
Abstract
Deep learning is far and wide considered to be the most powerful method in computer vision fields, which has a lot of applications such as image recognition, robot navigation systems, and self-driving cars. Recent developments in neural networks have led to an efficient end-to-end architecture to human activity representation and classification. In light of these recent events in deep learning, there is now much considerable concern about developing less expensive computation and memory-wise methods. This paper presents an optimized end-to-end approach named stochastic deep conviction network (SDCN) formulated using the deep learning method. It comprises of deep learning method namely deep belief network (DBN), two supervised machine learning algorithm support vector machine (SVM) and decision tree (DT) with optimization capability for speech emotion identification. In the beginning, pre-processing is performed and the features are automatically extracted from the input speech signal by the DBN. Since speech signal features loses most of the information and the performance cannot be guaranteed because dynamic interactions can generate uncountable emotion-specific experiences that have the same core feeling state but different perceptual inclinations so DBN provides more robust features. The next step is to classify the emotions in the training phase; here the SVM classifier is chosen which performs dual classification. In order to enhance this classification process, defects must be reduced and the best discrimination of the extracted features should be obtained hence particle swarm optimization (PSO) technique is being added along with SVM classifier in the training phase. To reduce the over fitting problem and risks of a single classifier a DT is being used in the testing phase for the exact identification of emotions (anger, disgust, fear, happiness, neutral and sadness) and therefore it obtains better performance than a single classifier. The complication of the decision tool is that it can increase the computation time. Thus to eliminate this defect whale optimization (WO) technique is being added to the decision tree to reduce the complexity of the system, which in turn lessens the time taken for recognizing the emotion of the speech signal. This formulated proposed SDCN system improves the recognition rate accurately. In this work, theMATLAB environment is being preferred to perform speech emotion recognition. Using the proposed technique the achieved accuracy of emotion detection is above 95% and the identification of various emotions exceeds 98% recognition rate with a computation time of 23 seconds, which has not been achieved so far by any other existing techniques.
Keywords
Introduction
Emotions are personalized and people deduce it differently. It is difficult to define the meaning of emotions and it can also be through the facial images etc. [1]. In emotion recognition through facial images there is a setback that each of the action units in it corresponds to a specific facial muscle movement that are used both individually and in combinations to define a particular facial expression and different illusion which may also bring confusion and provides less accuracy in recognition [2]. Thus, in search of another mode, the human speech signal comes into the picture. At every instance, emotions play a vital role in the lifetime of each and every human being. At least 38% of the complete communication can be identified and communicated through emotions of the speech signal. Automatic classification of emotion is being developed by speech emotion identification (SEI) which is applied in various fields [3, 4]. A medical robot has also been designed using SEI that helps in providing an enhanced wellness program for patients by monitoring the patients’ emotional state [5] constantly and provides indicative ideas [6]. Both speech feature extraction and classification are included in machine learning through which the SEI is being implemented. Due to the deficiency of better generalization, feature extraction has become an issue for all classification methods [7]. The extracted features must diminish the distances between samples with a similar emotion class and exploit the distances between samples with the altered emotion classes [8]. The good performance cannot be obtained if the features are not well defined. Actually, the most powerful speech features cannot be clearly determined in various emotions. The features which are being extracted from the speech include pitch and energy contours which are directly affected by various factors like speaker’s speaking way, phrases, and dialogue rates [9]. A new speech signal cannot be tuned accordingly because obtaining correct classification boundaries is hard as there are overlying features in various speeches. These disputes can be eradicated by using deep learning methods which can spontaneously discover the several levels of representations in speech signals [10–13]. Moreover, deep learning is preferred here because it does not require manual feature extraction. Thus, maximum recognition tasks are being successfully undertaken by these techniques. But the challenges faced by these methods are the complicated decision boundary of the classification [14–19]. The common ensemble classifiers are boost-based, bagging-based approaches, random subspace [20, 21], and so forth. In the case of a single classifier [22], the overfitting complications cannot be reduced, whereas the different classifiers usage has the potential capability to reduce the overfitting problems and expected performance cannot be obtained even if these methods are applied in speech emotion recognition. In order to solve this issue, the novel deep learning architecture is necessary. In [23] a genetic algorithm, particle swarm optimization, and artificial bee colony optimization techniques are preferred for optimizing the different hidden layers and neurons of the hidden layers of an artificial neural network for maximum speech recognition accuracy. In [24] the opposition artificial bee colony optimization technique is proposed for the enhancement of accuracy. Minimax and pole-zero constant optimization methods are proposed in [25] for improving the performance of the system. The optimization techniques are used by various researchers for increasing the accuracy of the work [26–30]. WO algorithm provides the best-optimized output because the problem that is found in the output of the classifier, can be learned and corrected by itself.
Even though the available strategies perform emotion recognition from speech, they fail in finding the necessity of subject-matter from an input, so by using machine learning algorithms the subjective matter can be obtained by optimized learning strategies and automatic feature extraction can be performed. Incoming voice signals cannot be tuned because obtaining correct classification boundaries is hard as there are overlying features which are identified in various speeches. These disputes can also be removed by using deep learning methods which can spontaneously determine the numerous levels of representations in speech signals. The proposed network includes numerous successive frames to form a high dimensional features, which can automatically pre-process the incoming signal and proceed with the next step.
This paper is organized as follows; introduction emphasizes speech emotion identification, Section 2 describes the related work. The proposed framework is explained in Section 3. The experimental results are evaluated in Section 4 and finally, Section 5 provides a brief conclusion.
Related works
Hook et al. [31] in 2019 have proposed a modest performance in speech-based emotion identification with a small set of features. The outcome and the proposed features seems to be promising. But distinguishing the anger and happiness is found to be difficult in the SEI field for machines and humans.
Zhao et al. [32] in 2019 has proposed one dimensional and two dimensional (1D and 2D) convolutional neural network (CNN) and long short term memory (LSTM) networks to identify the speech emotion. Learning the local correlations and global contextual details from various sources like raw audio clips and log-mel spectrograms are being examined. Various aspects must be improved even if the proposed methodology improves the performance in speech emotion identification.
Badshah et al. [33] in 2019 have presented a CNN with a rectangular kernel method to recognize emotions in speech. The proposed technique can be enhanced better if more labeled data can be gathered and deeper CNN has rectangular kernels that can be trained effectively with enhanced recognition rate.
Pu et al. [34] in 2019 have demonstrated a robust principal component analysis (RPCA) which decomposes a data matrix into a superposition of a low-rank matrix and a sparse matrix under certain incoherent conditions. In this paper, a nonlinear generalization of RPCA is proposed that uses two autoencoder networks to achieve such a decomposition, in which one autoencoder accounts for the low-rank component and the other for the sparse components.
Gupta et al. [35] proposed a novel CNN architecture with the spatial pyramid pooling (SPP) layer which works on the fluctuating length feature illustration of speech signals for classifying the emotions from various speech inputs. The benefit of the projected method is that the varying length is considered as the feature representation of speech signals as input. The restriction of the projected kernel is that it necessitates a CNN model to acquire fluctuating size feature maps. Shen et al. [36] in 2019 have explained a cloud removal procedure based on multisource data fusion to overcome this limitation. On the basis of the temporal-based approaches, which employ a cloud-free image as reference, this method further introduces two auxiliary images with similar wavelengths and close acquisition dates to the reference and target (contaminated) images into the reconstruction process.
Wei et al. [37] in 2019 have proposed a novel speech emotion recognition algorithm based on an improved stacked kernel sparse deep model, which is based on auto-encoder, denoising auto-encoder and sparse auto-encoder to improve the Chinese speech emotion recognition. The first layer of the structure uses a denoising autoencoder to learn a hidden feature with a larger dimension than the dimension of the input features, and the second layer employs a sparse auto-encoder to learn sparse features. Finally, a wavelet-kernel sparse SVM classifier is applied to classify the features. The proposed algorithm is evaluated on the testing dataset, which contains the speech emotion data of spontaneous, non-prototypical, and long-term accuracy.
Huang et al. [38] in 2019 have described a novel sub-band spectral centroid weighted wavelet packet cepstral coefficients (W-WPCC) for robust speech emotion recognition. The W-WPCC feature is computed by combining the sub-band energies with sub-band spectral centroids via a weighting scheme to generate noise-robust acoustic features. Deep belief networks (DBNs) are artificial neural networks having more than one hidden layer, which are first pre-trained layer by layer and then fine-tuned using the backpropagation algorithm. The well-trained deep neural networks are capable of modeling complex and non-linear features of input training data and can better predict the probability distribution over classification labels.
