
Abstract
In order to improve the evaluation effect of classroom education, this paper proposes the MFO intelligent optimization algorithm based on the idea of machine learning, and builds the classroom education effect evaluation model based on the MFO intelligent optimization algorithm. Moreover, this paper uses a logarithmic spiral to simulate the path of the moth to the flame and invert the pending parameters in the mathematical model, and adds vertical and horizontal algorithms and chaos operators on this basis. The crisscross algorithm allows different moth individuals and the same moth to perform cross calculations with different computing dimensions to increase the diversity of moth populations, so that moths in the search space can traverse the entire search space as much as possible to find a better solution. Moreover, in view of the problems of BP neural network such as low fitting accuracy, this paper applies the CCMFO algorithm to improve the BP neural network to form the CCMFO-BP algorithm, and improves the weight and threshold update process of the BP neural network to make the network operation more efficient and accurate. Finally, this paper designs experiments to analyze the performance of the model constructed in this paper. The research results show that the model constructed in this paper meets the expected requirements.
Introduction
With the rapid development of “Internet +” education and the full implementation of the strategic goal of revitalizing the country through science and education, the balance of classroom education in colleges and universities has attracted much attention, and high-quality education has become a necessary condition for people’s livelihood. Educational balance not only undertakes the fundamental task of establishing morality, teaching and educating people, but is also regarded as a measure of international education strength and social equity [1]. Therefore, constructing a reasonable and effective school education quality evaluation system is an urgent problem to be solved in the balanced development of education. At present, most researches on school education quality evaluation are presented in the form of analyzing their existing problems and proposing suggestions, while quantitative evaluation studies are rare. In those quantitative studies, the evaluation indicators and evaluation methods of the college classroom education evaluation system are in the exploratory stage, and there are problems such as incomplete evaluation indicators and incomplete evaluation methods. The evaluation indicators in the current “National Education Supervision Team” evaluation system include: total number of students, total number of teachers, teaching and auxiliary room area, sports field area, teaching equipment value, number of computers, number of books, number of full-time teachers, number of teachers with higher than required academic qualifications, and number of teachers with intermediate professional and technical positions, etc. The comprehensive evaluation of school education quality is of great significance for education guidance, decision support and the realization of education balance. In order to build a reasonable education evaluation system, improve the rationality of evaluation index selection and the stability of evaluation methods, and further improve the accuracy of education evaluation quality.
Educational balance is the focus of classroom education in colleges and universities, and it is the basis and manifestation of educational equity. The equilibrium index of college classroom education is a parameter for judging the fairness of education development, which indirectly affects the fairness of education and society [2]. The balanced index of college classroom education also includes the soft index of collecting school admission scores through the Internet, which accurately reflects the school’s educational performance. The comprehensive evaluation dimensions of college classroom education balance indicators are divided into three dimensions: city, region, and school. It takes schools as the analysis dimension, and studies the evaluation of the quality of junior high schools in a certain city around the evaluation indicators and evaluation methods, and divides the quality of these junior high schools into grades [3].
Related work
The balanced development of college classroom education is a process of balancing the supply and demand of education. This process requires a reasonable and effective education evaluation system as a support, and college classroom education balance indicators and education quality evaluation methods directly affect the complexity of the college classroom education evaluation system [4]. The literature [5] proposed that educational activities should pursue the idea of equality in a society full of differences and need to consider identity differences and equal coordination of educational opportunities. The literature [6] analyzed the causes of educational imbalance through quantitative and non-quantitative methods from the perspective of sociology. The literature [7] put forward the per-student teaching and auxiliary room area, per-student education expenditure, per-student number of books, enrollment rate, dropout rate, etc. as evaluation indicators. The literature [8] regarded three aspects of resource allocation, school development ability and school quality as the evaluation indicators of the balanced development system of college classroom education. The literature [9] puts forward a relatively complete system of balanced development of classroom education in colleges and universities, including four aspects: educational opportunities, educational resource allocation, educational quality and educational achievement. The literature [10] believed that the evaluation index system for the balanced development of classroom education in inter-school colleges and universities in the county should follow the principles of balanced resource allocation, fiscal neutrality, weak compensation, and data availability, and the evaluation indicators should consider the balance of admission rules, the allocation of educational resources, and school education output. The literature [11] proposed a screening method for evaluation indicators. Moreover, it believes that the candidate set of educational evaluation indicators should be selected first, and then representative educational indicators should be selected from the set of educational evaluation indicators through methods such as expert consultation, principal component analysis or questionnaire surveys. The literature [12] proposed that the equilibrium index of college classroom education should be considered from three aspects: opportunity equilibrium, process equilibrium, and outcome equilibrium. The literature [13] combined the principal component analysis method and the AHP method to calculate the absolute difference and relative difference of statistical data, and obtains the change trend of the equilibrium index by analyzing the change of the difference. The literature [14] introduced the experimental procedures and error-prone points of principal component analysis, and compared the similarities and differences between principal component analysis and factor analysis. The literature [15] summarized the misunderstandings and errors in the relevant textbooks and articles of principal component analysis.
Literature [16] pointed out that the current self-evaluation of colleges and universities blindly pursues the supremacy of standards, and the purpose of self-evaluation is only to meet the acceptance of the higher education department, and s self-assessment only pays attention to “hardware” standards, such as student academic performance, teacher-student ratio, and per capita floor area, etc., while it ignores the “software” standard as the self-evaluation standard. Moreover, it believed that the establishment of a scientific, reasonable and effective quality assurance system within universities is the driving force behind the development of higher vocational education. The literature [17] pointed out that the self-assessment behavior of colleges and universities is passive and only follows the needs of higher-level departments and the market, and the self-evaluation indicators are not sound. Under the framework of the quality assurance system, the literature [18] regarded the five levels of schools, teachers, majors, courses, and students as diagnostic items. Moreover, in accordance with the five main lines of work of “decision command, resource construction, service support, quality generation, supervision and control", it systematically searched for evaluation indicators at all levels to make the “diagnosis reform” project clear and clarified, and truly implement it to all responsible entities. The literature [19] proposed to establish and improve the school’s micro-level quality standards including talent training quality standards, teaching quality standards, teaching management standards and job responsibility standards. The literature [20] proposed a three-level self-assessment index system, including 6 first-level indicators, 15 second-level indicators, and 39 third-level indicators. The literature [21] put forward four core indicators for improving the quality of education, namely, improving the comprehensive strength of the school, the ability of students to grow into abilities, social contribution and international competitiveness. The literature [22] constructed a quality assurance system with full participation, full process control, and full management in the school according to the concept of total quality management.
