
Abstract
Sentiment analysis is one of the most important and interesting tasks in natural languages. A number of resources and tools have been developed for sentiment analysis of English, Turkish, Russian and other languages. Unfortunately, there were no data and tools available for sentiment analysis in Kazakh. The Dictionary of Kazakh sentiment words has been created during this study. In this work, we described the rule-based method using a dictionary of emotional words for sentiment analysis of texts in the Kazakh language, based on the morphological rules and ontological model. We studied the texts in Kazakh and determined the parts of speech that define the text mood. Based on the conducted studies, a lot of phrases were identified as determining the text polarity. This paper is an extended version of the paper published in [in: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), LNCS, 2017, pp. 669–677]. In addition to the original material, the paper includes additional rules for determining sentiment on a 5-point scale.
Introduction
Sentiment analysis or opinion mining in natural languages is one of the fastest growing technologies of natural language processing. Sentiment analysis, also called opinion mining, is the field of study that analyzes people’s opinions, sentiments, evaluations, appraisals, attitudes, and emotions towards entities such as products, services, organizations, individuals, issues, events, topics, and their attributes [14]. Sentiment analysis is considered as a major topic for companies, enterprises who might be interested in identifying opportunities within a new market. Emotions and opinions play a significant role in people’s everyday life and their decision-making process. The sentiment analysis tools have been widely accepted in the commercial and social fields. It can be noticed that the number of blogs, reviews, forums, web pages of social networks are growing by the day in worldwide network. Therefore, manual processing such a big amount of data becomes impossible, thus different linguistic and machine learning methods are used. Sentiment analysis had been applied on various levels, starting from the whole text level, then going towards the sentence and/or phrase and aspect levels.
For English a plenty of resources and systems have been developed for sentiment analysis of texts by now [14,16]. A number of researches are conducting on sentiment analysis for Russian [7–9], Turkish [3,11,28], Spanish, Arabic [15,20] and other languages. For Spanish [21] proposed an approach to the subjectivity detection on Twitter micro texts that explores the uses of the structured information of the social network framework. For Arabic proposed a semantic approach to discover user attitudes and business insights from Arabic social media by building an Arabic Sentiment Ontology that contains groups of words that express different sentiments in different dialects [20].
