
Abstract
Human communication is not limited to verbal speech but is infinitely more complex, involving many non-verbal cues such as facial emotions and body language. This paper aims to quantitatively show the impact of non-verbal cues, with primary focus on facial emotions, on the results of multi-modal sentiment analysis. The paper works with a dataset of Spanish video reviews. The audio is available as Spanish text and is translated to English while visual features are extracted from the videos. Multiple classification models are made to analyze the sentiments at each modal stage i.e. for the Spanish and English textual datasets as well as the datasets obtained upon coalescing the English and Spanish textual data with the corresponding visual cues. The results show that the analysis of Spanish textual features combined with the visual features outperforms its English counterpart with the highest accuracy difference, thereby indicating an inherent correlation between the Spanish visual cues and Spanish text which is lost upon translation to English text.
Keywords
Introduction
Multimodal sentiment analysis is a technique that offers a new dimension to the traditional text-oriented sentiment analysis by taking into consideration different modalities like visual data, audio data, etc. Multimodal sentiment analysis has become a crucial topic of research that aims to solve and analyze problems that fall into an array of disciplines. A variety of frameworks, methodologies, and techniques have been designed for such analysis that aims to leverage the data from multiple modalities to infer the context and predict the underlying individual sentiment using a more diverse technique of emotion recognition.
People hailing from different cultural and linguistic backgrounds are accustomed to varying gestures and expressions (both spoken and unspoken) [1], which may hold completely different meanings in a cultural setting removed from their native one.
However, even when an individual learns the language prevalent in this new cultural setting, the expressions and non-verbal cues learned in their original cultural setting will inevitably permeate into their overall speech and mannerisms. This can have a significant impact on sentiment analysis, which is essential for many global product-based companies that continuously analyze and respond to customer feedback and reviews [2].
Previous work has also shown how multimodal analysis of video reviews, due to their natural flow, is a more effective way of opinion collection as compared to textual reviews alone [3]. Consider a person with their first language as language A who records a review in language B; however, the visual cues the person adopted while speaking language A also make their way into this recording. Traditional analysis methods will perform multimodal sentiment analysis on this recording with reference to both textual and visual features corresponding to language B, while overlooking any non-verbal cues pertaining to language A. The proposed work studies a corollary where textual features of language B and non-verbal cue features of language A are analyzed together in an attempt to find the variation in the results which can then be extrapolated to the initial situation, thereby providing useful insight into the impact such a cultural shift in non-verbal cues can have on multimodal analysis.
Experimentation in the proposed work augments the power of Open Face [4], a state-art-the-art facial feature extraction toolkit to extract features from the video at specific timeframes. The extracted facial features are combined [3] with the English and Spanish speech textual features one at a time, and classification models are employed to analyze the results of sentiment analysis with two modes.
The paper is organized as follows: In Section 2, related work done in both the psychological and technical perspectives are discussed in detail. Section 3 introduces details of the approach implemented to obtain the results in the proposed work in a stage-wise manner. Sections 4 and 5 conclude with a thorough discussion of the results obtained and the future implications of the same, respectively.
Related work
Veronica Perez-Rosas [3] experimented with the addition of video and audio features to perform multimodal analysis at the utterance level. The paper employs the Computer Expression Recognition Toolbox (CERT) tool for extracting facial features from the raw video [5]. The results prove that the addition of visual modalities allows us to better grasp the sentiment of the reviewer as compared to the use of just textual patterns.
Benjamin D. Thomas [6] investigates facial mimicry responses of bilingual English-Spanish speakers to study the differences in their responses, and the results showed that bilinguals for whom Spanish was the first language were overall more expressive than their English counterparts and were more likely to mimic facial expressions when stimuli were primed with English. There was also a difference in the emotion mimicked by both groups - Spanish L1 bilinguals were more likely to mimic happiness in English primed expressions, while English L1 bilinguals were more likely to mimic surprise. Spanish L1 bilinguals were more likely to mimic anger in the English prime, and English L1 bilinguals were more likely to mimic anger in the Spanish prime.
