
Abstract
This paper presents an automated vehicle identification and classification method from traffic videos. The proposed method unlike other traditional methods combines the multiple time spatial frames to detect moving objects. These moving objects are the potential vehicles however there may be some other moving objects also. Therefore to further improve the accuracy of the proposed method, the moving objects are classified using object oriented classification scheme. The identification of vehicles from traffic videos plays an important role in Intelligent Transport systems (ITS). A virtual line is placed on each frame such that the objects crossing this line are the desired moving objects. The object based classifier makes use of fuzzy rules based on features like area, perimeter, and elongation and so on. These fuzzy rules are used to classify them into vehicle and non-vehicle classes. The second level of classification further classifies the vehicles into two wheeler, four wheeler and six wheeler vehicles. The method can be appropriately used for traffic surveillance as it also computes the speed of vehicles using the time spatial frames. The proposed method is applied on traffic videos of multiple time lengths. A comparative study of the proposed method with the existing methods reveals that the proposed work has higher accuracy. The motion detection, vehicle classification and speed of computation make this method best suited for many ITS applications like traffic surveillance and other similar applications.
Keywords
Introduction
Computer vision based techniques have evolved as an efficient solution for video analysis. Monitoring vehicles is widely used for applications like detection of traffic violations, traffic monitoring and other such suspicious activities. The available methods require specialized camera views and cannot be used for wide area coverage. Also, the quality of surveillance videos obtained is generally poor. The range of acquisition conditions like occlusions, night time, changeable weather etc make the task more challenging. Thus, in this paper, all the above mentioned issues are addressed with the use of image processing techniques. Fatalities and accidents caused by traffic is a very serious and growing problem worldwide due to increasing usage of automobiles (National Highway Traffic Safety Administration, 2011). In the past decades, a lot of work has been done on designing an intelligent transportation system which can control the traffic and detect possibility of any kind of miss-happenings on the roads. The system should have the capability to automatically smooth the traffic movement and give automatic alerts for over-speeding, congestion etc. With the availability of CCTV cameras in 1950s designing of such systems has become cheaper and easier as you can get live streaming of all the movements on the roads. The videos obtained from these cameras can be used to design intelligent transportation systems which can be used for both real time monitoring and post event analysis for finding reasons of occurrence of an event.
The first and most important step in designing any Intelligent Transportation System is detecting and tracking the vehicles. After detection the information can be further used to design numerous transports surveillance related applications including detection of speed, congestion of vehicles, detection of suspicions activities etc. [1]. The approaches for detecting different vehicles on roads can be classified into three different categories including radar sensing [2, 3], lidar sensing [4, 5] and computer vision based detection [6, 7]. Performance of sensor based methods is highly dependent on quality and availability of controlling frequency signals. Also radar or lidar sensors are costly and sometimes fail to provide sufficient field-of-view required for detection. In this context, video based tracking techniques have immensely progressed in recent years as they do not depend on availability of network and such signals.
Vehicle detection methods using image processing techniques can be classified into two broad categories: appearance based and motion based techniques [8]. In appearance based methods, vehicles are detected directly from images applying some pixel operations. Some features of vehicles like length, height, aspect ratio, compact ratio, blob features etc may be used for type recognition purpose [9]. Motion based approaches on the other hand require sequence of images to recognize vehicles. Some of the motion estimation based techniques for detection include inter-frame difference method [10] Gaussian Scale Mixture model method [11] and background subtraction method [12, 13]. The most popular technique among all these is background subtraction method. In this technique, we estimate the background of the video. This background is then subtracted from subsequent frames of video to get foreground blobs which are nothing but moving vehicles. Background detection is the most challenging task in this technique as background of video may undergo changes due to jittering of camera, shadow, and change of illumination and presence of noise [14].
Some techniques based on deformable 3-D geometric models [15], virtual detection line [16] and Haar rectangular features for detection have also been proposed in literature [17]. Some detection and tracking methods based on active learning using networks and SVM is also proposed [18, 19]. Multi-time spatial images have also shown good results for detection and classification of vehicles [1, 14]. Detecting vehicles from traffic videos face some serious challenges like heterogeneous size, shape and color of the vehicles. Various acquisition conditions like illumination, background and scene complexity. Many methods in the literature have been proposed. But some of them do not work in cases of occlusion. Some other work well but are very time consuming and complex. The proposed method in this paper is based on Spatial Time Frame generations (STF) and object based classification. The use of STF helps in identifying moving objects only hence limiting the chances of miss detections. In existing time frame generation based methods classification is done by using different nearest neighbor classification methods after extracting features which increases complexity of the system. The vehicles to be identified are heterogeneous in nature. The features used should be shape and texture invariant. Thus, in this paper object based classification approach is used, which is simpler and better as compared to other state of the art methods. The method is applied on videos of available datasets [20, 21] and compared with other existing methods.
