
Abstract
In server clusters, the static scheduling algorithm has superior performance when the user visits are relatively stable. In the face of sudden increase in user traffic, the dynamic scheduling algorithm has a better load balancing effect than the static scheduling algorithm. However, in the face of complex network environments, the static scheduling algorithm cannot adjust the load according to the performance of the server in real time. The dynamic scheduling algorithm using a single weight to evaluate server performance is unreliable, and load scheduling with reference to the number of connections has uncertainty. In view of this problem, this paper proposes a cluster load balancing algorithm based on dynamic consistent hash based on the study of load balancing based on LVS clusters. By analyzing the performance and load parameters, we divide the request process into in-cycle and out-of-cycle. By setting up the LVS cluster system, the performance weights, load parameters, number of virtual nodes and cycles of the algorithm in this paper are determined experimentally. Finally, the response time and throughput of the algorithm in this paper are compared with the WRR algorithm and WLC algorithm. The results show that the time and throughput of this algorithm are better than WRR algorithm and WLC algorithm.
Introduction
The static scheduling algorithm and the dynamic scheduling algorithm in the server cluster have their own advantages and disadvantages. The static scheduling algorithm is usually applied in a simple network application, and has a superior performance when the amount of user access is relatively stable. In the face of the increase in the number of sudden user visits, the dynamic scheduling algorithm has better load balancing effect than the static scheduling algorithm, and distributes based on the requested content and the number of connections, which makes the server cluster load more accurate.
However, in the face of complex network environments, they have some disadvantages. In the actual network environment, the user’s visit volume fluctuates, which causes the load pressure of the server to change in real time. Because the static scheduling algorithm performs load balancing according to a preset scheduling policy, it is impossible to adjust the load according to the performance of the server in real time. In a high-concurrency network environment, it is easy to cause server load scheduling to be uneven and seriously affect the service quality of the server cluster. Although the dynamic scheduling algorithm can monitor the number of server connections in real time and set weights for each server, there are still some shortcomings in practical applications. The shortcomings of the existing dynamic scheduling algorithms for server clusters are described below: Using a single weight to evaluate server performance is not reliable. The weight is the empirical value obtained by the operation and maintenance personnel on the basis of the evaluation of the server performance, and does not have objectivity. The load balancing server cluster refers to the number of connections for load scheduling. This scheduling method has uncertainty on the pressure caused by the server.
