
Abstract
Automatic logo detection and recognition is significantly growing due to the increasing requirements of intelligent documents analysis and retrieval. The main problem to logo detection is intra-class variation, which is generated by the variation in image quality and degradation. The problem of misclassification also occurs while having tiny logo in large image with other objects. To address this problem, Patch-CNN is proposed for logo recognition which uses small patches of logos for training to solve the problem of misclassification. The classification is accomplished by dividing the logo images into small patches and threshold is applied to drop no logo area according to ground truth. The architectures of AlexNet and ResNet are also used for logo detection. We propose a segmentation free architecture for the logo detection and recognition. In literature, the concept of region proposal generation is used to solve logo detection, but these techniques suffer in case of tiny logos. Proposed CNN is especially designed for extracting the detailed features from logo patches. So far, the technique has attained accuracy equals to 0.9901 with acceptable training and testing loss on the dataset used in this work.
Introduction
For recognition of an organization a unique logo is used. These logos reflect the products, services and articles produced by a company. There are numerous real-world applications of logo recognition. In marketing, it can be used for recognition of product’s brand for intellectual property protection, marketing analytics and digital advertising. In smart transport management system it can be used to recognize vehicles [1]. Logo detection can be utilized for online product-brand management like in social media viz. Instagram, Pinterest etc. [2, 3], it is also used for checking errors in car advertisements [4]. Logo recognition in images and videos is the key problem in various domains like contextual advertisement placement, copyright infringement detection, vehicle logo detection for automated traffic control system [5].
In this paper, we propose patch-based convolutional neural network (Patch-CNN) for logo recognition. We draw patches of input volume and feed to Convolutional Neural Network by applying preprocessing and thresholding. In deep learning applications the transfer learning is commonly used. The advantage of transfer learning is that we can use a pre-trained network as a starting point to learn new task. The use of transfer learning makes fine-tuning a network, more efficient and easier than training a network with randomly initialized weights from start. In computer vision the logo detection is special form of object recognition [3–7]. Logo detection is complex task as compared to general object recognition. The logo recognition becomes complex due to several reasons such as very tiny size of logo, occlusion effects, lightening effects, rotation, transformation etc. The problems faced during logo detection are addressed by several visual descriptors in literature like SIFT [8, 9], Hough-transform [10], DWT [11]. These descriptors are good in capturing adequately discriminative local features with invariant characteristics to geometric or photometric transformations and are robust to occlusions. Generally, SIFT is known to be a popular technique for logo recognition problem. Due to its efficiency and accurate feature extractions it has substituted the methods like Fisher classifiers [12]. In last few years, Logo detection has been investigated extensively and several algorithms have been presented. For example, Bianco et al. [13] presented a recall-oriented logo recognition system on the basis of logo proposals. These region proposals were then fed to CNN and checked by employing different training options to get state-of-the-art results. Fast Convolutional Neural Networks (FCNN) is applied in [14] for logo recognition. The misclassification problem arises when logo object appears in small size in case of large size images with worse conditions and many other objects clearer than logo. Such images may contain other objects that may be classified as logo. We propose patch-based CNN for logo recognition. Patch-CNN takes tiny patches of logo or logo parts. Small patches are drawn from input images and patches regarding logo region and no logo region are separated by means of ground truth annotations. Then these small patches are feed to tiny CNN for classification. This strategy significantly improved the recognition rate and computational load too. Proposed CNN have less parameters as compared to state-of-the-art methods for logo recognition. So far, the patch-CNN is more accurate than other techniques. For logo recognition we have also utilized the capabilities of AlexNet and ResNet models. Key features of both these models include their strong robustness, and their superior performance. In the present work we exploit the capabilities of AlexNet and ResNet due to their deep learning ability for feature extraction. AlexNet has the advantage of better understanding the visual similarities present in real images.
Our Contribution: We develop a tiny convolutional neural network (Patch-CNN) for logo recognition with comparably less parameters to solve misclassification of small logos or any part of logo. We also explored benefits of transfer learning for logo recognition by using AlexNet and three versions of ResNet. We developed a small dataset by querying to Google images search facility to check the recognition potential of proposed CNN against images other than dataset.
This article is organized as follows: Section 2 reports the closely related work for logo detection. Section 3 contains proposed methodology. Section 4 explains the transfer learning approach used for logo recognition. Section 5 presents experimental results, discussion and analysis of results. The final section 6 will draw the conclusion of the work.
Related work
With the popularity of e-business, the business owners realized to put their products through internet to customers. Because of penetrating effects of social media on public, many companies required to predict popularity of their products form social media and e-business web pages. This can be done by detecting logo of the company on the product available on internet. In the current section our aim is to provide precise knowledge about the existing techniques in the area of object detection and recognition in various modes.
Image recognition in the domain of computer vision have emerged the effective applications using CNN based techniques of Deep learning models since 90 s [13–17]. For many real-world image scenarios like image segmentation, object detection, object classification the deep neural networks are utilized. In object detection domain, Logo recognition problem is getting more attention since last few years. For object detection and recognition Deep Convolutional Neural Networks (DCNN) have revealed excellent progress. Krizhevsky et al. [18] introduced the deep convolutional network based model aimed to classify high resolution images. They have tested their technique on huge database having more than 1.3 million images. This model was called as AlexNet model and it classifies the images in more than 1000 classes. It is one of the well-known works aimed to classify the real-world images. Logo detection and recognition is special case of object detection and recognition, it has been extensively studied in literature, even though most of the existing logo detection methodologies use very small dataset and there are only few publicly available dataset [13].
