – all on a traditional HDFS setup. In addition to real data, additional test cases were created, generated and the outputs were validated as well.
Step 0: Load the input files into Hadoop Cluster
Step 1: Extract the metadata features and the sensitivity labels
Step 2: Cleanse the data
Step2a: Data Preprocessing
Step 3: Create content vectors using Doc2Vec generator
Step 4: Check for the sensitivity labels configuration
Step 5: (If the labels are configured):
Step 5a: (If labels are preconfigured) – Semi-supervised clustering algorithm deployed to generate the sensitivity labels
Step 5b: (If labels are post-configured) – Unsupervised clustering algorithm deployed to generate the sensitivity labels with additional inputs (prior knowledge) from the Subject Matter Experts
Step 6: (If the labels are NOT configured):
Step 6a: (If labels are post-configured) – Unsupervised clustering algorithm deployed to generate the sensitivity labels
Step 7: Load the File, Block and Label Registers
Step 8: Algorithm to iterate through all the files
Step 9: Extract Calculated Sensitive Index (S0-S4) of the files (S0 being Not Sensitive and S4 being Highly Sensitive)
Step 10: (If the sensitive block placement is enabled):
Compute the number of Nodes (α) as
α = λ + ψ
Where: ψ = θ * бb
λ=No. of nodes required by no sensitive files
ψ=No. of nodes required by sensitive files
θ=No. of Blocks (of largest sensitive file)
бb=No. of Replicas (redundancy factor)
Assigns the block to a specific node on the sensitive zone based on the sensitivity level configured for the block
Step 11: If the sensitive block placement is not enabled, HDFS Default block placement is applied