In view of the above problems, this paper selects a widely used consistent hash algorithm, and uses its advantages in load scheduling to propose a cluster load balancing based on dynamic consistent hash, which solves the problem that the server negative cluster load balancing cannot meet the current network requirements.
Performance and load parameters
This article selects three factors: CPU performance, memory capacity, and disk I/O as factors to evaluate server performance. We set a weight to calibrate the performance index of the three factors, and represent these three factors as a weight vector [x1, x2, x3]. It satisfies
Similarly, the measurement of the load is the result of a comprehensive calculation based on the evaluation of CPU time occupancy L (C i ), memory space occupancy L (M i ), and disk I/O occupancy L (D i ). Set the weight vector [w c , w m , w d ] of each server node. This vector is called the load weight vector. The load value is calculated by the following formula:
The Consistent Hash Algorithm was proposed in 1997 by Karger et al. of the Massachusetts Institute of Technology in solving distributed Cache. This algorithm is often used in load balancing to require resources to be evenly distributed to all nodes, and to quickly route user requests to the corresponding nodes. As shown in Fig. 1, the idea of the consistent hash algorithm is: first construct an integer ring with a length of 232, and place it on the ring according to the hash value of Node1-4’s node name (distributed as [0, 232 - 1]). Now to store resources, according to the hash value Hash i of the key of the resource (also distributed as [0, 232 - 1]), a node closest to Hash i (the first greater than or equal to Hash i ) is found clockwise on the ring, and the mapping relations between resources and nodes are established.
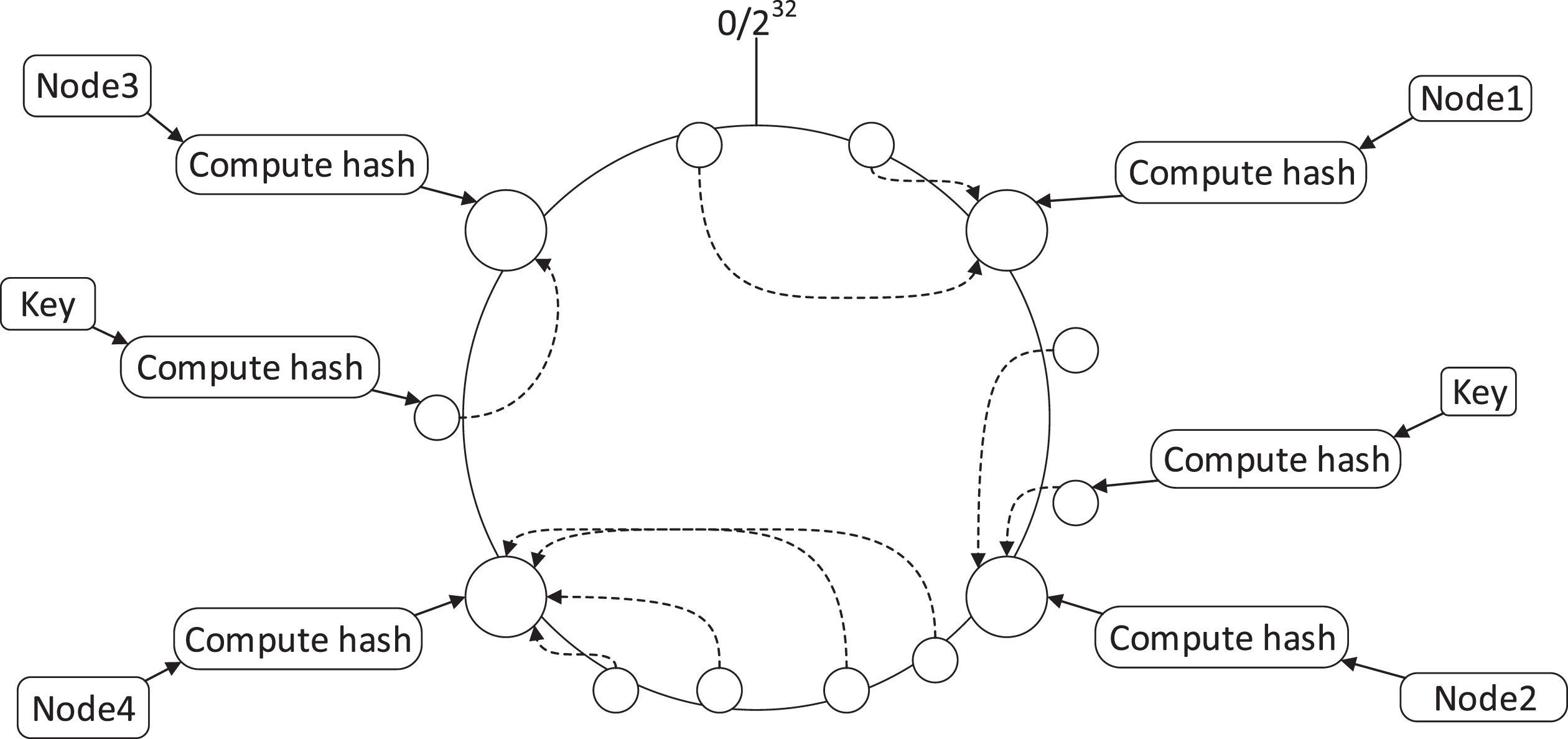
Consistent hash algorithm.
The easiest way to allocate nodes is to take the surplus, that is, there are 4 nodes, resource key = 5, 5 % 4 =1, select Node1, resource key = 4, 4 % 4 =0, select Node1. Although it is simple, it has an obvious disadvantage. If the number of nodes increases or decreases, and the server nodes are unevenly distributed, a large number of keys cannot be hit, which causes the transfer of request pressure. User requests will be concentrated on a certain server, causing server load pressure. If it is too large, it may even cause downtime and affect the operation of the entire cluster system.
The method of adding virtual nodes can effectively solve the above problems: when there are fewer server nodes and the distribution is uneven, the server nodes can be mapped into multiple virtual nodes, and these virtual nodes are evenly distributed on the hash ring. The user requests the corresponding virtual nodes, and then visit the server node corresponding to the virtual node. As shown in Fig. 2, the two requests point to V11 and V32 virtual nodes through hash table calculations, and finally find the physical nodes S1 and S2 by correspondence.
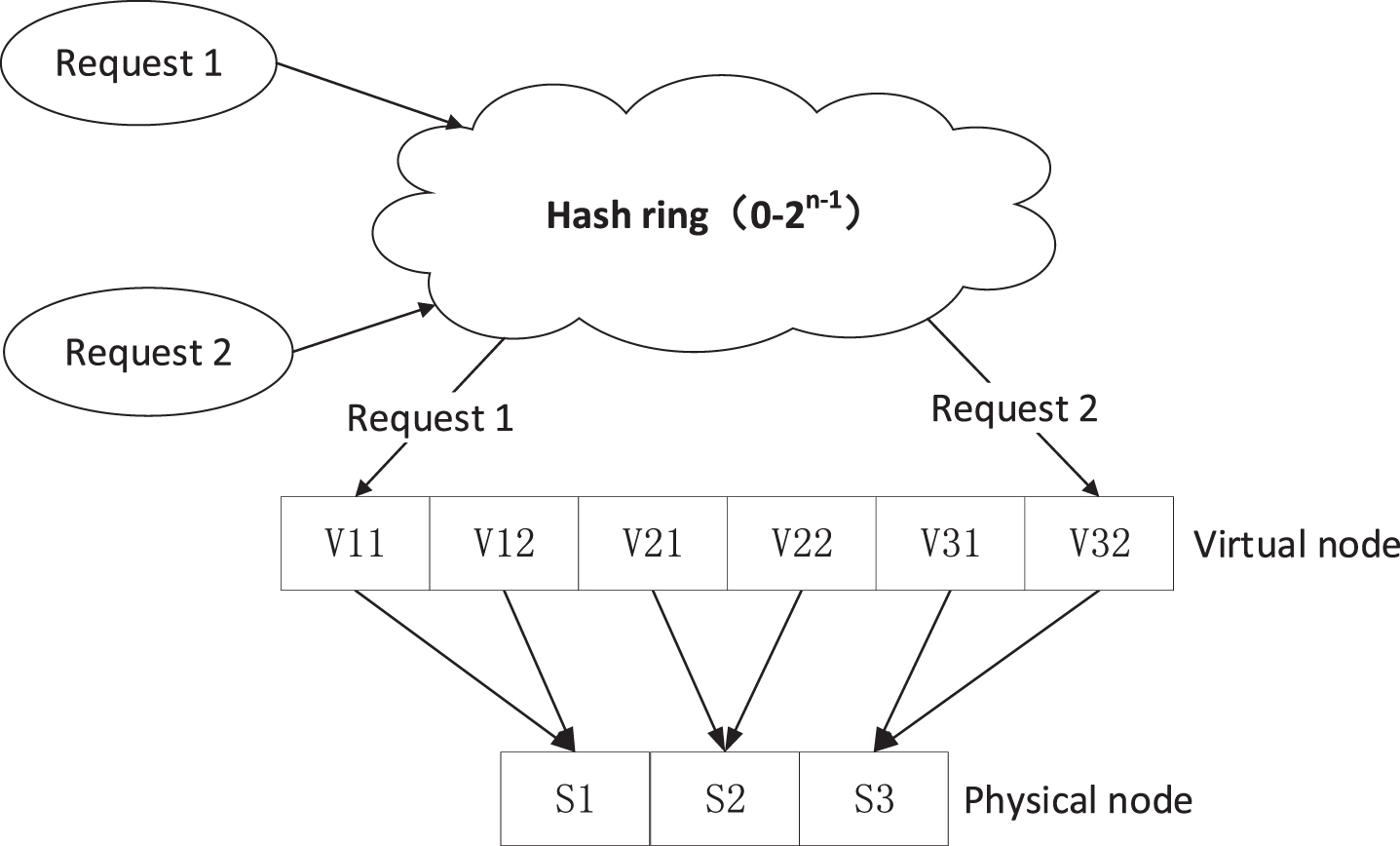
Consistent Hash Algorithm on Virtual Machine Point.