In last few years, logo detection has been investigated extensively and several algorithms have been presented. Local visual descriptors like Hough-transform [10] Discrete Wavelet Transform (DWT) [11], Scale Invariant Furrier Transform (SIFT) [8] have been proved to be able to capture sufficiently discriminative local elements with invariant properties to geometric or photometric transformations and are robust to occlusions. The orthodox approaches for logo detection were based on key-point based detectors and descriptors [19]. These techniques are best to handle well defined shapes. For object detection, in context of deep learning, the Fast Region-based Convolutional Network is the most prominent solution presented in [20]. They have improved the efficiency of training and testing phases. The accuracy was enhanced by employing some innovations. The technique is based on single stage training due to the usage of multi-task loss. All the layers of network model are updated in single stage training. The advantage of this technique is that it doesn’t require any extra disk space for the feature caching. In this approach they also utilized the concept of object proposal which remarkably enhanced the detection. However, in past it was quite costly to be examined and now it is practically achievable with Fast Region-based Convolutional Neural Network Fast R-CNN. Currently deep learning approach has made great breakthroughs in field of computer vision [5]. CNN based approaches have produced excellent results in computer vision tasks and in object detection [21].
In [15] a region proposal network for the logo detection is presented. The proposed technique extracts the convolutional features of whole image with detection network. They have generated high quality region proposal, which has enhanced the detection accuracy. The proposed technique predict simultaneous object bounds and objectness scores at each point is collected. Finally, the generated region proposals are passed to Fast R-CNN for the detection purpose. Highly scalable technique for the logo detection from images is proposed in [16]. This method extracts local features from special layouts of logo image. A proper method is deployed to encode and index the spatial layouts of local features. To reduce the rate of false positive detection and to derive the quantized representation of specific regions in logo image features and spatial structures like edges and triangles are analyzed. This technique proposes cascaded-index for the recognition of multi-class logos. The authors have also made a significant contribution by providing a benchmark logo dataset namely FlickrLogos32. This dataset is comprised of 32 different classes containing training, testing and validation sets. So far, this technique is properly evaluated, and it produced highly effective and precise results. We propose a tiny CNN with small number of parameters with superior accuracy. Patch-CNN has less training time with negligible training and testing loss. We have also exploited the abilities of AlexNet and ResNet for the logo detection problem. ResNet mode is capable of excellent learning. We take the advantage of transfer learning [22] for both of these models. Transfer learning is the suitable approach to confront the small dataset.
Patch-CNN
Early logo recognition approaches are either based key points methods [1] or features extraction followed by generation of key regions. Our solution is based on CNN (Fig. 3) specifically designed for precise logo recognition based tiny patches (Fig. 2). Usually, CNNs are typically employed for classifying entire image. Instead of classifying the whole logo image, we intend patch-based classification in this work. Mechanism of creating small patches is explained in section 3.2. In the proposed technique patches are passed to the classifier which relate the patch with original image and perform classification. In preprocessing, we perform histogram equalization for making CNN more robust against worse imaging conditions. Our Aim is to develop a method that recognize the logo identity even having small sized logo or small patch (incomplete) of logo in real world images. Extracted patches are trained on CNN model. The testing is performed by querying the specified test set of Logos32plus dataset. This system is tested on different images some test images are obtained from Google image search (Fig. 4) to find the recognition potential for images other than the dataset. Tiny dataset for testing is developed from these images. We also explore benefits of using pre-trained models like AlexNet and ResNet for logo recognition task. For transfer learning, we project ROIs and resize them to input size of employed pre-trained model. Algorithm of patch-based logo recognition system is as follows. START Load Dataset Dataset ←Logos32plus Read Images (i) Count Classes J←32 Preprocessing a. For each image i. Apply Histogram equalization ii. Divide each image in to 100×100×3 patches iii. If Patch size < 100×100×3 a) Pad Zeros Patch Selection Select logo labeled patches with corresponding logo class Select two times size of selected logo patches corresponding no logo So, logo vs no logo patches ratio← 2:1 Total classes J ← 33 (32 logo classes +1 no logo class) Split Dataset (Selected logo and no logo patches) 70% ←Train set 30% ←Validation and testing sets Load proposed patch-CNN Training Model Min Batch Size←10 Epoch ←40 Initial Learning rate ← 1e-4 Testing and Validation Phase I← 30% of Dataset (Selected patches) Phase II← Queries to Google image search (350 images) Divide each image in to 100×100×3 patches If Patch size < 100×100××3 Pad Zeros Check all patches against trained model Highlight the patch(s) having logo Compute Evaluation Parameters END
Each logo portion was segmented into small patches in sliding window fashion by taking benefit from ground truth annotations. Each patch lying in ground truth area was given an ordered unique-identity value. This value reveals its logo class as well as its rejoining order in ascending order. The hypothesis behind the patches creation was the alleviation of memory limitation of GPU and solve the problem of misclassification.
So far, the training mechanism is concern, the stream of patch sequences were trained to get the feature sets separately. Similarly, testing was performed by first segmenting logo images into fixed sized patches. Then patches were passed to CNN for prediction.
Testing of image was more critical as it was impossible to put whole patches from a test image into a single testing batch due to limited memory of GPU. Hence, we designed a simple mechanism of dividing the patches into several batches. The model gives the patch level prediction which was then projected back on the image at original scale after processing all patches of a test image.
