
Abstract
In speech emotion recognition, most emotional corpora generally have problems such as inconsistent sample length and imbalance of sample categories. Considering these problems, in this paper, a variable length input CRNN deep learning model based on Focal Loss is proposed for speech emotion recognition of anger, happiness, neutrality and sadness in IEMOCAP emotional corpus. In this model, Firstly, a variable-length strategy is introduced to input the speech spectra of the filled speech samples into CNN. Then the effective part of the input sequence is preserved and output by masking matrix and convolution layer. Thirdly, the effective output of input sequence is input into BiGRU network for learning. Finally, the focal loss is used for network training to control and adjust the contribution of various samples to the total loss. Compared with the traditional speech emotion recognition model, simulations show that our method can effectively improve the accuracy and performance of emotion recognition.
Introduction
As an important branch of emotion calculation, speech emotion recognition involves the preprocessing of speech signal, emotion description model, emotional speech database, speech emotion feature extraction and speech emotion recognition algorithm [1]. It is a typical pattern recognition problem, which can be studied by machine learning or deep learning theory. In the research of speech emotion recognition, a high-quality emotional corpus is a necessary prerequisite, but in practice, there are problems such as inconsistent sample duration and unbalanced sample categories. Due to the problem that the sample length distribution span of anger, happiness, neutral and sadness in IEMOCAP emotional corpus is large and uneven, it has caused some inconvenience to the study of speech emotion recognition using machine learning or deep learning. Deep learning-based speech emotion recognition system usually takes the high-level features of speech signals as the input of the training emotion classifier, which extracts the traditional acoustic features or original speech signals of speech through the neural networks such as CNN and DBN [2–6].In addition, machine learning and deep learning usually require a balanced number and a fixed input size for each category of speech emotion recognition training samples. Therefore, the current popular CRNN emotion recognition model based on language spectrum [7, 8] is used as the baseline model, and the variable length input CRNN deep learning model based on Focal Loss is proposed to study the speech emotion recognition of variable length speech processing and sample unbalanced processing in IEMOCAP emotional corpus.
Related work
In speech emotion recognition, the spectrogram has the advantages of the time domain feature and the frequency domain feature. It describes the variation of the speech spectrum over time and provides a theoretical basis for feature extraction and sentiment classification using the spectrogram. For comparison, the spectrogram extraction settings and neural networks similar to those used in [7] were used in the experiment, where the input of the variable-length deep neutral network is the spectrogram of the whole sentence, and the output is the classification result of emotion category for the sentence.
Along with research on speech emotion recognition went thorough, compared with the traditional handmade features, the statistical learning of original signals at different layers of deep network can significantly improve the accuracy of classification and regression solutions. On the basis of LLDs features such as speech speed, short-term zero-crossing rate and short-term energy, traditional speech emotion recognition system is used to extract HSFs global features such as mean value and maximum value [9] and obtain feature vectors of fixed length. However, there are problems that the timing information that can reflect the change of the emotion can be erased. The end-to-end neural network model oriented to speech emotion recognition is to segment or fill the original speech signal to a fixed length [7] or map the variable length input to a fixed length vector by using global pooling strategy [10] in the output of convolutional neural network. When segmenting a long non-neutral emotion sample, since the sample contains neutral emotion segments, non-neutral emotion segments, and non-emotional segments, the segmented sub-samples may not contain any emotional information or contain any Non-neutral emotions. When the emotion recognition model learns the sub-sample, it may cause the confusion of other non-neutral emotions and neutral emotions, resulting in a decrease in the accuracy of non-neutral emotion recognition. When the shorter sample is filled, the newly filled invalid data will disturb the parameter learning of emotion recognition model. The global pooling strategy also loses some timing information. In recent years, deep learning methods and tools have been widely used in the field of speech processing, mainly for feature extraction, classification/regression, et.al [11–13]. Sainath et al. match the performance of a large-vocabulary speech recognition (LVCSR) system based on log-Mel fifilter bank energies by using a Convolutional, LSTM-DNN [14, 15]. And in [16, 17], an end-to-end robust speech recognition system is described based on linearly-spaced spectrograms. In addition, [18] proved that the Mel-scale spectrum can directly perform speaker recognition.