Proposed methodology
Speech emotion recognition brings interaction between humans and the machine. The speech signal is taken to be the input that is being processed to determine the emotion of that particular speech signal. These dynamic interactions can generate numerous emotions which may cause loss of important features, so in order to extract efficient features, the deep learning algorithm is considered in the proposed work. It identifies the emotions since it extracts high-level features from data in an increasing way and moreover, it eradicates the necessity of subject-matter expert and performs automatic feature extraction. Incoming voice signals cannot be tuned because obtaining correct classification boundaries is hard as there are overlying features which are identified in various speeches. These disputes can also be removed by using deep learning methods which can spontaneously determine the numerous levels of representations in speech signals. In order to solve the above problem, the stochastic deep conviction network (SDCN) is introduced here, which is an ensemble of deep learning method DBN and two machine learning techniques, support vector machine and decision tree with the combination of optimization techniques PSO and WO. The proposed network includes a process to form a high dimensional feature, which can automatically pre-process the incoming signal and proceed with the next step. At the training phase, feature extraction is being performed on the training set. Firstly only low-level features are extracted and these features are served as an input to DBN after which high-level features are extracted. In order to improve the classification of different emotions, DBN adopts SVM with PSO, which gives the best training to extract high-level features. After that, it is required to classify the different emotions using trained conditions. In the testing phase, DBN inspired decision tree with whale optimization is used which categorizes an N number of emotions from the trained voice signal. The overall proposed framework introduces the SDCN method for speech emotion identification with the combination of generic stochastic subspace to improve the effect of identifying the emotion from the speech. The overall framework is described in Fig. 1.

Block diagram of the proposed system.
The proposed SDCN system consists of extracting features automatically using DBN and then uses a training phase and testing phase. In the training phase, the SVM classifier makes use of the extracted features of speech emotion to perform classification and its performance is categorized into two classifications. Thus, only two categories can be identified out of it in two dimensions (2D). Moreover, the features plotted nearby the boundary may cause less accurate output, so these defects are eliminated using the PSO optimization technique [39] which evaluates the fitness value only after updating the velocity and position of the particle. Hence, the optimized output can be obtained which is the trained output. This trained output is fed into the testing phase which thereby decides the emotion using the decision tree. All the categories of emotions in the speech can be differentiated, but it’s not a rapid process because more complications occur when different emotions are being classified which include (anger, disgust, fear, happiness, neutral, sadness). Thus the decision tree consists of a lot of complications during this process. These complexities have been eradicated by using the whale optimization technique [40] which uses a whale search mechanism that increases overall system efficiency, enhanced system reliability and security. Thus the optimized output obtained proves that the proposed method is the best way to recognize the emotions from the voice input data.
Speech is a significant way to communicate between individuals which will include various emotions. The tone of the voice can also represent the emotional state of a person.
The short time discrete input speech signal is given by
Here S(n) is the input signal, v(n) is the excitation, G is the gain parameter, a k is the prediction coefficients, p is an integer.
The common parameters which can be computed from the speech signal are the vocal quality which includes voice type, glottal attack, resonance, pitch, loudness, respiratory dynamics, and vocal registers. The parameters of voice given in Table 1 are said to be multidimensional in nature.
Parameters of the voice signal
Parameters of the voice signal
The input voice signal must undergo two primary steps which include preprocessing and feature extraction. Pre-processing is performed to remove unwanted noises, but in this work, this process is not used here because the proposed SDCN method is used which automatically performs pre-processing strategy and dimensionality reduction.
Deep learning plays an important role in extracting different speech emotion features and obtaining all the parameters. But these parameters are used for tuning which is a very expensive process. To avoid these optimal parameters, the ensemble learning framework is used. But this ensemble learning does not have the ability to enhance the effect of speech emotion recognition, thus random subspace is being inbuilt to train the base classifier for the ensemble. Even now the speech signal description is not perfect which affects the ensemble classifier’s performance due to the presence of low-level features in subspaces. In order to avoid this problem, a stochastic deep conviction network is introduced. The overall proposed framework is shown in Fig. 2.

Framework of SDCN.
Initially, DBN is used to extract the high-level features, which is made of a large number of restricted Boltzmann machines (RBMs), so that the high-level representation can be learned beneficially only to full fill speech emotion recognition. When a voice signal is taken as the input it may consist of even a few unwanted noises that do not help in recognizing the emotion. So the unwanted noise must be eliminated. After that, features are extracted automatically with the help of a greedy layer-wise learning strategy. A generic stochastic subspace is introduced in order to improve the effect of identifying the emotion from the speech by training the chosen base classifier. To extract high-level features, DBN is being adopted along with SVM–PSO classifier in the training phase, which is used to select parameters required and the emotions of the speech are classified. Finally, the emotions of the input speech signal are being labeled.
The general deep conviction network structural probability distribution function is given below,
Here d gives one feature of the input layer and is an element of the detectable layer. The concealed layer c aims to find dependencies between observed variables. w i j represents the weight between the detectable unit d i and the concealed unit c j . P (d, c) is the joint probability distribution of (d, c) and is given by the Gibbs distribution.
The energy function is equated as
where W represents the weight between the detectable unit and the concealed unit, b and a represents the offset of the detectable unit and the concealed unit respectively in RBM. The parameters used in the above equation are involved in learning from training data using DBN. The training and testing with ith parameters are time-consuming and features of different emotions may miss lead to inaccurate results.
On considering the traditional deep network there are various shortcomings such as lack of accuracy and computational time sufferings, so here a stochastic deep conviction network (SDCN) is used where DBN shortcomings are overcome by using an additional optimal classifier for both training and testing purpose. The section below describes the sectional working of SDCN.
In the training phase of SDCN, both SVM classifiers and PSO optimization techniques are introduced. The SVM classifier is among the most dominant machine learning algorithm which is preferred for data classification. The SVM classifier exploits the margin amidst boundary points of the classes and the splitting hyperplane. For the training, the SVM classifier is utilized to rectify the quadratic programming problem and avoid the convergence problem. The SVM classifier builds a linear model depending on the support vectors just to determine the verdict function. If the training data are linearly independent, then the discriminative classifier discovers the optimal hyperplane that departs the data from the error. The SVM classifier is said to be one among the best classifier due to their output having increased maximum margin, its ability to handle very higher dimensionality samples; and their convergence is less compared to the cost function. SVMs attain expressively advanced search accurateness than traditional query refinement schemes. Even though the SVM classifier is considered to be among the best classifiers, it also consists of various disadvantages like the dearth of an immaculate relationship between distance from the margin and the probability of the posterior class. Another issue of this classifier is that, in their unique formulation, they are confined to work with input vectors of fixed dimensions. The optimum separating hyperplane can be found by minimizing ||w||2 under the constraint y i (w . x i + b) ≥ 1, i = 1, 2, …, n, where b is a margin slack variable, the addition of margin slack variables allows a controlled violation of the constraints.
The determination of optimum hyperplane is required to solve the optimization problem given by:
s.t y i (w . x i + b) ≥1, i = 1,2,3, ... .n
The new optimization problem is given as:
s.t y i (w . x i + b) ≥1 - ξi, ξi ≥ 1, 2, 3, … n
c is a free parameter (known also as regularization parameter or penalty factor.
In the selection of the hyperplane in SVM classifier, additional time is consumed therefore here the optimally the hyperplane is selected and Equation 4 and 5 indicate this process. Thus a condition indicated in Equation 5 is defined to get exact hyperplane by replacing Equation 4 of the general SVM classifier.
At last, another constraint is that this classifier just orders, however, they don’t give us a dependable proportion of the likelihood of the rightness of the classification. The Equation 6 represents the positive SVM classification.
Here Y i describes speech emotion features, output b represents the bias, argmax means argument of max, K is the kernel, y i is the non-linear function and α is the Lagrange multipliers.