For which we use simple sliding window mechanism [23] which moves sliding window over test image to produce patches of size equivalent to that of training patches. This mechanism resulted in large number of patches, passed to the trained CNN for computing multiclass probability distribution regarding all patches of test image. The comprehensive probability values for all logo classes were used to make final decision (top 1) about presence of specific logo over test image. Simple heuristic approach was applied to finally classify the test image. The patches matching with less than five percent as well as no logo patches were dropped. Finally, predominant label was assigned to most frequent class.
As Patch CNN was trained using small patches of logos, it detected the small patches more accurately as it founded the alike features in the small test patch very easily. The benefit of patches was realized when the small logo were detected by CNN because there is comparison of patch to patch features instead of features from whole image.
Histogram equalization
We apply histogram equalization on images with lightening occlusions. Worse imaging conditions and lightening occlusions often disturb the robustness of CNNs. Histogram equalization enhance the contrast to make it easier to analyze or improve visual quality.
In histogram equalization [24], the contrast and dynamic range of an image is altered. Image is modified such that the histogram of intensities is converted to desired shape. For this, cumulative distribution function is used as mapping function. This function changes the intensity levels such that histogram peaks are stretched by compressing the troughs.
Suppose, X = {X (i,j)} representing an image consisting gray levels L as {X0, X1, X2, ... .,XL - 1}. X (i, j) representing image intensity at (i, j). The probability density function f (Xk) can be defined as:
Notably, f (Xk) is related to histogram of image, which represents specific amount of pixels in the image with intensity value Xk. Hence, plotting nk vs Xk is the histogram of image X. In Equation (1), nk is the interval that level Xk appearing within input image X, where n means the total samples within image. On the basis of probability density function (Equation 1), we can define the cumulative density function as:
In Equation (2), for k = 0, 1, 2, ... ., L –1, Xk will be equal to x and by definition C(XL - 1) = 1. Histogram equalization uses the commutative density function for mapping image into dynamic range i.e. (X0, XL - 1). Figure 1 shows the original image and restored image.
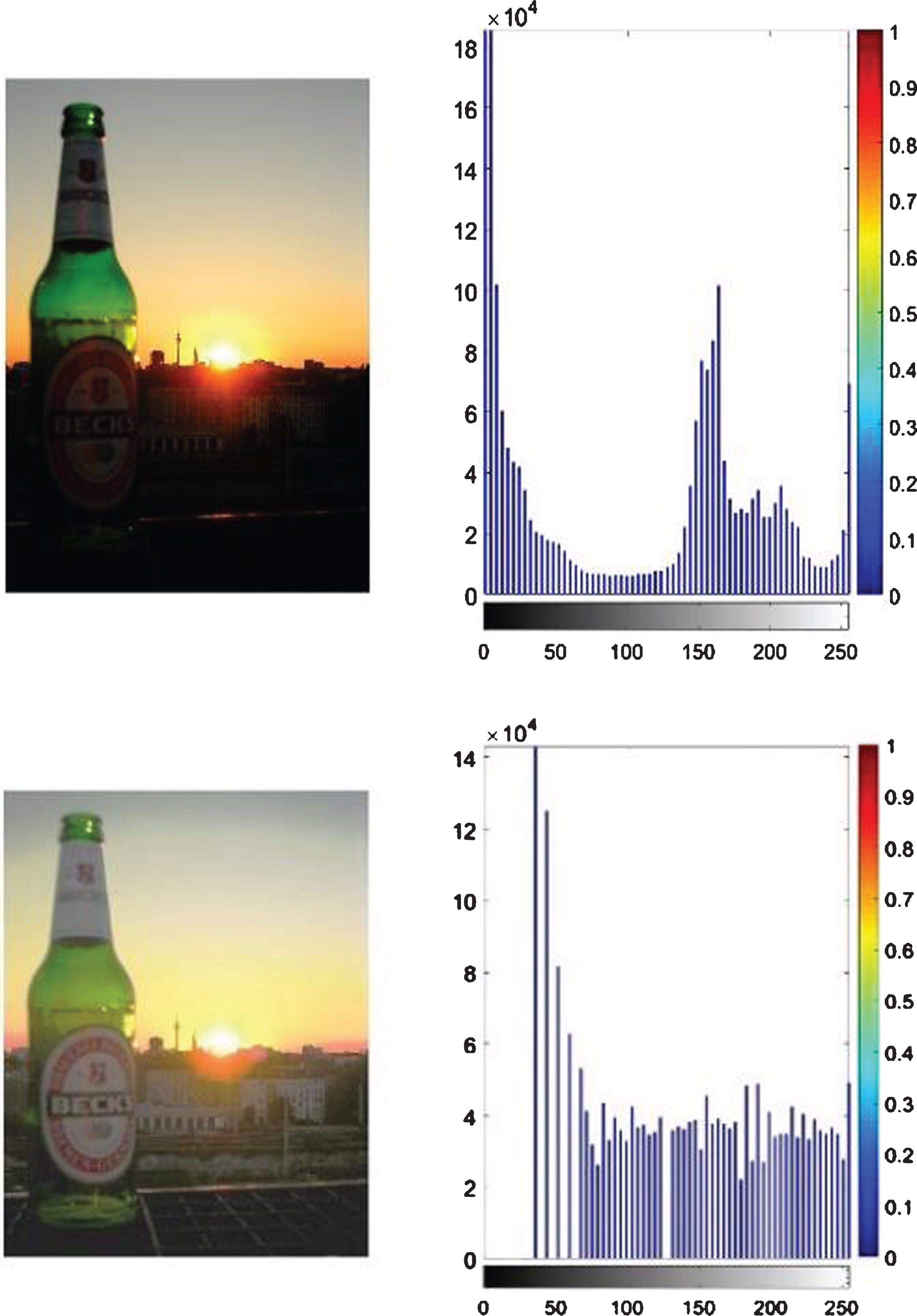
(a) Original image and its histogram. (b) Histogram Equalized Image and its histogram.