In the field of speech emotion recognition, several studies have been carried out using deep neural network for feature learning. Compared with traditional neural network, convolutional neural network has unique advantages in speech recognition and image processing due to its special structure and calculation method. In the training of convolutional neural network, in order to facilitate the connection of neural network, the size of input terminals should be consistent, such as fixed size of input terminals at the full connection layer. This provides a theoretical basis for the subsequent introduction of variable length CRNN inputs [19]. George [20] et al. recently proposed a convolutional recurrent neural network based on the original signal, which can perform end-to-end spontaneous emotion prediction tasks in speech data. Satt et al. [7] also combined CNN with LSTM to classify emotions from linearly spaced spectrograms, which achieves higher accuracy on the commonly used benchmark dataset IEMOACP. However, all of these methods split the speech input into the smaller and fifixed length segments, which introduce a loss of accuracy in the training and predicting stage. Therefore, the method of variable length deep neural network input is used to solve this problem.
Two-stage detectors and one-stage detectors are two tradition structures to solve object detection. Recent work on one-stage detectors, such as YOLO [21, 22] and SSD [23, 24], have been tuned for speed but the accuracy trails that of two-stage methods. SSD has a 10-20% lower AP, while YOLO focuses on an even more extreme speed/accuracy trade-off. Kaiming He and others thought to the inaccuracy of single stage structure is made up of the class imbalance. Focus loss (Focal Loss) is a loss function proposed by Kaiming et al. [25] for the problem of low accuracy of the One-Stage detector in image object detection, by reducing the weight of a large number of negative samples in training and reducing the weight of easily classified samples, it makes the model focus more on the samples with small sample size and difficult to classify. In our work, the focal loss can improve the sample imbalance by network training the sample characteristics of input CRNN with variable length.
Model
By analyzing the problem of inconsistent sample duration and unbalanced sample category in IEMOCAP database, the variable length input CRNN deep learning model based on Focal Loss is proposed. In the model, the same batch of spectrograml sequences are filled to the same length with zero value at the training phase. The lengths vary from lot to lot and are not filled during the prediction phase. In the variable-length CRNN input, it is assumed that S = [x1, x2, ⋯ , x V , ⋯ , x T ] is an input sequence, S1 = [x1, x2, ⋯ , x V ] is a valid part and S2 = [xV+1, xV+2, ⋯ , x T ] is a padding part.
In a convolutional neural network, the masking is used to reserve the outputs from S1 and ignore the outputs from S2. The formula is described as follows:
Conv (S) is the output of the input sequence S through the convolutional layer, and Mask (S) is a masking matrix. The value of the masking matrix represents whether the input is valid, ones for the valid part, S conv = [y1, y2, ⋯ , y V , ⋯ , y T ] and zeros for the padding part. is an output sequence as long as the input sequence S. When the convolution layer connects to the pooling layer, the boundary value between the valid part and the padding part may introduce invalid information. Therefore, before the input of y V to the maximum pooling layer, it needs to be zeroed to ensure the consistency of input and output in the training phase with filling and the prediction phase without filling. For example, suppose S conv is the input of the largest pooling layer, the pooling kernel size is 2 and the input sequence is [y V , yV+1]. The output will be yV+1 when y V < 0 and yV+1 = 0, which will cause the neural network to converge in the actual experiment [26]. The expected value should be y V because yV+1 is a padding value. Therefore, when k ≥ 2, it needs to be assigned a negative infinity before [yV+1, yV+k-1] is input to the maximum pooling layer. In this way, the same input will produce the same output after passing through the convolutional layer and the pooling layer, whether filled or not.
Speech emotion recognition in recurrent neural network is a sequence classification problem that needs to be output at the last valid time-step. For example, S is the input of the recurrent neural network, the expected result should be output at t = V. Besides, in the bi-directional recurrent neural network, the output of the backward recurrent neural network is the output at t = 0. The final output is the concatenation of the outputs in forward and backward recurrent neural network.
