
Abstract
The difficulty of obtaining the characteristics of the corpus database of neural machine translation is a factor hindering its development. In order to improve the effect of English intelligent translation, based on the machine learning algorithm, this paper improves the multi-objective optimization algorithm to construct a model based on the English intelligent translation system. Moreover, this paper uses parallel corpus and monolingual corpus for model training and uses semi-supervised neural machine translation method to analyze the data processing path in detail and focuses on the analysis of node distribution and data processing flow. In addition, this paper introduces data-related regularization items through the probabilistic nature of the neural machine translation model and applies it to the monolingual corpus to help the training of the neural machine translation model. Finally, this paper designs experiments to verify the performance of this model. The research results show that the translation model constructed in this paper is highly intelligent and can meet actual translation needs.
Introduction
With the development of information technology, the design of machine translation system based on computer-based integrated information processing has significantly improved the level of intelligence and precision of English translation. The application of automatic translation system is the main software carrier for machine translation. Therefore, the design of English automatic translation system has very important practical significance. The automatic English translation system analyzes English vocabulary features in detail by means of semantic analysis, and effectively combines semantic fuzzy matching and automatic phrase analysis methods to carry out large-scale sentence and vocabulary automatic translation to ensure the accuracy and reliability of translation through the combination of phrase translation.
Machine translation studies how to use computers to realize the automatic conversion from one natural language (source language) to another natural language (target language) to maintain the same semantics [1]. Early machine translation systems advocated the use of artificial rules and relied on the rules of conversion between languages discovered and summarized by human experts. The main challenge of this approach is that it has extremely high requirements for human experts, and a complete set of rules is usually not available to us. With the development of cloud computing and big data in recent years, corpus-based machine translation methods have gradually become the mainstream. This type of method advocates the use of a large-scale corpus to automatically learn mathematical models that can convert between natural languages and overcomes the bottleneck of rule-based methods. Among them, the most representative of this type of machine translation method is the statistical machine translation method [2].
In recent years, deep learning technology has developed rapidly. Due to the characteristics of deep neural networks that can automatically extract features, a large number of studies using deep learning technology to improve machine translation have begun to appear. The machine translation system that originally used deep learning technology still uses the framework of statistical machine translation, and uses deep learning technology to improve its components, such as improving the ordering model and word alignment model. Another type of machine translation system using deep learning technology no longer uses the framework of statistical machine translation but uses a neural network to directly map source language sentences to target language sentences. This approach greatly simplifies the model architecture and training process of the machine translation system, which is called an end-to-end neural machine translation system. The end-to-end neural machine translation system is a sequence-to-sequence model, usually using the encoder-decoder structural framework [3].
Related work
Machine translation refers to the process of translating a source language sentence into a semantically equivalent target language sentence through a computer and is an important research direction in the field of natural language processing [4]. The literature [5] proposed the idea of using machines for translation, which has since triggered a research boom in this direction. Machine translation can be divided into three main methods: rule-based machine translation, statistics-based machine translation, and neural network-based machine translation [6]. The rule-based method is the mainstream of machine translation research. This method has a good translation effect on sentences with standardized grammatical structure, but it also has the disadvantages of complicated rule compilation and difficulty in dealing with non-standard language phenomenon [7]. The literature [8] proposed a statistical machine translation model based on a noisy channel model. Machine learning methods such as deep learning have gradually matured and are beginning to be applied in the field of natural language processing. The literature [9] proposed the use of neural networks for machine translation, and the literature [10] proposed a neural machine translation model based on the encoder-decoder structure, which marked the entry of machine translation into the era of deep learning. The literature [11] compared neural machine translation and statistical machine translation on more than 30 language pairs. The results show that neural machine translation surpasses phrase-based statistical machine translation in 27 tasks, which demonstrates the powerful capabilities of neural machine translation. Although neural machine translation has shown better translation effects than statistical machine translation, it still has great development potential. The literature [12] proposed a neural machine translation model. This model solves the problem of the disappearance of the gradient of the depth model by introducing residual connections between the layers, stacking the number of model layers to 8 layers, and raising the level of machine translation to a new level. Literature [13] proposed an encoder-decoder model based on convolutional neural network, which surpassed Google’s model in accuracy and greatly improved the translation speed. The literature [14] proposed a Transformer model based on the attention mechanism, which has greatly improved the training speed and translation quality of the model. The literature [15] combined a variety of algorithms and introduced manual evaluation in translation evaluation and announced for the first time that the model has reached human level in the translation of news. Since 2019, many neural machine translation model structures have been proposed, and they have shown higher translation quality than the benchmark Transformer model in experiments. In addition, technologies such as reverse translation [16], data screening [17], and pre-training [18] also have significant effects on the improvement of translation effects.
