
Abstract
Presently, the Gaussian kernel approach has been widely accepted for measuring the similarities among samples and then constructing various fuzzy rough sets. Notably, the considered parameter plays a crucial role in deriving Gaussian kernel based similarities. This is mainly because different parameters will generate different scales of the similarities. From this point of view, different parameters may result in different fuzzy rough approximations and the corresponding reducts. Generally speaking, to search a parameterized reduct with better generalization performance, a naive approach can be designed by repeating the process of computing reduct through using different parameters. Obviously, it is very time-consuming. To fill such a gap, an acceleration approach is proposed which aims to reduce the elapsed time of searching reducts based on different parameters. The main mechanism of our proposed approach is to take the variation of the used parameters into account, and then the process of finding reduct under current parameter can be realized based on the previous parameter related reduct. The experimental results over 16 UCI data sets, which are obtained by testing different Gaussian kernel based fuzzy rough sets, demonstrate that our proposed acceleration strategy not only can significantly reduce the time consumption of finding reducts in terms of different parameters, but also will not lead to poorer classification performance and significant variation of length of the obtained reducts by comparing with the results obtained by the naive process. This study suggests technical support for quickly finding reducts of parameterized fuzzy rough sets.
Introduction
Attribute reduction [5–7, 45], a rough set based feature selection technology [4, 48], can be exploited in terms of various rough set models. Presently, with respect to different requirements, numerous generalizations of classical rough set model have been proposed and explored [1, 62]. As one of the most popular extended rough set models, fuzzy rough set has been widely concerned for attribute reduction due to its effectiveness in analyzing and handling continuous and even mixed data [8, 51].
For fuzzy rough set, it should be emphasized that different types of fuzzy relation may determine different fuzzy rough set models [41], it follows that different fuzzy rough approximations and the corresponding reducts may be generated. Immediately, how to acquire a suitable fuzzy relation has been an open problem in the researches of fuzzy rough set [36, 59]. For such propose, Hu et al. [13] have proposed a more effective strategy: introduce the Gaussian kernel function into the measuring of similarities between samples, and then derive the fuzzy relation over the universe. Notably, the appointed kernel parameter plays an essential role in deriving Gaussian kernel based fuzzy relation [3, 25]. This is mainly because different kernel parameters will contribute to different scales of Gaussian kernel based similarities, it follows that different fuzzy rough approximations and the corresponding reducts may be induced.
With a careful reviewing of the previous researches, it is not difficult to reveal that most of the Gaussian kernel fuzzy rough based attribute reduction approaches are essentially realized based on one and only one parameter, which are referred to as single parameter based attribute reductions in the context of this paper. In these approaches, given one fixed parameter, one and only one qualified reduct will be returned. Nevertheless, there are some inherent limitations in single parameter based attribute reduction, which can be summarized as the following aspects. Single parameter based attribute reduction may not provide the better adaptability to granularity world, which will result in the lacking of comprehensiveness [58]. For example, given one Gaussian kernel parameter, a fuzzy relation can be derived, and the deriving of such fuzzy relation can be regarded as the process of information granulation [17, 61]. Immediately, it is easily known that the considered kernel parameter actually suggests a corresponding level of granularity [28, 34]. Suppose that a reduct is derived in terms of such fixed parameter based granularity, it may not be still the reduct for a little finer or coarser granularity which may be caused by slight variation of parameter. It follows that multiple parameters based attribute reduction is required. Single parameter based attribute reduction may not be suitable for observing the variation tendency of generalization performance of attributes in the obtained reduct. For example, if one reduct is derived over one and only one parameter, then there is no comparison among the generalization performances of attributes in the reducts obtained over multiple parameters. Therefore, multiple parameters based attribute reduction is also required.