Due to the sentence length is different, the loss value was assigned different inverse weights to ensure that the sentence length does not cause the precision loss to the model. In addition, the IEMOCAP corpus is significantly unbalance, the number of some emotional categories is obviously more than other emotional categories. focal loss is used to conduct model training.
Based on the input of variable length CRNN, the focal loss function replaces the cross entropy inverse weight method for model training. By adjusting the contribution of each sentiment category sample in the corpus to the total loss of the model, the unbalanced situation of emotion corpus sample category is effectively improved. Focal Loss multi-classification cross entropy Loss function is shown as follows:
Given training set S and one of them (X, y), the network is trained by minimizing the focal loss of all (X, y) in sample set S. The final cost function can be performed such that
The frame of the variable length input CRNN deep learning model based on Focal Loss is shown in Fig. 1. In this model, firstly, CNN is used to extract the frequency-domain features in the language spectrum, and then BiGRU further extracts the time-series features in the language spectrum. Finally, focal loss is adopted to control the contribution of various samples to the total loss and adjust the contribution of easily classified samples to the total loss through network training.
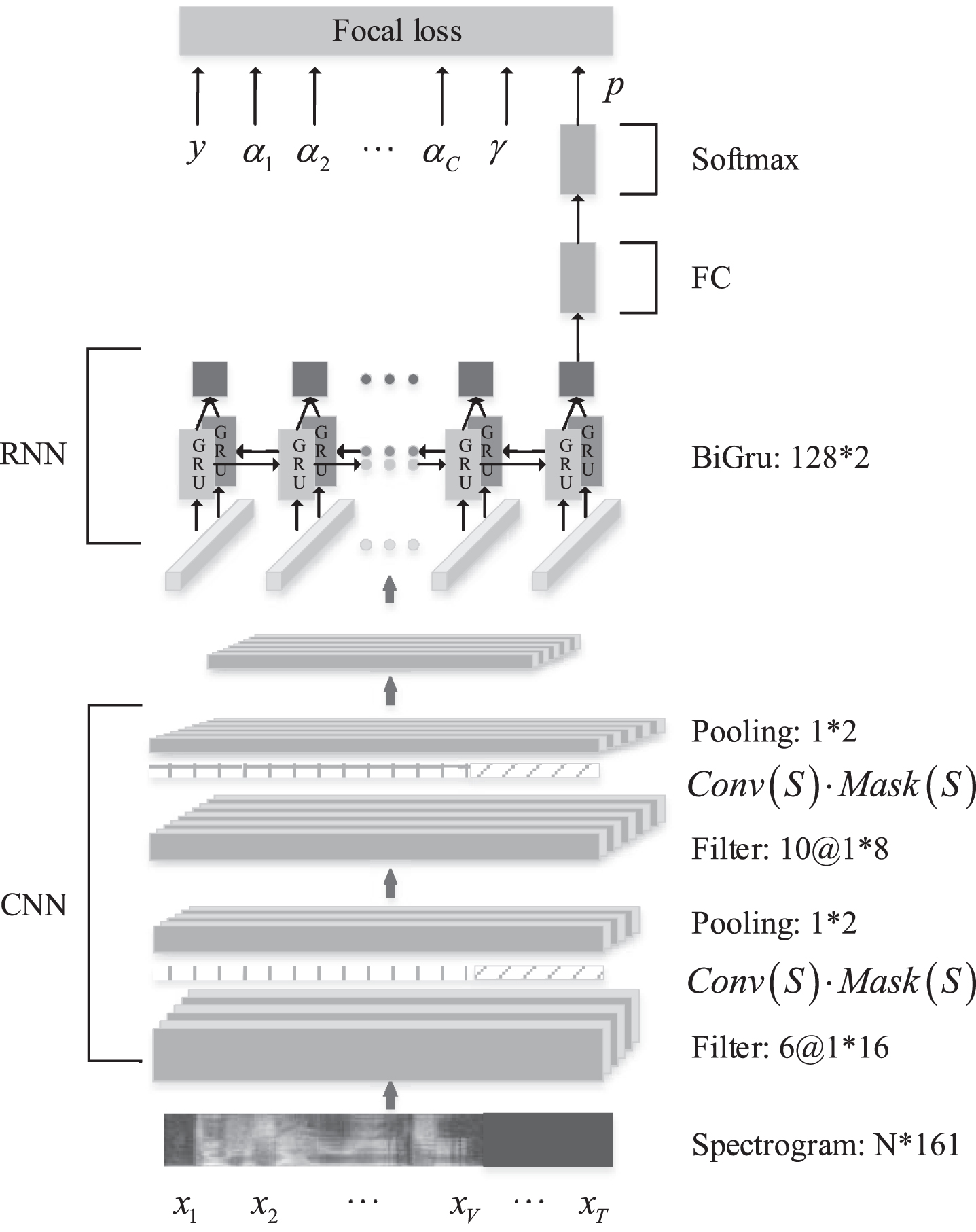
Schematic diagram of CRNN model framework based on Focal Loss variable length input.
