
Abstract
Sensor-based human activity recognition gained a lot of research interest within the field of pervasive computing due to its wide range of application domains. Recognition of complex human activities is a challenging task due to the tendency of humans to perform activities in an interleaved and concurrent scenario. In this paper, we address the problem of complex activities recognition using a combination of the discriminative features called Strong Jumping Emerging Patterns (SJEPs) and the fuzzy sets theory. The proposed approach is designed to fit the challenges of multi-label classification, nonlinear separation, and recognition of multiple overlaps of interleaved and concurrent activities. Besides the need for a training dataset of complex activities that is difficult to obtain. The proposed approach uses a training dataset of simple activities to extract two sets of SJEPs for linear and nonlinear activities. Then, a novel SJEP-based recognition approach is presented to recognize simple and complex activities. We evaluate our approach using two datasets collected from two different labs. Experimental results show the efficiency of our approach in recognizing simple and complex human activities, besides the superiority of our approach against other competing approaches with regard to recognition accuracy.
Keywords
Introduction
One of the promising research themes in pervasive computing is Human Activity Recognition (HAR), which is concerned with monitoring the users and their surrounding environment using computing devices, and inferring the performed user activities from the sensor events triggered by the user [1]. The forefront research attempts in HAR were vision-based HAR. In the last few decades, due to the rapid developments of sensors and mobile devices, recognizing human activities based on sensors has drawn a lot of research interest. Sensor-based HAR [2] operates through the collection of data from sensors attached to the user or installed in the environment to measure the user movement, environment variables, or physiological signals [1]. Research in sensor-based HAR stems from the vast array of its applications in medical, military, and security applications [3]. A common application is monitoring activities of daily life (ADL) for eldercare, healthcare, and assistive living applications.
Human activities can be categorized from two different dimensions, time span, and execution patterns. With regard to the time span, there exist two categories, action and activity [4]. An action refers to any simple indivisible operation, which spans a short time, and corresponds to a single event triggered by a sensor such as holding a cup. An activity spans a longer time and consists of a set of actions (i.e. sensor events) such as cooking. Regarding the execution pattern, a single user can perform activities in two different scenarios, a simple (i.e. sequential) or a complex (i.e. overlapping) scenario [5]. A simple activity is performed by a single user when no other activities are performed simultaneously. In complex activities, a single user performs multiple activities in a concurrent or interleaved fashion. In concurrent activities, actions of multiple activities are carried out simultaneously. Interleaved activities contain actions of various activities carried out in an interwoven (i.e. shuffled) manner. Figure 1 illustrates examples on different types of human activities.

Different types of activities with Examples.
The human nature is to perform activities in a random overlapping pattern than in a sequential pattern. This makes complex activities recognition a more realistic target. From machine learning perspective, complex activities recognition is a multi-label classification problem. Existing data-driven approaches for complex activities recognition have some limitations. First, they require a training dataset of complex activities in order to recognize complex activities, which is difficult to obtain (for m activities, there exist m (m - 1) different patterns of complex activities). Second, existing data-driven approaches [5–9] assume that activities are linearly separated. In fact, some nonlinearly separated activities will need to be recognized as such. For example, consider two activities, ‘making coffee’ and ‘preparing breakfast’. The sensor events in the first activity are completely contained within the second activity, and thus they require a methodology to detect both activities from the same set of sensor events. Finally, existing approaches such as [10] can recognize a maximum number of two interleaved or concurrent activities, which does not capture the general case of having multiple activities interleaved or executed in parallel.
In this this paper, we present a novel SJEPs (Strong Jumping Emerging Patterns)-based approach for the recognition of simple and complex activities with linear and nonlinear characteristics. This is accomplished using discriminative features (i.e. SJEPs) that represent the unique sensor features that are exclusively present in each activity class. The proposed approach is composed of two main phases. In the first phase, we use a hierarchical pattern-mining approach to discover SJEPs for linear and nonlinear activities from a training dataset of only simple activities. Moreover, we extract two other features, an activity weight vector, and a correlation matrix for sensor/activity interdependency. In the second phase, our recognition method uses the extracted SJEPs, and features besides the fuzzy sets theory to recognize simple and complex activities.
The main contributions of this paper are: We propose a unified framework for multi-label classification of complex activities using a training dataset of only simple activities. We apply a hierarchical pattern-mining approach to identify SJEPs for both linear and nonlinear activities. We generalize the recognition of complex activities to recognize more than two interleaved or concurrent activities. We validate the efficiency of the proposed method on different datasets and perform comparison with existing research attempts. The experimental results demonstrate superiority of our proposed method.
We organize the remainder of the paper as follows: in section 2, we review the previous research attempts for complex activities recognition.
Then, the problem of complex HAR is formulated in section 3. In section 4, we review preliminaries on the pattern mining approach. Then, we present our proposed approach for simple and complex activities recognition in section 5. In section 6, the experimental evaluation and comparisons are illustrated and discussed. Finally, we conclude our work and discuss our plans for future work in section 7.
Research on Human activity recognition generally addresses two main dimensions, activity monitoring devices, and activity recognition techniques. In this section, we review HAR from these dimensions.
Regarding the type of monitoring devices used for HAR, HAR is classified into two categories, vision-based HAR, and sensor-based HAR. Vision-based methods are the forefront in HAR that use cameras for activity monitoring and apply computer vision techniques for activity recognition process. In [11], the authors review some of the most important work in vision-based HAR. On the other hand, sensor-based methods use sensors to monitor human activity. These sensors may be wearable such as accelerometer, or dense sensors distributed in the environment such as motion sensors. An important research on sensor-based HAR is presented in [1]. Each monitoring method has advantages and disadvantages beyond its typical applications. Sensor-based methods gain a lot of research attention because of the rapid developments of low computational and lightweight wearable and environmental sensors. This leads to mature applications such as assistive living, healthcare monitoring, sports, surveillance, etc. In this paper, we are interested in sensor-based HAR.
Existing techniques for sensor-based HAR are divided into two main approaches, knowledge-driven, and data-driven approaches [12]. In Knowledge-driven approaches, experts capture domain knowledge to construct a model, and then use that model to identify input sensor data. Ontology modeling [13] is one of the main techniques used to represent knowledge models [14–16]. Although knowledge-driven approaches have a clear semantics, they require a rich knowledge domain to represent activities. Obtaining this knowledge depends primarily on the expertise of experts. In addition, they are weak in dealing with uncertainty and temporal relationships between data. On the other hand, data-driven approaches use pre-existing datasets to construct an activity model using machine-learning techniques. Then the constructed model is used to identify new sensor data. Some of the advantages of the data-driven approaches are their ability to deal with uncertainty using well-established machine learning techniques. In addition to the use of temporal information to capture short-term and long-term temporal dependencies [15]. However, they require large amounts of datasets to learn the activity models and have problems in reusability and applicability. In this paper, we are interested in data-driven approaches. Next, we review the most important data-driven techniques proposed for complex HAR.
