
Abstract
Aspect-based sentiment analysis (ABSA) is a hot and significant task of natural language processing, which is composed of two subtasks, the aspect term extraction (ATE) and aspect polarity classification (APC). Previous researches generally studied two subtasks independently and designed neural network models for ATE and APC respectively. However, it integrates various manual features into the model, which will consume plenty of computing resources and labor. Moreover, the quality of the ATE results will affect the performance of APC. This paper proposes a multi-task learning model based on dual auxiliary labels for ATE and APC. In this paper, general IOB labels, and sentimental IOB labels are equipped to efficiently solve both ATE and APC tasks without manual features adopted. Experiments are conducted on two general ABSA benchmark datasets of SemEval-2014. The experimental results reveal that the proposed model is of great performance and efficient for both ATE and APC tasks compared to the main baseline models.
Keywords
Introduction
Aspect-based sentiment analysis (ABSA) is an important task of natural language processing and a fine-grained sentiment analysis task, which includes aspect term extraction (ATE) and aspect polarity classification (APC). ATE aims to identify and extract aspect terms from sentences, while the objective of APC is aimed at classifying the sentiment polarity of the extracted aspect terms. For example, in a review of the sentence “The camera shooting function of this mobile phone is very powerful, but the function of endurance is poor”, the identified aspect terms of ATE are “camera shooting function” and “function of endurance”, the aspect polarity classification identifies these two functions’ polarity that is positive are negative respectively. Most of the previous studies carried out ATE and APC tasks independently. However, it breaks the correlation between those two tasks. ATE is the underlying task of APC, so the quality of ATE results directly influences the accuracy of APC. Previous studies require a great number of resources to construct efficient ATE and APC model, and the internal relationship between ATE and APC has not been fully explored and studied. Therefore, in view of the above analysis, this paper proposes a model, Multi-task Learning Model for Aspect Term Extraction and Aspect Polarity Classification Based on Dual-Labels (MTL-ATEPC, also called MTL). By adopting general IOB 1 labels and sentimental IOB labels to enhance the feature input, this model regards APE and APC as a multi-task joint label model, conducting APE and APC tasks at the same time.
Figure 1 is the main block diagram illustrating the MTL models for the ATEPC task. At the bottom of the diagram is the input layer of the model. Before the training starts, the input sequence needs to be annotated and tokenized. The embedding module is essential for most NLP models, and the annotated text needs to be transformed into a form that can be recognized and processed by the model through embedding technology. For most models, only the word embedding is utilized, however, the character embedding is used additionally in this paper. The main network is the core of the model, consisting of a bidirectional LSTM network and a CRF layer for extracting and learning text features. The ATEPC module also deduces aspect polarity and extracts aspect terms, while the ATE layer is only responsible for extracting aspect terms.

The main block diagram of the model.
We organized the article into five sections. The first section introduces the research problems; the second part discusses the related work; the third part states the methodology of the model, and the last two sections conduct a large number of experiments to evaluate models’ performance and conclude the advantages of the model.
The contributions of this paper are highlighted as follows: This paper is the first study to conduct multi-task learning for ATE and APC by using Dual-Labels where MTL deals with ATE and APC simultaneously with the help of general IOB labels and sentimental IOB labels. A new weighted fusion loss function is used in this paper, which focuses on the optimization of the multi-task model for ATE and APC. The experimental results on two benchmark datasets of SemEval2014 verify MTL. Compared with other state-of-the-art models, the proposed model posses strong competitiveness in both ATE and APC.
Aspect term extraction
Since the ATE task is of great significance for the APC task, it catches more and more researchers’ attention. The researches aimed at the ATE task consist of rule-based methods, traditional machine learning methods, and deep learning methods.
The rule-based methods usually extract the aspect terms of review by formulating a rule. Hu et al. [1] first put forward that it is practicable to extract explicit aspect terms with high frequency from corpus by associating rules, and to detect implicit aspects by calculating the minimum distance between aspect terms and opinion words. Qiu et al. [2] made use of the syntax tree rule between opinion words and aspect terms to extend the dictionary of initial opinion and extract aspect terms. To a great extent, the rule-based methods depend on the predetermined rules and are restricted to specific applying fields.