Figure 3 represents the structure of the SVM classifier. x(i-1), x(i-2), ... x(i-p) are the extracted features fed for training into the SVM classifier. In our approach, spectral features, prosodic features, and Hu moments for weighted spectral features (HuSWF) are combined. The spectral features contain linear predictor cepstral coefficients (LPCC), zero crossings with peak amplitudes (ZCPA), and perceptual linear predictive (PLP) [39]. Prosodic features are often used together with spectral features in speech emotion recognition, as they have good supplement effectiveness within the SVM classifier; these features undergo non-linear function (Ø) and kernel function (K). Finally, the predicted output is determined. In this paper, the SVM classifier is executed along with the PSO optimization technique. Yi will be the optimized output as gbest in Fig. 4.

Structure of SVM classifier.

Process Flow of PSO Optimization.
Figure 4 shows the process that takes place when the PSO optimization algorithm is inserted inside a procedure.
Each particle’s velocity is updated using this Equation:
i is the particle index a is the inertial coefficient e1,e2 are acceleration coefficients, 0 ≤ e1, e2 ≤ 2 s1, s2 are random values 0 ≤ s1, s2 ≤ 2 regenerated every velocity update
Each particle’s position is updated using Equation 7:
PSO optimization technique has two phases: initialization phase and cycle phase. Hence it begins by initializing the particle with random position and velocity vector. After the initialization, the fitness value is being calculated for each and every particle position. If fitness (p) is better than fitness (pbest) then pbest = p. From the acquired pbest the best one is chosen to be gbest. Now both the position and the velocity are updated. The final step is reached when gbest is chosen to be the optimal solution. Until the gbest value is selected the cycle goes on which is said as cycle phase. The optimized output is then provided to the testing phase. The advantage of PSO compared to other techniques is that it has fewer algorithmic parameters to specify. Thus well-optimized data is said to be the trained data.
Figure 5 shows the flow graph of the hybrid form combining the SVM classifier and PSO optimization technique. The training samples are fed for feature extraction and after high-level feature extraction classification is being performed on the extracted features, using the SVM as the base classifier. After classification is being implemented the output is optimized using the PSO optimization technique. The hybrid form obtained by combining the SVM classifier and PSO optimization technique provides the actual output as the class label of the input sample. This combo has just one aim that is to shrink the time usage. This hybrid form has a positive point that is to estimate its effectiveness.

Flow process representing the hybrid form combining SVM classifier and PSO optimization technique.
The investigational result determines both the sound confirmation and training time of the proposed forward combination algorithms are enhanced than that of using the SVM classifier algorithm independently. Furthermore, this hybrid form converges more rapidly than traditional gradient descent. Moreover, when comparing with the regular algorithm the percentage enhancement in the time and accuracy is found to be enhanced. The output of the SVM classifier is provided to PSO optimization since this SVM classifier has few defects that are rectified by adding PSO optimization technique. Now the optimized output will be gbest.
Let ‘F(t)’ be the output of the training phase. This output is fed to the testing phase as its input. Thus it is made very clear that by the usage of SVM classifiers the quadratic programming problem and the convergence problem are being evaded. The combination of this classification method and optimization process as the combo has shrunk the time usage and increases the effectiveness.
In the testing phase, a hybrid form combining the decision support tree and whale optimization method is introduced. Decision tree models are prevailing analytical models that are simple to analyze, visualize, implement, and score. They are also skilled at managing variable interaction and model convoluted verdict boundary by piece-wise approximations. But the decision tree has various disadvantages which include complexity and they are time-consuming. The charge of training makes decision tree analysis an expensive selection. In order to reduce all these disadvantages whale optimization method is added to it, so that speech can be recognized with high effectiveness and reduced complexity. Let’s consider the output of the decision tree tool be S
i
. The whale optimization method is one of the recent metaheuristic optimization based on the whale hunting mechanism. Compared to various other techniques WO algorithm provides the best-optimized output because the problem that is found in the output of the decision tree can be learned and corrected by itself. This ability is very less in various other traditional techniques thus in this paper the whale optimization method is preferred. The best search agent is being identified in the below equations,
Where
Where the value of the variable
The second phase is the exploitation phase which is accomplished in two techniques which are shrinking encircling technique, and spiral updating position.
Here
Here p is a random number over the interval [0,1]. In global search, the new position is being been formulated as in (8) and (9) equation.
Here
Thus the effectiveness, as well as accuracy, are being increased and the time consumption, as well as complexity, are being reduced.
Experiments are performed on the input speech database. This input speech signal can have any form of emotion. Those can be any one of the following emotions: anger, disgust, fear, happiness, neutral and sadness. This paper finally recognizes which one of the above-mentioned emotion is present in the input speech signal.
Figure 6 is the input speech database waveform of an incoming speech signals for experimentation and to extract the required features. An innovative idea is introduced here by using the SVM classifier in the training phase and decision tree method in the testing phase. The trained data is capable of identifying the exact emotion from the speech signal with high accuracy and efficiency. The enhancement of the output is performed using the PSO optimization which boosts the system performance. The complexity of the output obtained from the decision tree is completely eradicated by the usage of the whale optimization technique.

Input Speech Database waveform.
To authenticate the proposed SDCN, experiments are performed on a speech database. Berlin’s emotional speech database in German (EMODB) [28] is one of the famous databases used for speech emotion identification. Six emotion classes are present in this database. The number of each class is termed as follows: include anger (127), fear (69), disgust (46), happiness (71), neutral (79) and sadness (62).
Simulation work using our proposed technique
The input data undergoes pre-processing and feature extraction simultaneously using proposed SDCN and then the extracted features are fed for classification using SVM classifier and since this classifier has few defects those are rectified by adding PSO optimization technique. The aim of this combo is for lessening the time usage. SVM classifier based approach is compared with the combination of SVM classifier and PSO optimization algorithm in order to estimate the effectiveness. The experimental result determines both the sound verification and training time of the suggested combination algorithms are enhanced. Furthermore, it has been established that this combination converges more rapidly than traditional gradient descent. The communication is said to be effective only if the emotion is not misinterpreted and replied quickly, but the complication of the decision tool can cause a delay. Thus this defect is being eliminated using whale optimization by reducing the complication of the system which lessens the time taken for recognizing the emotion of the speech signal. Thus in this paper, the proposed SDCN along with various enhancing techniques involved have fulfilled all the requirements to recognize all the emotion of the speech successfully.
Figure 7 shows that the data is being classified using an SVM classifier, which uses a threshold value to classify the given data. Thus the classification given above is differentiated in two different colors. If the values are above the threshold value then it is shown in green color, above a hyperplane and if the value is beneath the threshold value then it is shown in red color below a hyperplane, which visibly shows the classification. Here x1 and x2 defines the feature for classification.

Classification of positive and negative classes using SVM classifier and PSO optimization technique.
In order to show the classification perfectly, a hyperplane in 2D is being used so that the classification can even be viewed if the data is just nearby the threshold value. In Fig. 8 the decision boundary represents the threshold value. Here x1 and x2 defines the feature for classification. The nearby threshold value, the data are represented using dots.

Hyperplane in 2D which represents the classifications properly.
This graph in Fig. 9 displays the initial data set of the features drawn between fitness value and iteration. The required features are being extracted automatically using DCN, which are represented by various symbols in order to differentiate various emotions present in the input speech signal. Figure 10 visibly shows that the majority of the emotion present in the input speech signal consists of fear as the dominant emotion whereas anger and disgust are very less in the ratio.

Initial data sets of features are represented.
Region of various emotions including anger, disgust, fear, and happiness are being represented.
