
Abstract
This paper proposes a new content recommendation system which combines the newly proposed embedded feature selection method and the new Fuzzy Temporal Logic based Decision Tree incorporated Convolutional Neural Network classifier. The newly proposed embedded feature selection called Fuzzy Decision Tree and Weighted Gini-Index based Feature Selection Algorithm (FDTWGI-FSA) that contains the existing incorporated the Fuzzy Decision Tree (FDT) and the Weighted Gini-index based Feature Selection Algorithm (WGIFSA) for getting optimized feature subset. Moreover, an enhanced CNN and Fuzzy Temporal Decision Tree for performing the deep learning process which is able to identify the exact e-content from the huge volume of data with the help of the recommended features by the proposed embedded feature selection method. The exact e-content can be identified after performing the five-layer network structure for extracting the relevant features and it also can be classified by applying the Fuzzy Temporal Decision Tree for the e-learners. Finally, the proposed content recommendation system provides exact content to the e-learners according to their level of understanding and it also satisfies them by providing the exact high level contents. The experiments have been conducted for evaluating the proposed content recommendation system and compared with the existing classifier including the standard CNN.
Keywords
Introduction
E-Learning is an important component today for performing the collaborative learning process to teach the new concepts and subjects and to learn the innovation as pack in various forms of methodologies [3]. These kinds of collaborative learning techniques are widely recommended by the expert due to the availability of enormous learning theory with more relevant theories. The learning theories such as connectivism, behaviourism, constructivisism and cognitivism are useful for easy understanding the innovation techniques and concepts through e-learning. By using this learning theories that are incorporated with the content recommendation systems, the exact content will be retrieved by applying feature selection and content classification processes. The fuzzy logic [13] based web content recommendation system [23] which incorporates the learning theory, feature selection and text classification processes is used to recommend the more relevant and exact content to the e-learners for their easy understanding. For this purpose, many researchers developed various e-learning applications and have taken enormous effort to provide the expected e-learning document by using feature selection, classification and information retrieval algorithms. The researchers incorporated the collaborative learning techniques in their e-learning software for facilitating the group work interactions and exchanging the learner’s knowledge in their e-learning applications [19].
The data pre-processing task [35] is very important in data analytics. For analyzing the data or huge volume of data, feature selection process is necessary to identify the key attributes / words and also to identify the positive and negative features. According to the identified positive or negative features only can categorize the whole data in a website or web document. Generally, the dataset is classified into two subsets such as training and testing dataset. Moreover, three different types of feature selection such as filter method, wrapper method, and embedded methods are available [2]. Among them first, the filter methods rank the features directly based on the evaluation metrics that are used to select the Top-N most contributed features. Second the wrapper methods to select a set of features as a subset when trained in a system by applying classification techniques. Generally, it is expensive and few wrapper methods perform the forward selection process, the recursive feature elimination process, and the backward elimination process. Later on, classifiers such as Support Vector Machine (SVM) and Decision Tree (DT) based wrapper methods are also introduced by the different researchers. In their methods, they have used the classifiers for splitting a dataset. Moreover, they also introduced a kernel function based feature selection method for providing better results than the standard SVM and DT based wrapper methods [26, 34].
Convolutional Neural Network (CNN) [16] is an advanced version of the Artificial Neural Network (ANN). In CNN, the input layer is used for providing inputs and the output layer is used for supplying the result that is forwarded from the processing layers as input. Here, multiple layers are available as processing layers for performing convolution operation. In between the input and output layers, it has four layers such as embedding layer, convolutional layer, pooling layer, and fully connected layer. These layer outputs are considered and forwarded to the next processing layer as input. The output of the final layer is forwarded as a result of the output layer. First, the embedding layer is a matrix in that each word of the contents and are organized in a specific order based on a top-down manner. Second, the convolutional layer is able to get many features as maps by applying the convolution operation. Third, the pooling layer is considered and named as sub-sampling layer that can be reduced the input data size. Many kinds of pooling are possible but, the very common one is a max-pooling layer. Finally, the fully connected layer is usually connected with one or more connected layers and the output of the fully connected layer as a final output. There are three features of CNNs such as spatial sampling, local connection and weight sharing. These three features are playing major role in the processes of reducing the number of features and increasing the classification accuracy.
Motivations
The availability of huge volume of content in online, the e-learners are struggling a lot to identify their suitable contents. The available content of each topic is also relevant when we accessed them according to the e-learners requirements and expectations. For example, software engineering subject related contents want to extract from internet then all the available contents and used terms are more relevant. In this scenario, e-learners get confusion to identify the relevant content from the local repository or internet. It is necessary to propose a new content recommendation system for finding the suitable contents from the internet. The e-learners are also expected to identify the content which is more relevant according to their learning capability.
Contributions
The major contributions of this paper are as follows: Proposal of new content recommendation system which combines the newly proposed embedded feature selection method and the new Fuzzy Temporal Logic based Decision Tree incorporated Convolutional Neural Network classifier. Propose a new Fuzzy Decision Tree and Weighted Gini-Index based Feature Selection Algorithm (FDTWGI-FSA) for getting optimized feature subset, propose a new classifier called enhanced CNN and Fuzzy Temporal Decision Tree for performing the deep learning process that can be identified the exact e-content from a huge volume of data. Introduce a new Fuzzy Temporal Decision Tree classifier for extracting the relevant features and it also can be classified by applying the Fuzzy Temporal Decision Tree over the existing CNN for the e-learners. Finally, the proposed content recommendation system provides exact content to the e-learners according to their level of understanding and it also satisfies them by providing the exact high level contents.