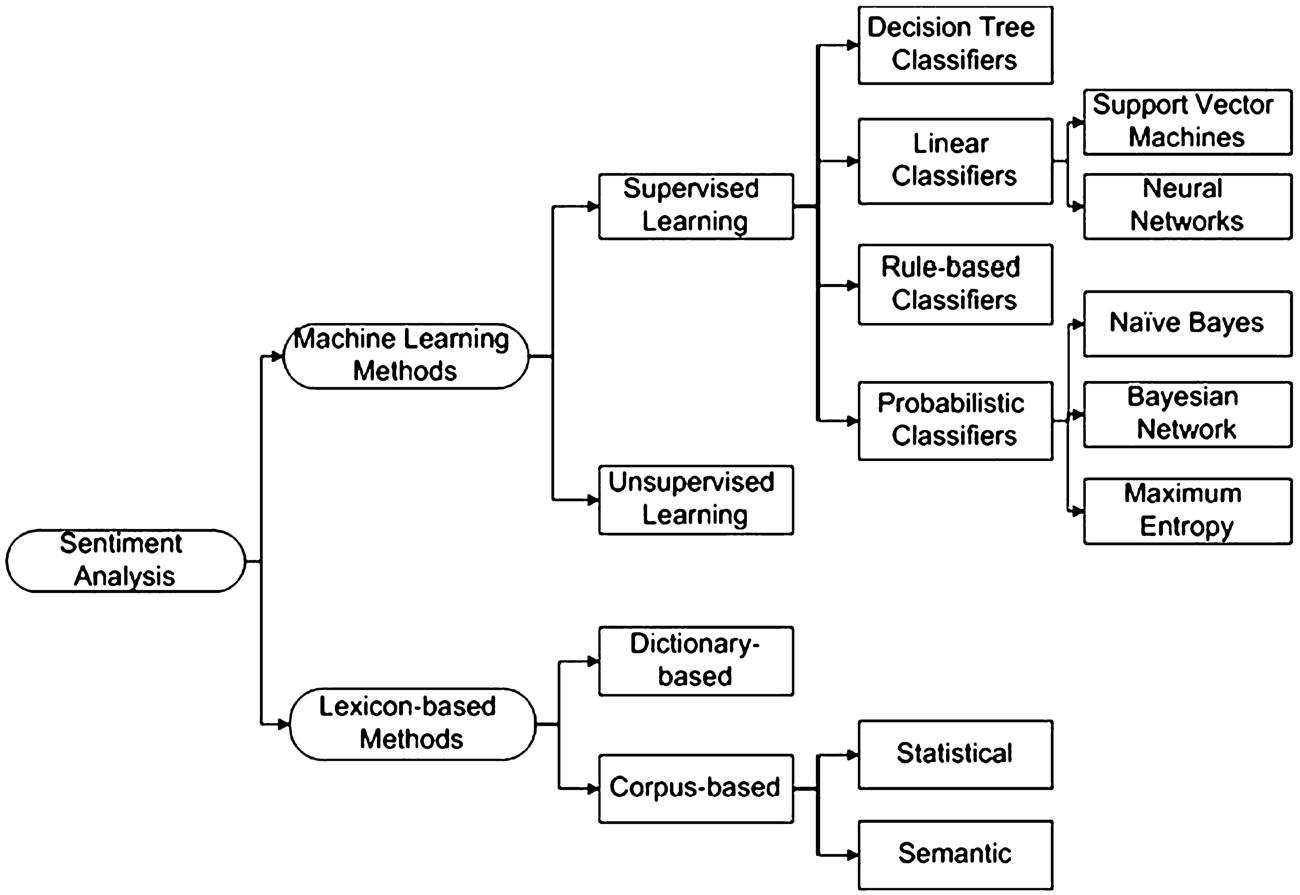
Sentiment analysis methods.
The sentiment analysis of texts written in Kazakh language has been studied little. There are some works on sentiment analysis for dual languages, Kazakh and Russian [1,19]. [19] described modern approaches of solving the task of sentiment analysis of news articles in Kazakh and Russian languages by using deep recurrent neural networks. Thereby, research shows that good results can be achieved even without knowing linguistic features of a particular language. Also a deep neural network model that uses bilingual word embedding to effectively solve sentiment classification problem for a given pair of languages has been proposed. The authors apply this approach to two corpora of two different language pairs: English–Russian and Russian–Kazakh. It is shown how to train a classifier in one language and predict in another. This approach achieves 73% accuracy for English and 74% accuracy for Russian. For Kazakh sentiment analysis, propose a baseline method, that achieves 60% accuracy; and a method to learn bilingual embedding from a large unlabeled corpus using a bilingual word pairs [1].
Computers are beginning to acquire the ability to recognize emotions. In 1995 Rosalind W. Picard [17] reported about key issues in “affective computing”, computing that relates to, arises from, or influences emotions. Since then, a lot of research has been carried out. Many studies are related to the emotion recognition from texts. [5] suggest an approach for emotion recognition using web-based similarity and also propose an emotion ranking model based on semantic proximity measures, e.g. confidence, PMI, PMING.
Today, there are a lot of mobile devices, such as smart phones, tablets, cameras and PC around the world. Also, a lot of applications for audio, video posting, chats are implementing day by day. Accordingly, text, audio and video information are increasing. Because of this, the task of extracting emotion from text, image, audio and video information becomes an important task.
The emotion is extracting not only from texts, but also from audio and video content [4,18], from images [13]. Such applications can be used in as social media marketing, brand positioning, election and financial prediction.