Experiment setup
In the IEMOCAP database, the experiment conducted a five-folds cross-validation experiment of anger, happiness, neutral and sadness, and calculated the weighted average recall rate (WAR) and unweighted average recall rate (UAR) as the evaluation indexes of the algorithm. In the variable length CRNN input, CNN consists of two convolution layers and two maximum pooling layers. The RNN layer is the BiGRU of 128*2 nodes. According to the proportion of happy, sad, angry and neutral emotions, the inverse weight of focal loss was set as α = (0.78, 0.48, 0.49, 0.24), and the focus coefficient was set as γ = 2. In each fold, the data from four sessions is used for training the deep neural network, and the data from the remaining session is split t one speaker for validation and the other for the accuracy testing. Considering the imbalance of IEMOCAP database sample categories, the training aims to improve the recognition rate of emotion categories of data samples by maximizing UAR. Since the topological structure and parameters of the actual network model are not exactly the same as those of the network model in reference [7], the model conducted a comparison experiment of “fixed-length input” on the network model. This contrast experiment enhances the contrast of the experiment to ensure that the improvement of emotion recognition effect of network model is not caused by different network structure parameters. Finally, network training is conducted by minimizing the total focal loss of all samples.
Experimental results
The experimental results are shown in Table 1. The variable length input obtains the recognition results of 69.33% (WAR) and 66.59% (UAR). Compared with [7] and “fixed-length input”, it is improved by 7.19% (WAR), 0.53% (UAR) and 4.99% (WAR), 7.19% (UAR).
Comparison of WAR and UAR on IEMOCAP datasets by different methods
Comparison of WAR and UAR on IEMOCAP datasets by different methods
It indicates that the improvement of system performance is not due to the adjustment of network model parameters or the change of network model topology. In addition, focal loss is improved by 0.34% (WAR) and 2.06% (UAR) compared with variable-length input. The recognition results of various emotion samples are shown in Figs. 2–4. In the confusion matrix of fixed-length input, variable-length input and focal-loss network model, the probability of other emotions being wrongly identified as neutral emotions is significantly reduced, and the recognition accuracy of happy emotions in the focal-loss network model is 21.39% higher than that in the variable-length input model. It shows that using the whole speech sample as the input of the network can effectively alleviate the confusion between neutral emotions and other non-neutral emotions. The results show that the model can improve the recognition accuracy and improve the sample imbalance by using the training methods of variable length input and focal loss function.
