
Abstract
The traditional English examination and the current examination system have been unable to meet the needs of the education industry for English examinations. In view of this, based on the neural network algorithm, this study proposes a hierarchical network management model from the user’s perspective. Based on the in-depth study of the neural network, this study combined with the network performance characteristics of large data volume, complex data to propose a new BP neural network algorithm. By dynamically changing the momentum factor and learning rate, the algorithm has greatly improved the accuracy and stability of the error. In addition, this study proposes a user perception prediction model, and the model is continuously trained on the model based on the improved BP neural network algorithm and the monitored network performance. In order to study the performance of the research model, a control experiment is designed to analyze the performance of the model. The research results show that the intelligent model and algorithm proposed in this paper are completely feasible and effective.
Introduction
The English examinations is the most commonly used method for the final evaluation of teaching in China, and it is also a crucial step in the teaching process, and the examinations can improve the quality of education [1]. In any school or educational institution, English examinations are indispensable in the teaching process [2]. Moreover, for each exam, the teacher needs to spend a considerable amount of time and energy according to the actual situation to produce a reasonable, scientific and fair test paper. In the information age, computer technology has gradually replaced many manual jobs in the past, and it is also an important tool and helper in education. During the bank ’s training process, the evaluation and examination of trainees is an important task and an indispensable part of the entire training process. The reason is that the bank can understand the training situation of the trainees in the training process through the test results and can detect the trainees’ knowledge level of the training knowledge. The bank trains trainees more frequently and the number of trainees is also very large. Therefore, in the face of such a large number of trainees and learning content, the workload of the teacher who issued the paper has greatly increased. On the other hand, many banks are still using paper test papers for examinations. The process of this method is usually a series of tedious tasks such as manual paper production, manual proctoring, and manual paper examination. This not only consumes a lot of manpower, but also adds a lot of costs.
With the rapid development of computers, the requirements for work efficiency at work posts are becoming higher and higher. Therefore, the most traditional paper-based examinations no longer meet the current demand for examinations. This traditional examination is not only time-consuming, but also has a large amount of paper waste and high cost requirements. Moreover, since the testers are all in one test room, the cheating rate will be very high. In the final assessment, the assessment teacher needs to review a large number of examination papers, and it is easy to be mentally exhausted, so that the examination papers will be wrongly judged inadvertently. Moreover, the total score on a test paper also needs to be calculated manually by the teacher. After teachers complete a large number of assessment papers, it is easy to make mistakes in such mathematical calculations and lead to the phenomenon that the actual scores of the examination papers are inconsistent with the scores of the assessments. With the development of many years, the technology for using computers to take exams has gradually matured. These examination systems are a great improvement over traditional examinations, but these examination systems are not perfect. Because it can only randomly select questions from the test questions bank when selecting questions, the test questions of the two students may be completely different, which leads to the loss of fairness [3]. In terms of assessment, it can only judge some fixed answer question types (choice questions, judgment questions, fill in the blank questions), but it is difficult to judge some subjective questions (questionnaire questions, composition). For this type of question, it is generally done manually. Although the manual method does improve the accuracy of subjective questions, it is undoubtedly the same as the traditional examination for teachers who evaluate the examination. Although these traditional examination systems solve the judgment of objective questions on the examination, these examination systems still have no solution to subjective questions. At most, it can only make a vague judgment by comparing the correct reference answers, but the accuracy rate is very low [4].
In this study, based on the neural network algorithm, this study constructs a layered model of English automatic scoring and analyzes its performance.
Related work
The basis for the realization of intelligent test papers is to establish a sound and perfect test question database. The initial establishment of the question bank is to compile a set of test questions with good quality and high performance indicators and stored by category under the standard educational measurement theory to meet the needs of certain exams [5]. When the test paper is needed, it is convenient to use a certain test algorithm in the test set to extract the test questions to form one or several sets of test papers. On the basis of the excellent test question database, in order to improve the quality of test papers and the rate of test paper formation, many experts and scholars at home and abroad have conducted in-depth research on test paper formation methods. The status quo of intelligent paper composition abroad is now organized as follows: The CTSS (Classroom Teacher Supporting System) developed by IBM in the United States adopts batch processing method. When the question maker scans the completed test paper constraints into the computer, the system will automatically select the qualified test questions in the test question bank, print the test questions, and will generate corresponding reference answers and scoring standards [6]. Later, CATC (Computer Assisted Test Construction) developed by UCR in the United States not only can store test questions in more courses, the system functions are more complete, and the test papers generated by the test paper method can also test the true level of the testee [7]. The SLSI company in the United States has a huge library of test questions, which mainly provide computerized examinations, including certification in the IT field, academic examinations, and professional certificate examinations. It can provide more than 2,000 examinations in more than 20 different languages. According to the different test types, the method of grouping test papers can be adjusted in different degrees on the constraints such as the difficulty and differentiation of test papers to meet the needs of different levels of test. The more commonly used English level tests are GRE [7] (Graduate Record Examination) and TOEFL [8] (Test of English as a Foreign Language). Although they use different test paper composition methods, the test papers obtained through the test paper method can test candidates’ foreign language ability in terms of validity, cognitive level, reliability and other indicators. The test questions in the test paper have many attributes and constraints, and the requirements of the test paper vary according to the test level. Test paper generation can use the method of intelligent test paper combination with educational measurement theory, and the test paper has scientific measurement standards [9]. The literature [10] proposed a method of combining project response theory with adaptive testing. This method not only ensures the quality of test papers, but also significantly reduces the test time and ensures the effectiveness of test results. The literature [11] proposes an efficient SMA method for generating test papers. SMA uses sub-model optimization technology to enhance the iterative multi-objective fuzzy algorithm, and at the same time combines the greedy approximation algorithm to find the approximate optimal solution. The advantage of this method is that it speeds up the efficiency of composing test paper, and the time of composing test paper is lower than that of other multi-target test algorithms. In view of the difficulty of measuring the difficulty in the test paper, the literature [12] applied the proxy mechanism to the test paper and proposed the grouping test paper algorithm of UBTP. The algorithm selects test questions in the test question database according to the difficulty index provided by the user. The experimental results show that the algorithm has practical feasibility. The application of agent mode provides another way for the research of intelligent test paper method, and Agent also reduces the grouping test paper time in actual use, improves the grouping test paper efficiency, and meets the actual needs of users [13]. In view of the tedious traditional paper-composing method, literature [14] has designed an automatic paper-composing system, in which the paper-composing method takes into account the complexity of generating test paper. This method selects the test questions according to the pre-set test paper mode and marks the selected test questions, so as to ensure that the test questions in the test paper are not repetitive and the entire process is automatic. The literature [15] proposed a method of randomly generating test papers based on genetic algorithm. The algorithm uses an optimized test paper vector to improve the algorithm’s global search capability and test paper knowledge coverage. From the above research status, we can see that foreign research on the method of composing papers mainly focuses on the quality of test papers and the rate of test paper generation. Although the method of generating test papers has been improved to some extent, there is still much room for research in this area.
The literature [16] proposed an intelligent test paper generation algorithm based on improved genetic particle swarm. In this paper, a particle swarm optimization algorithm is used to generate a test paper set, and then an adaptive genetic algorithm is used to initialize the population to obtain the initial population. This design makes the speed of intelligent test paper generation and the generated test paper meet the needs of users. The literature [17] proposed a test paper generation algorithm based on genetic algorithm and constructed an optimized model of intelligent test paper composition. The model optimizes the test paper with a certain probability of cross mutation and obtains a better test paper. In view of the characteristics of low efficiency and slow speed of traditional test paper forming algorithm, the literature [18] used improved particle swarm algorithm for intelligent test paper generating. The algorithm uses a greedy algorithm to initialize the test paper cluster, divides the test paper into a high fitness test paper and a low fitness test paper according to the fitness value, and randomly generates a new test paper. The experimental results show that the algorithm generates test papers quickly and with high quality. The literature [19] proposed a simulated annealing algorithm for intelligent test paper composition. According to the principle of simulated annealing, the test questions were quickly searched to obtain the best test paper, and the generated test paper met the constraints of the test paper composition.
Neural network model
Biological neurons mainly include three parts: dendrites, axons and synapses. The neural network model abstracts these three parts into a mathematical model. Among them, the dendrite abstraction is used as the input signal, the axon abstraction is used as the output signal, and the synaptic phase is used as the connection weight to realize the nonlinear characteristics of the function [20].
(1) Classification of neural networks
There are many classification methods of neural network, which can be divided into three types based on network structure: feed-forward, feedback and hybrid.