Although neural machine translation has achieved quite high translation quality on the standard data set, there are still many problems to be solved in practical applications. Neural machine translation models have the problem of inconsistent behaviors during training and testing. This problem is called “exposure bias”, which has attracted wide attention from researchers. In addition, in the case of simultaneous interpretation, in order to reduce the translation delay, the model needs to output the translation when the input sentence is incomplete, so that the user can receive high-quality translation results with low delay. In addition to text, sometimes other modal data such as images and videos can be used by translation models. The translation system can incorporate this information to further improve the quality of translation. In order to improve the translation speed, the non-autoregressive model independently builds the translation probability, so that the entire sentence translation can be decoded in parallel. However, this method will also cause serious omission and over translation. When translating the text of the text, in order to ensure the consistency of the translation, the model also needs to consider the context information when translating. When there are low-resource data in the domain and high-resource data outside the domain, in order to improve the translation quality of the model in the domain, it is necessary to make reasonable use of the data outside the domain. When translating between multiple languages is needed, training a multilingual translation model can greatly reduce the number of translation models required, while improving the translation quality of low-resource languages [19].
Based on the advantages of the multi-modal machine translation model, the research of multi-modal machine translation fusing text and image visual information has attracted the attention of researchers in recent years. In the task of image description generation, referring to the end-to-end framework in machine translation, the literature [20] took the picture vector output by the pre-trained convolutional neural network as input and sends it to the decoding end as the initial implicit state vector representation. In this way, in the process of generating picture description sentences, the decoder can more fully use the semantic information in the picture to improve the effect of the picture description generation task. Under the framework of end-to-end machine translation based on encoding and decoding, the literature [21] integrated the visual information of pictures into the encoding and decoding ends of the translation framework to enhance the effect of pictures for text machine translation. In another work, two independent attention mechanism frameworks are used to process the word region and image region in the source language separately to improve the translation result of the model.
Problem definition
Taking multi-objective optimization as an example, the model in this paper mainly considers two important factors in the selection of the objective optimization route: one is the redundancy risk of the objective optimization route. The second is to give priority to areas with higher weights [22].
1 is the data length, v is the data processing speed, and the time spent when data is interrupted is the sum of the normal data processing time and the data economic processing time:
T is the time-consuming data processing, and the time index needs to be processed without dimension.
In the process of data translation, the road network model is formed by the data recognition system, that is, the undirected weighted graph [24].
Among them, the data input point, output point and data processing center constitute node set V ={ v1, v2, ⋯ , v
n
}, the data processing point set to be translated constitutes set Z ⊆ V, and the manual data input and manual replenishment points are denoted as v
s
, v
t
∈ V. At the same time, the upper limit of the amount of data processing is M, the road network constitutes an edge set E ={ e1, e2, ⋯ , e
m
}, and each road in the road network is a disordered pair composed of two different nodes, which is recorded as:
The security risk and time cost of each data channel are standardized weight vectors [25].
A path from node v
i
to node v
j
is recorded as an ordered set.
