
Abstract
Legal practitioners analyze relevant previous judgments to prepare favorable and advantageous arguments for an ongoing case. In Legal domain, recommender systems (RS) effectively identify and recommend referentially and/or semantically relevant judgments. Due to the availability of enormous amounts of judgments, RS needs to compute pairwise similarity scores for all unique judgment pairs in advance, aiming to minimize the recommendation response time. This practice introduces the scalability issue as the number of pairs to be computed increases quadratically with the number of judgments i.e., O (n2). However, there is a limited number of pairs consisting of strong relevance among the judgments. Therefore, it is insignificant to compute similarities for pairs consisting of trivial relevance between judgments. To address the scalability issue, this research proposes a graph clustering based novel Legal Document Recommendation System (LDRS) that forms clusters of referentially similar judgments and within those clusters find semantically relevant judgments. Hence, pairwise similarity scores are computed for each cluster to restrict search space within-cluster only instead of the entire corpus. Thus, the proposed LDRS severely reduces the number of similarity computations that enable large numbers of judgments to be handled. It exploits a highly scalable Louvain approach to cluster judgment citation network, and Doc2Vec to capture the semantic relevance among judgments within a cluster. The efficacy and efficiency of the proposed LDRS are evaluated and analyzed using the large real-life judgments of the Supreme Court of India. The experimental results demonstrate the encouraging performance of proposed LDRS in terms of Accuracy, F1-Scores, MCC Scores, and computational complexity, which validates the applicability for scalable recommender systems.
Introduction
Advancement in the information age forms an opportunity for Legal institutions and fraternities to publish various kinds of Legal documents online. Internet-based various digital repositories manage the different types of Legal documents such as Precedents (Judgments), Constitutions, Various Codes, Laws, Acts, Rules, and Regulations, etc. Previously delivered judgments are the essential source of law to derive the decision in the judiciary system (i.e., the Court). Indian judiciary system follows the belief of “stare decisis” that is “similar facts, and circumstances should be treated in a similar way”. Thus, judicial decision-makers are bounded to consider and follow interpretations of prior judgment(s) as per concern, if the present case and prior judgment(s) have comparable arguments, facts, circumstances, and issues [1–3]. These prior judgments are also known as a precedents, which is interchangeably used with the judgment in this research. Judgment is a textual document discussing the arguments, facts, circumstances, issues, and decisions associated with the particular case. Referential information such as previous judgments and codified statutes related to particular issues are also embedded in judgments. There are various types of case matters (case type) for which judge(s) transcribes the judgment such as Criminal matters, Civil matters, Constitutional matters, Taxes matters, etc. To prepare the strong, convincing, strategic, and supportive arguments for the ongoing case, Legal professionals requires to investigate and analyze relevant previous judgments and their associated Legal issues [4]. The relevant judgment identification process is complex, domain knowledge-, time-, and labor-intensive. These critical challenges strongly demand an efficient and effective Legal Document Recommender System (LDRS) to automate the process.
In recent years, existing frameworks utilize referential and/or textual information to capture the relevance among Legal documents. Primarily, text-based approaches [1, 5] aim to identify semantically relevant Legal documents, by computing the Cosine similarity score between respective document vectors. Thus, Legal documents are required to be transformed efficiently into fixed-length and real-valued vectors using vectorization techniques such as TFIDF [4], LDA [6], Word2Vec [7, 8], and Doc2Vec [9]. Whereas, Reference-based approaches [4, 11] construct a citation network from the referential information to apply the network-based similarity measures like bibliographic coupling, co-citation analysis, node embedding. Hybrid approaches [2, 13] enrich similarity measures by integrating text- and reference-based approaches.
