
Abstract
The classical principal component analysis (PCA) is not sparse enough since it is based on the L2-norm that is also prone to be adversely affected by the presence of outliers and noises. In order to address the problem, a sparse robust PCA framework is proposed based on the min of zero-norm regularization and the max of L p -norm (0 < p ≤ 2) PCA. Furthermore, we developed a continuous optimization method, DC (difference of convex functions) programming algorithm (DCA), to solve the proposed problem. The resulting algorithm (called DC-LpZSPCA) is convergent linearly. In addition, when choosing different p values, the model can keep robust and is applicable to different data types. Numerical simulations are simulated in artificial data sets and Yale face data sets. Experiment results show that the proposed method can maintain good sparsity and anti-outlier ability.
Introduction
Principal Component Analysis (PCA) [1] has a wide range of applications in pattern recognition, multivariate statistical analysis and machine learning [2, 3]. Classical PCA attempts to search for a set of principal components (PCs) which is obtained by maximizing variance after data projection [4]. In addition, PCs are irrelevant, which is conducive to the statistical analysis of the data after dimension reduction. However, the classical PCA is a linear combination based on the L2-norm, which expands easily the effect of outliers and noises on the data [5, 6]. To overcome these shortcomings, improvements of methods are constantly explored.
Based on the consideration of robustness, the L1-norm is usually used in sparse learning and robust learning [7–9]. Kwak [10] proposed a PCA learning framework by the L1-norm maximization, called as PCA-L1, where the greedy algorithm was used to transform the problem into a single PC problem. The algorithm proposed by Kwak is straightforward, easy to calculate and implement. Then Kawk [11] developed a PCA by extending L1-norm to L p -norm (called PCA-L p ),where p is any non-negative number.In addition, PCs tend to have non-zero weight coefficients [12], which makes classical PCA not sparse enough, and interpretability worse in some applications. A variety of methods for sparsity have been developed [13–15]. For example, Jolliffe [13] directly introduced Lasso penalty into principal component analysis, which enables automatically selection of original variables of PCA. Zou et al. [14] introduced a PCA learning framework based on elastic net. To further achieve both robustness and sparsity, Meng et al. [16] maximized the variance of the data by the L1-norm, called RSPCA. This algorithm is easy to implement and the computational speed greatly exceeds the existing sparse PCA method. And the RSPCA has robust performance for data with inherent outliers and noises. Shao et al. [17] proposed a robust and sparse PCA-L p (called LpSPCA) by replacing the L1-norm with the L p -norm, which guarantees the sparsity of PCs and verifies the robustness of the algorithm in numerical experiments, where the model can be implemented using a simple iterative algorithm.
In this paper, we propose a new sparse PCA based on zero-norm (called L p -ZSPCA), where intends to maximize the variance of the data under L p -norm (p ≥ 0). Unlike using the L1-norm to approximate the L0-norm, we apply a Gaussion function η (·) function to approximate the L0-norm with good approximation. However, nonconvexity of the η (·) makes the problem difficult to optimize. A continuous optimization method is developed to solve the proposed framework. The problems are reformulated as DC (difference of convex functions) programming. The corresponding DC algorithms (called DC-LpZSPCA) converge linearly. Experiments on the artificial data and Yale face with outliers and noises show that the proposed LpZSPCA (0 < p ≤ 2) has a good advantage in sparsity and robustness compared to traditional PCA and other methods. Choosing different p values, DC-LpZSPCA can achieve different results.
The structure of this paper is as follows: The second section introduces the related work; in the third section we propose two new sparse PCA models and algorithms; Numerical experimentations on different datasets are shown in Section 4. The conclusions summarize the main contributions and future directions.
Related researches
Let X = [x1, x2, . . . , x
N
] ∈ Rd×N be the input data matrix, where d denotes the dimension and N is the number of the given data. Transforming a location, we can assume that every
The conventional PCA seeks a m (< d) dimensional linear subspace to maximize the variance of the input data. Such a subspace can be obtained by solving the following optimization
From statistical perspectives, the L1-norm is more robust to outliers than the L2-norm. So, substituting the L2-norm in Equation (1), the L1-norm was put to use in the variance function [10], where a greedy algorithm is used to attain a local optimal solution. This approach reduces the influence of the outliers and it is invariant to rotations [10]. With an arbitrary non-integer value, the L p -norm (p > 0) is applied in PCA study [11], which leads to following optimization.