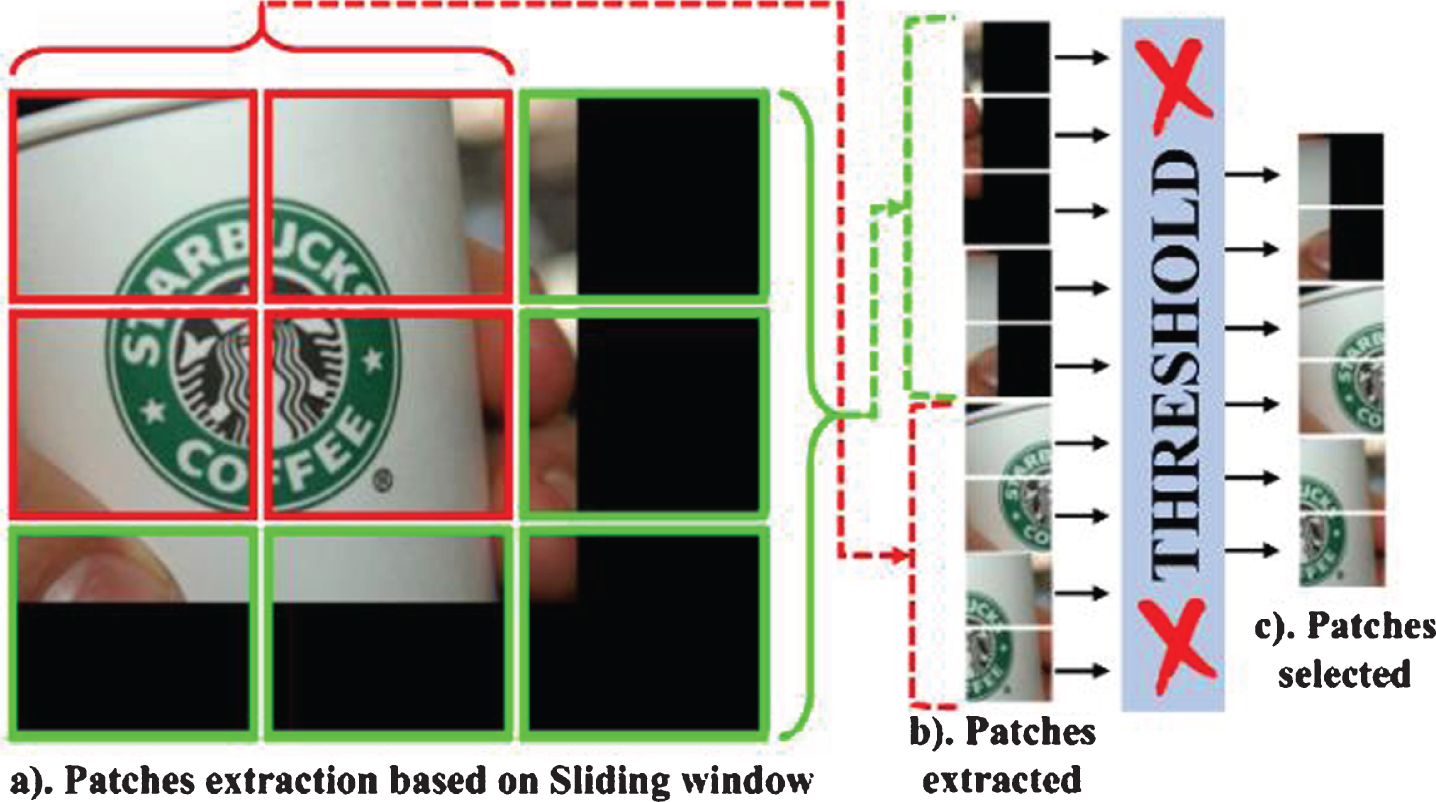
(a) Extraction of patches using sliding window. (b) Extracted 100×100×3 Patches. (c) Selected patches after applying threshold.

Patch-CNN architecture.

Dendrogram showing query sets for retrieving images. For retrieving images of HP, we used query as “HP logo business events” and for Becks images we used “Becks Logo Bear Cold drink” and so on.
Patches are drawn from entire images of logos32plus dataset. Images of all classes are divided into 100×100×3 patches. As images are of varying size so without disturbing the original size of image these patches are generated. If the last patch remains less than 100×100×3, patch is completed by zero padding. Logo and no logo patches are separated by using ground truth annotations. This mechanism resulted in large amount of no logo patches as compared to logo patches. We randomly picked no logo patches in 1:2 (half of all logo patches) as being more than enough for targeting the logo. The logo and no logo patches are then passed to convolutional neural network.
Patch-CNN architecture
The architecture of proposed CNN for Logos32plus consists of 18 layers. Aim was to develop a model that can be trained on ordinary GPU i.e. 2/4GB memory within less time. Input layer takes 100×100×3 images (logo and no logo patches). Model consists of four convolutions and two fully connected layers. Each convolution layer is enclosed by max pooling and batch normalization. First convolution layer computes 16 filters of size 3×3 while other three convolutions compute 64 filters of 3×3 size.
Hence convolutions did not change the size of image. All pooling layers have pool size of 6×6 with stride 2 and zero padding. Each pooling layer halved the size of image. Batch normalizations are computed by taking epsilon = 0.00001. Afterward, we have two fully connected (FC) layers i.e. each FC is enclosed by 0.5 dropout. Fully connected layers contain 33 neurons and finally we have final Softmax classifier.
