
Abstract
The linguistic artificial intelligence teaching model can be assisted by the intelligent speech recognition model. The traditional speech recognition algorithm has certain problems, so it cannot effectively eliminate speech noise. Based on the advantages of the linguistics teaching model, this article combines the linguistics teaching model and the artificial intelligence model to build an artificial intelligence assisted teaching model that can be used for classroom teaching. Moreover, this study improves the traditional algorithm and constructs an artificial intelligence linguistics teaching model based on the improved algorithm. The filtering part of noise includes preliminary filtering of speech signals based on the short-term energy detection method, and further detection and recognition of preliminary filtering speech signals based on the artificial intelligence model detection method. After these two steps of filtering and recognition, the voice file is sent to the client for processing and control. In addition, this study set up a control experiment to analyze the performance of the model. The research results show that the algorithm in this paper has a certain effect.
Introduction
With the continuous development of science and technology, artificial intelligence models gradually gain English in teaching. Moreover, Artificial intelligence will not only change the teaching method, but also bring some help to teaching. For linguistics teaching, due to the influence of the teaching model and the teacher’s own pronunciation, the improvement of students’ language ability is not good. At this time, the artificial intelligence model can play a role, intelligently recognize the student’s voice through the language model, and obtain the corresponding result and output it to the terminal. Moreover, through artificial intelligence models, teachers can grasp the language learning situation of students in time.
The age of English enlightenment is gradually getting earlier and learning methods and learning effects are receiving widespread attention. From the perspective of age, students and white-collar workers are no longer the main body of English learning, and the population has expanded to preschool children and middle-aged and elderly groups. Regardless of the learning effect or way of these people, we are often attracted by the following situations. For example, students who work very hard on campus are not as good as those who are not diligent; some students master and use new words and sentence patterns faster than ordinary students; some students successfully completed Japanese and French in high school; some students are very capable of language learning and use in their early childhood, but their language learning performance is poor in high school or college [1]. Outside the campus, some older people’s language learning ability and language use ability are much better than young people’s, or the acceptance ability of infants and young children is much better than young people. The reason is that there are huge differences between these language learners, and learners themselves also have significant differences at different ages. The key is that learning effect is affected by many variables such as cognitive strategy, cognitive style, learning motivation, intelligence, personality, age and so on. The influence of these variables on foreign language learning has been extensively and deeply studied. However, language aptitude is the most important factor influencing foreign language learning in addition to motivation and the most effective factor in predicting foreign language learning performance.
Language is an important means for teachers to engage in teaching work, as well as the basic skills and necessary qualities of teachers in teaching. For teachers, language is the key to open the treasure trove of knowledge and a bridge connecting the hearts of teachers and students. Both the cultivation of students’ abilities and the development of students’ intelligence must rely on language [2]. Moreover, the pros and cons of language are closely related to the effect of classroom teaching. Since the implementation of the new curriculum reform, chemistry teaching does not want teachers to “fill the classroom” in the classroom, but requires teachers to teach less and better language, to ensure that students have sufficient time for independent exploration and practice activities. First, for any problem that students can solve through understanding, thinking, discussion, experiment, etc., teachers need to make sure that they don’t say the problem first. Second, teachers need to never waste time on unnecessary repetitions of problems that students already understand. Third, teachers can never sum up any questions that can be clearly explained in one or two sentences. In addition, the new curriculum reform requires strengthening students’ initiative in the classroom and actively mobilizing students’ enthusiasm for learning in the classroom. At the same time, it also requires teachers to have good classroom teaching language cultivation. It can be seen that the beautiful language of teachers can inspire students’ thinking and stimulate students’ enthusiasm for learning [3].