Proposed method
The proposed method is based on spatial time frame (STF) generation and Object based classification using fuzzy based rule approach. The method is novel method for classification as it has used spatial times frames for removal of occlusion which is a great concern in this area and also combined object based techniques with this which has reduced the complexity of the prior methods available. The flowchart of the proposed method is shown in Fig. 1. The various steps are discussed in the following sections.
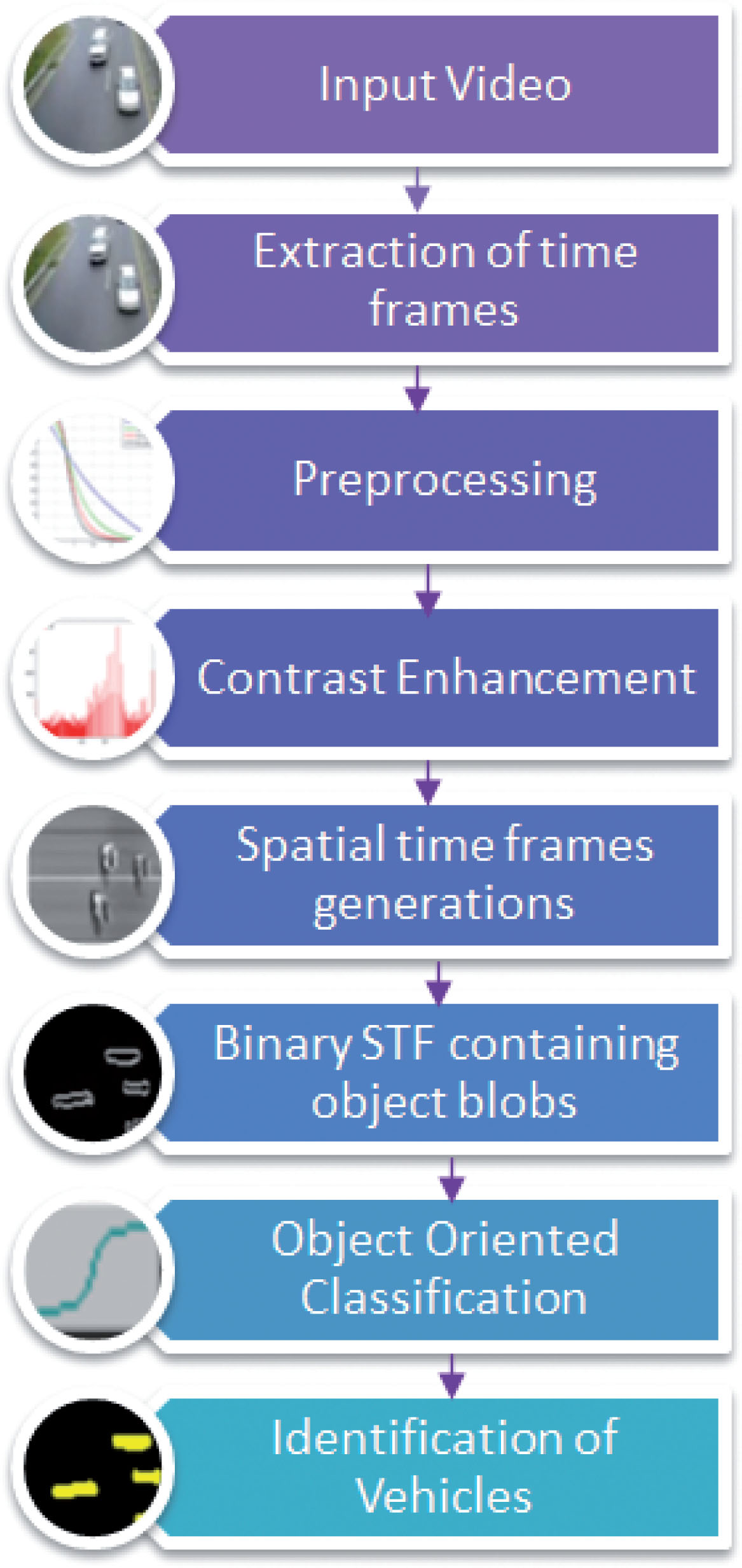
Flowchart of proposed method.