The LDRS performs recommendation of relevant Legal documents given a query document by computing pairwise similarity scores between the query document and rest of documents in the corpus. However, the major challenge lies in handling the massive amount of presently available Legal documents, which are also exponentially growing. Accordingly, LDRS should implement the recommendation as simple lookup of priorly (i.e., offline) computed pairwise similarity scores for all unique pairs [14]. Consequently, it possesses the scalability issue since computing the number of pairwise similarity scores increases quadratically with the number of documents. There is a total
This research focuses on the scalability issue that occurres due to the computation of pairwise similarity scores for a massive amount of judgments. It is observed that most of judgments hold strong relevance only with a small number of other judgments (e.g., tens, hundreds, or thousands). Thus, there is no significance to compute the similarity score for insignificant pairs consisting of no or trivial relevance between judgments. However, judgments with comparable case matters could hold strong relevancy compared to judgments of other case matters. Also, a group of judgments with comparable case matters shares a similar kind of associated citations. So, to overcome the issue of scalability, this research proposes scalable LDRS that performs graph clustering on the citation network to form clusters (i.e. groups) of referentially relevant judgments. Pairwise similarity scores are computed for the individual cluster instead of the entire corpus. This way, similarity scores are only computed for significant pairs consisting of strong relevance between judgments. This practice considerably reduces the number of pairs to be computed, which saves the vast amount of computational resources. Also, the proposed LDRS effectively captures the semantic relevance among judgments (i.e., identifying textually similar judgments) within clusters.
To the best of authors’ knowledge, the proposed graph clustering based LDRS is an initial effort to reduce the computational complexity in the Legal recommendation system, specifically to the Indian judiciary system. The major contributions of the proposed work are abridged as follows: This research work presents the scalable LDRS to effectively and efficiently capture the comprehensive relevance among judgments, using textual and referential information. The proposed LDRS applies a fast and scalable Louvain approach [15, 16] on the citation network to form clusters of referentially similar judgments. Existing work [2, 4] constructs the sparse citation network of judgments only. In contrast, present work strengthens the citation network by incorporating codified statute and laws along with judgments. This research computes pairwise similarity scores for each cluster instead of the entire corpus to make the LDRS scalable. This practice computes the similarity score only for significant pairs while irrelevant pairs are not considered, which drastically reduces the computational complexity. The proposed LDRS employs Doc2Vec [9] to identify the semantically relevant judgments within a cluster. Doc2Vec transform the textual judgments into real-valued vectors such that semantically relevant judgments are in proximity in the vector space. Empirical analysis was performed using large number of real-life judgments of the Supreme Court of India
1
to evaluate the effectiveness of the proposed LDRS. Experimental results of graph clustering are validated by demonstrating excellent performance in terms of Accuracy, F1-Score, and MCC Score [17]. The proposed LDRS has also demonstrated a significant reduction in computational complexity to compute pairwise similarity scores as compared to the Brute Force approach.
The rest of the paper is structured as follows: Section 2 reviews the literature and related work. Section 3 presents an methodology of the proposed cluster based LDRS. Section 4 demonstrates the empirical analysis of the proposed LDRS. Finally, Section 5 summarizes the presented research work including challanges and future goal.
Literature review
This Section provides a brief introduction to the existing similarity analysis approaches. The brief discussion is also carried out on the recent document clustering approaches. The studies of two approaches named Doc2Vec and Louvain approach are also briefly described in this Section.
Similarity analysis
In the Legal domain, existing research is centered on similarity analysis using textual and/or referential information for recommendation of relevant document.
•
Kumar et al. [4] analyzed the lexical similarity that matches the string/lexical among text documents. Here, TFIDF was applied to the textual features for constructing the judgment vector space. However, it possesses challenges like sparsity, high dimensionality, and the inability to preserve the semantic [18]. Alternatively, semantic vector space modeling can enable a fruitful similarity analysis, which has motivated existing works to capture semantic relevance [1, 19–21]. LDA based topic modeling was utilized to find relevant Legal documents given query [5], which may lack in capturing some of hidden semantic features from long textual documents [22]. Word2Vec and Doc2Vec utilize contextual information which can prominently help to preserve semantic relationships among words or documents [23]. In an experimental study of Mandal et al. [1], Doc2vec has demonstrated the best performance when whole judgment text considered as a single document, in terms of Correlation and Accuracy referenced to the human expert similarity score.