A Robust sparse principal component analysis
In order to enforce sparsity and robustness, we propose a new PCA learning framework, called L p -ZSPCA,(p > 0):
To find m principal components, Equation (4) is reformulated as
In this work, we apply a generalized the zero-norm that is a Laplace kernel-based function η (·) to approximate the zero-norm ∥ · ∥ 0 [18]. With different parameters, the Gaussion function η (·) is illustrated in Fig. 1. The closer the parameter is to positive infinity, the more approximate the Gaussion function is to the zero-norm.

Approximations to L0-norm for the Gaussion function η (x) and L1-norm.
We first consider L p -ZSPCA with one principal component. With m = 1, we obtain L p -ZSPCA with one PC
For minimizing ||w||0, Equation (8) can be reformulated as the following optimization.
A good approximation [20] of the ||w||0 would be
with
Compared with other approximation of the zero-norm such as
The objective function of Equation (10) can be reformulated as
Assuming that Ω is the feasible set of Equation (10) and χ
Ω
(x) is the indicator function for the convex set Ω:
According to the generic DCA scheme, at each iteration l, we need to compute ▿H (w l ) and deal with the following convex programming to obtain the solution wl+1
Although the approximation of Equation (14) is closer to the L0-norm than the L1-norm, the Equation (14) also generates many components that are close to zero but not exactly equal to zero because of the limitations of approximation. So we sort w by the absolute value of the value and get w1, w2, . . . , w n . Let γ > 0 and γ = wk+1. In other words, γ is the (k + 1)-th largest number of |w|, where k represents data sparsity. Based on Equation (21), the solution w need to be changed by the following state.
In what follows, we describe the DC algorithm of LpZSPCA when m = 1.
Algorithm 1 generates a sequence The sequence
The greedy algorithm is used in this section. The basic idea is to obtain the first PC1 (w1) by applying the algorithm 1 to original data, and then project the data into the space that is orthogonal to vector w1 to get the new data set. After that, based on the projection data, we continue to apply algorithm 1 to obtain PC2 and then get the m-th principal component.
1: α > 0 and λ ∈ (0, 1) is fixed.
2: δ > 0 is sufficiently small and set l = 0. Choose an initial point w0 ∈ Ω;
3: Singularity check:
if p<0 and ∃ i: w T (l)x i = 0, then w(l) ← (w(l) + ρ)/||w(l) + ρ||2, where ρ is a small random vector;
4: Compute ▿H (w(l)) via (19);
5: Solve the SOCP (21) to obtain w(l+1);
6: Let γ be the (k+1)-th largest element of |w|. According to the (21), get the
7: Convergence check:
a) If
b) Else,
The PCs do not vary if the value of m changes. PC1 is local optimal solution of Equation (5) by Algorithm 1 and PCs (m > 1) are local suboptimal solution of Equation (5) by Algorithm 2. What’s more, the orthogonality of
1: δ > 0 is sufficiently small and set k = 0.
Choose an initial point w0 ∈ Ω and
2: For j-th principal component, j = 1, 2, . . . , m
a), let data point
b) Apply Algorithm 1 on X j
3: Apply algorithm 1 in dataset X to obtain the j-th principal component w j , (j = 2, ⋯ , m).
Experiment results
In order to verify the proposed LpZSPCA and its DC algorithm, especially the robustness in noises setting, the traditional PCA [1], RSPCA [16], PCA-L p [11] with p = 0.5, 1, 1.5, 2 and LpSPCA [17] with p = 0.5, 1, 1.5, 2 methods have been used as the benchmark methods. For the sake of convenience, we use the name of LpPCA instead of PCA-L p . All programs were completed in Matlab 2018, and the experiments used the popular package SeDuMi as a solver. The implementation environment was the personal computer with 2.3 GHz Intel Core i5.