The set of nodes that v
i
can reach through only one edge is recorded as σ (i) +, and the set of nodes that can reach v
i
through only one edge is recorded as σ (i) -. Then, if and only if vi+1 ∈ σ (i) +, pi→j is a feasible path from node v
i
to node v
j
. After the constraint conditions of the severely damaged node set Z are further considered, then
Among them, u
m
indicates whether to make a data processing node, and
Formula (7) means that the total security risk of the M groups of data redundant processing routes is the smallest, and formula (8) means that the total time cost of the M groups of data redundant processing routes is the smallest. Formula (9) means that when the m-th group of data redundancy processing is performed from node v
s
at time u
m
= 1, the out degree of node v
s
on the m path is one greater than the in degree. When the m-th group of data redundancy processing is not performed from the v
s
node at u
m
= 0 time, the out degree and in degree of the v
s
node on the m path are equal and zero. Formula (10) is similar to formula (11), restricting the out-degree and in-degree of v
t
node on m path. Formula (12) means that the out-degree and in-degree of each node except the starting point v
s
and the end point v
t
of the network path of each group of data redundancy processing are equal. Formula (13) means that node z ∈ Z is accessed by at least one of the M data processing paths. Formula (14) means that u
m
is a binary variable with a value of 1, if and only if the m-th group of data redundancy processing plan is executed. Formula (15) shows that
We set S
c
to represent a subset of C and add the following sub-loop to remove constraints:
Formulas (7) ∼ (16) and (17) constitute a complete multi-objective route optimization model of designated data output points and replenishment points.
The model proposed in this paper is an extension of the traveling salesman problem and the shortest path problem. The traveling salesman problem generally requires that all nodes are visited once and then back to the starting point, that is, there is no loop in the path. The shortest path problem requires the shortest path between the specified node pair.
The model in this paper requires generating at most M paths with the shortest sum of the length of the specified node set between the specified node pairs and allows loops in the paths. Under the condition of the same number of nodes, the model in this paper is more difficult to solve than the simple traveling salesman problem and the shortest path problem. When the edge of the network model G has only one weight and M = 1 is limited, the above model has the following solution:
First, the shortest path between any pair of nodes in Z is found, and the length of the route is recorded as d
ij
,
Then, d ij is taken as the distance between i and j, and Z is solved by TSP to get the final solution. The above solving ideas cannot be used directly when M ≠ 1, and cannot be naturally extended to the situation where there are multiple objective functions.
The multi-objective genetic algorithm operates on a set of feasible solutions and gives a set of non-inferior solutions after several iterations. It is a practical method to solve multi-objective optimization problems. In this paper, the model solving algorithm is designed based on genetic algorithm. Among them, the key issues are: 1) the generation of the initial feasible solution; 2) how to ensure that the offspring produced by the cross mutation is a feasible solution during the constrained optimization solution process; 3) How to weigh the possibility of the non-dominated solution and the dominating solution entering the offspring to make the selection of the offspring; 4) multi-objective optimization algorithm stopping conditions and optimal solution extraction.
Solving algorithm design
For the shortest path problem that must pass through a number of designated nodes, if the designated node repeats multiple times, once the order of the nodes is determined and the path between nodes is determined, a unique path can be determined. The algorithm design in this paper is based on this basic idea unfolds.
Initial population generation
First, node z ∈ Z is randomly assigned to M sequences. Among them, M is the upper limit of the number of rescuers, the m-th sequence is like
That is, all z ∈ Z is accessed by 1 of M paths. Then, for all m ∈ Ms, starting from
These paths constitute a complete data processing plan, that is, a feasible solution. Several initial feasible solutions can be obtained by repeating so many times, which is the initial population of genetic algorithm.
The above algorithm ensures that there is no loop in the path from
Circuit that shortens the path length.
The loops in the generated path have the following definitions of “beneficial loop” and “non-beneficial loop”. Among them, beneficial loops are loops that may reduce path safety risks or time spent, and non-beneficial loops are loops that are not beneficial to reducing path safety risks or time spent. The specific definition is as follows.
