
Abstract
The sustainable economic learning course recommendation can quickly find the knowledge information that the user really needs from the massive information space and realize the personalized recommendation to the user. However, the occurrence of trust attacks seriously affects the normal recommendation function of the recommendation system, resulting in its failure to provide users with reliable and reliable recommendation results. In order to solve the vulnerability of the recommendation system to the support attack, based on text vector model and support vector machine, this paper makes a comprehensive analysis of the current research status of the robust recommendation technology. Moreover, based on the idea of suspicious user metrics, this paper has conducts in-depth research on how to design highly robust recommendation algorithms, and constructs a highly reliable sustainable economic learning course recommendation model. In addition to this, this research tests the performance of the system from two perspectives of course recommendation satisfaction and system retrieval accuracy. The experiment proves that the model constructed in this paper performs well in the recommendation of sustainable economic learning courses.
Introduction
The development of the circular economy is a new economic form and economic product formed after the human economy and social development reached a certain stage and fell into a resource crisis. It is the result of a re-examination and reflection on the relationship between man and nature after the practice of the traditional economic operation model. The emergence of the concept of circular economy and the development of circular economy have extremely important value in modern society and are an important condition and foundation for leading the sustainable development of economic society. However, the learning process of the sustainable economics course is relatively complicated, so how to obtain effective teaching information is the key to improving the course learning.
With the development and progress of human society, Internet technology has been greatly developed, such as blockchain and artificial intelligence technologies that have been rising in industry in recent years. Enterprises continue to develop new businesses, and new technology talents have become the “resources” they are competing for, especially for recent college graduates. However, the college training program is much slower than the iterative update of technology, and the college curriculum system focuses on the cultivation of knowledge base and learning ability. If only through the courses of the training program, the students will lack practical experience and more professional knowledge. Therefore, if college students want to find more satisfactory jobs, it is necessary to plan their careers in advance and know their shortcomings. At the same time, students need to understand the capabilities required by the enterprise, and then increase the project’s practical experience and expand the learning content and need to constantly look for extracurricular learning resources to meet the needs of employment season recruitment [1].
The current extracurricular learning platforms are diverse, and typical ones include Coursea, MOOC, and Csdn. For new users, the courses of these learning platforms can only be obtained through friend introduction, advertising promotion, personal interest, etc. Afterwards, with the information left by the user on the platform, such as user evaluation, browsing history, content of interest, joined groups, etc., the system will recommend courses to users based on the course recommendation algorithm. There are many kinds of course recommendation algorithms. Typical algorithms include collaborative filtering recommendation and content-based recommendation. These algorithms rely on a large amount of user information and require a certain diversity of projects. For college students, on the one hand, most students have no experience of learning on an extracurricular platform, there is no accumulation of data, and course recommendations are too commercialized, which does not fully meet the interests of students. On the other hand, due to the small number of majors in colleges and universities, the simplification of professional courses leads to highly repeated training programs for different students, and the difference only exists in a few elective courses, general courses, etc., so it is difficult to compare and recommend [2].
With the development and progress of human society, Internet technology has been greatly developed, such as blockchain and artificial intelligence technologies that have been rising in industry in recent years [3].
Related work
The literature [4] used the user’s labeling and operation behavior record information to reprocess and sort the mail. The literature [5] proposed GroupLens, a recommendation system for news messages, which uses the idea of collaborative filtering. Literature [6] proposed the concept of a recommendation system at the collaborative filtering symposium. Netflix’s movie recommendation contest further promoted the development of recommendation systems and the promotion and enthusiasm of recommendation algorithms. With the maturity of machine learning technology, recommendation algorithms have also applied some of these principles, and advanced recommendation algorithms have emerged,such as: deep learning (convolutional neural network CNN [7], deep belief network DBN, recurrent neural network RNN), PageOptionization, LearntoRank [8], context-aware recommendation, tensor decomposition/decomposition machine, and social recommendation [9]. These methods solve some problems encountered by traditional collaborative filtering, such as personalized recommendation of long-tail content, and have achieved good recommendation results [10]. In recent years, people began to pay more attention to whether the recommendation system really meets the needs of users, and put forward context-based recommendations, that is, contextual recommendations. Common scenarios include whether to choose a working day or a weekend in the movie watching scenario, the distances and dishes of various restaurants in the meal order scenario, the shopper’s mood and the shopper’s personal hobby in the online shopping scenario. The scenario recommendation algorithm is divided into: TensorFactorization [11] and Factorization Machine. TensorFactorization