To overcome the limitations mentioned above, it is necessary to develop a novel thinking for Gaussian kernel fuzzy rough based attribute reduction: take multiple different parameters into account. To realize that, a naive approach can be directly designed through repeating the process of searching single parameter based reduct with respect to the number of the considered parameters. However, it is obvious that such method is time-consuming, especially the number of the considered parameters is great. In view of this, an acceleration approach for multiple different parameters based attribute reduction is proposed, which aims to decrease the elapsed time of searching reducts over multiple different parameters. The main mechanism of our acceleration strategy is based on the consideration of variation of used parameters, and the searching of current parameter related reduct may be guided based on the previous parameter related reduct. Figure 1(a) shows the process of the naive approach to search multiple different parameters based reducts, while the framework of our proposed acceleration strategy is illustrated in Figure 1(b).

The processes of searching reducts based on the naive approach and the acceleration strategy.
Following Fig. 1, it is not difficult to observe that different from the naive approach, our process of deriving reduct over current parameter is generated based on the reduct related to previous parameter instead of the whole raw candidate attributes. For example, in Fig. 1(b), if the 1-st parameter based reduct is obtained, then the 2-nd parameter based reduct can be searched based on the reduct related to the 1-st parameter, that is, the searching of the 2-nd parameter related reduct is not begin with an empty set, but with the attributes in the 1-st parameter based reduct. Moreover, it is not difficult to reveal that the searching space of attributes will be reduced in the framework of our acceleration strategy, while all attributes should be checked in the process of computing reducts based on the naive approach. It follows that our acceleration strategy may contribute to lower elapsed time of searching multiple different parameters based reducts, and further improve the time efficiency of finding parameterized reducts.
The rest of this paper is organized as follows. Section 2 will review the basic notion related to various Gaussian kernel fuzzy rough set models and the corresponding attribute reduction. The acceleration strategy for multiple parameters based Gaussian kernel fuzzy rough attribute reduction will be presented in Section 3. Experiments will be shown in Section 4 as well as some related analyses. This paper will be concluded with conclusions and perspectives in Section 5.
Classical fuzzy rough set
Generally speaking, a decision system can be described as DS =< U, A, d >, in which U is the finite set of samples, also known as universe, A is the set of condition attributes, and d is the decision attribute. ∀x ∈ U, a (x) denotes the value of sample x over the attribute a ∈ A, while d (x) indicates the label of sample x. Following the decision attribute d, an equivalence relation over universe U can be obtained by d such that IND d = {(x, y) ∈ U × U : d (x) = d (y)}. Immediately, a partition U/IND d = {X1, X2, …, X q } over universe U can be induced, in which X p (X p ∈ U/IND d ) is the p-th decision class consisting of samples with the same label.
In rough set theory [32, 33], the indiscernibility relation [35] can be regarded as the basic mechanism for granulating the universe, and then the corresponding results of granulation can be used to approximate the target concept, i.e., the decision class. However, if the considered data is continuous, then such model may be powerless in handling and analysing these data. This is mainly because the indiscernibility relation is only suitable for dealing with categorical data. In view of this, various approaches have been proposed to expand classical rough set [11, 60] with respect to different requirements. Presently, the concept of fuzzy rough set has been widely concerned and can be regarded as one of the effective rough sets for analyzing continuous data. An important reason is that the fuzzy rough set is constructed based on the similarity among samples and it will not change the distribution of the raw data. As what has been reported in Reference [13], the Gaussian kernel can be employed to measure the similarity among samples and then such approach has formed a bridge between rough sets and kernel methods.
Given a decision system DS =< U, A, d >, ∀B ⊆ A, the similarity between arbitrary two samples can be measured by the Gaussian kernel function such that
Following Definition 1, it is not difficult to observe that the membership degree of x ∈ U belonging to fuzzy rough lower approximation of X p is actually the fuzzy dissimilarity between x and its nearest sample from U - X p . Similarly, the membership degree of x ∈ U belonging to fuzzy rough upper approximation of X p is actually the fuzzy similarity between x and its nearest sample from X p [10].
Following Definition 1, the operators play an essential role in deriving fuzzy rough approximations, it follows that different operators will result in different fuzzy rough approximations, and then different fuzzy rough set models can be constructed. Therefore, Hu et al. [12] have not only analyzed the inherent limitations of classical fuzzy rough set, but also investigated several operators, and further proposed corresponding fuzzy rough set models. The detailed definitions with respect to these operators are shown as follows.