For complex HAR, there are three prominent data-driven approaches, approaches based on probabilistic models, based on time-series analysis, and pattern-mining based approaches. Most of the existing data-driven approaches are probabilistic models such as Conditional Random Fields (CRF), Hidden Markov Model (HMM), and Bayes Network (BN) [17]. CRF cannot recognize concurrent activities, so some variants of CRF were proposed such as Factorial CRF (FCRF) [6], and Skip Chain CRF (SCCRF) [7, 8]. For HMM, it has a limitation on the recognition of interleaved activities. To solve this problem, [18] presented an Interleaved Hidden Markov Model (IHMM). Using the BN, the authors in [9] presented an Interval Temporal Bayesian Network (ITBN) that makes a combination of probabilistic Bayesian network with Allen’s temporal relations. These graphical models are based on time points, and can capture only three relations (i.e., precedes, follows, equals). Therefore, they cannot characterize rich temporal characteristics about activities. In addition, their computational complexity increases with the number of overlapping activities. Regarding time-series based approaches, an attempt is presented in [5]. In this work, the authors extract discriminative subsequences of time series called shapelets to identify activities. However, this work requires more computational complexity to extract shapelets.
Finally, the pattern mining-based approaches extract a set of discriminative patterns for each activity class, and then output the activity label(s) with the highest likelihood score. In [10], and [19] the authors make use of Emerging Patterns (EPs). In [10], the authors proposed a framework for recognizing simple and complex activities, besides a dynamic trace segmentation algorithm. This approach has some shortcomings; they use a separate recognition module for simple and complex activities and did not specify which module to select for incoming data. Moreover, they can handle only two concurrent or interleaved activities. Finally, the applied recursive segmentation approach is not robust; wrong recognition of a specific segment affects the recognition and segmentation of subsequent segments. In [19], the authors converted the problem of complex activities recognition into the problem of recognizing multiple simple activities. They proposed a dynamic segmentation algorithm that split the incoming stream of sensor readings into multiple simple activities. Then, for each obtained activity segment, they made a combination of random forest and EPs to identify its activity label. Although this approach simplifies the problem of complex HAR, it has some drawbacks. Initially, the authors put a great responsibility on the segmentation method; prediction error in one segment affects the recognition and segmentation of subsequent segments. In addition to the increased time and computational complexity, to recognize n simple activities, they require to train and test n random forests.
In this paper, we propose an EP-based approach, our work is somewhat similar to [10], and [19]. However, we discover a discriminative type of EPs called SJEPs that represent the unique features that are present exclusively in each class of activities. Our approach differs from theirs in its ability to handle both linear and nonlinear activities. In addition, we can recognize more than two overlapping (i.e. interleaved or concurrent) activities.
Problem formulation
For the task of sensor-based human activity recognition, wearable or environmental sensors monitor human’s behavior over time. When human performs a specific activity, a sequence of sensor events is triggered, and then sent to an integrating device for further processing.
To recognize complex human activities, we utilize a training dataset D that consists of q observations o of m simple activities Equation (1). In dataset D, attributes represent sensor readings and observations represent activities. An observation o =< e1, e2, …, e n > is comprised of a subsequence of sensor events e from n different sensors. Each event is a tuple of four elements e =< ts, sn, sv, a i >, where ts is the time stamp, sn the sensor name, sv the sensor value, and a i is the corresponding activity label from a predefined set of labels A = {a1, a2, …, a m }.
Our objective in the training phase is to define a mapping function MF that assigns each new observation of sensor readings for simple or complex activities with the correct activity label(s) Equation (2).
Before going in depth to the proposed approach, in this section we introduce the definitions required in our approach.
Emerging Pattern (EP) is an important type of discriminative patterns [20]. For HAR, EPs represent the discriminative features between different classes of activities. There are different types of emerging patterns; there are Minimal Emerging Patterns (MinEPs), Maximal Emerging Patterns (MaxEPs), Jumping Emerging Patterns (JEPs), Strong Jumping Emerging Patterns (SJEPs), Fuzzy Emerging Patterns (FEPs), and Noise-tolerant Emerging Patterns (NEPs) as depicted in Fig. 2. Each class of EPs has its own characteristics and usage, a detailed discussion about these classes is presented in [21].
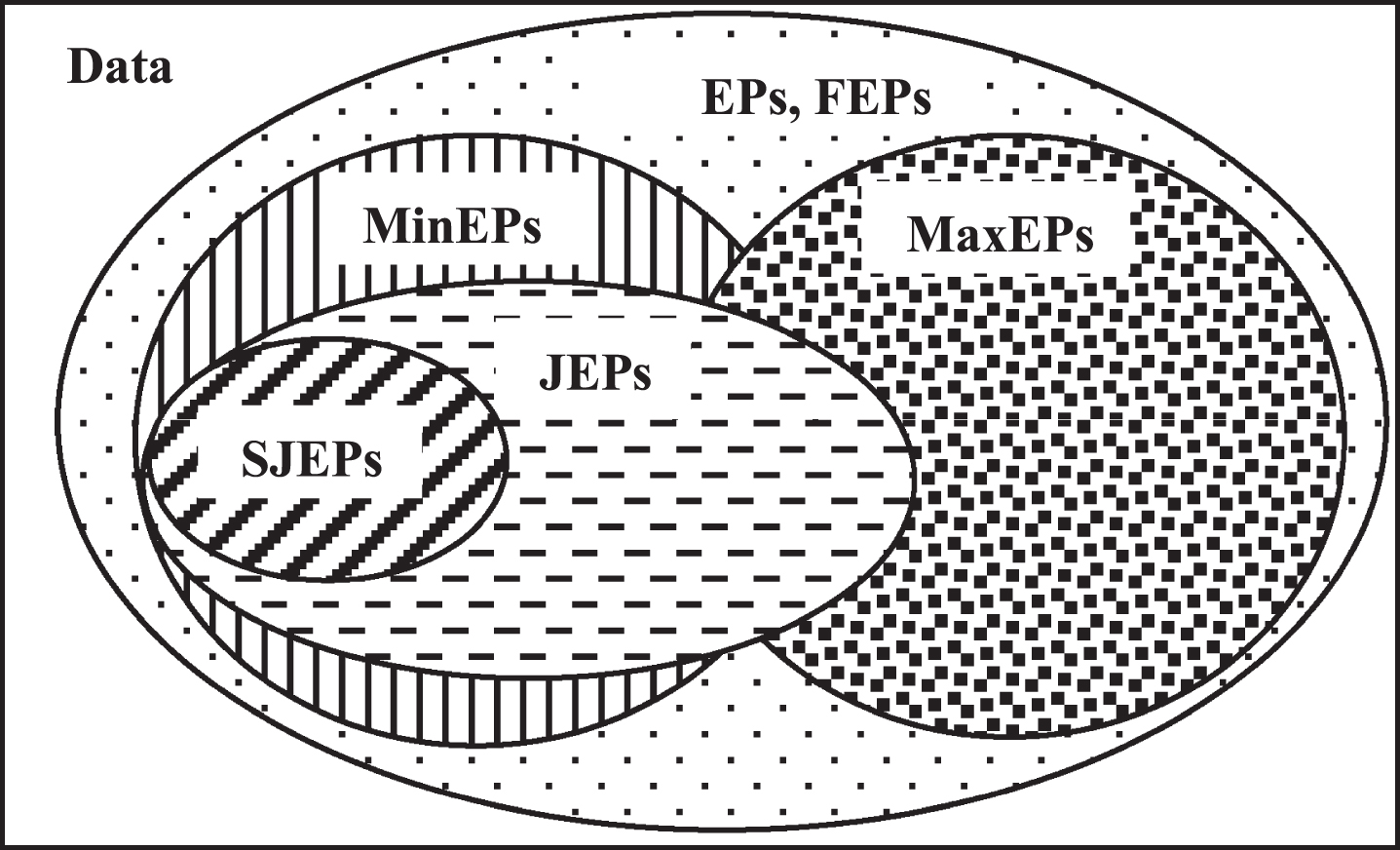
Relationships among different types of Emerging Patterns [20].