This work can be considered as an introduction and an attempt to apply the linguistic approach for sentiment analysis of the texts written in the Kazakh language. For that reason, this paper describes the rule-based methods used in sentiment analysis and approaches used to determine the sentiment of Kazakhs sentences by formalizing the morphological rules.
According to the work described in [14], the automatic analysis of a sentiment of texts in the natural language is carried out by applying the methods such as machine learning methods and lexicon-based methods (Fig. 1).
The sentiment analyses based on machine learning methods are “trained” on a collection of pre-marked texts. These methods include a support vector machine (SVM), logistic regression, naive Bayes classifier, maximum entropy, k nearest neighbor (k-NN) and other methods.
Lexicon-based methods usually use morphological analysis, specifically designed sentiment dictionaries of words and phrases as well as sets of linguistic rules and corpora [22].
Determining the sentiment of phrases in Kazakh language
Determination of sentiment of sentences in Kazakh language is based on a classification of texts by five features [−2..2]: very negative (−2), negative (−1), neutral (0), positive (1), very positive (2). For this purpose, a dictionary of emotional Kazakh words was developed which participates in determining the polarity of the text. The dictionary was manually created and marked by polarity on a 5-point scale [−2..2]. The dictionary contains about 11000 emotional words and phrases [23]. In Kazakh language the polarity of a phrase is given by parts of speech as noun, adjective, verb and adverb. After that, morphological rules of parts of speech are formalized that are involved in determining the polarity of the sentence: words and/or phrases are extracted from the sentence, which contains evaluative words. The overall sentiment of the text is evaluated according to the sentence/phrase polarity.
Adjectives mainly determine the sentiment polarity of the text, and the noun plays a role of an aspect (object) of discussion. From the extracted phrases we can determine the polarity of the whole text. The polarity of evaluative words might depend on the context and subject area. Also, the polarity can be changed or intensified depending on adverbs, verbs and conjunctions. The following phrases can be used to define the polarity:
[NOUN] + [VERB]
[NOUN] + [VERB] + [Negation]
[ADJECTIVE] + [NOUN]
[ADJECTIVE] + [Negation] + [NOUN]
[ADJECTIVE] + [VERB]
[ADJECTIVE] + [VERB] + [Negation]
[Not ADJECTIVE] + [VERB]
[Not ADJECTIVE] + [VERB] + [Negation]
[ADVERB] + [ADJECTIVE]
[ADVERB] + [NOUN];
For determining of morphological features we used work described in [26]. In that work we explained how semantic hyper-graphs are used to describe ontological models of morphological rules of the Kazakh language. On the basis of this work, morphological analyzer was built. This morphological analyzer is used for extraction of morphological information from texts.
There is a growing demand for information systems-oriented interpretation of human language. These systems are designed to be capable of understanding the intentions and opinions of the author with minimal human intervention. In the article [10] entitled Considerations on Ontologies Construction, the author identifies the challenge the interpretation of heterogeneous information by automated tools and analyzes possibilities of using ontology to resolve these issues. The combination of ontological model and natural language rules can improve performance of sentiment analysis. Ontology can be used to solve various tasks [2,6].
Ontology is a powerful and widely used tool to model relationships between objects belonging to various subject fields. In the context of computer and information sciences, an ontology defines a set of representational primitives with which to model a domain of knowledge or discourse. The representational primitives are typically classes (or sets), attributes (or properties), and relationships (or relations among class members). The definitions of the representational primitives include information about their meaning and constraints on their logically consistent application.
This formalism determines ontology O as triple
In Fig. 2 presented part of ontology model for determining the sentiment of phrases in the Kazakh. For example, if we have some collocation, it can consist of adjective and noun (verb). The ontology formalism – O(adjective, has_polarity, adjective with positive(negative) orientation); O(collocation, has_polarity, sentiment).

Ontology for determining the sentiment of the collocation.
Ontology has allowed us to present in a model form of phrase with sentiment for further use of OWL in RDF schema. In addition, construction of semantic queries in SPARQL language based on the rule presented in Part 4.