Feed-forward network refers to that the nth output of the network is only related to the connection matrix of the network and the current input, but it has nothing to do with the previous output. This processing method is similar to the “long-term memory” of the human brain. Its structure is shown in Fig. 1 [21].
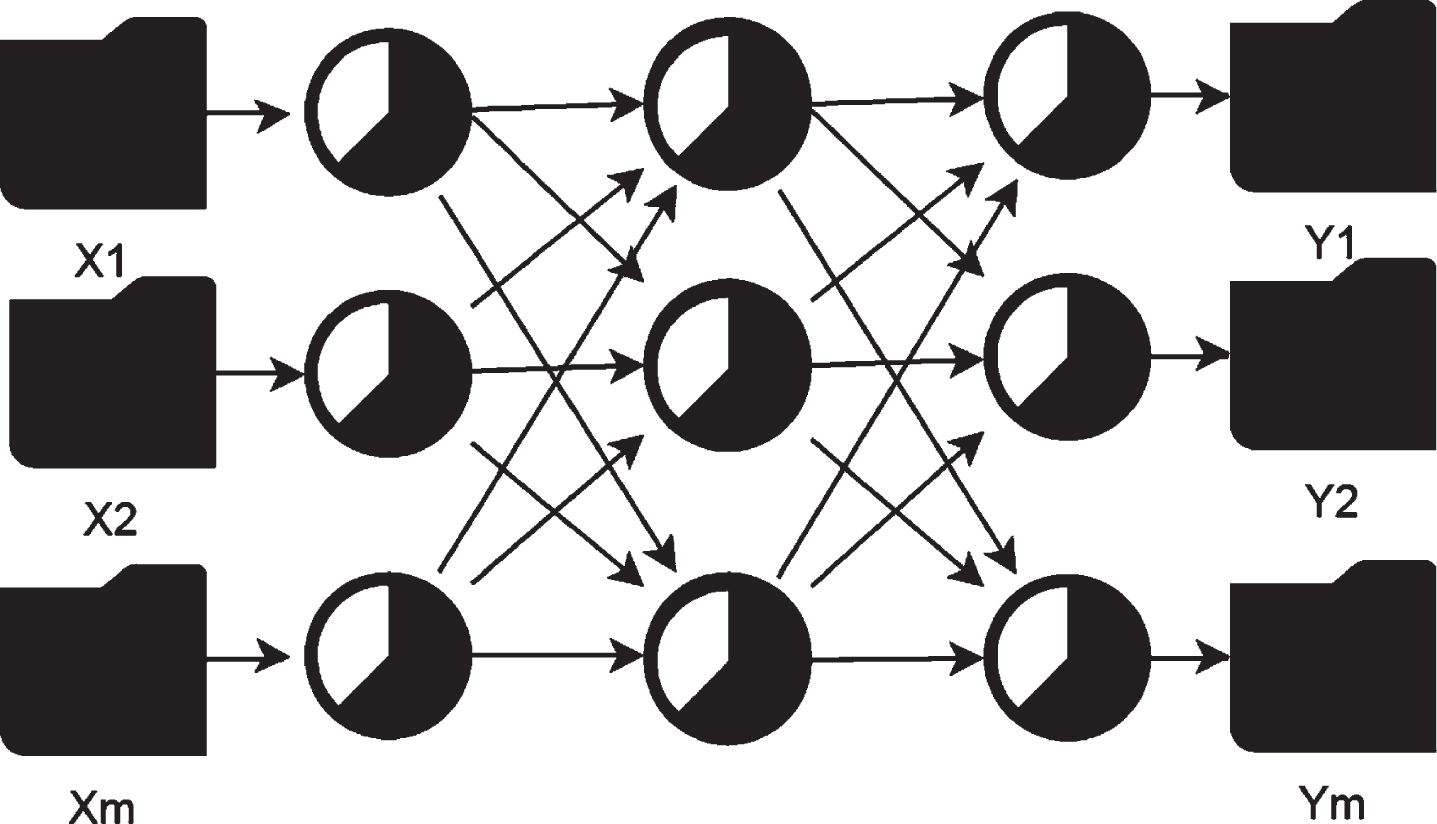
Multi-layer feedforward network.
Feedback network means that when there is an error between the training output and the expected output, the output result will be fed back to the input network through the connection weight. In this way, the nth output result is related to the n–1th output and the current input. This is similar to the “short-term memory” function of the human brain. Among them, Fig. 2 is a partial feedback structure diagram, and Fig. 3 is a full feedback structure diagram.
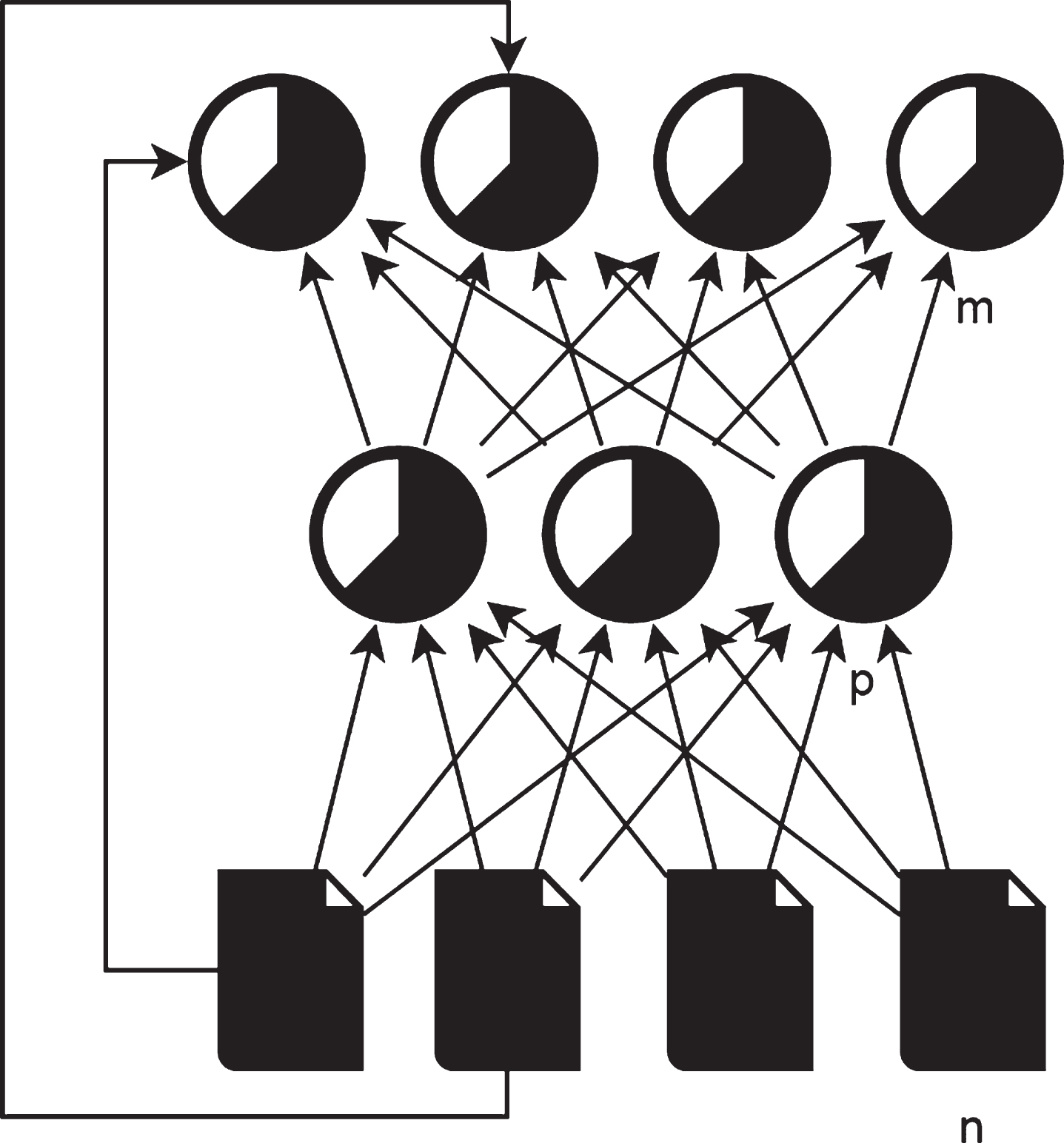
Partial feedback.
