
Abstract
As the COVID-19 epidemic continues to spread, the government has managed to prevent people from gathering. The audit work can only be carried out through the network, which puts forward higher requirements for the accuracy and effectiveness of the audit work. Under the background of the continuous development of big data and other information technologies, big data audit has gained important technical support and played an increasingly important role. Units at all levels gradually attach importance to the enterprise management mode based on the financial sharing service mode. This paper analyzes the related problems of big data audit under the financial sharing service mode, involving big data flow, big data preprocessing, big data audit process and other issues, in order to provide useful reference for the implementation of big data audit by using the financial sharing service mode under the influence of COVID-19.
Introduction
Facing COVID-19 epidemic, many countries have recently strengthened epidemic prevention and control measures. All non-essential services will be suspended. Schools and offices will be closed. The inability of people to gather makes the audit a problem.
Under the background of rapid development of big data technology, information technology has made new breakthroughs, especially the development of cloud computing and data mining technology, which has laid a solid foundation for the progress of new audit methods in the era of big data. In this case, big data audit has become the main audit method used by audit institutions and auditors. For the audit object, auditors can use the new audit method of big data audit to collect and sort out all the data related to the business, and output the audit report on the basis of comprehensive analysis of these data, so as to make a comprehensive evaluation on whether the audited object can effectively use the financial information system to reasonably arrange the asset operation. In the era of big data, it has the characteristics of 4 V (volume, velocity, variety, veracity), which is the fundamental difference from traditional audit.
At the same time, the continuous advancement of information technology has changed the financial management model. The financial sharing service model based on cloud computing, data mining and Internet technology is the representative. Under the condition of the financial shared service model, enterprises and institutions rely on advanced technologies such as cloud computing to reevaluate their internal financial processes, and independently strip off their internal routine, standardized and repetitive financial processes, and put them in a unified To be processed in the processing system, this unified processing system is the cloud accounting platform of the group enterprise financial shared service center. The establishment of the cloud platform system has broken the traditional management mode in which the internal subsidiaries and branches and functional departments cannot be organically connected, and is of great significance to optimize business management processes with business management as the core. Under the new model, the platform system can collect all the financial information of the unit, and the various functional departments of the unit can obtain all kinds of information in real time according to their actual needs [1].
Big data technology has improved the financial management model of enterprises, and optimized the traditional audit methods, and promoted the audit work to a higher standard and more efficient direction [2]. Under the financial sharing model, the big data audit can be defined as follows: all enterprises included in the audit platform system are taken as the audit target, and the big data audit method is used to audit the relevant data to obtain relevant suspicious information. The technology can also find relevant evidence in this process, and finally draw audit conclusions and write audit reports.
Pretreatment of big data in Financial Sharing Service Mode
Flow direction of big data
Whether we can fully obtain all kinds of big data related to the production and operation business of the auditee is the precondition of big data audit. Before preprocessing big data, we should first confirm the flow direction of big data in the financial sharing service mode. The construction of cloud platform system is a necessary condition for the establishment of financial service sharing mode. Through this system, RRP / SCM of each functional department in the unit can be organically linked, which makes it different from the traditional financial accounting mode. Under the financial sharing service mode, big data audit can better solve many problems faced by big data audit under the traditional financial accounting mode [4].
The task of data collection is heavy
In the traditional financial accounting mode, the financial information inside the unit is not highly related, and it is difficult to communicate with each other effectively. If it is necessary to audit the unit, it is necessary to integrate the accounting information of each department into the relevant audit data of the unit, which greatly increases the work task. However, the above difficulties will not be encountered in the financial sharing service mode. With the cloud platform system, auditors can easily obtain the relevant data required by the audit, saving a lot of human and material costs.