Perlovsky, L. (2009) [7] developed a mathematical model to analyze an emotional version of the Sapir–Whorf hypothesis that suggests that differences in language emotionalities influence differences among cultures no less than conceptual differences. Perlovsky concludes that the emotional contents of language are indeed equally as important, if not more so than the conceptual contents of a language.
Erik Cambria, Devamanyu Hazarikab [8, 9] addressed the key issues concerning the problem of Multimodal Analysis and set a benchmark for further experimentation on the MOUD Dataset [3]. Yue Gu, Kangning Yang [10] present a deep multimodal network to classify utterance-level speech data using feature attention and modality attention and also provide a detailed comparison of traditional methods with deep learning methods on the features. Pradeep K. Atrey [11] conducted a detailed survey on the best fusion strategies for combining multiple modalities to achieve the best possible results and discusses the potential issues which can arise with these fusion methods. Praveen Kulkarni, Rajesh T M [12] gave a thorough comparative study of various methodologies that can be used to identify the human sentiments and presented the complexity in classifying the human facial expression.
Chen Xi [13] proposes a novel method for data extraction and training a multimodal sentiment analysis model based on a multi-head attention mechanism. The technique achieves 90.43% accuracy on the MOUD dataset. S. Poria [14] makes use of deep convolutional neural networks for extracting visual and textual modalities from the dataset. A multiple kernel learning classifier is trained using these extracted features.
Research material and methods
Dataset
The Multimodal Opinion Utterances Dataset (MOUD) constitutes videos of people reviewing an array of different kinds of products in Spanish [3]. Each utterance in the video has been fetched and is associated with a sentiment. Each video thus has a CSV file with timestamps (start time and end time), text fetched at utterance level, and the corresponding sentiment annotation associated with that text as the features of the dataset. An overview of the text data is shown in Fig. 1. Each utterance in a video has been labelled as positive (1), neutral (0), or negative (–1), but for conducting experimentations and analysis, the proposed work will be working with only the utterances with positive and negative sentiments [3]. Figure 2 illustrates a brief representation of the multimodal extraction process on a single video of the dataset.

Sample utterance-level annotations.

Multimodal extraction.
In the first stage of multimodal sentiment analysis, a single modality is used, which is the textual or linguistic features [15] to classify the sentiment expressed by the video reviews. The same classification models of XGBoost and Random Forest [16, 17] are run for both the Spanish and English textual features. Upon translation, the dataset appears, as shown in Fig. 3.
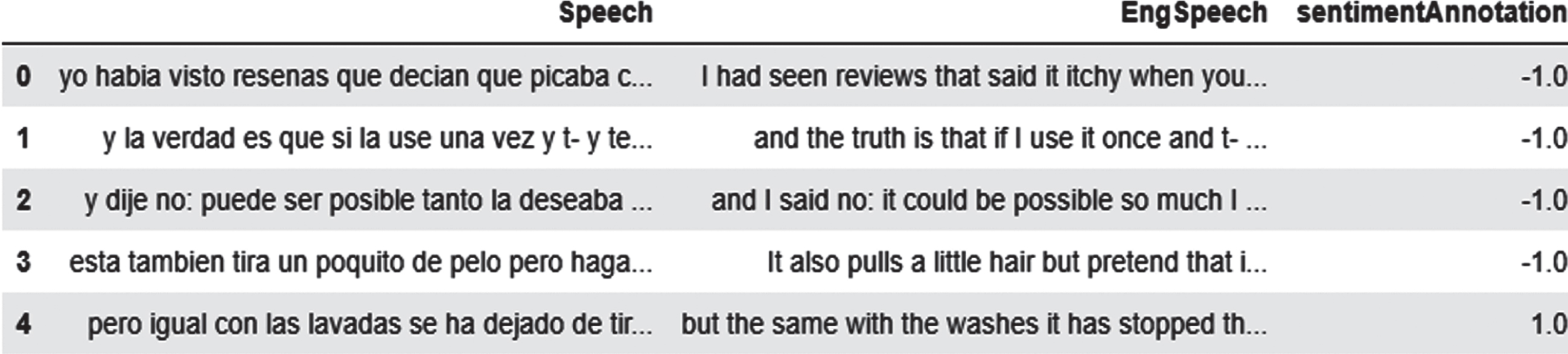
Sample Utterance-level annotations in Spanish and Translated English Text.