For traditional machine learning-based methods, ATE is regarded as a sequence labeling task. Hidden Markov Model (HMM) and Conditional Random Field (CRF) [3, 4] are the most commonly used approaches in the past few years. Jin et al. [5] raised a lexicalized HMM model, which integrated semantic characteristics like Part of Speech (POS) and contextual information. Jacob et al. [6] extracted aspect terms by taking the token, POS, short dependency path, word distance, and opinion sentences as features and putting them into CRF. The experiments were conducted in four datasets: movies, web-services, cars, and cameras. Chernyshevich et al. [7] took advantage of the abundant vocabulary, syntax, and statistical characteristics and combined CRF to extract aspect terms of two specific fields. Traditional machine learning methods are greatly dependent on tedious manual feature selection, regardless of the interaction between aspect terms and opinion words.
Present researches indicate that deep learning methods are competent to capture and process token features, and it performs well in the aspect term extraction. Therefore, the aspect term extraction based on deep learning becomes popular. Wang et al. [8] proposed a joint model that can deal with explicit aspect terms extraction and opinion words at the same time. This model combines the recursive neural network and CRF. Besides, manual features can be adapted to this model, which further improves the ability of information extraction. Without any supplementary supervision, Xu et al. [9] used general-purpose embeddings and domain-specific embeddings as the input of the convolutional neural network, which obtained the competitive experimental results. Luo et al. [10] come up with a new bidirectional dependency tree network that enables the model to extract the dependency tree from sentences and combine the bidirectional long short-term memory network (LSTM) with CRF. It can also obtain the tree-structured and sequential information of the dependency tree. Consequently, it does good for solving aspect terms extraction.
Aspect polarity classification
APC is a task that aims to recognize the sentiment polarity of the extracted aspect terms. For three-way classification, the polarity of each aspect term may be positive, negative, and neutral. In early works, APC were considered as a standard text classification problem, which were integrated with traditional machine learning and feature engineering to establish the sentiment classifier. These methods requires a large number of manual features and additional resources, taking no consideration of the problem that there can be multiple aspect terms in a sentence and the polarity between diverse aspect terms may be different.
Neural network-based models achieved great improvement and success in aspect polarity classification tasks. Generally, the recurrent neural networks (RNNs) are pretty applicable for APC task compared to traditional machine learning methods. Tang et al. [11] proposed two target-dependent long short-term memory (LSTM) models. By integrating aspect terms into the model, Experimental results on two benchmark datasets prove that the performance is superior to the standard LSTM-based model. Tai et al. [12] applied Tree-LSTM network architecture to identify aspect polarity, and the experimental results reveal that Tree-LSTM performs better than LSTM. The attention mechanism is also commonly applied in the APC task. Wang et al. [13] put forward a long short-term memory neural network model based on the attention mechanism. When different aspect terms are input into the model, the attention mechanism calculates attention weights for each token of the sentence, and the tokens holding highest attention weights will be focused. Ma et al. [14] raised the interactive attention network model, which deploys two attention layers to learn the relationship between context and aspect terms interactively and to generate the representation of aspect terms and context. Furthermore, the convolutional neural networks (CNNs) are also applied in the APC task. Xue et al. [15] utilized gated convolutional neural network to selectively output sentiment characteristics. Parallel training can be carried out in this model. Xing et al. [16] proposed the convolutional neural network based on attention. Once aspect terms are deployed and combined in the model, the performance of aspect terms polarity classification can be enhanced remarkably.
Multi-task aspects-based sentiment analysis
Aspect term extraction is the fundamental task of aspect polarity classification, furthermore, the results of aspect term extraction will directly influence the accuracy of aspect polarity classification. Consequently, it is necessary to establish a multi-task learning model for aspect term extraction and aspect polarity classification. Nguyen et al. [17] proposed a joint model where general IOB labels are mixed with sentimental IOB labels, which can tackle the ATE task and APC task in parallel. Wang et al. [18] proposed a multi-task neural learning framework that can simultaneously deal with the ATE and the APC tasks. This model deploys an attention mechanism to learn the joint representation of aspect terms and sentiment polarities. Ma et al. [19] designed a hierarchical gated RNN architecture for learning the abstract features of ATE and APC. The impact of IOB labels and sentimental labels are taken into consideration in this network.
