
Abstract
In Botnet Detection, Domain generation algorithms are the most effective method to intercept and analyze captured package. In this article, we propose a new method to classify harmful domain names using Neutrosophic Sets. Data of domain name, after being selected featured and fuzzed into Neutrosophic Sets will be used to classify benign domain names, malicious domain names and indeterminacy domain names, minimizing false detection of benign domain names. The proposed model is going to be tested and evaluated with other malicious domain detection models in the aspects of accuracy points, Accuracy, Revocation, and F1, all of which show that our proposed model has good results.
Introduction
Botnets are computer networks, electronic devices with internet connection are infected with malicious code and controlled by a C&C Server [19]. The main connection architectures of botnets include Client – Server, peer to peer and hybrid models. The centralized architecture consists of a central controller, a system of controlling machines and maliciously controlled workstations. The control station sends a message to the entire network to issue control commands, but firewalls and IDS/IPSs easily detect it. Peer to peer model uses the method of transmitting messages from botnet machines. Although detecting C&C Server using this method is more complicated, the construction and design of this model are very complicated. According to hybrid models, botnets will not contact the C&C Server directly but listen to connections and commands from specific servers. C&C Servers will scan on the network for botnets and send control messages when botnets are detected.
Currently, most botnets are still using centralized architecture due to the ease of construction and development [37, 38]. DGA domains are designed to overcome the disadvantages of centralized architecture [4]. With previous botnets, bots will periodically connect to the control server and wait for the command. Therefore, if the control server is detected, the botnet will be destroyed. So the method of using DGA Domain is applied to conceal the behavior of connecting to the botnet’s control server [5].
In DGA botnets, the domain of the control server will be randomly generated. When bots want to connect to the control server, they will run the algorithm and generate the domain name. Then the bot will connect to each domain name in this episode in turn. From time to time, the botmaster knows the set of domain names created by the bot to register the address for the control server. Domains of the control servers in the domain name set by the botmaster are mostly unregistered and not correspondent to IP addresses, and non-existent domain names NXDomain (NoneXistent Domain) or DGA Domain.
The advantage of DGA Botnet is that if the control server’s address is detected and blocked all connections to these addresses, the botnet is still not completely removed. The problem is that at each point in time, the domain name set will be different. Therefore, at subsequent connections, the domain name will be different from the previous ones. The control server only needs to register a new address, and the bot will still work as usual.
In this paper, we propose a method of malicious domain classification using neutral fuzzy set and application in DGA Botnet detection system. First, we will conduct the extraction of all essential features of the sample domain name, then use the correlation map to select the critical characteristics, significantly affecting the classification and reduction results. Next, we build a Neutrosophic set by calculating a truth membership function (T), an indeterminacy membership function (I) and a falsehood membership function (F) of each element. Finally, we use the Neutrosophic C-Means clustering (NCM) algorithm to conduct the classification of elements.
Our contributions in this article include: Reducing the number of features used: The characteristics of domain names which are less affected by factors such as abbreviations, dialects, or not using keywords in English will be selected. The correlation matrix is used to select important features, minimize the number of characteristics, reduce the number of dimensions. Proposing the use of Neutrosophic NCM clustering algorithm to detect DGA domains. Experimental comparison with previous Domain DGA detection models shows that the use of NCM has better results in detection and time. Neutrosophic algorithms utility helps the model to classify domains that need to be questioned and labeled to continue monitoring to increase the accuracy and minimize the false detection in the DGA Domain detection problem.
The article structure is distributed as follows: In part 2, related studies and comments will be presented. The reduced set of attributes to use for DGA domain detection is presented in Part 2. In Part 3, we present the proposed model, using the NCM algorithm to detect DGA domains. Part 4 will conduct experiments, discuss and compare with previous results. The last part is the conclusion and the direction of development.
Related works
In recent years, there have been many studies on botnets being published. Author Stalmans [8] proposed using botnet behavior through DNS traffic characteristics. This mechanism eliminates the need to maintain blacklists or update bot signs. The method uses the characteristics of DNS traffic such as the Server Name record, IP address, domain name life span, and the letters that appear in the domain name. The classification process is made using the Naive Bayes algorithm. The effectiveness of this approach is not high because the use of the above features and algorithms is not sufficient to perform accurate detection. Subsequently, author Rajalakshmi et al. [33] proposed a learning model using Naive Bayes subdivision combining CNN to classify domain data sets based on features such as numbers, letters, solid characters, and white space, finding DGA domains. Wei et al. [43] proposed a method of detecting malicious domain names based on the new n-gram feature, Nhauo Davuth and Sung-Ryul Kim [9] provide a method for classifying domain names based on SVM and bi-gram distribution of data sets. Bigram features of the domain name are used, extracted and filtered by a threshold. Then, SVM Light classifier is used to classify normal domain names and DGA Domains. This method is quite effective but can only distinguish known botnets, while there are unknown forms of botnets (untrained forms), leading to a decrease in classification efficiency. Schiavoni et al. [36] proposed the Phoenix mechanism based on the semantic information of domain names and IP-based features to detect domains generated by DGA. In this process, the system uses Mahalanobis distance function to evaluate compatibility and use IP addresses to cluster DGA Domains
Antonakakis et al. [27] has developed a malware detection model based on Definitions and Notation, n-gram Features, Structural Domain Features combined with the X-means algorithm and discovered several new DGA variants.