Vehicles on road can be detected and tracked by recording the videos of traffic. The recording can be done by either CCTV cameras which can be placed and installed anywhere at some elevation or an ego vehicle. CCTV cameras capture the videos of fixed location while ego vehicles are moving vehicles having camera installed and capture videos. These cameras record videos in the form of digital frames or succession of still images. The total number of frames contained by video in one second is called frame rate of the video. Mostly videos are recorded at a frame rate of 25– 30 frames per second. Each video sequence can be described as given in Equation (1)
ϑ T = Video Sequence recorded at T th second. φ n = n th frame of video sequence.
Noise free and high contrast images are requires for identification & classifications from videos. The videos recorded from CCTV cameras under different environmental and illumination conditions often contain some disturbances. All these disturbances are modeled as noise, shadows, occlusion, illumination and reflection. These disturbances need to be removed before further processing of these videos. The preprocessing steps are applied on HIS image thus the RGB image is first converted to HIS image. This is done because unlike RGB, HSI separates image intensity from color information. Also HSI components are not much affected by noise and indirect lightening from surroundings [22]. HSI frame from a RGB video frame is obtained using the following equations:
Where
The shadow removal is applied on the HSI image. The videos recorded from different sources are noisy due to quality of image sensors and camera calibration. Dynamic nature of surveillance sequences is also a reason for noise generation. Due to presence of noise, a large area of frames obtained from these noisy video sequences may be misclassified as moving objects. Averaging the frames obtained is one of the possible solutions but it has limited de-noising effect and also results in blur. Gaussian low pass filters are the traditional models which were used mostly for removal of impulse noise in the digital images. But usage of this filter results in loss of some high frequency components in the image. As a result the edge and shape related detailed information may lose in the image. In this paper, Butterworth low pass noise removal filter is applied to each HSI frame of the video to remove noise using Equation (6).
Where (x, y) denotes the spatial location of the pixel.
Contrast enhancement is the technique used to adjust the dynamic grey levels in the image. The process improves the quality of the image so that it can give better results in further feature extraction and recognition faces. We are using dynamic histogram equalization technique [23] to adjust the contrast of the preprocessed images. The method works in three steps. Steps include division of histogram, range allocation to each sub part and finally histogram equalization. The algorithm for the same is as follows:
The result of applying this algorithm on an image and their equivalent histograms are shown in Fig. 2.
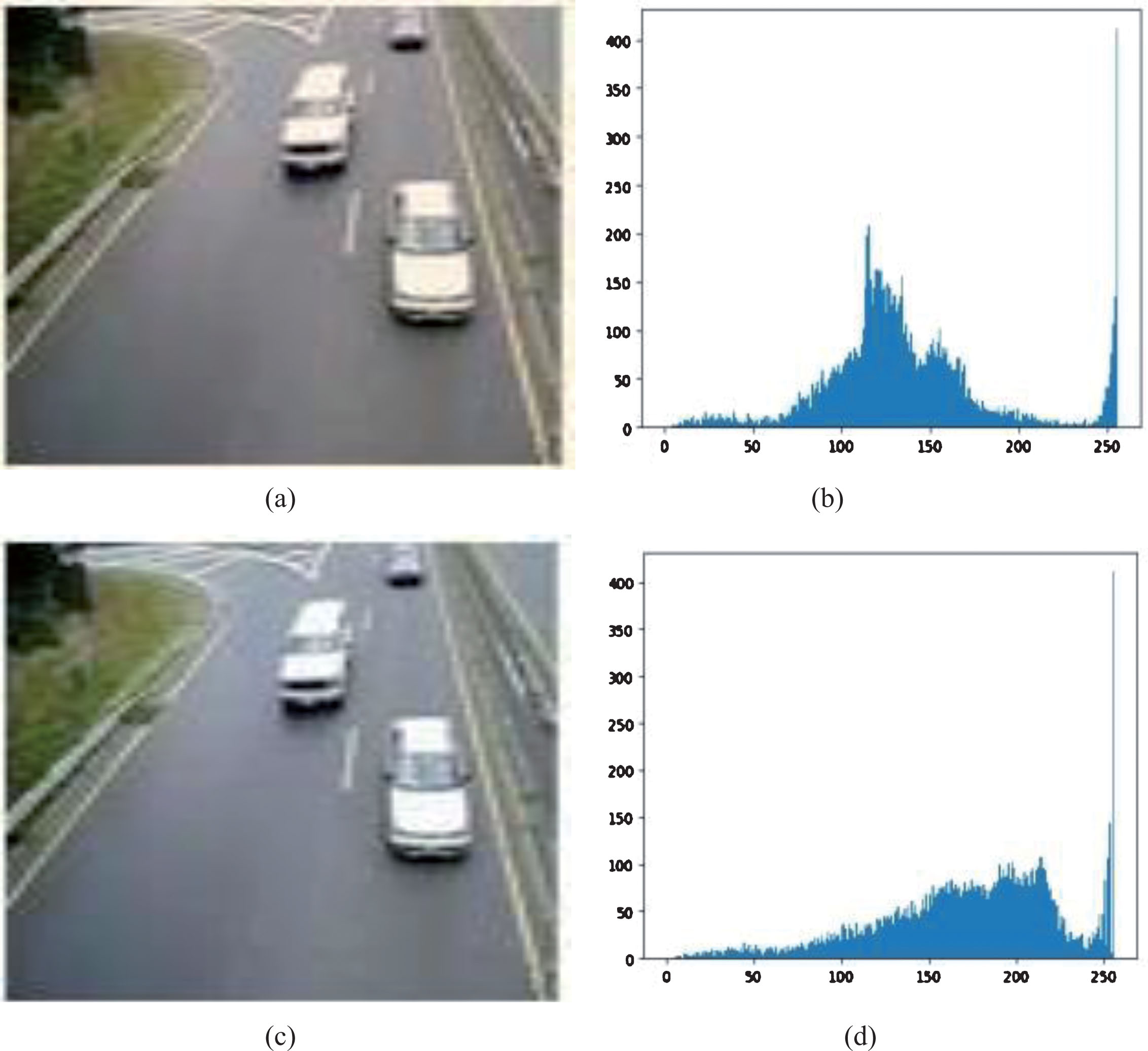
(a) Normal Image, (b) Corresponding Histogram of Normal Image, (c) Contrast Enhanced Image, (d) Histogram after Contrast Enhancement.