MFO algorithm implementation process
The MFO algorithm draws on the basic principle of moths capturing flames, and uses a logarithmic spiral function to simulate the flight path of moths capturing flames to achieve the purpose of finding the optimal solution in the search space. The moth flame-catching optimization algorithm has strong parallel search capabilities and is easy to program. It can find better coefficients in the multi-dimensional calculation optimization with fewer iterations. Moreover, it is suitable for solving multi-factor seepage pressure prediction problems, can effectively solve the problem of optimization of seepage pressure prediction model parameters for water diversion projects, prevent the algorithm from falling into local optimization, and finally obtain the global optimal solution of each dimension. The operation process of the basic moth flame optimization algorithm is as follows: Normalization. Due to the different physical meanings and dimensions of the water level, temperature and seepage pressure obtained from actual observations, it is necessary to preprocess the data before applying the MFO algorithm to model seepage pressure monitoring data. Normalization is a basic data preprocessing method, and the measured data of seepage compaction can be transformed into a dimensionless expression.
Initialization. m
nd
represents the spatial position of the nth moth in the d dimension, and OM
n
is the fitness value of the nth moth. The dimension represents the number of parameters of the osmotic pressure prediction model, and the number of moth populations represents the number of randomly generated solutions in the search space. The matrix of formula (2) is used to represent the spatial position of the moth population, and the matrix of formula (3) is used to store the fitness value of individual moths.
The flame space position. The flame is another key part of the MFO algorithm. Its matrix is similar to the moth matrix and expressed by formula (4), and the fitness value of the flame is stored by the matrix of formula (5). F
nd
b represents the spatial position of the nth flame in the d dimension, and OF
n
is the fitness value of the first flame.
MFO algorithm definition. Both moths and flames are candidate solutions. The difference lies in the way they update their positions during evolution. In the space of solution, the moth is the actual moving subject, and the moth can sense the position of the flame. However, the flame is the optimal position that the moth can reach during multiple iterations, and can be regarded as a mark when the moth search is terminated. The moth keeps approaching the best position (candidate solution) through position update until it finds the best position. The MO algorithm can be defined as:
In the above formula, I is the randomly generated moth population size and the corresponding fitness value; P is the function of the moth moving in the search space: T is the discriminant function of the termination condition.
The candidate solution of the initial osmotic pressure monitoring model parameters is generated by the function I, which is the moth population M, and the individual fitness value of the moth population is calculated. The function P is used to change the position of the moth in the search space and output the updated moth matrix. After that, the terminal condition is judged on the updated individual position of the moth, the iteration is continued or the algorithm is terminated, and the result is output. Moth flame algorithm position update. In order to reflect the flight of moths around the flame, a mathematical model is established with a spiral function. If the fitness value of the moth individual updated by the spiral function is better than the fitness value of the flame, then the flame position is replaced, otherwise the individual moth is discarded to complete a position update. We define the MFO algorithm to simulate the spiral flight path of the moth to follow a logarithmic spiral, which is expressed as:
In the above formula,
The above formula shows that the moths move in a circular space centered on the flame, instead of moving in a straight line between them. t determines the distance between the position of the moth on the trajectory and the flame. This spiral flight path makes the position of the moth more possible in the iterative process, and ensures the global search ability and local development ability of the algorithm. If it is assumed that the moth starts flying from the starting position of the spiral and the flame position is the end position of the spiral, and the moth is constantly approaching the flame along the spiral, then the update point of the moth position is the moth position at any time on the spiral. Because the search range of the moth is the prescribed search space, the floating range of the spiral should not exceed the search space. The geometric trajectory of the moth is shown in Fig. 1.