•
The other predominant source of information is cited references such as Statutes, Acts, and previous judgments. Citations are significant features to capture the qualitative relevance since it implies direct associations with citing documents [24]. Thus, citation network is formed using referential information where each node signifies the Legal document, directed edge from citing node (i.e., A) to citation node (i.e., B) signifies that document A has cited the document B. Existing works have adopted various network-based retrieval techniques from the field of Scholarly Article citation network [25]. Kumar et al. [4] proposed an approach to identify similarity among Indian judgments, applying Bibliographic Coupling [26] and Co-Citation [27] analysis to the judgment citation network. Koniaris et al. [10] utilized the structural and statistical information (i.e., degree) of the network to capture the relevance among European Union Legal documents. However, network-based techniques’ performance and utility are purely dependent on how strongly a network is connected. The majority of judgments have only a few citations forming a sparse citation network [1].
•
Kumar et al. [2] improved the performance using hybridization of textual and referential information. Authors formed a citation network using previous judgments and “paragraph links ”. There exists a paragraph link between two judgments, if the similarity between TFIDF vectors of two paragraphs from different judgments is beyond the threshold value. The hybrid approach has demonstrated a significant improvement in performance when compared to standalone approaches [4]. Raghav et al. [3] designed an approach to catch the relevancy using citation network, paragraph links, and both, followed by performing the clustering. Leibon et al. [12] coupled a network-based approach with the textual representation technique like LDA for US Supreme Court opinions. With the advancement in network representation techniques, Sugathadasa et al. [13] designed an approach to find similar legal documents using Node2Vec [28], a neural network-based graph embedding approach to represent nodes as dense feature vectors, and TextRank algorithm [29] for sentence similarity.
Document clustering
Document clustering is the practice of grouping up similar types (i.e., comparable in some way) of documents [30]. It has been extensively employed in the field of bibliometric [31] and Legal informatics [24, 32], where text and citations are main streams of information. Clustering based on the textual information considers the lexical or semantic feature matrix (i.e., vector space), derived using TFIDF, LSA, LDA, Word2Vec, Doc2Vec, etc. Subsequently, clusters can be prepared by applying traditional clustering methods (i.e., k-mean, hierarchical clustering) to the feature matrix [30]. Citation-based clustering considers document citations to model the citation network, where clustering is the practice of identifying the group of densely linked nodes which are sparsely linked with nodes of other groups. In recent years, network-based clustering techniques are increasingly getting consideration in the variety of research domains where information can be modeled in the network structure, such as social networking [33], bibliometric literature [34], epidemiology [35], and recommendations [36], etc.
Louvain approach and Doc2Vec
Louvain method [15] aims to maximize the modularity objective function, which measures the inside edge density of the cluster compared to the external edge density between clusters. A higher value of the modularity results in healthier partitioning, and smaller value results in the poor partitioning of a network. However, modularity maximization is an NP-Hard problem [37]. Louvain approach performs a greedy optimization-based heuristic to achieve rapid convergence. It is therefore an extremely scalable, fast, and effective solution for real-life large-scaled graphs. Zhao et al. [38] performed the comparative analysis of state-of-the-art graph clustering algorithms in terms of efficiency and effectiveness, over the various sizes of artificial networks wherein, Lovain approach emerged as the superior candidate resulting the best accuracy and computation time. It has been widely adopted in the field of bibliometrics and informetrics [39], and Legal information system [24, 40].