Methodology
Task definition
Suppose that [w1, w2, … w n ] represents a sentence consisting of n words. And the character sequence of word is [c1, c2, … c m ], m is length of the word. The general IOB labels are [B asp , I asp , O], the asp denotes the label of aspect. And the sentimental IOB labels applied in this paper are [B pos , I pos , B neg , I neg , B neu , I neu , O]. pos, neg, neu means positive, negative and neutral respectively, which are the sentimental labels of the aspects. By utilizing the proposed MTL-design models, the tasks of ATE and APC are carried out simultaneously.
Long short-term memory network
LSTM is an advanced RNN architecture, which has been widely adopted to varieties of NLP tasks. Huang et al. [20] adopted the LSTM network to sequence tagging tasks. LSTMs are effective to capture semantic features, and they are powerful to maintain historical information. Owing to the long-term memory mechanism, LSTM networks can make full use of long term features.
An typical implementation of LSTM cell is as follows:
Traditional LSTM networks are single-directional, it weakens the network’s ability to feature extraction. In recent years, bidirectional LSTM [20, 21] is more popular compared to traditional RNN architecture, since they are more efficient at capturing features and can learn features both backward and forwards. By utilizing Bidirectional LSTM, the model proposed in this paper performs better and achieve a considerable performance.
Word Embedding is of great significance and indispensable for most NLP tasks, and it maps words into vector spaces. This paper adopts the Word2Vec [22] as word embedding that was pre-trained in a large corpus. Given a word embedding matrix
Condition random field
Conditional Random Field is a common and widely applied method in name entity recognition (NER) and other tasks, which improves the performance of most sequence tagging tasks. The output representation and the input of CRF are connected, CRF accepts the representation of hidden states from LSTM, and predicts the result on sentence-level. However, LSTM predicts the result on token-level generally.
Model architecture
The design of the models is called MTL. Moreover, this paper proposes 4 variant models of MTL, the architecture of those variant models are presented in Figs. 2, 3, 4, 5. In general, all of the MTL models share the similar network architecture, including word embedding layer, bidirectional LSTM (BiLSTM) layers, and CRF layers. The left side of the MTL model is CRF with sentimental IOB labels (Sentiment-CRF, S-CRF), and the right side of the MTL model is CRF with general IOB labels (General-CRF, G-CRF). The difference of four model architecture is as follows:

The architecture of MTL-1.

The architecture of MTL-2.

The architecture of MTL-3.

The architecture of MTL-4.
MTL-1: As is shown in Fig. 2, S-CRF, and G-CRF share the embedding layer and BiLSTM with each other. In this variation, the representation of hidden states can be delivered from BiLSTM into S-CRF and G-CRF.
The shortcut of MTL-2 is shown in Fig 3, S-CRF and G-CRF share the embedding layer with each other, but not sharing BiLSTM. They respectively input the output from the embedding layer into two different BiLSTM networks, and finally, respectively input the hidden output from the two BiLSTM networks into S-CRF and G-CRF.
Figure 4 is the overall architecture of MTL-3, S-CRF, and G-CRF do not share the embedding layer but share BiLSTM with each other. By inputting the different embedding layer into the BiLSTM network, they produce different presentations of the hidden states that will respectively input the presentations of the hidden states into S-CRF and G-CRF.
Figure 5 is the architecture of MTL-4, S-CRF and G-CRF share neither embedding layer nor BiLSTM with each other. They input different embedding layers into different BiLSTM, which produce a different representation of the hidden states, and then respectively input different representation of the hidden states into S-CRF and G-CRF.
All of the MTL-design models share a similar architecture, only some components are replaced with other architectures. S-CRF, on the left side of MTL-1, outputs sentimental IOB label that is used for the joint task of ATE and APC (ATEPC). G-CRF, on the right side of MTL-1, outputs general IOB labels that are used for the ATE task.