By virtualizing the virtual nodes in the consistent hash algorithm to achieve server cluster load balancing, this paper proposes a dynamic consistent hash algorithm based on this, and further refines the virtual nodes.
The dynamic consistency algorithm collects the performance information of the server according to the time cycle. The hardware information of the server cluster is fixed. The server performance information is collected in the first cycle when the algorithm is started, and the virtual node is hashed in the first cycle. The number is called the number of nodes in the cycle. Since the server cluster has just been opened at this time, there is no load problem in the server node, and the performance information of the server quantization is referred to when the hash algorithm calculates the virtual node. The load balancer collects performance data from the server and counts the average server performance, generates a server performance vector and normalizes the vector, and finally gets the number of virtual nodes in the first cycle:
Where n is the number of virtual nodes corresponding to the physical server. V i may have a decimal, so round up V i .
Under normal circumstances, the server does not use all the performance during the running cycle. At this time, the server still has the remaining performance to extend beyond the cycle. The number of virtual nodes that can be increased in this part is called the number of nodes outside the cycle. As shown in formula (4), p
i
indicates that the total performance of the server node is higher than the current cycle load value. A smaller value of p
i
indicates that the resource utilization of the server node is approaching saturation. Otherwise, it indicates that the resource utilization of the server node is smaller. Use the remaining resources to increase virtual nodes. The following formula:
A critical value is defined in the DCH algorithm. The disk I/O occupancy rate L (D i ) reaches γ, the memory space occupancy rate L (M i ) reaches α, and the CPU occupancy rate L (C i ) reaches α as the critical threshold. When any indicator of any server reaches the threshold, the scheduling algorithm will set the p i of the server to 0, and the user request will not be assigned to the server until the p i is recalculated in the next cycle. If some servers are not in the critical state, first obtain the weight load L i according to formula (2), and then calculate the load ratio p i .
Algorithm flow
The dynamic consistent hash load balancing algorithm collects server node information periodically. By calculating the proportion of CPU, memory, and disk occupied on the server node, it represents the load of the server node. According to the above description combined with the algorithm, the finishing process is shown in the figure. As shown in Fig. 3.
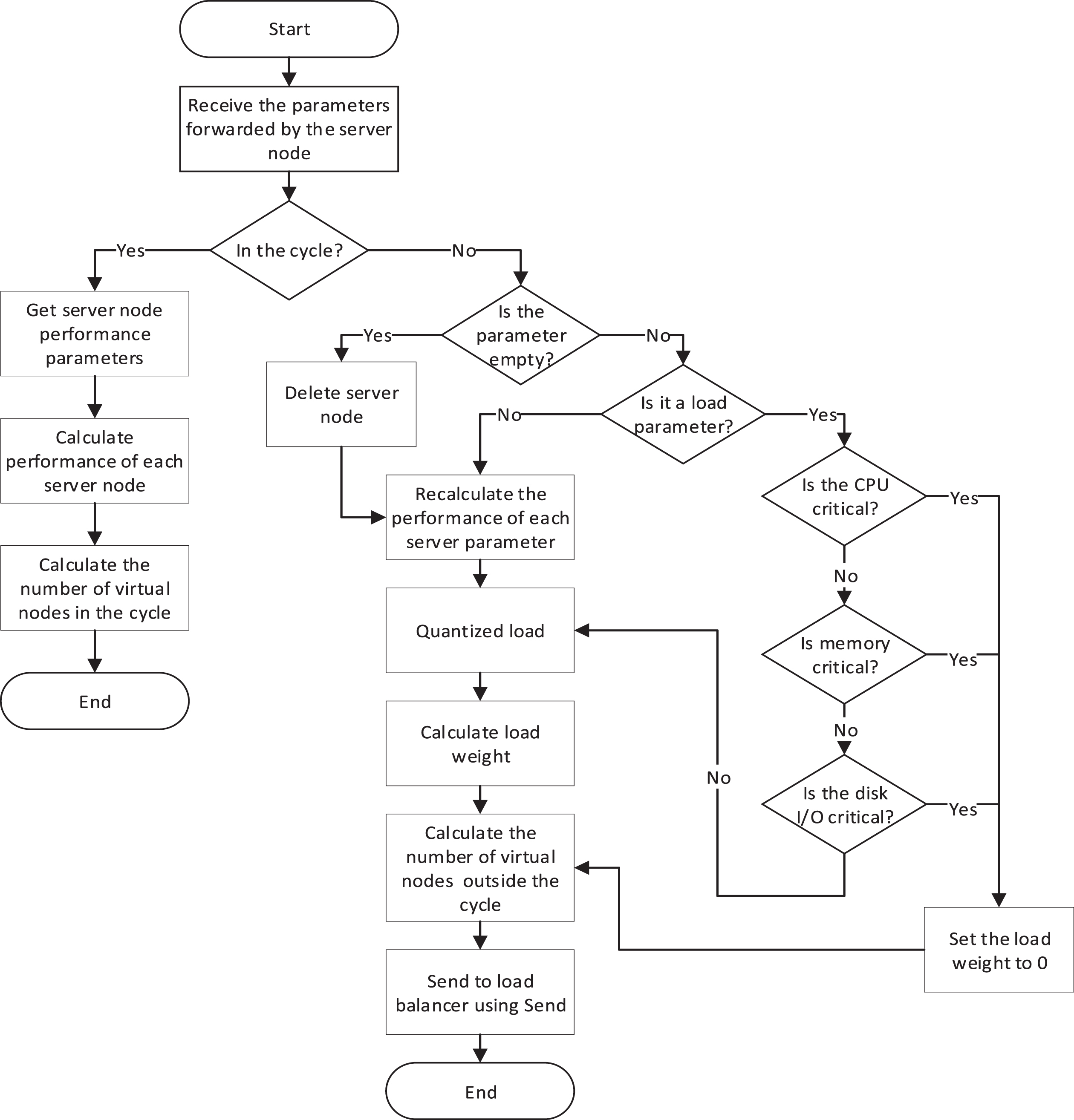
Algorithm flow.