The rest of this research article is organized as below. The related works in the direction of feature selection, classification, fuzzy logic, temporal logic, decision trees and CNN are discussed in Section 2. The overall system architecture of the proposed content recommendation is shown and explained in detail in Section 3. Section 4 discusses the proposed content recommendation system in detail with necessary explanations and background of the proposed work. Section 5 demonstrates that the performance evaluation parameters and the experimental results. Section 6 concludes the research article by highlighting the proposed model achievement and also suggests that few directions for further enhancements.
Literature survey
The various works have been proposed by different researchers in the past in the direction of e-learning, feature selection, classification, fuzzy logic, temporal logic and decision trees [2, 38]. Among them, Yi Liu et al. [38] developed a new ensemble classifier which is combined that the evolutionary sampling process along with the feature selection process. They have employed the Bootstrap approach over the original data for generating the subsets as sample. Moreover, the V-statistic is also proposed for measuring the distribution of imbalanced data and it is also has been taken consider as the objective of the GA for the sampling subsets. They have proved that their system achieved better classification accuracy than other algorithms. Simone et al. [31] designed a new semantic framework which is a hybrid model for performing the classification process over the tweets. Moreover, they also contributed that by leveraging the various contextual strategies that are enrichment. Their framework is also encompassed a new solution for handling the more number of features which output from the enrichment of semantic that is the combination of a pruning approach for selecting the area related features that are semantically matched and also considered other related feature selection methods. Finally, they have achieved better improvement in precision, recall and f-measure values.
Han Liu et al. [13] developed a new modified fuzzy logic method that is used to perform the classification process. In their work, they have proved that the fuzzy logic-based methods are able to perform well than the non-fuzzy methods that are available in the literature due to the capability of handling uncertainty and fuzziness of text. They have conducted various experiments using various aspects such as hate speech, religion, race, disability, and sexual orientation. Specifically, they have checked the performance of the proposed method with the standard classifiers including DT, SVM, and Naive Bayes. Their proposed fuzzy method outperforms all the existing works. Qi Li et al. [24] developed a new mechanism that is used to acquire the complete entity types that by combining the performance of the classifier. Moreover, they have used a remote supervision technique which contains noise filtration and also create a quality dataset for training. In addition, they have designed a new neural network model for extracting the various possible text features. Finally, they have demonstrated their model efficiency through experiments.
Mahdieh et al. [17] proposed a new multivariate filter-based feature selection algorithm for classifying the text. The main objective of their algorithm is to eliminate the irrelevant and redundant features from input text data. Moreover, they have compared their algorithm with existing methods such as DT, Modified Naive Bayes, and Multi-Layer Perceptron and proved that their algorithm is better by using the evaluation parameters such as Precision, Recall and F-measure. Bushra et al. [8] proposed a new feature selection method that incorporates the human thoughts and to improve the classification accuracy using less number of relevant and most contributed features. Shiwen et al. [33] proposed a new prediction model that is developed by using CNN for predicting the lung cancer through the analysis of CT scan images of the patients. Their model can predict the nodule malignancy by classifying the five different nodule characteristics semantically that includes texture, margin, calcification, sphericity, and subtlety. Moreover, these all features are useful for predicting lung cancer diseases effectively. Finally, they have proved that the performance of their model by conducting various experiments.
Emilia et al. [10] demonstrated that the performance of classification similarity learning which is depending upon the data format that used for learning the model. They have developed an enhanced classifier for performing similarity learning which combines feature expansion and extraction processes. Moreover, they have developed a data transformation approach that uses standard distance measurement formulas over the training datasets. Amal et al. [3] aim are to provide an overview of the existing collaborative learning methods especially by combining more than one social media as a tool. For this purpose, they have incorporated a new framework with four views such as tool, purpose, subject, and method. They have used ten different collaborative e-learning methods for identifying the potentiality and the lack of fulfill the requirements. Abdalraouf and Ausif [1] proposed a new CNN and Recurrent Neural Networks (RNN) based unsupervised method for preserving the information even with one layer. Moreover, they have used a recurrent layer as a substitute for the pooling layer for reducing the loss data in local information and it also captured the long-term dependencies efficiently. In addition, their method performed well over the standard benchmark datasets and also achieved better classification accuracy.
Asad et al. [4] proposed a new method based on deep-learning for classifying the user’s opinion that expressed in reviews. They have employed that the RNN composed by Long Short-Term Memory (LSTM) for taking advantage of sequential processing and also to overcome the various flaws that are available in the standard models where the data loss occurred. Moreover, their method applied sentiment knowledge, rules and the various strategies for overcoming the disadvantages such as types of sentence, polarity as contextual and opposite, word coverage and sense the word according to the differences. Finally, they have conducted the classification process as per sentence-level and sentiment. Marcos et al. [18] provided a detailed review of EDM researches against the teaching-learning process those are considered an educational perspective. Moreover, they have analyzed the various works in the direction of education and learning and also suggested some useful recommendations. Saurabh et al. [29] proposed a new machine learning which incorporates an effective feature selection and the various classification algorithms such as MLP, SVM with radial basis function and Random Forest. They have achieved a classification accuracy of 94% over the WebKB4 dataset. Finally, they have concluded that semantically different and also feature selection when adapted sequentially leads to improving the machine learning accuracy and the accuracy is also validated with non-healthcare data sets.