Doc2vec [9] is a document vectorization technique representing the arbitrary length of text (i.e., sentence, paragraph, document) as a low-dimensioned and real-valued vector. It is strongly developed based on the word embedding technique named Word2Vec, which represents a word as a semantically riched vector. Word2Vec is a shallow Neural Network (NN) that utilizes the contextual information (i.e., surrounding information of words) to learn the vector representation. It follows the belief of distributional hypothesis [41], summarized as “semantically similar words share a similar kind of contextual information”. So, vectors of such words are embedded in proximity in the resultant vector space. Inherently, Doc2Vec incorporates document vectors along with word vectors to learn semantic document vectors. This way, document vectors capture semantics during the learning of word vectors.
Research significant
Semantic relevance is captured by text-based approaches using vectorization techniques (TFIDF, LDA, Word2Vec, and Doc2vec) [1, 5]. Reference-based approaches [4, 11] uses direct or indirect citation relationships to capture the relevance among judgments. However, the performance of these approaches is dependent on the density of the citation network. Specifically for Indian judgments, existing works form the citation networks using only previous judgments as citations, which cause a very sparse network. Alternatively, Hybrid approaches [2, 13] are also proposed in the literature to improve performance at the cost of higher computational resources. A review of significant studies in this area found that they are centered on computing the qualitative similarity measure (i.e., how well relevance can be captured) among judgments aiming to enhance the correctness. While, in the recommender system, computing pairwise similarity scores (i.e., for all unique pairs) in priorly is also an essential process to achieve sufficient response latency at the time of querying. However, it possesses the scalability issues as the number of unique pairs grows quadratically with the increasing number of judgments. It is very expensive in terms of computing and memory due to the existence of an enormous amount of judgments. This problem has received very limited consideration in the existing Legal recommender system. To mitigate the above mentioned challenges, the next section provides an in-depth methodology of the proposed LDRS.
Proposed LDRS
Computing pairwise similarities is a computationally very expensive task due to quadratic complexity. To overcome, this research proposes a scalable LDRS that utilizes the Louvain approach to obtain clusters of referentially relevant judgments. Pairwise similarity scores are computed for an individual cluster instead of the entire corpus to prevent unnecessary computation. Within those clusters, Doc2Vec is utilized to identify semantically relevant judgments. The architecture of the proposed framework is illustrated in Fig. 1 and consists of three Phases: 1) Citation Network Clustering 2) Judgment Vectorization 3) Cluster based Pairwise Similarity score Computation (C-PSC). First Phase, Citation Network Clustering aims to form the citation network using citations on which graph clustering algorithm (i.e., Louvain approach) applies to decompose the network into clusters. Second Phase, Judgment Vectorization aims to generate semantic judgment vector space applying a prominent document embedding technique (i.e., Doc2Vec) on the judgment text. These two phases are independent of the order of their execution due to the use of a different type of information. Third Phase, C-PSC intends to compute pairwise semantic similarity scores for each cluster instead of the entire corpus. The detailed description of these phases is discussed in following subsections.
Citation network clustering
There are various types of case matters for which judgments were delivered. Specifically in the Indian judiciary system, these case matters could be categorized as Criminal, Civil, Constitutional, Taxes matters, etc. Judgments discuss the specific case matter(s) and also cite related citations such as previous judgments, Statutes, and Laws. It is observed that judgments hold strong relevancy with judgments having a similar kind of case matters as compared to judgments with diverse case matters. Even, a group of judgments having comparable case matters also share a similar set of associated references. This belief has motivated us to utilize the referential information for clustering judgments.
The judgment may refer to previous judgments and Statutes along with the specific article number or section number. This research extracts all the referential information to form the citation network. However, some references may be utilized several times at different places in judgment, which does not have any significance in citation networks. Hence, this type of repetitive citations are eliminated. Earlier works [4] have considered only previous judgments as citations that forms a very sparse network. However, the present work considers previous judgments, Statutes, Laws, specific articles, and specific sections as citations to strengthen the density of the citation network.