The load balancer obtains the performance parameters of all server nodes through data transmission, and processes these parameters through a dynamic consistent hash algorithm. During the cycle, the parameters transmitted from the server nodes are received, the benchmark performance parameters are converted into standardized performance parameters through calculation, and the number of virtual nodes is calculated. If a server cluster goes down or a new server node joins the server cluster outside the cycle, the basic performance parameters need to be recalculated. Standardize server node performance and calculate load weights based on quantified load of CPU frequency, memory size, and disk I/O. Finally, use the Send function to send the number of virtual nodes to the load balancer.
1) CPU frequency
The CPU parameters are mainly obtained through computer programming. Under Linux system, you can directly read the parameters in the cpuinfo file. The frequency is calculated by programming. The calculation formula is as follows:
2) memory size
The memory size can be obtained directly through the meminfo file, or it can be obtained through program coding. The memory size calculation formula is as follows:
3) Disk I/O rate
A disk I/O refers to a continuous read or write of a disk. The total number of disk reads and writes per second is called the disk IOPS. IOPS is used to measure the disk I/O rate. Assuming that the number of revolutions per second of the disk is C, the quasi-return time is
The dynamic consistent hash algorithm has several functional divisions in the specific implementation process. The specific functions are the acquisition of server node performance parameters, communication between the load balancer and server nodes, calculation of the number of virtual nodes on the load balancer, and load scheduling. Figure 4 is the overall design of the dynamic consistent hash algorithm, which is mainly divided into two ends of the load balancer and server nodes.
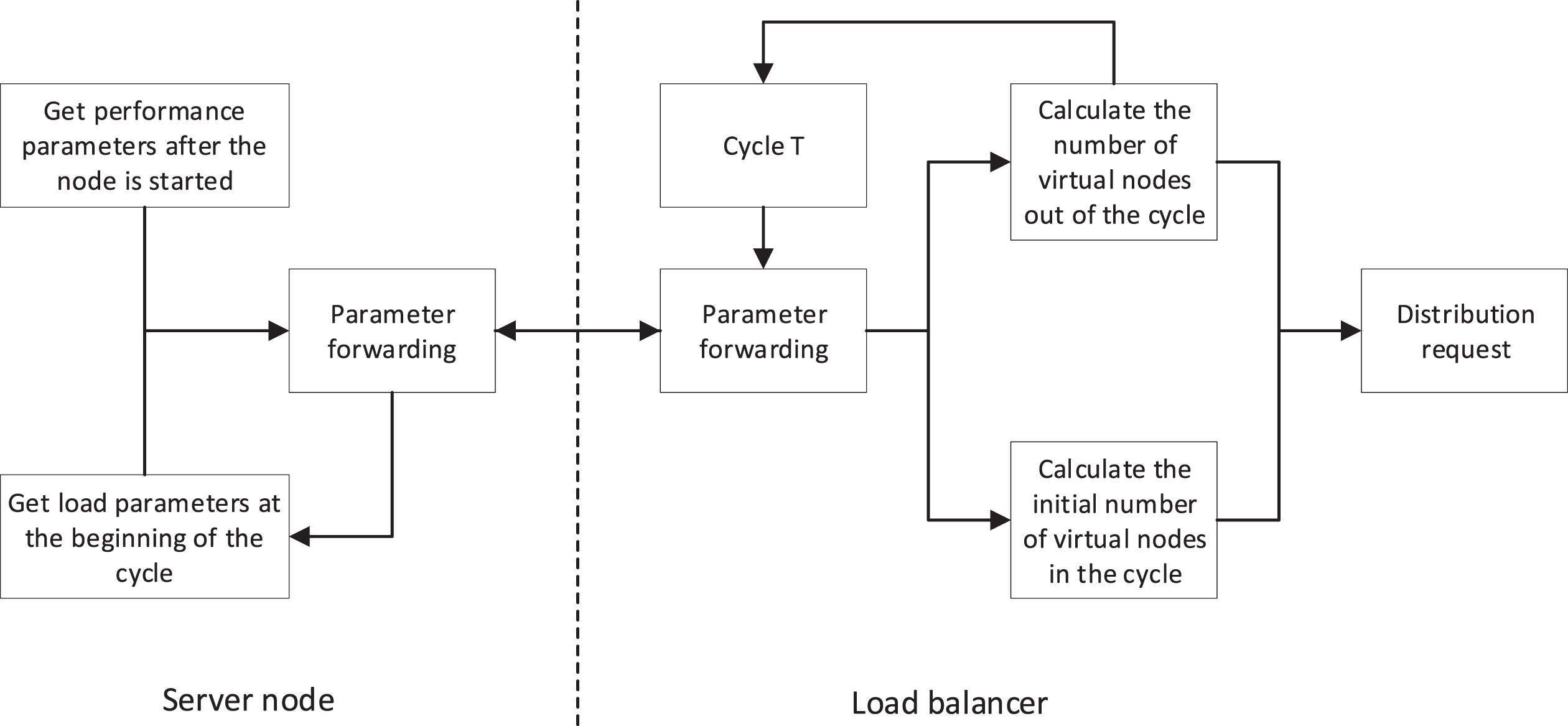
Overall design of dynamic consistent hash algorithm.