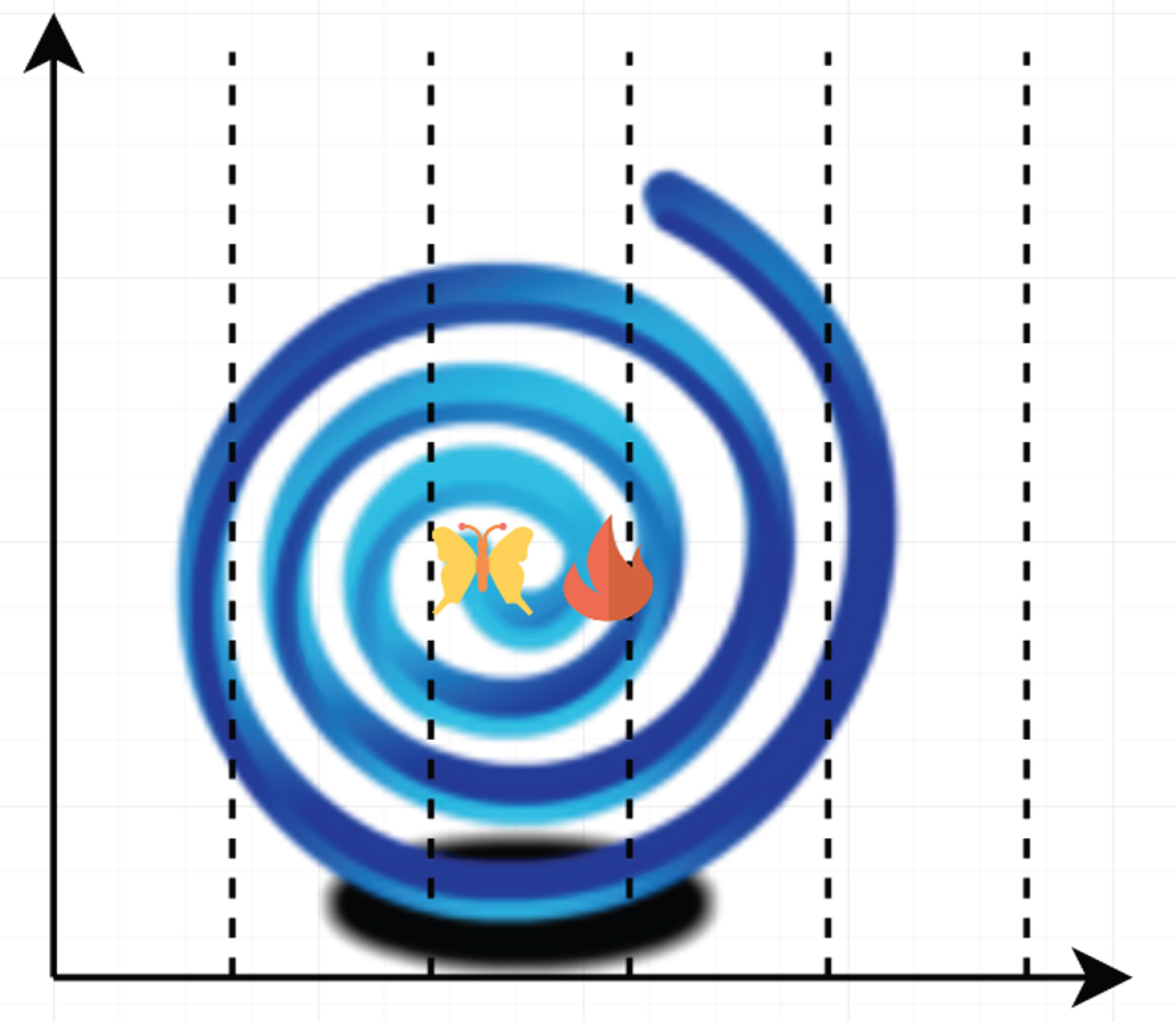
Geometric trajectory diagram of moths catching flames.
Abandoning flame behavior. As mentioned above, the flame is the optimal solution searched by the moth in the iterative process. The moth can approach one or more flames, and each moth approaches multiple flames to prevent local optimization and algorithm stagnation. During the iteration process, all the better flames in the parent and offspring are kept and sorted according to the size of the flame fitness value. In addition, flames with poor fitness values are discarded to reduce the number of flames adaptively, and finally converge to 1. This avoids the moth from losing the local optimal solution during the position update, so that the moth gradually moves to the flame with better fitness value and speeds up the later convergence speed. The algorithm terminates. When the flame fitness value reaches a predetermined standard or the number of iterations reaches the maximum number of iterations, the algorithm stops and outputs the spatial position and fitness value of the flame.
In view of the large number of seepage pressure monitoring model parameters, the MFO algorithm can be applied to solve the seepage pressure monitoring model coefficients. Each dimension of the moth matrix represents the parameters of the corresponding seepage pressure monitoring model, and the candidate solution flame position of the MFO algorithm is the undetermined seepage pressure monitoring model coefficient. When the moths are constantly approaching the flame, the error of the seepage pressure monitoring model is also continuously reduced. When the error is reduced to the desired value, the optimal flame position is output, that is, the model construction is completed.
Both the moth and the flame in the MFO algorithm are search factors for the optimization problem. The moth is the candidate solution of the problem to be solved and the position is constantly updated, and the flame is the best position currently searched in the iterative process of the moth. This kind of optimization strategy can explore the unknown search space as much as possible without giving up the optimal solution. However, when solving the parameter coefficients of the osmotic pressure model, due to the large number of dimensions set by the moths, the artificial moths approach the undetermined solution with a single spiral trajectory, which limits the variation of the moth population to a certain extent. In the solution of the coefficient problem of the seepage pressure monitoring model with multiple local optimal solutions, when the artificial moth has achieved a higher degree of optimization in some dimensions, it gives up the search for better values in the whole dimension, which causes the algorithm to be unable to find the global optimum flame when solving high-dimensional problems and fall into the local optimum. The golden mean solution generated by the vertical and horizontal crossover algorithm and the dominant solution generated by the parental competition enter the screening mechanism together to retain the global optimal flame position. On the one hand, this cross-over mechanism can effectively prevent local optimal moths from continuously iterating into their offspring, and on the other hand, it increases the advantages of global optimal moths in the iterative process. Moreover, the vertical and horizontal crossover algorithm improves the diversity of moth populations to reduce search blind spots, quickly transfers the position information of moths in the population with higher solution accuracy, retains the ability of moths to develop new positions, and effectively improves the overall solution accuracy of the algorithm. Through comparative tests with MFO, DE, and PSO algorithms, it is found that the CCMFO algorithm can improve the accuracy of the solution and the stability of the algorithm when solving high-dimensional complex function problems.
Horizontal crossing is an arithmetic crossing between two different moths in the same dimension in a moth population. Before crossover, all moths must be paired randomly without repetition, and then the same dimension of the paired moths must be crossed arithmetic. If we assume that the moth M
i
and the moth M
j
are paired, the horizontal crossover formula is:
In the formula, c1, c2, t ∈ [- 1, 1], and b = 1. Among them, M hc (i, d) and M hc (j, d) are the flame solutions of the offspring generated by the parent artificial moth M i and the parent artificial moth M j crossing on the d-th dimension, respectively.