includes early CP decomposition and Turker decomposition, which can be regarded as the promotion of SVD. In recent years, there have been some new tensor decomposition methods such as TT/QTT, TensorNetwork and so on. FactorizationMachine is a generalization of the fusion of matrix TensorFactorization and linear (logical) regression. In general, FactorizationMachine will have a better effect [12]. Online education platforms at home and abroad mainly include: Coursera, Khan Academy, Udemy, iTune, Youda College, Netease Cloud Classroom, School Online. Due to the continuous improvement of the quality of online courses and people’s desire for knowledge, more and more people participate in online learning. At present, there is a continuous increase in courses on online education platforms, but it still relies on traditional email to send manually selected courses such as Coursera. The majority of online courses in China are high-quality courses that need to be promoted by manual operation. At present, there is no perfect course recommendation mechanism for individual users to provide users with personalized course recommendations [13]. Regarding the research recommended by the question answerer, the main methods adopted by researchers at home and abroad include extracting the relevant features of the answerer to construct the answerer model and using machine learning or neural network methods to evaluate the indicators of the answerer. For the evaluation of the respondent’s knowledge or expertise, literature [14] used neural network model algorithms to evaluate the respondent’s skill level. The literature [15] used Bayesian networks to predict the deductive reasoning skills of the respondent. The literature [16] reflected the knowledge level of the answerer by evaluating the quality of the answer of the answerer. In the literature [17], the participation of respondents was evaluated and added to the recommended respondents. In the literature [18], based on the constructed answerer recommendation algorithm, the social network relationship of the answerer is added, and a certain effect is achieved. In the literature [19], the degree of interest of the answerer to the question asked was added to the recommended answerer algorithm. The literature [20] believed that the ability of answerers to answer questions in a timely manner and peer help are essential to the sustainability and successful lifelong learning of the online learning community. To this end, using SO as the data source for research, the literature used five basic strategies: frequency, knowledge, desire, willingness, and recency to predict which SO responders can promptly answer the questions raised by the questioners in SO. For the measurement of the answerer’s knowledge level, the literature [21] proposed to divide the answers in StackOverflow into 5 categories: Greatanswer, Goodanswer, Niceanswer, Teacher and pooranswers. Among them, Teacher is a satisfactory answer, and the types of these answers are divided according to the total scores of the answers evaluated by other learners. The literature [23] addresses the various problems in the field of vehicle communication with the suggestion of a mutual unified and dispersed spectrum sensing model. The application of the mutual cognitive paradigm minimizes conflict and multiple unknown problems. The literature [24] discusses the problem of vast volumes of big data and introduces the SmartBuddy idea of an adaptive and smart world incorporating human activity and human dynamics. The literature [25] talks about the development in parallel reconfigurable computing systems of a directed acyclic graph for video coding algorithms for motion estimation. Partitioning algorithm also plays a major role in speeding up the production of images. The article [26] deals with leveraging IoT and BigData Analytics in real-time applications using the Hadoop platform. The above-mentioned processes enable the deployment of an IoT-based Smart City. The article [27] centers on IoT and its major part in sophisticating the human practices and endeavors [28]. This paper moreover managed with the collection of different information from different assets that are associated to the web [29].
Approachable neighbor model fused with suspicious user identification
In the recommendation system, the user’s rating of a certain item can reflect the user’s preference for this item, and the user’s rating of all items can reflect the user’s tendency to popularize the item. The similarity between different users can also be measured by scoring. Therefore, based on the distribution of the user’s rating information for items, two calculation methods are proposed: deviation of the number of ratings and average similarity of neighbors, and the relevant definitions are given below.
Among them, the similarity sim tp > 0 of users u t and u p is calculated by using the traditional Pearson correlation coefficient measurement formula.
Among them, ∑i∈popJF (r
ui
) represents the number of ratings of popular items by user u, ∑j∈unpopJF (r
uj
) represents the number of ratings of non-popular items by user u. In order to facilitate the comparison of the results, the original data is linearly transformed by the min-max normalization, and the deviation degree of the number of original scores is mapped to the [0, 1] interval. The calculation method is shown in formula (5).
Among them, DDRN u represents the deviation degree of the number of ratings of users u, DDRNmin represents the minimum value of the deviation degree of the ratings of all users, and DDRNmax represents the maximum value of the deviation degree of the ratings of all users.
The degree of deviation of the score of attacking users is smaller than that of the score of real users, as shown in Fig. 1.

Example diagram of deviation from the number of user ratings.
Usually, an attacker will inject fake user profile information with a high degree of similarity to the real user profile into the recommendation system. Therefore, in the recommendation process, the attacking user is most likely to be selected as the target user’s nearest neighbor and the real user to participate in the recommendation together, so as to achieve the purpose of the attack. Meanwhile, the attack profile is influenced by the generative model and has a high degree of similarity. Therefore, the average similarity of neighbors of attacking users is higher than that of real users, as shown in Fig. 2.