At the same time, the necessity of loop (p
l
= [vk*, vk1vk2, ⋯ , vk*]) in path (p) is analyzed as follows. The loop endpoints (start and end points) and other nodes in the loop have the following situations: 1) There are only non-designated nodes in the entire loop
Clearing the loop will inevitably shorten the path length, and it will not cause the path to become an infeasible solution. This type of loop is unnecessary. 2) The starting point (that is, the end point) of the loop is a designated node, and other nodes in the loop are all non-designated nodes.
Clearing the path other than the end points will necessarily shorten the path length, and it will not cause the path to become an infeasible solution. Therefore, paths other than the start and end points are unnecessary. 3) There is a designated node in the loop, and the same designated node exists outside the loop.
Such a loop may be beneficial to shorten the total length of the path. 4) There is a designated node in the loop, and the node does not exist outside the loop.
Such a loop is necessary, and deleting the loop will make the solution infeasible. In summary, when all the nodes of the loop except the end point are non-designated nodes (there is no restriction on the situation of the end point, that is, the end point can be a designated node or a non-designated node), the loop can be cleared.
Therefore, the generated initial feasible solution does not have non-beneficial loops. After crossover and mutation operations are performed, the newly generated path needs to be cleared of non-beneficial loops.
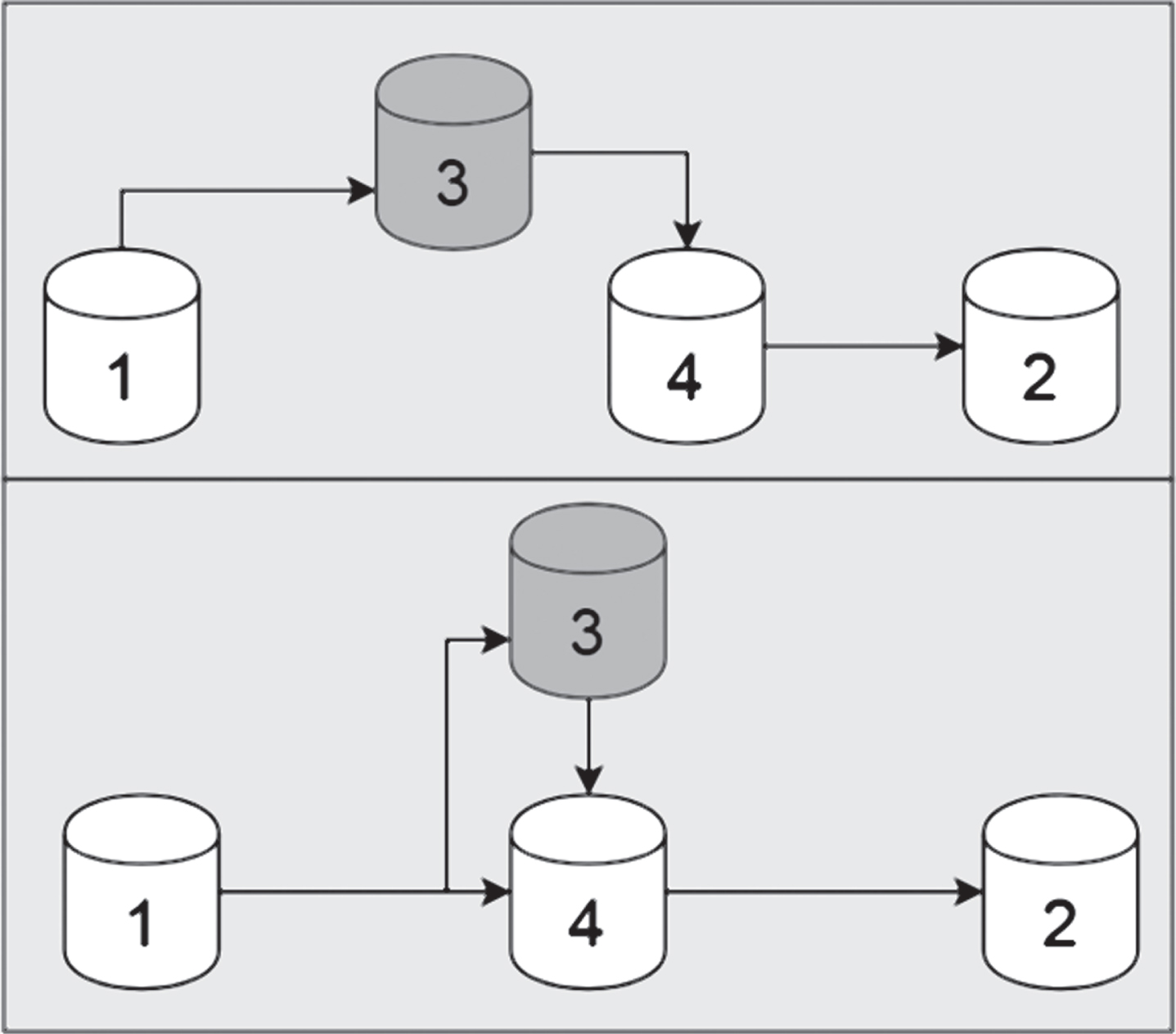
The data processing path of the multi-objective optimization algorithm constructed in this paper is shown in Fig. 2. The first part is the data input layer, the second part is a number of available transit nodes, and the third part is a number of demand nodes.