Both sets of textual data are pre-processed similarly. Any unwarranted HTML tags, non-alphabetic characters, and stop words of the respective languages are removed. All the text is also converted to lowercase for uniformity and simplicity. The next step is to vectorize the textual data in English and Spanish, respectively, using a Count vectorizer as well as a Term Frequency-Inverse document frequency (TF-IDF) [18] vectorizer with lemmatization [19].
The number of features obtained after the completion of all pre-processing steps is given in Table 1.
Comparing Feature Size of each pre-processing implementation for text modality
Comparing Feature Size of each pre-processing implementation for text modality
Initially, five different classification models [20], namely - Logistic Regression, Decision Tree, XGB Classifier, Random Forest and Support Vector Classifier [21] for both the Spanish and English dataset were made and run on the Count vectorized and Tf-Idf vectorized features [15, 20] respectively. For the purpose of this paper, only the accuracies for the Random Forest and XGB Classifier models with the Tf-Idf Vectorizer applied have been recorded.
Sentiment analysis using facial features
In the second stage of the proposed work of multimodal sentiment analysis, the second modality is modelled after extracting the facial features from the videos.
Data extraction
Facial Features of an individual can provide a great deal of information about his/her sentiment, and they can also be used to complement the textual data to provide a more consistent and accurate model performance. The proposed work augments the power of Open Face [4] tool, a state-of-the-art facial feature extraction algorithm. The tool lets enable automatic extraction of the following features: Facial Landmark Features: location of 2D and 3D facial landmarks in pixels. Eye-gaze estimation: Gaze direction vector of the eyes in the world, location of 2D and 3D eye region landmarks in pixels. Facial action units: They are a way to describe human facial expression, the tool detects the presence and intensities of the 18 facial action units associated with a human face [22]. Head Pose Data: Extracts the location of the head.
The OpenFace algorithm is run on each video, and it extracts relevant facial features at the corresponding timestamps. Graphical depictions of the data extracted from a single input video are shown in Figs. 4 and 5.

Time Series Plot of Facial Action Unit Prediction of the Face Detected.

Graphical Depiction of gaze movement extracted from input video.
Upon running the facial feature extraction algorithm on every video of the dataset, the mean of the features extracted for each utterance over all the valid frames is calculated. Each such frame with the averaged feature values over the utterance period is associated with the sentiment corresponding to that particular utterance [3].
A total of 709 facial features are extracted for every video by the OpenFace algorithm, this prompts the need for efficiently selecting the best and the most relevant features that could improve the model performance. The proposed work employs the Recursive Feature Elimination Algorithm [23, 24] for Feature Selection. In the Recursive Feature Elimination Algorithm, attributes are recursively removed, and a new model is built with the new feature set. The feature set, which gives the highest accuracy score, is retained for further modelling.
Implementation for facial features sentiment analysis
The data obtained after pre-processing is trained on a series of supervised classification algorithms, and the model that consistently gives the best accuracy score is selected as the final model [25]. Logistic Regression, Decision Tree Classifier, Random Forest Classifier, XGBoost Classifier, and Support Vector Classifiers are used for the experimentation.
Sentiment analysis of text and video fused data
In the third and final stage of the multimodal sentiment analysis, multimodal sentiment analysis is performed by using both types of modalities - text and video data [3, 27]. The same classification models of XGBoost and Random Forest are run for both the merged Spanish and English textual + facial features.
Implementation for multimodal sentiment analysis
The text data frame and the refined video data frame are horizontally stacked at point of overlapping utterances [3, 26]. The data obtained after pre-processing is trained on a series of supervised classification algorithms [2], and the model that consistently gives the best accuracy score is selected as the final model. The experiments were conducted on the fused video and text data with both English and Spanish Texts, which are vectorised by the tf-idf vectorizer. The results obtained are compared and thoroughly analysed to make a further deduction on our hypothesis. Figure 6. illustrates an overview and pipeline of the complete implementation. Each step of the pipeline has been covered in detail in sections 2 through 4.