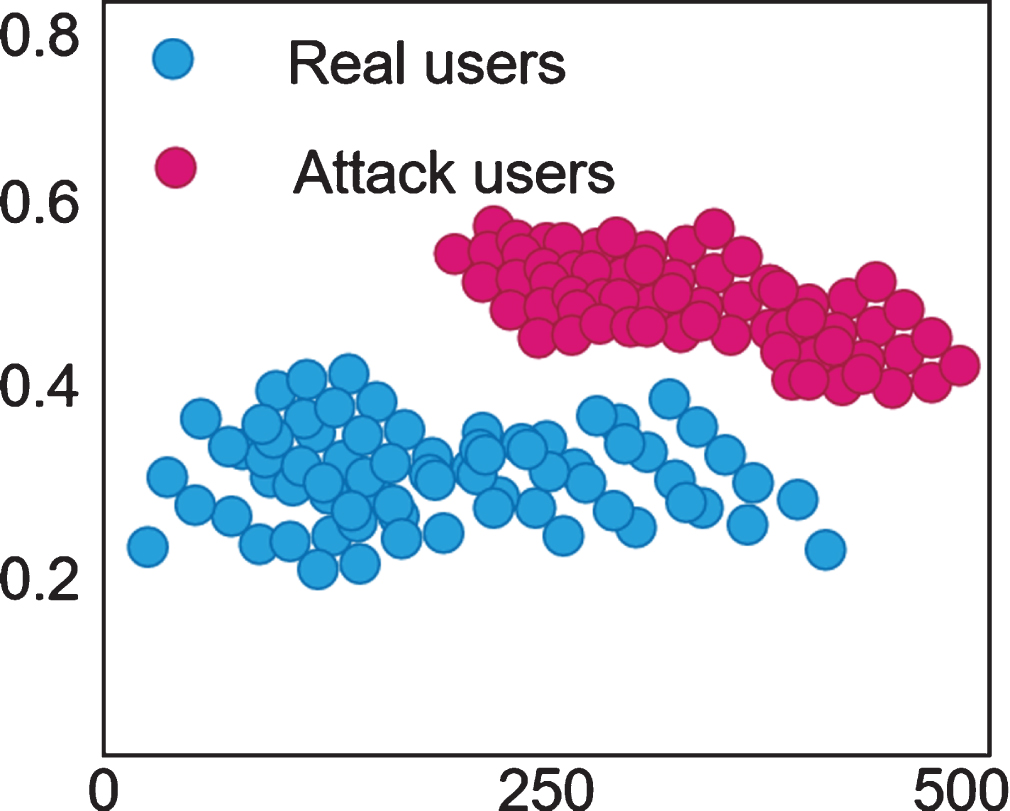
Example graph of average similarity of user neighbors.
Based on the above analysis, it can be seen that compared with the real users, the attack users have a small deviation in the number of scores and a large average similarity between neighbors. If a user has both a small deviation degree of scores and a large average similarity of neighbors, it has the characteristics of attacking users and can be identified as a suspicious user.
The user-based recommendation algorithm is a common one in collaborative filtering algorithms Its central idea is based on the target user’s neighbors to predict the score for a certain item. In the user rating database, there are obvious user preference features and item preference features. The former means that some users rate the items higher than others, and the latter means that some items get higher scores than other items. In order to reduce the impact of these two situations on the predicted score, we package it as a reference offset, the specific form is shown in formula (7).
Among them, μ represents the average of all ratings. b
u
and b
i
represent the deviations of user u and item i from the overall score data distribution, respectively. The calculation method is shown in formulas (8) and (9).
Among them, I u represents the set of items rated by user u, and U i represents the set of users rated for item i.
Now the reference offset, the suspicious user identification result and the user-based recommendation model are combined to construct a Reliable Neighbor Model Incorporated with SuspiciousUsers Identification (RNSUI). The prediction score calculation method is shown in formula (10).
Among them, N (u) represents the proximity set of the target user u,
As can be seen from the above formula, in the process of selecting neighbors for the target user u, even if the similarity between a certain user v and the target user u is relatively large, if the user v belongs to the range of suspicious users, the user will not be included in the target user’s neighbor set to reduce the impact of the attack profile on the recommendation process.
In the recommendation algorithm based on the matrix factorization model, the prediction score
In order to obtain p
u
and q
i
, the least squares problem of formula (13) can be solved by stochastic gradient descent:
Among them, r ui represents the user’s true rating of item i, λ (∥ q i ∥ 2 + ∥ p u ∥ 2) is the regular term added to avoid overfitting, and λ is a constant.
In formula (13),
From the formula (14), it can be seen that when the value of r ui is relatively large, the value of e ui will also be relatively large. In the case of the presence of a support attack in the system, r ui generally takes the maximum value (push attack) or minimum value (nuclear attack). Therefore, the residual value of the attacking user is larger than that of most real users. The MovieLens data set (this data set is used for the experiments in this article) is taken as an example, and the score value is an integer between 1 and 5, that is e ui ∈ [- 5, 5].