Experiment preparation
The tested LVS cluster system consists of Nginx load balancing servers, switches and background servers. The background server virtualizes many server nodes, and one of the physical servers serves as the test client.
A cluster load balancing algorithm based on dynamic consistent hash, which contains some changing parameters, mainly including performance weight vector [x1, x2, x3], load parameter vector [w c , w m , w d ], cycle T, number of virtual nodes n, and so on. Before experimenting, the optimal values of these parameters need to be determined.
Because the project targeted by this algorithm is developed based on the B/S platform, the request content mainly includes dynamic content and static content. Dynamic content mainly depends on the processing of the CPU. The content is mainly cached in memory. And the degree of dependency between CPU and memory is greater than the disk I/O rate. Refer to the above-mentioned CPU and memory ratio is relatively large, so [x1, x2, x3] is set to [0 . 4, 0 . 4, 0 . 2] in the experiments in this article. The load parameter setting needs to consider that the number of virtual nodes within and outside the cycle fluctuates within a certain range to ensure the stability of the algorithm. According to the formula (2), L
i
is to ensure that the variation within and outside the cycle is within a fixed range, and L
i
is calculated to change around a value of 1. Push to get the formula:
Set the load parameters L (C
i
), L (M
i
), and L (D
i
) to calculate the load when the formula is:
According to the performance vector [x1, x2, x3] is [0 . 4, 0 . 4, 0 . 2] and the load parameter vector [w c , w m , w d ] is [0 . 8, 0 . 8, 0 . 4] by calculating.
The setting of the number of virtual nodes n needs to consider the number of virtual nodes in the cycle and the number of virtual nodes outside the cycle. The number of virtual nodes outside the cycle is related to the cycle T. The algorithm in this paper refers to the WLC algorithm and sets the cycle to 5s. T = 5s to test the number of virtual nodes n. The choice of n value determines the load uniformity of the LVS cluster. A larger n can cut the hash ring more uniformly and make the load better. However, if n is too large, the load calculation pressure will be reduced, and the cluster throughput will decrease. If n is small, the hash ring will be cut unevenly, and the load balance will not be uniform. By learning other consistent hash algorithms, the general empirical value of the number of virtual nodes corresponding to the server node is between 120and260. This range can effectively ensure the load balancing effect of the cluster. By comparing the experimental results, as shown in Fig. 5, the peak value of the maximum throughput appears between 160and180. In this paper, 170 is selected as the optimal value of the cluster load balancing algorithm based on dynamic consistent hash, and it is used to test request response time and throughput.
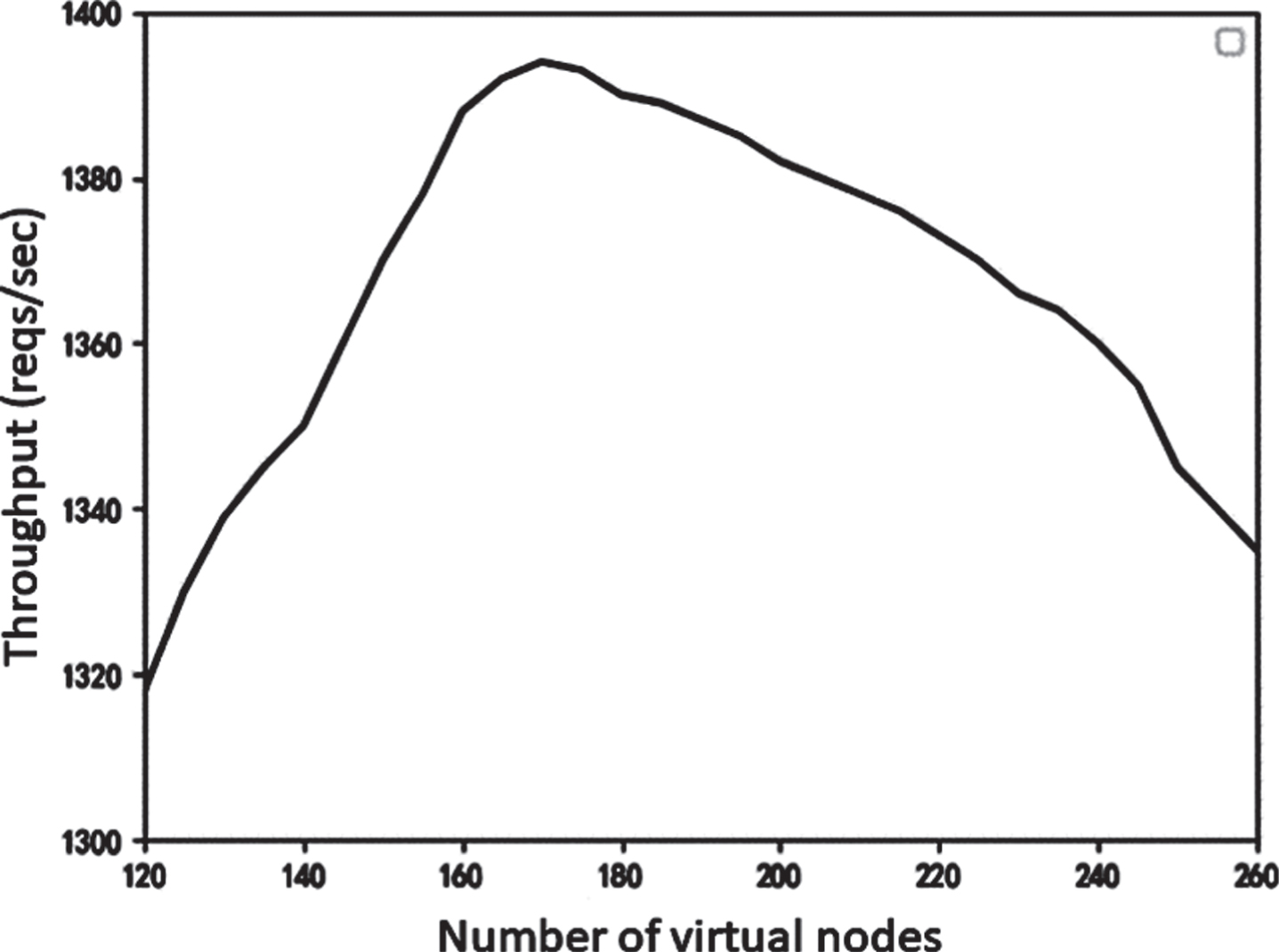
Throughput of virtual nodes.