So far idea about size of network, our network has 3.2×105 parameters which are less than AlexNet [25] and ResNet [26] having 6×107 and [17] parameters. Hence, the designed neural network for Logo recognition is less likely to over fit. We trained this model on Logos32plus.
Ablation test was performed on a separate set collected from whole dataset used in the final experiment. We got similar accuracies on the separated development set. Optimally, Patch-CNN has smallest number of parameters as well as fast training time as compared to AlexNet and ResNet.
There are several images in the dataset in which logos were appearing in very small size. Generally, logos present in the small size as compare to other objects like road, greenery, table etc. in the whole image. The aim was to develop such method that also tackle the misclassification of logos when they appear in small size or partially appear within a frame.
Training Patch-CNN
The patches extracted from entire dataset are randomly divided into 70:30. Seventy percent of all patches from each label are used for training and remaining thirty percent is spared for testing.
So far, no logo patches are additionally labeled as no-logo. Hence the total number of labels becomes 33. The extracted patches of 100×100×3 are feed to CNN to get the precise features (Fig. 8a).
Testing
The testing is performed in two phases. First the thirty percent spared set was passed to trained CNN. Secondly, the manual queries regarding each label of dataset are given to Google images search and top 10 images are retrieved. These images are converted in to patches by following mechanism explained in section (Logo/Nologo Patches). This tiny testing dataset is then passed to train CNN to check out the recognition potential. The queries composition mechanism is shown in Fig. 4.
The figure shows different queries composed for retrieving images i.e. query a is general query for retrieving images of nine brands attached to it. While the Queries b, c, d, e, and f are individually combined with subset of query a to make composite query. Each query set is followed by the desired brand name.
Transfer learning
Transfer learning is the improvement of learning in a new task through the transfer of knowledge from a related task that has already been learned [22]. Logo detection has several applications in various domains. Numerous techniques for logo detection are reported in literature [9, 27]. After successful implementation of patch-based recognition pipeline, we also explore the logo recognition by transfer learning. Transfer learning framework used for logo recognition is presented in Fig. 7. Logos-32plus data set is used in this work.
Data set
Logos-32plus dataset was introduced in 2017. Due to its suitability for applying deep learning approaches on real-world problems we have used it for our framework. The logos-32plus dataset is the extension of FlickrLogos-32 dataset. Logos-32 plus has same object categories and classes as FlickrLogos-32. Logos-32plus dataset has also larger co-cardinalities i.e. 12312 instances.
Preprocessing
The preprocessing phase include following steps:
Precise ground-truth logo annotations
Despite that train set and test set are given in the dataset we have used randomized split for better performance of classifier. The real potential of image classification techniques can be judged when the train and test set are selected randomly. So, we first randomly split the 70% of images for training and get the associated ground truth values given in the dataset. These ground truth values specify the position of logo object as well as relevant class. These ground truth values are rectangular portions around logo objects.
Region of interest logo annotations
It is essential to extract the region of interest (ROI) in this case logo portion only. ROI projection is only applied on train set. The extracted ROIs (Fig. 5) are then labeled against associated label or logo class. In literature region proposal generation and checking the generated region proposal is widely reported which is time consuming. That is why we just use ground truth values to extract the region of interest.

ROI projection using ground truth annotation.
The variation in size of the region of interest may cause over-fitting in training phase. Over-fitting occurs in different models when different sizes of inputs are passed to the model. Therefore, to tackle this issue we first resize all the images in the train set to same size of 227×227×3. It is also requirement of relatively all deep learning models to input the same sized data. Hypothetically there should be same input probability for each class so that we can predict the actual potential throughout the training process.
AlexNet architecture
AlexNet is the most popular convolution neural network (CNN) for computer vision. The AlexNet perform better than its competitors [28]. Proposed model is based on 25 layers, each layer performs a specific task based on required functionality. The proposed model works in sequence of layers. Each layer takes input volume and performs function assigned to it and passes output to the next layer. Next layer get input. The layers of model work for obtaining features gradually. The layers may repeat in the model. The repeated layer has different filters, but its operation is same at all its instances. AlexNet has 6×107 parameters.
Res-NET architecture
After the celebrated victory of AlexNet at the ILSVRC2012 classification contest, deep Residual Network was arguably the most groundbreaking work in the computer vision/deep learning community in the last few years. ResNet makes it possible to train up to hundreds or even thousands of layers and still achieves compelling performance. Residual Network (ResNet) contains several residual blocks which provide a shortcut link among layers. These shortcut connections are used to train hundreds of layers and to achieve robust performance. ResNet was designed for the classification and analysis of very large-scale datasets. ResNet has different flavors with different number of layers including ResNet 18, 50 and 101 convolution layers.
ResNet adopts residual learning to every stacked layer. ResNet building block shown in Fig. 6. is defined as:

Residual Learning.
In Equation (3), x is the input while y is the output vector of the layers considered. Here x and y are the input and output vectors of the layers considered.
The function F(x, Wi) represents the residual mapping to be learned. The two layers in Fig. 6 are represented by F = W2σ(W1x) in which ReLU is represented by σ. To simplify the notations biases are omitted. The element wise addition and shortcut connection is performed by F + x operator. In this work we have adopted nonlinearity after the addition of i.e. σ(y) shown in Fig. 6. In Equation 1 the shortcut connection does introduce neither extra parameter nor computation complexity. Residual network is an attractive practice as compared to plain networks. Both plains and residual networks having same numbers of parameters, computational cost, width and depth. In Equation (4), the dimensions of x and F must be equal in Equation (3). For matching the dimensions, we can perform linear projection Ws by the shortcut connection.