Among them, ρ (e
ui
) is the bounded function about residual e
ui
obtained by Tukey function, as shown in formula (16).
Among them, c is a constant, the value is 4.7.
The impact function is intuitively the first derivative of the robust estimator in the probability distribution space. It describes the ability of outlier data to affect the robust estimator. Therefore, in robust statistics, the robustness of the estimator can be reflected by the influence function. The influence function of Turkey M-estimator mentioned above is shown in equation (18).
Among them, sup represents the upper limit. Negligence error is a measure of the worst degree of pollution at a point x, and if it is finite, it is a biased robustness to the distribution function F.
From definition 8, we can see that if the influence function of an estimator is unbounded, the sensitivity of the fault error tends to infinity. Therefore, when the residual value tends to infinity, the value of the influencing function also tends to infinity, so that the parameter estimates are sensitive to outliers and the results are biased. Therefore, its influence function should be a bounded function to ensure that an estimator is a robust estimator, and in order to ensure the uniqueness of the estimation, the objective function is required to adopt a convex function form. The following proves that the Tukey M-estimator is a robust estimator from the boundedness of the influence function and the uniqueness of the solution of the objective function.
That is
Therefore, the influence function of Tukey M-estimator is a bounded function.
Since most M-estimators are difficult to find analytical solutions, it is usually solved by using an iterative method. The solution of objective function formula (15) is equivalent to solving the weighted least squares problem shown in formula (21).
Among them, A is the weight function obtained by using the influence function of Tukey M-estimator, as shown in formula (22).
It can be seen from formulas (21) and (22) that each residual is given a different weight through a weight function. Therefore, how to limit the influence of larger residuals in the parameter estimation process depends on the weight function. Figure 3 plots the weight function images of Huber M-estimator and Tukey M-estimator used in this article, respectively. As can be seen from the image, as the residual value |e ui | gradually increases, the weight function values of both estimators become smaller and smaller. Meanwhile, the weight function value of Tukey M-estimator is significantly smaller than that of Huber M-estimator. Therefore, for the Tukey M-estimator, the larger the residual, the smaller the weight. According to the previous analysis, the larger the residual, the greater the possibility of attacking the user, so the Tukey M-estimator can weaken the impact of the attack profile.

Weight function image.
In order to improve the robustness and accuracy of the recommendation algorithm based on matrix factorization, the approachable neighbor model incorporating suspicious user identification is combined with the robust matrix factorization model based on Tukey M-estimator. A robust recommendation algorithm based on the identification of suspicious users is proposed. The overall framework of the algorithm given below is shown in Fig. 4.

Robust recommendation algorithm RRA-SUITME framework.
It can be seen from Fig. 4 that to complete the recommendation to the target user, we first need to train the model to obtain the optimal value of each feature parameter. Therefore, based on the approachable neighbor model and the robust matrix decomposition model based on Tukey M-estimator, we use the stochastic gradient descent method to iteratively solve equation (15). The calculation method of each parameter is shown in formulas (23)∼(26).
Next, according to the optimal value of each feature parameter, the prediction score formula (27) is used to complete the recommendation to the target user.
The physical meaning of the variables in the above formula is the same as in formula (10).
The relevant components required for the effective operation of a recommendation algorithm are user-facing client, developer-oriented server and data storage related database. Shivo College is a video learning teaching website for teachers. The daily recommendation is a very important display field on the home page. The main function is to recommend some video courses that are of interest to teachers to increase teachers’ interest in the website. Therefore, the client mainly displays the daily recommended video content, which are different recommendation results calculated by the above recommendation algorithm according to each user. The recommendation module is one of the main modules on the server side. The recommendation module is mainly implemented with the related algorithms mentioned in the previous chapter. The database is mainly used to store user-related data, video-related data, and some user behavior data on the website. The personalized daily recommendation design is mainly shown in Fig. 5.