For MTL-1, the embedding layer delivers the concatenated vector of word embedding with character representation. Character representation is the hidden states delivered by the BiLSTM encoder. The concatenated vector h
c
can be calculated as follows:
“ ⊢ ” denotes the word embedding process; “,” denotes the vector concatenation operation.
When inputting x
cw
into the BiLSTM, the result is h
cw
. The calculation process is as follows:
Finally, by inputting h
cw
respectively into S-CRF and G-CRF in MTL-1, ATEPC and ATE can be done at the same time. After this process, two groups of predictive sequence labels can be gained. They are sentimental IOB labels and the general IOB labels. Suppose the sequence delivered to the CRF layers is X = [x1, x2, ⋯ x
T
], and the label sequence is Y = [y1, y2, …y
T
], and then each sequence score socre (X, Y) is calculated as follows:
A is the matrix of transition scores; A
ij
represents the score of a transition from tag i to tag j; Z is the input of CRF, which represents h
cw
, the output of BiLSTM; Z(t,i) represents the scores of tag i. In the course of training, the calculation formula of the negative log-likelihood of the minimized label sequence is as follows:
Y
X
is the collection of all label sequences; p (Y|X) represents the probability of label Y under the condition of the given X. MTL has two labels output. In this paper, the loss function of ATEPC and ATE is weighed and summed. The formula is as follows:
loss asp means the loss function of task ATE; loss sent means the loss function of task ATEPC; λ ∈ (0, 1), and λ is the weight coefficient between ATE and ATEPC. In the course of training, the minimized loss function is losses.
Datasets and experiment settings
In order to verify the performance of MTL, the experiments are conducted on the two benchmark datasets of SemEval-2014 task4 2 . These two benchmark datasets contain reviews about restaurants and laptops. The statistical information of the datasets is shown in Table 1.
Statistical tables of SemEval-2014 datasets.
Statistical tables of SemEval-2014 datasets.
In this paper, the custom word embedding W2V [17] was trained on the corpus from different fields and based on Word2Vec. The word embedding dimension is 150. It uses the Adam Optimizer training model with a learning rate of 0.001; the size of batch size is 5; the number of hidden units in the BiLSTM layer is 200. The dimension of character embedding is 100, and character embedding is randomly initialized. The hidden units of LSTM after character embedding are 100. In order to prevent over-fitting, dropout is used for optimization and its value is set to 0.5.
To better evaluate the performance of MTL variations, this paper selected several models with excellent performance as a comparison. According to the experimental results, our model has achieved excellent performance.
Experiment analysis
In this paper, the macro F1 score is adopted as the evaluation criterion for ATE, while the accuracy is the criterion for APC. Table 2 is the accuracy of the baseline models for APC, and Table 3 is the F1 score of the baseline models for ATE.
The Accuracy of the baseline models for APC.
The Accuracy of the baseline models for APC.
The F1 score of the baseline models for ATE.
From Tables 2 and 3, the multi-task joint model with sentimental IOB labels MATEPC and MNN achieve the higher accuracy and F1 score on the Restaurant and Laptop datasets. In particular, the accuracy of MATEPC on the Restaurant dataset reaches 81.17%, which exceeds all comparison models. Moreover, the F1 of the MNN-2 model on the Restaurant and Laptop datasets outperforms all comparison models. The results illustrate that the sentimental IOB labels obtain a great promotion for MATEPC and MNN. Additionally, it has great advantages for solving ATE and APC tasks.
Tables 4 and 5 are the experimental results of MTL on the Restaurant and Laptop datasets. ATEPC : ATE corresponds (1 - λ): λ on Formula 19; F1 ATE is the F1 score of ATE on the left side of MTL; F1 ATEPC is the F1 of ATEPC on the right side of MTL; Accuracy represents the accuracy of ATEPC and APC MTL model. As is shown in Tables 4 and 5, under the condition of different ATEPC : ATE, the experimental results of F1 ATE , F1 ATEPC , and Accuracy in the four models are the best.