In the above formula, it can be observed that the moths search in the hypercube space formed by the crosswise cross. The hypercube takes the parent moths M i and M j as the diagonal vertices, and the size is half of the population, and new moth individuals are more likely to be generated in the hypercube. In addition, the progeny moths are produced at the periphery of the space with a small linear decreasing probability, which increases the possibility of the moths to explore the external information of the hypercube, and reduces the search blind area of artificial moths to enhance the global search ability of the algorithm. Finally, the offspring moths are compared with the parent moths through a competition mechanism, and the better moth position is selected as the flame.
Longitudinal crossing
Longitudinal crossing is the crossing operation between two different dimensions of the same moth. In the seepage pressure monitoring model, the physical meanings of the vertical dimensions are not the same. In order to prevent overflow caused by the different value ranges between the two dimensions, it is necessary to ensure that the two dimensions of the vertical cross operation are consistent. Therefore, the data needs to be normalized. crossing is the crossing operation between two different dimensions of the same moth. In the seepage pressure monitoring model, the physical meanings of the vertical dimensions are not the same. In order to prevent overflow caused by the different value ranges between the two dimensions, it is necessary to ensure that the two dimensions of the vertical cross operation are consistent. Therefore, the data needs to be normalized.
At the same time, only one dimension is updated each time the flame catching of longitudinal crossing, which can effectively make the one dimension that is trapped in the local optimal dimension get rid of the stagnant state without destroying other normal dimensions. We perform the longitudinal crossing operation on the d1 and d2 dimensions of moth M
i
to generate the d1-th dimension offspring. The formula for longitudinal crossing is:
In the above formula, c, t ∈ [- 1, 1], and b = 1. Among them, M vc (i, d1) is the flame solution of the offspring generated by the artificial moth M i in its d1-th and d2-dimensions crossed vertically to update the d1-dimension.
When the swarm intelligence optimization algorithm is solving multi-dimensional problems, it is often unable to search for the global optimal individual because some dimensions reach better values. This kind of stagnant population iteration is called falling into the local optimal. The seepage pressure monitoring model tends to fall into the local optimum during the population iteration process due to many parameters. Therefore, integrating the longitudinal crossing into the MFO algorithm can effectively prevent the algorithm from falling into the local optimum. Moreover, the longitudinal crossing mutation method can produce a mean value, which effectively prevents the algorithm from selecting the optimal moth in individual dimensions to enter the offspring and abandoning the global optimal individual. In addition, the probability of longitudinal crossing occurs at [0.2, 0.8], which helps to get rid of the local optimum, and then make the population evolve towards the global optimum. After crossover, it is also compared with its parent moths, and the best ones are retained in the parent population. The vertical and horizontal crossover algorithm makes up for the spatial search ability lost by the competition mechanism due to the pursuit of convergence accuracy, while maintaining the diversity of the population without destroying the individual peacekeeping moths that may be better.
The crisscross optimization algorithm can increase the diversity of moth populations and randomly generate more moderate solutions to find the global optimal solution. In order to make the generated moth individuals more diverse, the cubic mapping method in the chaos algorithm is applied to the CCMFO algorithm. The moth performs a vertical and horizontal cross operation, and the initial value of the parameter t is a random value between [- 1, 1] and not 0. Subsequently, the value of t is generated by the cube map based on the previous generation solution, and the calculation formula of the chaos operator is:
The multiple regression model is an important method in the regression model. Influencing factors can be obtained and quantified, thereby determining the relationship and extent of the influence of each influencing factor on the dependent variable. We use x1, x2, ⋯ , x
m
to represent m independent variables, and Y to represent dependent variables. Then, the established multiple linear regression model can be expressed as:
In the formula, ɛ is a random error and β0, β1, β2, ⋯ , β m is m + 1 unknown parameters.
For practical problems with n sets of observation data, the regression model can be expressed as:
Its matrix form is:
In the above formula:
The parameter estimation of the multiple regression equation adopts the conventional least square method (OLS). Using this estimation method to estimate regression parameters needs to satisfy the following basic assumptions.
A0 model setting assumption (linear assumption)
This is not a statistical assumption, but a model setting. This assumption requires that the conditional mean of Y is a linear function of all independent variables X:
In the above formula, Y is a column vector of n × 1 composed of observations of dependent variables, x is a matrix of n × p composed of observations of independent variables, and p < n.
That is to say, the conditional expectation of Y under X can be expressed as a linear combination of X, and this conditional expectation is the regression equation. The model requires that X′X must be a non-singular matrix.
A1 orthogonal hypothesis
We assume that the error term matrix ɛ is not related to each x vector in X. In other words,
When the first column of the X matrix is all 1, the above equation is equivalent to:
This assumption ensures that the least squares estimation of regression model parameters is unbiased.
A2 independent and identical distribution assumption
This assumption is for the error terms of the overall regression model, requiring them to meet the conditions of mutual independence and the same distribution. Specifically,
Independent distribution: each error term ɛ
i
is independent distribution, namely:
Homoscedasticity:
In matrix form, these two properties can also be expressed as:
In the above formula, I is the unit matrix of n × n order.
Gauss-Markov Theorem shows that if the assumptions of A1 and A2 are satisfied, the regression parameter estimate b obtained by the least square method will be the best linear unbiased estimate among all the estimates.
Linear estimated value refers to the estimated value θ that can be expressed as a linear function of the dependent variable, namely:
w i can be a function of the independent variables in the sample.
Under the assumption of A1, the unbiased estimate b of the regression parameters can be obtained by using the least square method, that is
Since there may be many linear unbiased estimates, it is necessary to use the validity criteria to select the best estimate.
In the case of satisfying A2, according to the Gauss-Markov theorem, it can be proved that the estimation result of the least square method is the smallest variance among all linear unbiased estimates.
A3 normal distribution assumption
On the basis of the A2 assumption, this assumption further requires that ɛ i obey a normal distribution N (0, σ2). The assumption of normal distribution makes the least square estimation can be understood as the maximum likelihood estimation-the best unbiased estimation.
However, the normal distribution assumption is mainly used for statistical testing of the least squares estimated values of the regression parameters, and this issue needs special attention only in the case of small samples. For large samples, according to the central limit theorem, even if the error term does not satisfy the normal distribution, the estimated value of the regression parameter can still be inferred statistically.