Fusheng et al. [12] analyzed the capability of a CNN based deep learning approach for performing binary classification in a responsive manner and non-responsive manner over the real and legal matters. Moreover, a classical CNN model is used in their experiments for performing the optimization process and for achieving better performance. They have proved their approach is better than other standard classifiers. Wenxin et al. [37] proposed a new EHR-independent approach that leverages and distributional representations semantically over the UMLS concepts. They also performed the feature selection process which drives semantically best with characterization. El Barbary and Salama [22] proposed a new Topological Information Retrieval System as the generalization of the Information Retrieval System (IRS). They have examined the relationship order which represents the documents.
Min Yang et al. [20] developed enhanced feature attention based network for improving the performance of a sentiment classifier that is target-dependent. First, they learned the enhanced feature word representations by leveraging the features, Part of Speech (POS) features and other features that express the word position. Second, they have designed a new network which is a multi-view based co-attention for learning a sentiment aware and the target-specific sentence depiction through modeling the situation terms, sentiment terms, and the target words. They have conducted various experiments using two real-world datasets and achieved better performance. Sergio et al. [30] described a new patter classifier that adopts ontology for extracting the relevant contents effectively. Jose et al. [15] proposed a new feature selection algorithm for predicting the related topic by using semantic data. They have compared their result with the existing results that are achieved by using information gain and proved their result is better than the existing results. Fernando et al. [11] developed a new multivariate feature selection approach. They have compared with the standard feature selection methods such as filter, wrapper, and a univariate approach. Moreover, they have used a fuzzy rule-based classification model for classifying the data perfectly with the consideration of selected features.
Wang et al. [36] developed a new feature selection algorithm called Hebb rule-based feature selection (HRFS) algorithm for selecting the most contributed features from the dataset. They have used six bench-mark datasets for conducting a comparative analysis with their feature selection algorithm and proved their algorithm is better than others. Alper et al. [2] proposed a new classifier named genetic algorithm oriented latent semantic features (GALSF) for obtaining a better representation of input web documents in the process of text classification. Binh et al. [7] developed a new variable length and PSO based feature selection method for selecting the most useful features that are used to improve prediction accuracy. These all systems are not satisfied with the current requirement due to the rapid development of technological development, internet users, computer and technological dependency. No recommendation systems recommend the suitable e-content to the e-learners according to their requirements. For this purpose, a new content recommendation system is proposed in this paper for recommending suitable e-content by using the embedded feature selection and Fuzzy Decision Tree-based CNN. In addition, many classifiers have been introduced by various researchers [5, 23] for achieving better classification accuracy.
The various recommendation systems have been proposed by researchers for recommending the con-tents or data to the e-learners in the past. Among them, five works have been summarized with their contributions, merits, and demerits in Table 1.
Recommendation Models
Recommendation Models
The overall system architecture of the proposed content recommendation system is shown in Fig. 1. The proposed architecture contains seven important components such as Database, Data Collection agent, content recommendation system, temporal agent, rule base, rule manager and decision manager that are the entire system and it is useful for explaining the flow of the proposed system.

Overall system architecture.
It is used to collect the terms that are available in the database. The meaningful data only extracted as words from the database others are eliminated.
Decision manager
The decision manager is responsible for controlling the overall system architecture. It takes the final decision over the dataset when performs the feature selection process and the classification process. Moreover, it selects the suitable rules from the rule base with the help of the rule manager and temporal manager, and it applies over the decision making process in feature selection and classification.
Temporal manager
The temporal manager is used to supply the time for retrieving the relevant features from the input document and also used to perform feature selection and classification.
Rule manager
The rule manager is used to extract the relevant rules that are useful for making decision over the input web documents.
Rule base
The rule base contains the various useful IF ... THEN rules and facts those are used to make effective decision over the web content or documents.
Content recommendation system
The proposed content recommendation system consists of two modules such as feature selection module and classification module. First, the feature selection module contains Fuzzy Decision Tree and Weighted Gini-Index based Feature Selection Algorithm (FDTWGI-FSA) for optimizing the feature set. Second, the classification module uses a newly proposed Fuzzy Decision Tree (FDT) with temporal constraints and the existing CNN for performing classification over the input documents.
Proposed work
The proposed content recommendation system consists of two modules such as feature selection module and classification module. First, the feature selection module contains the Fuzzy Decision Tree and Weighted Gini-Index based Feature Selection Algorithm (FDTWGI-FSA) for optimizing the feature set. Second, the classification module uses a newly proposed Fuzzy Decision Tree (FDT) with temporal constraints and the existing CNN for performing classification over the input documents.
Data pre-processing
In this subsection, the data pre-processing is performed by applying the standard text analysis activities such as tokenization, POS (Parts of Speech) tag-ging and Parser. First, the tokenization process is splitting the review comments into token, remove all stop words and useless information. Next in the process of POS tagging, the subjective terms are re-moved and adjectives are to be considered for further process. Then, the parser is applied for constructing a tree for each review comment. It is also implicit the relationship among the words or terms in the review comment. Moreover, the formula is shown in Equation (1) is used in this work for similarity computation which is adapted from the standard formula for measuring the Jaccard’s coefficient.