Consider the setting of the cycle T. If the cycle T is too small, the load balancer frequently requests performance parameters and load parameters from the server, which is not a small burden on the load balancer and the server. If the cycle T is too long, the load balancer will monitor the server in time, which will cause uneven cluster load. In order to determine the cycle T, combined with the number of virtual nodes to set the experiment, by comparing the WLC algorithm, the cycle T range is between 2sto10s. In this paper, the relationship between the cycle T in the cluster and the maximum throughput of the cluster is tested. As can be seen from Fig. 6, when the time is from 2sto6s, the cluster throughput increases steadily and reaches a peak around 6s. When it is longer than 6s, the throughput gradually decreases. Therefore, in this paper, the cycle T = 6s is selected as the cycle of this algorithm. Through the comparison of the number of virtual nodes, the settings for the cycle and the virtual nodes are optimal.
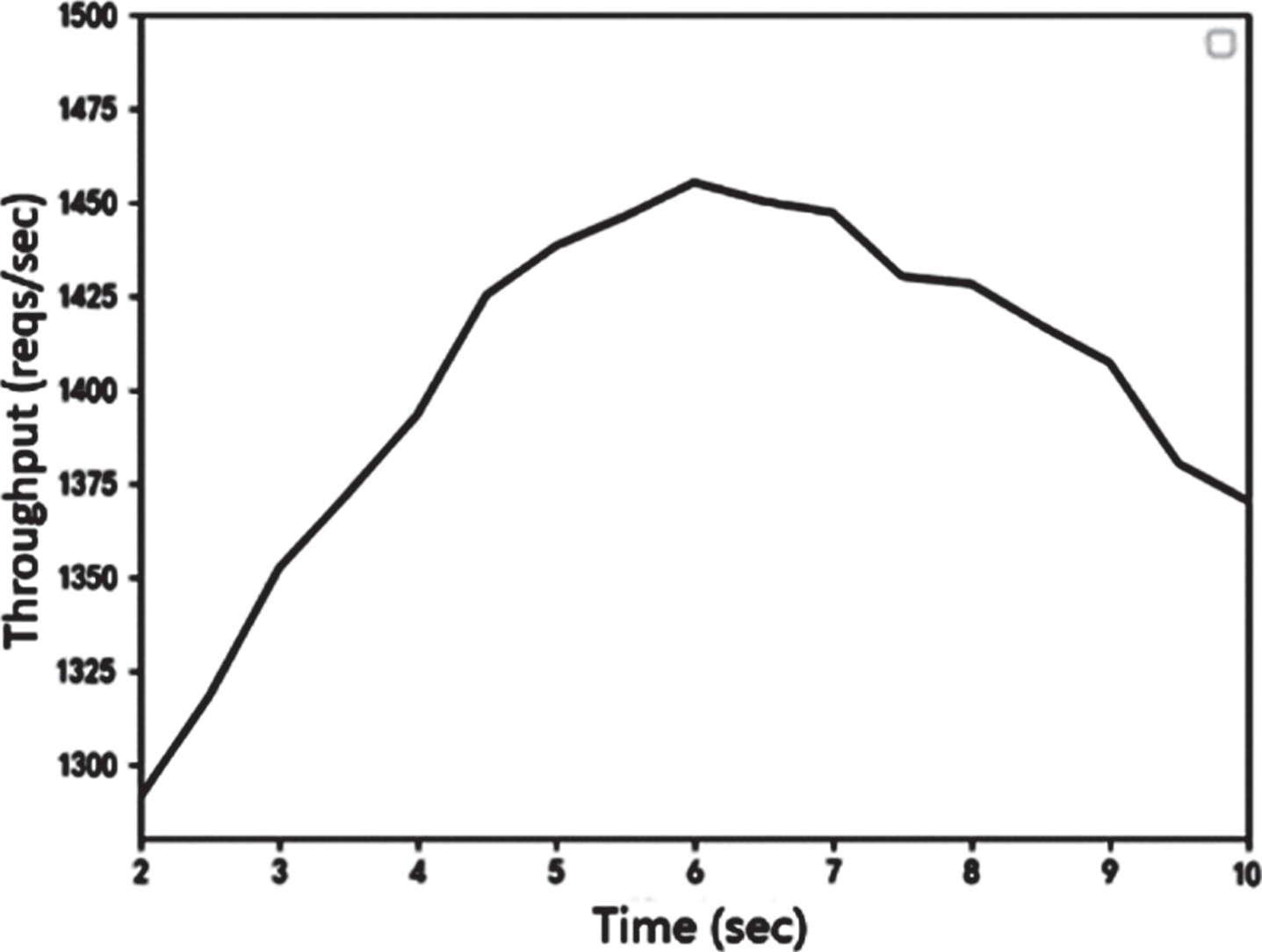
Cycle T and throughput.