Detailed Pipeline of the Implementation.
The proposed methodologies are run on the MOUD Dataset to analyze and visualize the results to make further conclusions. The dataset consists of 80 product review videos. Each utterance in the video has been extracted and is associated with the sentiment (positive or negative). All the text utterances at various timestamps for every video are merged and constitute the text database, which upon pre-processing will be fit for modelling.
Facial Features are extracted from the video using the OpenFace Toolkit, and these features are later associated with the utterance sentiment available in the text database. This forms the video features database, which is later fused with the text database at a common utterance point to create the multimodal database. All of these databases act as input to the classification algorithms used, which are Logistic Regression, Decision Tree, XGB Classifier, Random Forest, and Support Vector Classifier. Accuracy and F1 Scores are used as metrics to determine the goodness of the classification models.
We select the scores obtained from experimentations run using Random Forest Classifier and XGBoost Classifier for the input data as these two ensemble classification algorithms give a consistent and comparable performance on databases of all modalities, proving their robustness while working with both text and numeric data. Equations (1), (2), (3) and (4) indicate the metrics used to assess the models.
Accuracy and F1 Scores are used to prove the efficacy and robustness of the experimentations.
This section is dedicated to analyzing the results obtained at each stage and their contribution to the final conclusion.
In the first stage where sentiment analysis is performed with the single textual modality, the translated English textual features performed better than the original Spanish textual features, after both sets of features were subjected to the same pre-processing, vectorization and lemmatization. The highest difference in the accuracies was displayed by the Random Forest Model, which gave a difference in scores of 0.056 or 5.6%. A tabular depiction of the results obtained is shown in Table 2.
Comparing Accuracy Scores of the experiments on the text data
Comparing Accuracy Scores of the experiments on the text data
In the second stage, sentiment analysis was performed with the single visual modality comprising 709 facial features extracted from the videos. The initial experimentation was run on all of these features without any feature selection. This was followed by performing the experiments on the feature set reduced by Recursive Feature Elimination. The RFE (Recursive Feature Elimination) algorithm was run on an array of feature set size and the feature set size, giving the best classification goodness is selected for the comparison. The best accuracy scores are obtained for models trained on data with a feature size of 500. The models that were trained on the refined feature set performed better than the models which were trained on the original feature set, with the highest accuracy score of the two differing by 2.2%. Bar plot showing the performance of different algorithms is shown in Fig. 7.

Model Accuracy Scores for Facial Features.
In the final stage, where both the textual features and visual features were combined to perform dual-modality sentiment analysis, the Spanish integrated features outperformed the English integrated features, which is in contrast to the results obtained in both the preceding stages. The highest difference between the two can be seen in the XGB Model with the difference in the accuracy score being 0.044 or 4.4%, whereas the Random Forest Model shows an accuracy score difference of 0.033 or 3.3%. The accuracy scores obtained are given in Table 3 and Fig. 8.
Comparison of accuracy scores among different levels of modalities
A noteworthy fact is that when combined with the visual cues, the original Spanish data performed much better as compared to the translated English data, as depicted in Fig. 8. For the Random Forest Model, not only did the Spanish (T + V) analysis overcome the initial difference of 5.6% in scores as seen in the single modality textual analysis but even scored better than its English counterpart by a margin of 3.3%. Similarly, in XGBoost, the Spanish combined model overcomes the textual analysis difference of 4.4% and goes on to outperform the combined English model by 4.4%.