Heavy task of data sorting
Under the traditional financial accounting model, there is no effective connection between relevant departments of the unit, and there are many differences in data interfaces and standards. This requires auditors to carefully collect relevant information on the one hand and to sort out the data on the other hand. The length of the sorting process and the complexity of tasks greatly reduce audit efficiency and the audit cost remains high. In the financial shared service model, the establishment of the cloud platform system has standardized various types of financial data, and the related business systems have also been organically connected. Audit staff do not need to consider how to spend too much manpower and material to organize data when collecting standardized data, and the quality of the data can be better guaranteed [5].
Inefficient use of external data
In the traditional financial accounting mode, because the accounting information system of each department and the relevant business system are relatively independent from each other, it is difficult for auditors to collect all kinds of external information related to audit in each business system. However, under the financial sharing service mode, the cloud platform system can realize the effective management of internal and external information of the enterprise. Through this platform system, the audit staff can easily obtain the required external data, which will greatly improve the efficiency of data collection.
Preprocessing of big data
After the big data flow is clear, we can clearly grasp the big data audit based on the financial sharing service mode, which can fully improve the audit efficiency and reduce the audit cost. After that, the main work is to preprocess big data.
Big data collection
The various types of data collection based on the cloud platform system are mainly conducted in the following three ways: The first method is to directly collect financial data, business data and various strategic data related to audit objectives through the cloud platform system; the second way is to complete the seamless connection with the cloud platform system. For example, from the ERP system, the auditors can directly obtain all kinds of relevant data directly related to the production and sales of the enterprise. The third way is to obtain various types of data related to enterprise audits from outside the enterprise [6]. Under the financial shared service model, standardized financial data can reduce the work pressure of auditors during the data collection process, and can also reduce audit costs and improve audit efficiency.
Big data cleaning
When the big data collection is completed, the relevant data needs to be cleaned in order to further improve the quality of the audit related data, and at the same time correct or eliminate any conflicts in the various types of data. Although under the financial shared service model, various types of financial data or other data in the cloud platform system have been standardized, but in order to improve the quality of the data, the relevant data still needs to be cleaned, which is a process that preprocessing must complete [7].