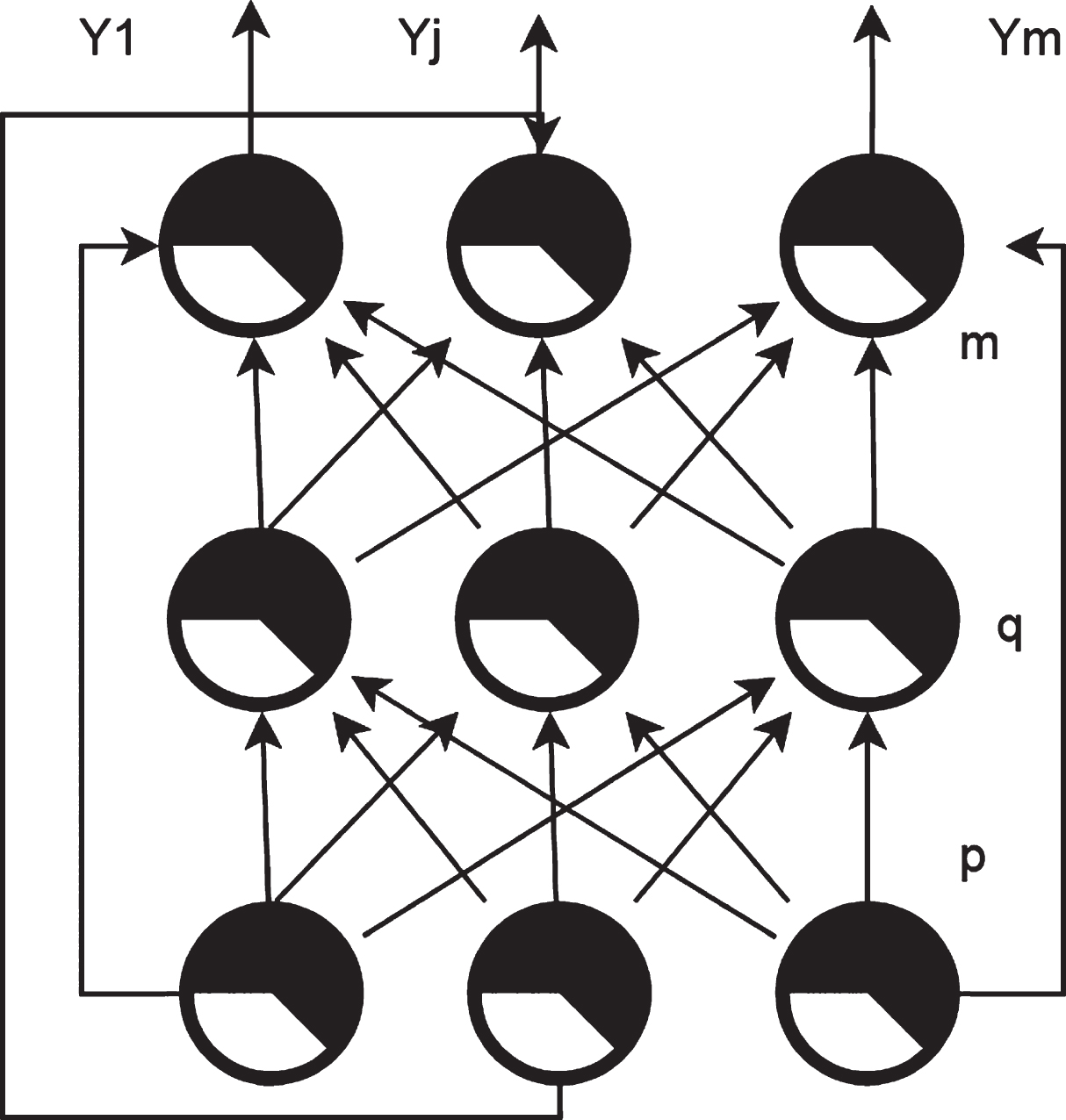
Full feedback.
The hybrid network combines the characteristics of feedforward and feedback networks, and any two neurons may be connected [22–23]. Its structure is shown in Fig. 4.
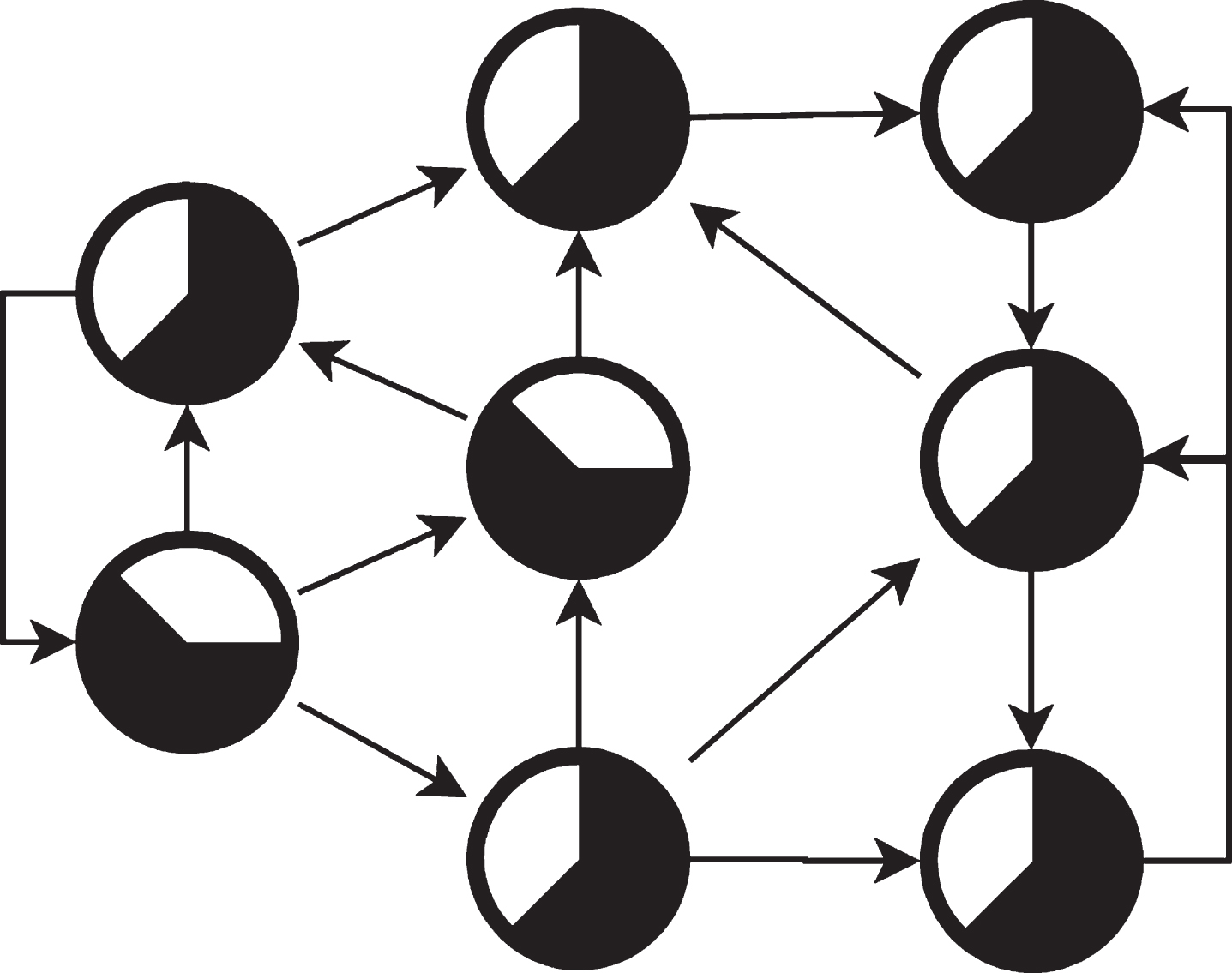
Hybrid network.
Different neural networks have different advantages. Due to the correlation of network data, the last data has a certain guiding significance for the next time. Therefore, this paper chooses feed-forward neural network.
(2) Neural network learning rules
Neural networks have multiple learning rules, and the commonly adopted rules are mainly Hebb learning rules, δ learning rules and discrete learning rules.
(1) Hebb learning rules
The principle of this rule is to assume that the basis for human learning and memory is the change in the strength of synaptic connections between neurons in the human brain. Furthermore, frequent synaptic connections can enhance nerve signals. In essence, it is an unsupervised self-learning method.
According to Hebb’s rule, we assume that the current input of the neuron is x = (x1, x2, ⋯ , x
n
)
T
and the output is:
w (t) is the connection weight, and its adjustment amount is:
Then the weight of the neuron is corrected as:
f (x) is an activation function, which can be any form of activation function. Hebb rules are generally used to extract certain features of the network.
(2) Discrete Perceptron Learning Rules
This rule is a supervised learning method, which is generated when neurons use linear functions as basis functions and hard limit functions as activation functions.