The model uses a deep denoising autoencoder to denoise the original input data set and then conduct unsupervised layer-by-layer learning and training. Moreover, the model minimizes the error between the original input data set and the unsupervised training output data to obtain the feature vector of the original input data set. Then, the model uses support vector regression as the predictor of the final output layer of the model, and uses the acquired feature vectors of the original data set as the input feature vectors of support vector regression for prediction. The structure of the DDAE-SVR deep neural network model is shown in Fig. 2:

Model network structure.
The evaluation sample data set is divided into training data set and test data set. The training data set is input into the model mentioned in this chapter for training. Afterwards, by adjusting the number of hidden layers of the model, the optimization algorithm and other parameters, as well as the relevant parameters of support vector regression, a stable and optimal model is obtained to optimize the prediction efficiency. Finally, the test data set is input to verify the effectiveness of the model in evaluating teaching quality. The flow chart of DDAE-SVR deep neural network model to evaluate the teaching quality of colleges and universities is shown in Fig. 3:
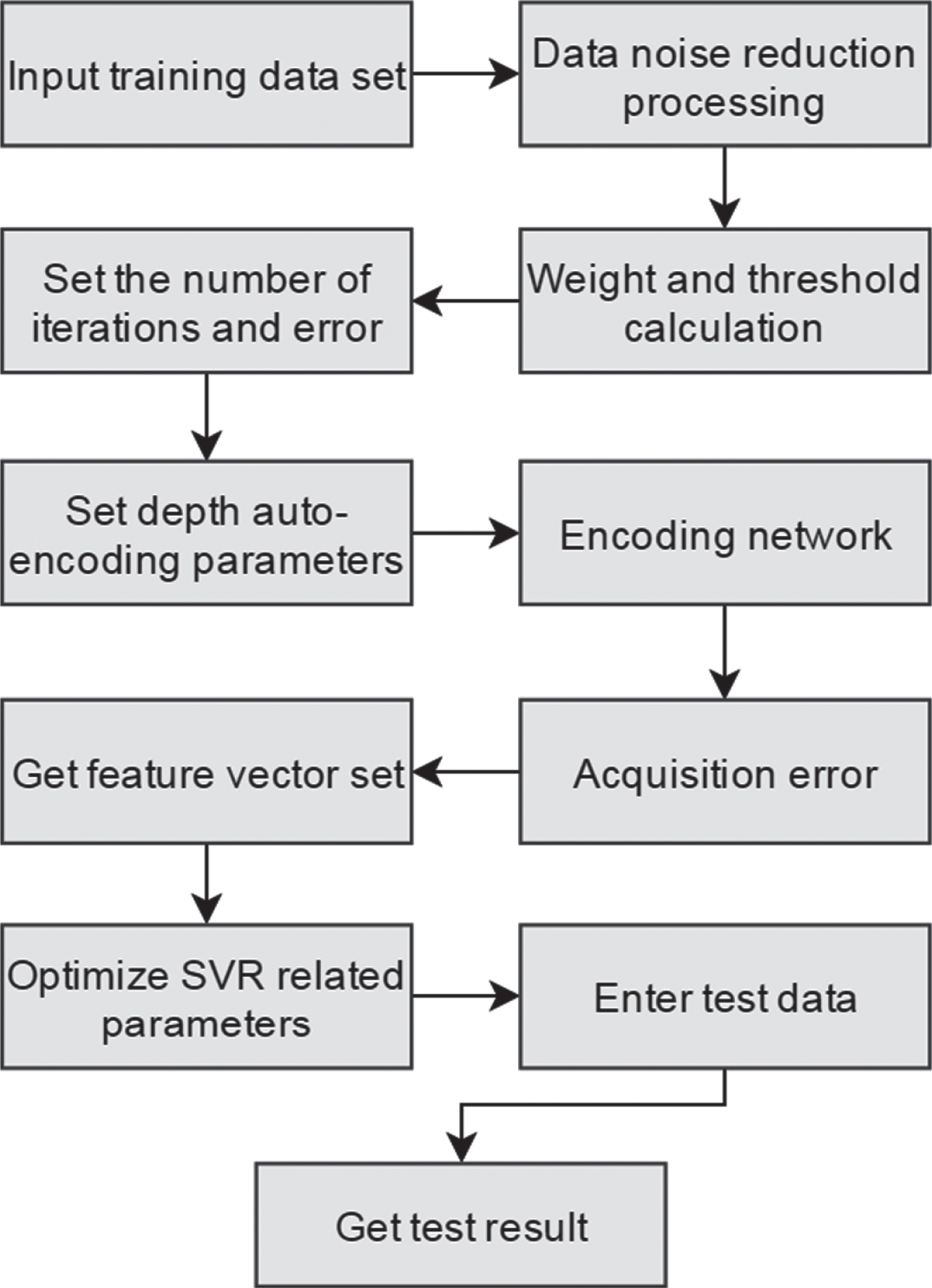
The flow chart of DDAE-SVR deep neural network model to evaluate the teaching quality of colleges and universities.
The quality evaluation model for classroom teaching is shown in Fig. 4.