The experimental results of MTL Model on the Restaurant dataset. “ATEPC : ATE” represents λ : 1 - λ.
The results of MTL Model on Laptop dataset. ATEPC : ATE represents λ : 1 - λ.
From Tables 4, the F1 ATE , F1 ATEPC , Accuracy obtains the superior performance while ATEPC : ATE are set as 0.2:0.8, 0.4:0.6, and 0.6:0.4 on the Restaurant dataset. Compared with F1 of MNN-2, F1 ATE and F1 ATEPC respectively increase by 0.37% and 0.53%. Compared with MATEPC, Accuracy increases by 0.67%. The F1 ATE , F1 ATEPC , and Accuracy of MTL-2 on the Restaurant dataset reach the maximum while ATEPC : ATE are set as 0.5:0.5, 0.4:0.6, and 0.7:0.3. Compared with F1 of MNN-2 and the Accuracy of MATEPC, the F1 ATE and Accuracy increase by 0.26% and 0.56%, respectively. When the ATEPC : ATE are 0.1:0.9, 0.1:0.9, and 0.6:0.4, F1 ATE , F1 ATEPC , and Accuracy on the Restaurant dataset of MTL-3 achieve the superior performance. And F1 ATE and F1 ATEPC increase by 0.62% and 0.46% compared with F1 of MNN-2. Compared with MATEPC model, Accuracy increases by 0.65%. The optimal ATEPC : ATE for MTL-4 on the Restaurant dataset are 0.5:0.5, 0.1:0.9, and 0.9:0.1. Compared to F1 of MNN-2 and the Accuracy of MATEPC, F1 ATE and Accuracy increase by 1.04% and 1.16%, respectively.
By analyzing the experimental results we collated in the Laptop dataset (See Table 5), we explore the optimal ATEPC : ATE and performance of MTL design models. The superior ATEPC : ATE setting of MTL-1 are 0.3:0.7, 0.1:0.9, and 0.8:0.2. The F1 ATE and F1 ATEPC of MTL-1 increase by 0.75% and 1.53% compared to F1 of MNN-2, respectively. And Compared with RAM, the Accuracy increases by 1.60%. For the MTL-2 model, while the ATEPC : ATE are set to 0.6:0.4, 0.1:0.9, and 0.7:0.3, F1 ATE , F1 ATEPC , and Accuracy on the Laptop dataset of MTL-2 attains the promising result. Compared with F1 of MNN-2, the F1 ATE and F1 ATEPC increase by 0.15% and 0.84%, respectively. For the MTL-3 model, the optimal ATEPC : ATE are 0.4:0.6, 0.4:0.6, and 0.9:0.1. And the F1 ATE and F1 ATEPC increase by 1.05% and 0.71% compared with F1 of the MNN-2 model, respectively. While the ATEPC : ATE settings are 0.8:0.2, 0.2:0.8, and 0.4:0.6, F1 ATE , F1 ATEPC , and Accuracy on the Laptop dataset of MTL-4 reach the best performance. Compared with the F1 score of MNN-2, F1 ATE and F1 ATEPC increase by 0.85% and 0.43%, respectively. Compared with RAM, the Accuracy increases by 0.71%. The experimental results in Tables 4 and 5 show that consistent performance is achieved in the four MTL models proposed in this paper. As for the ATE and APC, the performance of MTL models increases much more than that of the single-task model using the manual features. It illustrates that MTL models have greater competitive advantages in the situation of no manual feature. Compared with the MATEPC and MNN that only use sentimental IOB labels, MTL models based on general IOB labels and sentimental IOB labels obtains the best experimental results both on ATE and APC. It also shows that general IOB labels can provide extra features with MTL models, and these extra features can promote the performance of MTL models. Meanwhile, MTL models use dual-labels (general IOB label and sentimental IOB label) to enhance model feature input and then provide more features for the ATE and ATEPC of MTL models. Moreover, the ATE and ATEPC of MTL models will promote each other mutually, and increase the performance of MTL models on ATE and APC.