Data processing network structure.
The traditional language model is limited by the model order n (usually an integer from 1 to 5). It can only model the language model with the first n-1 words of a limited window size as a condition. Therefore, it may not be possible to capture enough contextual information in a vocabulary sequence of unlimited length, resulting in unsatisfactory language model effects. At the same time, whenever the order of the model increases by one unit size, the calculation of the probability value of the entire sequence increases exponentially, which can easily cause data explosion. In order to solve the shortcomings of traditional language models, the first large-scale deep learning neural network language model is proposed. The model can capture the contextual information of words by learning the distributed representation of words. When the context window size of the vocabulary sequence of the model increases, the number of parameters of the entire model only increases linearly. The structure of the neural network language model is shown in Fig. 3:
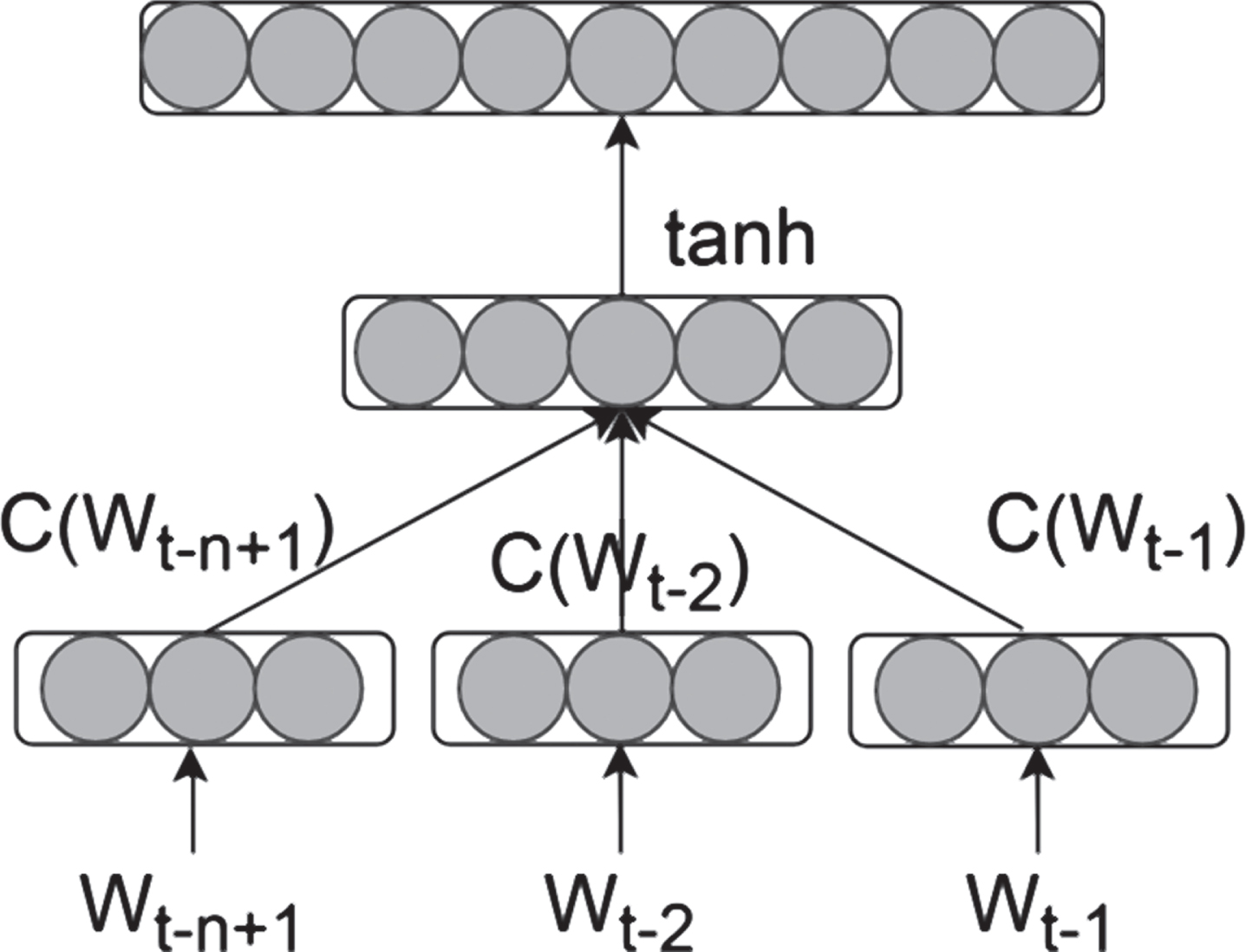
The structure of the neural network language model.
Different from ordinary RNN, LSTM is a special neuron with long and short-term memory. We know that ordinary RNNs are extremely sensitive to short-term input, but cannot maintain long-term memory. By introducing the “gating mechanism” (gating mechanism), LSTM adds an internal state that can store long-distance information in the hidden layer unit of the ordinary RNN, thereby solving the long-distance dependency problem of the ordinary RNN. The structure diagram of the improved RNN with internal state c is shown in Fig. 4:

RNN with improved structure.
First of all, in the process of training the source language-target language translation model using the method proposed in this paper, it is necessary to use the pre-trained target language-source language translation model to translate the target language sentences in the monolingual corpus. This process is similar to the method of back-translating monolingual corpus to generate pseudo-parallel corpus to enrich training data. The difference between the method proposed in this paper and these related works is that the method in the related work directly