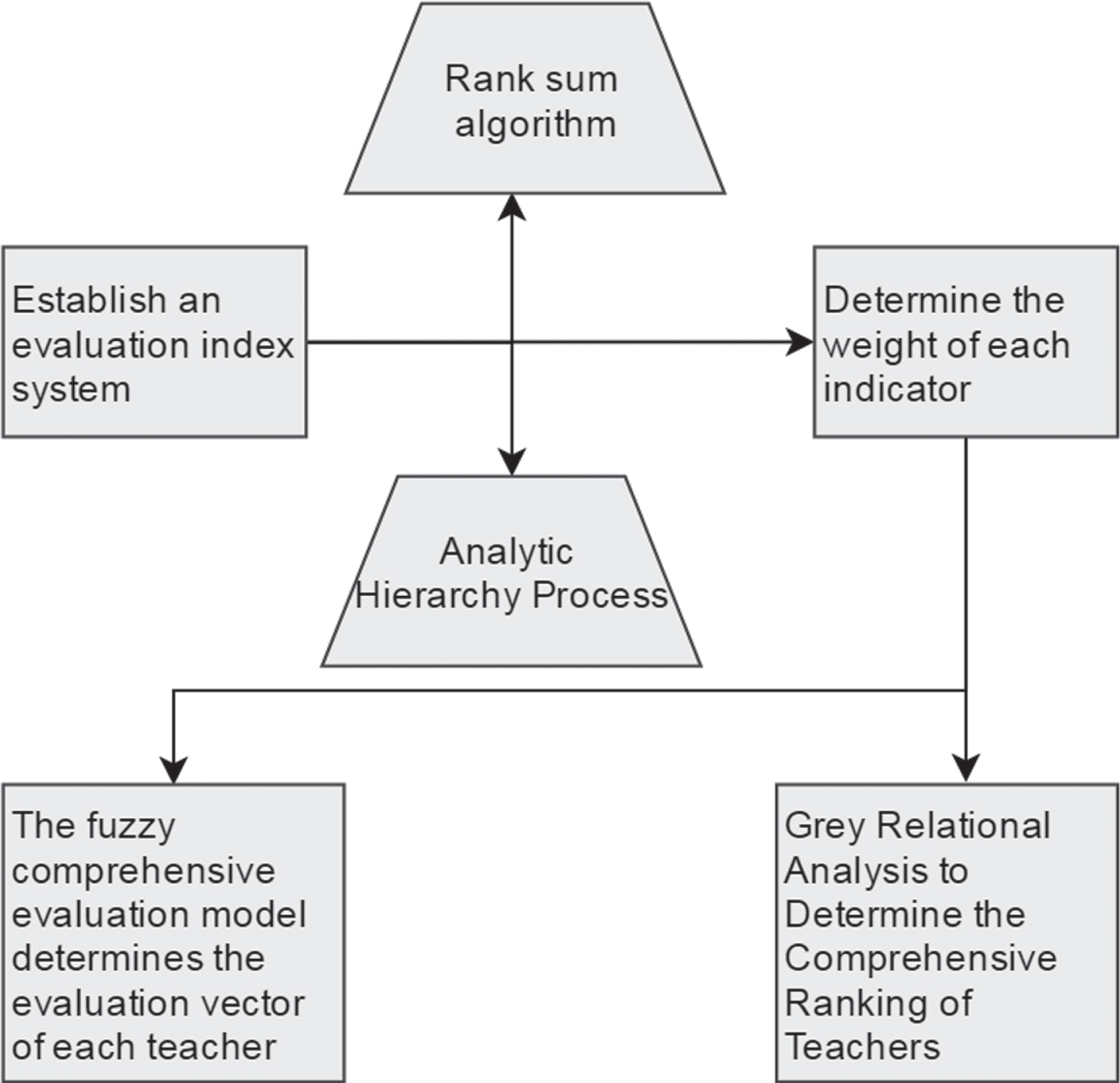
Classroom teaching quality evaluation model.
The teacher’s teaching quality evaluation model is shown in Fig. 5.
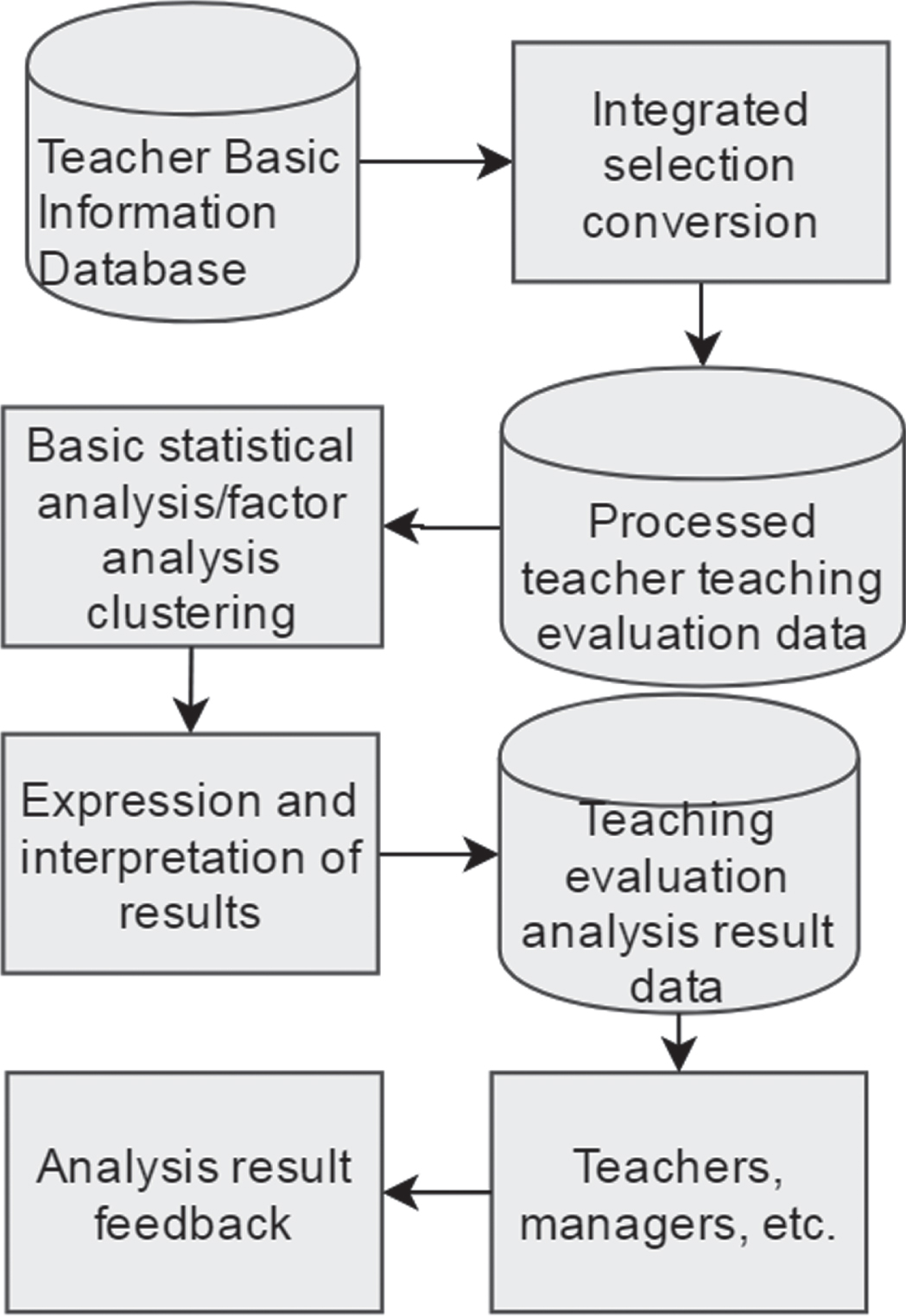
Teacher’s teaching quality evaluation model.