The function F(x,Wi) illustrate residual mapping which is going to be learned.
We have used the ground-truth values corresponding to logo images to crop the image (Fig. 8b). As a result, the required logo portion is obtained. All the cropped images are resized to 227×227 pixels (RGB) images by using the default image resizing function in MATLAB. The images are resized because default input size of AlexNet is 227×227×3.

Transfer learning framework for logo recognition.

(a) Training pipeline for patch-CNN. (b) For transfer learning.
Out of the 25 layers of AlexNet we replaced the layer number 23, 24 and 25 and these layers were named as “Fully connected layer, a Softmax layer and a Classification layer”. We have given the size of fully connected layer according to our data which is according to our dataset classes. In our case there are 33 classes, so the size of fully connected layer is set to 33 (32 classes +1 no logo patches). The ResNet accept input images of size 224×224×3. Image resizing was simply performed by the augmentation function. ResNet has one main issue that it requires same number of images in each class. So, we kept 182 images per class.
Main objective of this work is to evaluate the performances of proposed patch-CNN and pre-trained models for logo recognition. Training is performed on small GPU (GeForce GTX 750 Ti with 2GB memory) installed in Dell Precision T3500 with Intel Xeon W3530 / 2.8 GHz processor. For enabling the benchmark study, we followed standard setup for partitioning the dataset into training and testing i.e. 70:30. For Logos32plus, we randomly split 70% images for training and 30% for testing. The proposed patch-CNN model is specifically trained and tested for logo patches referring specific class. Testing is also performed by querying some images collected from Google image search.
The experiment for patch-CNN was conducted on 40 epochs as being more than enough since corresponding accuracy becomes linear at 40th epoch. The results of transfer learning for logo recognition are also explored by engaging state-of-the-art deep learning models i.e. AlexNet, ResNet-18, ResNet-50 and ResNet-101. Same data partitioning is used for transfer learning experiment. The corresponding accuracy becomes relatively linear after 40th epoch in case of all models.