The performance of LVS cluster load balancing is mainly reflected in two factors: cluster throughput and response time. The former is a manifestation of cluster processing power, while the latter’s response time directly affects the user experience. Two factors are the performance of the load balancing capability of the entire cluster, and also the embodiment of the load utilization of the cluster by load balancer scheduling. The following two sets of experiments are used to test the response time and maximum throughput of an LVS cluster using a cluster load balancing algorithm based on dynamic consistent hash. The weighted round-robin scheduling WRR and the weighted minimum connection WLC are compared. The response time is shown in Fig. 7. The horizontal axis is the number of requests per second (QPS) of the cluster. In this experiment, the average response time under a certain QPS is mainly tested. The response time is shown on the vertical axis. As shown in the figure, when the number of requests increases, the response time of the three algorithms also increases. When it is less than 1100, the response time of the three algorithms is basically the same. At this time, the user will not experience any delay. When the request volume is greater than 1100, the response time of the WRR algorithm and WLC algorithm starts to increase, but the increase of the response time of this algorithm is less than the WRR algorithm and the WLC algorithm, and its response time is the smallest. As the number of requests continues to increase, the gap between the response times of the three algorithms is increasing. From the above analysis, it can be concluded that when the number of requests is low, the response time of the algorithm in this paper is basically the same as the WRR algorithm and WLC algorithm. When the number of requests is high, the advantages of the algorithm are reflected, and the response time is less than that of the WRR algorithm and WLC algorithm. Therefore, the algorithm in this paper is better than other algorithms in response time to high concurrent processing of LVS clusters.
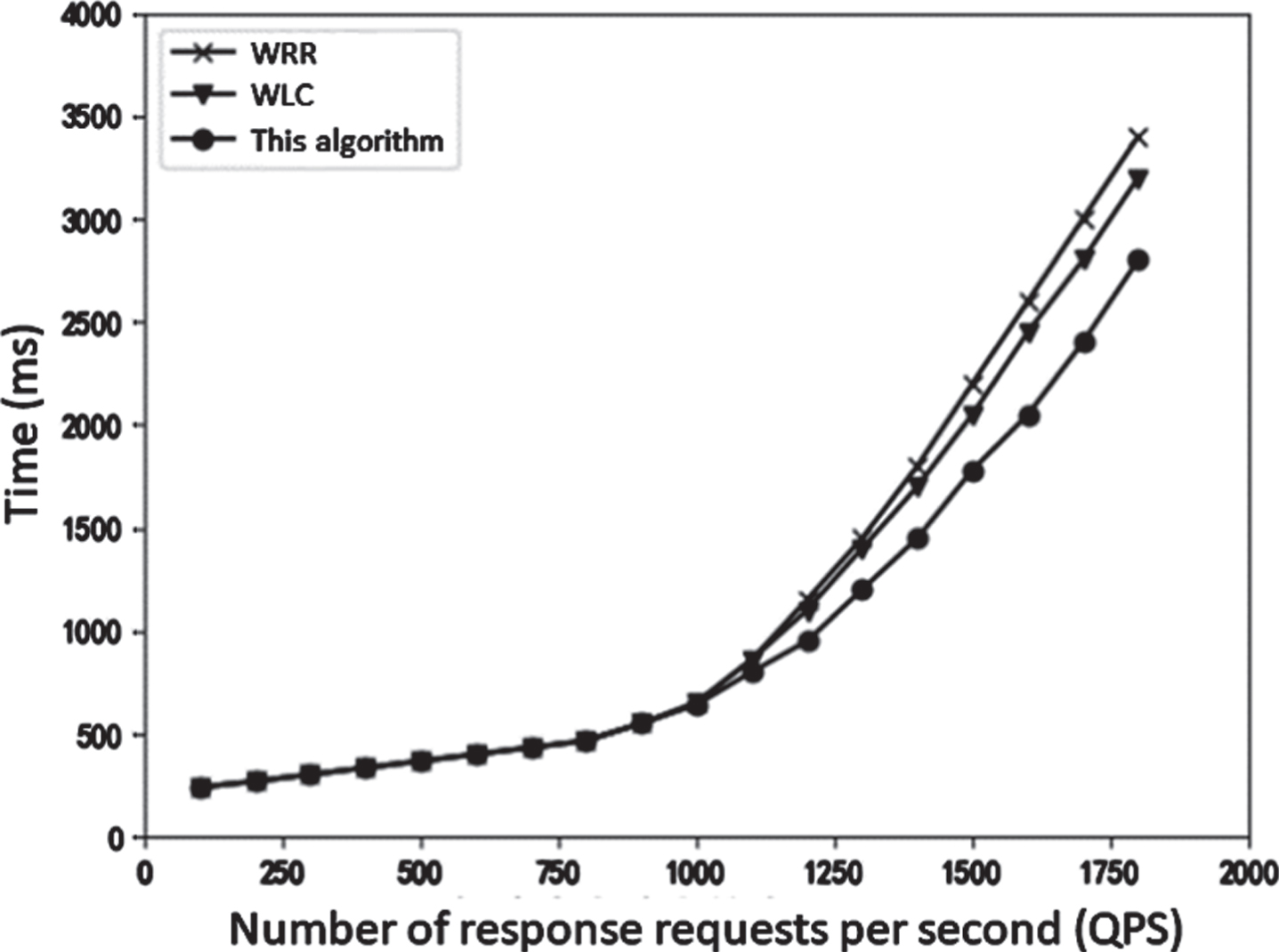
Response time.
