
Abstract
Fuzzy measures are used for modeling interactions between a set of elements. Simplified fuzzy measures, as k-maxitive measures, were proposed in the literature for complexity and semantic considerations. In order to analyze the importance of a coalition in the fuzzy measure, the use of indices is required. This work focuses on the generalized interaction index, gindex. Its computation requires many resources in both time and space. Following the efforts to reduce the complexity of fuzzy measure identification, this work presents two algorithms to compute the gindex for k-maxitive measures. The structure of k-maxitive measures makes possible to compute the gindex considering the coalitions at level k and, for each of them, the number of coalitions sharing the same coefficient (called inheritors). The first algorithm deals with the space complexity and the second one also optimizes the runtime by not generating, but only counting, the number of inheritors. While counting the number of descendants is easy, this is not the case for the number of inheritors due to all the inheritors of previous considered coalitions have to be taken into account. The two proposed algorithms are tested with synthetic k-maxitive measures showing that the second algorithm is around 4 times faster than the first one.
Introduction
Fuzzy measures were proposed by Sugeno [20] to generalize probability measures by relaxing the additivity axiom with a monotonicity constraint. The ability of fuzzy measures to model the interaction among subsets of a set N = {X1, …, X i , …, X n } make them suitable for diverse fields of science like biology [17], economics [9], computer science [28], decision making [22, 27], to name a few.
Despite the descriptive power of fuzzy measures, their practical application is limited by the complexity of their coefficient identification: n elements require the evaluation of 2 n -2 coefficients. This exponential growth is their Achilles’s heel, restricting their use to problems with a handy number of elements. Although there are many algorithms to identify the 2 n elements of the fuzzy measure [1, 24], they are limited to small values of n. In an attempt to achieve identification scalability, simplified fuzzy measures have been proposed based on the inclusion of new restrictions. The λ-measure [21] reduces the number of coefficients to be identified to n + 1: singletons and λ, but this simplification goes along with a loss in modeling capability. A trade-off between complexity and modeling capability is proposed by measures that model the interaction between at most k elements, including k-additive [3] and k-maxitive [11, 12] measures. The use of k-maxitive measures instead of general fuzzy measures is supported by semantic and complexity considerations [14]. Coefficients of k-maxitive measures are identified for coalitions of cardinality up to k, the ones with cardinality between k and n are set based on those already identified.
This simplification reduces the space and time complexity of the identification algorithm: only values for coalitions with cardinality up to k are identified and stored.
The coefficient μ (A) associated with a coalition A considering a fuzzy measure μ may be interpreted as a weight assigned to the coalition A. However, since fuzzy measures are constrained by monotonicity, a more precise characterization of A contribution to the set N cannot be directly deduced from μ (A). In the field of cooperative game theory, Shapley [19] proposed an index to characterize individual contributions. The index was first generalized to pairs of elements [16] and then, to subsets of arbitrary cardinality through the gindex [3].
The collective behavior characterization is a key point in problems where individual considerations may not be statistically significant. Through gindex, behaviors such as complementary or redundancy among elements can be evaluated [15].
The classical computation of the gindex includes two summations. All the subsets of N are considered in the formula (in the first or second summation) and their individual generation is not a straightforward. But it is possible to rewrite the formula with only one summation [4], which makes the generation of all elements in
Although the indices provide useful information about interactions of coalitions, their computation may require an important effort. Some algorithms to compute the Shapley index on special situation [8] or to compute other indices [18, 25], were proposed but none of them makes the most of the structure of k-maxitive fuzzy measures. Following the efforts to reduce the complexity of fuzzy measure identification, the motivation for this work is to achieve a similar reduction in the calculation of the gindex. The objective of this work is twofold. Firstly, a new algorithm to compute gindex for k-maxitive measures is introduced. This new algorithm, naive kindex, uses the formula with only one summation and an easier way for subset generation. It also introduces several improvements to reduce the complexity. Secondly, to take advantage of the underlying structure of k-maxitive measures, a second algorithm, kindex, is presented. All the coalitions that share the same coefficient are considered at the same time. In this way, their contribution to the gindex is computed without individualizing all their elements, i.e., not all the coalitions are generated.