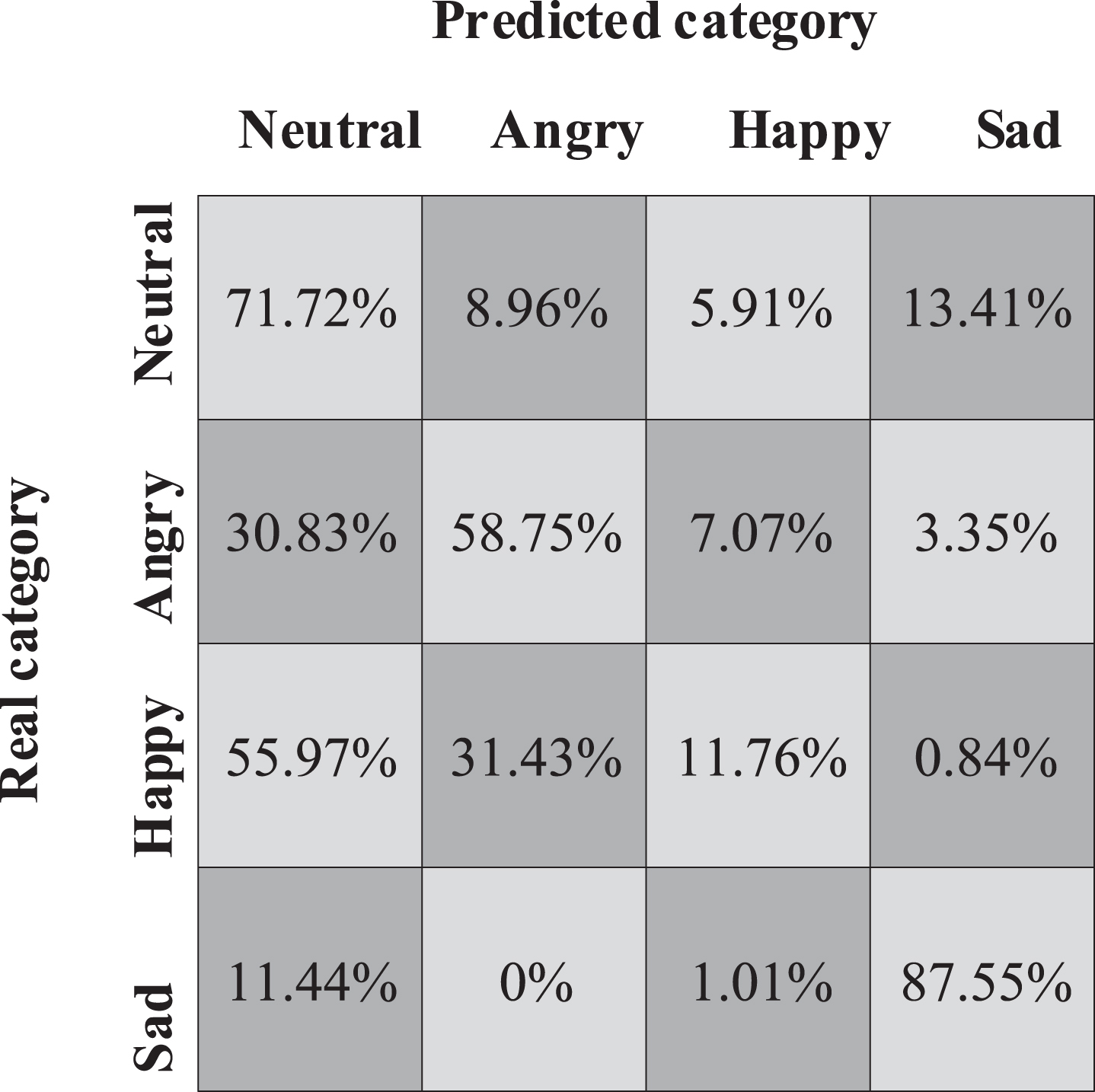
The fixed-length input.