By training the model with high quality images may cause miss-classification in case of images with worse conditions in test set. Such images may contain other objects that may be classified as logo. To overcome this problem, we applied histogram equalization on such images in train set so that CNN better recognize such images. We tested our models by training and testing five times and getting results in five turns. We then calculated evaluation parameters for each of five turn. Finally, we take average of each evaluation parameters values against five turns.
Evaluation criteria
Various evaluation criteria are used in literature to determine the ability of classifier. Different parameters are exploited for the quantitative measurement of the classification results i.e. true positive (TP), true negative (TN), false positive (FP), and false negative (FN). These parameters were used to compute accuracy, precision and recall. The accuracy, precision and recall score for proposed technique is calculated as Equation 5:
The approaches regarding logo detection are frequently evaluated by precision, recall rate and accuracy percentage. We also applied these evaluation matrices for our approach. We achieved the better results as compare to recent approaches because of three reasons (Table 4). a) By training the proposed patch-CNN on small patches of logos so that it can recognize even a small logo part of specific logo during testing. b) By utilizing the abilities of transfer learning by means of AlexNet and ResNet. c) We have trained the network on the only logo portion i.e. cropped images.
Figure 9 shows the accuracy score vs number of iterations used for patch-CNN. Our model showed the superior accuracy because of using small patches instead of whole image. Figure 10 is showing the learning behavior of Patch-CNN. Proposed model can decrease the training and testing loss without over-fitting. We achieve the training loss equal to 0.911 and testing loss equals to 0.630. The results of pre-trained model vs patch-CNN are shown in Fig. 11.

Accuracy vs number of iterations of proposed patch-CNN.
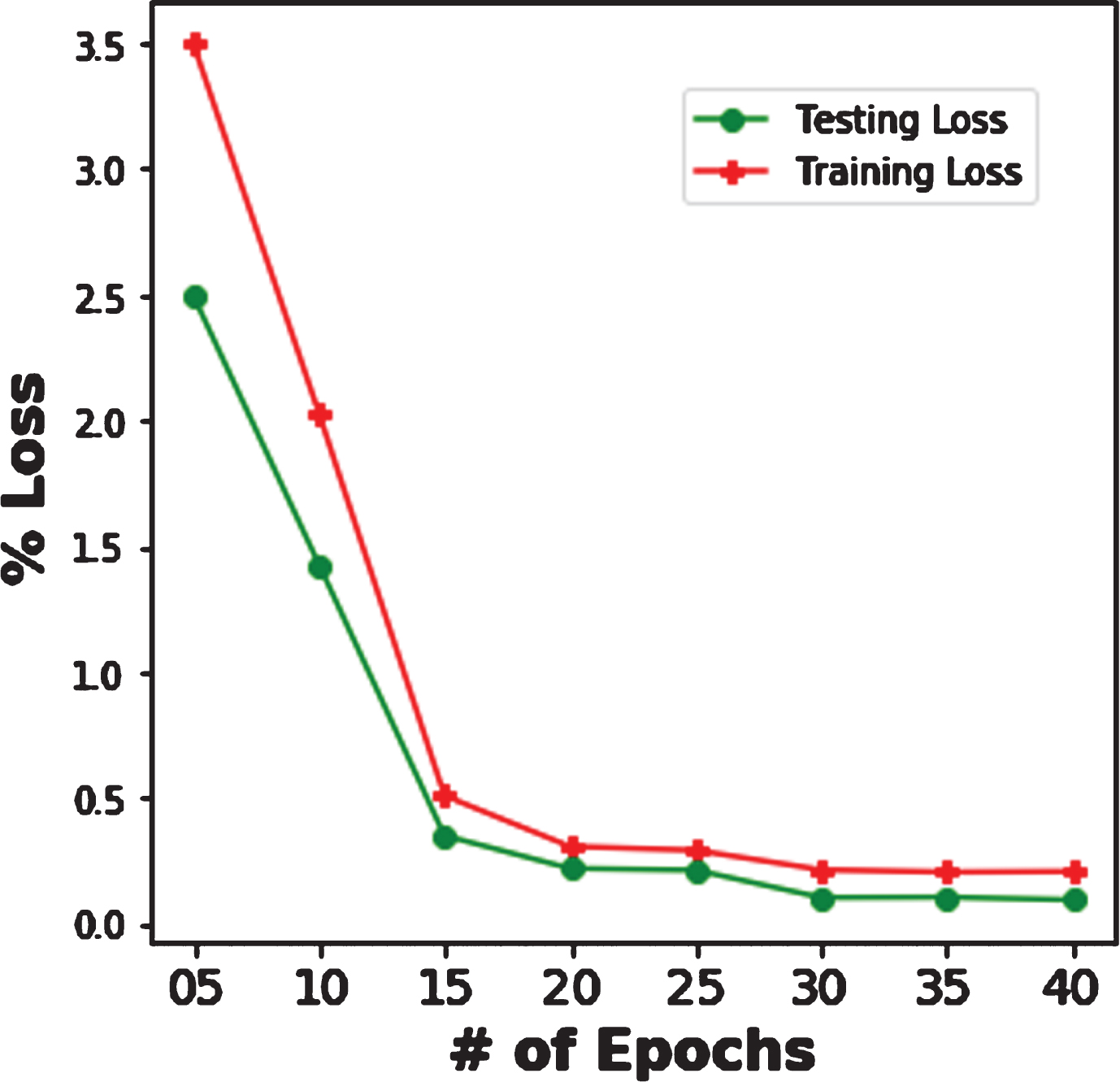
Epoch vs training and testing Loss of iterations of proposed patch-CNN.
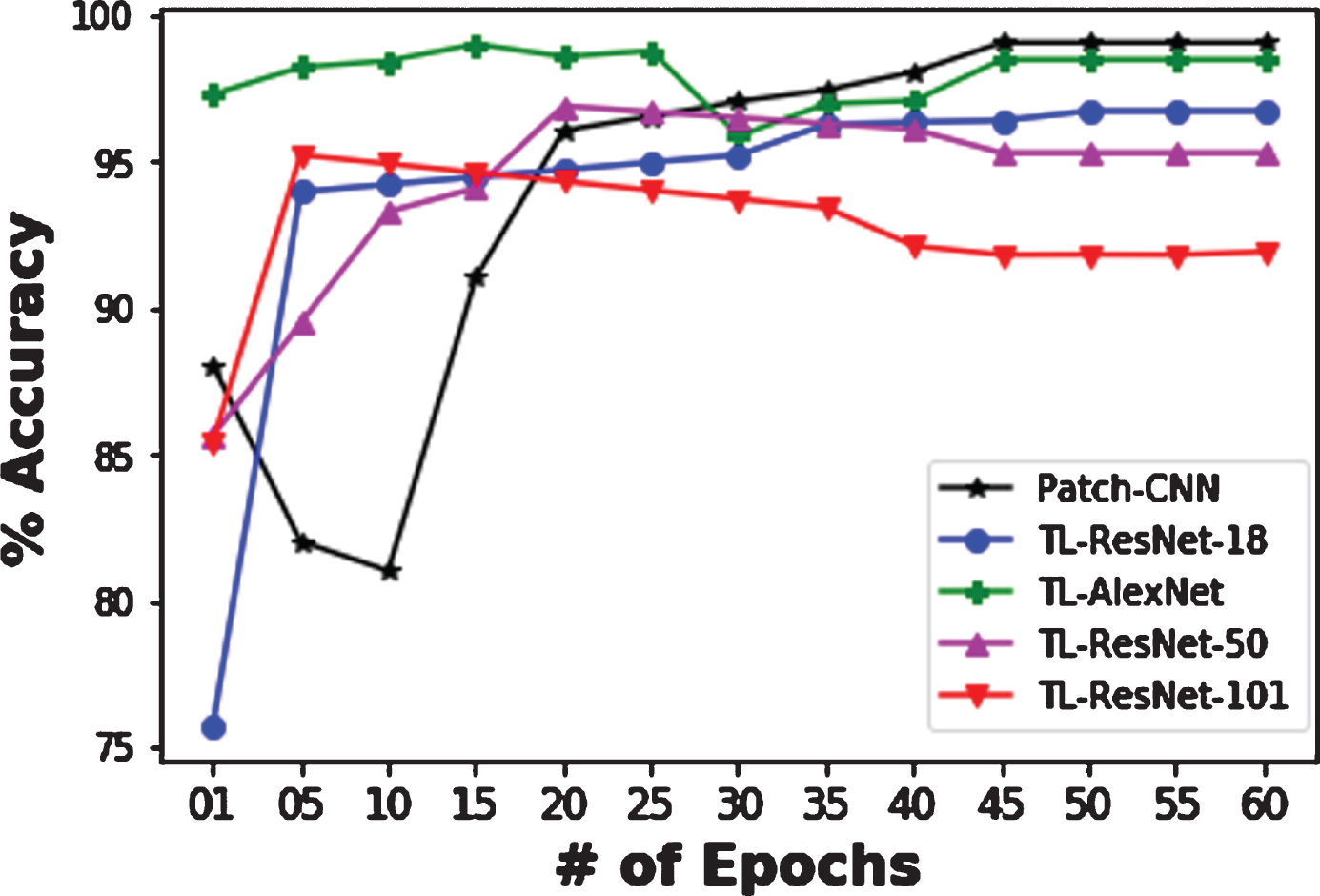
Transfer learning results on different models.