Schuppen et al. [40] proposed a DGA domain detection system called FANCI. The system uses domain names similar to Antonakakis, to build the training data set, then use the SVM algorithm and Random Forest to classify and detect DGA domains independently. Results showed that FANCI had significantly better results than Antonakakis.
The above results all have certain advantages and disadvantages. Publication [8] using a featured data set also misses some essential features for DGA domain detection; The models in [9, 33] depend on the DGA sample data set, not yet discovered unknown DGA algorithms. Model [36] has a low level of real-time response because it takes much time to perform calculations on features. Models [27, 40], although they have solved the above problems as well as discovered new DGA variants that are easily detected by the abbreviated domain names and domain names used Domain or domain name does not use English words.
In most of the above, data clustering has many vital applications in data mining, pattern recognition, information retrieval, and machine learning. This is an indispensable component in the DGA Domain detector problem. However, in practice, the data is often complicated, missing or vague, uncertain. To solve this problem, fuzzy set theory was proposed by Zadeh, in which uncertain information is modeled in terms of element membership into a set. Zadeh’s fuzzy clustering algorithm, Fuzzy C-Means (FCM), by Bezdek et al. [16] has now been applied in many different fields and yielded better results than the Clear clustering algorithm.
A fundamental problem in studies related to Zadeh’s traditional fuzzy set is the ability to represent information related to “non-affinity” and “hesitation”. For example, when diagnosing a patient, the doctor usually concludes the severity of the patient’s disease but does not indicate what the disease is. Then, the traditional fuzzy set of Zadeh is not suitable to model information about “no” and “hesitant” properties. Alternatively, for the DGA Domain detection problem, a typical domain, made up of a meaningful word, can still be a malicious DGA Domain that is used to connect to the control server. Some extensions of the traditional fuzzy set have been proposed, such as Antanassov’s fuzzy or Smarandache’s Neutrosophic Sets. For the fuzzy clustering problem on Neutrosophic Sets, the essential problem is to determine similar measurements to divide the elements into clusters [34]. Sahin [32] has proposed solutions to improve hierarchical clustering methods on Neutrosophic sets to conduct clustering. Guo and Sengur [48] improved Fuzzy C-mean algorithm on neutrosophic sets to find neutral elements and noise elements. It is applied very effectively in image processing, margin finding problems. Ye et al. [21–23] proposed three solutions using the same measurement for Neutrosophic Sets set including measuring Jaccard, Dice, and Cosine to apply to multi-criteria decision-making system with simple neutral data.
Models [27–40] have improved the disadvantages in previous models, but there are some unresolved issues such as doubtful labeling of domain names that are vague, unclear, uncertain, and time for calculating characteristics is still high. In order to improve the shortcomings that exist in the models [27–40], we made a selection of a set of features based on two models [27–40], eliminating some features without affecting the clustering results. Some features are shortened to include features related to issues such as abbreviated keywords, domain names using dialects or non-English domain names. Correlation matrices are also used to select relevant features, helping to reduce computation time. This stage is described in Part 3 of this article.
Proposed characteristics for domain names in the DGA Domain detection system
For Neutrosophic clustering, the selection of characteristics is significant. We classify the characteristics of the domain name into three groups as follows: Structural characteristics Grammar characteristics Semantic statistics characteristics
Structural characteristics
Table 1 describes structural characteristics which use for algorithm:
Structural characteristics
Structural characteristics
DNL: Domain Name Length.
Example: vnexpress.net has DNL = 13.
NoS: Number of Subdomains.
Example: finance.gov.ls has NoS = 3; baomoi.com has NoS = 2.
SLM: Subdomain Length Mean.
Example: vnexpress.net has SLM = 9.
HwP: Has www Prefix.
Example: www.edu.vn has HwP value = 1;
HVTLD: Has a Valid Top Level Domain: Contains valid root domain names. A valid root domain database is taken at Root-zone database (www.iana.org). Domains with root domains that are not in the root-zone database will be treated as DGA domains. Example: DGA Domain shtkwcex.bit has HVTLD value = 0 (bits not in Root-zone database).
CTS: Contains Top Level Domain as Subdomain: Contains a subdomain located in Root-zone database.
Example: dantri.com.vn has CTS value = 1.
UR: Underscore Ratio: Contains “_” in the domain name. Usually, Domain DGAs will not contain this value; the formula determines UR:
count (“_”) is the number of “_” characters in the domain name; Wool (domain) is the length of the domain.
Example: 2018_smileshop99.com has the value UR = 0.0625
CIPA: Contains IP Address: Domain name is an IP address. Many websites are accessed without domain names, but through IP addresses, these IP addresses will be considered valid addresses. Example: 8.8.8.8 is Google’s DNS with CIPA value = 1; vnexpress has CIPA value = 0.
The selected gramamar characteristecs is shown in Table 2:
Grammar characteristics
Grammar characteristics
contains_digit: Contains digit.
Example: naroberts27.github.io has contains_digit value = 1; DGA domain 7rsbs8sz1hq5y6qya1.ru has contains_digit value = 1.
Vowel_ratio: The ratio of vowel: The ratio of vowe/ length of the domain name. This value is determined by the formula:
Vowel(domain) has values: “a”, “e”, “i”, “o”, “u”.
Example: Valid domain name: kcsecurities.com has Vowel_ratio value = 0.416666667.