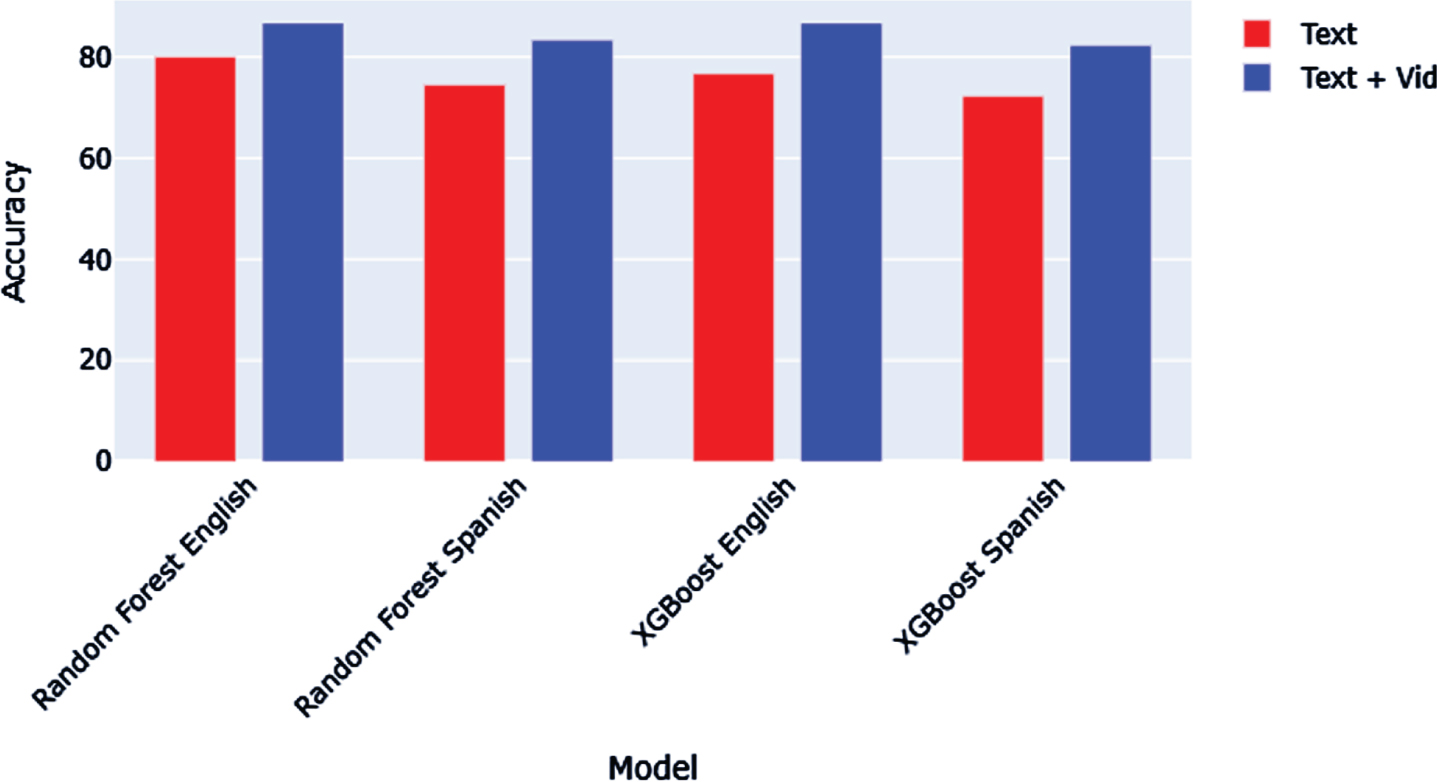
Model Accuracy Scores.
The F1-scores obtained for the same models are given in Fig. 9. The F1 Scores obtained for the models give further confirmation of the results obtained by the accuracy scores, thus proving the robustness of our proposed work. The models trained on multimodal data performs significantly better in terms of the F1 Score than the models trained on just text data, and the Spanish integrated features outperformed the English integrated features, which is in contrast to the results obtained in both the preceding stages.