uses the generated pseudo-parallel corpus as a supplement to the original parallel corpus to participate in the training of the model, while the method in this paper uses the generated sentence to calculate the probability of each component in the full probability formula. This method of using monolingual corpus can reduce the negative effects of low-quality pseudo-parallel corpus on translation model training. In the method proposed in this paper, since the full probability formula is an inherent property that holds for any sentence pair, the quality of the sentences produced in the back translation process will not have such a big impact on the quality of the translation model. Furthermore, the method of sampling single sentences using the reverse translation model also includes a method based on monolingual corpus reconstruction. That is, the source language-target language and target language-source language translation models are used to reconstruct the monolingual corpus of the target language, and the source language-target language and target language-source language translation models are jointly trained. These reconstruction-based methods believe that translation models in both directions can benefit from the iterative process of joint training. However, in fact, due to the problem of error propagation, this training process is difficult to control. Specifically, errors generated in the source language-target language translation process will be propagated to the target language-source language translation process. Compared with reconstruction-based methods, the method proposed in this paper realizes the direct modeling of neural machine translation models by mining probabilistic properties. Specifically, the method proposed in this paper only needs to use the reverse translation model for one sampling, so there is no problem of error propagation. On the other hand, intuitively, the method proposed in this paper can also improve the effect of the reverse translation model through iterative training of the two models. However, in practice, when training a machine translation model, you can sample from any reverse translation model. Therefore, the process of iteratively sampling from the two models is not necessary in the method proposed in this paper.