Digit_ratio: The ratio of digit: The ratio of digit/ length of the domain name. The formula determines this value:
Digit (domain) is the number in the domain.
Example: Valid domain name: naroberts27.github.io has the value Digit_ratio = 0.181818182. DGA domain afj7jmxngvrsm4p15d.com is valid Digit_ratio = 0.071428571.
Table 3 shows the Semantic statistic characteristics:
Semantic statistic characteristics
Semantic statistic characteristics
RRC: The ratio of repeated characters in a subdomain: The formula determines this value:
Repeated (domain) is the number of times the character is repeated in the domain.
RCC: The ratio of consecutive consonants: This value is determined by the formula:
Cconsonants (domains) are the number of repeated consecutive vowels in the domain.
RCD: The ratio of consecutive digits: The formula determines this value:
Cdigits (domain) is the number of times a digit is repeated consecutively in a domain. Entropy: The entropy of subdomain: The formula determines this value:
t is a character in the domain, p is a set of characters in the domain.
Similar to the Phoenix model, we apply stages to remove black domain names from blacklists, then we conduct domain classification according to the model below:
Classification model, detecting malicious domain names includes three stages in Fig. 1:
Characteristics calculation phase: For each domain name, related characteristics will be calculated, creating a characteristic data source for the next selection phase. The characteristics calculation methods have been presented in the next section of this article. Characteristics selection phase: We use the correlation map to select the influential characteristics in the characteristics data set to achieve results for the clustering process, minimize interference, and increase calculation performance for the algorithm. The more characteristics, the higher the accuracy; however, it also leads to the reduction of the performance by time. Therefore, the selection of the most influential characters is the critical phase