Step 12: HadoopSec Rebalancing Analytics Engine to ensure that homogenous distribution of blocks across multiple sensitivity zones (Note: HadoopSec Rebalancing Analytics Engine is an external module not part of the main HadoopSec Block Placement Strategy).
Experimentation and results
This section analyses the result of the Multi-Model Sensitivity Labelling Engine implementation module of HadoopSec. Module-I implementation of HadoopSec was expected to work by providing sensitive levels for a different set of test data input DataSet-1: No input files contain sensitivity labels configured DataSet-2: All input files contain sensitivity labels configured DataSet-3: Partially labeled input with 40% of files having preconfigured sensitivity labels DataSet-4: Partially labeled input with 65% of files having preconfigured sensitivity labels
The output generated by Module 1 is further capable of ingesting as input to Module 2 HadoopSec Rebalancing Analytic Engine. The screenshots of the results obtained from this implementation is shown in this section. Figure 4 shows the distribution of the files based on 5 sensitive levels configured for a dataset using the unsupervised unlabeled unit. Figure 5 shows the size of each sensitive zone after the files are allocated using semi-supervised labeling unit with no SME input. Figure 6 shows the size of each sensitive zone for the files processed using semi-supervised labeling unit with SME input
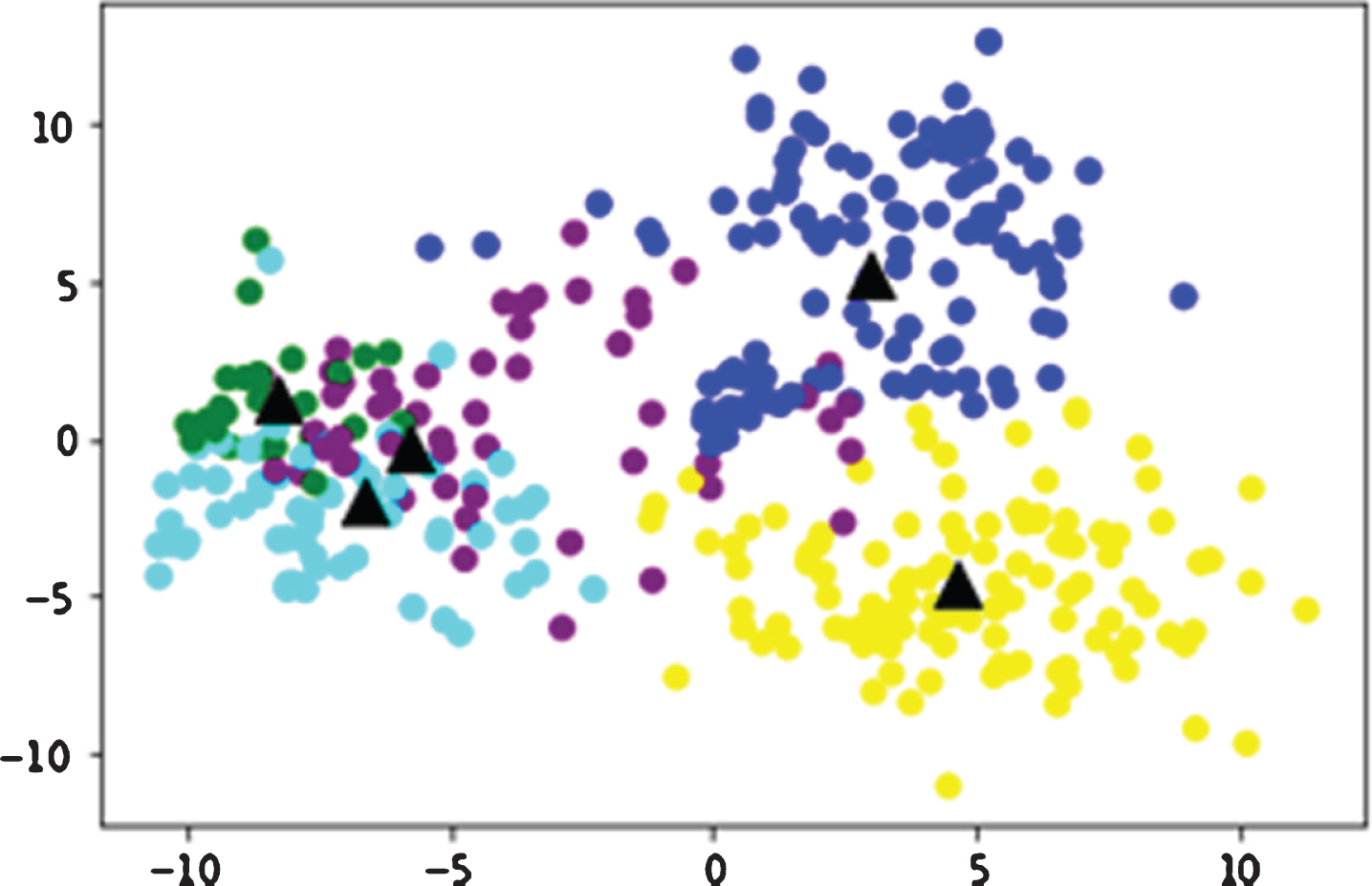
Unsupervised Clustering Model.

Semi-Supervised Model (No SME Input).

Semi-Supervised Model (With SME Input).