The method of combining language models first uses monolingual corpus to train an independent language model, and then combines the trained language model into the training process of the neural machine translation model. Compared with the training method of maximum likelihood estimation, this method requires almost no additional training time and machine memory besides training the language model. However, this method of combining language models is very limited in improving the effect of machine translation models. The reason is that this method does not fundamentally solve the problem of parallel corpus training data shortage. On the other hand, for methods based on data enhancement, in general, although this type of method has different training goals and strategies, they are all based on the process of data enhancement. The process of data enhancement is to use the source language-target language translation model to translate the source language-side monolingual corpus or use the target language-source language translation model to translate the target language-side monolingual corpus. Due to the process of data enhancement, this type of method usually requires additional training time and machine memory. Training time and machine memory consumption mainly depend on the sample size. That is, after a single sentence is given, it is translated into the number of corresponding language sentences. Compared with the iterative sampling and training of the translation model, the method proposed in this paper only needs to translate the single sentence in the target language once, which saves a lot of training time. In summary, in semi-supervised neural machine translation algorithms, data enhancement is a necessary operation to improve translation effects in existing research. Therefore, longer training time and larger machine memory are a compromise to improve the model effect. In general, the method proposed in the paper has saved a lot of training time compared to the iterative training method.
Usually, bilingual corpus at the text level is scarce. Therefore, in this paper, we propose to use bilingual corpus (non-text) to train the completion model. In Table 1 to Table 3, from the bilingual corpus of different data scales, it can be seen that the performance of the completion model is still greatly improved. The corresponding statistical graphs are shown in Fig. 5 to Fig. 7.
Statistical table of 900K text bilingualism
Statistical table of 900K text bilingualism
Statistical table of 10 million bilingualism + 900K text bilingualism
Statistical table of 130 million bilingualism + 900K text bilingualism

Statistical diagram of 900K text bilingualism.

Statistical diagram of 10 million bilingualism + 900K text bilingualism.
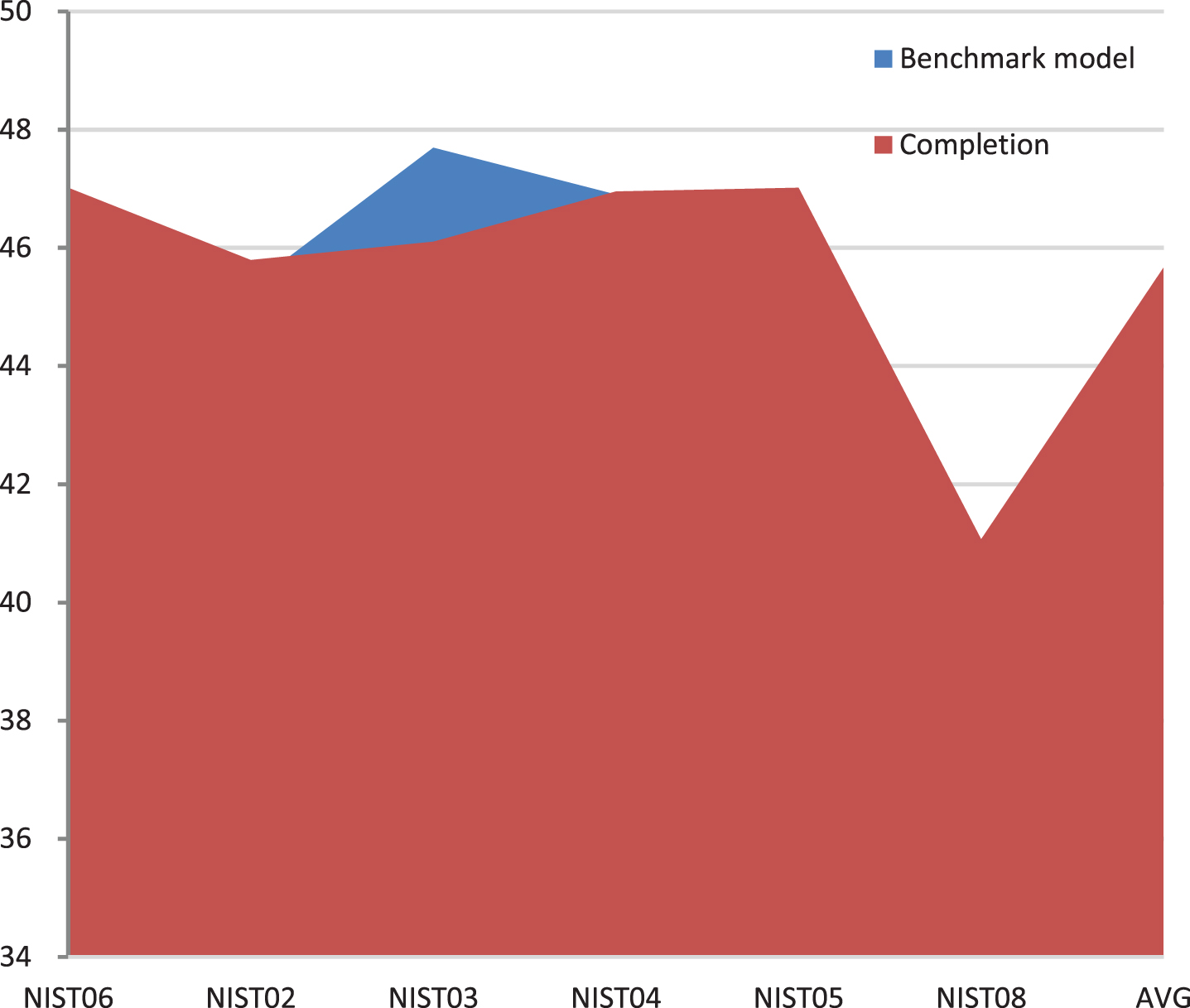
Statistical diagram of 130 million bilingualism + 900K text bilingualism.