The model is trained through the neural network model. After repeated training cycles, the actual output value of the network and the target expected value reach the expected error. This process is the entire training network error reaches the required minimum value. After repeated iterative calculations of the network, if the error is less than the allowable minimum value, the training process of the network stops. The training process flowchart is as follows:
The data set format is (x1,x2,......,x23,y), and there are 1788 sample data in total. Among them, the data used to evaluate the teaching process of teachers with students as the main evaluation body is used as the input value of the evaluation model. Because the expected output value of the target is very important to the verification of the model, a comprehensive score based on the evaluation of multiple lecture records by the teachers of the teaching supervision group is used as the expected output value of the model. Through the analysis of the data set, the sample data with high evaluation, low evaluation and inconsistent with the facts are removed, and finally 1578 sample data are obtained. Then, normalization preprocessing is performed on the finally obtained data samples. The purpose is to improve the computational efficiency of the BP neural network model. The sample data after normalization is shown in Table 1 and Fig. 7.
Examples of sample data after normalization
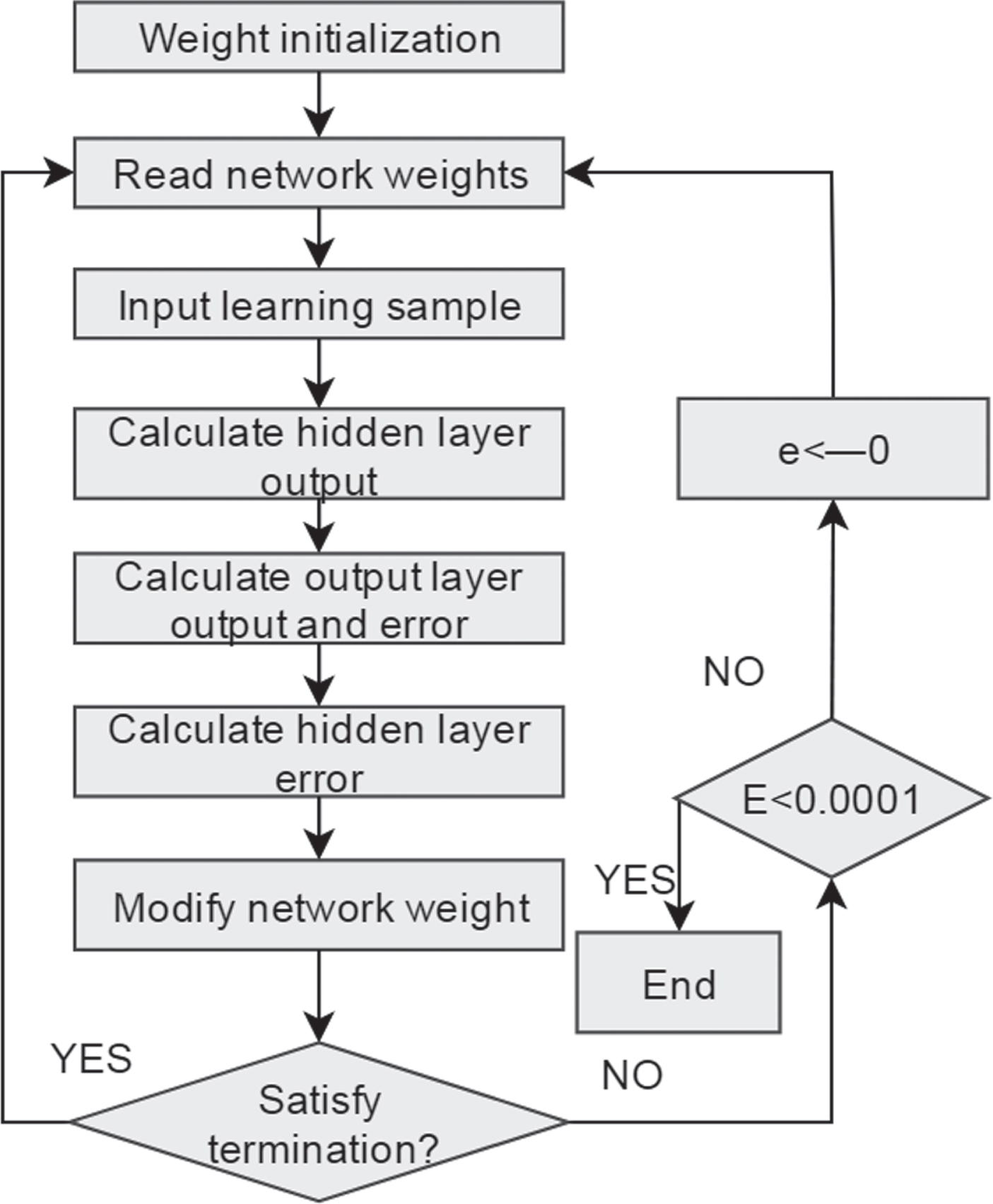
Flow chart of network training process.