We assume that x is the sample input, y is the current output, d is the expected output, and the sign function is taken as the activation function. Then, according to the discrete perceptron learning rules, the weights are adjusted to:
Among them, e (t) is the error signal:
We can take any value as the initial weight of the neuron. This rule is mainly used in discrete perceptron networks, such as single-layer or multi-layer perceptron networks.
(3) δ learning rules
This algorithm is the most commonly used neural network algorithm, which is also called gradient method or steepest descent method, and the learning rule is also a supervised learning method.
In the δ learning rule, a linear function is generally used as the basis function, and an S function is used as the activation function. The reason is that the gradient method needs to use the gradient value of the final function, namely
The purpose of the δ learning rule is to minimize the output error (7) of the training sample pair (x, d) through continuous training weights w, and calculate the vector (8).
By setting Δw (t) = - ∇ E, the weight correction formula is obtained:
The δ learning rule is currently the most widely used learning rule and is often used in BP neural networks.
BP neural network has its own unique calculation method and weight correction method. The following is a brief introduction to its algorithm principle:
We assume that it has P learning samples, and it has three layers of networks, namely the input layer, the hidden layer and the output layer. There are m inputs and n outputs in the network model. The corresponding input is: X p = (xp1, xp2, ⋯ , x pm ) T , the hidden layer output is Y p = (yp1, yp2, ⋯ , y pj , ⋯ , y pr ) T , the output layer output result is O p = (op1, op2, ⋯ , o pm ) T , and the corresponding expected output is D p = (dp1, dp2, ⋯ , d pm ) T . W ij g represents the weight value from the i-th node (input layer) to the j-th node (hidden layer), and the weight value from the j-th node (hidden layer) to the k-th node (output layer) is V jk . Moreover, θ j represents the threshold corresponding to the j-th hidden node, φ k represents the threshold corresponding to the k-th output node, and r is the number of hidden layer nodes.
The first step is the positive learning process.
The data of the input vector X
p
= (xp1, xp2, ⋯ , x
pm
)
T
is input to calculate the output of the hidden layer:
Then, the output of the hidden layer is used as the input of the output node to calculate the output result of the output unit as:
Then, the weight is corrected according to the output error.
The difference between the output of all samples and the expected output is calculated:
Whether the error is less than a certain value ɛ is judged. If it is less than ɛ, the training ends, otherwise, the weights need to be adjusted. The specific adjustment formula is as follows:
The output layer weights are adjusted to:
Among them,
The threshold adjustment formula is:
Among them, t is the training times.
The adjustment of hidden layer weights is:
The adjustment of the threshold is:
Among them,
Then, all sample output errors are recalculated and counted to judge the errors. The above process is repeated until a certain accuracy is reached.
BP neural network has the advantages of nonlinear mapping ability, global convergence ability and generalization ability, but the traditional BP neural network still has many shortcomings.
First, the convergence rate of the algorithm learning process is slow. The reason for this is that the gradient descent method used to implement the updated objective function has a high complexity, which makes the implementation efficiency of the algorithm relatively low. Moreover, the back-propagation function is more complicated. When the output signal is close to 0 or 1, the network enters the flat area, and the error change is almost 0 at this time, so that the training is stopped prematurely.
Secondly, the algorithm is easy to fall into the local minimum point. The reason is that when the backpropagation algorithm is used to solve the global problem, it is first entered into the local search, so that the global minimum will not be achieved because of the local minimum, and the training will fail.
In response to the above shortcomings, scholars at home and abroad have proposed many improvements. Among them, the most commonly used method is to increase the momentum term and adaptively change the learning efficiency. However, in all the improvement methods, the momentum factor has been kept constant, and for learning efficiency, many scholars have proposed many improvement methods and proposed their own improvement methods for their own fields. However, these improved methods are difficult to adapt to the characteristics of large network data volume and wide data change range.
In view of the above shortcomings and the characteristics of network management, this paper proposes a new method for improving neural network, which is called adaptive BP neural network algorithm. The adaptive BP neural network algorithm is a method to dynamically modify the learning efficiency and momentum factor. The sample verification data has proved that the prediction system established by this method has high prediction accuracy and good stability.
For the improvement of the algorithm, the emphasis is on the modification of the weight and threshold, and the modification of the weight and threshold is mainly achieved by adjusting the learning rate and momentum factor.
The research has proved that for the learning rate, when the learning rate is too small, convergence is easily guaranteed, but the convergence rate is too slow. On the contrary, when the learning rate is too large, the learning speed is fast, but it will cause divergence or oscillation. Moreover, the data changes are different for different fields. Therefore, in order to achieve a fast and effective learning convergence process in network prediction, this section proposes a new method for adaptively changing the learning efficiency. The basic principle is: when the training error becomes larger, it indicates that there may be some problems in training, and the learning rate should be appropriately reduced at this time. Conversely, when the training error decreases, the learning rate should be increased appropriately.
In addition, when adjusting the learning rate, the momentum factor should not be a fixed value. In fact, if the difference between the two training errors before and after is ΔE > 0, it means that the error adjustment direction is wrong. At this time, while reducing the learning rate η, the momentum factor should be adjusted to α = 0. The reason is that the search direction of the error gradient may be completely unreasonable at this time. If ΔE < 0, the error adjustment direction is correct. Therefore, while increasing the learning rate η, we can appropriately increase the value of the momentum factor α to speed up the adjustment. The specific principle is shown in Fig. 5:
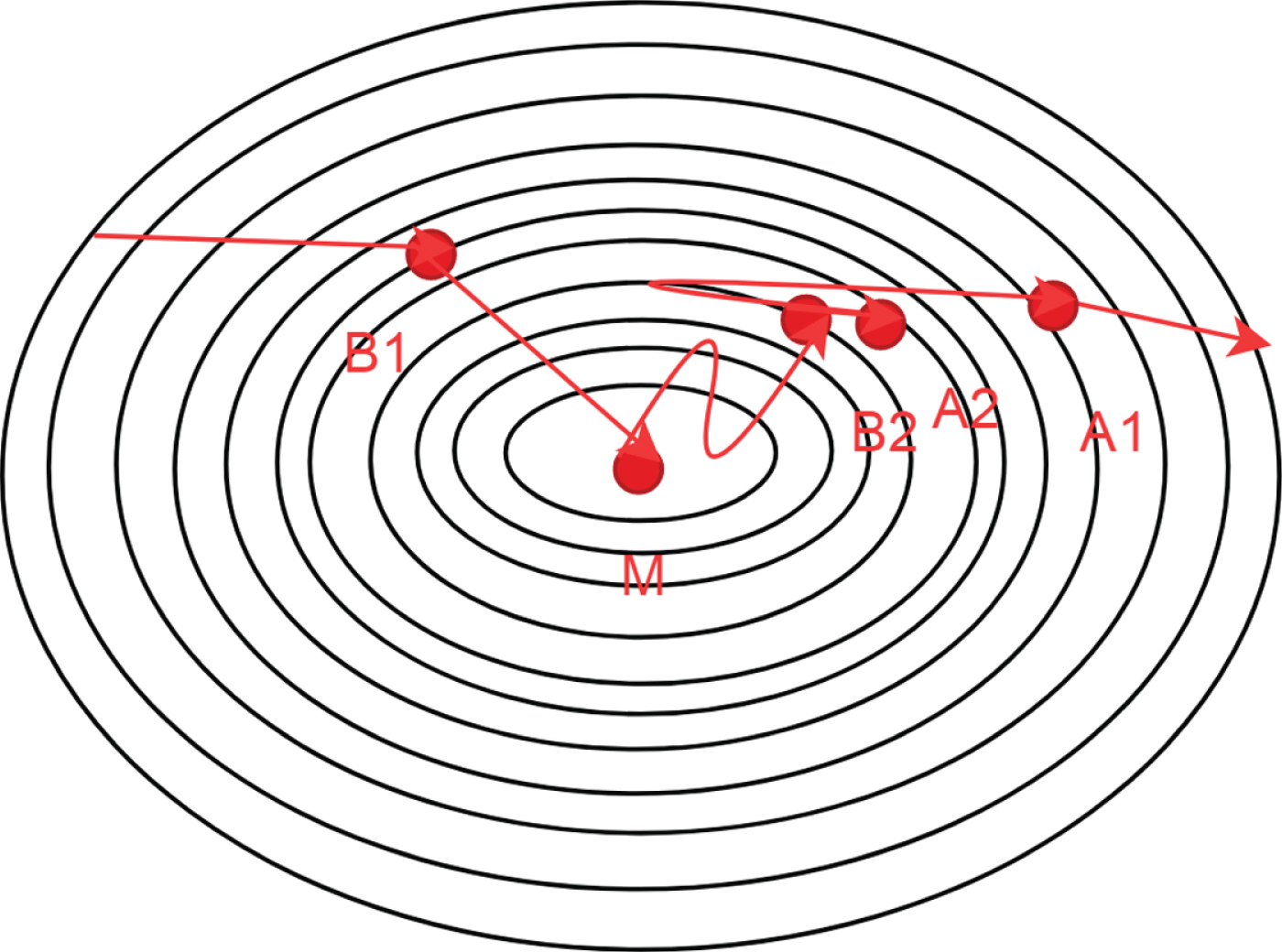
Top view of the two-dimensional error surface.