We formalized rules for defining the phrases sentiment in the Kazakh language and are described using production rules. For this, we introduce the following meta notations (Table 1).
Meta notations
Meta notations
The production rules for determining the sentiment of an adjective and noun phrases are given below in the sequential form
If the extracted word is a positive noun, and the next word is a neutral verb, then the sentiment of this phrase is positive.
Example, toi (1) boldy (0) (there was a wedding).
If there is a negation word “emes” (not) between the negative adjective and noun, then the sentiment of this phrase is become positive.
Example, zhaman (negative adjective) emes (negation) kino (noun) (movie is not bad).
If the found word is an adjective with positive polarity and the next word after it is a neutral verb, then the polarity of this phrase is positive.
Example, zhaksy (positive adjective) isteidi (verb) (works good).
If a noun follows by a verb phrase, then the word coming after the verb should be checked. If the noun is positive and there is a negation word (emes/zhok (not)) after verb, then the sentiment of this phrase is negative.
Example, adilettilik (positive noun) ornagan (verb) emes/zhok (negation) (there is no justice).
If the adjective is very positive and the next word is a neutral noun, then the sentiment of this phrase is very positive.
Example, ardaqty (positive adjective) ana (noun) (honorable mother).
If the adjective is very negative and the next word is a negative noun, then the sentiment of this phrase is very negative.
Example, qatygez (very negative adjective) terrorist (negative noun) (violent terrorist)
Program fragment. Example for collocations [adjective] + [verb], [adjective] + [noun], [adverb] + [adjective].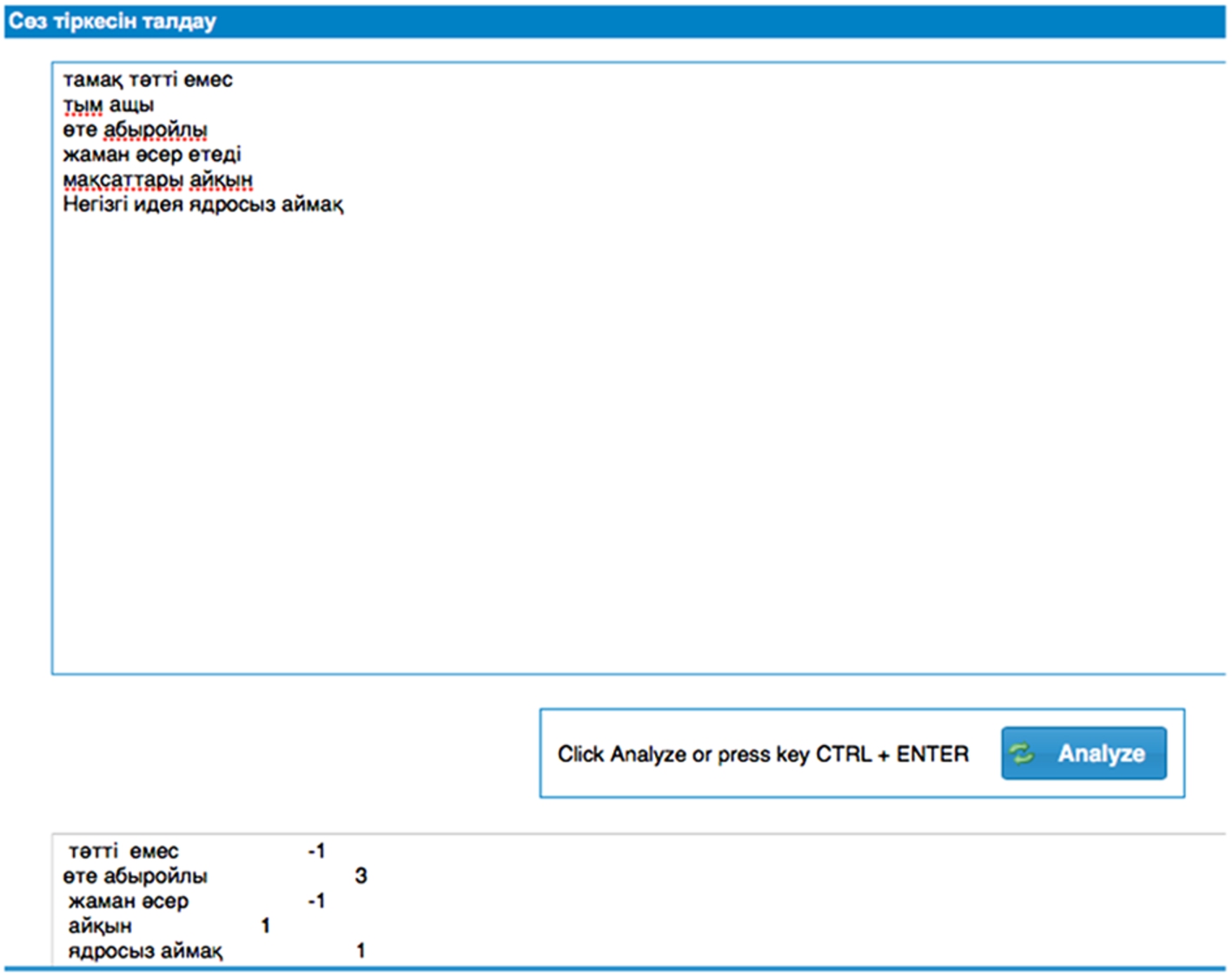
If the superlative or comparative adverbs comes before noun with negative sentiment, then the sentiment of this phrase is very negative.
For example, nagyz (adverb) shaitan (negative noun) (real devil).
The polarity of the whole text is defined as the arithmetic average of the values of the polarity of lexical units (sentences) and the rules for their combination.
In [24] the simple and extended fuzzy evaluation models are described. The technique of fuzzy inference associated with the estimation of the general level of the hotel state on the basis of the calculated criterion for each aspect is proposed. The criterion is measured in percent and is derived on the basis of fuzzy subjective estimates of the hotel services in Kazakh.