Let us consider G = (V, E) is a citation network (i.e., directed graph), where V signifies the set of vertexes {v1, v2, v3 . . . , v n } consisting n nodes and E signifies the set of directed edges. In citation network G, each node corresponds to the judgment or citation, and a directed edge v x → v y between node v x and node v y indicates that judgment v x referred citation v y . G does not have any two-way edge like judgment v x referred citation v y and citation v y referred judgment v x , and self-loop like judgment referred itself.
The proposed LDRS uses the modularity based Louvain approach to form clusters of relevant judgments in the citation network. However, modularity suffers from the problem called “resolution limit” that may not discover small-sized certain clusters even though clusters are clearly noticeable [16, 42]. In order to prevent the resolution limit, proposed LDRS utilizes the Louvain approach with improved modularity objective function upgraded with “resolution” parameter that provides certain flexibility to control the cluster size [15, 42]. Input to the Louvain approach is judgment citation network G = (V, E). It decomposes citation network into m clusters (C), where each group comprise of an assigned set of nodes (i.e., judgments), as shown in equations (1) and (2). This research eliminates all citation nodes (i.e., only keep citing judgments) from each group as they are insignificant for computing the pairwise similarity score.
This phase utilizes the textual information to capture the semantic relevance among judgments within each cluster. All raw formatted judgments are available in the form of textual files containing the headnote, temporal information, judge or bench name, publicizing court, judgment text, and other metadata. Generally, judgment text discusses several issues, facts, arguments, and decisions regarding the specific case, which are an essential source of information in relevance capturing. Accordingly, only judgment text is extracted by discarding all other inappropriate data using contextual rules. It is observed that there is a lack of linguistic and structural homogeneity in available judgments, due to the use of natural language and unavailability of predefined structure for transcription. So, the direct utilization of such judgments may result in performance deterioration. Moreover, the judgment text also contains noisy and useless data like stop-words, punctuations, whitespace, etc. The proposed LDRS performs following text pre-processing steps aiming to structure, standardize, and reduce the vocabulary of raw judgment text.
• Text is translated into the lower case.
• Text is tokenized by considering line breaks, white spaces, and paragraphs.
• Removal of tokens with a length of one and two character, white space, new line, punctuations, numbers and stop-words.
Once the judgment text is pre-processed, the proposed LDRS applies Doc2Vec to learn the semantically rich, low-dimensioned, and real-valued vector representation for input judgments. Thus, vectors of semantically relevant judgments result in neighboring vectors. Input to the Doc2Vec is a set of judgments and their respective pre-processed judgment text. The resultant is the judgment embedding consisting a set of judgments and their respective vectors, as shown in equations (3) and (4):

This phase aims to compute pairwise semantic similarity scores for an individual cluster using resultant of Phase-1 and Phase-2. In Phase-1, the Louvain method decomposes judgments into several clusters consisting set of densely interconnected judgments and sparsely connected with judgments of other clusters. This characteristic intuitively articulates that a judgment within a cluster has a strong relevance as compared to judgments of other clusters. The proposed LDRS determines the potential set of relevant judgments consisting of strong inter-cluster associations. Hence, this phase computes pairwise similarity scores for an indivisible cluster instead of the entire corpus. This practice eliminates the large number of unimportant pairs having irrelevant judgments, which rigorously decreases the requirement of computational resources. The strong relevance can be captured by preserving the semantic relations among judgments. So, within each cluster, Cosine similarity scores are computed using semantic judgment vectors learned from Doc2Vec, as computed in equation (5).
The algorithmic representation of the proposed Cluster based Pairwise Similarity Score Computation (C-PSC) is shown in Algorithm 1. Citation based information is used to decompose judgments into the cluster where an intention is to restrict the search space from the entire corpus to a single cluster. While, text-based information is used to capture semantic relevance and identify the most similar judgments by computing pairwise similarity scores within the cluster only. Hence, Resultants of Phase-1 and Phase-2 are inputted to compute pairwise similarity scores. Step No. 1 to 8 is the
Experiments
This Section describes the dataset used for empirical analysis, experiment settings, and evaluation measures. Results and discussion are also discussed in this Section.