Store big data
After completing the cleaning of big data, the auditors need to establish an audit database to centrally manage and store the various types of cleaned data so that the audit staff can extract the relevant data at any time.
Implementation process of big data audit based on financial shared service model
Construction of process framework
After the big data preprocessing is completed, the audit staff can carry out the audit work according to the established audit plan, and find the audit doubtful points, and collect relevant evidence that can prove these doubtful points, and draw the audit conclusion and write the audit report. The specific audit work flow is mainly carried out in accordance with the following six steps: determining audit objectives, identifying and evaluating audit risks, formulating and improving audit plans, selecting operational audit procedures, implementing audits in detail, drawing audit conclusions and writing audit reports. The specific audit process framework is shown in Fig. 1 [8].
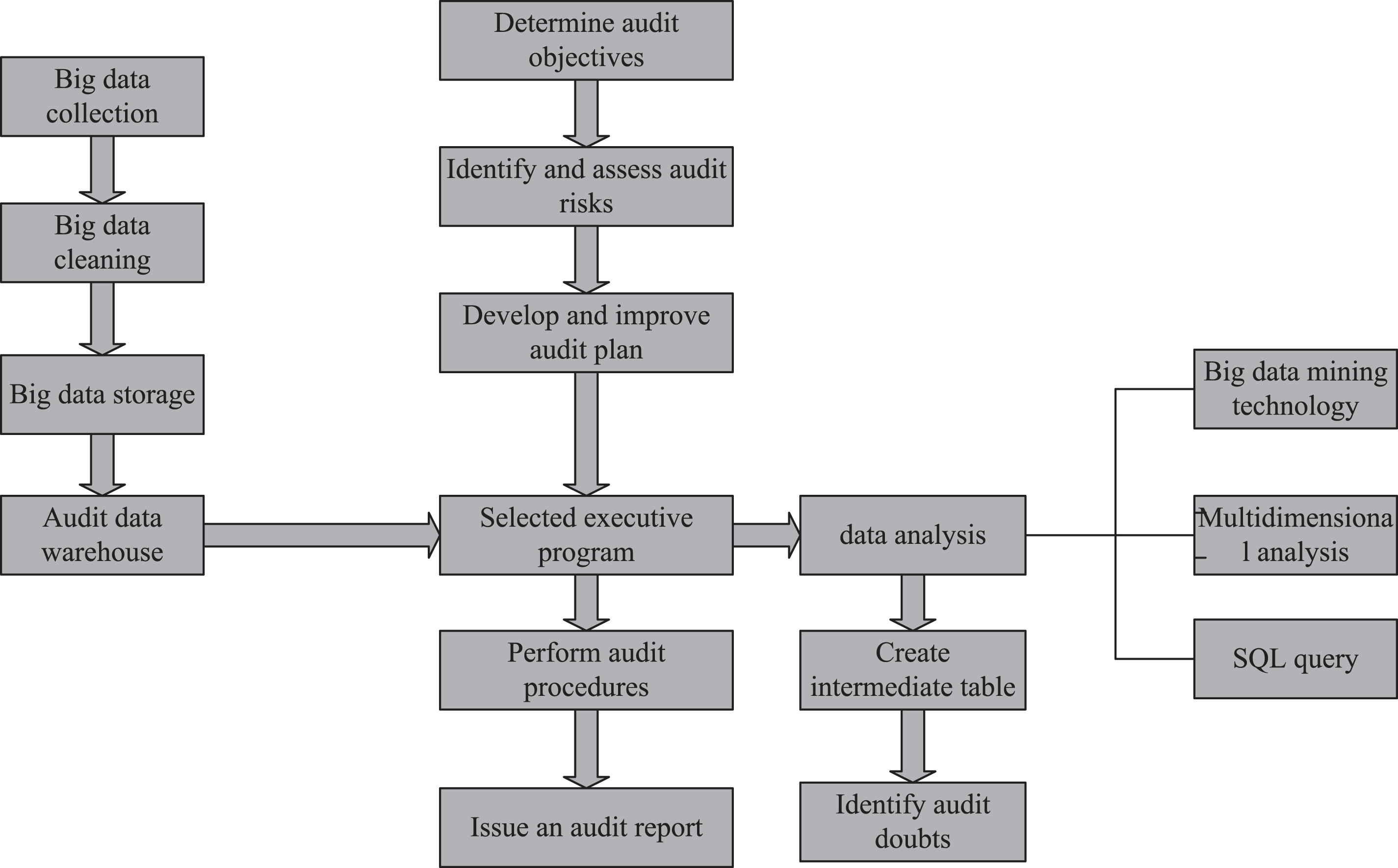
Flow chart of big data audit based on financial shared service model.
Determine the audit objectives
Essentially, big data auditing is an auditing method. This auditing method has no effect on the audit staff in setting audit goals. The determination of the audit objective requires the audit staff to choose according to the actual situation. From the perspective of the executive, we can see that the big data audit based on the financial shared service model can not only serve the internal audit of the internal auditors of the enterprise, but also provide the external audit services of the auditors of external accounting firms to the enterprise [9]. From the perspective of audit objects, on the one hand, big data auditing can audit the business of the enterprise, and on the other hand, it can audit the accounting information of the cloud platform system. If the object of the audit is all kinds of business of the enterprise, the focus of the audit should be on the process and capital flow that can fully reflect the business. If the object of the audit is a cloud platform information system, the focus of the audit should be on whether the cloud platform system can protect enterprise assets, maintain data, and minimize the consumption of economic sources. If an internal audit is required, the focus of the audit should be on whether the financial information system based on the shared financial service model can help management decisions. If an external audit is required, the focus of the audit should be on judging whether the various financial statements provided by the enterprise to the expected information users in the financial shared service model can help its decision-making [10].