Spatial time frames are generated (STF) from the traffic videos for detecting moving vehicles. Multiple virtual lines [14] are used for generating these frames which are basically set of pixels in a frame taken in the direction perpendicular to the motion of vehicles as shown in Fig. 3.

Virtual lines on consecutive frames in the video.
STF frame is generated by placing the pixel intensities of all the vehicles which pass through the virtual line in the chronological order as shown in Fig. 4. Thus the image is generated using the luminance value of pixels of the moving objects that pass the virtual line. Therefore if we are having n frames of size x × y in time interval of t then the resultant frame will be a n × x STF frame. This frame will contain different objects which pass through the virtual line in the time interval t.

STF generated for 130 consecutive frames.
In the proposed method, three different virtual lines are used at different locations in the frame as shown in Fig. 5. The basic idea behind using multiple lines is occlusion detection. In certain scenarios, vehicles in STF will seem to be merged into each other resulting in occlusion. As the vehicles will be in motion they will appear disjoint in at least one of the three STFs.

Multiple virtual lines.
As STF are generated using continuous pixel intensities passing VDL thus, horizontal length of objects will provide information regarding number of frames through which the object has passed and similarly vertical length can tell about their geometry. Therefore next step is to find all the object blobs in the STF. Vehicle Identification operator β used for vehicle detection is Top hat transform of the STF and is calculated as
T (x, y) = STF frame
α = structuring element
Finally all the vehicle pixels along with pixels which are similar to the vehicle pixels are detected by applying a threshold value to the β calculated to get binary STF ∂
n
. After finding ∂
n
, all the connected components of STF frame are identified. Canny edge detector is used to detect fine details of objects in ∂
n
[24]. The gradient components of the images in x and y direction are calculated as
Magnitude of the gradient is calculated as
Direction of the gradient is calculated as
After calculating gradient non-maximum suppression is applied on the image to get correct edge positions. To remove the discontinuity in the edges, dilation morphology operation denoted as K γ applied with a vertical line structuring element, where γ where γ > 1 is length of line in unit of pixels. This operation is followed by another morphology closing operation with a square structuring element St μ , μ > 1 where μ is width and height of the square in unit of pixels. The choice of γ and μ may vary and is highly dependent on the type of videos, their resolution and size of vehicles on the road. As a result, final STFs of a video sequence will contain segmented blobs corresponding tsso moving objects, and total number of vehicles can easily be counted by counting number of blobs in STFs. Counting error may occur if objects are occluded with each other as shown in Fig. 6. The use of multiple STFs is that it helps in overcoming joint blobs. For example in the first and third STF, the blobs are occluded with each other and hence appear to be a single object. But in the second STF they appear disjointed due to continuous motion.