The beautiful, vivid, definite, concise language in the teaching makes the students feel happy when they listen to the class, and makes the class a kind of enjoyment, so that the students have a desire to learn actively. Teachers’ ability to use language will directly affect the teaching effect. For young teachers who have just stepped into work, how to accurately and refined lectures has become a top priority. Therefore, the cultivation of young teachers should deeply analyze the connotation of teachers’ classroom teaching language from the perspective of linguistics, put forward the formation and training content of classroom teacher language, and then put forward a training system for classroom teaching language skills. Moreover, the trainers need to propose training strategies that can improve and enhance the language skills of classroom teaching in response to the problems encountered by young teachers during the lectures, and provide help for young teachers entering the workplace to make them closer to the actual classroom teaching operations of teachers. In this way, young teachers can try their best to adapt to the working environment as quickly as possible and achieve the best teaching effect.
Based on the advantages of the linguistics teaching model, this article combines the linguistics teaching model and the artificial intelligence model to construct an artificial intelligence-assisted teaching model that can be used for classroom teaching, thereby effectively improving classroom teaching efficiency and helping students quickly improve their grades.
Related work
With the development of Internet technology and artificial intelligence, the field of intelligent hardware has ushered in a golden period of fierce development. In various fields, a variety of smart devices are constantly emerging, and they have penetrated into all aspects of life [4]. At the same time, the development of science and technology has also promoted the upgrading of the human-computer interaction interface, which has gone from the command line interface (CLI) to the graphical user interface (GUI) to today’s natural user interface (NUI). This development trend tells us that today’s users are eager to achieve human-machine interaction in a more natural, intuitive and user-friendly way [5]. In recent years, the introduction of new human-computer interaction methods such as voice [6], somatosensory [7], and eye movement [8] have greatly improved the naturalness of interaction.
In the 1990 s, the audio guides represented by the American LISTEN brand were popular all over the world. The audio guide uses wireless communication technology, that is, voice information will be synchronously sent to the receiver headset worn by the user through the form of radio waves. However, the voice information cannot be re-listened, and the explanation content cannot be selected, and the user can only listen passively [9].
The iBeacon function launched by Apple is popular in the market, prompting the rapid development of somatosensory voice equipment. The typical representatives are Siemens short-distance interpreter and We Chat “shake” to explain. The working principle is that the iBeacon hardware sends a unique ID to the voice device at a certain distance from it. After that, the voice device receiving the ID will make corresponding feedback information according to the ID. Therefore, as long as the user approaches the exhibit or shakes the mobile phone, the explanation function of the corresponding exhibit will be triggered naturally [10]. Modality [11], that is, various types of communication Modalities for users to communicate and obtain information. It contains four elements: human information representation [12], human organs [13], computer interactive equipment [14] and computer information display [15–22]. According to the input and output direction, it is divided into action input modality and perceptual output modality. A motion input modality is an information pathway in which human information is expressed through certain action organs, acquired by specific input devices, and converted into the corresponding computer information representation through appropriate processing. The perceptual output modality refers to an information pathway in which the computer information representation is presented through an output device, acquired by a specific human sensory organ, and then converted into the corresponding human information representation through appropriate processing [23]. Multimodal refers to the nature of an interactive system designing two or more channels in one direction of input or output, and an interface with this property is called a multimodal interface. Human-computer interaction, that is, the communication between the user and the computer system, is a two-way information exchange between various symbols and actions between the human and the computer. Multi-modal human-computer interaction [24–28] is based on advanced interactive technologies such as line-of-sight tracking, human-machine dialogue, gesture recognition, and sensory feedback. It provides users with multiple interaction channels to interact with the computer system in a parallel and imprecise manner and aims to improve the efficiency and naturalness of human-computer interaction. In a multi-modal human-computer interaction system, users can use natural interaction methods, such as gestures, voices, eye movements, etc., to work collaboratively with the computer system. The research on multi-modal human-computer interaction began in the 1970 s and was mainly used in the computer field. Moreover, the concept of “conversational computer” was proposed. Users can use language, body, expression, etc. to interact with the computer, that is, the user uses the communication methods in their daily life as communication with the computer [25]. From a biological point of view, human experience in life scenes can be attributed to the cooperative work of various physiological organs, including eyes, nose, ears, etc. Corresponding to this, the multi-modal has been generated. Multi-modal human-computer interaction uses two or more channels of perception to interact with the product. Moreover, it strives to conduct human-machine dialogue in a natural, parallel, and collaborative manner, to achieve diversification of product use, and to pursue the assimilation of product functions [29].