A complexity analysis is carried out for the two proposed algorithms. Finally, time requirements are evaluated using synthetic k-maxitive measures.
The outline of this work is the following: Section 2 introduces basic concepts related to fuzzy measures and their representation, Shapley index and k-maxitive measures. Section 3 presents two approaches to compute the gindex from a k-maxitive measure. In Section 4, the complexity of the two proposed algorithms is analyzed. In Section 5 optimization enhancements are presented and both algorithms are tested with synthetic k-maxitive measures. Finally, Section 6 presents the conclusions and open perspectives.
Preliminaries
Let N = {X1, …, X
i
, …, X
n
} be a finite set and
Fuzzy measures and their representation
μ (∅) =0, μ (N) =1 A ⊆ B ⊆ N ⇒ μ (A) ≤ μ (B)
The first axiom, called the normalization axiom, allows for meaningful comparisons between fuzzy measures. The second axiom formalizes a monotony constraint. The numbers μ (A), called the coefficients of the measure μ, are the weights given to the elements of
A suitable way of representing fuzzy measures in the finite case is through a lattice.
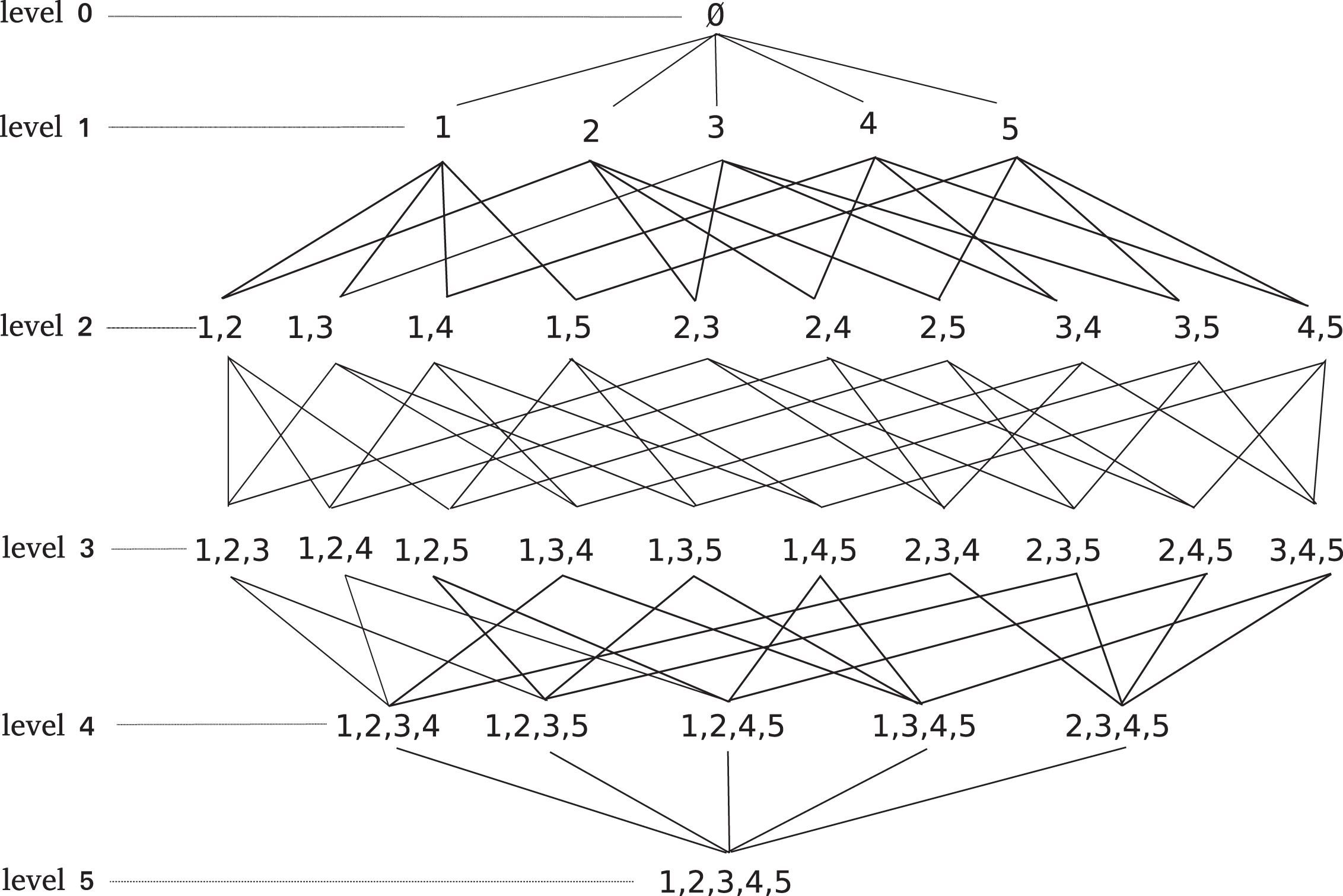
A lattice representation of
The Shapley index of an element X
i
∈ N [19] is calculated as follows:
The computation of the gindex for a set A in Eq. (3) comprises two parts, each of which includes a summation. The first one, considers all subsets Z of the set N \ A, i.e.,
It is possible to rewrite Eq. (3) as follows [4]:
The possibilistic Möbius transform [2] of a fuzzy measure μ on N is a mapping
A way to design a k-maxitive measure is to set the coefficients μ (A), for a > k, to the maximum coefficient value of the k-size subset included in A as stated in Eq. (6).
Note that, unlike the concept of descendant, this definition requires a measure. Therefore, this definition is more restrictive than Definition 4. Let us assume N=5 as in Fig.1 and a 2-maxitive measure where μ ({1, 2}) > μ ({1, 3}) > μ ({1, 4}) > ⋯ > μ ({4, 5}). Coalition {1, 2, 3} is a descendant of coalitions {1, 2}, {1, 3} and {2, 3}. Moreover, since μ ({1, 2}) > μ ({1, 3}) > μ ({2, 3}) then {1, 2, 3} inherits from {1, 2}, i.e., μ ({1, 2, 3}) = μ ({1, 2}). While counting the number of descendants is easy, this is not the case for the number of inheritors. This is a key point the proposed algorithm has to tackle.