of the model. From the selected characteristics, we build Neutrosophic Sets. Neutrosophic clustering phase: Using Neutrosophic clustering to conduct clustering, find out the normal domain names, DGA domain names, neutral domain names. In this model, we propose using the C-Means Neutrosophic clustering algorithm (NCM), which is suitable for the problem of short calculation time, a large data set, and good processing in real-time.

Diagram of the malicious domain classification model using Neutrosophic Sets.
In this model, we use the correlation matrix to select the most influential characteristics in the clustering process. There are three methods of correlation matrix construction, including Pearson Method, Spearman’s method, Kendall method, and Goodman and Kruskal’s method. In this model, we use Pearson’s correlation coefficient to select the influence characteristic. Pearson method is as follows:
For two elements x and y we have:
n is the number of elements; x i , y i :element x i and y i
After determining the correlation values, we built up the correlation matrix of characteristics from the database sets [1–3] described in Fig. 2:

Matrix correlates the characteristics in the DGA Domain classification model.
We made the selection of the six highest quality features to classify, using the type feature to label, serving for clustering results, Entropy, Type, SLM, DNL, RCC, RRC, vowel ratio will be selected for classification.
As illustrated in Figs. 3, 4, 5 and 6, we can see that DGA domains always have higher entropy values than benign domains. Values of RCC and SLN are of high value for DGA domains, characteristic such as RRC and vowel ratio tend to cluster into a value area.
After selecting essential characteristics, using the selected characteristics to conduct clustering on the Neutrosophic Sets, the clustering method is presented in the next section of this article.
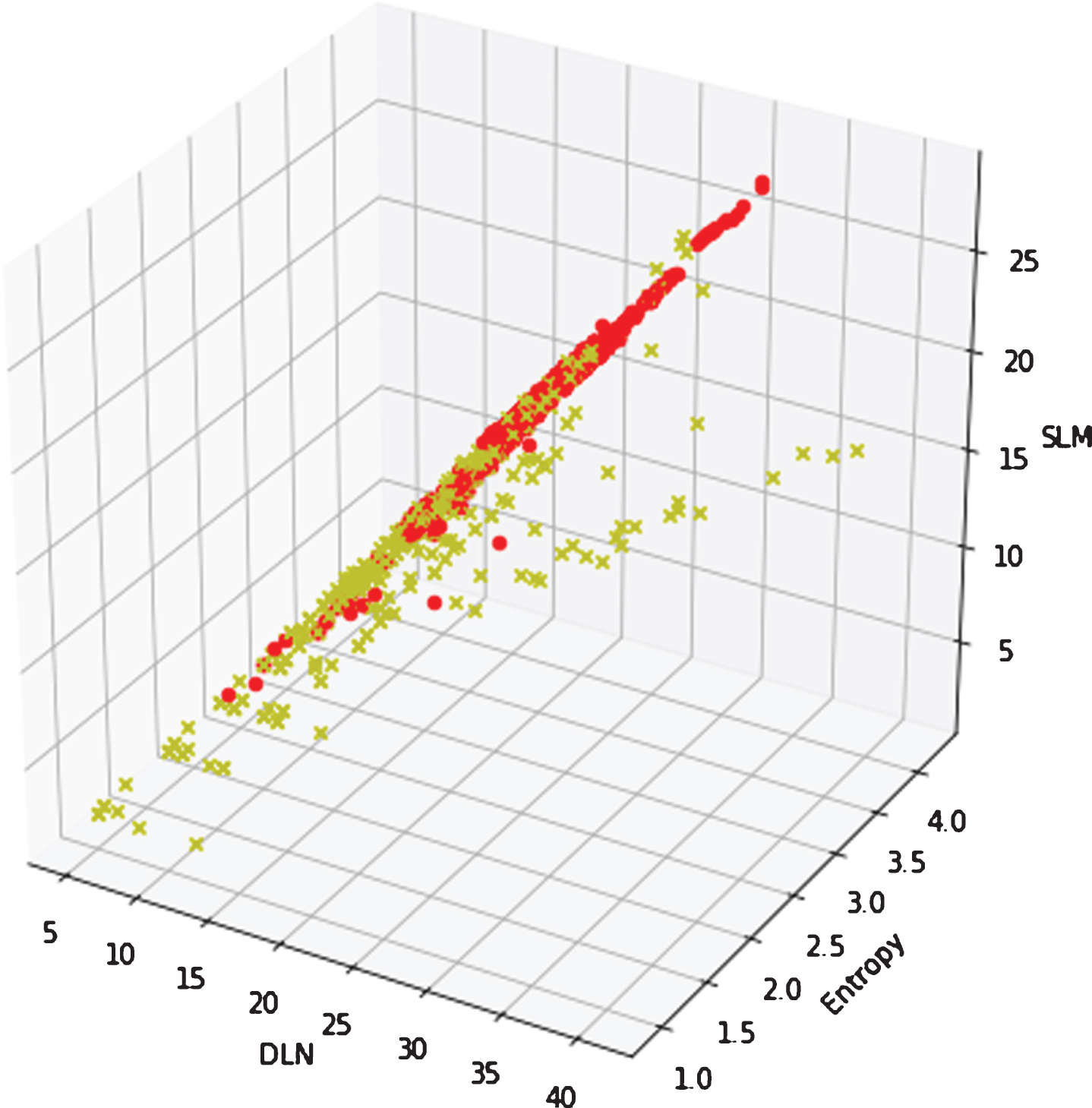
SLM characteristic.

RRC characteristic.
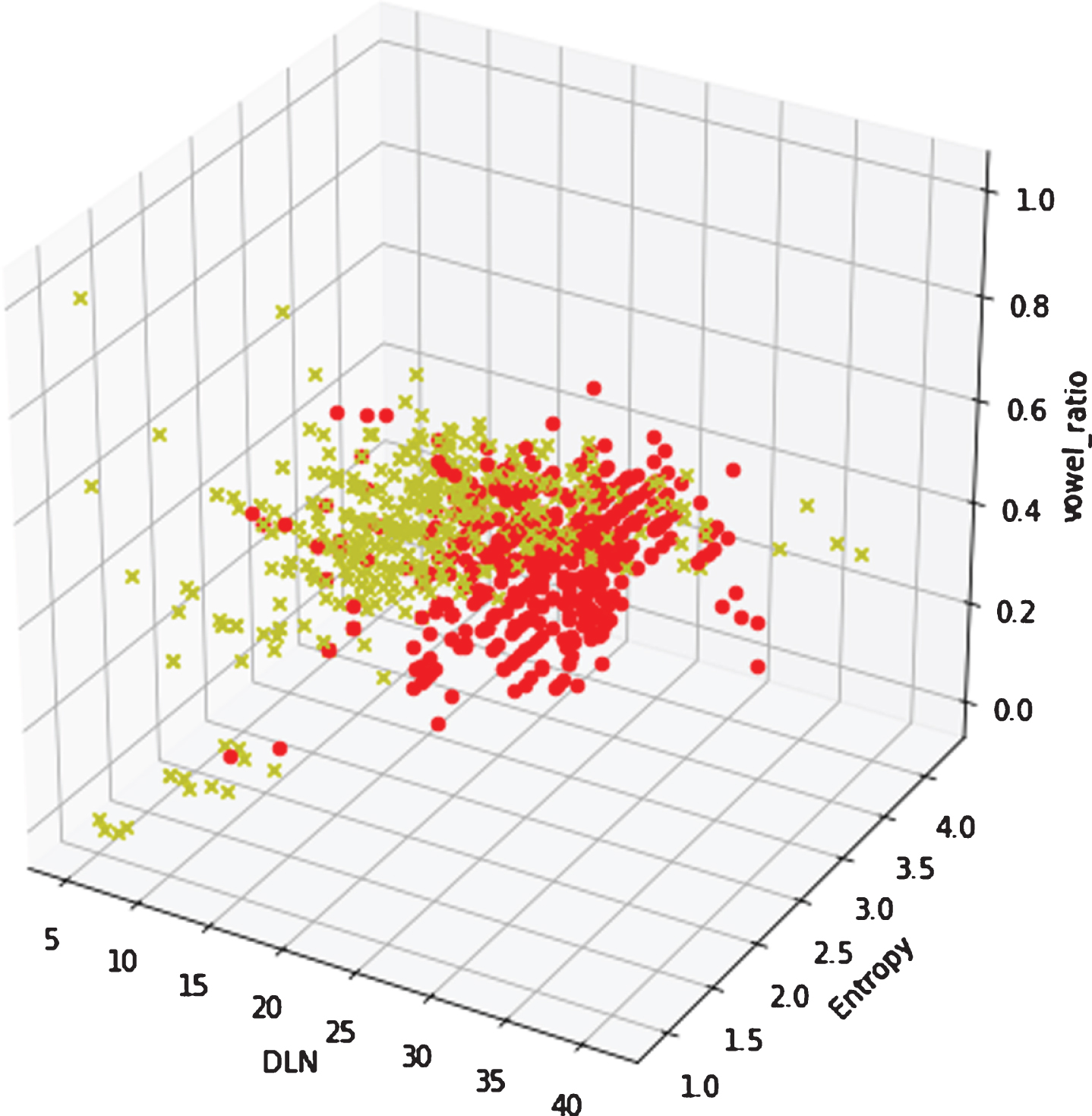
Vowel ratio characteristic.