The implemented system is based on the described rules for Kazakh language. The fragment of the implemented program is given in Fig. 3.
Explanantion for Fig. 3.: 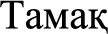
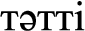
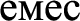 (the meal is not tasty),
(the meal is not tasty), 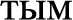
 (too spicy),
(too spicy), 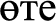
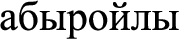 (highly respected),
(highly respected), 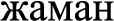
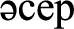
 (bad influences),
(bad influences), 
 (have clear objectives),
(have clear objectives), 


 (main idea is a place without nuclear)
(main idea is a place without nuclear)
In addition, the sentiment might also depend on the conjunctions between words or sentences
if there are connecting conjunctions, the sentiment does not change;
if between words or sentences comes dividing or adversative conjunctions, then semantic orientation of sentence changes to opposite. For example, bul kampit tatti, birak katty eken (this candy is tasty, but hard).
In Table 2 we compare the methods implemented for the Kazakh language.
Results
Results
As can be seen, our method gives good results.
In this work, we reviewed the ontology-based sentiment analysis of Kazakh phrases. Ontology has allowed us to present phrases with sentiment in a model form and for further use of OWL in RDF schema. In addition, ontology allowed constructing semantic queries in SPARQL language. Queries are based on the formal rules determining sentiment of phrases in the Kazakh language.
We also plan to apply this method for defining sentiment of sentences ant text in the Kazakh language in the future. For this purpose, we will consider the conjunctions (and, or, but, etc.) and apply different logics to formalize them. Also we will expand the ontological model to determine the sentiment polarity of texts in the Kazakh language.
This work describes the first attempts to extract the sentiment of texts on very positive/positive/neutral/negative/very negative. In the future, we plan to classify the texts not only by polarity, but also extract the emotion of the author of the text by using psychological models (Ekman, Plutchik).