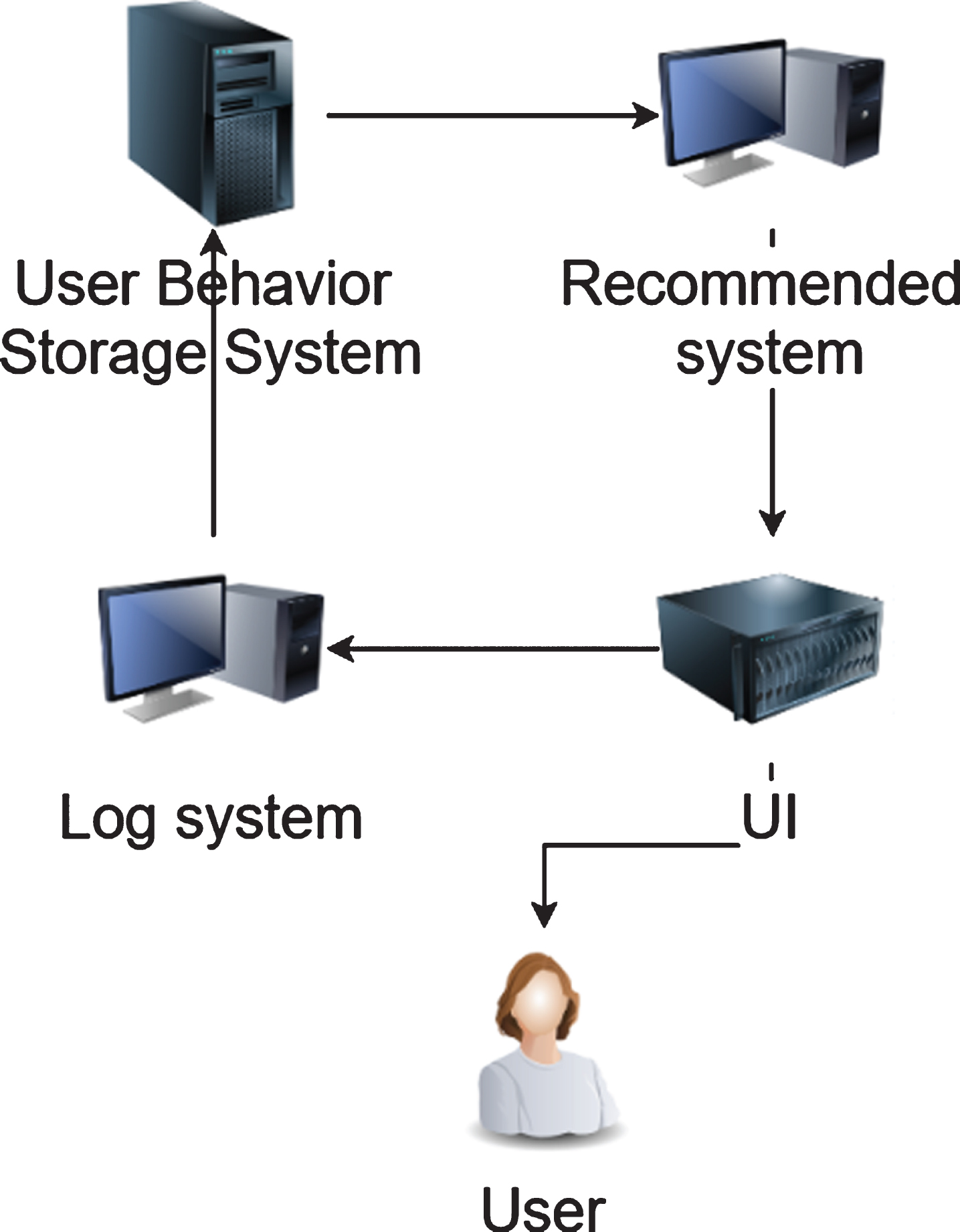
Recommendation system framework.
The server mainly provides a stable and reliable service for the algorithm. Since no real-time data is connected here, the result of the recommended algorithm is generated offline. For scenarios with a large number of users, storing and querying personalized results is a very time-consuming part. What needs to be explained in detail is the realization of the stability and high performance of the back-end service in the daily recommendation scenario. At present, most large companies deploy algorithms based on APIs. This approach guarantees complete isolation of algorithm services and back-end development and allows algorithm engineers and back-end engineers to develop simultaneously without affecting their respective schedules. The corresponding back-end engineer only needs to leave the interface in the corresponding module, and the algorithm personnel can access the corresponding algorithm API to run. When doing daily recommendation related projects, it also uses the above process to provide personalized recommendation services for the back-end team.
The search module is divided into two parts: word search and result scoring. The flow of the search module is shown in Fig. 7. Taking “machine learning” as an example, the word segmentation results are the respective results obtained by machine, learning, machine learning, and reverse index respectively. Through the sorting and scoring algorithm, a sorted set of results is obtained and then displayed.
Flowchart of server development.