Statistical graph of sample data after normalization.
In order to verify the effectiveness of the model proposed in this article in the evaluation of teaching quality in universities. This paper uses the standard BP neural network model to input the traditional data set (model1) and the new data set (model2), and the self-applicable BP neural network model to input the new data set to construct three neural network models for the evaluation of university teaching quality. Moreover, this article runs 10 experiments for each model to get the average value. At the same time, two models based on decision tree algorithm and support vector machine are constructed to evaluate teaching quality, and the other four models constructed are compared with the models proposed in this chapter. The experimental results are shown in Table 2 and Fig. 8.
Comparison of operating effects of different models
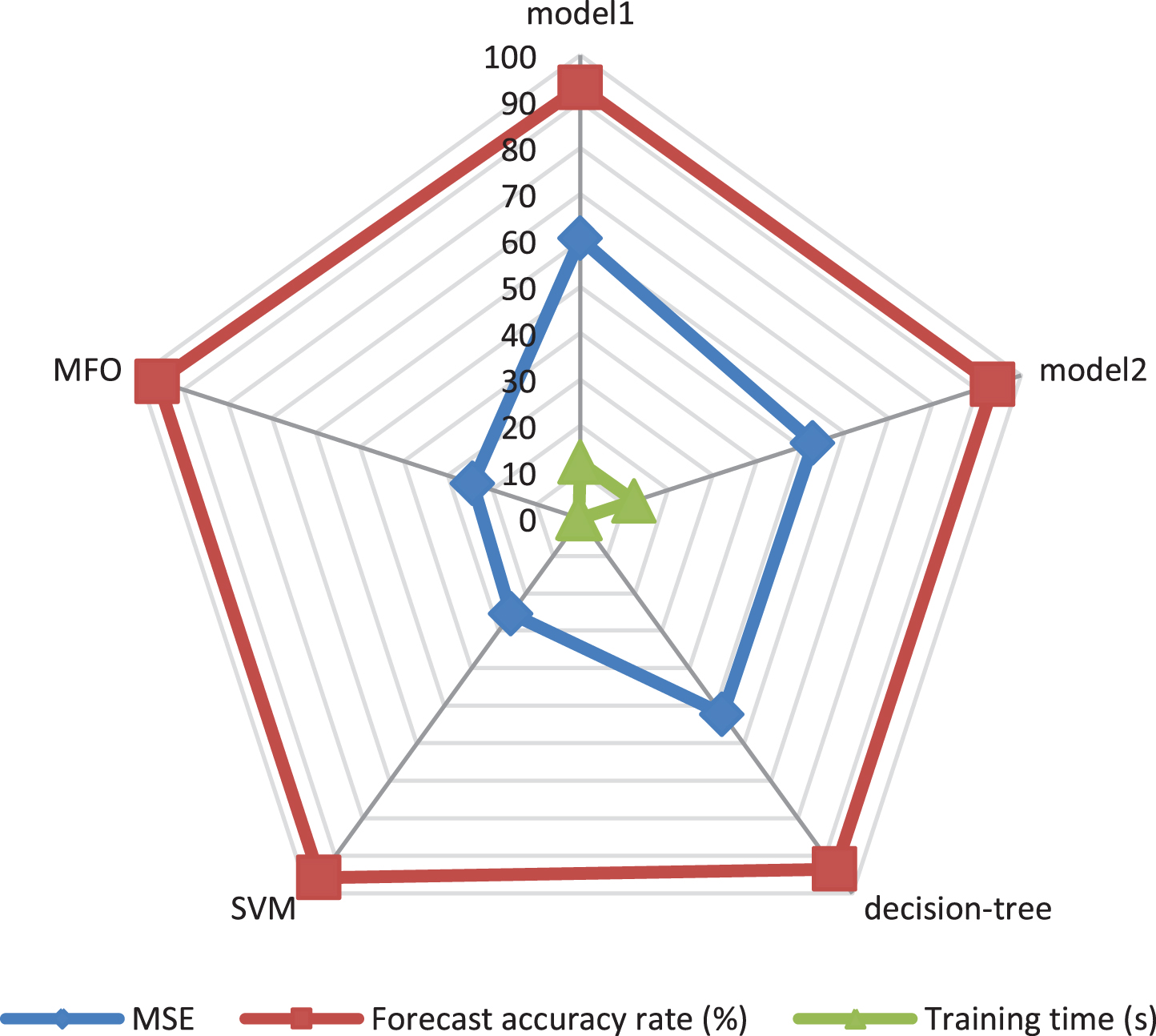
Comparison diagram of effects of different models.
It can be seen from the above chart that the model constructed in this article is more effective than other models.
Teaching quality is the core content of educational competitiveness, the lifeline of higher education, especially higher vocational colleges, and the foundation and prerequisite for the sustainable development of education. Improving the quality of teaching is the core of improving the quality of education in universities, especially higher vocational colleges. In particular, it is necessary to improve the teaching quality of teachers’ courses. The MFO algorithm imitates the horizontal positioning principle of moth-catching flames in nature, uses a logarithmic spiral to simulate the path of moths toward the flame, and inverts the pending parameters in the mathematical model. Moreover, this paper adds vertical and horizontal algorithms and chaos operators on this basis. The crisscross algorithm allows different moth individuals and the same moth to perform cross calculations with different operational dimensions to increase the diversity of moth populations, so that moths in the search space can traverse the entire search space as much as possible to find a better solution. At the same time, the introduction of chaos operator is conducive to artificial moths to jump out of the local optimal solution during chaos development. In addition, the model constructed by the MFO algorithm is used to evaluate the effect of teaching quality, and the performance of the model is analyzed through experiments. The research results show that the model constructed in this paper has certain effects.