This figure is a top view of a two-dimensional error surface. We assume that there is only one minimum point. If point A1 is reached after n0 iterations, and point A2 is reached after n0 + 1 iterations, A2 points can accelerate convergence because of the same gradient direction at the two points. However, if n0 and n0 + 1 iterations are at B1 and B2 points, respectively, the gradient directions of these two points are opposite. This shows that the convergence directions of the n0-th and n0 + 1-th orders are not accurately directed to the minimum point M.
Based on the above theoretical analysis, this article proposes the following weight adjustment method:
If α is 0, the α value becomes the initial value during the next training. The 1.04 in the formula is obtained after a large amount of training comparison. This coefficient cannot be too large, otherwise if the training is wrong, it may not be found immediately, and the entire training process deviates from the required minimum. Among them, t is the number of trainings, η is the momentum factor, α is the learning efficiency, and E [t] is the mean square error of the tth training. In order to make the training error reach a certain accuracy, it is necessary to continuously adjust the connection weights between the layers. In this section, the learning efficiency and momentum factor will be modified according to Equation (19). Then the weight between the hidden layer and the output layer is adjusted as follows:
The weight of the input layer node to the hidden layer node is adjusted to:
Then, the weights of each layer are adjusted according to the following formula:
The specific calculation flowchart of the improved BP neural network is shown in 6:
The delay, packet loss rate, throughput and delay jitter in network performance are used as the training input of the neural network, and the determined user perceived quality is used as the expected output of the neural network. If in the three-layer network, the output layer uses a linear function and the hidden layer uses an S-shaped function, it can approximate any function with almost any precision. So this paper uses a three-layer network model, which has four input nodes, a linear output node, and a hidden layer using the sigmoid function. The model is shown in Fig. 7:
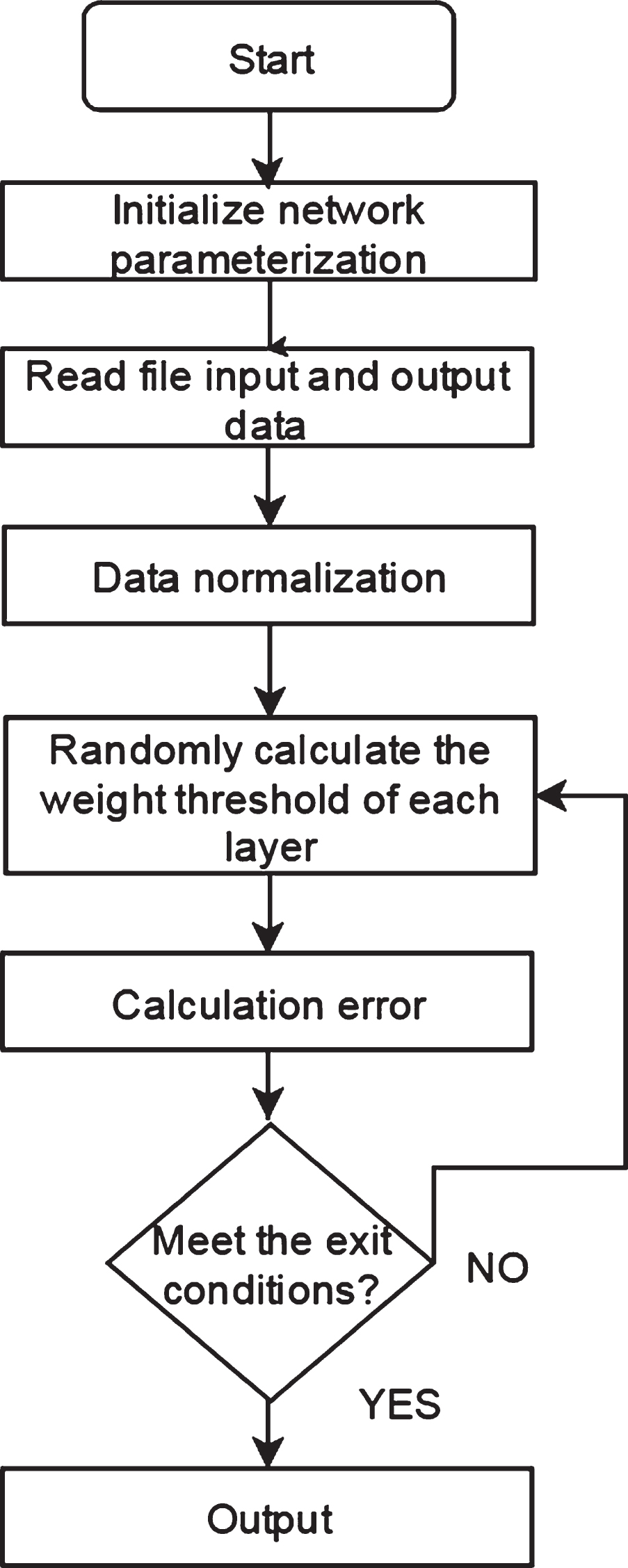
Flow chart of improved BP neural network.
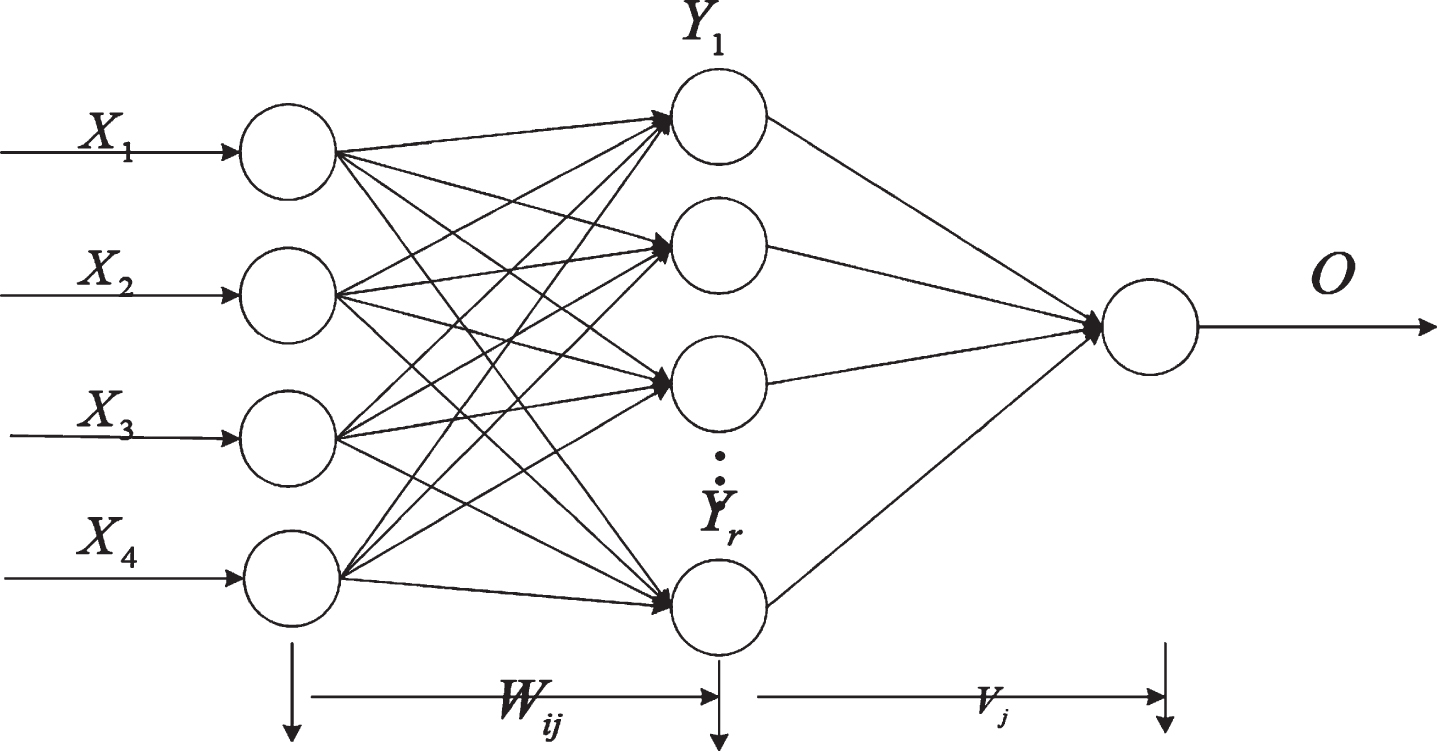
Topological structure of a 3-layer feed-forward BP neural network.