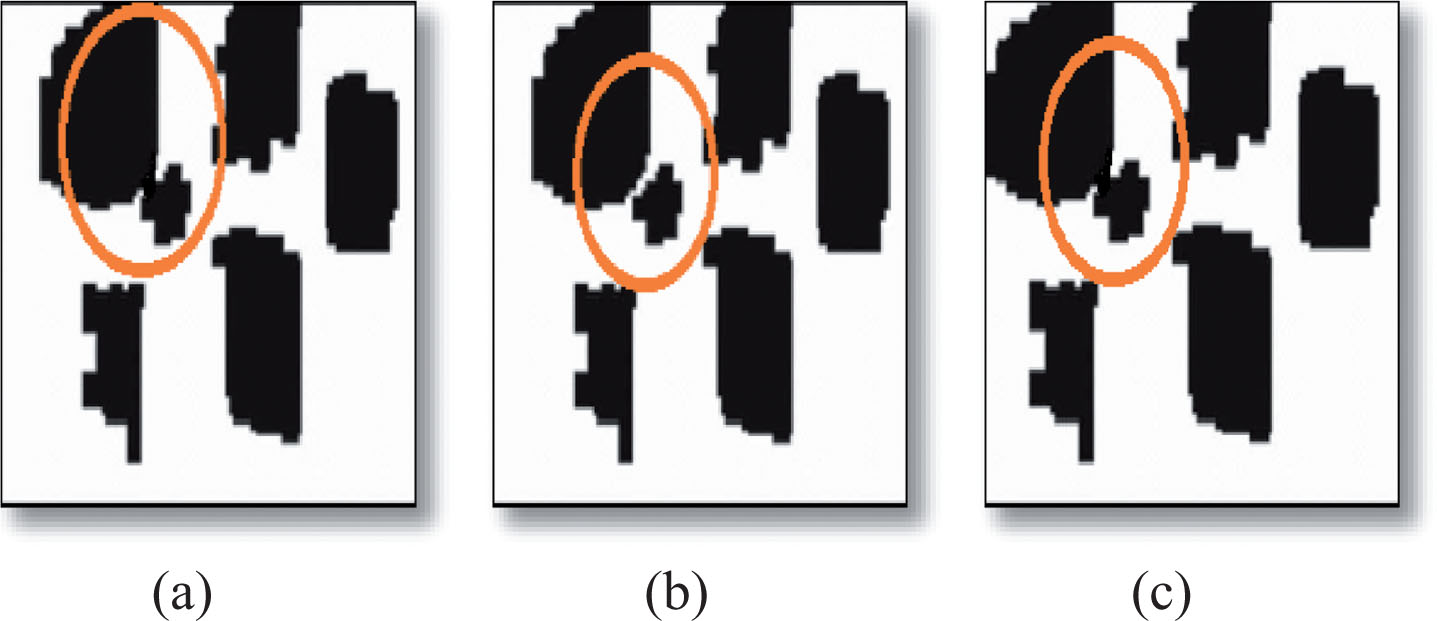
Multiple STFs of the continuous frames (a) STF1 (b) STF2 (c) STF3.
For detection of possible merging a feature based technique is used [1]. As all traffic motion is taken in one direction and the virtual detection lines taken are also very close to each other, the y axis of the centroid and its area does not change significantly in different STFs. Therefore we have used area and centroid for comparison of the blobs generated in different frame sequences. The merging of blobs is decided based on the threshold values. If the dissimilarity is above the selected threshold then the blobs are merged. Else the blobs are not merged. The algorithm developed for merging the blobs is as follows:
The threshold values for centroid and area are dependent on illumination and video resolution. In case there is high illumination conditions the shadows will affect the segmentation and thus high threshold values are taken. The values are selected based on the scenario used in the experiment.
Object based classification (OB) using fuzzy logics are used to analyze the frames. Pixel based methods are based on information in each pixel. But to detect vehicles OB technique is more reliable as it works on the information from a set of similar pixels or objects [25]. The objects can be classified based on size, shape, and texture.