Dataset
An empirical analysis was performed on the real Legal dataset crawled from a profound online Legal repository 2 . The dataset comprises more than 48000 judgments decided by the Supreme Court of India, during the span period of January 1950 to December 2016 (76 years). The raw format of judgment is comprised of textual information such as “headnote” (optional), and “judgment text”, and Referential information such as “citations”.
Phase-1 of the proposed LDRS clusters the similar types of judgments using citation network to eliminate irrelevant pairs of judgments. While, the textual information is being utilized to identify the semantically relevant judgments within a respective cluster. Hence, two datasets were derived from the raw Legal dataset: 1) Citation Network Dataset that consisted of judgments and their respective citation(s) where, each of them (i.e., judgments and citations) were assigned unique numeric identity (UID). 2) Legal Text Dataset comprised judgments (i.e., assign UIDs similar to the Citation Network Dataset) and their respective judgment text.
Experiment settings and performance measures
During this empirical analysis, two experiments are performed which are discussed in following subsection.
Citation network clustering
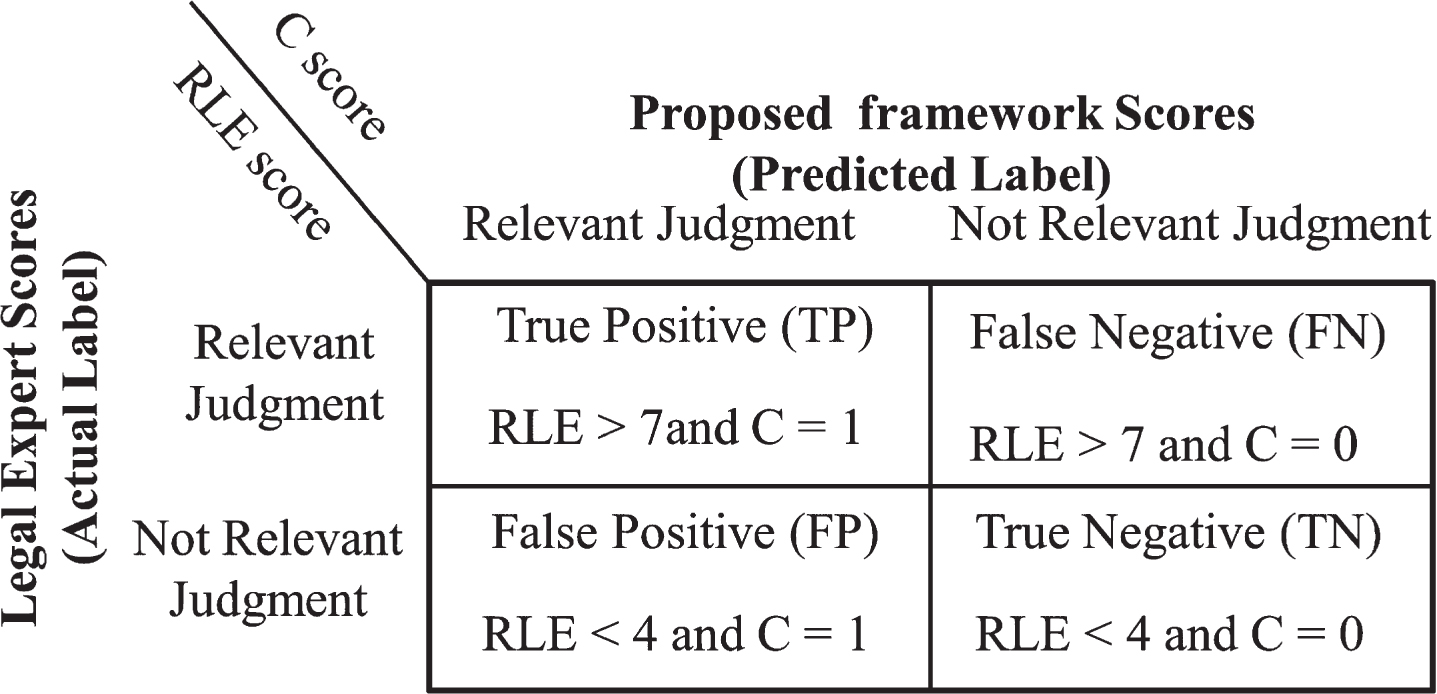
Experiment-1 is conducted on the Citation Network Dataset to evaluate and validate the performance of the Louvain approach. In the absence of standard labeled results (i.e., pairs having similar or not similar judgments), Kumar et al. [4] collected the

Architecture of the Proposed LDRS.