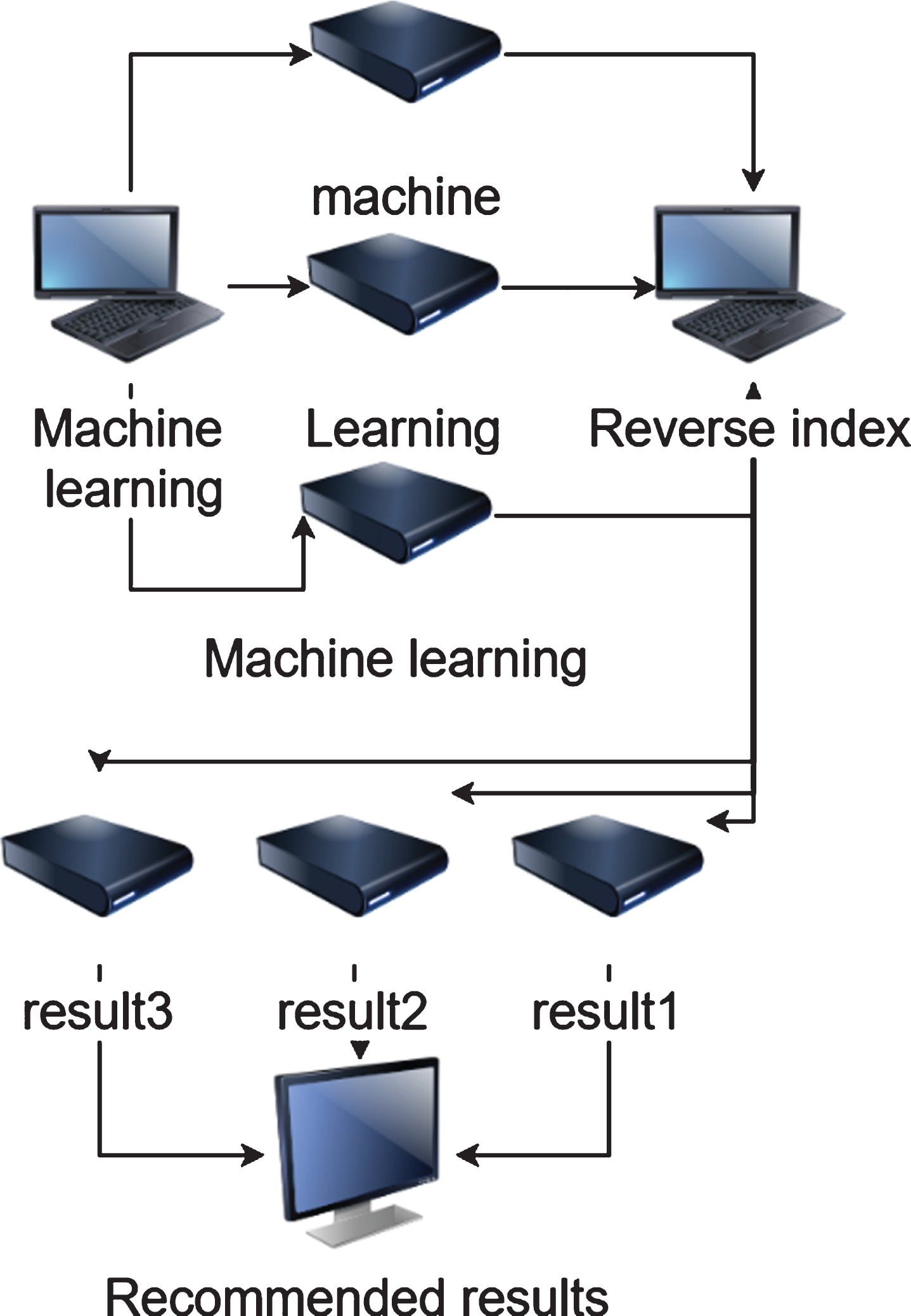
Retrieval flowchart.
When there are multiple keywords in the search sentence, we need to perform the search through the word segmentation search. On the one hand, stop words in search sentences can be filtered, such as “of”, “and” and so on. On the other hand, it can comprehensively consider the semantic information in the search sentence to make the search results more comprehensive and accurate. This article uses Jieba toolkit for word segmentation of search sentences. Using indexing technology can shorten the average retrieval time, but the speed is not enough, and the quality of the retrieval results is also crucial. In order to match the results more comprehensively, the word segmentation search sorts the matching results to match the search results more accurately. In order to make the results with a higher matching degree appear more forward, it is necessary to rank the search results. In search engines, commonly used web page sorting algorithms are link-based sorting algorithm, that is, PageRank, content-based sorting algorithms, that is, TF-IDF, BM25, etc. This article uses the content-based BM25 word-document correlation algorithm to score the matching results.
Next, the performance of the system is tested. In this performance test, this article focuses on the satisfaction of course recommendation and the accuracy of system retrieval. First, this article investigates and analyzes the satisfaction of course recommendation. The system constructed in this study recommends the courses required by users of sustainable economic learning, and through survey feedback, satisfaction is obtained. In this study, 100 groups of users were counted, among which there are 50 groups using the recommendation system and the traditional recommendation system respectively, and the results are compared with the traditional recommendation model. The results are shown in Table 1 and Fig. 8.