Following the operators shown in Definition 2, Hu et al. [12] have proposed three fuzzy rough set models which are referred to as k-trimmed, k-mean and k-median fuzzy rough sets, respectively. The detailed definitions of fuzzy rough approximations with respect to these three models can be formulated as follows.
The fuzzy positive region of decision attribute with respect to condition attribute set shown in Definition 4 is actually a fuzzy set, which is derived by the union of fuzzy rough lower approximations of decision classes. Additionally, the fuzzy positive regions with respect to different fuzzy rough sets can be obtained by replacing the counterparts in Equation (9) with fuzzy rough lower approximations based on corresponding operators.
The fuzzy dependency shown in Definition 5 reflects the average degree of the samples which certainly belong to decision classes. Obviously,
∀B′ ⊂ B,
Following Definition 6, it is not difficult to observe that the first condition aims to find all the relevant attributes, while the second condition guarantees that no redundant attributes are contained in the obtained reduct. Obviously, the fuzzy dependency is important in the attribute reduction shown in Definition 6, and the fuzzy dependency can be employed to design significance function, which is used for evaluating the significance of the candidate attribute. The definition of significance function can be formulated as follows.
Sig σ (a, B, d) can reflect the variation of fuzzy dependency when attribute a is added into B, therefore, the higher value of Sig σ (a, B, d) is, the more important the attribute a will be. And such significance function can be employed in the forward greedy searching algorithm to compute γ-reduct. Immediately, the main steps of forward greedy searching for computing γ-reduct can be described as follows.
Potential reduct B is initialized to an empty set. Calculate the fuzzy dependency For each candidate attribute a ∈ A - B, evaluate its significance in terms of the value of Sig
σ
(a, B, d). Select the most important candidate attribute, and add it into the potential reduct B. If the potential reduct B satisfies the first condition shown in Definition 6, then go to Step (6); otherwise, repeat Steps (3), (4) and (5). For each attribute c ∈ B, let , if the attribute subset does not satisfy the second condition shown in Definition 6, then remove the attribute c from B. If no attribute can be removed from potential reduct B, then γ-reduct B is generated; otherwise, repeat Steps (6) and (7).
Based on the above steps, and to simplify our discussion, the detailed algorithm to compute γ-reduct based on classical fuzzy rough set can be described as follows, and the algorithms to compute γ-reduct with respect to different fuzzy rough set models can be analogized.
1) ∀a ∈ A - B, compute Sig σ (a, B, d);
2) Select b such that Sig σ (b, B, d) = max {Sig σ (a, B, d) : ∀ a ∈ A - B};
3) B ← B ∪ {b};
4) Compute
C ← B;
Compute
B ← B - {c};
Following Algorithm 1, it should be noticed that the fuzzy dependency derived by arbitrary attribute subset will be less than that induced by the whole attribute set. This is mainly because the Gaussian kernel based similarity among samples will decrease with the growth of number of the used attributes, and then the membership degrees of samples belonging to the fuzzy rough lower approximations will be increased, which will lead to the increasing of value of fuzzy dependency. That is, the value of fuzzy dependency increases with the growth of number of the considered attributes. Consequently, the threshold ɛ in Algorithm 1 is employed to avoid the case that no attribute can be removed from the raw attribute set.
Moreover, it is not difficult to observe that all candidate attributes should be scanned in the process of searching reduct through using Algorithm 1, and the main time consumption of such algorithm lies in the evaluation of significance of candidate attribute. It follows that the time complexity of Algorithm 1 is O (|U|2 · |A|2).
Problem description
Following discussions above, it is not difficult to observe that one and only one parameter has been considered in most of previous researches related to Gaussian kernel based fuzzy rough attribute reduction. However, it should be emphasised that there are some inherent limitations in one and only one parameter based attribute reduction, as what has been pointed out in the part of Introduction, and these limitations can be attributed to the following two points: 1) single parameter based attribute reduction may result in the lack of better adaptability to granularity world; 2) single parameter based attribute reduction may not be suitable for observing the variation tendency of generalization performance of derived reduct.