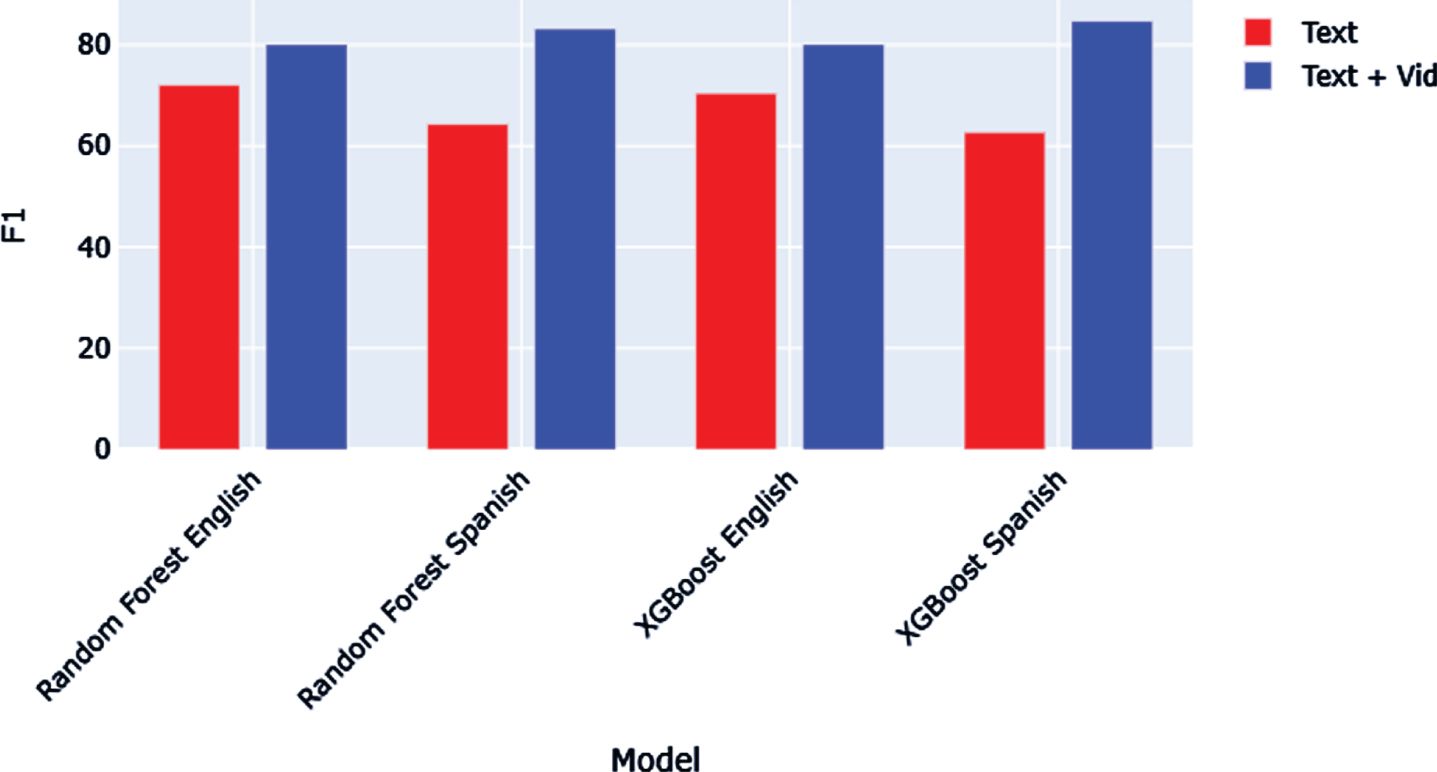
Model F-1 Scores.
To test the hypothesis that classification performance of models trained on multimodal data is statistically significantly better than the classification performed for models trained on just text data, an Independent samples T-test [28] is conducted to compare model performance for a model trained on data with visual features and model trained on data without visual features. K-fold cross-validation [29] with 10 folds for the models is conducted to create less biased models as the method ensures that each data point or observation in the original dataset has the likelihood of appearing in the train and test sets. This method does justice to each data point in a dataset of limited size while creating the model. 10-fold cross-validation is thus employed to create a population of accuracy scores for models trained on 10 different and unique data samples of the original dataset. The test was performed on the models with the best accuracy scores for both English and Spanish Data. This is followed by Student’s t-test [30] to check if the mean accuracy of the two models trained is statistically significant, thereby rejecting the null hypothesis that states that there is no significant difference between two distributions.