Parameter selection
The choice of parameters will affect the final result. There are three parameters, k, α, λ in the proposed DC-LpZSPCA method. The sparsity k can be well selected according to the characteristics of data set. Later, the grid search method is adopted to determine parameters, α and λ. It is proved in the literature [19] that a good value of λ in Equation (21) using the zero-norm is better to be larger than 0.5. But it also depends on the dataset type, so we consider the values λ < 0.5 as well. In this work, we suggest using the following set of candidate values in our experiments:
In order to observe intuitively the sensitivity on different parameters λ and α, for yale face dataset with occluded noise and p = 0.5, we draw a graph (see Fig.2) that shows the reconstruction error (ARCE) varies with the parameters λ and α. According to the Fig.2, we find the ARCE increases when λ ranges from 0.0001 to 0.9, and that the ARCE produces greater values when α is set to a large value.

The sensitive analysis on parameters λ and α.
We design a three-dimensional toy dataset
The data is generated by picking x i ∈ [-3, 3], and yielding y i and z i from the uniform distribution on [0,0.1] and [-1,-0.9] respectively, which is approximately parallel to the x-axis. In order to further verify the robustness of the algorithm, two sets with outliers will be introduced, whose coordinates are expressed as (4 + α i , 2 + β i , 4 + γ i ) and (α i , - 3 + β i , 4 + γ i ) respectively,here, α i , β i , γ i are randomly taken from the uniform distribution on interval [0,0.1], i = 1, 2.
The artificial data set is composed of a main direction parallel to the x axis and four outliers deviating from the main direction. The essence of the data set is a one-dimension vector in three-dimension space. Therefore, this set will test the robust effect of above methods. The selection of parameters is as follows. The sparsity k of RSPCA and DC-LpZSPCA is set to 2. When p takes from the set {0.5, 1, 1.5, 2}, λ takes from the set {0.05, 0.002, 0.001, 0.004} respectively and α takes from the set {0.1, 5, 5, 0.5} respectively.
To further explore the robustness of the algorithm, we introduce the concept of the average residual error, called ARSE.
Here, ζ i = {(x i , y i , z i )} is the i-th data point; w is the first PC vector and N is the number of the data set.