Consequently, to overcome the inherent limitations mentioned above, it is necessary to search reducts over a set of different parameters.
Naive approach for attribute reduction
Regarding the problem stated above, given a set of considered parameters, a naive approach can be directly designed: compute reducts repeatedly through using Algorithm 1 over a set of different parameters. Immediately, the main steps of naive approach for searching reducts over a set of considered parameters can be described as follows. The set of γ-reducts For each kernel parameter σ ∈ T, derive the reduct B with respect to σ through using Algorithm 1, and then add B into The set of γ-reducts
Based on the above steps, and to simplify our discussion, take the classical fuzzy rough set as an example, the detailed naive algorithm to compute γ-reducts over a set of parameters is shown as follows.
1) Compute reduct B based on σ through using Algorithm 1;
2) Add B into
Following Algorithm 2, it should be noticed that the output result is a set of reducts instead of one and only one reduct. Moreover, it is not difficult to reveal that Algorithm 2 is mainly performed through repeating the process of Algorithm 1. It follows that the time complexity of Algorithm 2 is O (n · |U|2 · |A|2), where n is the number of kernel parameter in T.
Forward acceleration strategy for attribute reduction
Following Algorithm 2, it is trivial to know that the process of naive approach for searching reducts based multiple parameters is time-consuming, especially the number of the considered parameters is great. Immediately, how to accelerate the process of computing reducts over multiple parameters has become an open topic. For such purpose, an acceleration approach will be designed as follows. Given a decision system DS, if two kernel parameters are considered such that σ1 ≤ σ2, then the main mechanism of our forward acceleration strategy is that the process of finding the σ2 based reduct B2 is in terms of the σ1 based reduct B1. In detail, to search the reduct with respect to σ2, we begin our searching with σ1 based reduct instead of an empty set. Correspondingly, the main steps in our forward acceleration strategy can be summarized as follows. Compute the σ1 based reduct B1 through using Algorithm 1. If B1 satisfies the constraint related to σ2, then we have B2 = B1; if B1 does not satisfy the constraint with respect to σ2, then we select more suitable attributes from A - B1 and add them into B1 until the constraint with respect to σ2 is satisfied, it follows that B2 is generated.
Through applying the above mechanism to the searching of multiple parameters based reducts, and based on classical fuzzy rough set, a forward acceleration algorithm to compute γ-reudcts over a set of parameters can be designed as follows.
1) B s ← Bs-1;
2)
Add B
s
into
s ← s + 1, and go to 1);
Compute
3)
num 1) ∀a ∈ A - B s , compute Sig σ s (a, B s , d);
num 2) Select b such that Sig σ s (b, B s , d) = max {Sig σ s (a, B s , d) : ∀ a ∈ A - B s };
num 3) B s ← B s ∪ {b};
num 4) Compute
4)
C ← B s ;
Compute
B s ← B s - {c};
5) Add B
s
into
Following Algorithm 3, it should be noticed that the first parameter based reduct is still derived by using Algorithm 1, it follows that the time complexity of computing reduct B1 is O (|U|2 · |A|2). However, the time complexity of computing reduct B2 is O (|U|2 · |A - B1|2). This is mainly because in the worst case, B1 does not satisfy the constraint with respect to parameter σ2, and then the searching space of attributes is actually A - B1 instead of A. Similarly, the time complexity of computing reduct B3 is O (|U|2 · |A - B2|2); …; the time complexity of computing reduct B
n
is O (|U|2 · |A - Bn-1|2). Consequently, the time complexity of Algorithm 3 is
Additionally, to facilitate the understanding of our proposed acceleration strategy, an example is presented as follows.