Language feature extraction
As we all know, speech is a non-stationary signal, so when analyzing speech-related characteristics, we often use the short-term analysis method, that is, the speech is assumed to be short-term and stationary. Generally, the features of short-term speech analysis include short-term zero-crossing rate, short-term energy, and cepstrum distance. The common speech features are described in the following in Fig. 1.

MFCC feature extraction process.
For each frame of speech signal, the number of times the signal sign of the sampling point changes is the short-term average zero-crossing rate. It reflects the characteristics of frequency changes. Obviously, the signal has a higher zero-crossing rate at high frequencies, and the zero-crossing rate will decrease at low frequencies. Therefore, a rough estimate of the spectral characteristics can be obtained through it. For discrete signal x (n), the short-term average zero-crossing rate is defined as:
Among them, the effective length of the signal is N, and the definition of the symbolic function is shown in (2):
The short-term average energy can track the change trend of the voice signal, and the difference between voiced and unvoiced frames is obvious. Therefore, this feature can effectively identify the effective starting segment of the voice. The short-term average energy is defined as:
In the formula, w (n) is the window function.
In 1989, triggered by the human sound perception model of inner ear frequency analysis, Davis et al. first proposed Mel-frequency cepstrum coefficient (MFCC). The steps of MFCC feature extraction are [3]:
It is obvious from the extraction process that MFCC essentially calculates the energy held by the frequency band in a certain frequency range, which is similar to the characteristics of short-term energy. However, since the calculated frequency band is within the hearing range of the human ear, it exhibits an amplification effect in the voice part. The MFCC features have large numerical differences in different dimensions. In order to average the contribution of each dimension and reduce the impact of the acoustic signal distortion, the MFCC features need to be further processed by mean normalization. The processed feature vectors are as follows:
Among them, M is the MFCC feature of the current frame,
In the formula, n is the order of the MFCC feature.
Speech recognition is to convert a piece of audio containing speech into the corresponding text output. The development of speech recognition technology has experienced the recognition of small vocabularies, specific people and isolated words, large vocabulary, continuous speech and non-specific person speech recognition. Each technology and algorithm innovation bring breakthroughs to speech recognition.
The use of probability and statistical modeling is the mainstream idea of current speech recognition technology. Through Bayesian principle, speech recognition can be described as a prediction problem of text output for observation sequences. The mathematical formula is described as follows:
Among them, X represents the input observation sequence, that is, the speech feature vector, W represents the possible word sequence, and p (W|X) represents the posterior probability of the output word sequence W under the condition that the observation sequence X is given. Because it is difficult to directly derive p (W|X), the conversion is performed using Bayes’ formula. p (W|X) represents the probability that the observation sequence is output under the condition of a given word sequence, and this probability can be obtained through an acoustic model. p (W) represents the output probability of the word sequence, which is only related to the language model of the system. p (X) is a constant term that has nothing to do with the word sequence, and has no effect on the solution of the system output probability.