In this formula, A and B are two documents that discuss fundamental concepts in software engineering. The probability of A and B is the set of all words which appear in both documents A and B and are similar. On the other hand, P (A ∪ B) indicates the number of words that occur either in document A or B or both and which are similar. The Cosine similarity is defined using the formula given in Equation (2).
Due to the use of fuzzy logic with the similarity measures, the similarity is measured in terms of the values from 0 to 1 in which 0 indicates no similarity and 1 indicates full similarity. Any value between 0 and 1 indicate the degree of similarity based upon its nearness to either 0 or 1.
This paper introduces a new feature selection algorithm for handling the imbalanced data to select the most contributed features from the dataset. The major part of this algorithm is a fuzzy temporal decision tree algorithm which is proposed newly in this paper in the standard form of CART. Moreover, the proposed feature selection algorithm introduces the weighted index weighting method for handling a dataset that is imbalanced. In the classification process, the decision tree algorithm is a widely applied learning approach and it also applied in the process of text classification and spam detection. Moreover, the decision tree represents the classification according to the features that are helpful for effective decision making over the dataset with the help of the generated IF ... THEN rules.
Weighted Gini-Index
A fuzzy temporal decision tree is developed by using fuzzy rules with temporal constraints and the recursive method which need to identify the best splitting node. Every splitting node is chosen by repeating the process with all features and values that are possible. Here, the Gini index is used to split the dataset and it also reduces the features using classification results. The best contributing features can be selected by using Gini-index values.
Assume that N is a group of classes and the Pn indicates the probability of class ‘n’. Generally, the Gini index can be defined by using the Equation (3).
In this work, N classes with sample records in a specific class ‘n’ is represent as Cn for the input dataset ‘DS’. Here, the Gini index value of DS is calculated by using the Equation (4).
In this scenario, the input dataset DS is to be split into two sub datasets such as DS1 and DS2 according to the value of feature x. Now, the Gini index value of DS is calculated by using the formula which is given Equation (5).
Now, the specific record is chosen by applying the ranking process over the data set DS along with ‘x’ record. The specific record is ranked according to the ascending order. This case the binary classification is performed and it produces the Positive and Negative. The confusion matrix of the root class is given in Table 2.
Confusion matrix of the root class
Based on the Table 2, the Gini-indices look like in the given Equations (6), (7), (8), (9) and (10).
Where, NR is number of records and D is an original dataset which consists of two different classes that are categorized into two such as positive and negative. Moreover, if x selects as a main feature which is used to split node and the input dataset is also divided into two subsets as DS1 and DS2. Here, DS1 is positive and the DS2 is negative. Moreover, the True Positive (TP) and the False Positive (FP) are the numbers of records of DS1 whose label name is “positive” and “negative”. Similarly, the False Negative (FN) and the True Negative (TN) are the numbers of records in DS2 whose label name is “positive” and “negative”. In addition, ‘N’ indicates the total number of records available in the input dataset DS. In addition, the GI(DS, x) is the impurity value for the dataset DS when applying the attribute ‘x’ as a split feature (node) in the decision tree. If the x value is 0 then, all records must have the similar named label and ΔGI(x) indicates that the decrement over the impurity value in this work. The biggest Gini-index value of the node represents the more chance to select ‘x’ as a splitting feature.
Moreover, this work clearly shows that the Gini-index values of the sub datasets such as DS1 and DS2 that have equal distribution. The result is calculated and it will bias the majority class when uses the imbalanced dataset is handled and produced the solutions for the maximum number of biased problems that are available in the literature. For resolving these issues, this wok introduced a new weight based Gini index for increasing the possibility for the attributes that tend for biasing the class which is minority class and the formation are shown in the Equations (11), (12), (13), (14) and (15).
In Equation (15), w indicates that the weight and it is newly added into the TP and FN in this work.
Moreover, a new weighted Gini-index approach is applied for splitting an input dataset. According to the Equations (6), (7), (8) and (9), the input dataset feature A is selected as a key feature (node) by applying the newly proposed weighted Gini-index approach. Anyhow, very small set of data only categorized correctly. In addition, the Equations between (11) and (15), the weighted Gini-index are used as a spitting criteria and the feature B is selected as a node or key feature and achieved better classification accuracy than the previous one where the feature A acts as key feature for the small set of data.
Input: Dataset DS // DS contains n number of features {F1, F2, ... . Fn}
Output: Tree
Step 1: Initialized a Tree as Empty.
Step 2: If DS is “Original” Then
Exit
Else If DS met any other stopping criteria
Then
Exit
End If
End If
Step 3: For 1 to Number of Features (Fi) in DS do
Step 4: Split the features from DS and check the feature is Fi or not
Step 5: If the split feature Fi is available in DS then
End For
Step 7: Choose a best contributed feature Fi based on Weighted Gini-Index values.
Step 8: The feature Fi is assigned as Root node for the new tree
Step 9: Sub-DS = Extracted features from input dataset DS according to the values of Fi.