A toy example of decision system
A toy example of decision system
Suppose that the threshold ɛ is 0.05 and classical fuzzy rough set is used, we want to find γ-reducts over a set of kernel parameters such that T = {σ1, σ2, σ3} = {0.01, 0.03, 0.05} by Algorithm 3. The main process of computing reducts over T is elaborated as follows. For kernel parameter σ1, the corresponding reduct is initially derived by using Algorithm 1 such that B1 = {a1, a2}. For kernel parameter σ2, B2 is initialized to B1, due to For kernel parameter σ3, similarly, B3 is initialized to B2, due to
Following Example 1, it is not difficult to observe that different from the naive approach, the searching space of attributes has been reduced in the framework of our forward acceleration strategy. For instance, if σ2 based reduct is required, then all candidate attributes in A should be searched by using Algorithm 2, while only the candidate attributes in A - B1 are searched in terms of Algorithm 3.
To demonstrate the effectiveness of our acceleration strategy, 16 UCI data sets have been employed to conduct the experiments, and the detailed description of data sets is shown in the following (see Table 2).
The detailed description of data sets
The detailed description of data sets
In our experiments, a set of 30 different kernel parameters has been appointed such that T = {0.01, 0.02, …, 0.30}. As used in Reference [12], the value of k has been set to be 3 in k-trimmed, k-mean and k-median fuzzy rough set models. The value of threshold ɛ in algorithms to compute reducts has been set to be 0.05. Moreover, 5-fold cross-validation has been employed. That is, each data set U is divided into 5 disjoint parts such that U = U1 ∪ U2 ∪ … ∪ U5. In the first round of calculation, U2 ∪ U3 ∪ U4 ∪ U5 is regraded as the training set for computing reducts in terms of different parameters, U1 is regarded as the testing set for evaluating the classification performance of attributes in the obtained reducts; …; In the last round of calculation, U1 ∪ U2 ∪ U3 ∪ U4 is regarded as the training set for computing reducts in terms of different parameters, U5 is regarded as the testing set for evaluating the classification performance of attributes in the obtained reducts. Accordingly, the mean values of the corresponding experimental results from 5-fold cross-validation will be mainly compared.
Notably, in the following experiments, to simply our discussion, NA-FRS, NA-FRS k-trimmed, NA-FRS k-mean and NA-FRS k-median denote the Naive Approach in terms of classical, k-trimmed, k-mean and k-median Fuzzy Rough Sets, respectively; FAS-FRS, FAS-FRS k-trimmed, FAS-FRS k-mean and FAS-FRS k-median indicate the Forward Acceleration Strategy in terms of classical, k-trimmed, k-mean and k-median Fuzzy Rough Sets, respectively.
In the following, the elapsed time of searching reducts over a set of kernel parameters through using the naive approach and our acceleration strategy will be compared. The detailed results are exhibited in the following.
With a careful investigation of Fig. 2, it is not difficult to observe the following. Compared with the naive approach, our proposed acceleration approach can significantly reduce the elapsed time of finding reducts over multiple different parameters, especially based on k-trimmed, k-mean and k-median fuzzy rough set models. Moreover, in most cases, if the value of employed σ increases, then the corresponding time consumption of finding reduct may tend to be higher. This is mainly because with the increasing of value of σ, then the constraint with respect to σ may be stricter, it follows that more attributes may be required to satisfy such constraint, and then the corresponding time consumption of searching reduct may be increased. Compared with the classical fuzzy rough set, searching reducts based on other three fuzzy rough set models generally result in higher elapsed time. Take the data set “Forest Type Mapping” as an example, if σ = 0.25, then finding the corresponding reduct by NA-FRS costs 2.1067 seconds, while the searchings of corresponding reducts with respect to NA-FRS k-trimmed, NA-FRS k-mean and NA-FRS k-meidan cost 10.8481 seconds, 11.2685 seconds and 11.5677 seconds, respectively. The main reason for such result is that the operators used to derive fuzzy rough lower approximations in the latter three models are actually based on k nearest samples instead of only one nearest sample in the classical fuzzy rough set model, it follows that more elapsed time is required. The time consumption of computing reduct over the first parameter based on naive approach is similar to that based on our forward acceleration strategy. Take the data set “Waveform” as an example, if σ = 0.01, then searching such reduct by NA-FRS costs 38.1567 seconds, while computing corresponding reduct in terms of FAS-FRS costs 39.9724 seconds. This is mainly because both the first parameter based reducts from the naive approach and our forward acceleration approach are generated by Algorithm 1. Comparisons among time consumption (seconds) of finding reducts.