Identify and evaluate audit risks
The importance has a certain negative impact on the risk of big data audits. The process and results of big data pre-processing will also have a certain negative impact on the audit in various ways and bring certain audit risks. Normally, if the pretreatment process fails to comply with the regulations, or the audit results and audit requirements are different, it will increase the probability of audit risk [13]. In addition, audit risk is also closely related to the credibility of the cloud platform system. If the credibility is low, on the one hand, it will increase the audit risk, and on the other hand, it will also have a certain impact on the audit results. In order to effectively identify and evaluate audit risks, it is necessary to effectively supervise the big data preprocessing process. The audit working group should also use a professional third party to evaluate the internal control and credibility of the cloud platform system and other systems, and use this to judge the status of the audit risk.
Develop and improve the audit plan
When formulating a big data audit plan, the scope, time, arrangement of specific matters, and resources required for the audit should be fully taken into account. In particular, attention should be paid to the time and labor arrangements related to the big data preprocessing process. Compared with traditional audit methods, the audit scope specified by big data audit is wider. These data mainly come from the audit database constructed by the previous big data preprocessing link, which contains internal and external financial data related to the audit and other data related to the audit.
Selection of operational audit procedures
The big data audit procedure based on the financial shared service model requires the following three steps to achieve: Data Analysis, Establishment of Intermediate Tables and Formation of Audit doubts. About the technical principles of these tools, the article will be specifically discussed in Chapter 5.
Implementation of audit procedures
According to the audit plan, we should start to implement the relevant audit work. In the specific implementation process, we should conduct a comprehensive supervision on the collection, sorting and storage of all kinds of audit big data. Third party experts have conducted professional comprehensive evaluation on the reliability of “cloud platform system” and other business systems. Audit staff should take this as the basis, find evidence through cloud platform system and other business systems to confirm audit doubts, and lay a good foundation for the formation of audit results. The problems found in the audit process should be fed back to the management in time, and the review and evaluation of these problems should be done well.
Report audit results to management in a timely manner
The auditors determine the doubtful points of the audit according to the audit plan, and obtain various audit evidences based on them to confirm the doubtful points of the audit and obtain the audit results. Before making the final audit conclusion, the auditor needs to fully consider the auditee and its environment, and should also refer to the previously determined audit objectives. All kinds of misreporting problems found in the audit process should be reported to the audited management in a timely manner, and specific improvement opinions can also be given, and an audit report will be formed after the management’s response.
Technology implementation of big data audit service platform
As mentioned above, the big data audit procedure based on the financial shared service model needs to complete the following three steps: Data Analysis, Establishment of Intermediate Tables and Formation of Audit doubts. Next, we have a special chapter on the technical realization of the above steps.
Data analysis
The discovery and formation of audit suspicious points requires the use of data analysis during the audit process, and the acquisition of audit evidence needs to be based on audit suspicious points. In the process of data analysis, the audit staff should pay attention to the connection between the cloud platform system and ERP, SCM and other business systems, and should also pay attention to the control of business processes such as settlement management, voucher certification, auditing and file filing in the platform system. Data analysis mainly includes the following three methods:
Big data mining technology
Data analysis and mining is the most critical step in big data processing. Data analysis mainly uses big data analysis tools to analyze and classify the massive data stored in the distributed database or distributed computing cluster to meet the common analysis needs. For example, some real-time requirements will use EMC’s Greenplum, Oracle’s exadata, and MySQL based columnar storage infobright. For some requirements based on semi-structured data or batch processing, Hadoop can be used in the process of statistical analysis. Because of the large amount of data involved, it will take up a lot of system resources, especially I / O. In addition, there are high requirements for the use of statistical tools and keywords that need to be classified. They determine whether the data can be classified accurately, which will directly affect the accuracy of data mining value. Data mining is based on the calculation of various data mining algorithms for the big data that has done a good job in statistics. It extracts the hidden and potentially significant information, reveals its laws and results, and is used for decision-making and prediction. Therefore, the traditional relational, structured data sets and mining methods are no longer applicable. Big data mining generally does not have a pre-set topic, only accurate and appropriate algorithm can get valuable data analysis results. The typical algorithms are K-means for clustering, SVM for statistical learning and naive Bayes for classification. The main tools used are mahout of Hadoop.