Notation. As subsets of N are used in different contexts in this paper, the word coalition is used to refer to elements in the domain of the fuzzy measure or those for which the interaction index is computed, and the word subset is used for any other general purpose.
The computation of the gindex can benefit from the particular structure of k-maxitive measures. In this case, only coefficients up to level k are individually set and those of levels l > k are derived from the ones at level k.
Two algorithms are proposed. Both of them assume that the coefficients associated with coalition of cardinality greater than k are not stored in memory to reduce space requirements [14]. In the first algorithm, each coalition of level higher than k is generated and its coefficients computed “on the fly”. In the second one, the coalitions higher than k are not even generated.
First approach: a naive implementation
One alternative to compute the gindex from a k-maxitive measure is to replace the function μ in Eq. (4) with the function μ* in Eq. (7):
The calculation of the gindex using Eq. (7) is implemented in Algorithm 1.
1:
2:
3:
4: b′ ← |I ∩ A|
5: z′ ← i - b′
6:
7: m ← μ (I)
{store coefficient}
8:
9:
{max of coefficient at level k included in I}
10:
11:
12: sum ← sum + (-1) (a-b′) · w · m
13:
14:
This modification introduces, for all coalitions I ∈ C and i > k, the search for the maximum over all coefficients associated with coalitions contained in I at level k (Line 9 and Eq. (6)). Lines 6, 8, 9 and 10 are specific to k-maxitive measures, they are not needed for general fuzzy measures, i.e., when all the coefficients are stored.
When computing the gindex using this approach, all the coalitions are generated (Line 3) so that the complexity was reduced in terms of space but not in terms of time.