For the benchmark model and the completion model, the training methods are different. For the benchmark model, since large-scale bilingualism and a small amount of textual bilingualism belong to different fields of data, we adopt the way of training domain models, that is, pre-training + fine-tuning. However, for the training of the completion model, we consider that in large-scale bilinguals, there are no completed tags and completed words. If pre-training and fine-tuning methods are used, there is no fairness to the training completion model. Therefore, we use the completed text corpus and large-scale bilingual direct mixed training. For the two different training methods, we give specific experimental results in Table 4 and Fig. 8. In Table 4, we compare two different training methods in 10 million bilingualism + 900K text bilingualism. We found that when choosing different training methods, the benchmark model and the complement model can achieve different effects. The benchmark model chooses pre-training and fine-tuning methods to achieve the best results. However, for the completion model, the best result can be achieved by choosing the method of direct mixed corpus training.
Comparison of the different training methods of the two models on the development set

Statistical diagram of the comparison results of the different training methods of the two models on the development set.
Since neural machine translation was proposed, it has gradually replaced the traditional phrase-based statistical machine translation method with its strong performance. End-to-end neural machine translation no longer uses the cumbersome structure and complex feature design in statistical machine translation, but directly passes the parallel corpus to the neural network to complete the training of a complete translation system. However, while neural machine translation has brought many opportunities to industry and academia, there are also some challenges. In order to further improve the accuracy of the translation model and enhance the decoder’s ability to obtain encoder context information, we propose a new calculation method that can comprehensively consider context vectors at different times. Moreover, this paper proposes to use the completion method to solve the problem of incompleteness, consistency, and ambiguity of sentence representation at sentence level. This method first extracts information from each sentence in the text, and then adds the extracted information to the source sentence by tagging. Experimental results show that the completion method proposed in this paper has a very good effect on the text translation system.
Footnotes
Acknowledgment
Key project of the Ministry of Education in China, 2017. “Research on Blended Learning in the Context of the Internet +” (EIJYB2017_026).