Statistical table of course recommendation satisfaction
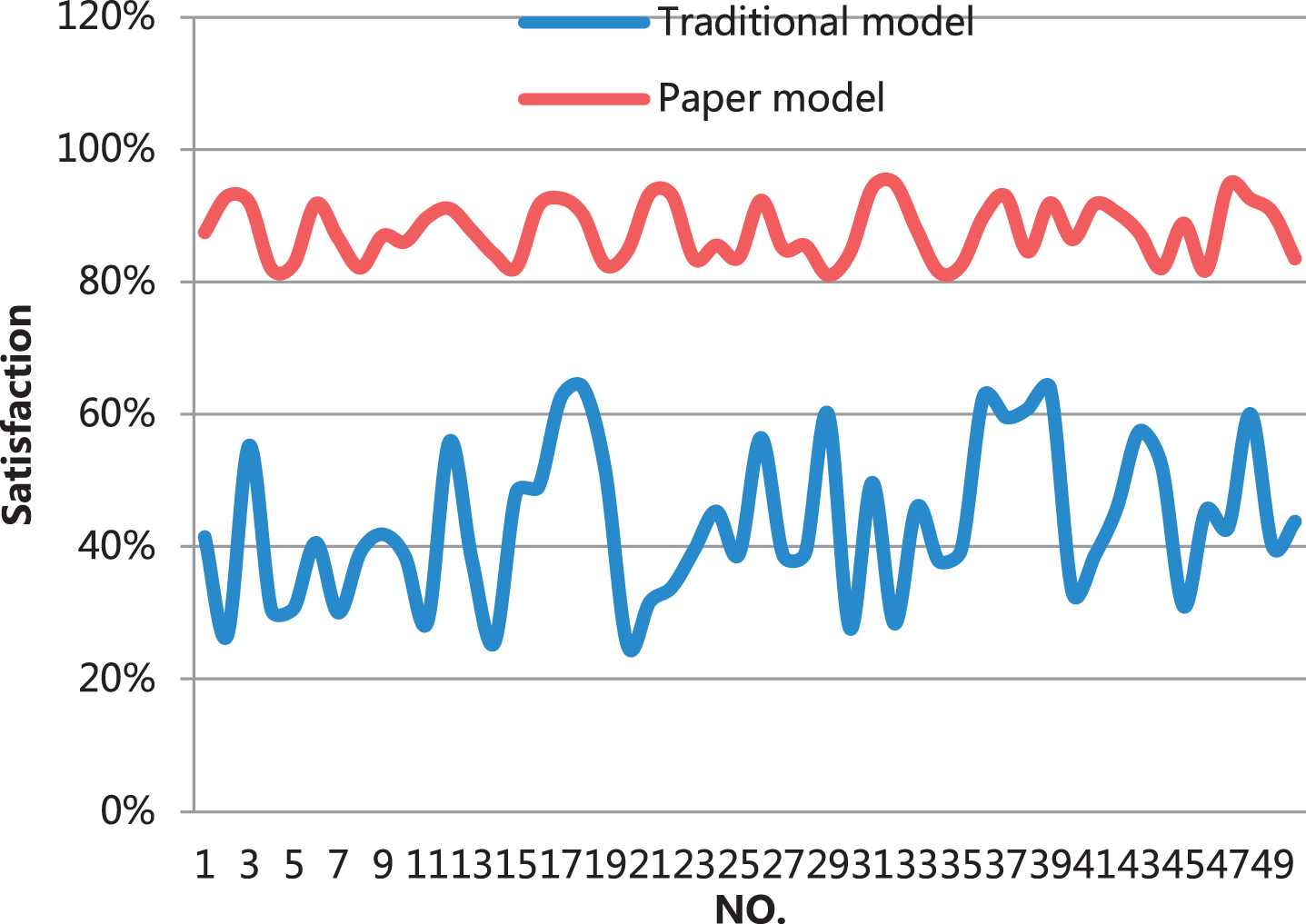
Statistical table of course recommendation satisfaction.
It can be seen from the above diagram and table that the users’ satisfaction with the traditional model is not high, while the users’ satisfaction with the model constructed in this paper is between 80–95%, which is higher. Next, this study conducted a research and analysis on the accuracy of model retrieval, and also compared the research model constructed in this paper with the traditional model. The results obtained are shown in Table 2 and Fig. 9.