Among all transfer learning models, AlexNet showed the good accuracy score in less training (Table 3). The ResNet also showed good accuracy but it consumes training time very much as compared to Alexnet. The patch-CNN showed highest accuracy of 0.9901 because of specifically training the logo images from scratch. Another reason is that the small patches are more likely to be classified correctly as compared to whole image. It is easier and less time consuming for CNN to learn features from small patches of logos only. Patch-CNN is trained on small patches of logos referring to specified class of dataset. Each of these patches are trained individually to extract detailed features of logo. Training of small patches greatly influenced the accuracy. The advantage of small logo patches is that it makes feature extraction easy which can be easily learned by CNN. In testing we also create patches in same way. Patches of testing images easily match with the trained set features even having tiny logo in a certain patch. On the other hand, learning from whole image is time consuming and more likely to learn extra features from no logo area.
Transfer learning has also proved the effective and robust results. The AlexNet has obtained the highest classification accuracy among all models used for transfer learning. However, proposed patch-CNN showed highest accuracy within very less training time because the number of parameters in patch-CNN is less than AlexNet and ResNet. Logo detection results are shown in Table 2.
Details of our dataset
Results of Patch-CNN and pre-trained models
Results on Different Training choices for transfer learning
Training is largely influenced by the number of epochs which has an impact on the classification performance as shown in Table 3.
Parameter setting like learning momentum, depth, and batch size is also important during the training of deep networks. To achieve the high accuracy Patch-CNN and AlexNet needs less epochs and acceptable training time. On the other hand, deeper networks like ResNet require large number of epochs to attain the highest accuracy. AlexNet showed the best results at 10 epochs while ResNet showed its best results at 10 epochs. ResNet consumes large time as compared to AlexNet. For better performance it is mandatory to monitor the training process. In case of patch-CNN, the best results are obtained at only 10 epochs.
The depth of AlexNet is 8 with 61 million parameters. The depth of ResNet 18, 50 and 101 is 18, 50 and 101 respectively. Number of parameters for ResNet-18, 50 and 101 is 11.7 million, 25.6 million and 44.6 million respectively. The classification performance is highly influenced the by these parameters. Depth of Patch-CNN is 06 with only 0.32 million parameters. For better performance it is worth investigating to better understand these parameters and their influence on accuracy.
Different approaches were proposed in literature for logo detection problem shown in Table 4. The highest detection accuracy (0.9901) achieved in our work, which is considerably the best than any other approaches mentioned in the literature. Other than patch-CNN achievement, we also explored transfer learning which has obtained detection accuracy that has exceeded all the previous reported accuracies (Table 4).
Comparing our best results with previous methods
Comparing our best results with previous methods
The general idea for exploiting transfer learning was to use knowledge, which is already learned by these pre-trained models (AlexNet and ResNet. Obviously, these models have already learned from ILSVR where a lot of labeled training data is available. The Beauty of Transfer learning (TL) lies in the fact of using learned knowledge for new task like logo recognition where comparably we don’t have a lot of data. For logo recognition, there are two reasons behind the slightly low performance of ResNet as compared to AlexNet. 1. ResNet process same thing (residual) multiple times which increase its complexity. 2. ResNet required equal number of images in each class. Minimum number of images in Logos32plus dataset is 182 in class namely Google. So, the overall training of AlexNet is greater than ResNet. The advantage of AlexNet is that it required less timing to train as compared to ResNet in case of logo recognition. On the other hand, the training time of patch-CNN is very less as compared to time consumed by AlexNet and ResNet models. However our aim was also to explore the benefits of transfer learning for logo recognition.
Logo may appear under any point, in any scale or position that is why its detection becomes more challenging. In this paper, we propose patch level prediction given by patch-CNN, which to the best of our knowledge has not been shown before for logo recognition. Patch-CNN uses small patches of logos for training to solve the problem of misclassification especially when logo appears is small size or small portion. Proposed CNN is tiny model with lesser parameters. Histogram equalization is applied on train set to enable more robustness. Considering the results, patch-CNN greatly improved recognition rate by consuming very less training time. We also check results against images retrieved through Google image search facility which reveals the good generalization ability of patch-CNN. We also evaluated the performance of different CNN architectures for logo image detection. We have exploited the transfer learning approach for the classification of logos-32plus dataset. For transfer learning we project the ROIs to minimize the irrelevant pixels from logo image and pass them to AlexNet and three versions of ResNet.
In future, we consider that performance may be improved in by expanding patch-CNN architecture and applying on large scale logo datasets. We believe that the proposed patch-CNN is very promising for logo recognition especially for tiny logo appearing on large size images. In this sense, future directions may be using extended patch-CNN by designing a new large-scale dataset. Other CNN architectures like FRCNN, RNN etc. may also be explored by feeding sequences of logo patches. Although this study is related to logo classification, patch-CNN may also be studied for solving different problems requiring the learning of local features. Moreover, Essential image descriptors like PCA-SIFT [35] can be used for drawing more distinctive features from logo images. Similarly, more robustness can be achieved by using combination of local features and area based approaches [36].