Auditors can use automatic big data mining algorithm to deal with all kinds of big data in data warehouse, so as to find out all kinds of problems hidden in all kinds of data, and finally determine audit doubts. The main functions of big data audit data mining technology based on financial sharing service mode are as follows: on the one hand, it can discover the financial, non-financial or other business data abnormalities through this technology; on the other hand, auditors can associate the financial data in cloud platform system with business system data such as ERP. So as to establish the cross checking relationship between various types of data, and then determine the audit doubts, and find out the problems in the business work [14].
The application of big data mining technology mainly adopts Apriori algorithm, which is introduced as follows.
Apriori algorithm is a frequent item set algorithm for mining association rules. Apriori algorithm scans transaction database many times, and generates frequent sets by using candidate frequent sets every time. Its main steps can be divided into defining minimum support, filtering all frequent item sets and generating association rules based on confidence. Its algorithm is mainly based on the distributed implementation of spark, as shown in Fig. 2 [15].
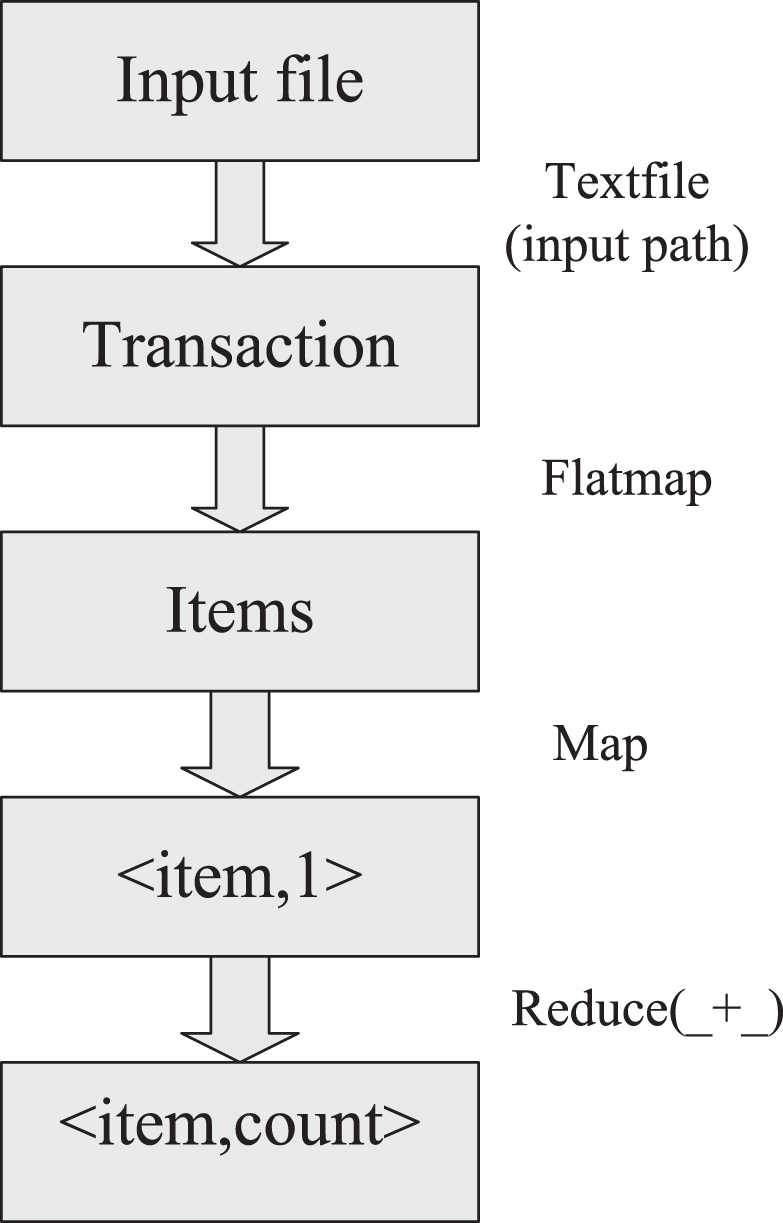
Implementation flow chart of distributed Apriori algorithm.