The image blobs obtained from STF correspond to connected regions representing different objects. Using OB classification approach thus objects are classified into vehicles using specific features. Vehicles are expected to be compact objects with rectangular shape that have a length and width within a certain size range and orientation parallel to the road. Thus different features that were expected to reflect these properties were tested. The vehicles are rectangular objects. As the perimeter will become large as compared to area, the object will be thinner which is characteristic of trees, buildings as they are thin. Hence in this paper, we have used shape oriented features to remove the misdetections and classify vehicles into three categories which are two wheeler (T w ), four wheeler (F w ) and six wheeler (S w ). Cars are covered in F w class and trucks and buses are classified as S w . Once the segmented STF images are obtained fuzzy logic based rules are applied for classification of vehicles.
Features used for level 1and Level 2 classification
Features used for level 1and Level 2 classification
All the blobs needs to be divided into any of the four classes based on the calculation of likelihood of a blob to class defined with the help of membership. Memberships are calculated as valued returned by the fuzzy rules which are designed using different features or set of features. Following features of all the connected regions are calculated for designing the rule base. Elongation is used to determine how close the object to rectangular shape is. It is measures as ratio of area and square of perimeter. Image objects were classified using different membership functions and threshold values which are summarized in Table 1. The classification was done in two levels. In the first level, vehicles all non-vehicles are identified using three features Rectangularity, perimeter and compactness. In the second level, vehicles are further classified into T w , F w and S w using two features area and elongation. Rule sets used for the classification are defined below.
Using the above parameters the rule set is defined as follows in Table 2.
Rule set used for level 1and Level 2 classification
Once we have identified all the vehicles from the STF of the video we can analyze the behavior by calculating the speed of the detected vehicles. As STF is generated using pixels on the virtual line of each frame, x-axis length of the object blob in the STF will tell that through how many frames the vehicles has been passed. Let x - axis (OB
j
) denotes this length. Let R
v
be the resolution of the video in meters per pixel and F
r
be the frame rate of the video than speed of the vehicles in meters per second may be calculated as
Once we have detected the speed of vehicles we can identify the vehicles which are over-speed by setting a threshold limit for the same.
Experiments are carried out using various publicly available video databases of on-road traffic. One of the databases contains video clips captured at different locations of Dhaka, Bangladesh and Suwon using a fixed camera [20]. The frame rate of the captured videos is 25 frames per second with a frame size of 176 × 144. Other dataset used is LISA-Q vehicle dataset [21]. The dataset contains 1600 consecutive frames in the videos captured in sunny light. The dataset consists of on road data that is taken per day and added to the archive into naturalistic driving and intelligent driver-assistance systems. The data taken consists of videos captured from six cameras. The front facing cameras contribute to the LISA-Q Front FOVdata sets. Some of the frames from both the datasets are shown in Fig. 7.

The dataset does not contain any validation datasets. However, for the evaluation procedure the numerical values of the vehicles are used to compute the performance metrics.
The generation of spatial time frames is done on Matlab 2017a. Thereafter the blobs are classified using ecognition software. The ecognition software is a development environment for performing object based image classification. It is used to design rule sets or networks and is very useful especially in change detections, object recognition and satellite image processing. The result of various steps of the proposed method for a STF of the video is shown in Fig. 8. The structuring element used for the generation is disc with a radius of size 15. The threshold values used for the object classification are summarized in Table 3.

Results of various steps of proposed method using first data set [20] for incoming vehicle (a) RGB Frame, (b) HSI Frame, (c) Preprocessed Frame, (d) STF Generation, (e) Binary Top-Hat transform of STF, (f) Canny edge detection. (Bottom row): (g) Morphology operation and object detection, (h) Final detection and classification of vehicles.
Threshold values used for classification
Speed of the detected vehicles in STF is shown in Table 4. Some more results showing the input binary STF, one level classification and two level classifications are also shown in Fig. 9.

Output examples from both datasets (First Column): STF input. (Second column): Binay STF. (Third column): Level 1 classification. (Forth column): Final Classification.
Speed of vehicles
Comparative analysis with other methods
The performance of the proposed method is quantitatively analyzed using two different metrics: true Detection rate (TDR) and False Detection rate (FDR).True Detection rate is calculated as ration of correctly identified vehicles and total number of vehicles.