Projection direction of the first PCs of the proposed LpZSPCA (p = 0.5, 1, 1.5, 2) and traditional PCA is shown in Fig. 3. The ARSEs conducted by PCA, RSPCA, LpPCA, LpSPCA and LpZSPCA methods are presented in Table 1. The results from Fig. 3 present that the PC1 direction obtained by DC-LpZSPCA (p = 1.5) is closest to the true direction of the data; when p = 1 or 2, the influence of the outliers increases. Compared with the traditional PCA, the DC-LpZSPCA (p = 1, 1.5, 2) methods are closer to the real direction. When p = 0.5, it is the closest to the projection direction of the traditional PCA.
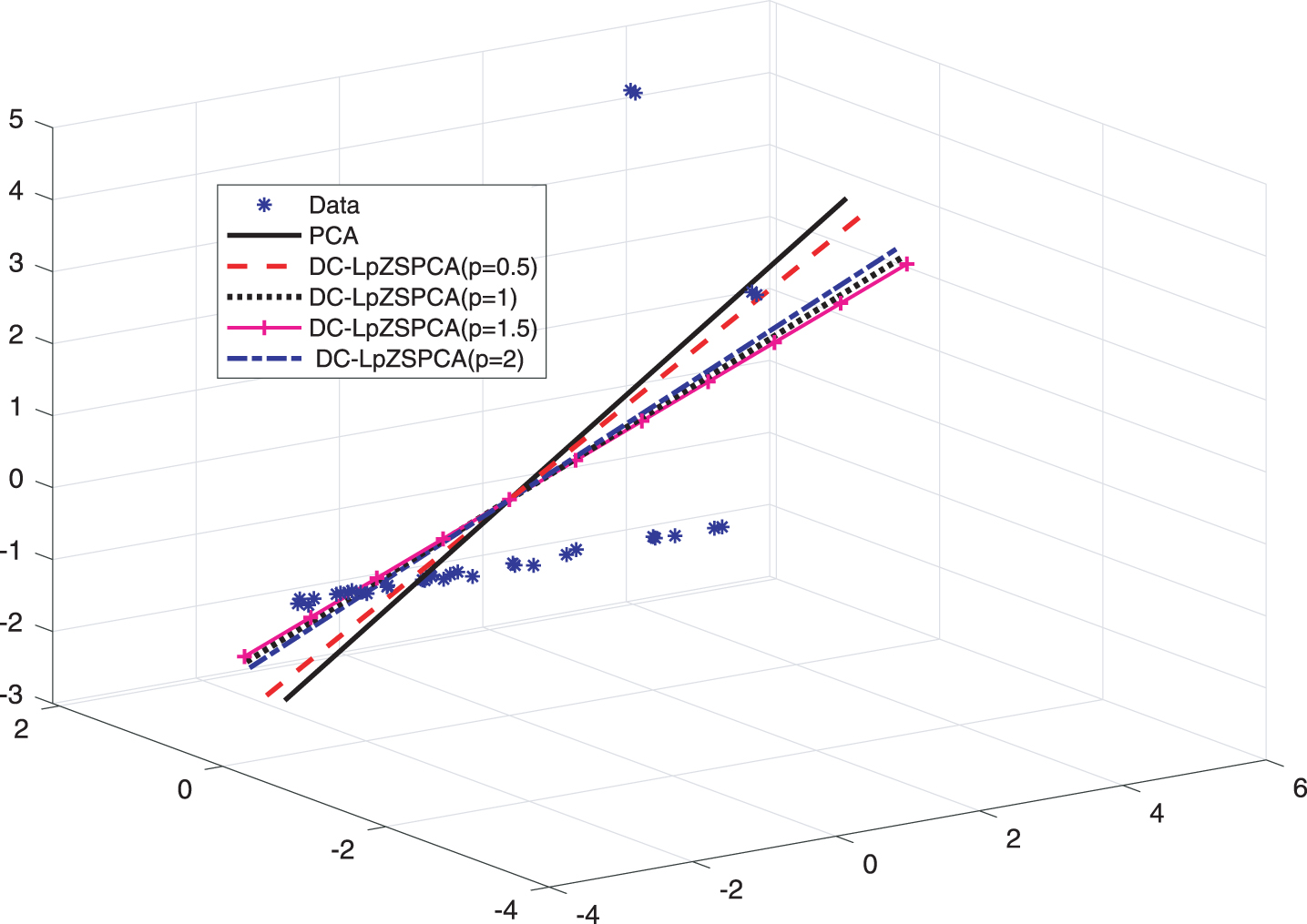
The first PCs obtained by the PCA and DC-LpZSPCA respectively in toy data.
PC1s and the ARSE of 5 methods
According to Table 1, it is found that ARSE of DC-LpZSPCA (p = 0.5, 1, 1.5, 2) is smaller than PCA. When p = 1, the ARSE of DC-LpZSPCA is the smallest among all methods. When p value is fixed, the average residual error of DC-LpZSPCA is smaller than that of LpPCA and LpSPCA except for p = 0.5. These results show that DC-LpZSPCA has good robustness with different values of p (p ≤ 2).
In this section we produce the artificial dataset similar to literature [14]. This is a set of ten-dimensional datasets generated by the following steps:
First define three potential factors:
V1∼N (0, 160)
V2∼N (0, 200)
V3 = -0.1V1 + 0.88V2 + ε
where ε∼N (0, 1), and V1, V2 and ε are independent of each other. x i is denoted the i-th feature of the data points, (i = 1, 2, . . . , 10). The x i (i = 1, 2, 3, 4) take from V1; x i (i = 5, 6, 7, 8) take from V2; x9 and x10 take from V3.
The variance of the three underlying factors is 160, 200, 156.48, respectively. The numbers of the data variables related to the three factors are 4, 4, 2. Hence V1 and V2 are almost equally significantly, and they are much more important than V3. The article data itself has a certain degree of sparsity.
The algorithms (PCA, RPCA, LpPCA, LpSPCA, DC-LpZSPCA) are applied to the data, and the results are shown in Tables 2 and 3. It can be seen intuitively that the standard PCA and LpPCA (p = 0.5, 1, 1.5, 2) are not sparse, and RSPCA, LpSPCA and DC-LpZSPCA (p = 0.5, 1, 1.5, 2) is sparse. At the same time, when p = 0.5, DC-LpZSPCA is closed to the true value. Because it can be calculated that the ARSE of the different methods. The ARSE value of DC-LpZSPCA(p = 0.5) is 91.13 but the ARSE values of other methods are not above 80.