The main idea of the algorithm is as follows:
Step 1: Generate frequent 1 item set L1. The transaction set T is distributed to each machine in the form of RDD < string, l > . The cumulative number of items and the item set with higher support are reserved.
From frequent k term set Lk, frequent K + 1 term set Lk +1 is generated. LK self-connects to generate CK +1, and then scans the database to generate LK +1 according to C + 1.
The core steps of parallel Apriori algorithm are:
val fiml = transactions. FlatMap(1ine = >line). Map ((,1))
ReduceByKey (_ + _). Filter (_._ 2 > min-Support)
savefiml (fiml,output+”result--1”,sum)
def savefiml(fim:RDD[(string,int)],path:string,
count:double):Unit = {
fim.map(1ine = >{
line._1+“:%.2f”.format(1ine.–2/count)}).
Coalesce(1, true). SaveAsTextFile(path)}
var(trans,newfim) = LI tofim2(rim I.rnap(_-____________1).
collect,transactions,minSupport)
save(newfim,output+”resultÒ2”,sum)
def
L 1 tofim2(L 1:Array[String],trans:RDD[(String,
Int)],minSupport:Double):RDD[(List[String],Int)] = {
val L 1 C—L 1.size
val citems = scala.collection.mutable.ArrayBuffer[List
[String]]()
for(i< -0 until Llc){
for(j< -i+1 until Llc){
Citems + = List(L 1(i), L1(j)). sortWith(_ < _)
}
}
Step 2: Supporting data De duplication data holding certification scheme:
If the user is logging in to the data client for the first time, the first step is to register an account, which contains a unique user name, ID and password. At the same time, all the information in the account will also be owned by the cloud service provider and the trusted third party.
At this point, the key used to validate the file is generated by calculation on the local client.
The specific steps are: to find the large prime number p,q, when p = 2p + 1 and q = 2q + 1, and meet the condition of N = pq at the same time, the generator g needs to be found in the category of the positive integer PQ cyclic subgroup, and then find the large prime number e and large prime number d that are larger than the safety parameters, so that the large prime number e and large prime number d meet ed = 1(mod pq), and then the binary number v of k-bit will be randomly generated by the system.
Among them, the private key sk is embodied by (e,d,v) and the public key pk is embodied by (N,g). The above steps are the same as the traditional PDP scheme. After the public key and private key are generated, the new password PW needs to be input. After the private key is encrypted by AES, it is stored again, and then the public key is publicly stored in the database. The user needs to upload the file F. the client first calculates the MD5 value M of the file, and then sends the result to the cloud server after the calculation. The verification process of the cloud server for the received M is as follows:
if (searchHash (HashTable,m)==true):
sendClien (t randomKey,FID);
else requestFileTag ()
In the process of searching hash table by the server, if M can be verified, the system will generate a random ran domkey key after returning to the client, and the system will continue to run step (2) after the key generation is completed. However, if the existence of M cannot be verified, the system will request the client to upload the file label and the corresponding file. (2) When the server finds the existence of m in the running process, the system returns to the client and generates a file number FID and a random key.
The client sends the result to the cloud server through the calculation of M ‘value and FID of the file. The secondary verification process of the received M’ by the cloud server is as follows:
F = getFile (FID);
temp = MAC (F, randomKey);
if (m′==temp):
addFileUser (FID,user);
sendThirdParty (FID);
else requestFileTag ();
The client of the system includes user and file management, visual verification and integrity verification. The user management business in the client is realized through the user management module, which mainly includes two businesses: user login logic and user registration. The file management module implements all business logic related to file storage in cloud storage. The visualization of the client interface is realized by the visualization module. At the same time, the module supports the user to read, write and manage the file on the client, which can give the user a better practical embodiment. Using the client to verify the integrity of files can improve the business logic, and then effectively complete the verification module.