Confusion Matrix to Evaluate the Performance of Clustering.
The existing work [1] has already demonstrated and validated Doc2Vec’s superior performance for similarity analysis of the Indian judgments. This research therefore did not perform the empirical analysis to validate the performance of Doc2Vec. Instead, experiments were performed on the Legal Text dataset aiming to fine-tune the Doc2Vec model with hyper-parameters such as window size, vector size, and iterations [9]. So, rigorous experimentation was performed by varying the values of hyper-parameters. The most encouraging performance was determined with the vector size of 200, the window size of 20, and the number of iterations of 5. Consequently, these judgment vectors will be utilized in Experiment-2 to compute Cosine similarity scores.
Pairwise similarity score computation
Experiment-2 assesses the effectiveness of the proposed Cluster based Pairwise Similarity Score Computation (C-PSC) compared to the Brute force approach. The Brute force approach computes pairwise similarity scores for the entire corpus. This research evaluates the performance using time and space complexity. Time complexity signifies the total time 3 requires to compute cosine similarity for all unique judgment pairs. Space complexity signifies the memory 4 requirement to store the cosine similarity scores of all unique judgment pairs.
The citation network was constructed using Gephi 5 to visualize the knowledge flow. Louvain implementation from Gephi was utilized to cluster the network as it allows controlling the cluster size with the “resolution” parameter. Gensim 6 , a Python-based Open source Machine Learning Library, was exploited to learn the judgment vectors using Doc2Vec. All experimentations were executed on the Ubuntu 14.04 based machine with hardware consisting of Intel i7-7700 processor and 16GBs of RAM.
Experimental results
This subsection analyzes experimental results derived from the two aforesaid Experiments. First, the experimental result of the citation based analysis is being presented in Experiment-1. The proposed C-PSC approach is compared with the Brute force approach in Experiment-2.
•
During experimentation, it was observed that citation network decomposed into several components (i.e., connected graphs) viz. giant graph consisting of almost 99.86% of nodes to a total number of nodes, and several tiny graphs. There is no significance of such outlier tiny graphs in graph clustering. So, we kept only a giant graph, and rest tiny graphs are eliminated to reduce the process complexity.
In the Louvain method, resolution parameter handles the issue of resolution limit and partially controls the cluster size. This research analyzes the performance of proposed LDRS by varying the resolution values from 0.1 to 2.5 with an interval of 0.1, as depicted in Figs. 3, 4 and 5. Accuracy, F1-Score, and MCC Score are deteriorated with minor fluctuation when increasing resolution value. However, the recall remains consistent inferring that the most of relevant pairs’s judgments are correctly assigned to the same cluster irrespective of resolution. While, the precision declines inferring that irrelevant pairs’s judgments assigned to the same cluster as increases the resolution. The underlying reason is that smaller the value of resolution leads to a more number of clusters (i.e., small in size) and inversely, bigger value leads to a less number of clusters (i.e., large in size) as illustrated in Fig. 6. Hence, there is a high probability with large clusters (higher resolution) that judgments of irrelevant pairs assigned to the same cluster, which causes the incorrect classification.

Accuracy with Various Resolutions.

F1-Score, Precision and Recall with Various Resolutions.

MCC Score with Various Resolutions.

Cluster Size Distribution for Various Resolutions.