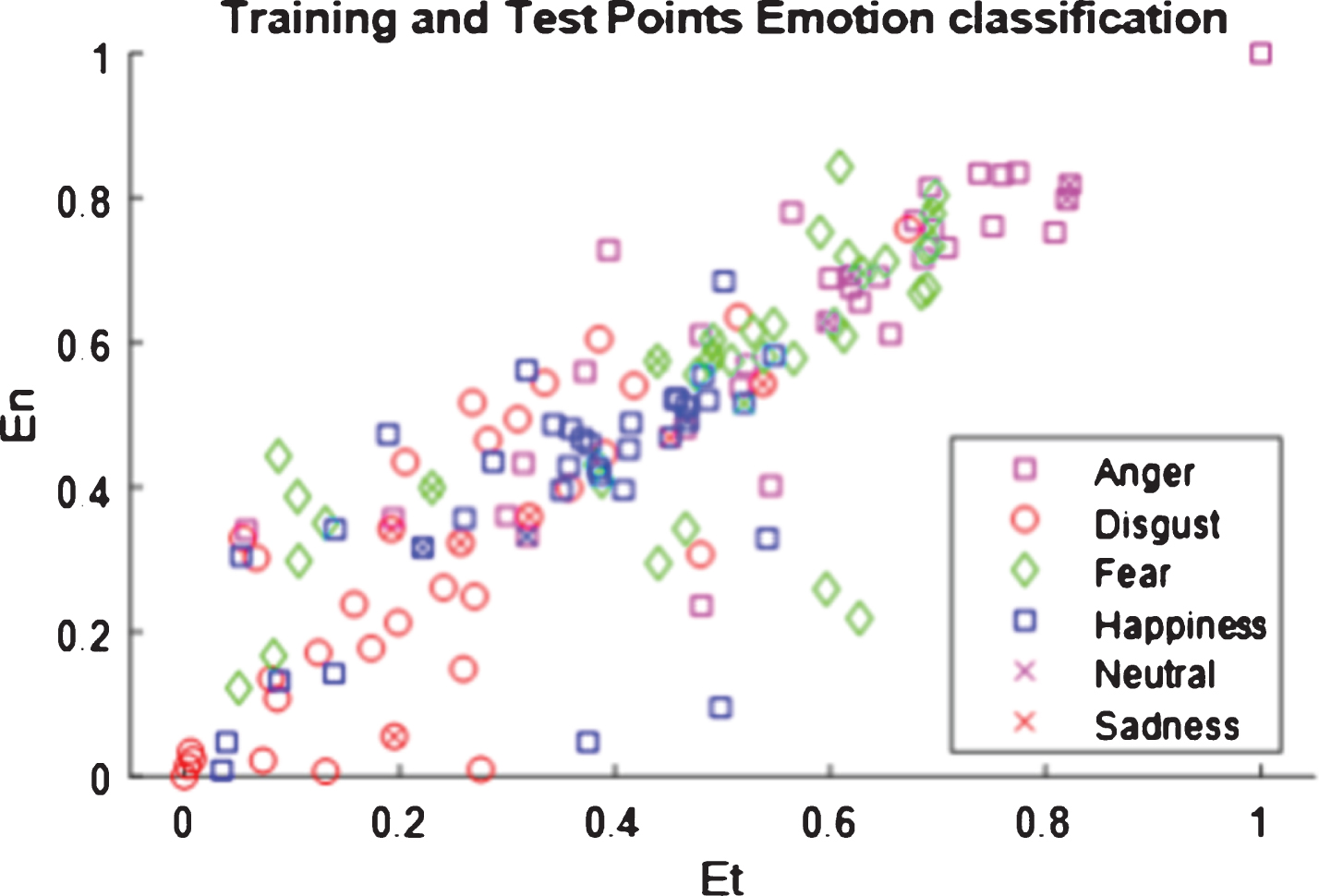
Figure 11 shows training and testing points for various emotions which include anger, fear, disgust, happiness, neutral, surprise and sadness. Here Et is the threshold of emotions and En is the total emotion features. Based on this emotion classification the actual emotion can be identified, but just by using SVM classifier accurate output cannot be obtained hence PSO optimization is being applied to the output of the SVM classifier.
Training and Test points Emotion classification.
When PSO optimization is preferred, it calculates the fitness value only after updating the velocity and position of the particle. After evaluating the fitness value corresponding to each position and velocity iteration, it forms a convergence curve plotted in Fig. 12. The different colors in the plot indicate relative curves between different fitness values and iterations for different emotions.
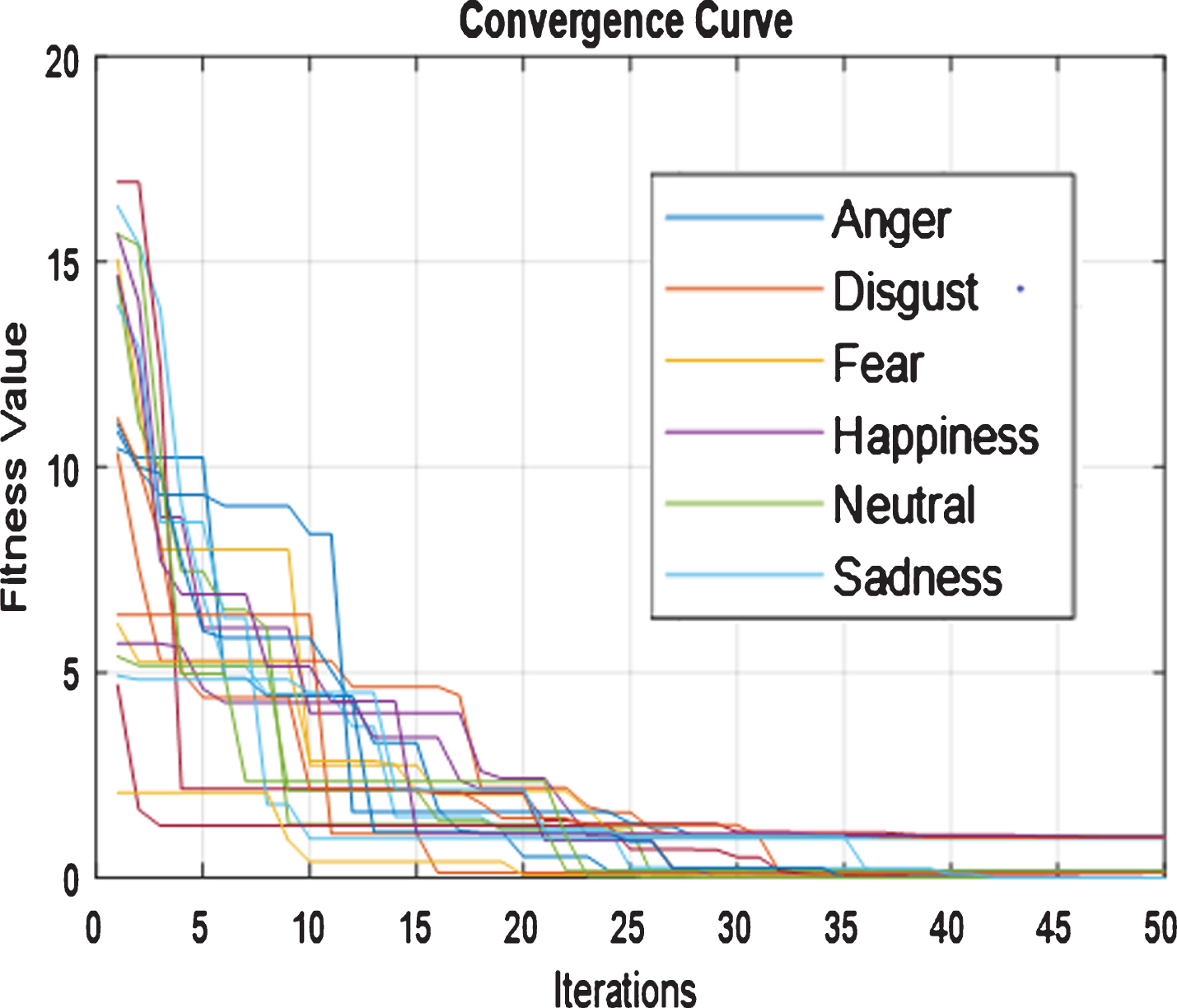
The convergence curve is plotted between fitness value and iterations.
There are four possibilities which include true negative (TN), false negative (FN), true positive (TP) and false positive (FP). True negative represents that there are no definite class values and no expected class value. False-positive represents that there is actual class value, but no predicted class value. False-negative represents that there is no actual class value, but predicted class value is present. By including the enhanced methods optimized output are being obtained which shows excellent improvement in their performance. This is verified by receiving the actual characteristics of the applied techniques which include precision, recall, and accuracy in Fig. 13.