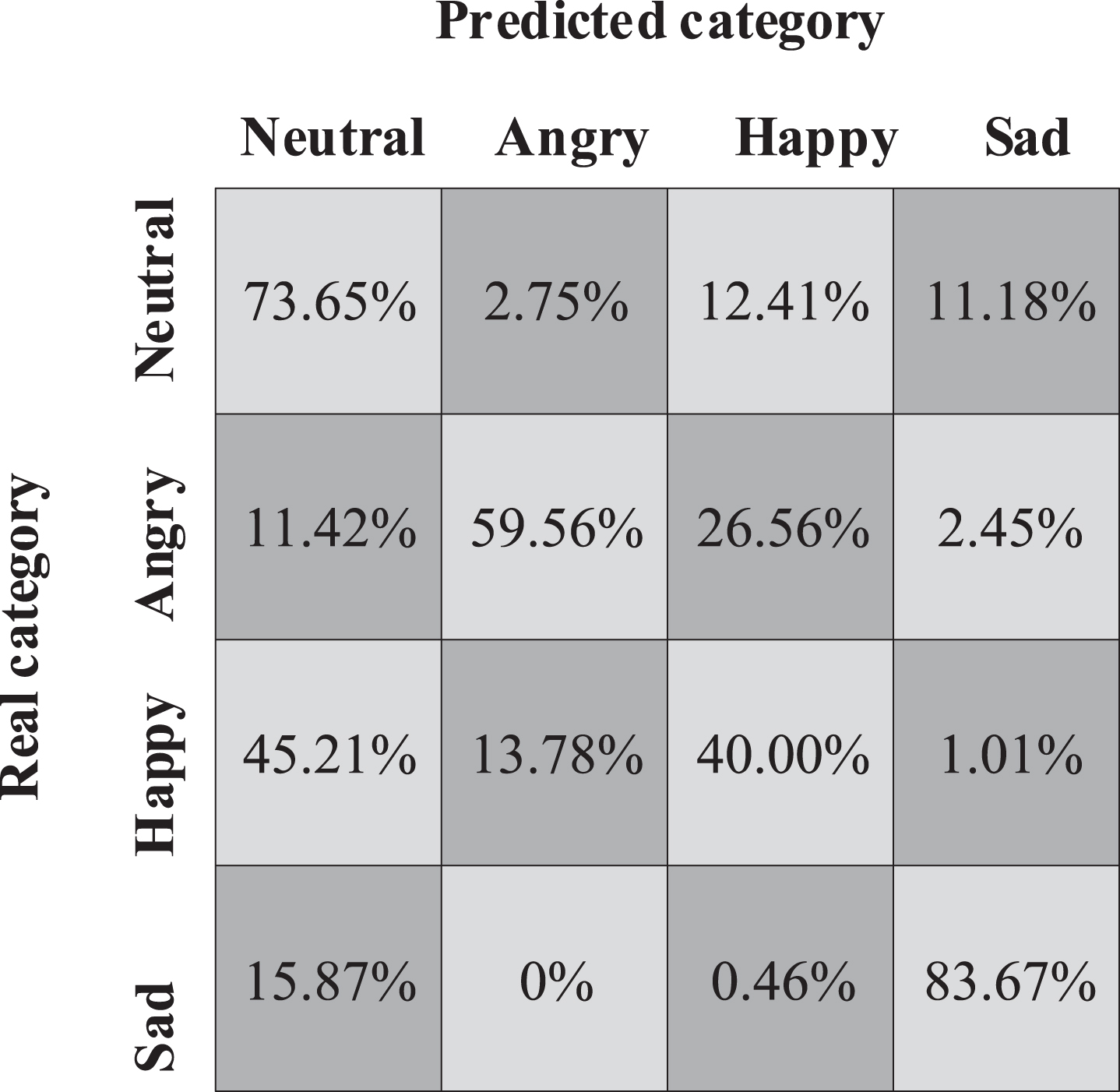
Variable-length input.