Considers a pattern X, and two different activity classes D1 and D2, we have the following definitions.
In this paper, we are interested in a specific type of EPs which is the SJEPs incorporating the proprieties of JEPs and MinEPs. SJEPs achieve absolute separation and represent the unique features that are exclusively present in a single class.
The proposed SJEP-based approach for the recognition of simple and complex human activities is comprised of two main phases, training, and testing as shown in Fig. 3. The input to the training phase is a set of labeled sequences for simple human activities. At the end of this phase, we get three outputs: the extracted SJEPs, an activity weight vector, and sensor/activity correlation matrix. Then, in the testing phase, the incoming stream of sensor readings is segmented, and then each segment is assigned the corresponding activity label(s) using the constructed recognition model. We discuss these phases in detail in the following sections.
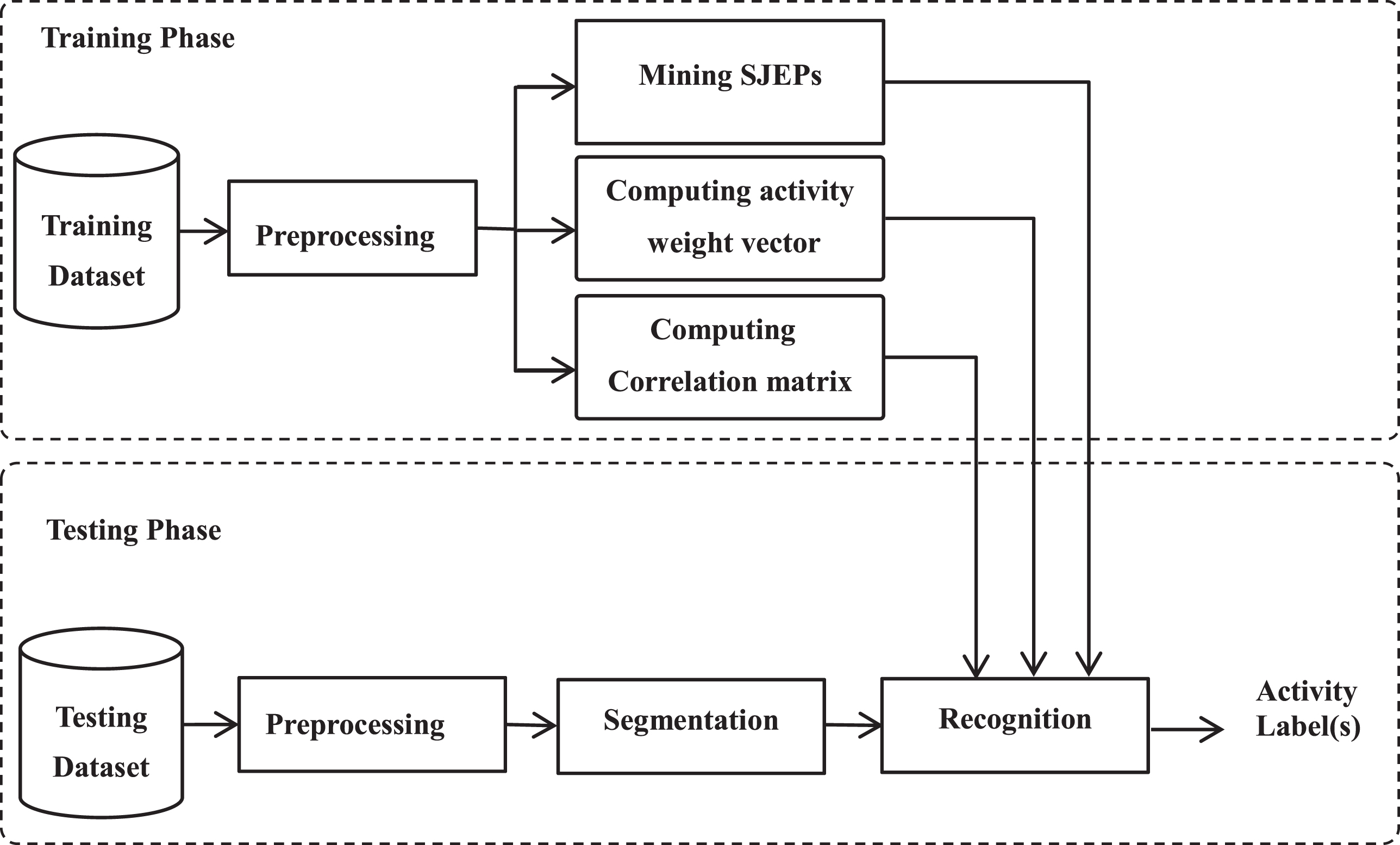
The proposed SJEP-based framework architecture.
Given a labeled dataset of observation sequences for different classes of simple activities, we perform the following steps.
Mining of strong jumping emerging patterns
Due to the characteristics of SJEPs, they make absolute class separation (i.e. they completely separate one class from the remaining classes). However, there are some cases where activities are not linearly separable. In order to deal with linear and nonlinear separated activities, we extract two classes of SJEPs, which are One-Versus-All SJEPs (OVA-SJEPs) and N-Versus-All SJEPs (NVA-SJEPs), for linear and nonlinear activities respectively. we present a hierarchical SJEPs mining approach that first searches for OVA-SJEPs for linearly separated activities. Then, for nonlinearly separated activities, it discovers NVA-SJEPs (N refers to the number of nonlinear activities). The SJEPs mining problem is a multi-objective optimization problem that can be described as follows:
m: number of simple activities. D
a
i
: preprocessed observation sequences for activity class a
i
, for i = 1, …, m
OVA-SJEPs for linearly separated activities. NLSA:The set of nonlinearly separated activities.
For each activity class a
i
, we use the FP-growth algorithm [22] to find the set of all possible itemset combinations for events/items in D
a
i
referred as X. Then for each candidate x ∈ X, we compute the following variables:
Finding the OVA-SJEPs Find a pattern x ∈ X that:
s.t. Finding the set NLSA of nonlinear separated activities such that |NLSA| < m
Find: s.t.
After obtaining the OVA-SJEPs and the set of nonlinear separated activities NLSA, the previously defined mathematical model is recursively repeated to find the NVA-SJEPs for the set of nonlinear activities in NLSA against the remaining activities.
A graphical illustration of the difference between OVA-SJEPs and NVA-SJEPs is presented in Fig. 4. Consider five activity classes {c1, c2, c3, c4, c5}, such that activities c1, c2, c3 can be separated linearly, but activities c4, c5 are nonlinearly separated (i.e. c5 is completely contained within c4). In such case, we extract OVA-SJEPs for c1, c2, c3 as illustrated in Figs. 4 a, b, c, and NVA-SJEPs for c4, c5 in Fig. 4d.
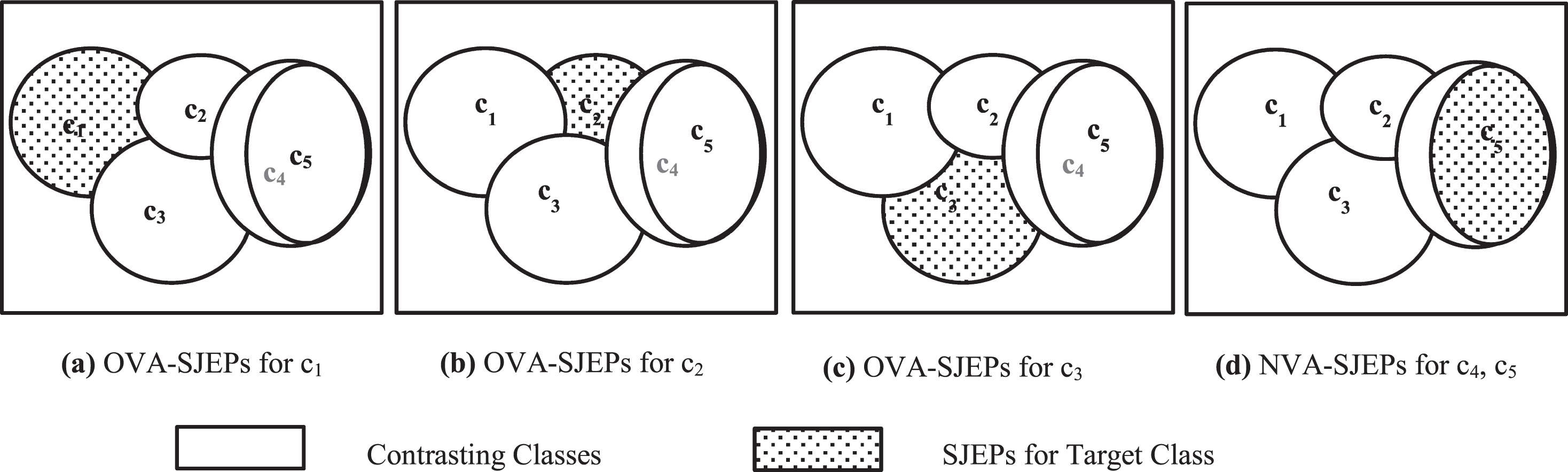
Graphical Illustration of the difference between OVA-SJEPs and NVA-SJEPs.
The second task in the training phase is to build an activity weight vector representing the discriminative power for each activity.
For m activities, we produce an m × 1 weight vector that is computed as follows:
Finally, we build the correlation matrix representing the interdependency between the sensors and the activities. In our approach, we measure the correlation using the support. We compute the support of each sensor within each activity class. For a specific activity, the sensor with high support is highly correlated to the activity and vice versa. For a training dataset of m activities, measured by n different sensors, we produce a m × 1 correlation matrix as follows:
The input to this phase can be a testing dataset or an online trace of sensor readings. In both cases, the input traces are segmented, and then the activities within each segment are recognized. These steps are explained in the following subsections.
Trace segmentation
There are two main trace segmentation approaches, fixed-size segmentation [5], and dynamic segmentation [23]. Fixed-size segmentation approach includes two methods, time-based, and event-based segmentation. In this paper, we use fixed-size segmentation that uses fixed-time sliding window to split the incoming activity traces into equal-sized time segments.
There are two main challenges with fixed-time segmentation. The first is the size of the sliding window used for segmentation. Activities occur with different durations, so it is difficult to find the exact size for the sliding window. The second challenge is the distribution of an activity over different segments. Therefore, while computing the score for an activity a at a specific segment s t , we should take into account its score in the previous segment.
Simple and complex activities recognition
For each test segment, to recognize the performed simple and complex activities, we perform the following steps. First, we identify the candidate activities by computing the matching score that measures the percentage of SJEPs contained in the test segment Equation (4). Then, we use our scoring function to measure the likelihood of the suggested candidates to the input test segment Equation (5). Finally, we decide that a specific activity exists in the test segment according to the formula in Equation (10).
The proposed approach for simple and complex activities recognition can be mathematically formulated as follows:
s
t
: a preprocessed trace segment of sensor readings. m: number of activity classes. n: number of sensors. OVA-SJEPs: SJEPs for linearly separated activities. NVA-SJEPs: SJEPs for nonlinearly separated activities. weight: an m × 1 activity weight vector. corr: an m × n correlation matrix.
-Win: The set of winning activities occurring at segment s t such that |Win| ≥ 1.
For each test segment, the following steps are performed. First, we identify the candidate activities by computing the matching score referred as mat
score
that measures the percentage of SJEPs contained in the test segment as follows:
If all the resulting candidates are linearly separated activities with OVA-SJEPs, then they are the winning activities. Otherwise, if the candidates contain nonlinearly separated activities, we compute the likelihood score for candidate activity a
i
at segment s
t
referred as lik
score
(a
i
, s
t
) that is defined as follows:
Complex activity recognition is a multi-label classification task such that multiple activities could be performed within a specific test segment. Moreover, using fixed-time segmentation, a specific activity could be distributed along multiple time segments. Therefore, at a specific test segment s
t
, an activity a
i
could be not contained, partially contained or fully contained in that segment. From fuzzy set perspective [24], each activity has a degree of membership in the incoming test segment according to the percent of its sensor readings/events contained in that segment which lies in the interval [0, 1] as shown in Fig. 5. From this point, we define the discriminative score for activity a
i
at segment s
t
referred as disc
score
(a
i
, s
t
) that represents the fuzzy membership degree of activity a
i
within segment s
t
.It equals the summation of the fuzzy membership values μ
a
i
(e) of all events e in s
t
to activity a
i
.

Fuzzy membership function for an activity within a test segment.
Finally, due to the challenges associated with fixed-time segmentation. While computing the score for an activity a i at a specific segment s t , we should take into account its score in the previous segment. This score is referred as the cumulative score cum score that is calculated using the correlation coefficient alpha a ∈ [0, 1].
Our main objective is to output the activity label(s) that occurs within the incoming test segment.
Find arg ai max(cumscore(a i ,s t ))
s.t.
Where λ is a user-defined parameter that tunes the threshold (i.e.mean (lik score )).
In Fig. 6, we present an illustrative example on the proposed recognition approach. In this example, for a specific test segment, we have three probabilities: existence of linear activities (Fig. 6a), nonlinear activities (Fig. 6b), or both linear and nonlinear activities (Fig. 6c).
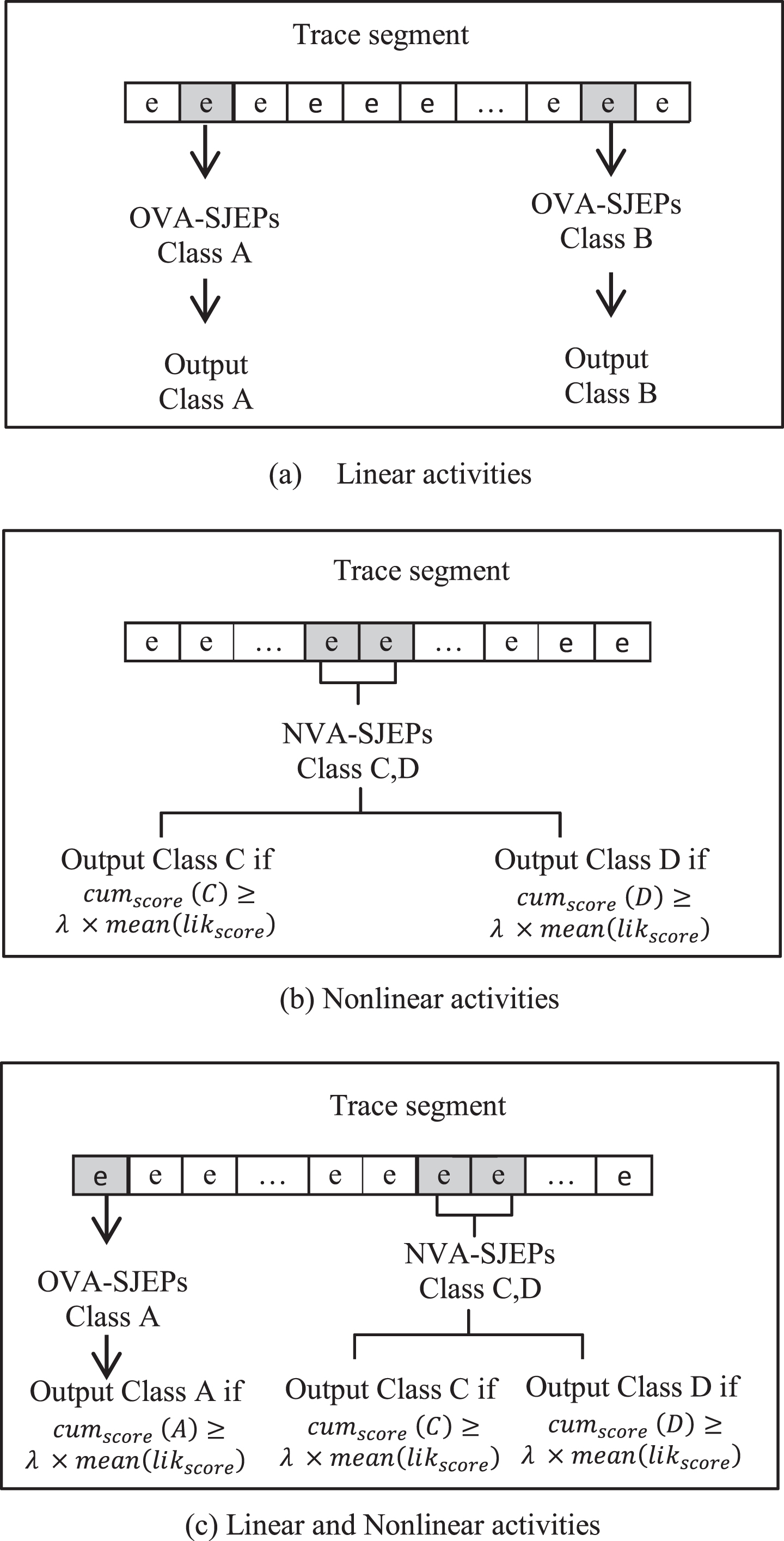
Illustrative examples for the proposed SJEP-based approach for simple and complex activities recognition.
As mentioned before, our proposed framework requires two main phases, training and testing. The main goal of the training phase is the extraction of SJEPs, which is a highly computational process, so this phase should be implemented offline. In this section, we analyze the complexity of the proposed SJEP-based recognition approach.
Assume the following: we have m activity classes with s sets of SJEPs,s ≤ m. Consider computing the matching score between a test segment and one set of SJEPs requires O (A), which is linear to the number of events in the segment. Then to check the existence of s sets of SJEPs we require s . O (A). The worst case occurs when both linear and nonlinear activities exist in the same segment. For k candidate activities, we require O (B) to compute the score for each candidate, and k . O (B) for all the candidates. As a result, the testing phase requires s . O (A) + k . O (B) for classifying a specific test segment.
Assume that the input stream is segmented into t segments; then the total complexity of the proposed method can be computed as t (s . O (A) + k . O (B))which is linear to the number of sensor events in the test segment, and s, k ≤ m.
Experimental results and evaluations
In this section, we evaluate the proposed approach for recognizing simple and complex human activities. First, we describe the datasets used, the implementation settings, and the evaluation settings. Then, the obtained results from experiments are presented and discussed.
Datasets
In the following experiments, we evaluate our SJEP-based approach using two datasets collected from two different labs. The first dataset is “The interleaved Activities of Daily Living” benchmarking dataset. This dataset was collected at CASAS [25] smart home repository at Washington State University [26] (CASAS for short) that is used in many researches such as [23, 27]. The second dataset is from [10] that contain sequential, interleaved, and concurrent activities (SICA for short).
The CASAS dataset contains eight activities listed in Table 1, collected by 20 subjects from a smart home equipped with eight different modalities of environmental sensors. To collect sequential activities, the participants (one at a time) perform each activity separately in the same sequential order. Then, the participants were allowed to perform any number of activities in an interwoven fashion to obtain a sequence of interleaved and concurrent activities.
Activities in CASAS Dataset [26]
Activities in CASAS Dataset [26]
The SICA dataset contains 26 activities listed in Table 2. These activities were performed by four subjects using two sets of wearable sensors; IMote2 set and RFID reader set. The subject wears IMote2 set on his hands and waist to measure user movement, and other environment-related information such as temperature, humidity, and light level. The subject wears the RFID readers on his hands for human-object interaction. During two weeks every day, each subject performed the activities in any order they decide, with a maximum number of two interwoven activities at the same time [10].
Activities in SICA Dataset [10]
We selected these datasets for three main reasons. First, both datasets used different methods for activity monitoring; the CASAS dataset used environmental sensors while the SICA dataset used wearable sensors. Second, the number of activities and the size of the dataset are different for both datasets; the number of activities and samples in the CASAS dataset is small with respect to the SICA dataset, including more activities and samples as illustrated in Table 3. Finally, the number of interwoven activities that form a complex activity was not limited in the CASAS dataset, but the SICA dataset limited that number to a maximum of two interwoven activities.
Number of Samples at CASAS and SICA datasets
In this section, we elaborate the basic steps required for the process of simple and complex HAR as shown in Fig. 7. Initially, to guarantee the robustness and flexibility of performance evaluation, we perform two experiments. The first experiment uses the CASAS benchmarking dataset, and the second one uses the SICA dataset. In both experiments, we evaluate the performance of the proposed approach to recognize simple and complex human activities.
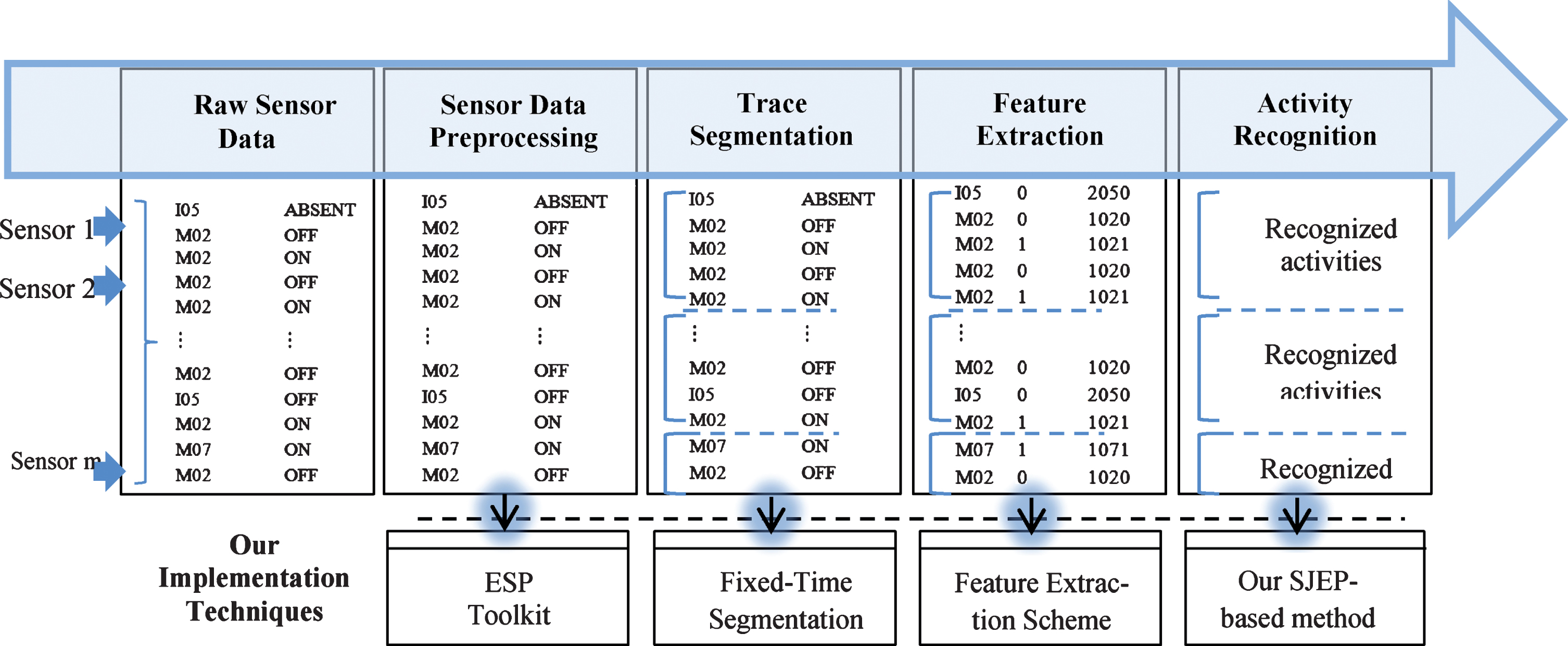
Visualization of the main components of the recognition phase.
We applied n-fold cross-validation to evaluate our approach. We used 3-fold cross validation for the CASAS dataset, and 10-fold cross validation for the SICA dataset as shown in Figs. 8 and 9 respectively. In each experiment, we use the simple activities from n - 1 folds for training and use the simple and complex activities from the remaining fold for testing. In Fig. 10, we present samples from the activity records at CASAS dataset used for training, whereas Fig. 11 presents a segment from sensor data stream used for testing. Then, for evaluation, we used the three standard evaluation metrics: precision (PR), recall (RC), and F-measure.

3-Fold Cross Validation for CASAS Dataset.
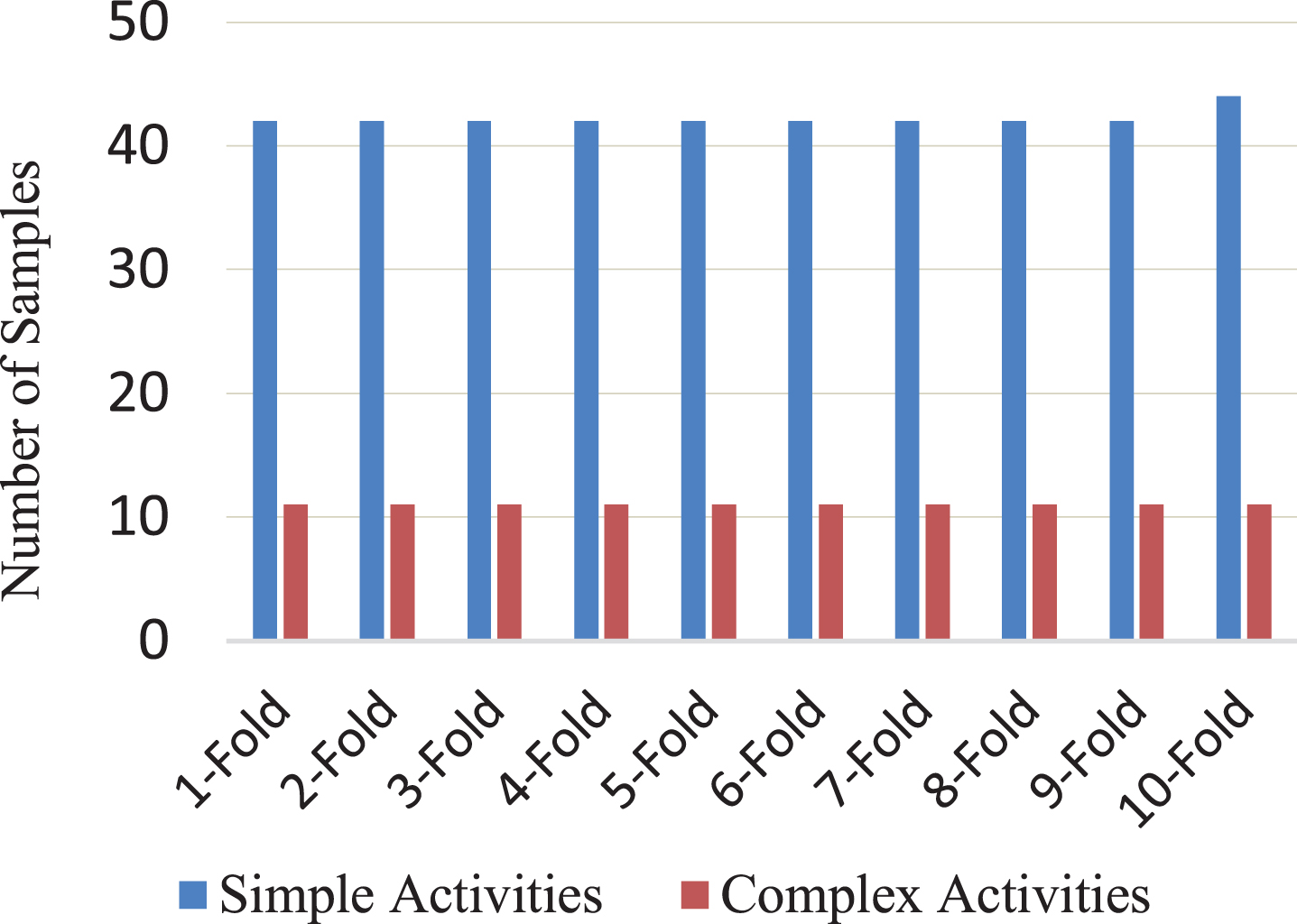
10-Fold Cross Validation for SICA Dataset.
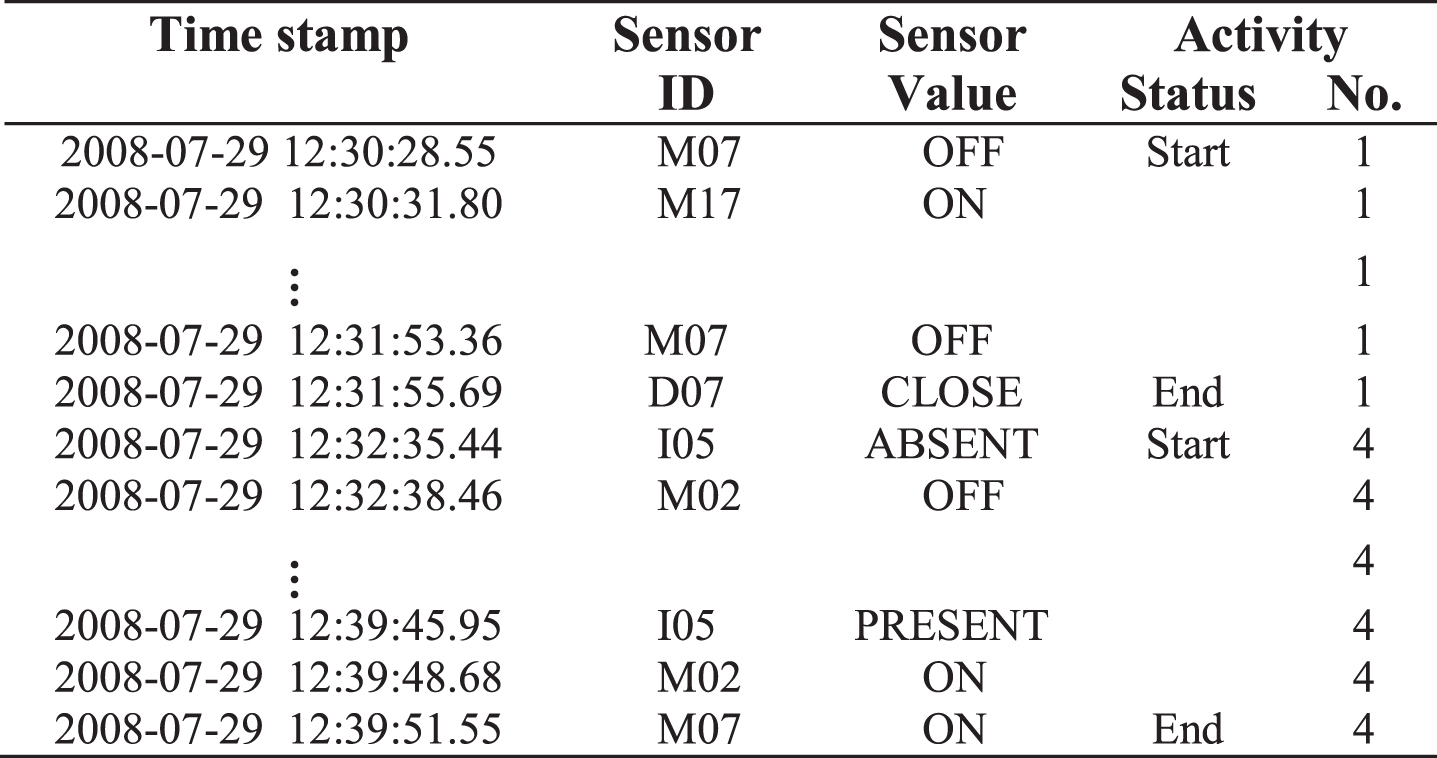
Sample records of simple activities used for training from CASAS Dataset.

Segment of stream of sensor readings used for testing from CASAS Dataset.
For complex activities recognition, we have a multi-label classification problem [30]. Therefore, we modify these evaluation metrics to deal with our problem as defined below.
In this experiment, we validate our SJEP-based approach using the CASAS dataset. In the training phase, during SJEP extraction process, all the activities are linearly separable except two activities, water plants and clean. As a result, we extract OVA-SJEPs for linear activities and NVA-SJEPs for these nonlinear activities with N = 2. In our approach, we have two key parameters, α, and λ. In order to analyze the sensitivity of these parameters, we evaluate our approach on fixed time segments t win = 2 × L avg . The results are shown in Fig. 6, where the X-axis represents λ, and the Y-axis represents the F-measure.
The results show that our approach reaches the best f-measure at α = 0.3 and λ = 0.1 that are used for the rest of this experiment.
For simple activity recognition, the average results for our SJEP-based approach compared with five popular classifiers (i.e. SVM, DT, NB, KNN, and HMM) is shown in Table 4. From these results, we notice that the competition is close between our approach and the remaining classifiers except NB and HMM. However, our approach outperforms the others with 100% accuracy for linear activities and almost 96% accuracy (i.e. F-Measure) for nonlinear activities.
The comparison results for simple activity recognition (CASAS dataset)
The comparison results for simple activity recognition (CASAS dataset)
For complex activities recognition, we compare our SJEP-based approach with [19]. The results for precision, recall, and F-measure are shown in Figs. 13–15 respectively, where the X-axis refers to the window size. We use different lengths for the time window t win that ranges from 0.1 × L avg to 3.5 × L avg .

Parameter Analysis (CASAS dataset).

The comparison of Precision in [19] and SJEP-based approach using CASAS dataset.
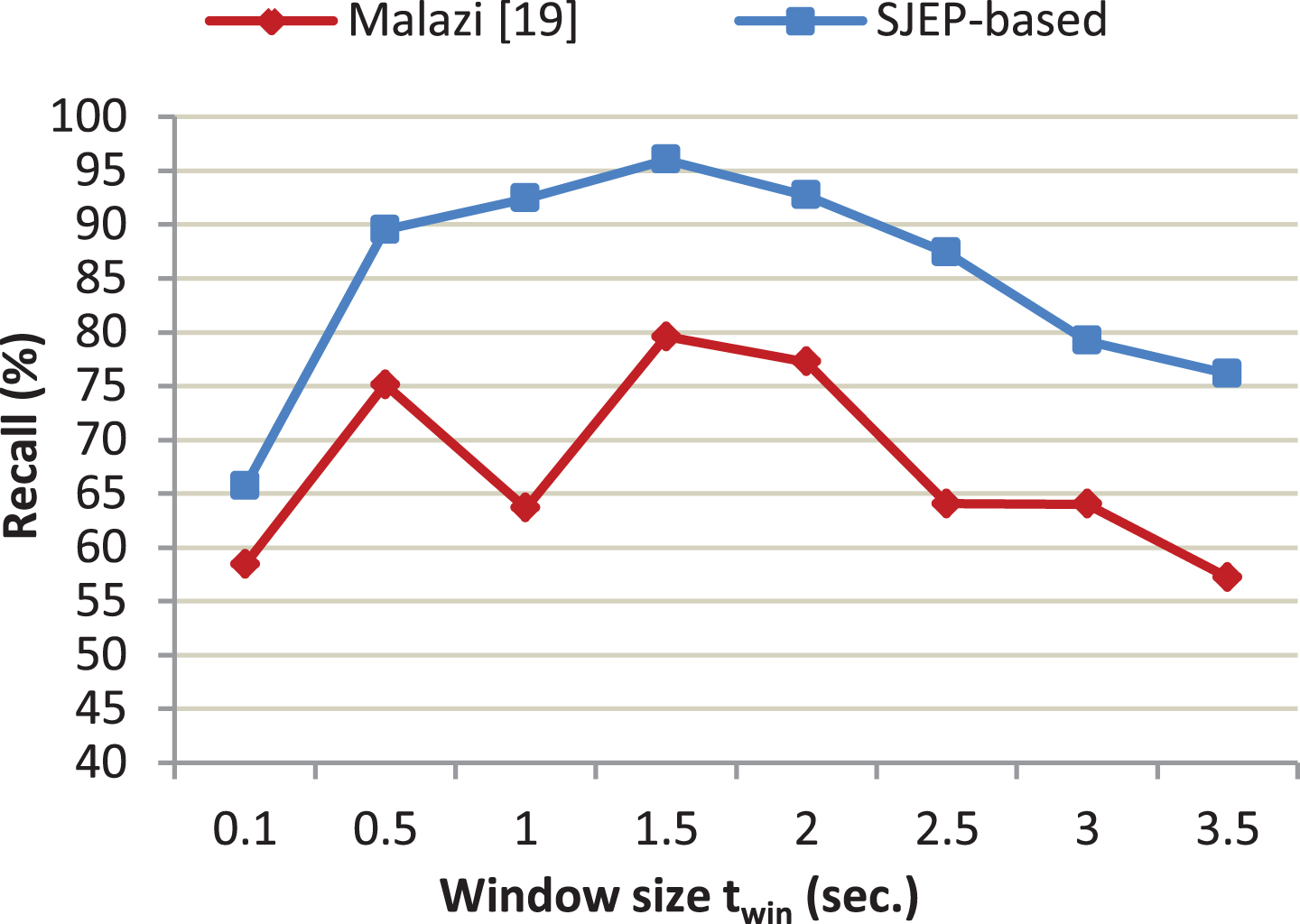
The comparison of Recall in [19] and SJEP-based approach using CASAS dataset.

The comparison of F-Measure in [19] and SJEP-based approach using CASAS dataset.
In this experiment, we follow the same evaluation steps done on experiment I using the SICA dataset.
First, in the training phase, we find that all the activities are linearly separable except two activities washing hands and washing face. Then, we analyze our key parameters α, and λ. The best F-measure at t win = 2 × L avg comes with α = 0.3 and λ = 0.1 as shown in Fig. 16.

Parameter analysis (SICA Dataset).
For simple activity recognition, we compare our approach with five common classifiers as shown in Table 5. From comparisons, our SJEP-based approach outperforms the others with an overall accuracy of 96.34%, with an acceptable performance of 90% with nonlinear activities.
The comparison results for simple activity recognition (SICA dataset)
For the recognition of complex activities, we compare our SJEP-based approach with another method in [10]. The results of our evaluation metrics are shown in Figs. 17–19, where the X-axis represents the window size that ranges from 0.1 × L avg to 3.5 × L avg .

The comparison of Precision in [10] and SJEP-based approach using the SICA dataset.

The comparison of Recall in [10] and SJEP-based approach using the SICA dataset.

The comparison of F-Measure in [10] and SJEP-based approach using the SICA dataset.
Using two different datasets for evaluation, the obtained results indicate the efficiency of the proposed approach besides its superiority against other state-of-the-art and EP-based competing approaches for recognizing simple and complex activities.
For simple activity recognition, we compared our SJEP-based approach with five popular classifiers (i.e. SVM, KNN, DT, HMM and NB). As a result, our approach outperformed the others, it achieved 98.6% in Experiment I and 96.34% in Experiment II followed by SVM, KNN, DT, NB, and HMM for the following reason. For sensor-based HAR, the size of the collected dataset is relatively small compared to real world situations and our SJEP mine for differences between activity classes rather than similarities that best suits this situation. In contrast, the discriminative SVM, KNN, and DT search for similarities which decreased their performance. In addition, the generative HMM and NB over fit the training data and require attribute independence assumption.
For complex activities recognition, we compared our proposed SJEP-based approach with two other EP-based approaches in [10, 19]. Remembering that activities occur with different durations, there exist short-term activities and long-term activities. In small window sizes, long-term activities are distributed along many segments, while large window sizes reduce the classification accuracy of short-term activities. Therefore, through evaluation, we note that all approaches show degradation of F-measure at small and large windows. However, the combination of SJEPS and fuzzy set theory within the proposed model overcomes this challenge and the results of F-Measure indicate the efficiency and superiority of our SJEP against the others [5, 3] that are 94.02% and 92.04% in experiments I and II respectively.
Conclusion
In this paper, our main objective is to design a general framework that can recognize any number of overlapping activities with linear and nonlinear characteristics using a training dataset of simple activities. The proposed SJEP consists of two phases: training and testing. In the training phase, we mine for irregularities in the training dataset and extract the discriminative SJEPs for linear and nonlinear activities. Next, in the testing phase, for each test segment, we apply our scoring function to compute the score for candidate activities, and then output the activity labels(s) that meet a specific criterion. We evaluate our approach using two datasets collected from two different labs with different characteristics. The results show the efficiency of the proposed approach in recognizing both simple and complex activities. On comparison with two common approaches incorporating the concept of Emerging Patterns, the results reflect the superiority of our approach with respect to recognition accuracy.
The use of SJEPs increases system scalability; it is easy to append new activity class through its SJEPs. Regarding noise tolerance, sensor data often contains noise with random distribution. So mining the differences between data is most effective than mining the regularities. To summarize, this paper proposed an efficient, scalable, error and noise tolerant model for sensor-based complex activity recognition. We look afterwards in the future to devise a dynamic segmentation algorithm exploiting both context and spatial information. In addition to this, we shall extend our work to deal with multi-residents applications.