In a k-maxitive measure, all the inheritors of a coalition at level k share the same coefficient. Then, their contribution to the gindex could be computed knowing the coefficient (the same for all of them) and their total number, avoiding their generation. The idea is to divide the gindex calculation into two parts: in the first part, the contribution to the gindex of coalitions from level 1 to k is computed as usual using Eq. (4) (through naive kindex). In the second part, the number of inheritors of each coalition at level k is counted and their contribution to the gindex computed. The count of the inheritors is performed level by level since the inheritors share the same coefficient but the normalization factor depends on the level.
gindex algorithm for k-maxitive fuzzy measures: kindex algorithm
The calculation of the gindex from k-maxitive fuzzy measures is presented in Algorithm 2. The input of the algorithm is a finite set of elements N, a coalition
1:
2:
3: sum← naive kindex(C, n, A, μ)
{contribution of all
4:
{sort coefficient at level k in decreasing order}
5: T ← N
6:
7:
8:
9: next B
10:
11: b′ ← |B|
12:
13: z′ ← l - b′
14:
15: qty ← InheirCount (J, B, l, T)
{uncounted inheritors of J at level l}
16: sum ← sum + qty · (-1) (a-b′) · w · μ (J)
17:
18:
19: T ← Split (T, J)
{split all elements of T containing J}
20:
21:
The first part of the algorithm computes the contribution of the coalitions up to level k using Algorithm naive kindex (Line 3). After that, coalition-coefficient pairs at level k are sorted in descending order of coefficients and saved in vector
The computation of Gindex (A) involves two types of subsets as stated in Eq. (3): the subsets of A, called B, and the subsets of the complement of A in N:
The coalitions at level k (Line 6) may include some elements of coalition A, then, when B ⊆ A (Line 7) there is no need to consider some subsets of B, this is stated by the test condition to be satisfied: |A ∩ J| > |B ∩ J|. The following example illustrates the possible situations.
The value of z′ (Line 13) depends on the level: it is the number of elements in J that do not belong to A. The weight of J (Line 14) is computed using the value of z′. Subroutine InheirCount identifies sets in T which includes {{J \ A} ∪ {B}}, i.e., T i ⊃ {{J \ A} ∪ {B}} and counts the inheritors of J at level l (Line 15). The way InheirCount counts inheritors using formula (8) and T is explained in subsection 3.2.3. The contribution of J and its inheritors to the gindex is calculated and the weighted sum is updated (Line 16). Finally, collection T is updated through Split function so that J can not be generated again from any of the sets in T (Line 19).
Method to avoid counting associated inheritors more than once
The determination of the number of descendants of an element at level k is given by
To count the number of inheritors, the coefficients at level k are sorted in decreasing order. A collection of sets, named T, is used to avoid counting coalitions already counted. At the beginning of the process T = {N}, meaning that it includes only one set, the one that includes all the elements. Then, the first step consists in counting the number of descendants of the coalition with the maximum coefficient value: all descendants are inheritors, their number at level l is
Let N = {1, 2, 3, 4, 5} with the following order of coalitions at level k=2: μ {1, 2}≥ μ {2, 3} ≥ μ {4, 5} ≥ μ {1, 3} … Initially, T = {{1, 2, 3, 4, 5}} and the coalition with the highest coefficient, {1, 2}, is analyzed and its inheritors counted. Table 1 shows the number of inheritors (# inh.) of the considered coalition per level and list them in the last column (only for reference, they are not generated).
Step 1: Inheritor of coalition {1, 2}

Then, the elements of T which include {1, 2} are duplicated. At the first step there is only one, the whole set N. In the original set, the element 2 is removed while element 1 is removed from its copy. T is updated: T = {{1, 3, 4, 5} , {2, 3, 4, 5}} and this completes the first step. Based on the coefficient order, μ {2, 3} is considered in the second step. Only element {2, 3, 4, 5} may generate inheritors of {2, 3} since {2} is not included in the other element. The summary of this step is given in Table 2.