The audio frames detected through the endpoints will be input into the speech recognition module for the pattern matching process. Feature extraction is the basis of the pattern matching algorithm, so the speech signal features will be extracted frame by frame next. Traditional feature types include Mel Cepstral Coefficients (MFCC), Perceptual Linear Prediction (PLP), etc. Subsequently, the extracted features are matched with the acoustic model to obtain the most probable words. Finally, the most likely word sequence is calculated and output through the language model. Figure 2 shows the overall process of the speech recognition system:
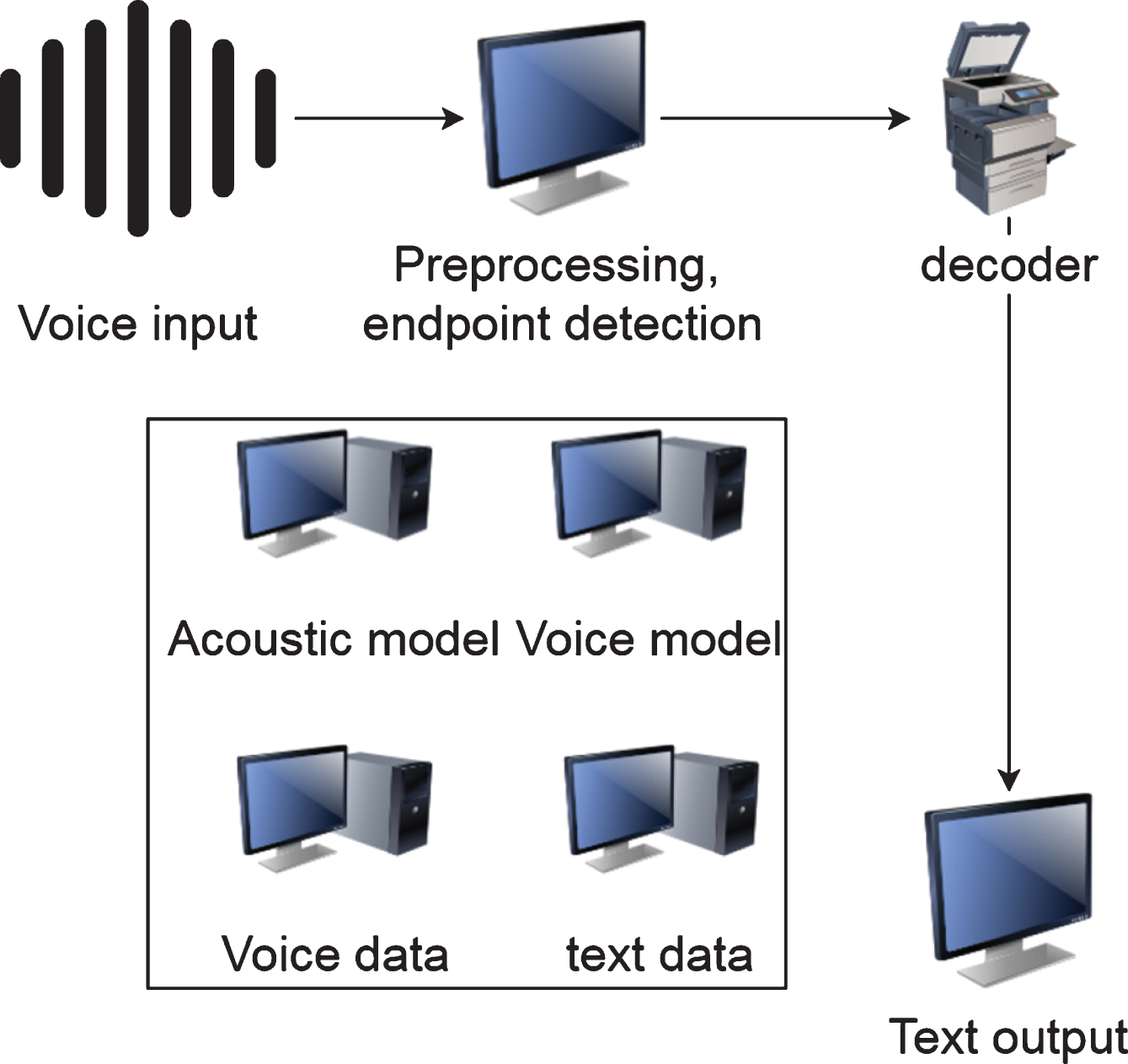
Flow chart of speech recognition.
In summary, the acoustic model is used to calculate the likelihood probability of the pronunciation elements corresponding to the observed sequence, the language model is used to calculate the combination probability of the word sequence, and the pronunciation dictionary is used to convert between sound and word. Therefore, acoustic models and language models play a vital role in speech recognition.
With the development of deep learning, research has found that deep neural networks (DNN) have powerful model fitting capabilities and can achieve better results when used in acoustic models. In the subsequent research, a context-sensitive deep neural network-hidden Markov model (CD-DNN-HMM) was proposed. Compared with the traditional GMM-HMM model, the performance of large-vocabulary continuous speech recognition can be greatly improved. Since then, the use of DNN-HMM model to study acoustic models has once become a research hotspot.