It is also observed that the performance achieves the stability beyond the resolution value of 1.5. The reason for that is a few large-sized clusters cover the majority of total judgments due to higher resolution value, as can be seen in Fig. 6(f). So, judgments of relevant and irrelevant testing pairs may cover by large clusters results in performance stability. The proposed LDRS resulted in a superior accuracy of 0.90 and an F1-Score of 0.86 and an MCC Score of 0.79 when the resolution value is 0.1. A total of 245 clusters were identified, and the size is ranging from 30 to 1642 nodes.
•
The efficiency of the proposed C-PSC is compared with the Brute force approach as a baseline. The Brute force approach computes the cosine similarity score of each judgment vector with every other judgment vector. (i.e., all unique judgment pairs for entire corpus). Table 1 depicts CPU time and Memory comparison of the proposed C-PSC and baseline approach. CPU time for baseline and proposed C-PSC are 28447.41s and 223.46s, respectively, demonstrating that the proposed approach achieves 127X speedup. Similarly, the proposed approach requires 0.026 GBs of memory that is comparatively much less than 3.32GBs of the baseline approach to preserve similarity scores. The reason behind better time and space complexity is that the baseline approach computes and stores similarity scores for
Performance Comparison of the Proposed LDRS and Baseline approach
The above empirical analysis is the evidence that graph clustering based proposed LDRS can achieve excellent performance. The promising performance has been demonstrated in terms of Accuracy, F1-Scores, and MCC Score of 0.90, 0.86, and 0.79, respectively. The reason for such an effective result is that relevant judgments refer to the similar kind of citation(s). Based on that belief, this research clusters relevant judgments by clustering the citation network. Results also confirm the encouraging computational efficiency in terms of time and space complexity. The proposed LDRS requires several orders of magnitude less memory than the baseline approach and reported the 127X speedup. The proposed LDRS computes the cluster based pairwise similarity scores since clusters consist of a relevant set of judgments. This practice prominently prevents excessive computational efforts by neglecting irrelevant pairs, which does not hold any significance.
Conclusion
The recommendation of relevant Legal documents is an essential action in the recommender system. Pairwise similarity scores are computed in advance to minimize the response time during recommendation. Due to the explosive growth of Legal documents, the quadratic complexity of pairwise similarity score computation turns out to be a scalability issue. To mitigate the scalability issue, proposed LDRS perform citation network clustering to cluster referentially relevant judgments. It computes pairwise similarity scores for each cluster, having strong relevancy among judgments. This way, unnecessary computation is prevented by restricting the search space to the cluster only instead of the entire corpus. Doc2Vec has been utilized to identify the semantically relevant judgments within each cluster. Experiments evaluated the citation network clustering, which has demonstrated the admirable performance in terms of Accuracy, F1-Score, and MCC Score. These results also demonstrate the potential superiority of proposed LDRS over the Brute force approach in terms of computational complexity to compute pairwise similarity scores. The encouraging performance of proposed LDRS can lead to the potential employment in the large scale Legal search engines.
•
Despite the success demonstrated, the proposed approach is limited by its consideration only for judgments with at least one citation. In a real scenario, there are many judgments without any single citation. In the future, consideration of all judgments would be an interesting aspect to enhance the proposed LDRS. Further, this research utilizes the Louvain approach, a crisp graph clustering approach that assigns each judgment to any particular cluster only. However, judgment may discuss multiple Legal concepts referring to dissimilar orientating references (i.e., criminal and civil). Accordingly, there is a possibility that a judgment may fall under more than one cluster. Hence, consideration of overlapping clustering can be a motivating research aspect in the future. In the Legal domain, the judgment citation network is very sparse owing to a lack of cited references. The network sparsity has severe impacts on the performance of the Legal information retrieval system. Hence, network connectivity would be enhanced by incorporating links constructed through textual information. Furthermore, the present work has not benefited from a parallel or distributed environment that can be investigated in the future.