Loadings of the first two PCs by PCA and RSPCA
Loadings of the first two PCs by PCA and RSPCA
Loadings of the first two PCs by LpPCA, LpSPCA and DC-LpZSPCA
The dataset used in this paper is the famous Yale face dataset which includes 165 gray faces, containing 11 different expressions of 15 volunteers. The dataset is available from the official website http://cvc.yale.edu/projects/yalefaces/yale-faces.html. The size of the original image is 320 pixels × 243 pixels. In this experiment, the original image is normalized as the image of 100 pixels ×100 pixels.
In order to test the robustness of DC-LpZSPCA, we add occluded noise and dummy noise to the Yale data respectively [16]. The specific processing method is as follows:
Occluded noise: Randomly select two images from each of the 15 volunteers’ face images. Then use a rectangular noise with black and white dots at random positions, whose size was 70 pixels ×30 pixels or 40 pixels ×60 pixels.
Dummy noise: Use black and white noise to create a picture of the same size as the face after cropping, and record it as a virtual picture. Then we add 30 virtual pictures to the original data set.
In this paper, the reconstructed feature face and the average reconstruction error are used as test indicators to detect the robustness of the DC-LpZSPCA algorithm. In this paper, the first m principal components (PCs) are selected to reconstruct the image, and the average reconstruction error (ARCE) is expressed as:
For yale face datasets with two kinds of noises, we extracted 20 PCs to create the reconstructed images by PCA, RSPCA, LpPCA, LpSPCA, and DC-LpZSPCA, and the results are shown in the Figs. 5 and 6 respectively. At the same time, the ARCE tendency curves are shown in Fig. 4, which illustrates the above 5 methods with various numbers of extracted PCs in occluded and dummy cases, respectively. Here, the optimal parameters of DC-LpZSPCA are obtained under different noises with different p values. Under occluded noise with k = 9500, p takes from {0.5, 1, 1.5, 2}; λ takes from {0.9, 0.7, 0.5, 0.001}; α takes from {1, 0.5, 0.5, 0.1} respectively. Under dummy noise with k = 9500, p takes from {0.5, 1, 1.5, 2}, λ takes from {0.7, 0.3, 0.3, 0.7}, and α takes from {0.5, 0.1, 0.5, 1} respectively.
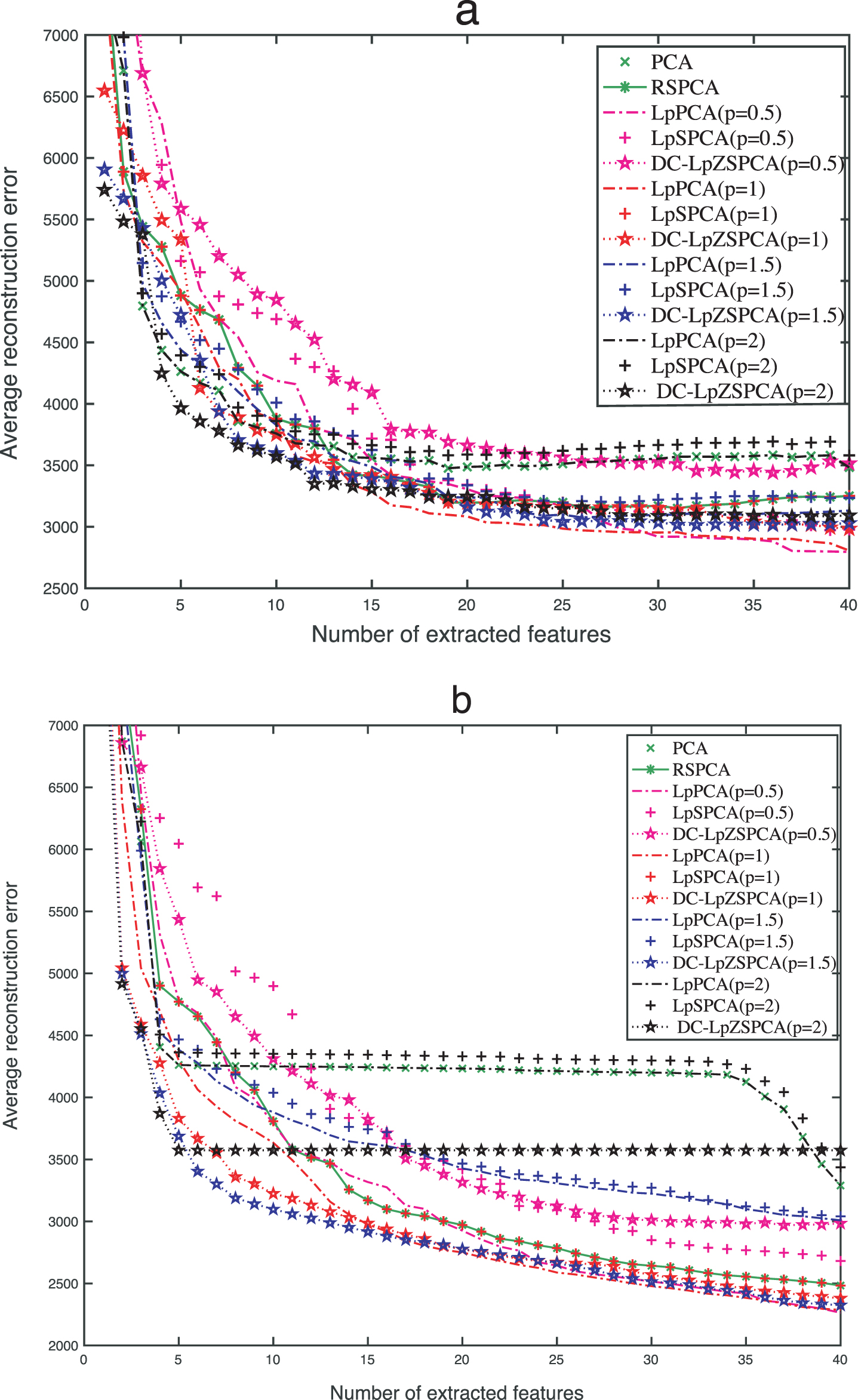
The ARCE Tendency curves for occluded (a) and dummy (b) Yale images respectively.
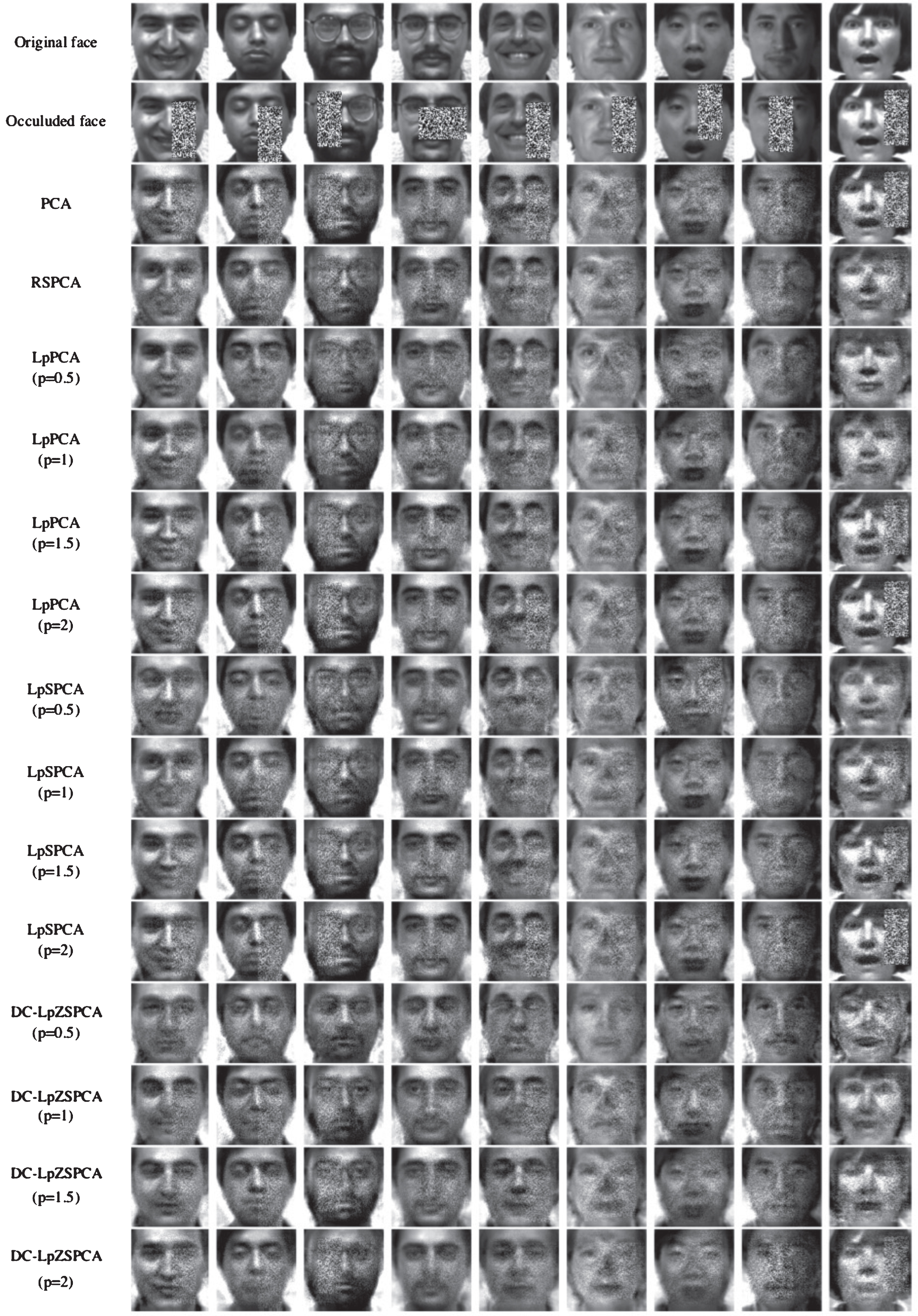
The original face images, the corresponding images with occluded noise, and the faces reconstructed by the classic PCA, RSPCA, LpPCA, LpSPCA and DC-LpZSPCA methods with 20 corresponding projection PCs, respectively.