Step 10: For I = 1 to All features (Sub-DS) TS = Fuzzy_Decision_Tree (Sub-DS)
Construct the full tree by combining all sub trees
Step 11: End For
Step 12: Return Tree
The most important key feature which has attained more number of times in the newly constructed fuzzy decision tree and the relevant feature are available in the class. Moreover, it can be represented as best feature among the more number of features presence in the dataset. Finally, rank the scores in descending order and choose the very best features. These all selected very best features have been applied for making final decision over the dataset for recommendation.
Classification
This subsection explains in detail about the Fuzzy Decision Tree incorporated Convolutional Neural Network (CNN) model with temporal features which is used to classify the data into relevant and irrelevant documents. The classification accuracy depends on the rules that have been generated and used as knowledge that given in to the CNN for training the model. The CNN is composed of some convolutional layers along with pooling layers and followed by fully connected layers. In general CNN was mainly used for classifying the images and speech recognition but here in this paper, CNN is mainly used for classifying the text and numerical data.
The selected features after pre-processing and feature selection as output are given as input into the CNN layer. Here, different dense layers are used such as 10, 50 and 100 filters along with using Rectified Linear Unit (ReLU) activation function. The CNN model is trained using training data and tested using testing data separately and the outcome features from one layer is fed into other layers as input. The training of dataset is to reduce the error for predicting the relevant content based on the individual user interest. Convolutional layers use 64 and 128 filters for mapping the features and ReLU function is used for not changing the size of volume in each layers. Convolutional layer output is given to fully connected layers which have some parameters like hidden units, bias value and ReLU activation function. Fully connected layer will mpute the score of a class such as predicting the relevant content or not. We can write the convolution function is given in Equation (16)
Where ⊗ is a convolution function and f (y) is an activation function (i.e.,) ReLU function, hj is given features, wj is convolutional kernel layer, bj is bias value of a layer. After using of some convolutional layer and feature maps by using filters, hj should be transformed to a vector.
This layer applies a soft-max function which is useful for classifying the input data according to the given condition in the classification. Moreover, it is a last layer of the convolutional neural network. Generally, it is trained the record or data according to the cross entropy which is able to provide a non-linear variant of logistic regression that is multi-nominal. In addition, the entropy function performs the mapping process between the particular indexes in to a real number, the imitative wants to consider the index.
The multi-nominal logistic regression is used to develop a probability model in statistics that applies the soft-max function as an activation function which is given in Equation (17). Here, the fuzzy rule based decision tree is incorporated with this layer for making effective decision. Generally, it is a classification methodology which generalizes the logistic regression into multiclass problems. By applying this soft-max function can resolve the multi-class problems.
Here, this work is considered the time duration between the time t1 and t2. The particular decision can be taken according to the situations and the time of e-learner’s request in the proposed content recommendation system. Moreover, the activation function is applied in the specific time duration only. So that we claimed this CNN is adopted with temporal features. Finally, the decision is made according to the result of activation function in the particular time duration.
This section discusses about the test bed which is used to evaluate the proposed content recommendation system in this work. The proposed content recommendation system has been tested by using the sentiment analysis dataset from GitHub for performing text analysis and the amazon product review dataset [25] is used for performing the training process for predicting them and also considered the text data from e-book of software engineering where freely available in internet. It is useful for retrieving the relevant e-contents from local repositories and the internet websites. The general evaluation metrics have been applied to measure the capability of the proposed recommendation model in terms of content relevancy. Many experimental results have been conducted by considering the e-contents or web documents which are available for the particular subject contents. Here, the input file will be in the form of documents that are collected from the standard e-learning document and the Software Engineering subject content as a word file. Here, we have used all the documents that are available for performing training and testing process. Moreover, the WEKA tool is used as software for carrying out all the experiments. In addition, the proposed method has been implemented in Python programming (in Intel core i3 with 3GB RAM) for performing the data pre-processing, feature selection and classification.
Performance evaluation metrics
The prediction accuracy over the documents or user data has been calculated in this work using the following metrics such as precision (PR), recall (REC) and F-measure (FM) which are defined in the Equations (18), (19) and (20).
Where, NRD indicates the number of relevant documents and NDR indicates that the number of document retrieved.
Where, NRRD indicates that the number of retrieved relevant document and TDRC means that the total number of document retrieved in collection.
The above mentioned performance evaluation metrics have been considered to perform the experimental analysis over the dataset and e-contents in this work. Moreover, the content relevancy is measured by using the mentioned evaluation metrics. Finally, the proposed system identifies the relevant contents and recommends it to the e-learners for improving their learning capability. It can be demonstrated through prediction accuracy and the recommendation score analysis.
Table 3 shows that the precision values of the proposed content recommendation system and the various works that are developed by Sai Ramesh et al. [27], Amal et al. [3], Qi et al. [24] and Sankar et al. [28] in this direction.
Precision value analysis
Precision value analysis
The precision value of the proposed system is better that all other existing recommendation systems that are developed in the past in this direction in Table 3. This table proved that the efficiency of the proposed system in terms of precision value when uses the different number of documents such as 100, 200, 300, 400 and 500. The reason for the improvement is the use of fuzzy temporal rules, improved CNN classifier with the incorporation of fuzzy temporal decision tree and the similarity score and semantic analysis.
Figure 2 shows the recall value analysis between the proposed recommendation system and the existing systems such as Sai Ramesh et al. [27], Amal et al. [3] and Sankar et al. [28].