There may be some false detection in the frames as well. False detections are basically the object blobs which are not vehicles but identified as vehicles using proposed method. False detection rate is calculated as ration of such false detections and total number of detections.
The proposed system was also compared with different other method. It was observed that Background Detection Method (BDM) was giving low TDR and high FDR due to large number of misdetections and background of the videos is not always constant. Active Learning based methods (ALR) show better TDR as they keep on learning the changes in background. Proposed method was tested for two different data sets (PMD1 and PMD2).The comparative analysis is shown in Table 5. It can be seen that the proposed methods give better results as compared to other state of the art methods. Results are also summarized in the form of graphs in Figs. 10 and 11.
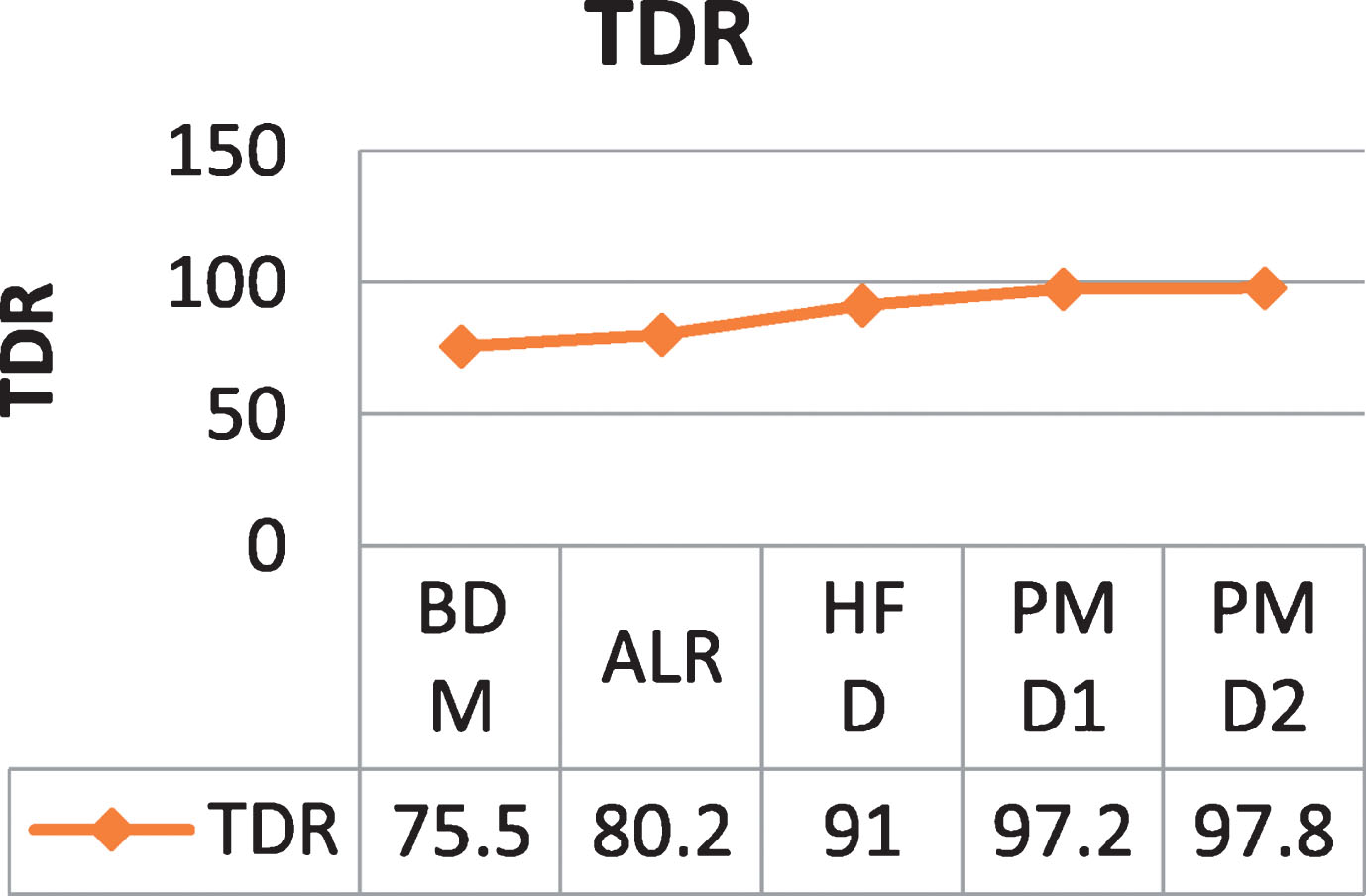
Comparative analysis of TDR of different methods.