Statistical table of retrieval accuracy of course vocabulary
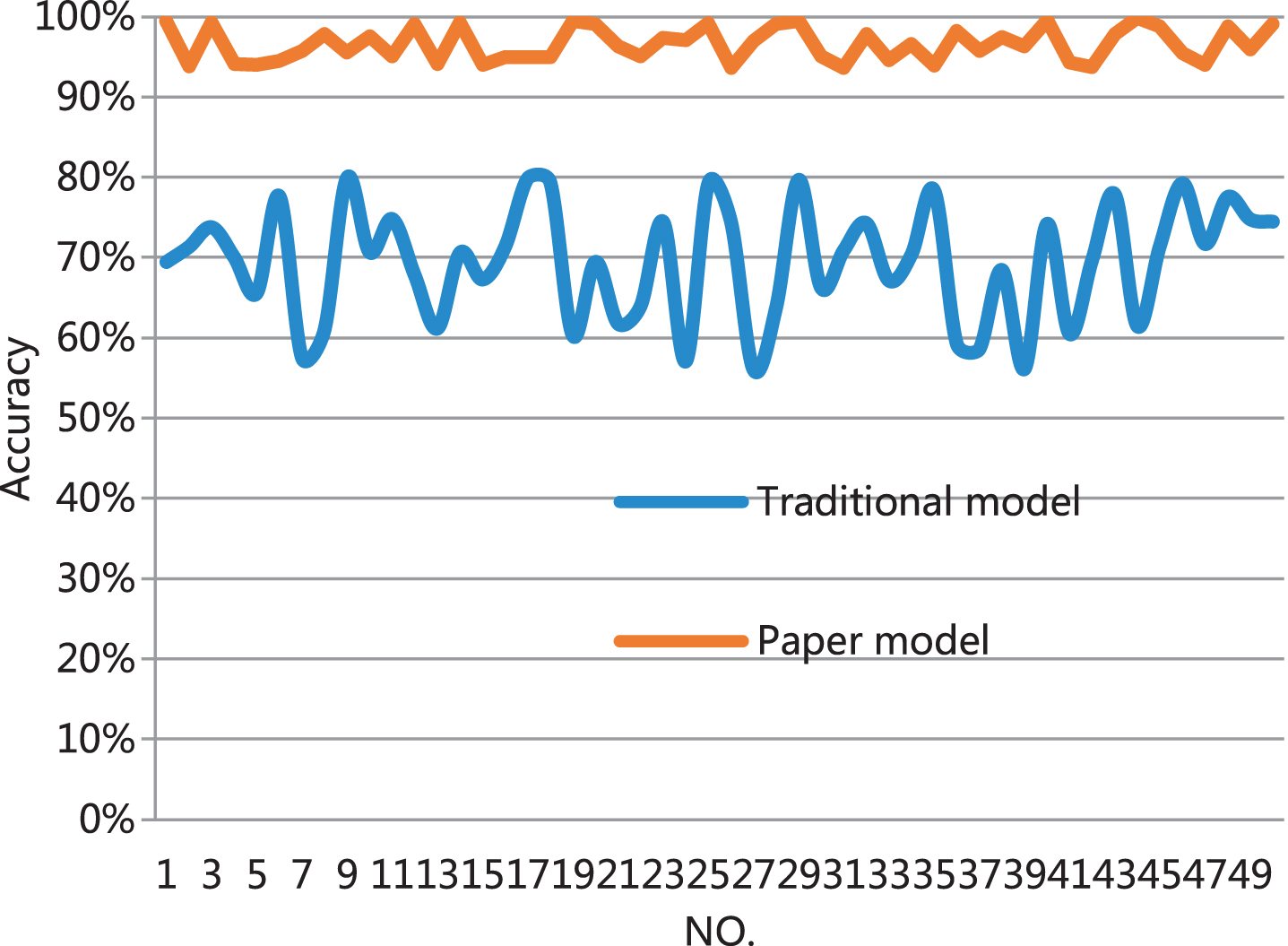
Statistical diagram of the retrieval accuracy of course vocabulary.
As shown in Fig. 9, the model constructed in this paper has a high accuracy rate for course vocabulary retrieval, all of which are above 90%, and the highest can reach 100%, while the retrieval accuracy rate of the traditional model is obviously not as good as the model of this paper. It can be seen that the model constructed in this paper is suitable for the sustainable economic learning classroom recommendation system.
The key to sustainable economic learning course recommendation lies in how to eliminate the interference data in course recommendation. This paper has conducted a comprehensive analysis of the current research status of robust recommendation technology. On this basis, in view of the shortcomings of the current recommendation algorithm, based on the idea of suspicious user metrics, an in-depth study on how to design a highly robust recommendation algorithm is carried out, and a robust recommendation method based on suspicious user metrics and multidimensional trust is proposed. Moreover, this study uses the correlation vector machine classifier to measure the user’s suspiciousness and integrates the suspiciousness into the three trust attributes of user rating authority, objectivity and similarity to build a reliable multi-dimensional trust model, which can effectively measure the trust between users. In addition, this paper combines the trust model with the user-based recommendation model to recommend courses to target users. The model constructed in this paper has a high accuracy rate for course vocabulary retrieval, all of which are above 90%, and the user satisfaction is between 80–95%, which is relatively high. The experimental results prove that the model constructed in this paper is suitable for the sustainable economic learning classroom recommendation system.