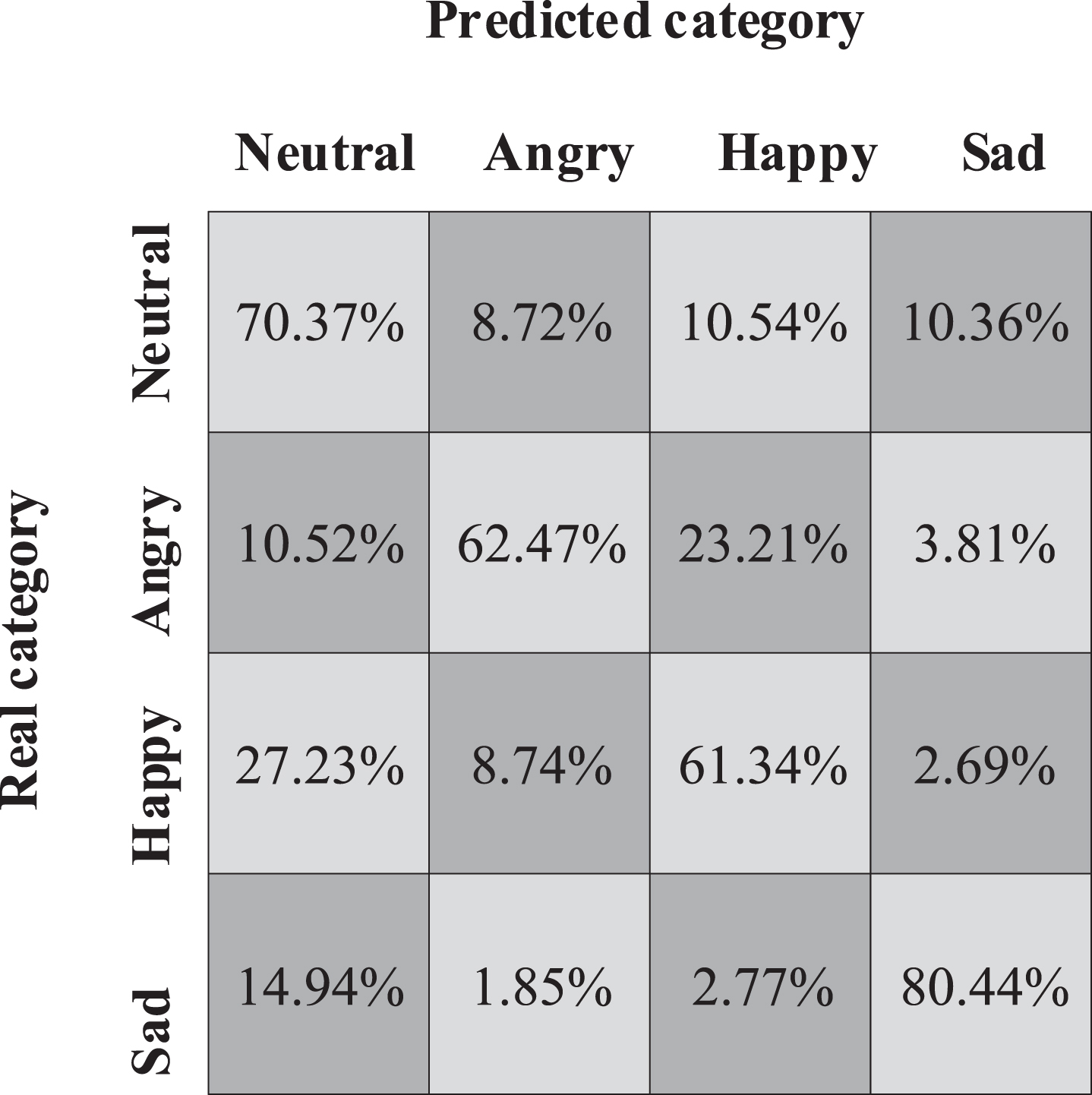
Variable-length input.
In this paper, a CRNN model with variable length input based on Focal Loss have been proposed to perform emotion classification task from variable length speech segments and speech sample category imbalance. In our model, the whole speech sample are input to the network and then the neutral emotion and other non-neutral emotion could be discriminated. The network training of focal loss avoids the problems of over-fitting and under-learning in emotional corpus samples, and effectively improves the emotional recognition accuracy and model recognition performance of speech samples in IEMOCAP database. Compared with the traditional speech emotion recognition model, the CRNN model with variable length input based on Focal Loss can effectively improve the recognition accuracy and the recognition performance of the model.
Footnotes
Acknowledgment
The research is supported by the science and technology development program of China’s Jilin province.