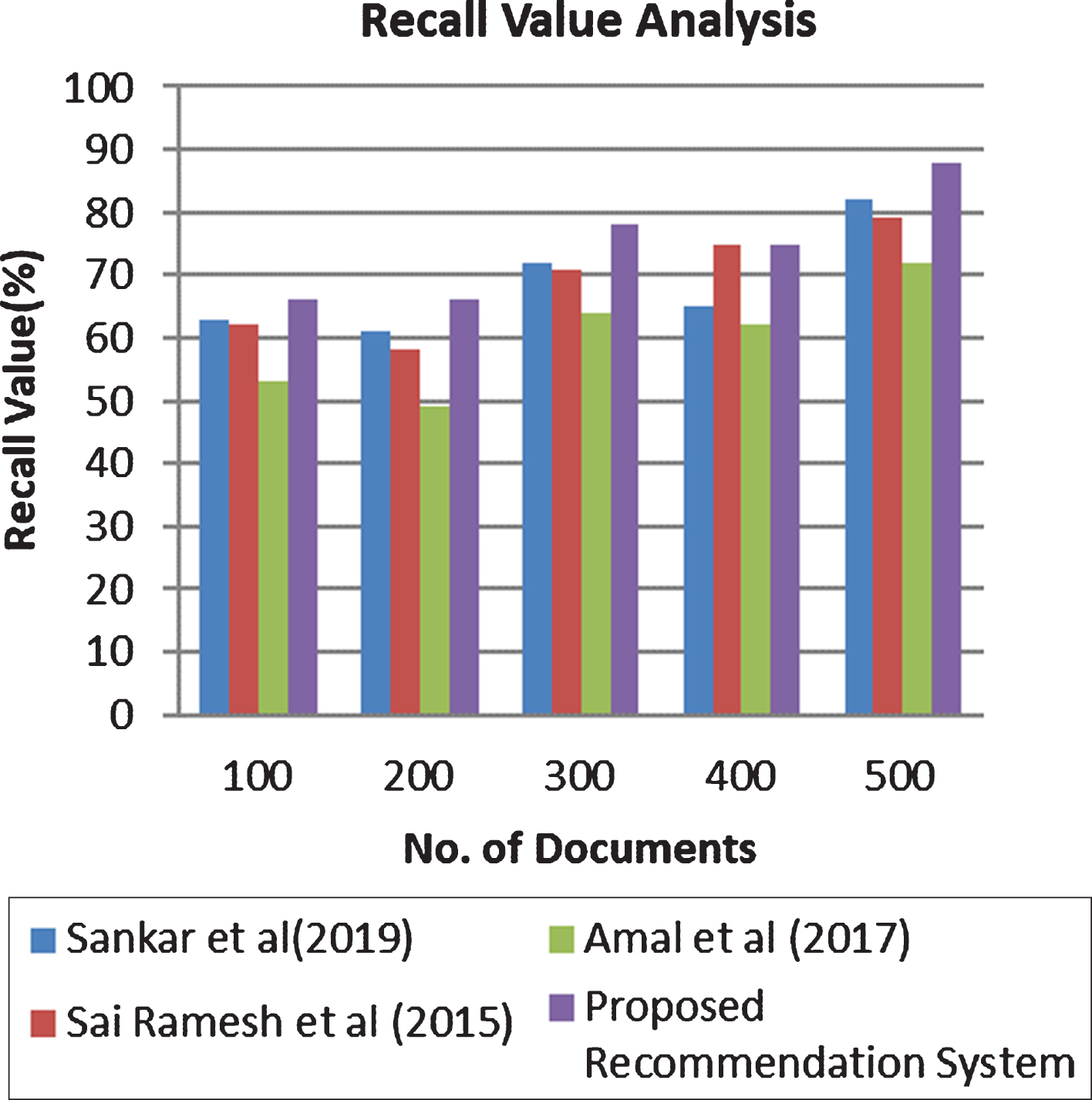
Recall value analysis.
From Fig. 2, it can be seen that the recall value of the proposed fuzzy recommendation system is high than the existing recommendation systems such as Sankar et al. [28], Sai Ramesh et al. [27] and Amal et al. [3]. The performance is increasing while increasing the number of documents such as 100, 200, 300, 400 and 500. This is due to the fact that the use of fuzzy temporal rules on decision tree through CNN, similarity score, feature selection and semantic analysis.
Table 4 shows the F-Measure value analysis between the proposed recommendation system and the existing systems such as Sai Ramesh et al. [27], Amal et al. [3] and Sankar et al. [28].
F-measure value analysis
From Table 4, it can be observed that the improvement of the proposed content recommendation system in terms of F-Measure value when it is compared to the existing systems such as Sai Ramesh et al. [27], Amal et al. [3] and Sankar et al. [28] when uses the different number of documents such as 100, 200, 300, 400 and 500. This is due to the use of feature selection, fuzzy temporal rules, Fuzzy Decision Tree incorporated CNN, similarity score and semantic analysis.
Figure 3 shows that the relevancies score analysis of the proposed content recommendation system and theexisting algorithms that are proposed by Sai Ramesh et al. [27] and Amal et al. [3]. Here, the various numbers of documents like 100, 200, 300, 400 and 500 used in five different experiments.