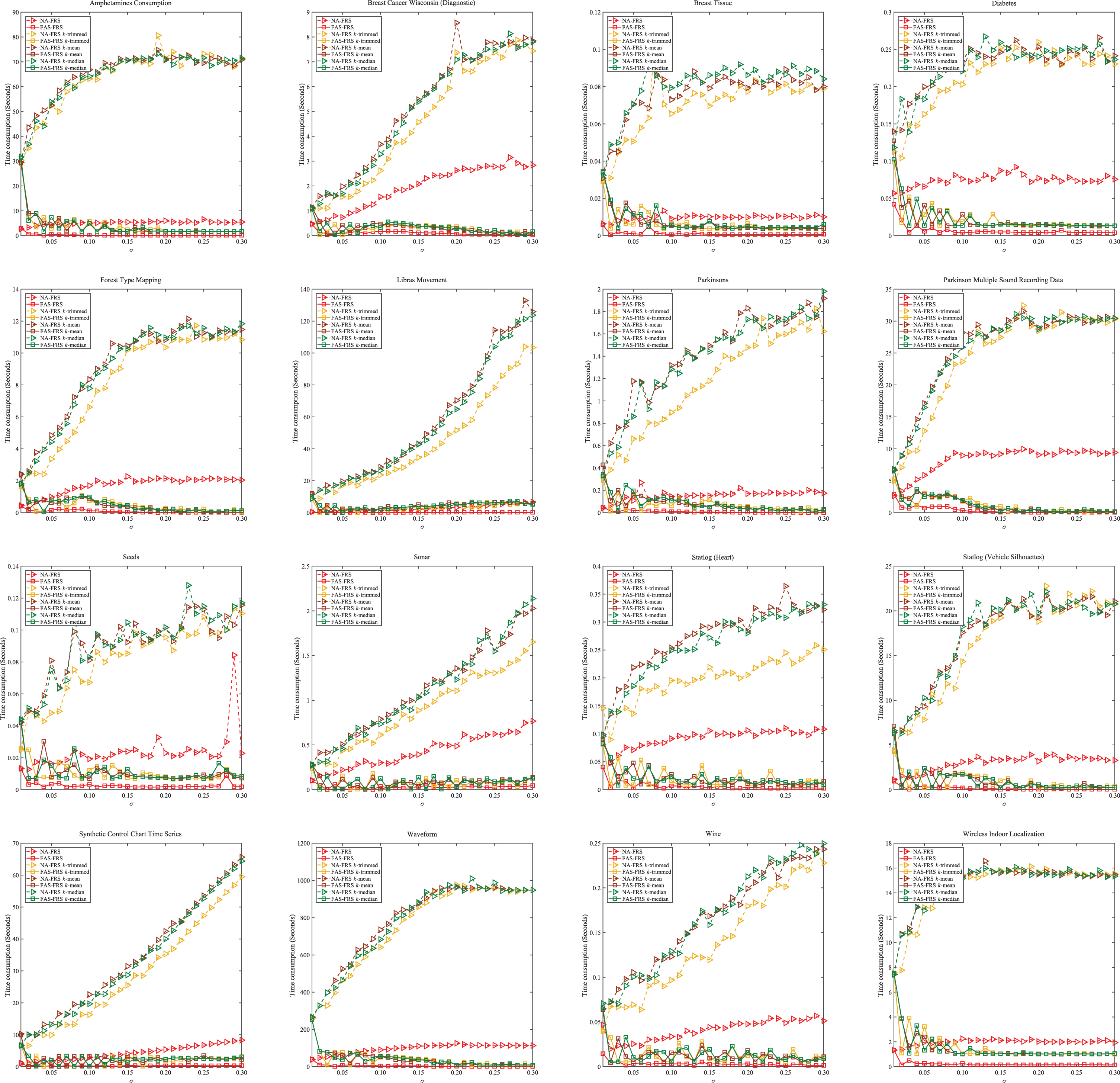
To further compare the time consumption of computing reducts between these two comparative approaches from the viewpoint of statistical theory, Wilcoxon rank sum test [46] will be employed. The purpose of our computation is trying to reject the null-hypothesis that such two approaches perform equally well in the elapsed time of searching reducts over multiple parameters. Assuming that the significance level is set to be 0.05, if the returned p-values are less than 0.05, then we reject the null-hypothesis. The detailed results of p-values are shown as follows.