The MD / MF (multi-dimensional / multi feature analysis) model, which was established by corpus linguist Douglas Biber in 1988, is used to describe the discourse relationship between spoken and written styles. This method uses standardized computer-based text corpus and automatic recognition technology to calculate frequent lexical and grammatical features. The co-occurrence pattern of these features can be used to analyze and confirm the functional dimensions of language variation in texts through multivariate statistical methods, and provide a comprehensive description of the relationship between the genres of these dimensions.
This is a common analysis method in big data audit. Based on the multidimensional data stored in the audit data warehouse, the audit staff summarize, associate, cluster, classify and analyze it from different perspectives. Compared with data mining technology, multi-dimensional analysis method is more convenient to find problems in business process in the process of data analysis, and obtain audit doubts. Finally, the audit staff get the audit evidence and form the objective audit conclusion with the help of the multi-dimensional data aggregate audit. The algorithm formula is as follows:
If C f (α, β) = 0, the linear approximation is called a zero-correlation linear approximation.
For each cipher text selected, it is obtained by partial encryption and decryption (p, c), the value of z can be obtained by formula (1), and the counter N [z] is established.
If the guessed key is the correct key, then the statistic T is expected to be
Then the formula can be deduced
In addition to the above two methods, SQL query technology is also a frequently used data analysis method in big data audits. SQL query technology can achieve cross query and fuzzy query between multiple tables. Audit staff can use this technology to find all kinds of potential problems in business processes faster and determine audit doubts. In order to verify the technical effects of SQL, this article compares it with traditional methods. The empirical results show that SQL search has a significant cost difference compared to traditional methods. See Figs. 3 and 4.
Traditional way of query.
SQL query.
No matter which data analysis method is used, to help the audit staff to find the problems in various types of data and determine the audit doubts is the ultimate goal. After the audit doubts are determined, we need to find evidence to confirm the audit doubts, and finally form an audit conclusion and write an audit report. The intermediate table is a transition to determine the audit doubts. It is a step table formed by the audit staff after processing the data standard table according to the audit analysis model. Due to the complexity of various types of audit business data in the audit process and the similarities and differences between the audit and audit relationships, the audit staff needs to set up one or more intermediate tables in the process of finalizing the audit doubts. These intermediate tables will provide important information for the auditors to verify the audit doubts Refer to. The intermediate tables established at all levels following the prescribed process provide a solid foundation for audit staff to determine audit doubts and obtain audit evidence. In the process of establishing the intermediate table, you can consider using “cascade", “projection” and other methods.
Determine audit doubts
All kinds of potential problems summarized after the above big data analysis and comparison of the intermediate table are audit doubts. After obtaining the audit doubts, the audit staff need to provide audit evidence for these doubts, so as to verify whether these doubts are false reports caused by operational errors or fraud, and form audit conclusions according to the verification results. In the process of verifying audit doubts, the key is to verify the authenticity and integrity of all kinds of financial, non-financial and business data. Under the background of big data audit based on financial sharing service mode, audit staff do not need to carry out complicated letter verification work in substantive procedures, only through cloud platform system or other business systems can directly verify the reliability of external data, which greatly improves the efficiency of audit work while saving audit cost.
Conclusions
As the COVID-19 epidemic continues to spread, the government has managed to prevent people from gathering. The audit work can only be carried out through the network, which puts forward higher requirements for the accuracy and effectiveness of the audit work. The article analyzes the data flow and preprocessing process of big data audit under the background of financial shared service model, and on this basis, elaborate all the processes of big data audit under this model, with a view to the financial shared service model. The implementation of big data audits lays a theoretical foundation and creates more favorable conditions for popularizing big data audit methods and financial shared service models under the influence of COVID-19 epidemic.