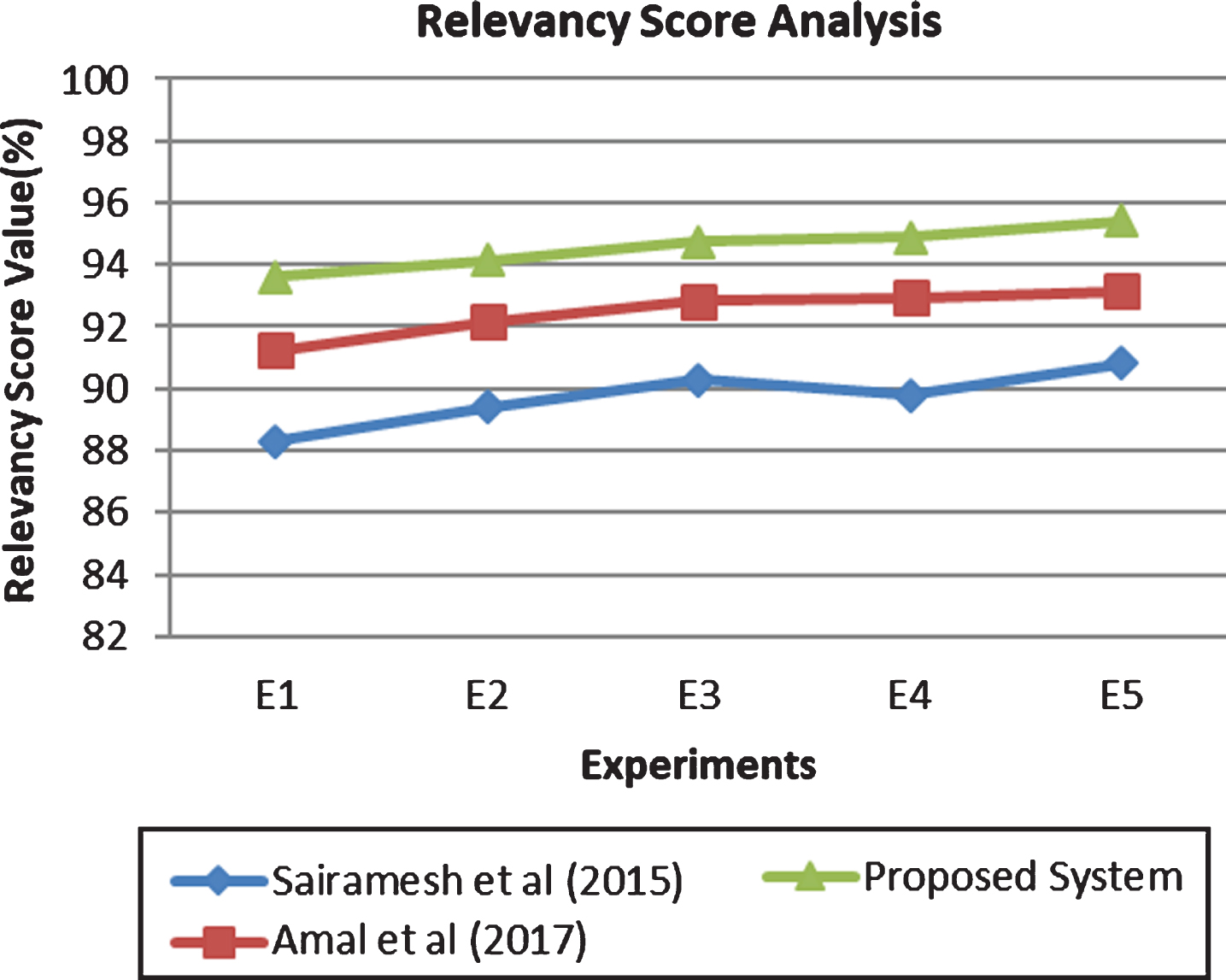
Relevancy score analysis.
From Fig. 3, it is proved that the efficiency of the proposed system in terms of relevancy score is better than the existing algorithms such as Sai Ramesh et al. [27] and Amal et al. [3]. The reason for the improvement of the relevancy accuracy in the proposed content recommendation system is the use of fuzzy decision tree, temporal fuzzy rules, feature selection, fuzzy temporal decision tree based CNN, similarity score and sentiment analysis.
Table 5 shows the performance of the proposed system and the existing systems. It consists of precision, recall and f-measure values for the proposed system and the existing systems.
Comparative analysis based on Precision, Recall, F-Measure and Accuracy
From Table 5, it is observed that the precision, recall, F-measure and the percentage of accuracy for the proposed fuzzy recommendation system is higher than the existing systems. This is due to the fact that the proposed system that uses semantic analysis, similarity score, fuzzy rules, clustering and ranking algorithm.
Figure 4 shows the recommendation accuracy analysis between the proposed content recommendation system and the existing models like conventional system [3], Sai Ramesh et al. [27] and Sankar et al. [28]. Here, this system considered the various documents such as 100, 200, 300, 400 and 500 for experiments.

Recommendation accuracy analysis.
From Fig. 4, it can be observed that the recommendation accuracy analysis of the proposed recommendation system is better than the existing models such as conventional system, Sai Ramesh et al. [27], Amal et al. [3] and Sankar et al. [28]. This is due to the fact that the use of effective semantic analysis and similarity score, feature selection, fuzzy temporal rules incorporated CNN.
Figure 5 shows the comparative analysis between the proposed Fuzzy DT based CNN and other neural and fuzzy rule based classifiers.