RCC characteristic.
We have the concept of Neutrosophic Sets as follows: Let X be a non-empty set, with an element of X denoted by x∈X. Neutrosophic Sets A defined on space X is characterized by three functions: function T_A (x) belonging to the degree indicating that event x will occur, neutral measurement function I_A (x) means that there is no idea whether or not event x occurs, and function Zero measurement F_A (x) believes that event x will not happen with X.
Unlike traditional clustering methods like K-means, fuzzy C-means. The Neutrosophic method used to conduct clustering can eliminate the data of interference or exceptions, neutral among clusters [26]. To detect the DGA Domain, finding interference data, neutral data is considered very important and need to be determined to conduct inspection and monitoring. Guo has proposed the algorithm of Neutrosophic C-Means clustering to find out interference data, neutral data based on Neutrosophic Sets. This algorithm determines the degree of dependence, neutrality, and degree of non-element belonging to input data with all clusters. The objective function and measure of the elements are as follows:
T
ij
, I
i
, F
i
to determine the membership, neutrality, and non-degree of each element. 0 < T
ij
, I
i
, F
i
< 1, With T
ij
, I
i
, F
i
satisfy with the following formula:
For each point i, the value of
With m being constant, p
i
and q
i
are the second largest and largest T values of each cluster. When p
i
and q
i
are calculated, the value
The values T
ij
, I
i
, F
i
are defined as follows:
Clustering is repeated, combining optimization of the objective function. The values of dependency, neutrality and non-dependency will be updated according to the above expressions in each iteration.
The value of
When satisfying the repeat condition
Then if k = C + 1 means the element belongs to the neutral class; if k = C + 2 the element in the class does not belong.
In the detection model, the algorithm will help to find elements of the DGA domain class or normal domain. Finding normal domain names but having the characteristics of a DGA domain name or a DGA domain name is hidden, possessing the characteristics of a usual domain name. From there, will give the level of domain names.
Experimental tools
In this section, we perform NCM algorithm assessment in the proposed model with other methods based on the following 3 criteria: Evaluation between neutrosophic algorithms: Sahin [32]; Evaluation of fuzzy clustering algorithms: FCM [16], FSVM [39]; evaluation between DGA detection models: X-means [27], SVM [40].
In the proposed model, we use the Manhattan similarity measure to distance the two elements x and y:
The algorithm is implemented in Python 3.5 programming language, using computers with Intel (R) Core (TM) i7-3470QM CPU clocked at 2.7 GHz, 8192MB RAM and using Windows 10 Professional 64 bits operating system.
We use training databases, including: One million most visited domains by Alexa [2] statistics. Malicious domain name database provided by Bambenek Consulting [3] at http://osint.bambenekconsulting.com/feeds/DGA feed.txt
DGA domain database provided by 360 Lab [1] at https://data.netlab.360.com/feeds/dga/dga.txt
Table 4 provides a general description of the empirical data set. Tables 11 and 12 describe in detail the number of DGA domains in two data sets [1] and [3]. In these two DGA data sets, this domain contains information such as botnet types, URLs generated by DGA algorithms.
General description of experimental data
General description of experimental data
The data set of 10,000 elements will be extracted from the Alexa data set in combination with the remaining two datasets. The above test set of databases will be labeled and mixed to build the training data set.
Our experiment will evaluate whether a domain has a DGA domain, so the specified value will be binary. The classification results will be in four cases, as shown in Table 5:
Classification result
Classification result
We evaluate the accuracy of the model according to Accuracy and Micro-averaging assessment methods as follows:
We use two measurements of Davies-Bouldin and Calinski Harabas to evaluate our method with the model of using FCM [16], FSVM [39]:
- Davies-Bouldin (DB) measurement:
For
For algorithms to be tested, the smaller the result of DB measurement, the better.
- Calinski-Harabasz Criterion (VRC):
The Calinski-Harabasz criterion is called the variance ratio criterion (VRC). VRC is defined as
SS
B
is defined as:
SS
W
is defined as:
The maximal value of VRC shows better performance.
Evaluating the proposed model results with algorithms of Sahin, X-means, SVM, FCM, TSVM, and FSVM on the data set above, we have obtained the following evaluation results as shown in Table 6, Tables 7 and 8:
Evaluate the results of DGA domain classification algorithms
Evaluate the results of DGA domain classification algorithms
Comparing results between algorithms for normal domain classification
Comparing Accuracy index between algorithms
Based on the chart we can see that NCM’s F1-Score, Precision, and Accuracy results are better on both the DGA-domain proper classification and the Common Domain compared to Shain algorithms, X-means, SVM, FCM, FSVM.
For the advantages of the method, we evaluated two NCM and Sahin neutrosophic algorithms on neutral elements. We have the classification rate as follows:
As can be seen from Fig. 10, using NCM classifier is highly effective in detecting the DGA domain, achieving the best DGA detection rate, reducing the number of smaller indeterminacy elements compared to Sahin algorithm.