(1) Hidden Markov model: HMM is an extension of the Markov process, so you need to understand the Markov process. Markov assumed that the current state of the random process is only related to the most recent historical state, but not to the earlier historical or future state. Speech is a time-related signal. After discrete sampling, the recognition process is transformed into a time-discrete, limited-state Markov process. However, the state of the stochastic process described by the traditional Markov model and its model output probability are completely bound. In order to get rid of this completely binding relationship, HMM also extended the state output of Markov process to a double random process. Its state cannot be directly observed but hidden behind the visible observation sequence. The principle of HMM in speech recognition is shown in Fig. 3:

HMM speech recognition model.
As can be seen from the above figure, a typical HMM structure includes the following 5 elements: π ={ π
i
}: Initialized probability matrix, also known as emission matrix; Ω ={ S
i
}: State collection; B ={ b
i
(x) }: State output probability distribution; A ={ a
ij
}: State transition matrix; X ={ x
i
}: Feature vector;
In the modeling process, the above parameters must meet the following constraints:
At the same time, according to the timing characteristics of speech, the HMM is defined as a first-order Markov process, that is, it is only related to the state at the previous time. The convention is given by formula (9). Another simplification is “output-independent assumption", that is, the output at the current time is only related to the state at the current time, and the convention is given by formula (10).
After establishing the conditional assumptions of the above HMM model, the next step is to solve the three classic problems of the HMM framework, namely the evaluation problem, the decoding problem, and the training problem.
The first problem to be solved is the basic evaluation problem, that is, when the HMM model parameter Φ and the observation sequence X ={ x1, x2, ⋯ , x T } are given, how to quickly calculate the likelihood probability p (X|Φ) of generating the observation sequence under the conditions determined by the model. Since the state sequence that produces X is hidden and cannot be directly calculated, it can only be obtained by summing p (X|S, Φ). However, the sum of all states has the problem of excessive calculation. In order to solve this kind of problem, the commonly used algorithm is forward-backward algorithm.
Secondly, since the observation vector is known but the most consistent state sequence is unknown, the decoding problem is to find the best matching state sequence under the condition that the HMM model parameters and the observation sequence are known, namely:
This is a problem of path optimization, which is generally solved by Viterbi algorithm.
Finally, the model training, which is a problem of parameter estimation. That is, under the condition that the observation sequence and initial HMM parameters are given, the model parameter Φ is adjusted to maximize the likelihood value p (X|Φ). The solution to this problem is generally through continuous iterative approximation, and the Expectation-Maximization algorithm (EM) and Baum-Welch algorithm are effective algorithms to solve this problem.
The establishment of the HMM model effectively solves the problem of changes in the timing of speech frames. The next step is how to determine the number of states of the utterance unit, which is just a general clustering problem. The following will introduce the application of hybrid Gaussian model and neural network in this aspect.
(2) Mixed Gaussian model: The mathematical definition of the Gaussian mixture model is shown in Equation (10), which is used to describe the probability distribution of continuous random variables:
In the formula, the weight c
m
is a positive real number, and its limiting condition is:
Speech is a changeable signal. It is affected by different factors and shows different states. For example, when a person has a cold, the pronunciation will change, or the speaker’s speech rate will be different. Therefore, the same pronunciation will show different states. The reason why the hybrid Gaussian model can be used to model the speech feature distribution is that it has super-strong fitting ability and can fit almost any distribution of data. Among them, each factor that affects pronunciation is fitted by a multivariate Gaussian, and then all the multivariate Gaussians are superimposed to obtain a speech feature distribution model in multiple states. For a D-dimensional Gaussian model with M components, its definition is as follows:
In the formula, μ is the mean vector and ∑
m
is the covariance matrix. The parameters of the Gaussian mixture model are mainly estimated by the EM algorithm, and the formula is as follows:
In the formula,
(3) Deep neural network: The deep neural network is a traditional multi-layered perceptron (MLP) with multiple hidden layers. The figure shows a 5-layer DNN, which includes the input layer, the output layer, and the hidden layer.