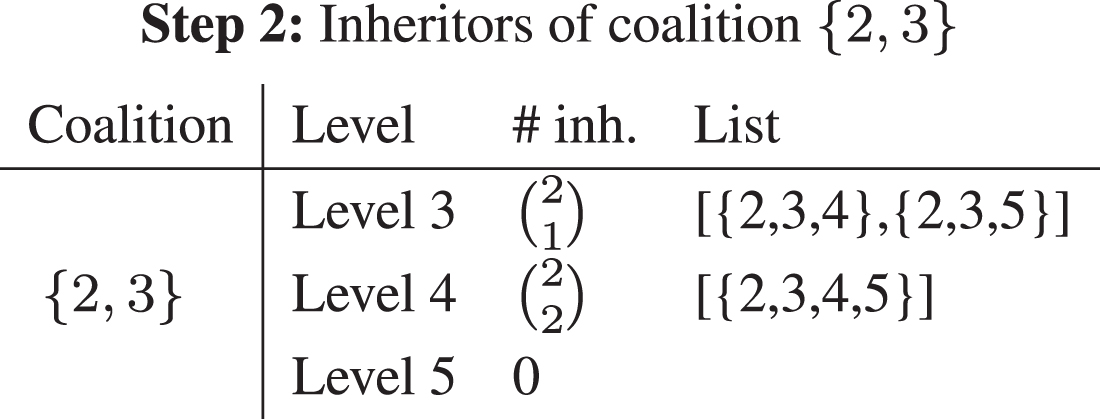
The collection is now updated: {1, 3, 4, 5} remains unchanged, and {2, 3, 4, 5} is replaced by {2, 4, 5} and {3, 4, 5}. As {3, 4, 5} ⊂ {1, 3, 4, 5} it can be removed from the collection to avoid a twofold counting. The collection is now: T = {{1, 3, 4, 5} , {2, 4, 5}}. The next coalition to be considered at the third step is {4, 5}. The results are given in Table 3. T becomes T = {{1, 3, 4} , {1, 3, 5}} as the sets of cardinality k were removed since they cannot generate combinations higher than k.

The last step considers the coalition {1, 3}. The results are shown in Table 4.

After examining coalition {1, 3} at step 4, 10 coalitions were counted at level 3, 5 at level 4 and 1 at level 5. Consequently, for each level l > k, all coalitions (between brackets) were counted without generating them and the algorithm ends.
If the order of the coefficients were: μ {1, 2}≥ μ {4, 5} ≥ μ {1, 3} …, the result of the second step would be:
In this case {3, 4, 5} would have been counted twice, since its inherits from {1, 3, 4, 5} and {2, 3, 4, 5}. This example shows that a careful counting process is required to avoid this kind of multiple counts, i.e., only distinct sets have to be taken into account.
Let S1, ⋯ , S
m
be m subsets of N. Let
The calculation of gindex according to Eq. (3) is called the standard approach. The two algorithms proposed in this work are referred to as naive and kindex. The computation complexity is analyzed according to space and time considerations. A memory amount of 4 bytes per coefficient is assumed.
The standard approach required 2 n coefficients to be stored in memory and 2 n elements to be summed individually. For n=20, n=25 and n=30 the total memory required is respectively 4Mb, 128Mb and 4Gb. This complexity limits the use of the standard approach to small values of n.
Algorithms naive and kindex take advantage of the underling structure of k-maxitive measures to reduce space or/and time complexity.
For the naive approach, the number of coefficients stored in memory is:
For the kindex approach, the number of coefficients stored in memory is:
A result summary considering k = 4 for memory usage is shown in Table 6.
Step 2*: Inheritors of coalition {4, 5} for coefficient order μ {1, 2}≥ μ {4, 5} ≥ μ {1, 3} …

Memory requirements for the standard, naive and kindex approaches
The number of times the coefficients are read is shown in Table 7.
Number of times the coefficients are read for the standard, naive and kindex approaches
The kindex approach demands more space requirement than the naive approach, but it highly reduces the number of individual summations and, consequently, the algorithm running time. Algorithm kindex reduces the access to the coefficient values in 26, 210 and 214 times compared to the standard and the naive approach.
Some improvements were made to both approaches, many of them dealing with implementations issues. Although these tips do not change the algorithm complexity, they make them faster. The optimized algorithms were then tested using synthetic fuzzy measures to evaluate their performance in different scenarios.
Optimization enhancements
The alternative formula presented in Eq. (4) to compute the gindex entails a unique summation where all
The computation of the normalization term in Eq. (3),
The number of elements en each lattice level l is known:
When all the inheritors were counted the loop (Algorithm 2, Line 6) can be halted.
When the number of subsets S i k in Eq. (8_condensed) increases, the number of combinations to consider might drastically increase the number of calculations. In those cases, it might be better to join all the subsets, consider all possible subsets with increasing cardinality and count those contained in at least one of the S i k . A threshold, Thr, can be added to kindex to control which of the two alternatives is used, i.e., if the number of subsets is below the threshold Eq. (8_condensed) is used, otherwise the union is performed. The sensitivity to this parameter is studied in the following section.