Although the NCM algorithm has a smaller number of domain names in question than Sahin, the ratio of Precision, Recall, F1-score, and Accuracy (Figs. 7, 8, 9) are higher than algorithms. Sahin Performing NCM comparison with two other fuzzy clustering algorithms are FCM [16] and FSVM [39] by two measures of DB and VRC, we obtained the results shown in Table 9:
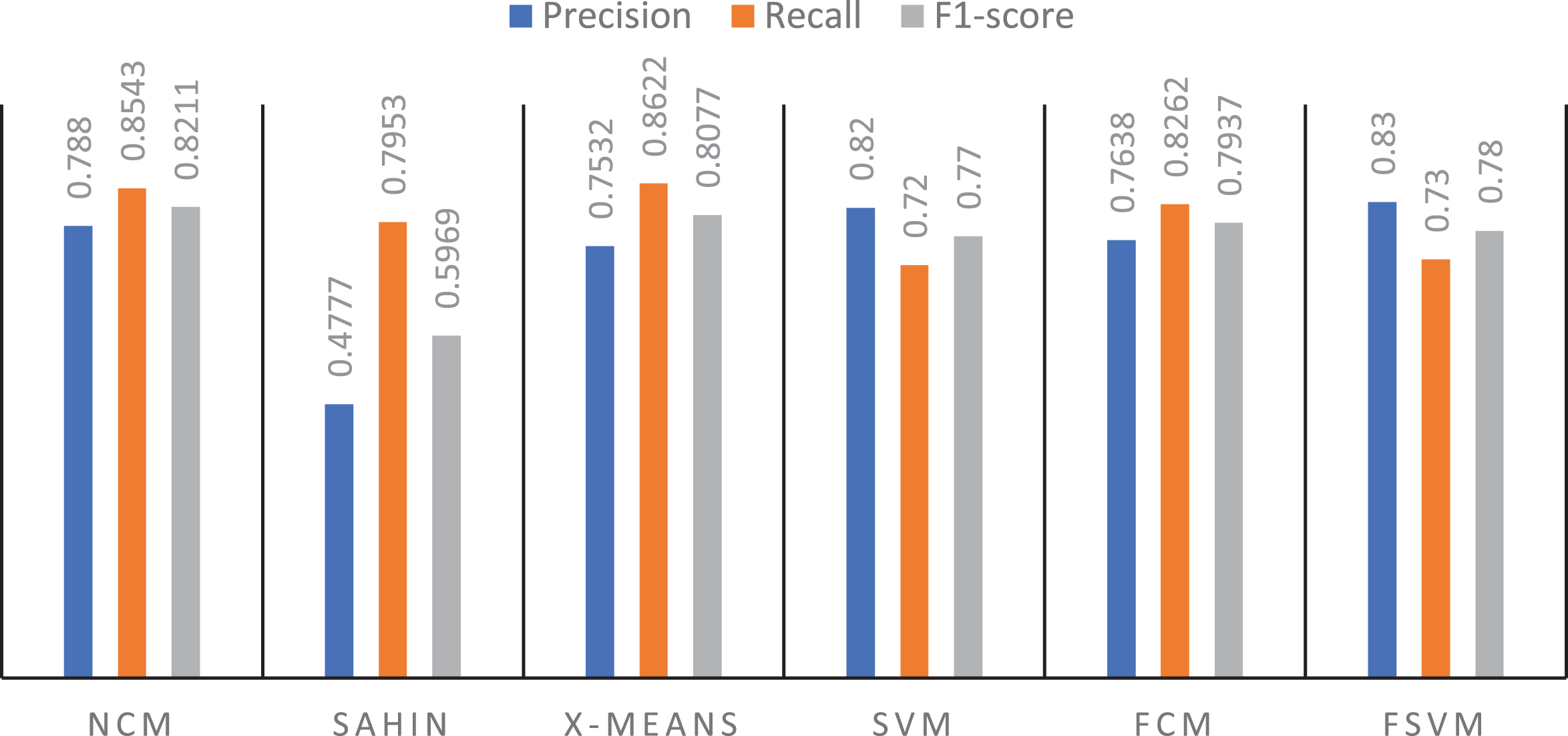
Compare indicators between classification algorithms.