Among them, the input vector of the Pth learning sample is X p = (xp1, xp2, xp3, xp4) T , the output of the hidden layer node is Y p = (yp1, yp2, ⋯ , y pj , ⋯ , y pr ) T , and the output vector of the Pth sample is O p = (o p ) T , and the expected output vector is D p = (d p ) T .
The output of the middle hidden layer node is:
The output of the output layer node is:
Among them, θ
j
represents the threshold corresponding to the j-th hidden node, φ represents the threshold corresponding to the output node, and r is the number of hidden layer nodes.
By adjusting the weights, a prediction model suitable for user perception prediction can be finally obtained.
In order to compare the advantages of improving the BP neural network in user-oriented network performance management, we use a BP neural network with fixed momentum factor and a learning rate, which is referred to as the classic BP neural network algorithm, and a BP neural network with fixed momentum factors and varying learning efficiency, which is referred to as a BP neural network algorithm with fixed momentum factors and an adaptive BP neural network to train the network performance parameters Figs. 8–10 are comparisons of the training results of three different algorithms.
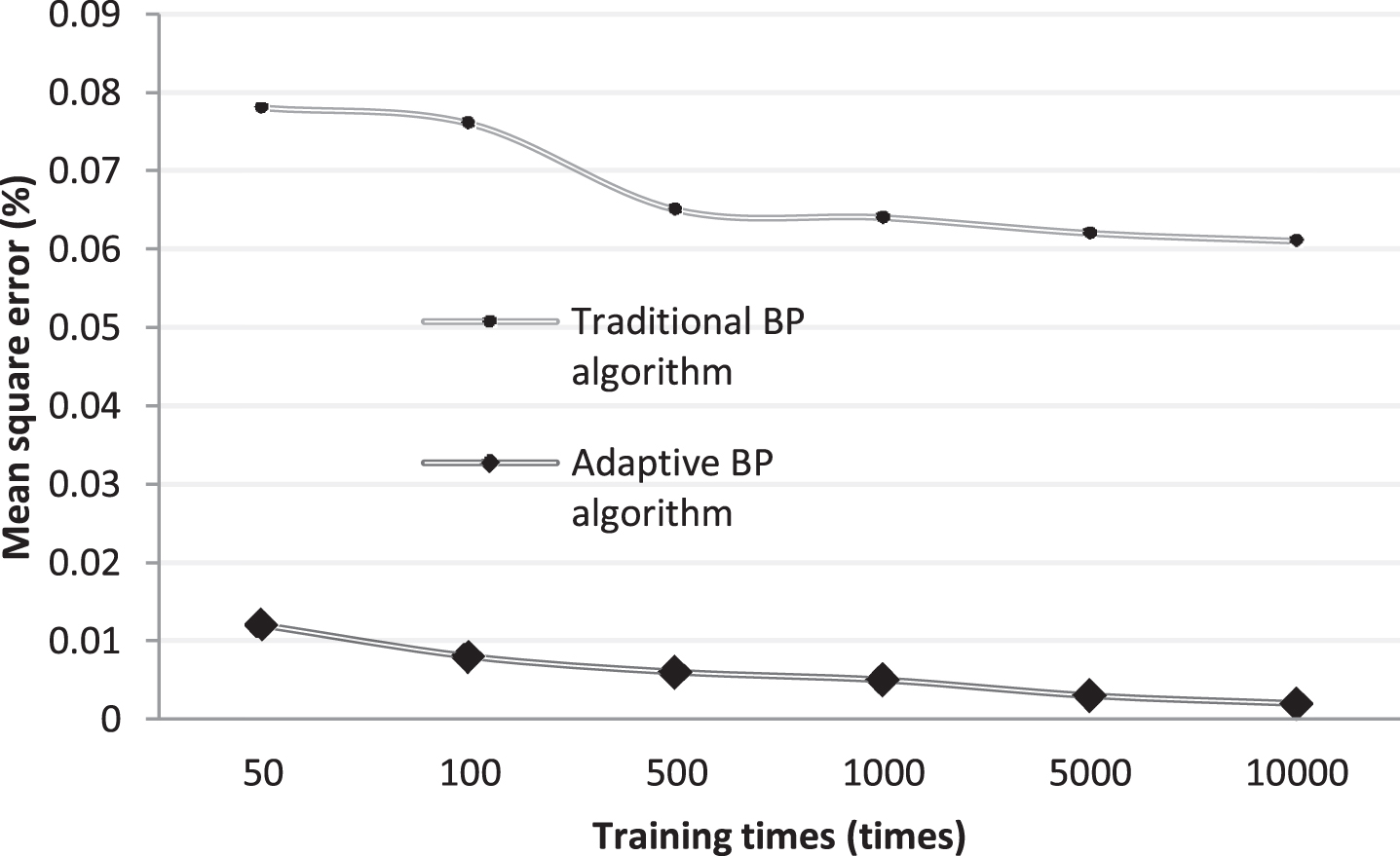
Comparison of error accuracy between classic BP algorithm and adaptive BP algorithm.
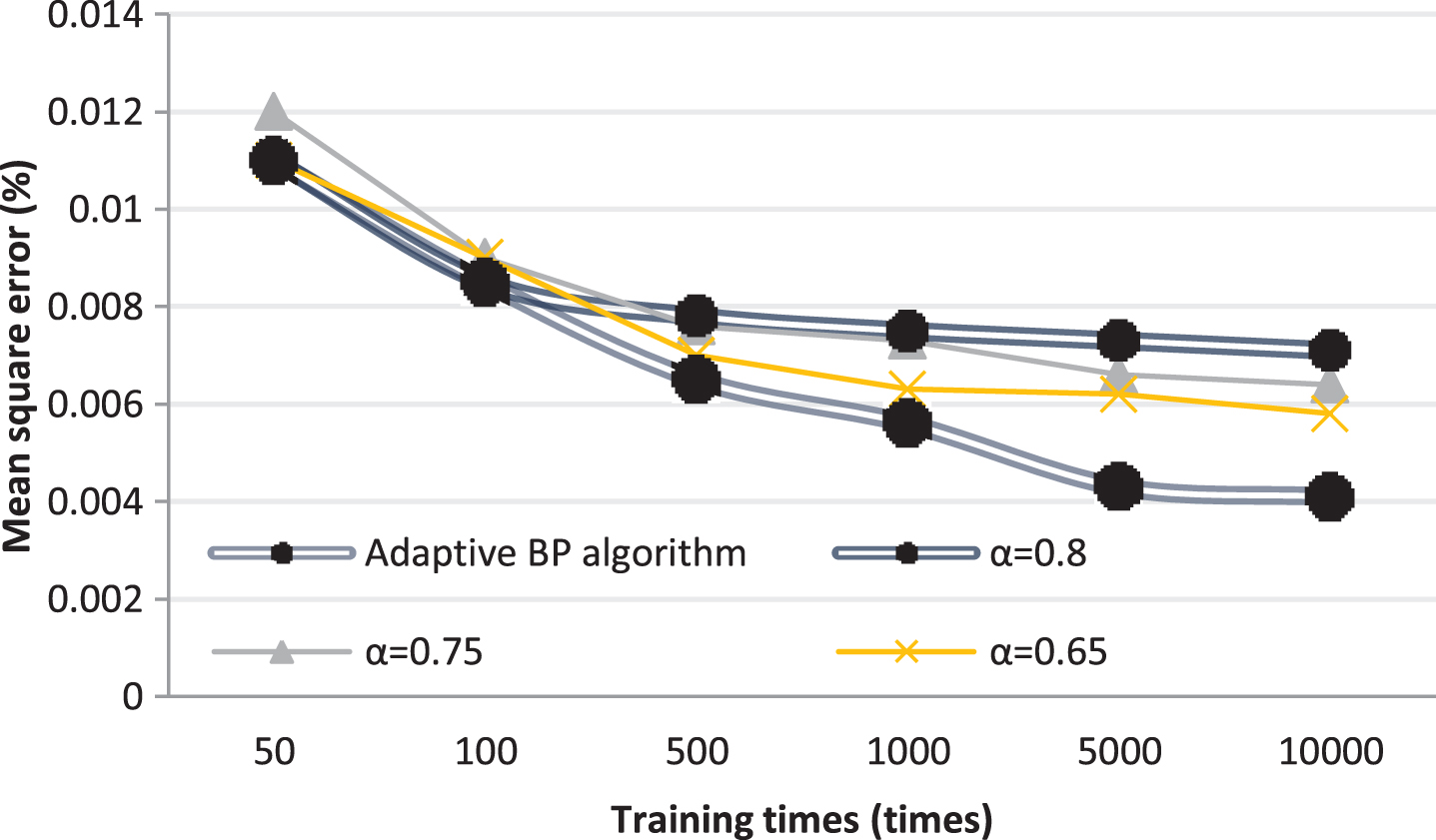
Comparison of error accuracy between adaptive BP algorithm and BP algorithm with fixed momentum factor.