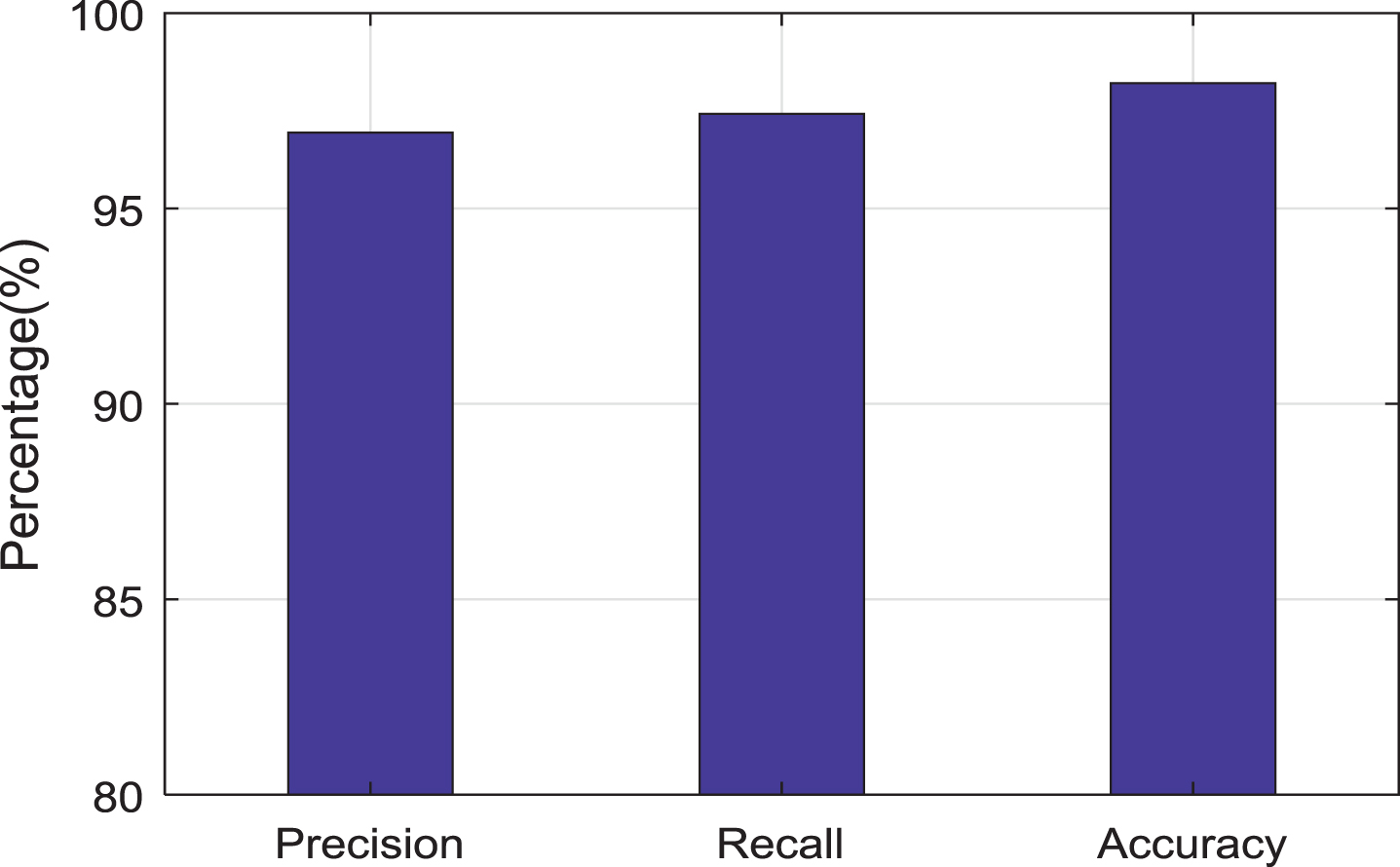
Bar chart to display the percentage of precision, recall, and accuracy obtained by using the proposed method.
The performance of the proposed method is being improved comparatively. The upcoming graphs are plotted that show precision, recall, F-score and accuracy for various emotions. Precision is being calculated using TP and FP.
The above graph displays the precision, recall, F-Score and accuracy variations for all the mentioned emotions. Figure 14(a) shows precision,which represents the consistency of the measurement. As the precision is high for all the emotions the repeated value of the reading can be gained. In Fig. 14(b) recall value is being plotted for various emotions. This recall value determines the number of appropriate documentation improved by a search segregated by the all-out number of existing significant records.
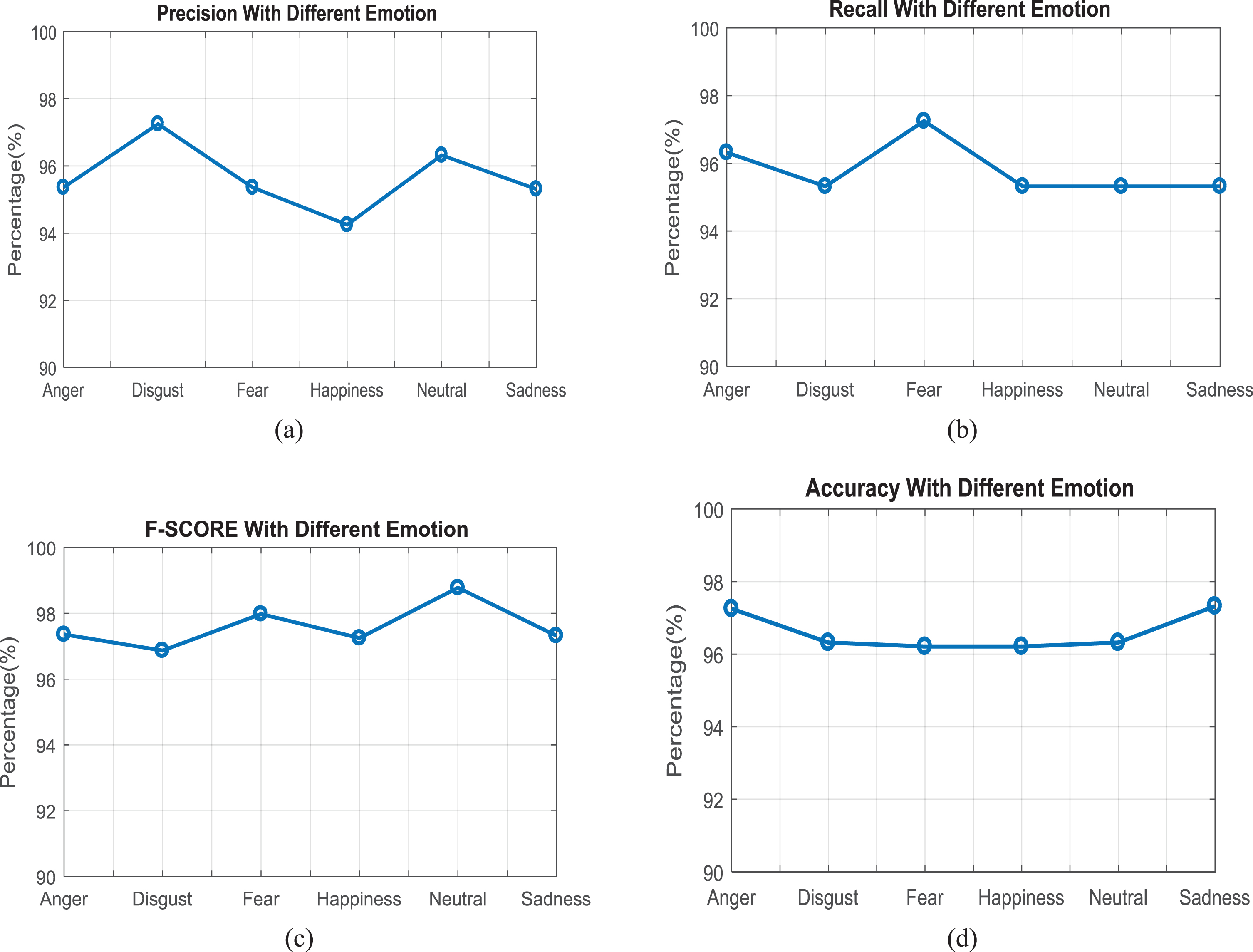
Various Emotions with (a) Precision; (b) Recall; (c) F-Measure and (d) Accuracy.
Thus from the above graph, it is clear that the recall value for all emotion has a maximum percentage. In Fig. 14 (c) F-score is being plotted based on the recall and precision value obtained in the previous graphs. If the class distribution is random F-score is more useful when compared to accuracy. In Fig. 14(d) accuracy is being plotted which clearly shows that the proposed method displays the finest accuracy ever. Only if the emotion is not misinterpreted and should be replied quickly the communication is said to be effective. Now it is proved that the accuracy of emotion detection is above 95% using proposed SDCN.