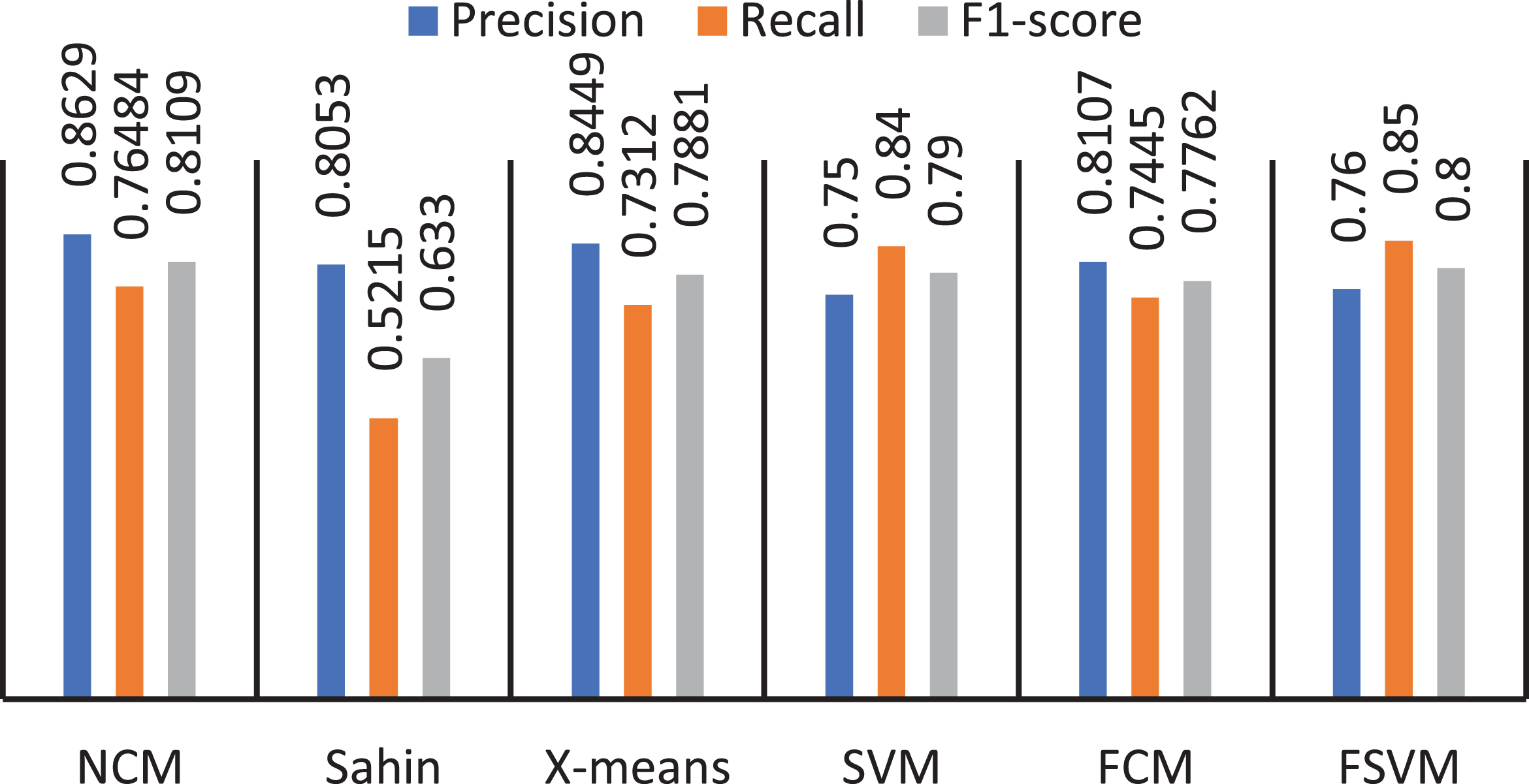
Comparing indicators between classification algorithms.
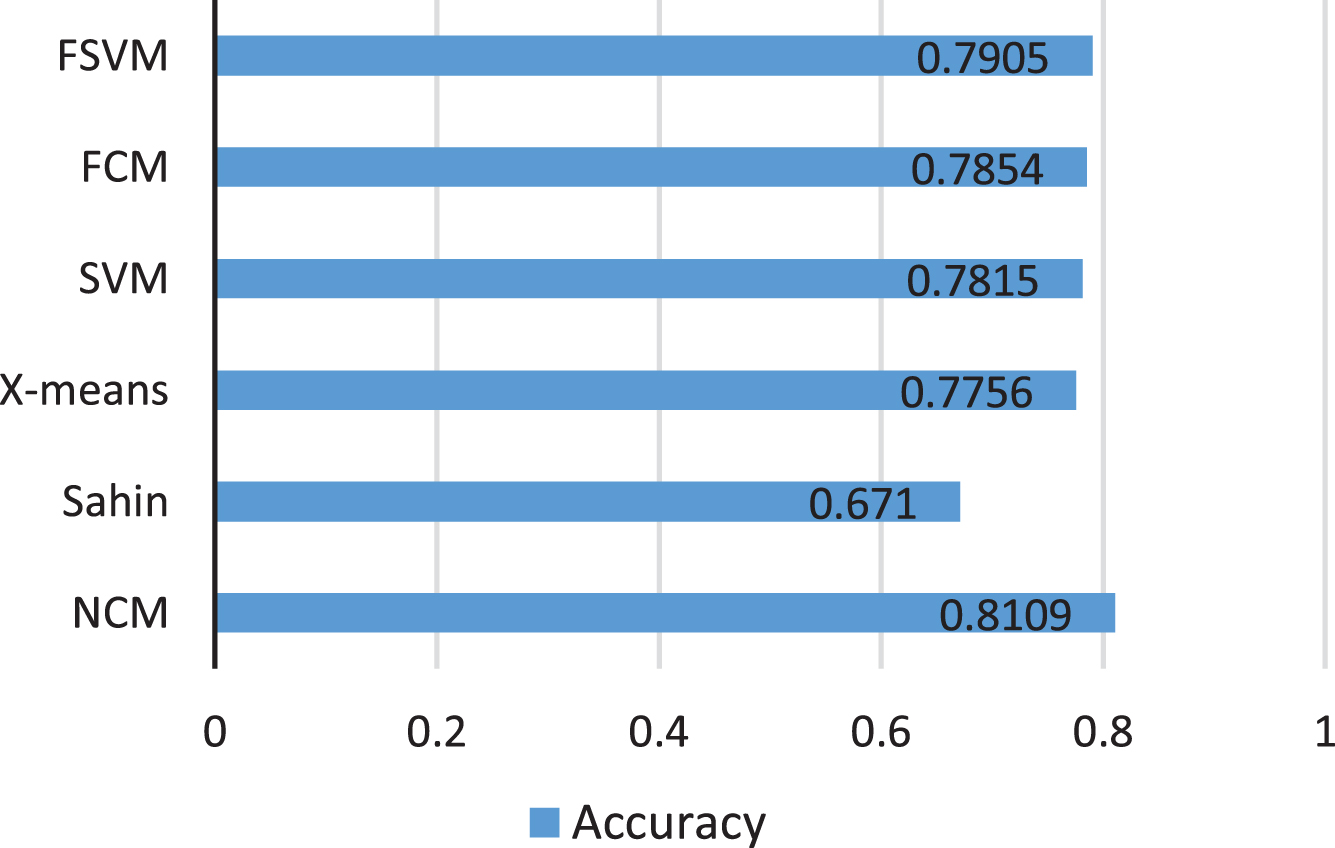
Comparing Accuracy indicators between classification algorithms.