Following Table 3, it is not difficult to observe that all the returned p-values are less than 0.05. Therefore, we can reject the null-hypothesis that such two approaches perform equally well in terms of time consumption of computing reducts over multiple different parameters. In other words, such result suggests that the elapsed time of computing reducts by using such two approaches is significantly different.
p-values of Wilconxon rank sum test w.r.t. time consumption of computing reducts
Additionally, following the results shown in Fig. 2 and Table 3, it is not difficult to reveal that compared with the naive approach, our proposed acceleration strategy can significantly reduce the elapsed time of finding reducts over multiple different parameters.
In the following, the classification performances of attributes in the obtained reducts will be compared. The KNN (parameter in KNN is 3) and SVM (LIBSVM [2]) classifiers are used for testing the classification performance. Note that the maximal and mean values of classification accuracies over a set of parameters will be mainly compared in this experiment. The detail results are presented as follows, where the higher values of classification accuracies are highlighted in bold, and the value in brackets is the kernel parameter corresponding to the maximal classification accuracy.
With a deep investigation of Tables 4–7, it is not difficult to observe the following. No matter which fuzzy rough set model is employed, the maximal values of classification accuracies obtained by using our proposed acceleration approach are similar to those induced by using the naive approach. Take the data set “Breast Tissue” (ID: 3) as an example, if KNN classifier is employed, then the maximal value of classification accuracies derived by NA-FRS is 0.6801, and the maximal value of classification accuracies derived by FAS-FRS is 0.6706; if SVM classifier is used, then the maximal value of classification accuracies derived by NA-FRS is 0.5952, and the maximal value of classification accuracies derived by FAS-FRS is 0.5952. The mean values of classification accuracies induced by using our proposed acceleration approach are similar to those derived by using the naive approach. Take the data set “Waveform” (ID: 14) as an example, if KNN classifier is used, then the mean values of classification accuracies derived by NA-FRS, NA-FRS k-trimmed, NA-FRS k-mean and NA-FRS k-median are 0.7697, 0.7565, 0.7630 and 0.7595, respectively; the mean values of classification accuracies derived by FAS-FRS, FAS-FRS k-trimmed, FAS-FRS k-mean and FAS-FRS k-median are 0.7664, 0.7578, 0.7598 and 0.7608, respectively. Such result implies that compared with the naive approach, our proposed acceleration strategy may not result in the poorer classification performance of attributes in the obtained reducts. Maximal values of classification accuracies w.r.t. different reducts (KNN classifier) Maximal values of classification accuracies w.r.t. different reducts (SVM classifier) Mean values of classification accuracies w.r.t. different reducts (KNN classifier) Mean values of classification accuracies w.r.t. different reducts (SVM classifier)
Similarly, Wilcoxon rank sum test [46] will be employed to compare the naive approach and our acceleration strategy in terms of the classification performance of attributes in the obtained reducts. Assuming that the significance level is set to be 0.05. The detailed p-values are shown in the following, where the poorer values are highlighted in italics.
Through a careful investigation of Tables 8 and 9, it is not difficult to observe that the derived p-values over the most data sets are greater than 0.05. In view of such result, for KNN and SVM classifiers, the classification performances of attributes in the obtained reducts generated by such two approaches are not significantly different.
p-values of Wilcoxon rank sum test w.r.t. classification performance (KNN classifier)
p-values of Wilcoxon rank sum test w.r.t. classification performance (SVM classifier)
Moreover, by Tables 4–9, it is not difficult to conclude that compared with the naive approach, our acceleration strategy can generate the reducts of which the attributes may not contribute to poorer classification performance.