Table 6 are the experiment results of MTL models on F1 ATE , F1 ATEPC , and Accuracy under the condition of high balance state. A high balance state is achieved among F1 ATE , F1 ATEPC , and Accuracy with the same ATEPC : ATE in MTL, and a relatively large value is achieved under three indicators. As can be seen from Table 6, the values of F1 ATEPC of MTL-1 on the Restaurant and Laptop are maximum. The values of F1 ATE and Accuracy of MTL-4 on Restaurant and Laptop datasets are optimal. A high balance state can be achieved among F1 ATE , F1 ATEPC , and Accuracy with the same ATEPC : ATE in MTL. The MTL models have competitive advantages both on F1 of ATE and the accuracy of APC. The experiment results show that under the condition of no manual feature and less consumption of resources, the MTL with general IOB labels and sentimental IOB labels has the advantage of simplicity and efficiency, which can tackle the ATE and APC efficiently at the same time.
The results of MTL Model in a high balanced state. ATEPC : ATE represents λ : 1 - λ.
In this paper, to verify the effectiveness of character embedding on this paper, a comparative experiment without character embedding as model input was designed, and the impact on character embedding on F1 ATE , F1 ATEPC , and the Accuracy was analyzed.
Figures 6 and 7 are line charts of F1 ATE of MTL-1 model on Restaurant and Laptop datasets. It can be seen from Figs. 6 and 7 that with the same proportion of ATEPC : ATE, the values of F1 ATE with character embedding are nearly larger than those without character embedding.

F1 ATE of MTL-1 on Restaurant dataset.