Comparing DB, VRC index between algorithms
The above results show that at both measurement levels of DB and VRC, NCM algorithm has achieved the best results, namely the DB index achieved the smallest result and the VRC of NCM achieved the largest results.
The classification results are presented based on some important characteristics such as Entropy, RRC, DNL... by our proposed model is shown in Fig. 11:

Classification results on two neutrosophic algorithms.
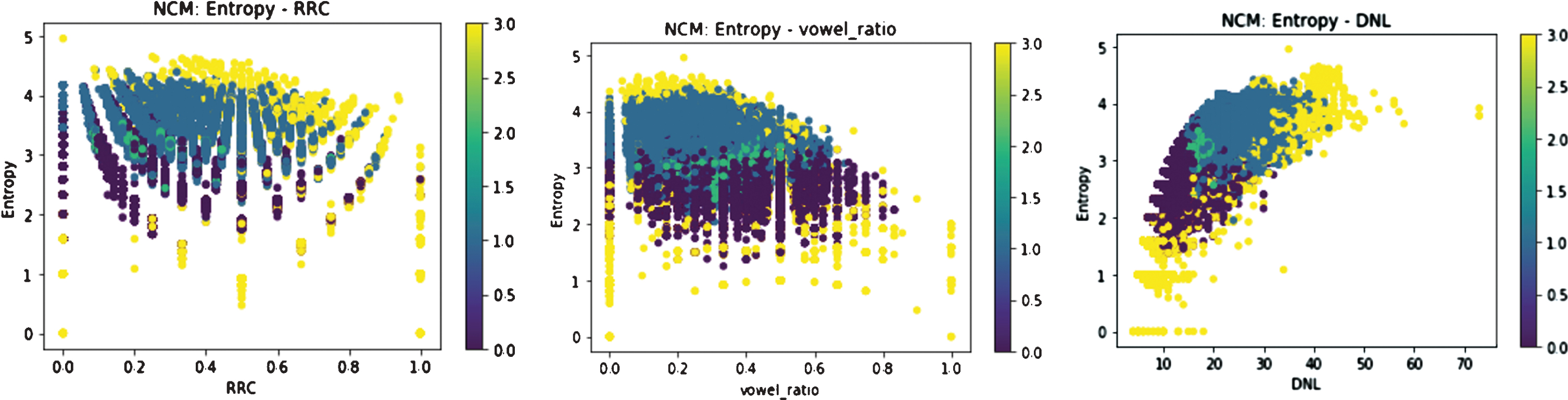
Classification results of the proposed model.
Through clustering results, we can see the level of the elements. The purple element denotes the normal domain; the dark green element represents the DGA domain; the yellow element is considered the interference element; it should be evaluated on other features. The blue is considered neutral elements.
Neutrosophic-based clustering method has advantages in DGA domain filtering phase, finding interference elements and neutral elements, These elements need to be used methods or based on other characteristics to assess level toxicity and suitable for application with multi-layer analysis model. Neutrosophic is highly effective.
Through the evaluation results of the runtime between algorithms, it can be seen that the NCM usage model achieved the most optimal results, the index comparison between FSVM and NCM has the same level of accuracy. However, NCM math has better computation time than FSVM algorithm. It can be seen that the model using NCM algorithm will achieve the most optimal results in terms of calculation time and exact detection level (Table 10).
Classify execution time between algorithms
Describe in detail the 360 Lab data set
Detailed description of the Bambenek Consulting dataset
In this paper, we have proposed a benign domain classification model and DGA domain based on NCM algorithm. Experimenting on 3 data sets of Alexa, Bambenek Consulting and 360lab shows that our model has better results with the recent classification methods, with reaching the highest Accuracy and F1-Score indicators. The computational time of the model is reduced compared to the TSVM model, while the Accuracy and F1-Score indicators are similar. In addition to higher accuracy, our model also can detect noise elements and provide neutral, exceptional cases. However, the model also needs to have additional testing methods for the cases where the element is determined by some other advanced fuzzy sets [7, 48] and the performance of proposed method needs to compare with some other machine learning method [6, 47]. This will be our next research direction in the future.
Footnotes
Acknowledgment
This work was supported by the Domestic Master/PhD Scholarship Programme of VinGroup Innovation.