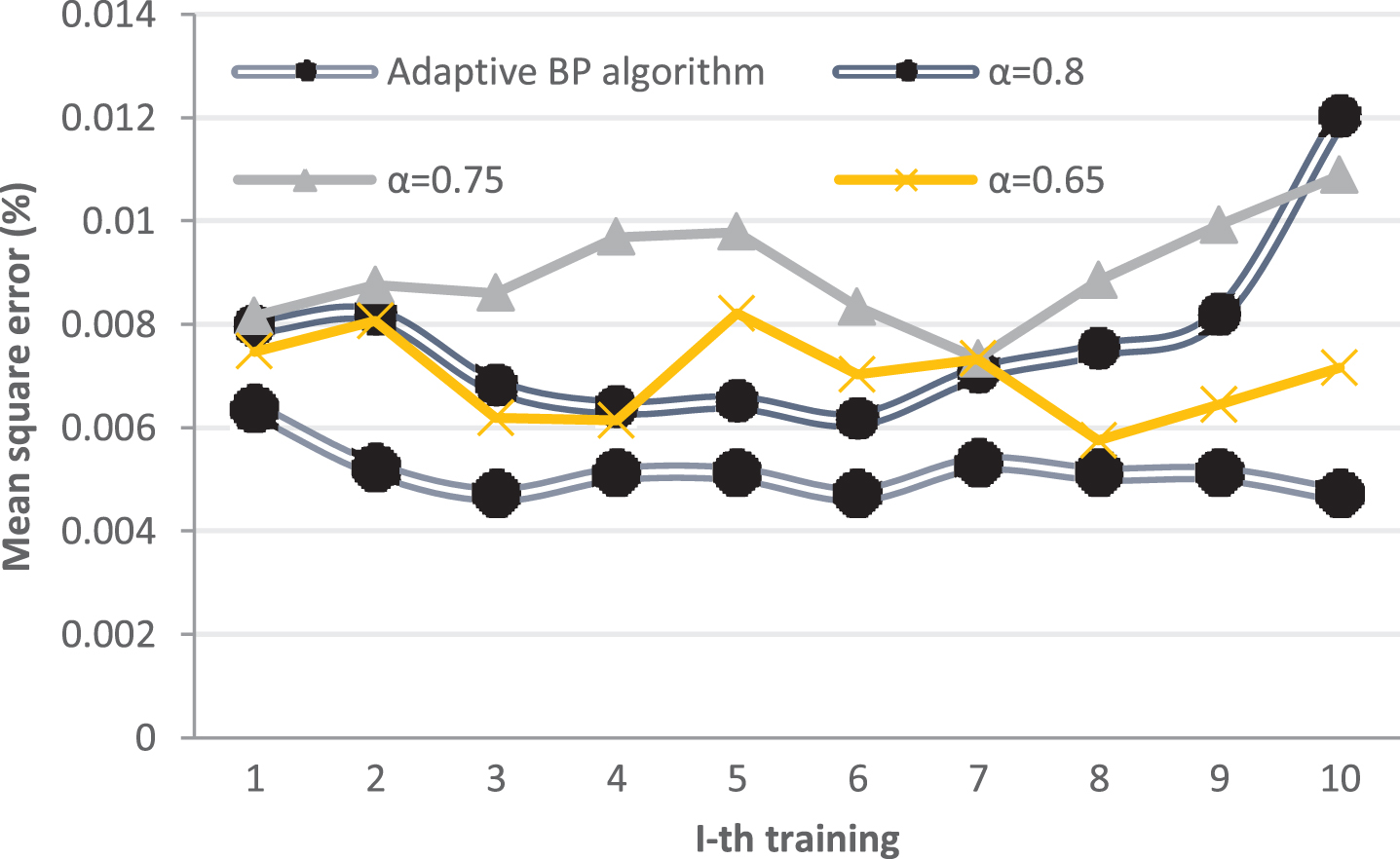
Comparison of different improved methods of BP neural network.
Figure 8 shows the error accuracy achieved by the classic BP algorithm and the adaptive BP algorithm under different training times. It can be seen from the figure that the adaptive BP algorithm is significantly better than the classic BP algorithm in terms of error accuracy. As the number of training increases, the error accuracy can be improved by an order of magnitude.
Figure 9 shows the error accuracy achieved by the adaptive BP algorithm and the BP algorithm with a fixed momentum factor under different training times. It can be seen from the figure that with the increase of the training times, the adaptive error accuracy of the BP algorithm is obviously better than that of the BP algorithm with a fixed momentum factor. At the same time, in the convergence speed, the adaptive BP algorithm is also significantly better than the neural network with fixed momentum factor.
Figure 10 shows the error accuracy that can be achieved during each training of the adaptive BP neural algorithm and the BP neural network with a fixed momentum factor under the premise of 1000 training times. Among them, the momentum factors are 0.8, 0.75, and 0.65, respectively. As can be seen from the figure, the result of each training of the adaptive BP algorithm is very stable, but the BP neural network with fixed momentum factor has a large fluctuation, and the maximum fluctuation can reach 50%. The reason is that when the weight is adjusted, the search direction of the error gradient may be unreasonable.
From the above comparison, we can see that the adaptive BP neural network algorithm is superior to the other two methods in terms of error accuracy, convergence speed, and stability.
In this paper, simulation standard test questions are used to verify the standard genetic algorithm and the improved genetic algorithm. The test questions library includes three sub-questions, multiple choice questions, judgment questions and subject questions, each of which includes 10,000 questions. All test question attributes of the question bank are randomly generated by the computer. The test question attributes are the difficulty, discrimination, number of uses, completion time and final exposure time mentioned in this article. The test papers grouping by this paper consist of three question types, that is, 25 multiple choice questions, 14 judgement questions, and 8 subjective questions.
Based on the multi-objective mathematical model proposed in the article, the operation of the two algorithms is compared. The standard genetic algorithm cross probability is 0.5, and the mutation probability is 0.01. In the improved operator probability formula, k1 and k2 take the values 0.5 and 20, respectively. The number of individuals in the population is 50, and the number of evolutionary generations is 150. The weight ratios of difficulty, discrimination, number of uses, completion time and last exposure time are selected as 0.3, 0.3, 0.2, 0.1, 0.1, respectively. The target difficulty value, discrimination value, number of uses, completion time and final exposure time of the grouping test paper are 0.7, 0.5, 3, 100 and 20 respectively. Among them, the last exposure time is converted into a real number by numerical value. The openness type of all test questions is selected to be open, and the scores of all test questions are added manually by the composer after the algorithm runs.
The maximum fitness value of the population obtained by testing and comparing the standard genetic algorithm and the improved genetic algorithm proposed in this paper is shown in Fig. 11. The average fitness value of the population is shown in Fig. 12. The corresponding data are shown in Tables 1 and 2, respectively.