F1 ATE of MTL-1 on Laptop dataset.
Figures 8 and 9 are line charts of F1 ATEPC of MTL-1 model on Restaurant and Laptop datasets. It can be seen from Figs. 8 and 9 that with the same proportion of ATEPC : ATE, the values of F1 ATEPC with character embedding are nearly larger than those without character embedding.

F1 ATEPC of MTL-1 on Restaurant dataset.

F1 ATEPC of MTL-1 on Laptop dataset.
Figures 10 and 11 are line charts of Accuracy of MTL-1 on Restaurant and Laptop datasets. It can be seen from Figs. 10 and 11 that character embedding has little effect on the accuracy of the model. With the same proportion of ATEPC : ATE, the accuracy of the model has little difference no matter it has character embedding or not.
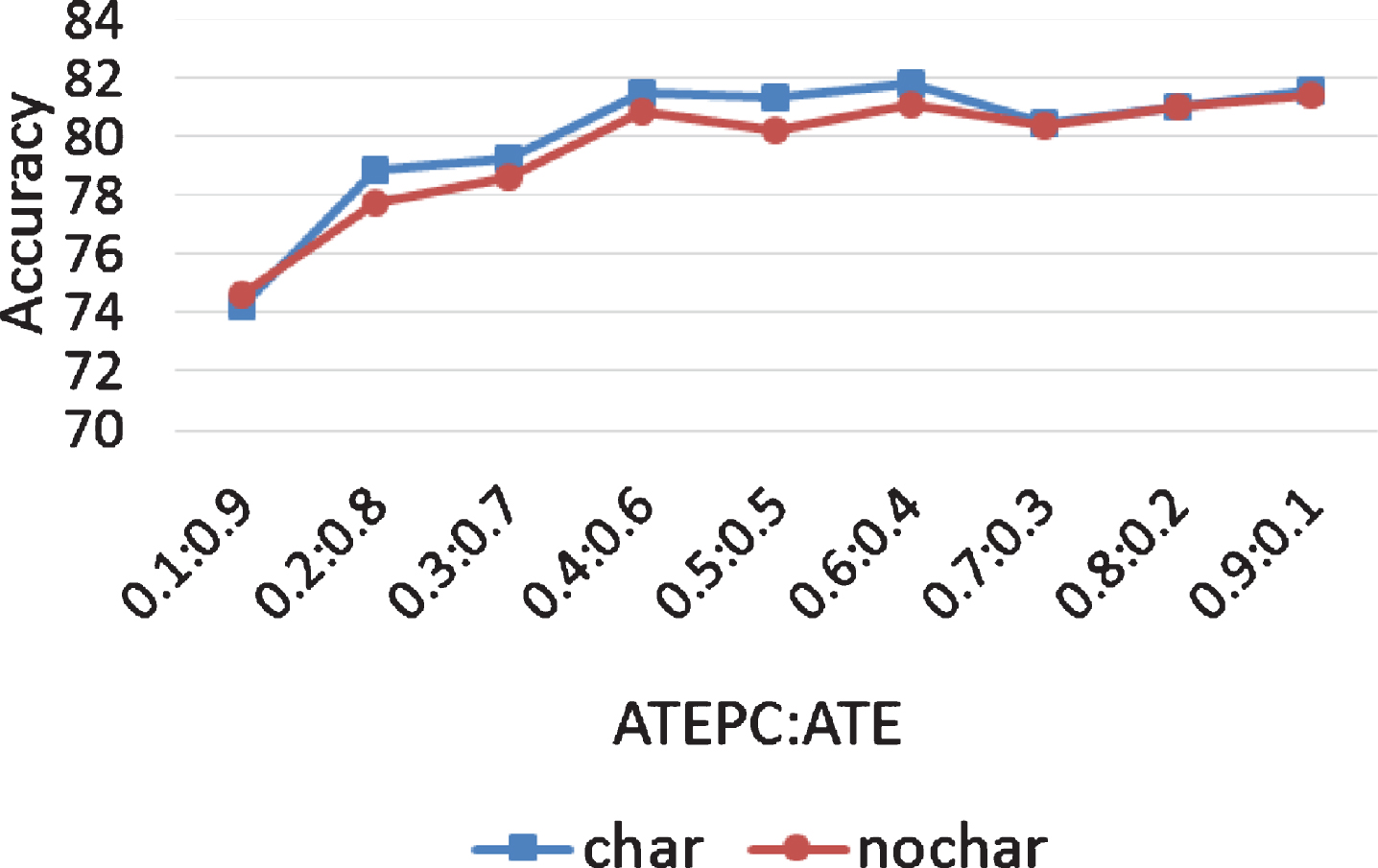
The accuracy of MTL-1 on Restaurant dataset.
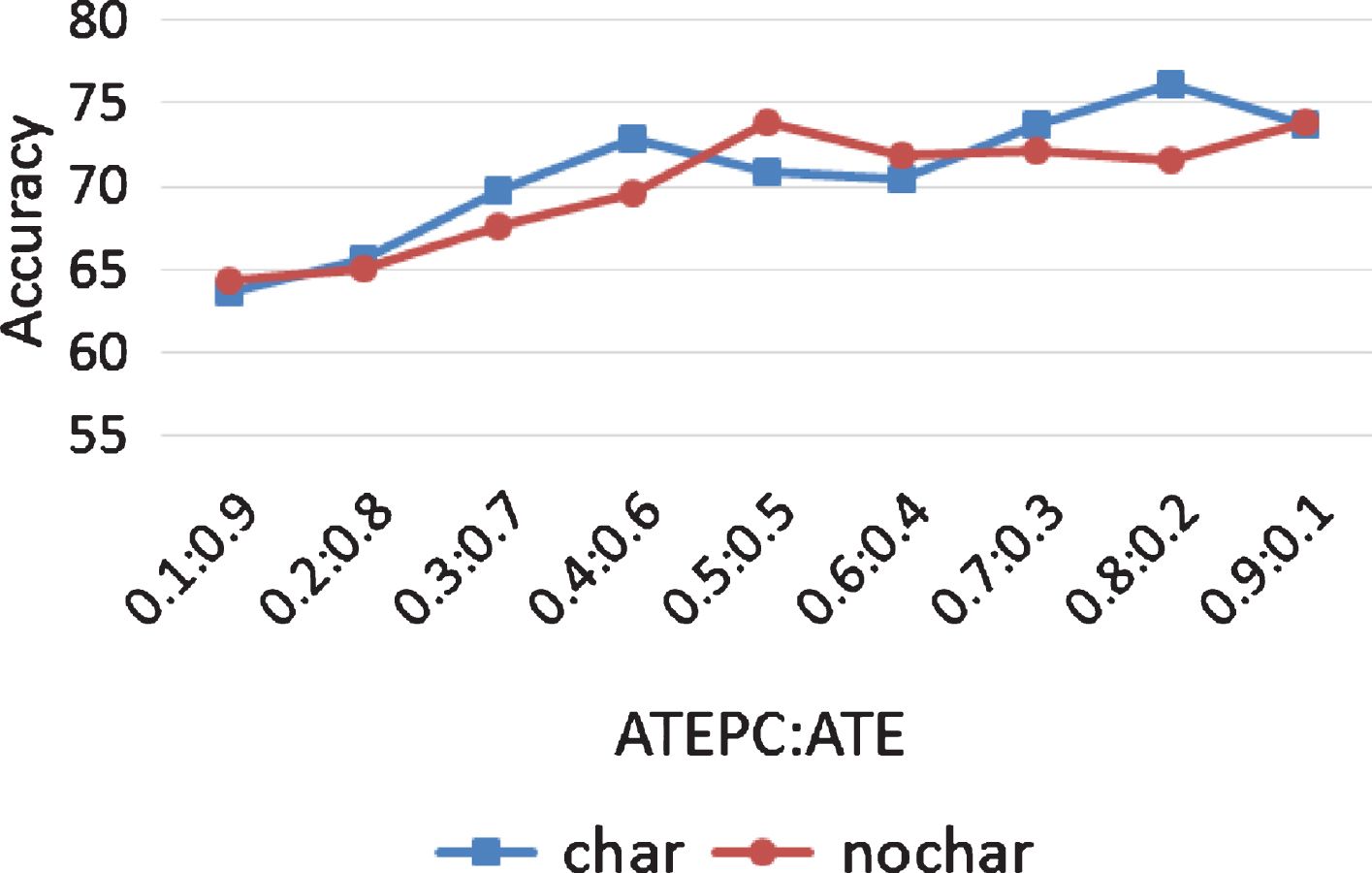
The accuracy of MTL-1 on Laptop dataset.
The above experiments only analyze the impact of whether or not the character embedding in MTL-1 has on F1 ATE , F1 ATEPC , and Accuracy. The experiment results of MTL-2, MTL-3, and MTL-4 on datasets Restaurant and Laptop are similar to those of MTL-1. Therefore, this paper omits the relevant details. The analysis of the experimental results of Figs. 6-9, 6, and 7 indicate that character embedding can increase F1 ATE and F1 ATEPC , while it has little impact on Accuracy. Character embedding can provide morphological features of characters, important relationships between characters and words, and similarity rules of character composition of aspect terms with aspect term extraction. However, these features provided by character embedding have little effect on aspect polarity classification.