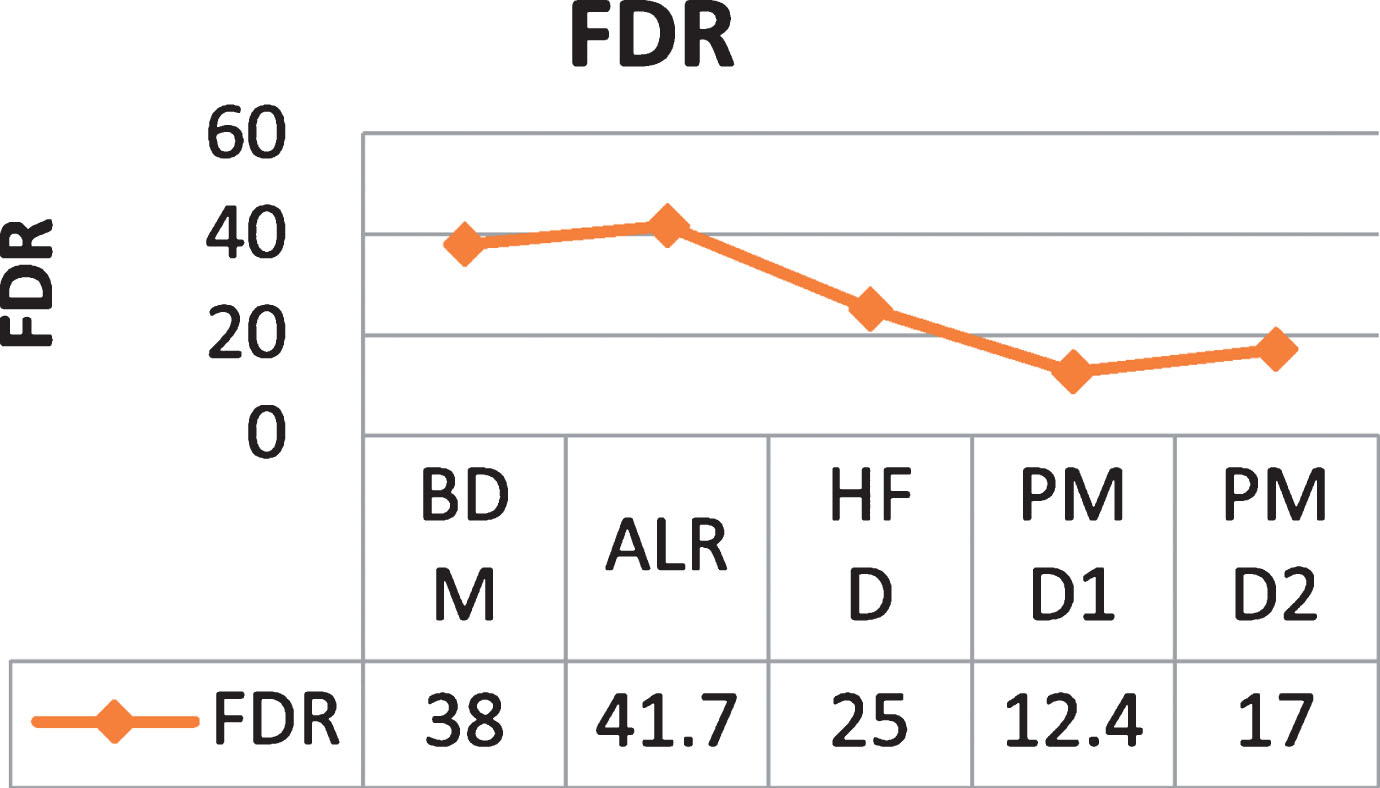
Comparative analysis of FDRConclusion.
In this paper, we proposed an automatic vehicle detection method from video frames. The detection was carried out in two steps. In the first step frames from the videos were extracted and preprocessed for applying detection methods. After that multiple spatial time frames are formed from the preprocessed frames. In the second step, binary morphology transforms of the preprocessed frame were calculated and object oriented segmentation and classification was applied to detect and then classify vehicles from the resultant components. Various experimental and quantitative analyses were done to compare the proposed method with other methods proposed in literature. It is observed that the proposed method gives better false detection rate and also improved TDR. Also, the method is based on simple object oriented features and is not complex in nature.