When related to other existing methods the proposed methodology consists of inbuilt deep learning architecture SDCN which automatically filters and pre-process the incoming speech signal and extracts the required features. An innovative idea has been introduced which uses the SVM classifier in the training phase by using the input voice data and decision tree method in the testing phase by using the trained data which have the ability to identify the exact emotion from the speech signal with high accurateness and efficiency. The enhancement of the output is performed using the PSO optimization which boosts the performance of the system. The complexity of the output obtained from the decision tree is completely eradicated by the usage of the whale optimization technique. Thus the optimized output has a precision of 96.94, recall of 97.42 and accuracy of 98.21 hence it is proved that the proposed method is the finest method to recognize the emotions from the voice input data. When comparing the proposed method with existing methods in like CNN and LSTM [41] tabulation is formed which shows that the proposed method has an excellent score under every category.
From Fig. 15, it is very clear that CNN and LSTM have accuracy, precision, F-score and recall values in the range of 80s whereas the proposed method gives the values in the 90s range which reflects that the proposed system has enhanced all the values. CNN which is a class of DNN contains several convolutions and max-pooling layers to a fully connected network [45]. Even though CNN works in the frequency domain to standardize acoustic variations for speech recognition, but the computation cost and time are comparatively greater than the proposed SDCN technique.
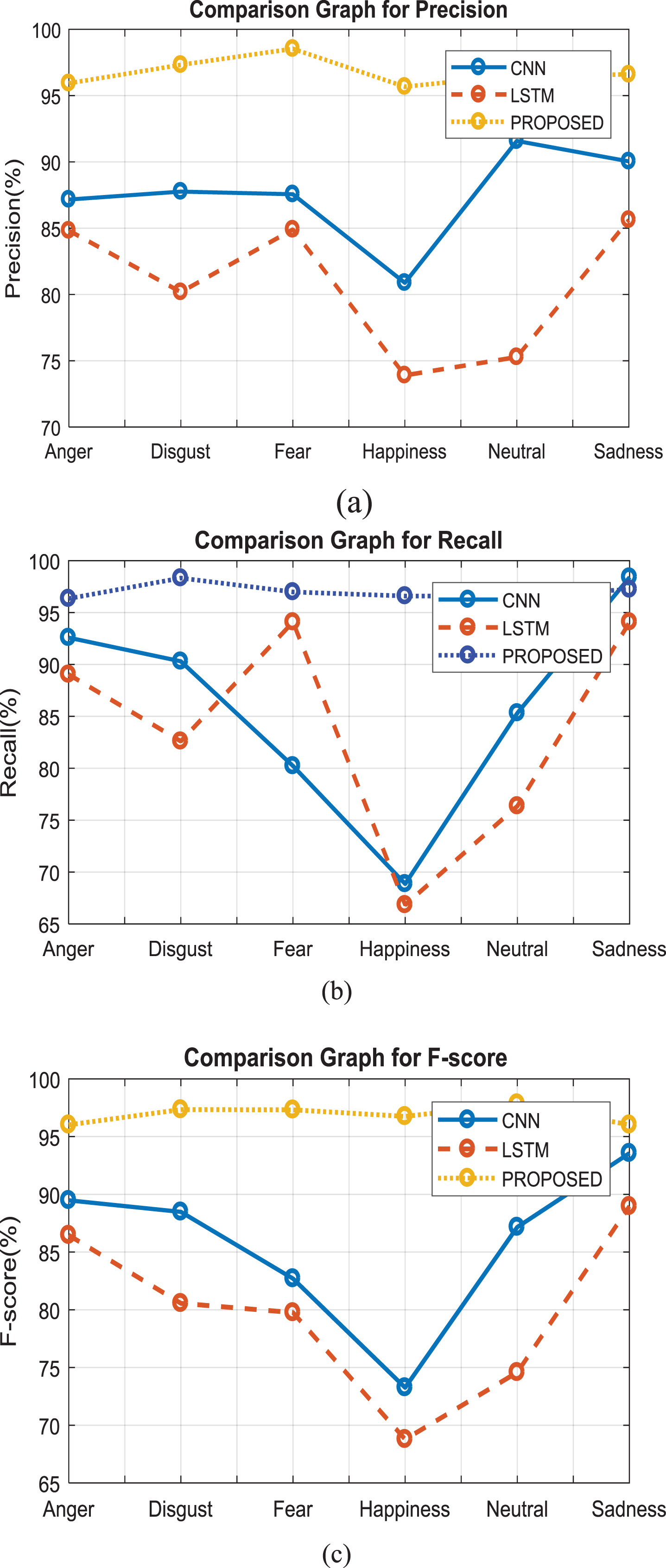
The (a) Precision (b) Recall and (c) F-Score is plotted for various emotions by comparing the proposed method with CNN and LSTM [44].
LSTM is an artificial recurrent neural network (RNN). An LSTM neural network cell comprises of input gate, output gate and forget gate. Even though long time lag problems are being reduced but by the usage of LSTM there is no memory associated with the model so that causes a problem for sequential data, like time series.
The precision determines the closeness of measurement and is independent of accuracy value. The graph given in Fig. 15(a) is plotted between precision percentage and various emotions (anger, disgust, fear, happiness, neutral, sadness) by comparing the proposed methods with CNN and LSTM methods.
The recall value is being plotted for various emotions mentioned. This recall value determines the number of appropriate documentation improved by a hunt segregated by the all-out number of existing significant records. Thus for existing methods, the recall value is comparatively less which is being visibly seen in the below graph plotted for CNN, LSTM and our proposed method-score is being plotted based on the recall and precision value obtained. If the class distribution is random F-score is more useful when compared to accuracy. The F-score plot also proves that the proposed method shows the superlative outcome comparatively.
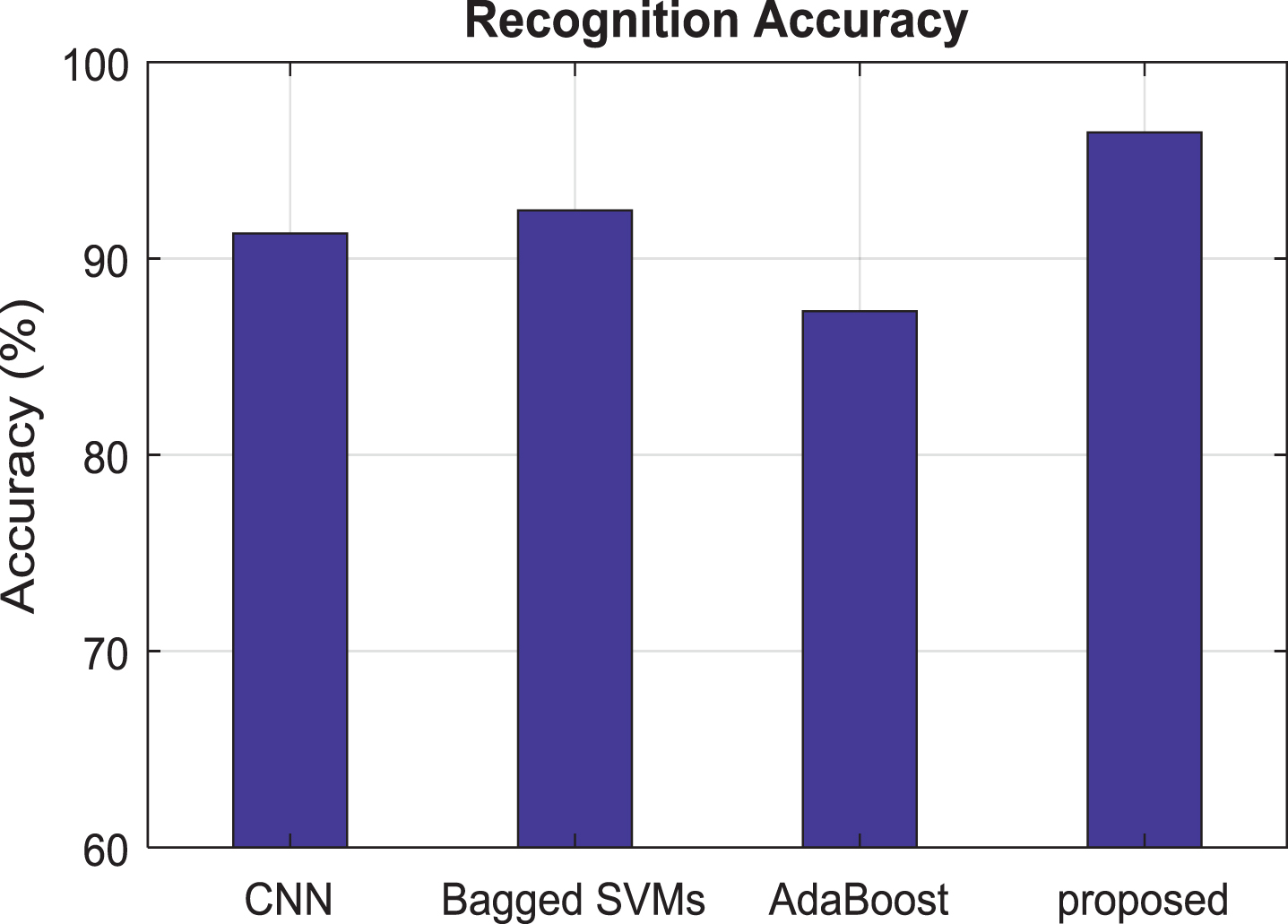
The proposed method is also compared with the bagged ensemble of SVMs [42] and the AdaBoost ensemble of SVMs [43]. Here it is made clear that recognition accuracy is excellent only for the preferred method given in Fig. 16. The bagged ensemble of SVMs was used in classifying problems when single SVMs cannot comfortably manage very large data sets, but the recognition accuracy is less when compared with the proposed novel SDCN. The AdaBoost ensemble of SVMs [44] provides better performance on imbalanced classification problems, but the existing algorithm CNN [45], AdaBoost and bagged SVMs accuracy are very less when comparing it with the proposed method. A communication is said to be effective only if the emotion is recognized quickly, the time of computation must be as less as possible. This requirement is also fulfilled in the proposed method which is being proved in Table 2.