In the following, the lengths of reducts, which are generated by using the naive approach and our acceleration strategy based on different fuzzy rough set models, will be compared. The detailed results are shown as follows.
With a careful investigation of the results shown in Fig. 3, it is not difficult to observe the following. The length of reducts generated with our acceleration strategy is similar to that generated with the naive approach over most data sets. Such observation result indicates that compared with the naive approach, the using of our acceleration strategy will not lead to significant difference in terms of the length of obtained reducts. With the increasing of value of kernel parameter σ, the lengths of obtained reducts based on different models show us an increased trend whether the naive approach or our acceleration strategy is employed. Such observation tells that if the value of σ increases, then more attributes will be selected to derive the reducts, which satisfy the intended constraint. The main reason for such result is that the fuzzy similarity between samples will be increased with the increasing of value of σ, and the membership degree of sample belonging to fuzzy rough lower approximation will be decreased, then the corresponding fuzzy dependency will be decreased. Therefore, to search the reducts which satisfy the predefined constraint, more attributes are selected. The lengths of the obtained reducts based on classical fuzzy rough set are greater than the lengths of the obtained reducts based on other three fuzzy rough sets over most data sets whether the naive approach or our acceleration approach is employed. Such result indicates that compared with the classical fuzzy rough set, the using of the other three fuzzy rough set models may generate the reducts with fewer attributes.

Comparisons of lengths among different reducts.
Similar to Sections 4.1 and 4.2, Wilcoxon rank sum test [46] is selected for comparing the lengths of reducts derived by the naive approach and our acceleration strategy. The detailed p-values are shown in the following, where the poorer values are highlighted in italic.
Assuming that the significance level is set to be 0.05, following the results shown in Table 10, it is not difficult to observe that the most p-values are greater than 0.05. From this point of view, such two approaches do not have significant difference with respect to the length of the obtained reducts.∥Moreover, based on the results shown in Fig. 3 and Table 10, it is not difficult to conclude that lengths of reducts derived by the naive approach and our acceleration strategy are similar, and the differences between such two approaches are not significant. That is, compared with the naive approach, the using of our acceleration strategy will not contribute to significant variation of the length of the obtained reduct.
p-value of Wilcoxon rank sum test w.r.t. length of reduct
Gaussian kernel is frequently employed to measure the similarities between samples, it follows that different kernel parameters may result in different fuzzy approximations and the corresponding reducts. Consequently, given a set of multiple different kernel parameters, to find a parameterized reduct with better generalization performance has become a key topic. For such purpose, a naive approach can be realized by repeating the process of finding reduct over each parameter. Nevertheless, such approach is too time-consuming, especially the number of the considered parameters is great. To alleviate such a problem, an acceleration approach is proposed to decrease the time consumption of searching reducts over multiple parameters. Such approach is mainly designed by considering the variation of the used kernel parameters, and the process of computing reduct over current parameter is searched based on the reduct related to previous parameter, which can reduce the searching space of attributes and the whole elapsed time of finding reducts over multiple different parameters. Moreover, the experimental results suggest that the proposed acceleration strategy can not only significantly reduce the time consumption of finding reducts over multiple different parameters, but also may not contribute to poorer classification performance of attributes in the obtained reducts.
The following topics deserve our further investigations. Only the forward acceleration strategy for attribute reduction is considered in this paper, the backward acceleration strategy will be further taken into account. Only the attribute reduction based on the measure fuzzy dependency is considered in this paper, the attribute reduction based on other measures such as conditional entropy and mutual information will be further explored. The acceleration mechanism to attribute reduction over single parameter will be introduced to further improve the time efficiency of our proposed framework.
Footnotes
Acknowledgments
This work is supported by the Natural Science Foundation of China (Nos. 61906078, 61572242), Key Laboratory of Data Science and Intelligence Application, Fujian Province University (No. D1901).