Throughput, as shown in Fig. 8, there is a certain relationship between the throughput of a cluster and the number of servers. Generally speaking, the more servers in a cluster, the greater the throughput. This section compares the response of the three algorithms with different numbers of servers. As can be seen from the figure, the horizontal axis is the number of servers, and the vertical axis is the cluster throughput. The throughput of the LVS cluster under the three algorithms is directly proportional to the number of cluster servers. When the number of servers is less than three, the three algorithms perform basically the same. When the number of servers is greater than three, as the number of servers increases, the advantages of the algorithms in this chapter become apparent. The throughput growth rate of the WRR algorithm and the WLC algorithm slows down, and the gap with the algorithms in this chapter is getting wider. From the above analysis, it can be concluded that when the number of servers is small, the throughput of the three algorithms is basically the same. As the number of servers increases, the algorithm in this paper is better than the WRR algorithm and WLC algorithm in throughout.
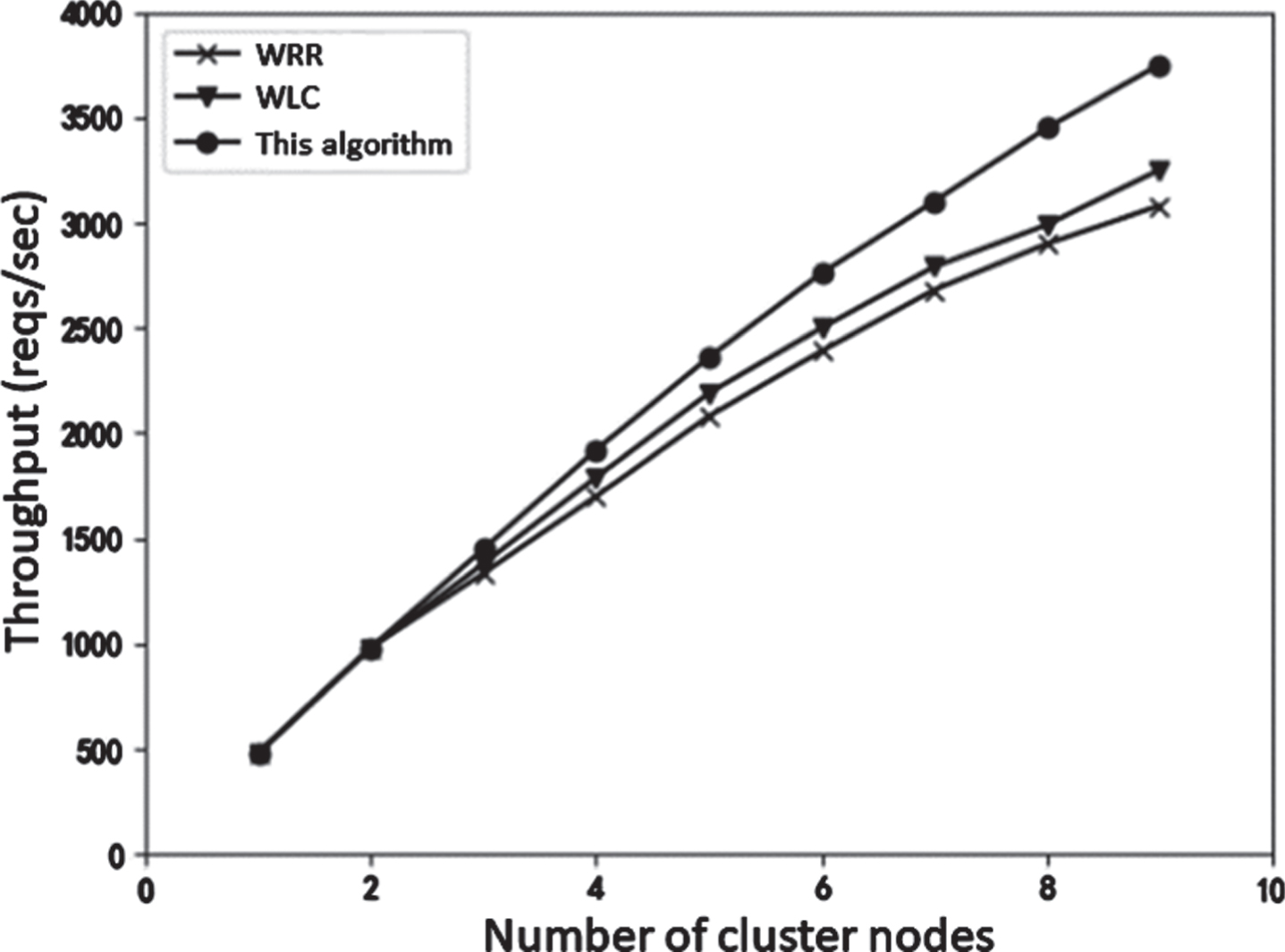
Throughput.
For the study of load balancing based on LVS cluster, this paper proposes a cluster load balancing algorithm based on dynamic consistent hash. By analyzing the performance and load parameters, the request process is divided into in-cycle and out-of-cycle. By setting up the LVS cluster system, the performance weights, load parameters, number of virtual nodes, and cycles of this algorithm are determined experimentally. Finally, the response time and throughput of the algorithm in this paper are compared with the WRR algorithm and WLC algorithm. The results show that the time and throughput of this algorithm are better than WRR algorithm and WLC algorithm.