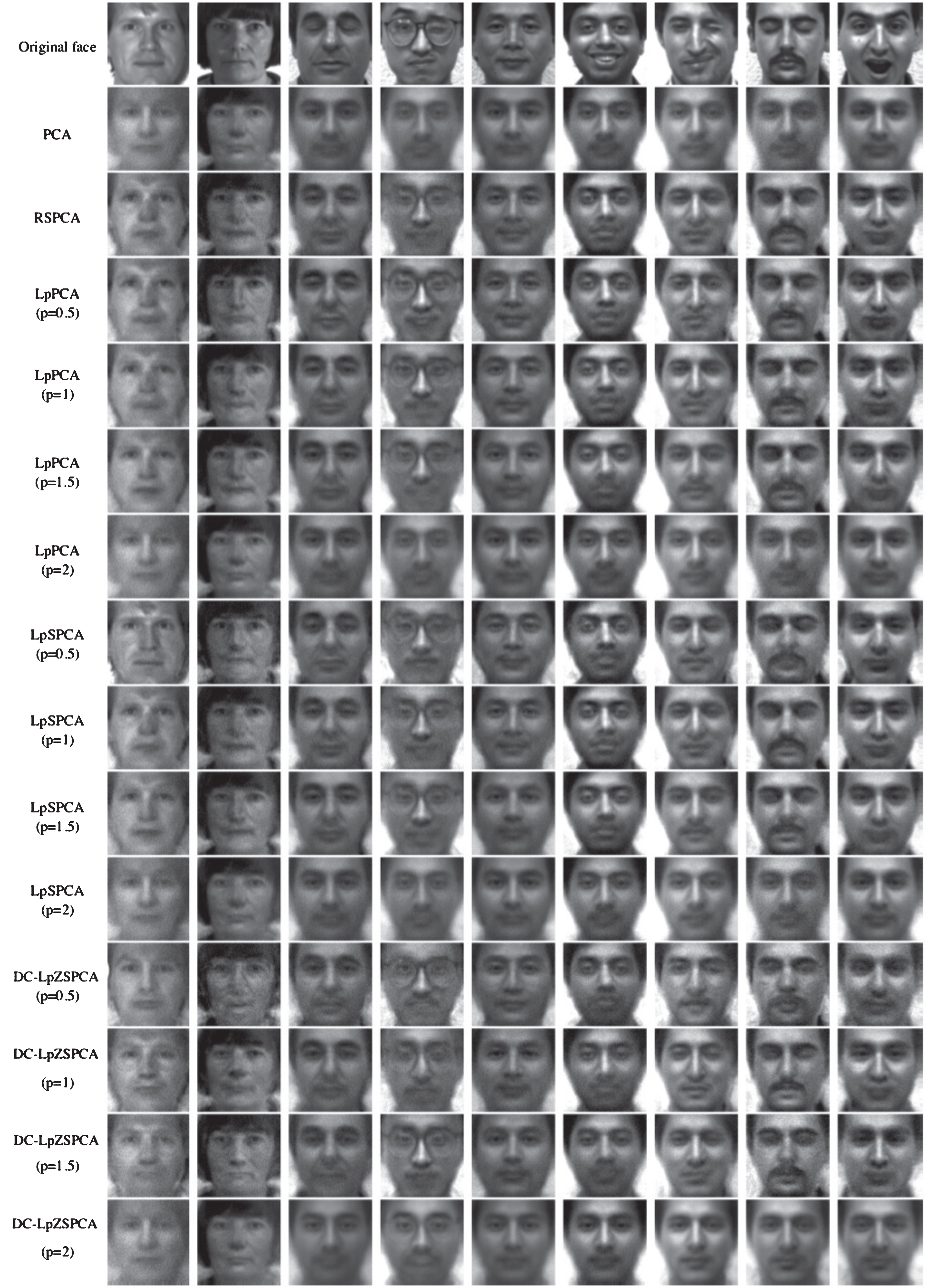
The original face images, the corresponding images with dummy noise, and the faces reconstructed by the classic PCA, PSPCA, LpPCA, LpSPCA and DC-LpZSPCA methods with 20 corresponding projection PCs, respectively.
For occluded case, Fig. 5 illustrates the face reconstruction images in occluded case, where it is seen that the faces reconstructed by the DC-LpZSPCA algorithm is closest to the original face. Although the RSPCA method has fewer noise points, the detailed shape and expression are quite different from the original face images. Comparing to the LpPCA method, for a fixed p, the reconstructed images by DC-LpSPCA are with higher resolution than that by other methods (PCA, RSPCA, LpPCA and LpSPCA).
In Fig. 4 (a), when the number of extracted features m is less than 15, the average reconstruction error computed by DC-LpSPCA with p = 2 is significantly smallest among all algorithms. As the number of principal components increases, the values of ARCE for DC-LpZSPCA with p = 1, 1.5, 2 are very close to the minimum value. And the DC-LpZSPCA achieves better sparsity without loss of ARCE. At the same time, we know that DC-LpZSPCA with p = 0.5 has unsatisfactory ARCE values.