Tabulation to displays the computation rate and recognition rate for various emotions comparing CNN, LSTM and proposed method
The computation rate is the term that indicates the time taken to accomplish the proposed work. Here recognition of emotion is done by the combination of DBN with optimized SVM thus the process finishes with greater accuracy and less computational time. In previous strategies CNN and LSTM only a single classification method is utilized thus it takes more time completion above Table 2 reveals the numerical value and below graphical representation gives the description.
The graph shown in Fig. 17 evidently proves that the computation time for the proposed SDCN system is comparatively very less. When CNN and LSTM are used the time utilized for computation is greater during emotion recognition.
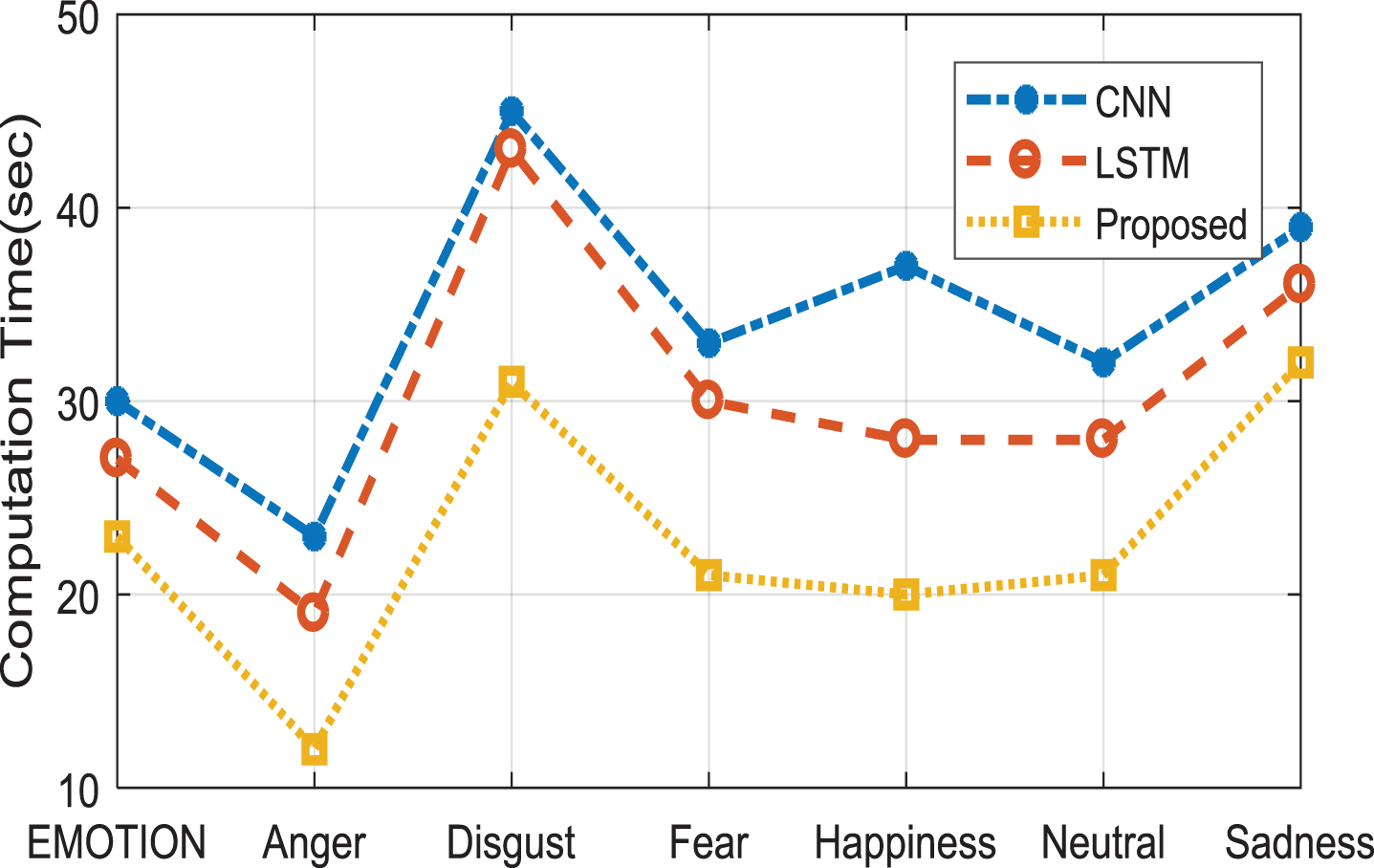
Computation time is plotted for various emotions by comparing CNN, LSTM and proposed a novel SDCN method.
The recognition rate is determined based on the exact and false decisions chosen. It is based on the Equation 7 given below
Recognition rate = (no. of correctly identified voice samples / Total no. of voice samples)*100 (7)
The sum of exact and false decisions chosen is the total number of voice samples. Figure 18 shows the recognition rates for different techniques. Finally from all the obtained graphs and tabulation, it is made clear that the best performance is provided by the proposed system and Table 3 and Table 4 shows the tremendous growth in accuracy when compared to various other methods.