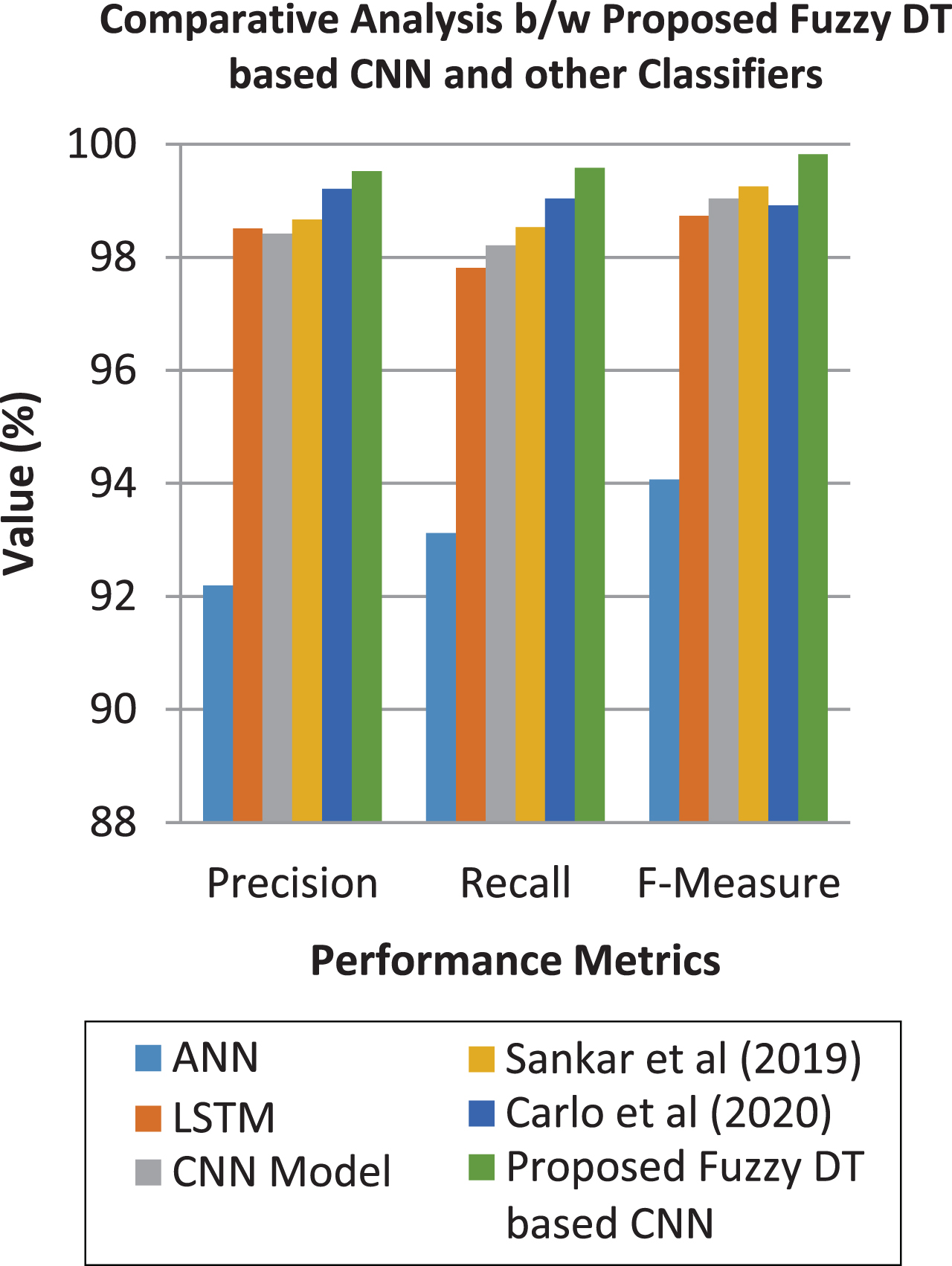
Comparative analysis.
From Fig. 5, it can be understood that the efficiency of the proposed neural classifier called Fuzzy DT based CNN. The proposed model performs well than other existing classifiers such as ANN, LSTM, CNN model, CNN based classifier [9] and Fuzzy rule based classifier [28). The reason for the enhancement is that the incorporation of fuzzy rule based DT on CNN. The necessary fuzzy logic considered rules have been generated and applied in CNN for decision making.
A new content recommendation system which combines the newly proposed embedded feature selection method and the new Fuzzy Temporal Logic based Decision Tree incorporated Convolutional Neural Network classifier has been implemented in this work. The newly proposed embedded feature selection called Fuzzy Decision Tree and Weighted Gini-Index based Feature Selection Algorithm (FDTWGI-FSA) for getting optimized feature subset. Moreover, an enhanced CNN and Fuzzy Temporal Decision Tree for performing the deep learning process which is able to identify the exact e-content from huge volume of data with the help of the recommended features by the proposed embedded feature selection method. The exact e-content can be identified after performing the five-layer network structure for extracting the relevant features and it also can be classified by applying the Fuzzy Temporal Decision Tree for the e-learners. Finally, the proposed content recommendation system provides exact content to the e-learners according to their level of understanding and it also satisfies them by providing the exact high level contents. Future works in this direction could be the introduction of new web crawler for searching and retrieving the more relevant content from internet.