In Fig. 4 (b), the value of ARCE of DC-LpZSPCA with p = 1.5 is the smallest in all methods when m < 5. When 5 ≤ m < 15, the ARCE value of DC-LpZSPCA with p = 1.5 is very close to the minimum. As m increases, the values of ARCE of DC-LpZSPCA are only slightly higher than the minimum and tends to be stable.
For dummy case, it is found in Fig. 6 that the reconstructed faces of PCA, LpPCA (p = 2) and DC-LpZSPCA (p = 2) are the most blurred and do not show the characteristics of each face. Relatively speaking, RSPCA, LpPCA (p = 1) and DC-LpZSPCA (p = 1.5, p = 1) are more successful in reproducing the original face image, and the details of eyes, glasses, beard and so on are well presented.
In this work, a sparse robust PCA is proposed based on the zero-norm regularization and the p-norm (0 < p ≤ 2) PCA. Following that, a continuous optimization method, DC programming algorithm (called DC-LpZSPCA), is developed to solve the proposed sparse L p -ZSPCA. The resulting DC optimization algorithm converges linearly. Numerical experimentations are carried out on an artificial data sets and Yale face data sets, and the results show that the proposed DC-LpZSPCA can maintain good sparsity and anti-outlier effect, compared with the traditional PCA methods in most cases.
Footnotes
Acknowledgments
This work is supported by National Nature Science Foundation of China (No.11471010 and No.11271367).