For a L + 1-layer DNN, the input layer index is L = 0 and the output layer is denoted as L. Then, for the output vector v
l
of the l-th layer, it is defined as:
Among them, the excitation vector is z
l
= W
l
vl-1 + b
l
∈ RN
l
×1, the activation vector is v
l
∈ RN
l
×1, the weight matrix is W
l
∈ RN
l
×Nl-1, the bias matrix is b
l
∈ RN
l
×1, and the number of neurons in layer l is N
l
∈ R. Obviously, the input feature vector is v0 = o ∈ RN0×1, and N
o
= D is the dimension of the feature. For the mapping function: f (·) : RN
l
×1 → RN
l
×1 is the activation function for element-level calculation of the excitation vector. In most cases, the activation function is the sigmoid function:
Or Rectifier Linear Unit (ReLU):
In speech recognition, acoustic modeling is used to establish which acoustic unit a single previous speech frame is most likely to belong to, which is a multi-classification problem. Therefore, the strong classification ability of DNN as shown in Fig. 4 can be used to model the acoustic model. Each neuron in the DNN output layer represents the category i∈ { 1, 2, ⋯ , C } of the current input feature vector o, where C = N
L
is the number of categories. The value
In the formula,
The forward and backward propagation algorithm is a common algorithm for DNN training models. For a given feature vector o, the output of the DNN is determined by the weight coefficient W and the bias coefficient b, and the activation amount is calculated through the input layer, and then the activation amount is propagated layer by layer to the hidden unit of each layer, and finally the output result is obtained. This process is often referred to as the forward algorithm. After a round of iterations of the forward algorithm, the output layer will incur an error cost. The back-propagation algorithm uses this error cost to calculate the derivative value of the activation function layer by layer backward, to estimate the error generated by each layer and to distribute it to each nerve of the layer to obtain the trim signal. Finally, it adjusts the weight of each unit based on this signal.
In terms of clustering, the advantages of DNN over GMM are:1) It does not need to make feature distribution assumptions to avoid the influence of human subjective factors; 2) it supports diverse feature training and reduces feature preprocessing operations; 3) it has the ability to retain contextual relevance.
After the acoustic model is determined, the decoding module decodes the current speech signal in conjunction with the pronunciation dictionary to obtain the corresponding possible word sequence. Moreover, for continuous speech recognition, the problem cannot be solved by word sequence alone. The language model is given out of this demand. In the case where the training corpus is given, the role of the language model is to count the collocation probability between words and words and part of speech, and then predict the most likely combination of all words predicted by the acoustic model and pronunciation dictionary. Therefore, when the a priori knowledge related to a specific field or task can be calculated, the language model to solve the most likely word sequence problem is a probability estimation problem. For this reason, the common language model modeling scheme is the Ngram model, also known as the N-gram model.
We assume that sentence S is composed of a sequence of word W ={ w1, w2, ⋯ , w
n
} in a specific arrangement. Where n is the number of words, and the probability of S appearing in the corpus is P (S), which is defined as the joint probability distribution of n words, namely:
Obviously, formula (19) has several disadvantages: 1) the parameter space is too large: too many conditional probability combinations lead to unpredictable calculations; 2) serious data sparseness: the calculation probability may be 0.
In order to solve the problem of excessive parameter space, the Markov assumption is introduced. The probability that the current word appears is only related to the first n - 1 words, and has nothing to do with the n words in front of it and the words after it. After formalizing the model, there are:
When n = 2, it is called bigram model. According to the above formula, we can obtain:
Similarly, when n = 3, it is a trigram model:

Deep neural network diagram.
When n becomes larger and larger, the data becomes more sparse and there is a probability of 0. Therefore, common methods to solve this problem are smoothing, such as Add-One Smoothing, Good-Turing Discounting, etc.