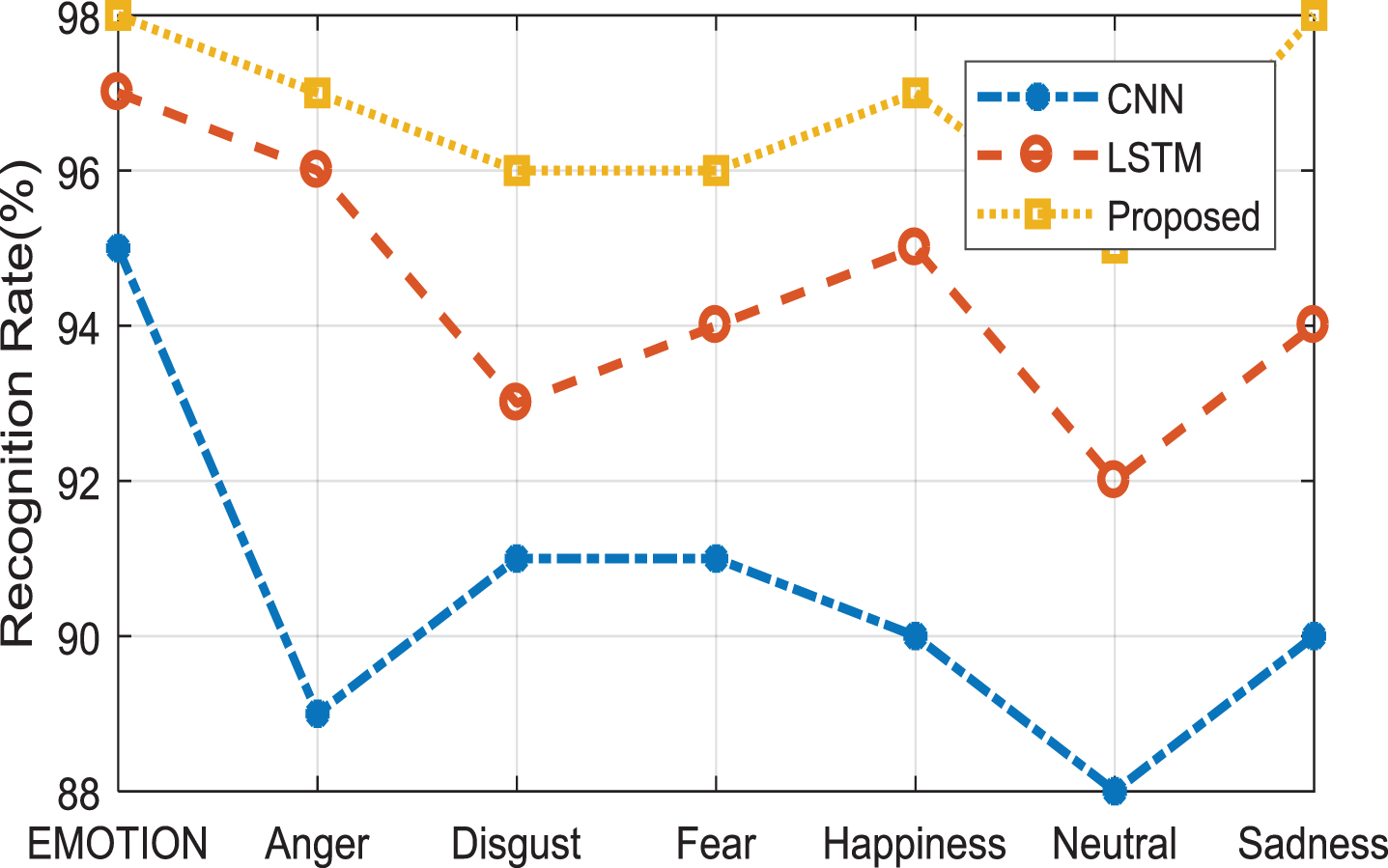
The recognition rate is plotted for various emotions by comparing CNN, LSTM, and proposed novel SDCN method.
Comparison of Accuracy for different emotions using Berlin database
Comparison of Average Accuracy using Berlin database
Figure 19 describes the different emotion to find performance of accuracy of our proposed deep learning and existing work like CNN [39], CNN-RNN [42], and cascading feed forward-back propagation neural network (CF-BPNN) [44] but compared to all the work our proposed work attains the better result. Similarly Fig. 20 shows the performance comparison of accuracy with different classifiers like CF-BPNN [46], Bayesian GMM, SVM with linear kernel, Gaussian mixture model (GMM), extreme learning machine (ELM) [48] our proposed work attain the best level of accuracy compared to all others. The proposed work also shows better results when compared with [49]. So it can be concluded that compared to all other existing work the proposed SDCN is far better to identify the different emotions accurately.
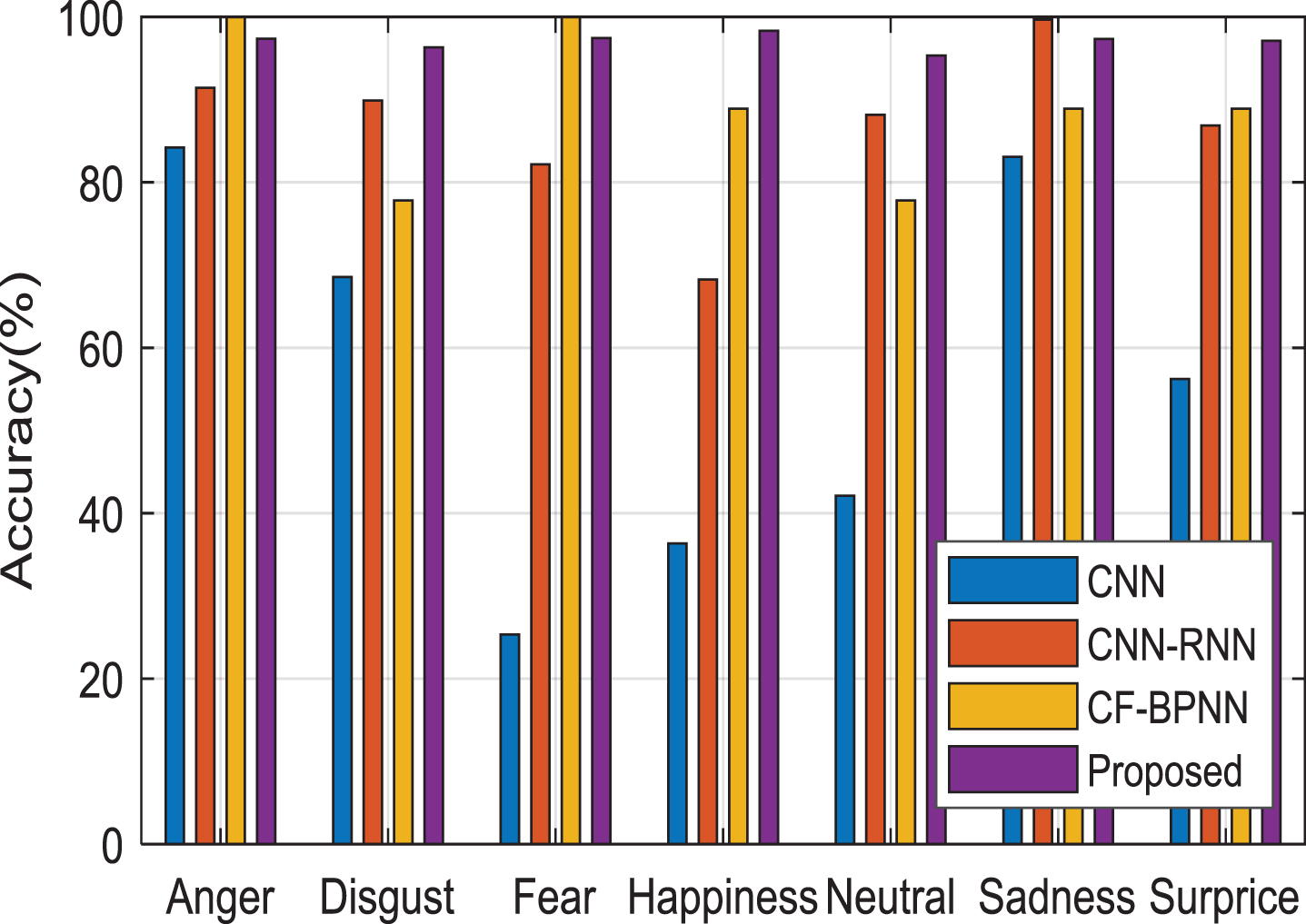
Performance Analysis of Different Emotion Accuracy level with other Deep Architecture.

Performance Analysis of Different emotion Average Accuracy level with other deep Architecture.
This paper proposes a novel SDCN ensemble method to undertake speech emotion identification. Various benefits are obtained using this method. Firstly, since the random subspace is utilized they have the capability to eliminate the dimensionality difficulties. Secondly, when the deep conviction network is applied on random subspaces and larger training database is presented then it has the probable capacity to attain improved performance. Thirdly, the concrete emotion label is being eliminated by the usage of the SVM classifier as the base classifier which results in providing the probability of a testing sample for various emotions. DCN has the capability to handle uncertainty information with the fusion of the used classifier. Finally, DCN also has the capacity to identify complicated emotions from the speech samples. So far in the various paper, the same classification technique is used in both the training and testing phase, but in this paper, different techniques have been proposed because only then the overfitting problem can be reduced and different emotions can be identified from the speech. Thus the accuracy has been improved massively comparatively. Thus in this paper, the proposed SDCN along with various enhancing techniques involved have fulfilled all the requirements to recognize all the emotion of the speech successfully. Finally, we have achieved an accuracy of emotion detection to be above 95% and the recognition rate obtained is about 98% with a computation time of 23 seconds which is not reached so far by any other existing works. Even though the proposed method shows various improved output in speech recognition the diversity of the ensemble is not taken under consideration, which must be stressed to additionally enrich the performance of our approach.