Results
Time performance of kindex and naive kindex are compared for 20 randomly selected subsets belonging to three synthetic randomly generated k-maxitive measures with N = 15, N = 18 and N = 21. Values of k ranging from 2 to 5 and thresholds in the range [4, 20] were evaluated. The results for three typical threshold values are shown in Table 8.
Relative time performance of kindex vs naive to compute the gindex value of 20 randomly selected elements of a k-maxitive measure for three threshold values.
Relative time performance of kindex vs naive to compute the gindex value of 20 randomly selected elements of a k-maxitive measure for three threshold values.
The highest value, +8.79, indicates that kindex is almost 9 times faster than the naive approach when N=21, k=4 and Thr=12. In fact, kindex outperforms naive kindex in almost all tested scenarios, except for Thr=20, k=2 and k=3. An average of the last row on each threshold shows that kindex is 1.8 better than naive in the worst case (for Thr=20) and 4.47 better in the best case (for Thr=12). The best performance, in average (in boldface), is obtained for Thr=12. In all the scenarios, kindex performance increases (on average) with the number of features considered, i.e., the higher the N the better its performance compare to the naive approach. The fact that the difference between performances increases with the number of elements is expected since the number of subsets that do not need to be generated by kindex grows with the number of elements in N.
A combination of a big threshold and a small N (N=15 and Thr=20) makes the algorithm kindex use Eq. (8_condensed) most of the time. In the other case, for a combination of a small threshold and a big N (N=21 and Thr=4), the approach of join all the subsets is used most of the times. A balance is obtained when considering a threshold around N/2.
A reasonable strategy, to significantly reduce time requirement, is to start computing the gindex of singletons. Then, for the gindex of coefficients pairs, consider only the coalitions of relevant singletons (gindex ≥ 1/n) [15]. This strategy can be repeated, in an analogous way for higher size subsets. Moreover, to speed up the process, the computation of the elements can be performed in a parallel way.
In this work, two algorithms, called naive kindex and kindex, are proposed. They compute the gindex from a k-maxitive measure where only coefficients up to k are stored in memory. In naive kindex, each subset is efficiently generated thanks to a binary representation, and the computation of the maximum in Eq. (6) is optimized by ordering coalitions of level k at the beginning of the algorithm. The kindex approach is divided into two parts. In the first part, the contribution of elements up to level k to the gindex (A) is done by using naive kindex. In the second part, gindex is computed considering the contribution of each k level element together with the contributions of its inheritors. In this way, the generation of higher order set is avoided and the time complexity of the algorithm is considerably reduced.
Optimization enhancements are suggested for both approaches: generation of subsets, computation of combinatorial numbers, halting criteria for loops and selection of a threshold to decide whether to use or not Eq. (8_condensed) to count subsets of a specific cardinality.
Both algorithms significantly reduce the space requirement compared to the standard approach. For kindex, the number of calls is reduced, since all inheritors of the same element are collectively computed. The price to pay is a small amount of extra memory space to avoid counting an element more than once (vector v).
The time performance of the two proposed approaches is tested for synthetic k-maxitive fuzzy measures. kindex is faster and the difference is more significant when more elements are considered. When analyzing a fuzzy measure, the processing time can be reduced by restricting the analysis to coalitions of interest. First, only small size coalitions, e.g., up to k + 1 elements, can be considered since the use of a k-maxitive measure assumes that the interactions involve at most k elements. But, among these coalitions only those including relevant singletons have to be studied. A singleton is said to be relevant if its gindex value is higher than 1/n as discussed in [15].
One optimization issue is left as a perspective of this work: a parallel version of the kindex algorithm to compute the gindex for different coalitions as each computation is independent from others even if it is based on the same information.
Footnotes
Appendix
Algorithm Choose (Algorithm 3) shows an efficient way to compute the combination of n elements taken t at the time [6].
1:
2:
3: r ← 1
4: d ← 1
5:
6: r ← r.n
7: n ← n –1
8: r ← r/d
9: d ← d + 1
10: