
Abstract
Smartphone-based periocular recognition (SPR) has gained significant attention because of the limitations of face and iris biometric modalities. For this problem, most of the existing methods employ hand-crafted features. On the other hand, deep convolutional neural networks (CNN), which learn features automatically, have shown outstanding performance for many visual recognition tasks over hand-crafted features. In view of this paradigm shift, we propose an SPR method based on CNN model. A CNN model needs a huge volume of data, but for periocular recognition problem only limited amount of data is available. One solution for this issue is to use a CNN model pre-trained on the dataset from a related domain, but this raises the questions of how to extract discriminative features from a pre-trained CNN model and classify them. We introduce a simple, efficient and compact image representation method based on a pre-trained CNN model (VGG-Net). This method employs the wealth of information and sparsity existing in the activations of convolutional layers of a CNN model. For recognition, we use an efficient and robust Sparse Augmented Collaborative Representation based Classification (SA-CRC) technique. For a thorough evaluation of ConvSRC (the proposed system), experiments were carried out on the VISOB database, which was presented as the challenge dataset in ICIP2016. The results show the superiority of ConvSRC over the state-of-the-art methods; it obtains a GMR of more than 99% at FMR = 10-3 and outperforms the first winner of the ICIP2016 challenge by 10%.
Keywords
Introduction
With the development of smart devices equipped with digital cameras and significant computational power, the biometrics research has turned its focus to mobile-based biometrics. Face is one of the most popular biometric modality, which performs well; however, the performance declines if the face is partially hidden [1]. The whole face of criminals often does not appear in surveillance videos. In some situations, the face is either covered by helmets, hair, glasses or skiing masks. Furthermore, due to cultural and religious reasons, women cover their faces partially in some countries. In these scenarios, the region around the eyes (periocular) is the only visible trait which can be used as biometric (see Fig. 1). Also, the acquisition of the image of the periocular region does not require high user cooperation and close capture distance unlike other ocular biometrics (e.g., iris, retina, and sclera). The periocular region gives a trade-off between the whole face and the iris alone.

Examples of some cases where using periocular biometric is effective.
Several efforts have been made on periocular recognition [2–4]. Most of the existing techniques use hand-crafted features such as Block HOG [5], HOG [6] and Color histogram [7], SURF [8], LBP [9, 10], Phase Intensive Local Pattern (PILP) [11] and SIFT [12]. The state-of-the-art techniques include the deep sparse representation [13], BSIF [14], Local phase Quantization (LPQ) features [15], Block BSIF [16], Phase Intensive Local Pattern (PILP) [40], Hybrid deep learning [41] and Deep Sparse Filters [17]. Only few works used learned features [18–22, 41]. For recognition, mostly KNN with distance metrics such as city block [9, 24], Euclidean [1, 25], chi-square [12, 27] and mean square error [28] has been used. Some works used learning based techniques like SVM [18, 29], and Neural Networks [19, 17].
Recent studies have shown that learned features are more effective than hand-crafted features [2, 30]. Currently, though CNNs, which learn features automatically, have attracted a lot of attention for visual recognition tasks due to their outstanding performance [31], a huge volume of data is needed for their learning. For periocular recognition, a huge amount of data is not available and it is hard to learn descriptive features using CNNs. According to some studies, when a CNN model, pre-trained on a large dataset from a related domain, is employed for a visual classification task with small dataset, it results in impressive performance [32]. Most of the methods based on pre-trained CNN models use the activations of a fully connected layer as a representation (global features). The recent studies have shown that there is a wealth of information encoded in convolutional layers (local features), which results in better performance [33, 34]. In view of this, we examined the potential of convolutional layers for periocular recognition.
Recently, sparse and collaborative representation based classification techniques have shown promising results [35]. In a recent work, Naveed et al. [36] proposed Sparsity Augmented Collaborative Representation based Classification (SA-CRC) technique, which is the augmentation of a dense collaborative representation with a sparse representation and improves the recognition performance. In this study, we examined its usefulness for periocular recognition.
Motivated by the effectiveness of convolutional layers and SA-CRC, we propose a simple technique for extracting local features from convolutional layers using a pre-trained CNN model, and a periocular recognition method based on local CNN features and SA-CRC, we call this method as ConvSRC. The development of the method raises many questions: (1) how to extract discriminative features from convolutional layers for periocular recognition? (2) can deep features extracted using CNN models pre-trained on a dataset from a related domain (e.g. face dataset) be generalized to periocular recognition task? (3) are the features extracted using CNN model pre-trained on a dataset of natural images (e.g. ImageNet dataset) effective for this task? (4) which features (i.e. local or global) are more suitable for this task? (5) Is SA-CRC effective with deep features?
To answer these questions, we thoroughly analysed the performance of different feature representations extracted from convolutional and fully connected layers using the pre-trained VGG-Face [37], which is learned on a dataset from a closely related domain, and VGG-16 trained on ImageNet dataset. For classification, we investigated the impact of using SA-CRC [36] compared to KNN, ridge regression and different fusing methods of the collaborative (CRC) and sparse (SRC) representations. Extensive experiments conducted on VISOB, the ICIP2016 challenge dataset for smartphone periocular recognition [30], show that ConvSRC gives promising results; it outperforms the state-of-the-art methods and the first winner of the ICIP2016 challenge (up to 10%).
The Novelty of the proposed method is to use a pre-trained CNN model to overcome the small data size issue for periocular recognition problem and the procedure to extract discriminative features from the CONV layers of the pre-trained CNN model. The main contributions of this paper are summarized as follows: Proposes an efficient and robust periocular recognition method, which is based on the discriminative feature extraction technique from a pre-trained CNN model and SA-CRC classifier. Demonstrates that for periocular recognition problem, local and global periocular CNN features, even with a simple KNN classifier, result in remarkable performance improvement over the state-of-the-art hand crafted and learned features. Thoroughly examines the effectiveness of local and global features and shows that for periocular recognition, local features extracted from a convolutional layer encode more discriminative information than global features determined from a fully connected layer. Empirically, it was found that VGG-16 pre-trained on ImageNet [38] results in almost similar features extracted using VGG-Face model. This outcome reveals the strength of VGG architecture.
The rest of the paper is organized as follows. Section 2 provides the detail of the proposed method. The evaluation protocol is described in Section 3. The model selection is discussed in Section 4, while the results and discussion are presented in Section 5. Finally, Section 6 concludes the paper.
A systematic diagram of the proposed method (ConvSRC) is shown in Fig. 2. First, the input image is resized to 224x224 and passed to VGG Net to obtained the activations of convolutional and fully connected layers. These activations are sparse and include a wealth of discriminative information, and principal component analysis (PCA) is employed to extract discriminative features from them. Finally, SA-CRC is used for decision making.
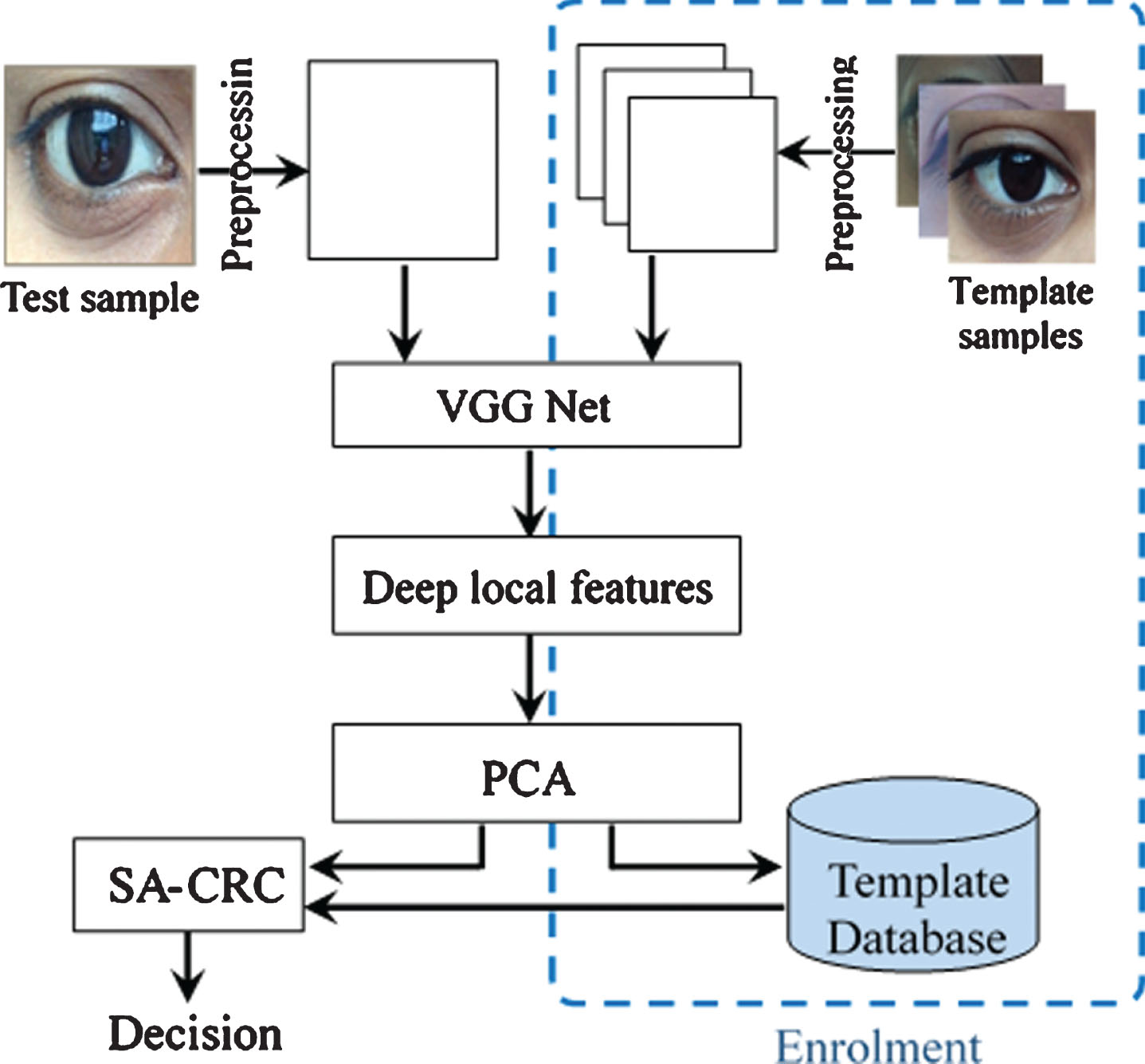
The systematic diagram of ConvSRC.
For extracting CNN features, the first task is to select the suitable CNN model. VGG Net is a commonly used model [39], which have shown promising results for different Computer Vision applications. We adopted very deep VGG-Face model, which is a VGG-16 model and is trained on face image dataset, a domain related to periocular recognition. Our selection is based on the observation that periocular region is a part of face and CNN learns hierarchy of features in such a way that higher level layers encode object parts.
The structure of Very deep VGG-Face model is shown in Fig. 3; it comprises 5 blocks of convolutional (CONV) layers, each followed by max pooling layer and three fully connected (FC) layers. Each CONV layer generates feature maps (activations) by convolving the input with a bank of linear filters, learned during training and is followed by a rectification layer (ReLU), which applies ReLU non-linearity on the features maps. The feature maps of low CONV layers are large in size but small in number but those of higher CONV layers are smaller in size but larger in number. The size of feature maps of first CONV layer is 224x224 and their number is 64, whereas the size of feature maps in last CONV layer is 14x14 and their number is 512. This structure encodes hierarchy of features. The last three layers are FC layers, which process the features with linear operation followed by ReLU non-linearity. The output of the first two FC layers is a 4,096-dimensional vector each and the last FC layer yields a vector of dimension 2,622, which is passed to a softmax layer to compute the class posterior probabilities. The input to the network is an RGB image of size 224×224. This network was trained using a huge dataset (2.6M face images of 2.6K people).
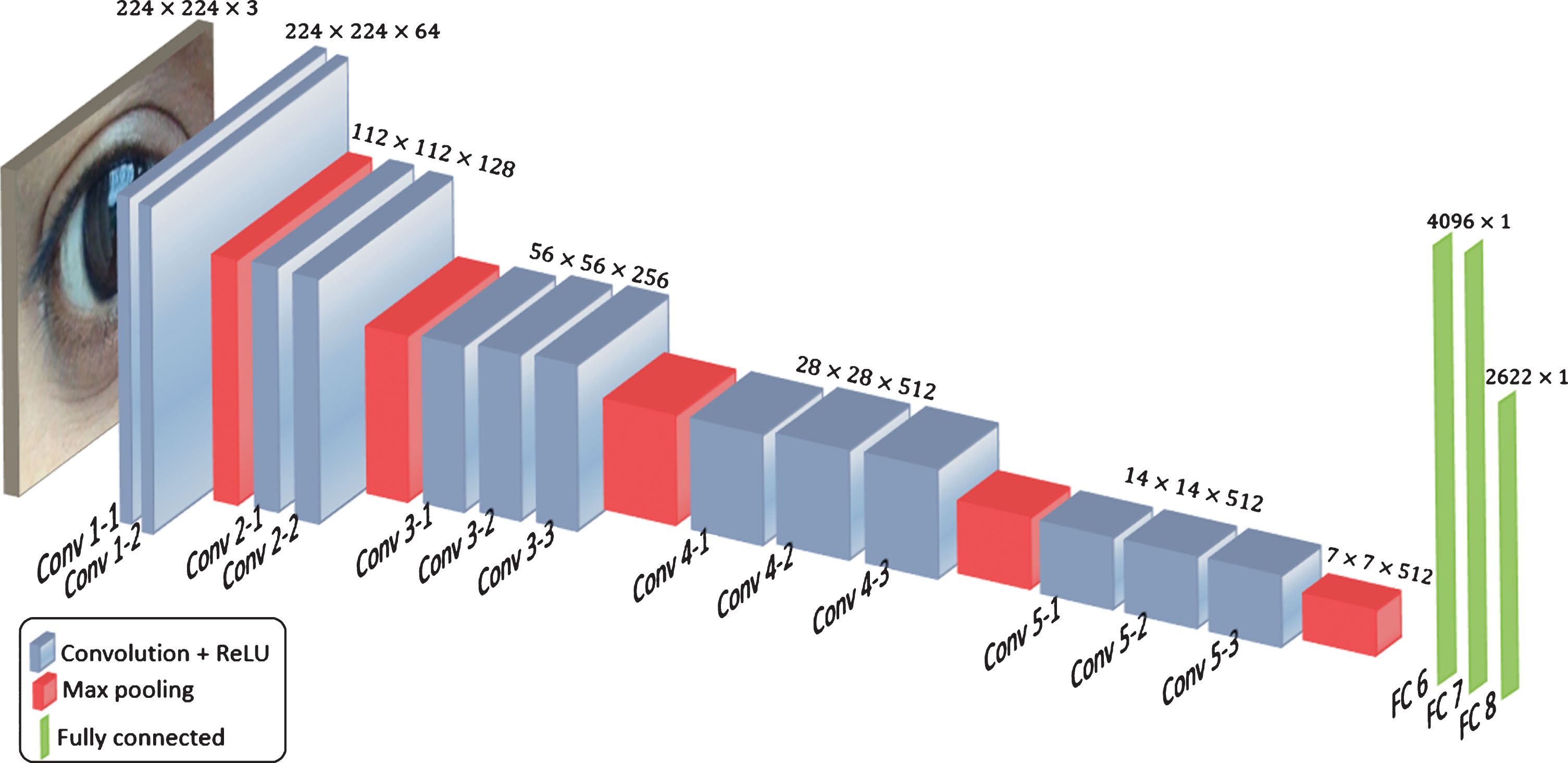
The architecture of VGG-Face.
Activations of different layers of a CNN model encode very rich information and can be employed for extracting discriminative features. CONV layers encode low, medium and high level features along with their spatial information, whereas fully connected (FC) layers embed global features discarding the spatial information. Layer selection is the key success factor to extract discriminative features for a certain application. We propose to extract two types of features: (1) global, extracted from an FC layer (2) local, extracted from a CONV layer.
Most of the pre-trained CNN based feature extraction methods use the activations of FC layers as representation; it has been shown that the activations of CONV layers are more informative [33, 34]. Unlike FC layers, CONV layers encode hierarchy of local features and retain the spatial information and can lead to more discriminative representations.
For local features, we focus on CONV layers. In very deep VGG-Face, low level CONV layers encode low level facial features such as micro-texture features, and high level CONV layers encode facial parts like lips, nose and different parts of periocular region. As such high CONV layers (Conv5_1, Conv5_2, Conv5_3) are the best choices for extracting local deep features. One simple way is to vectorise each feature map p
i
(i = 1, 2, ... , n) of a CONV layer to
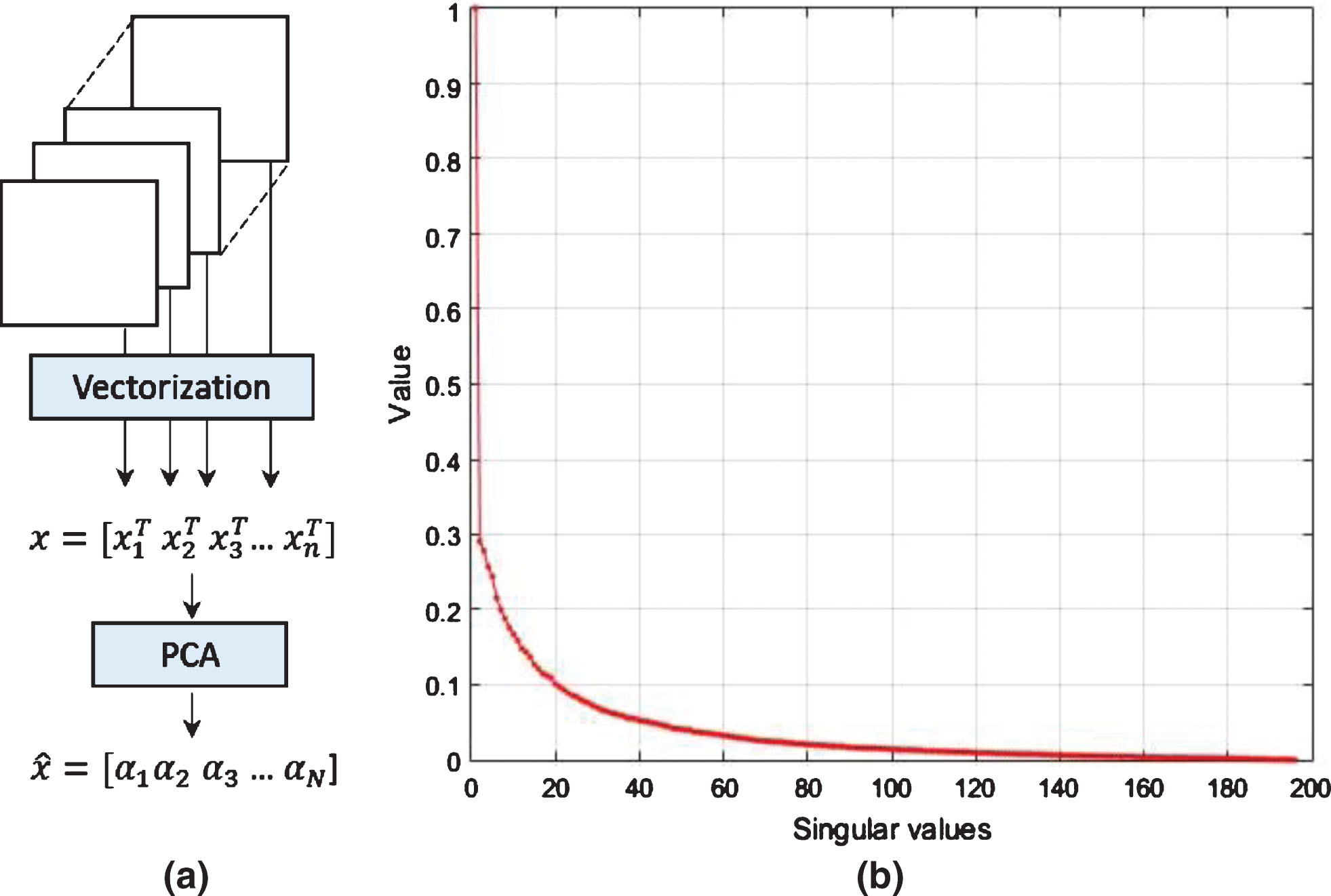
(a) Computation of local deep CNN features. (b) The singular value decomposition of the feature maps of an image.
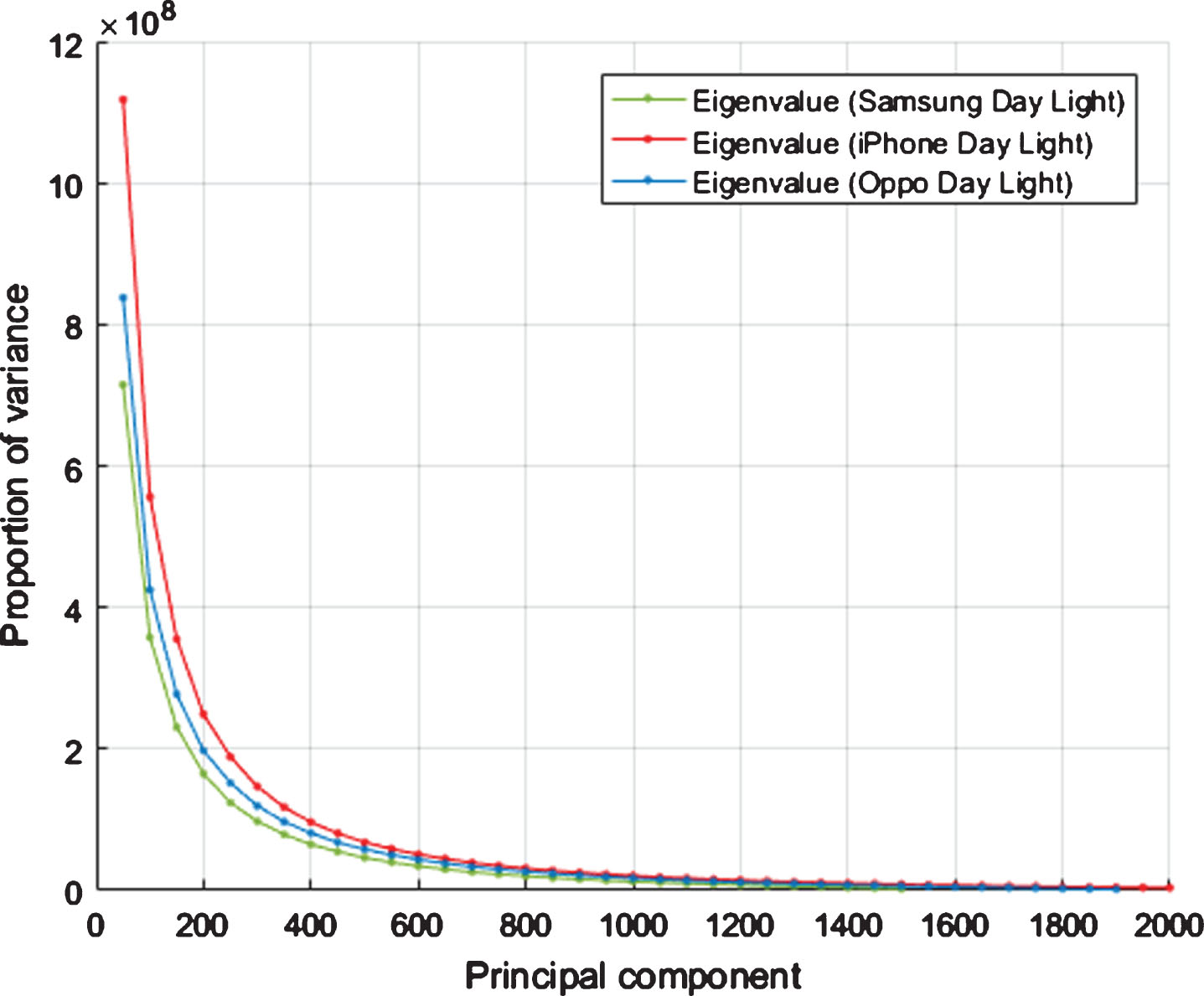
The proportion of the variance of the principle components for Samsung, iphone and oppo with day light condition from VISOB dataset.
The activations of FC layers of VGG-Face model are taken as global features, the spatial information is not retained in FC layers. There are three FC layers in the model, we examined the effect of each layer, and the detail is provided in Section 4.1.1.
Sparsity Augmented Collaborative Representation based Classifier (SA-CRC)
Using the extracted features (global/local) from the enrolment set, we form the dictionary φ = [φ1, φ2, …, φ
c
] ∈ RK×N, where the sub-matrix φ
i
∈ RK×n
i
is computed from feature vectors (normalized using l2-norm) corresponding to n
i
examples of the ith class, c is the total number of classes and
Then
Finally, these solutions are augmented as follows [36]:
Algorithms 1, 2 and 3 present the detailed description of the steps involved in enrolment, verification and identification processes; respectively.

We implemented the system using MATLAB R2015a on a PC with Intel (R) Core ™ i7-3610QM CPU @ 2.30 GHz and 12 GB RAM. The experiments were conducted on VISIT 1 of VISOB dataset [30], which is available in public domain. The identification performance of the system is reported in terms of accuracy, whereas the performance of verification is reported in terms of Genuine Match Rate (GMR) at False Acceptance Rate (FAR)=10-2 and Equal Error Rate (EER). Further, the performance of the system for verification has also been presented in terms of Receiver Operating Curves (ROC).
Visible Light Mobile Ocular Biometric Database (VISOB) contains ocular images from 550 healthy adult volunteers acquired using front facing cameras of three different smartphones i.e. Samsung Note 4, iPhone 5 s and Oppo N1. The Oppo and Samsung devices captured images at 1080p resolution, while the images captured by iPhone are at 720p resolution. The dataset is divided into enrollment and validation sets (see Table 1). It was presented as a challenge dataset in ICIP2016 for periocular recognition, the detail can be found in [30]. For evaluation, we used the recommended protocol.
Detail of the enrolment and validation sets of VISOB Dataset
Detail of the enrolment and validation sets of VISOB Dataset
The final design of ConvSRC involves various design decisions: global vs local deep features and the number of principal components (PCs). For these decisions, the experiments are conducted on one subset of VISOB dataset i.e. Samsung left periocular images under day light condition.
Global vs local deep features
First, we address two design questions: which CONV/FC layer is suitable for extracting local/global deep CNN features? Which type of features (local/global) is more discriminative for periocular recognition? To answer these questions, we conducted extensive experiments for identification and verification tasks.
Global deep CNN features
VGG-Face contains three fully connected layers: FC6, FC7 and FC8. The FC6 and FC7 layers yield 4096 features whereas the FC8 layer extract only 2622 features. The verification and identification results shown in Tables 2 and 3, respectively, indicate that the features extracted from FC6 provide the best results. Also, we notice from Table 3 that PCA reduces the dimension significantly (from 4096 to 500), but the decrease in accuracy is negligible. We tested with fixed number (500) of principal components (PCs) and the number of PCs, which save 99% of the information.
Verification results using features extracted from FC6, FC7 and FC8 and SA_CRC
Verification results using features extracted from FC6, FC7 and FC8 and SA_CRC
Identification accuracies (%) using features extracted from FC6, FC7 and FC8
There are thirteen CONV layers in VGG-Face architecture. We selected the last three CONV layers (i.e. conv5_1, conv5_2 and conv5_3) for our experiments on local deep CNN features. The reason for this selection is that the first layers encode texture information whereas last layers capture higher level features which represent the rich object based structural information in a better way and result in discriminative description. Each of these CONV layers contains 512 feature maps of size 14×14 units. The results obtained with local features extracted using the local deep CNN feature extraction technique described in Section 2.1.1 are shown in Tables 4 and 5; these results indicate that conv5_2 outperforms the other two layers in terms of EER and GMR, there is significant difference, especially, in EER and GMR at FAR = 0.001. PCA reduces the dimension of the feature space significantly without declining the verification and identification performance as is obvious from Table 5, the feature vectors of dimensions 100352 and 500 (reduced using PCA) from Conv5_2 give almost the same rank-1 identification result.
Verification results of features extracted from conv5_1, conv5_2 and conv5_3
Verification results of features extracted from conv5_1, conv5_2 and conv5_3
Identification accuracies (%) of features extracted from conv5_1, conv5_2 and conv5_3
There is significant difference in the performance of the three CONV layers. As we move higher in the hierarchy of the CONV layers, the low level features are composed into higher level abstractions, the results indicate that the composition of features at Conv5_2 results in the most discriminative features, which are further combined into higher level abstractions by Conv5_3 that defuses the features relevant to periocular regions. This effect further spreads up to FC layers, and one can see that the performance of FC layers is even worse that Conv5_3, look at EER values yielded by Conv5_3 in Table 4 and those by the FC6, FC7 and FC8 layers in Table 2. It indicates that Conv5_2 composes the lower level features into the representation that keep the structural information, which is important for discrimination of periocular region. From now onward, ConvSRC means the periocular recognition method that employs Conv5_2 for feature extraction.
In the previous sections, we presented and discussed the individual effects of global and local deep CNN features. The discussion revealed that local features form better representation than global features. Next question is whether the fusion of local and global features can improve the recognition performance. To address this question, we tested the effect of fusing local and global features. As FC6 and Conv5_2 result in the best performances among FC and CONV layers, we fused the features from the FC6 layer and the local features from the Conv5_2 layer. The features are fused after standardizing them so that each feature has zero mean and unit variance. The results are shown in Tables 6 and 7, which indicate that there is no improvement; instead, there is some deterioration in performance, which is due to the reason that the FC6 layer defuses the relevant features. A comparison between global, local and their fusion for verification and identification is given in Fig. 6. It further validates that fusion of global and local features does not improve the performance.
Verification results of the combination of local and global features
Verification results of the combination of local and global features
Identification accuracies (%) of the combination of local and global features

Comparison of the verification (a) and identification (b) results using different feature extraction methods.
The proposed approach involves dimension reduction using PCA. In PCA, the critical point is the selection of principal components (PCs) corresponding to the largest eigenvalues. Many criteria have been proposed in the literature in order to find the optimal number of dimensions in PCA. Due to the computational complexity of such techniques, we used a simple method which results in good result. We tried different numbers of components using three light conditions of the left eye of Samsung dataset. Figure 7 gives the detail; as the number of PCs increases EER decreases and it continues to decrease until the number of PCs is 1300, where it attains minimum value for all the three cases. It indicates that this number is a suitable choice for PCs, for onward experiments, we fix the number of PCs to be 1300.
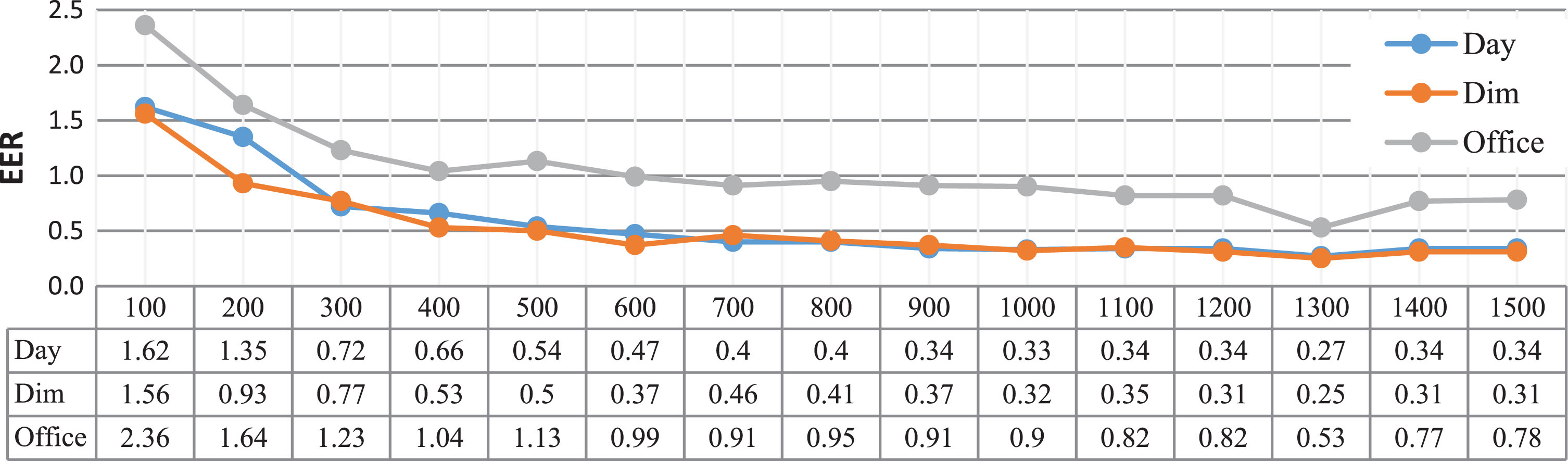
Equal Error Rate (EER) results of using different PCs on Samsung left eye dataset.
OMP algorithm is used to solve the optimization problem of equation (2) to get the sparse representation. OMP iteratively selects k dictionary vectors to represent the test samples and the sparse representation has at most k non-zero coefficients. To fine-tune the value of the sparsity level k, we performed experiments with different values of k on Samsung left periocular images under office light condition. The verification results and the time complexity are shown in Table 8. This table indicates that as the sparsity level increases (the sparsity decereases), the time required by OMP algorithm increases, while the performance in terms of EER and GMR at FAR = 0.01 decreases; the best value of GMR at FAR = 0.01 is achieved with k = 50. In view of this observation, the best time-performance trade-off is given by k = 50 and we used this value of k in our experiments.
Verification results and the average time needed by OMP algorithm using different sparsity level k
Verification results and the average time needed by OMP algorithm using different sparsity level k
In the previous section, we presented the discussion about model selection; based on this discussion the model of the proposed method consists of local deep CNN features extracted from Conv5_2 with 1300 PCs and sparsity threshold k = 50; and SA_CRC (ConvSRC). Using the model, this section reports results for verification and identification problems and discuss the performance of the proposed method in comparison with the existing methods.
Verification problem
First, we report the verification results of the proposed system; Table 9 shows the performance in terms of GMR and Figs. 8, 9 and 10 show the ROC curves for the left and right periocular regions captured by three types of smartphones under different lighting conditions. The results show the outstanding performance of the proposed method; it can be noted from Figs. 8 to 10 that it gives better results for day-light for the three devises and these results are almost similar. The performance is slightly poor for dim-light in case of iPhone, and for office-light in case of Samsung and Oppo. Almost similar results can be noted from Table 9 in terms of GMR.
Verification performance (GMR at FAR = 10–2) on VISOB dataset
Verification performance (GMR at FAR = 10–2) on VISOB dataset

ROC curve of the proposed method on iPhone data.

ROC curve of the proposed method on Samsung data.

ROC curve of the proposed method on Oppo data.
The comparison of the verification performance of ConvSRC with the state-of-the-art periocular verification methods is given in Table 9. It can be observed that ConvSRC performs better than the state-of-the-art methods for the three mobile devices and all light conditions. To check whether the difference in the performance of the proposed method and the state-of-the-art methods is statistically significant, we used the Wilcoxon signed rank test with 95% confidence level with null hypothesis that the performance of the proposed method is equal to that of a state-of-the-art method and alternative hypothesis that the proposed method is better than other methods. It can be noticed from last column of Table 9 that the proposed method is better and the difference is significant at 95% level (p-values<0.05 for methods).
ConvSRC significantly outperforms MR Filters [19] and Deep Sparse Filters [17], which are the first and the second winners, respectively, of ICIP2016 periocular competition on VISOB dataset. MR Filters, Deep Sparse Filters and ConvSRC employ learning based feature extraction methods. These results show that learning based features outperform the hand-engineered features, and among learned features, the features based on Deep CNN (ConvSRC) performs better because of its deeper structure, which captures the hierarchy of features in a better way and composes the discriminative description.
Moreover, we compare the performance of ConvSRC with that of MR Filters (i.e. the first winner) in detail. Figure 11 shows the detailed comparison of the three devices and the three light conditions of VISOB dataset. For fair comparison with MR filters, we reported the results in terms of GMR at FAR = 10-3 similar to that used for MR Filters. It can be observed that there is a large gap of performance that the proposed method achieved over MR Filters; the reason for better performance is that the deeper architecture of CNN captures the more discriminative description.

Comparison of the verification performance of the proposed method with MR Filters (1st winner of ICIP2016 competition)
The VISOB dataset was prepared for verification purpose. To adapt it for identification, we only consider the images of the subjects that are available in both verification and enrolment sets. We observe from Fig. 12 that the proposed method performs well for identification task. Also, we notice that the office light condition is the most challenging set in identification in case of all of the three mobile devices.

Identification performance of the proposed method on VISOB dataset.
The question arises whether the performance of the proposed method is due to SA-CRC classification. To this end, we passed pixel values of the original image as features to SA-CRC and compared the results with those obtained using CNN features. For this experiment, we used iPhone left under day light condition dataset. The results have been shown in Table 10; there is a significant difference between the results, especially EER and GMR at FAR = 10-3. It indicates that CNN features are effective in performance improvement.
Effectiveness of CNN
Effectiveness of CNN
The next question is about the impact of SA-CRC. For this purpose, we compare the results obtained using SA-CRC with those achieved employing KNN and ridge regression. Also, we investigate the effect of fusing the collaborative (CRC) and sparse (SRC) representations in different ways to highlight the effectiveness of the augmentation method used in SA-CRC. The identification results on the Samsung left under office light condition (see Table 11) show that SA-CRC achieved the best result.
Effectiveness of SA-CRC
Effectiveness of SA-CRC
We employed pre-trained VGG-16 model, which was trained on face dataset and so it encodes the periocular regions. The question arises whether we can get the similar performance using a pre-trained VGG-16 model, which is trained on a dataset of natural images from different domain. For this, we used VGG16 model that was pre-trained on ImageNet dataset [38]. A comparison of the results obtained with VGG16-Face and VGG16-ImageNet is depicted in Fig. 13; it is surprising to note that the results are almost similar; it indicates that ConvSRC is independent of the pre-trained model domain. For further investigation, we randomly selected 2 subjects and 10 features created with VGG16-Face and VGG16-ImageNet models, and created the boxplots of features generated by the two models corresponding to each subject, see Fig. 14. The boxplots corresponding to subject 1 indicate that the distributions of features generated by VGG16-Face are different and those of features generated by VGG-ImageNet are also different. Similar is the observation about the features of subject 2. It indicates that though the features created by each model do not have similar distributions, they are discriminative in each case. It demonstrates that the domain of the pre-trained model is not important for extracting discriminative features for periocular recognition as long the domain consists of natural images.

Comparison of the verification performance of ConvSRC using VGG16-Face and VGG16-imagnet pre-trained models.

Comparison of the features extracted from two subjects with pre-trained (a) VGG16-Face and (b) VGG16-imagnet models.
To further investigate the consistency and generalization ability of ConvSRC, we performed cross-light and cross-device experiments. In cross-device experiments, the gallery and probe sets are captured under different light conditions, whereas in cross-devise experiments, the gallery and probe sets are captured with different devices.
The results of cross-light experiments are shown in Table 12. Overall, the results for native-light (the same light conditions for gallery and probe sets) and cross-light authentication are similar. There is no significant degradation in the results for cross-light cases in terms of GMR@FAR=0.1. However, there is a slight decrease in performance in terms of GMR@FAR=0.001, but it is not due to cross-light, but due to light condition whether bright or dim. When day light (bright light) is used for gallery or probe, it gives better results for both native-light and cross-light authentication and vice versa for office light.
The verification results of Same-Light versus Cross-Light on Samsung left
The verification results of Same-Light versus Cross-Light on Samsung left
Table 13 shows the results of cross-device experiments. There is no significant difference between native-device (the same device is used for gallery and probe) and cross-devise authentication in terms of GMR@FAR=0.1. However, there is a degradation in the performance of cross-device cases (Samsung, Oppo), (Samsung, iPhone), (iPhone, Samsung) and (iPhone, Oppo) in terms of GMR@FAR=0.001 i.e. when Samsung and iPhone are used for gallery. It is due to the reason that manufacturing noises of the three devises are different and ConvSRC is not completely insensitive to these noises.
The verification results of Same-Device versus Cross-Device on left Day condition
The above discussion indicates that CovSRC gives equally good performance for native-light and cross-light as well as native-device and cross-devise verification with relaxed condition on FAR (0.1). However, there is a slight degradation in results for cross-light and cross-device verification when strong condition on FAR (0.001) is imposed.
To give an idea of the computational time of the proposed method, we computed the average time required for feature extraction and matching. The time in seconds is reported in Table 14, it shows the efficiency of the proposed method, the total time needed for a query is about half second.
Average time needed by the proposed method
Average time needed by the proposed method
We proposed a deep learning based periocular recognition, which employs a pre-trained CNN model for discriminative feature extraction and Sparsity Augmented Collaborative Representation based Classifier (SA-CRC). Taking into account the wealth of information and sparsity embedded in the activations of the convolutional layers and using principle component analysis, an efficient and robust method has been proposed for feature extraction. We evaluated the performance of the system using convolutional layers and fully connected layers for feature extraction and found that features extracted from convolutional layers are more discriminative and robust than those obtained from FC layers for periocular recognition; the convolutional layers at the last level result in the most discriminative representation. Through extensive experiments, we have shown that pre-trained CNN features can be generalized well to periocular recognition tasks (verification and identification). To determine the impact of domain on pertained CNN model, we examined the performance of the system using two different models VGG-Face (pertained on face data) and VGG-Net (pertained on ImageNet data); the results indicate that the system gives equally good performance when we use a CNN model pre-trained on any related domain i.e. ConvSRC is independent of the domain of the trained CNN model. The use of SA-CRC classifier plays a vital rule in the performance of the proposed method. We compared usefulness of SA-CRC method with the state-of-the-art KNN, ridge regression methods; the results pointed out that SA-CRC stands out in recognition performance. The comparison with the state-of-the-art methods reveals that ConvSRC outperforms significantly even the winner of ICIP2016 completion with GMR of over 99% at FMR = 10-3.
Although OMP algorithm solves the optimization problem to approximate the sparse representation effectively, it needs the sparsity level which is not known in advance and finding its suitable value empirically is not guaranteed to be the best value for this problem. In future work, to overcome this problem, we will consider alternative approaches which do not need a prior knowledge on the sparsity level to obtain the sparse solution such as sparse Bayesian learning (SBL) [44, 46] and Basis Pursuit (BP) [45].
Conflict of interest statement
There is no conflict of interests.
Footnotes
Acknowledgments
The research was supported under Researchers Supporting Project number (RSP-2019/109) King Saud University, Riyadh, Saudi Arabia.