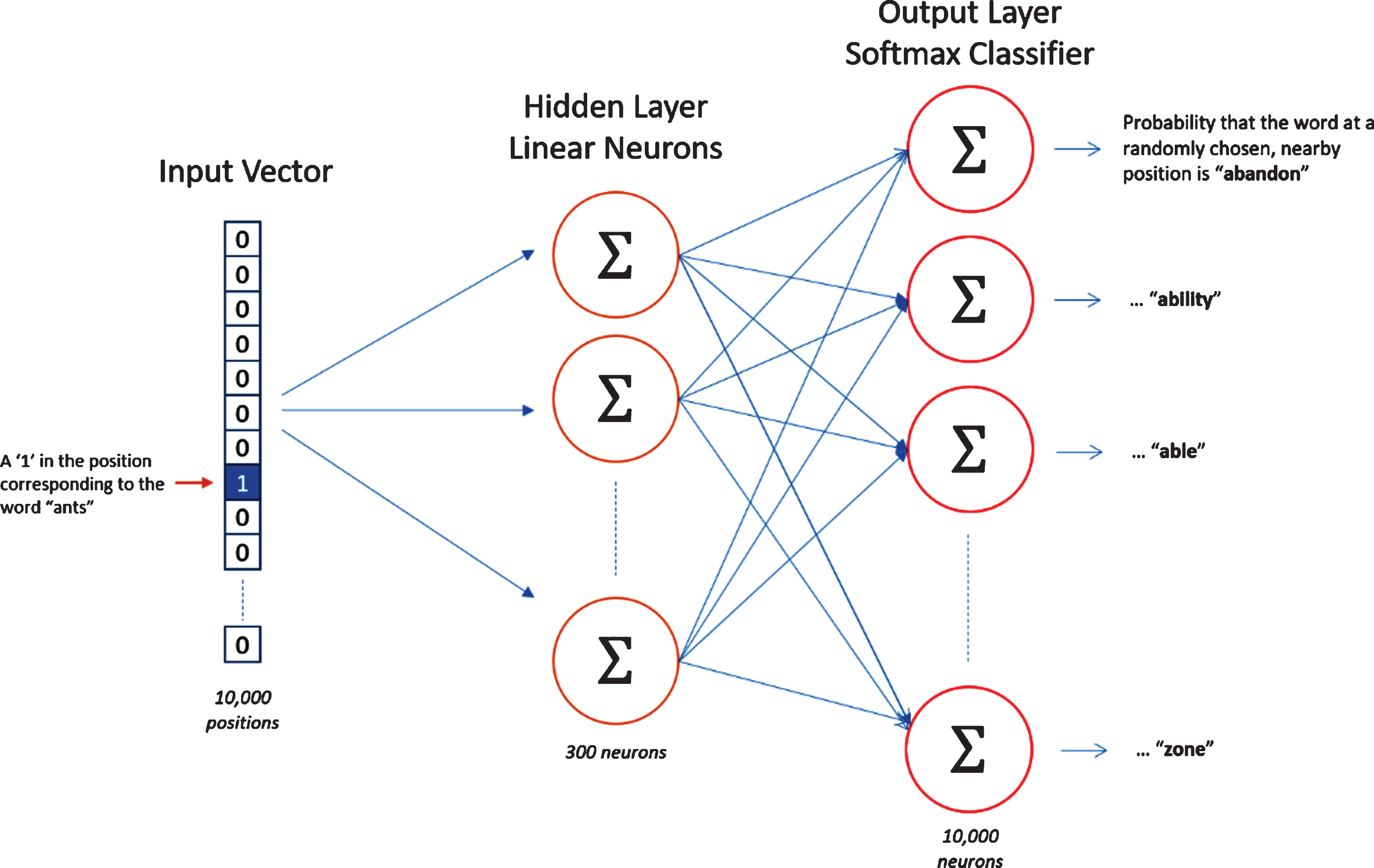
Word2Vec Architecture.
Hadoop has been one of the most sought out after Big Data Analytics platforms in the past decade and more with its ability to run thousands of applications on thousands of nodes involving many thousands of Terabytes of data. However, Hadoop also has its own set of challenges when it comes to security, privacy, and access control issues. With the entire Hadoop framework almost written entirely in Java, it is very vulnerable in the hands of cyber-criminals.
The present security framework no doubt has improved over the years. However, it does not address many areas like data encryption, data placement strategies, RBAC’s, etc., Even though Hadoop does support data placement strategies, it is very basic and sensitive information is still vulnerable. In this paper, the proposed Sensitivity Aware Data Placement Strategy for Hadoop (HadoopSec) using an advanced analytics framework brings down the risk level of placing sensitive data items in Hadoop. Sensitive information is configured as metadata purely based on the user inputs. The proposed framework will work for any type of sensitivity data requirement. Also, the current algorithm supports sensitivity on only the structured data. In the Future, the current algorithm needs to be enhanced to assign sensitivity levels for all types of data. Also, our experimental results show that there is an overhead posed by the proposed framework to the existing Hadoop implementation. But this is a trade-off for protecting sensitive information in Hadoop.