In specific implementation, the linguistics teaching system based on the artificial intelligence speech model utilizes the speech detection function of the system itself (this speech detection is based on short-term energy detection) and does not need to add other detection modules. The specific block diagram of the system is shown in Fig. 5. The traditional system has the problems of low voice recognition accuracy, mixed voice and noise, the existence of a large amount of noise or silence, and the possibility of missing some voices. The system has relatively many problems and shortcomings.

Linguistics teaching system based on artificial intelligence speech model.
The system is mainly composed of human-computer interaction platform, data acquisition module, receiver control module, data processing module, database management module, and detection efficiency evaluation module. Through the organic combination of various modules and the coordination of functional processes, the functions of signal reception, processing, filtering, detection and identification are effectively completed. The system performs human-computer interaction under a unified centralized platform, which is mainly composed of five modules: data acquisition, receiver control, data processing, database management, and efficiency evaluation. Among them, the data collection module is mainly responsible for real-time data collection and sending the data to other modules for analysis and processing; the receiver control module is mainly used for device control, including receiver control command transmission, status echo and parameter storage; the data processing module mainly analyzes, identifies, and detects the data received by the control receiver, and stores the results in the database; the database management module mainly manages the analysis and processing results, and performs operations such as querying, adding, and deleting; the effectiveness evaluation module mainly evaluates the effectiveness of each detection process to evaluate the processing effect over a period of time, and is used to improve and perfect the performance of the algorithm. The topology of the physical process is shown in Fig. 6.

Topology diagram of physical process.
As shown in Fig. 6 above, speech recognition is mainly concentrated on the detection part of the speech signal. This part is the key part of the realization of this system. It mainly includes preliminary filtering of speech signals based on short-term energy detection methods, and further detection and recognition of preliminary filtered speech signals based on artificial intelligence model detection methods. After these two steps of filtering and recognition, the voice file is sent to the client for processing and control. The main process is shown in Fig. 7.

Flow chart of the processing of the voice signal detection end.
The linguistics teaching recognition system constructed in this paper is used to test the seven-day teaching process of a college. In order to make a better comparison, the ultra-short wave speech detection and recognition system based on short-term energy model is compared with the linguistic teaching model based on artificial intelligence speech model constructed in this paper. The detection results of the ultra-short wave speech detection and recognition system based on the short-term energy model are shown in Table 1.
Detection results of ultrashort wave speech detection and recognition system based on short-term energy model
Similarly, the linguistics teaching model based on artificial intelligence speech model is used to test the seven-day teaching process of a college. The results obtained are shown in Table 2. After that, the detection results of the two are compared, and the obtained results are shown in Fig. 8.
Statistical table of test results of linguistics teaching model based on artificial intelligence speech model

Comparison diagram of noise ratio.
It can be seen from the results of the comparison of the above two tables that although the comparison is not very strong in different statistical intervals, it can still explain some problems: First of all, the proportion of ultra-short wave speech noise decreased by nearly 25%. Secondly, the effective voice volume of ultra-short wave voice increased slightly. In other words, the system constructed in this study is more efficient than the previous ultra-short wave voice control system based on short-term energy, which is obviously about 25% better. This also proves that our research experiment is correct, and the designed system has achieved the expected target effect.
Based on the advantages of the linguistics teaching model, this article combines the linguistics teaching model and the artificial intelligence model to construct an artificial intelligence-assisted teaching model that can be used for classroom teaching, thereby effectively improving classroom teaching efficiency and helping students quickly improve their grades. In specific implementation, the linguistics teaching system based on the artificial intelligence speech model utilizes the speech detection function of the system itself and does not need to add other detection modules. Speech recognition is mainly focused on the detection part of the speech signal, which is the key part of the system. It mainly includes preliminary filtering of speech signals based on short-term energy detection methods, and further detection and recognition of preliminary filtered speech signals based on artificial intelligence model detection methods. After these two steps of filtering and recognition, the voice file is sent to the client for processing and control. After that, the performance of the model in this paper is verified through a comparative test. The research results show that the method proposed in this paper has a certain effect.