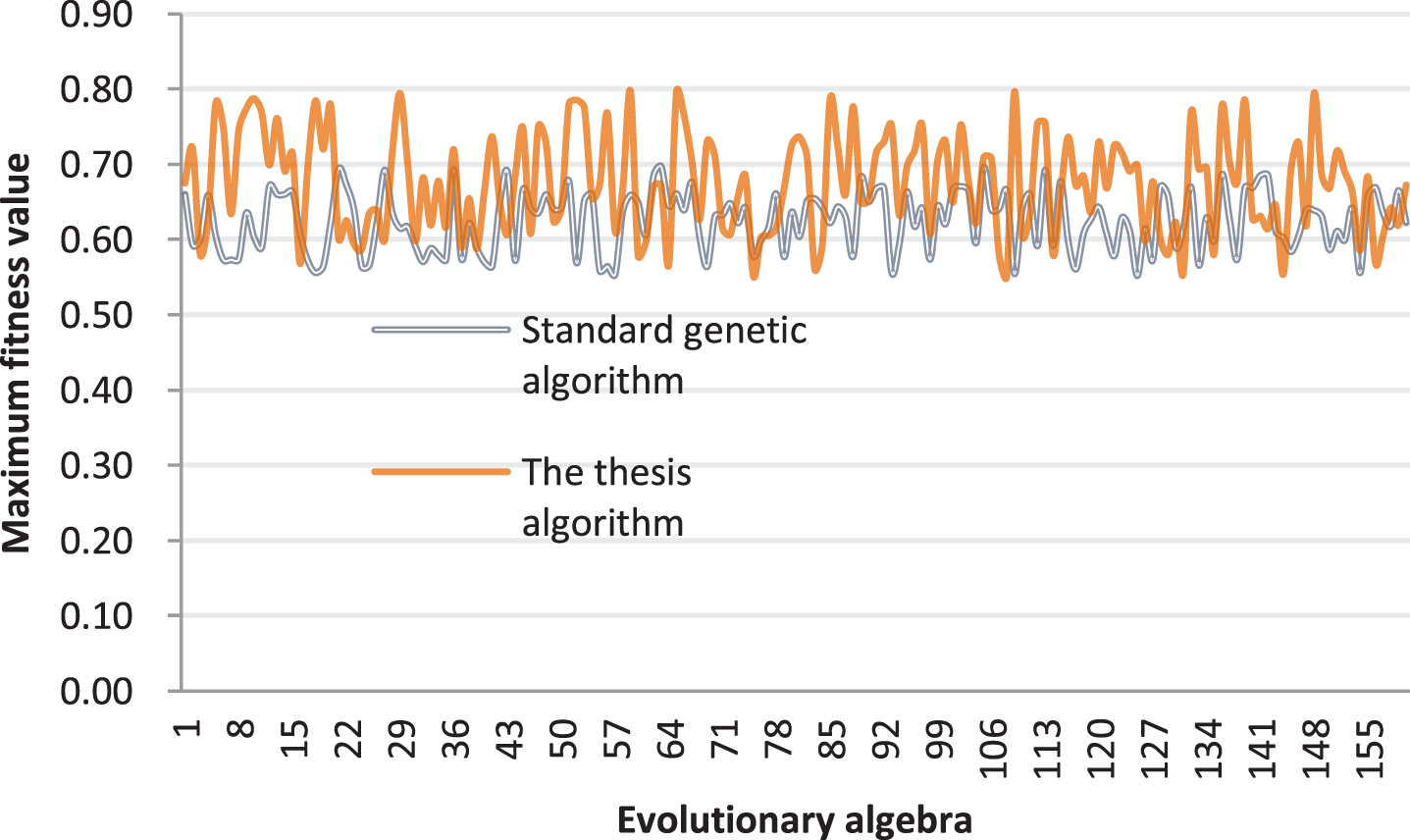
Comparison diagram of the maximum fitness value of the population.
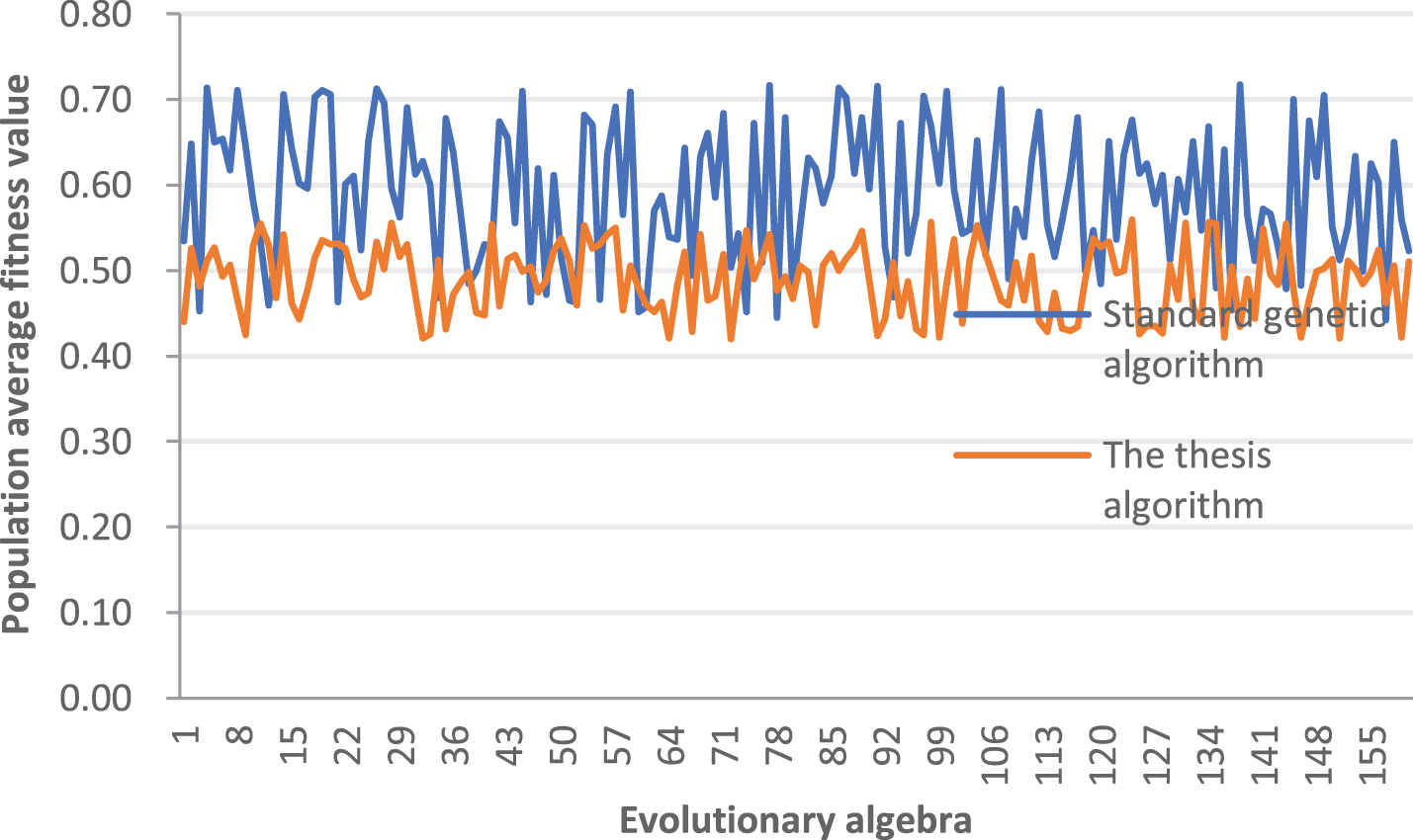
Comparison diagram of the average fitness value of the population.
Comparison table of maximum fitness value of population
Comparison table of average fitness value of population
It can be seen from Figs. 11 and 12 that the random question selection algorithm and the retrospective heuristic method cannot quantitatively describe the quality of the grouping test paper, and the running time is too long, and there is a phenomenon that the feasible solution cannot be found. The application of standard genetic algorithm avoids the phenomenon that the test paper cannot find a feasible solution and can evaluate the quality of test paper. However, the algorithm is easy to enter the local optimal solution and enter the premature convergence trap, and the average fitness value rises slowly, and the population quality does not improve significantly, which leads to a slow overall evolution. The improved algorithm proposed in this paper overcomes the shortcomings of standard genetic algorithm in the application of grouping test paper, greatly improves the execution efficiency of smart test paper composition, and can quantitatively evaluate and control the quality of test paper. Moreover, the running time of the improved algorithm and the standard genetic algorithm is basically no big difference.
The procedure of traditional English paper examination is very complicated, and the existing system can only automatically evaluate objective questions, but it cannot evaluate subjective questions such as composition. In order to improve examination efficiency and maintain the fairness of the examination, as well as to improve the speed of the test paper generation, this study combines with the advantages and disadvantages of existing systems to propose an adaptive genetic algorithm. The algorithm greatly improves the efficiency of the test paper generation, and the algorithm changes the order of the questions by disrupting the test paper again to achieve the effect of preventing cheating.
This article improves the combined use of the model and the algorithm, and introduces the entire workflow of the automatic test paper generation algorithm. At the same time, this study conducts performance tests on models and algorithms through multiple sets of test simulation experiments. The results show that the algorithm runs faster, the evolution process of the algorithm is steadily increasing, and it can produce the optimal solution set. Moreover, it can provide enough high-quality test paper selection for English test composers, and can achieve automatic scoring. Overall, the intelligent models and algorithms proposed in this paper are completely feasible and effective.
Footnotes
Acknowledgments
This research has been financed by The 13th Five-year Plan of Education Sciences of the Education Department of Inner Mongolia “The Construction and Practice of ‘Four-Dimension Integration’ English Intelligent Teaching Method Based on the Cloud Platforms”” (No. NZJGH2018234).