There was a significant difference in the scores for XGBoost Classification model trained on Spanish text + visual data (Mean = 0.805, Standard Deviation = 0.061) and model trained on just the Spanish text corpus (Mean = 0.667, Standard Deviation = 0.053), giving a high T-test t(18) = 5.176 and a very low p-value = 0.000065. These results suggest that visual facial features do have a significant impact on the sentiment analysis and the performances of the models increase if text data is merged with visual data.
Same experimentation is performed on models trained on translated English Text Data. Once again, a significant difference is observed for scores for XGBoost Classification model trained on English text + visual data (Mean M = 0.78, Standard Deviation = 0.057) and model trained on just English text corpus (Mean M = 0.707, Standard Deviation = 0.071), giving a high T-test t (18) = 2.4 and a low p-value = 0.027. Further strengthening the importance of visual data for modelling and the robustness of the technique incorporated.
Discussions
From the results obtained above, it becomes evident that when analysed using text alone, the English translated speech models outperform the models run on the original Spanish speech. However, when run along with the features extracted from the video, the Spanish prediction models immediately shoot up in performance, while the English models perform poorly in comparison.
The results obtained by addition of visual modalities allowed the classification models to get a better grasp and understanding of the underlying sentiment which was not possible with the use of textual data alone, thus complying with the results of works by Veronica Perez-Rosas [3] and Erik Cambria, Devamanyu Hazarikab [8, 9].
Since all the pre-processing steps followed are the same for both the textual feature corpora and the merged visual features for both languages remain the same, we can extrapolate that the disparity in the accuracy arises due to an inherent correlation between the facial feature cues and the textual features. This goes to show how, despite relaying the same sentiment as its Spanish counterpart in terms of speech, the English model is unable to synchronize with the facial feature cues that accompany the original Spanish speech. Thus, verifying the impact that cultural shift can have on non-verbal cues like facial expressions as demonstrated by Benjamin D. Thomas [6], which can highly influence the sentiment predicted by the classification models.
The proposed work is successful in exhibiting the impact of a cultural-shift on multimodal analysis. The experiments were able to establish the influence of non-verbal cues and how the variation that is obtained by incorporating facial features extracted from the videos during utterance level with the uttered text can help improve the result of sentiment analysis and how it can be used to study the influence of cultural shift on Multimodal sentiment analysis.
Future potential
The proposed work leaves room for a lot of future research. For starters, a study can be conducted to evaluate this cross-cultural impact using different datasets and different language corpora. This can help affirm the extent of the impact on sentiment analysis when translation takes place between any two selected languages. With a large enough dataset, it is also plausible to create a comprehensive list of non-verbal cues across different cultures that can then be stored against the particular facial features used to express them. We can then isolate these cues during similar impact analyses and quantitatively determine their effect on the accuracy levels. If this information is obtained, gathered over a reliable number of samples, it can potentially be included in multimodal sentiment analysis as a corrective measure to prevent such error in the accuracy score that might be caused in situations where the language of speech isn’t the speaker’s primary tongue. The proposed work can also be used to study the impact of machine translation of video, audio or text data on the overall sentiment.
Additionally, audio features can be added as the third mode in the multimodal analysis and studied separately for its impact on accuracy in terms of accentual changes from region to region, but this is an entirely separate study in its own right.
Conclusion
The impact that non-verbal cues quantitatively on the results of multimodal sentiment analysis. The experiments in the proposed work show that the performance of multimodal models trained on Spanish textual features combined with the visual facial features outperforms its English counterpart with the highest accuracy difference between the two implementations being 4.4%, thereby indicating the impact and influence non-verbal cues have on sentiment analysis and how cues extracted and their meanings differ with culture and language. The paper also showed that multimodal models outperform the models trained on single modalities with the best model achieving an accuracy of 86.66% on the multimodal data, 74.44% on single-modal text data and 82.22% on single-modal video feature data.