This paper proposes a multi-task learning model (MTL) that can tackle ATE and APC simultaneously. And the experimental results of datasets Restaurant and Laptop show that general IOB labels have the ability to supplement extra features to promote the performance of MTL. Meanwhile, using general IOB labels and sentimental IOB labels contributes to promoting the feature input of MTL. Furthermore, the ATE and ATEPC of MTL enable to promote each other. MTL has achieved the most advanced performance on ATE and APC. The MTL based on general IOB labels and sentimental IOB labels is more competitive than single-task models and multi-task models. That’s because it is capable of dealing with ATE tasks and APC simultaneously and efficiently under the circumstances of no manual feature and less consumption of resources. In the future, it is able to use the attention mechanism to improve the performance of the multi-task learning model for ATE and APC. In addition, regularizing the new fusion weighted loss function is also a potential research issue.
Footnotes
6
Thanks to the anonymous reviewers and the scholars who helped us. This research is supported by the Innovation Project of Graduate School of South China Normal University and funded by National Natural Science Foundation of China, Multi-modal Brain-Computer Interface and Its Application in Patients with Consciousness Disorder, Project approval number: 61876067.
This paper adopts the “IOB2”, a commonly applied tagging scheme for sequence labeling. “I, O, B” means inside, outside and begin respectively.