
Abstract
The hesitant fuzzy sets (HFSs) are an extension of the classical fuzzy sets. The membership degree of each element in a hesitant fuzzy set can be a set of possible values in the interval [0,1]. On the other hand, distance and similarity measures are important tools in several applications such as pattern recognition, clustering, medical diagnosis, etc. Hence, numerous studies have focused on investigating distance and similarity measures for HFSs. In this paper, some improved distance and similarity measures are introduced for the HFSs, considering the variation range as a hesitance degree for these sets. Comparing the proposed measures to some available distance and similarity measures indicated the better results of the proposed measures. Finally, the application of the proposed measures was investigated in the clustering.
Introduction
After the introduction of fuzzy sets by Zadeh [25], these sets attracted the attention of many researchers, and numerous extensions were introduced. For example, Zadeh [26] introduced the type-2 fuzzy sets and interval-valued fuzzy sets (IVFSs). Dubois and Prade [8] introduced type-n fuzzy sets. Atanassov [3] introduced intuitionistic fuzzy sets (IFSs). Recently, it has also been noted that humans are usually hesitant to make decisions. As an example, suppose two decision-makers who should determine the membership degree of a member like x in a set like A. If one of the decision-makers assigns the value of 0.3 while another assigns the value of 0.5, we are facing a set of membership degrees rather than one membership degree. Torra and Narukawa [18] and Torra [17] introduced the concept of hesitant fuzzy sets (HFSs) to overcome this problem. After the introduction of HFSs, these sets attracted the attention of many researchers. For example, Zhu et al. [30] introduced the dual hesitant fuzzy sets (DHFSs), which in a specific case includes fuzzy sets, intuitionistic fuzzy sets, hesitant fuzzy sets, and fuzzy multisets. Chen et al. [4] propose proportional hesitant fuzzy linguistic term sets, which include the proportional information of each generalized linguistic term. Wan et al. [19] develop a new hesitant fuzzy mathematical programming method for hybrid multi-criteria group decision making (MCGDM) with hesitant fuzzy truth degrees and incomplete criteria weight information. Chen et al. [6] develop a novel two-stage aggregation paradigm for hesitant fuzzy linguistic term set possibility distributions. Sajjad Ali Khan et al. [14] proposed a novel approach based on TOPSIS method and the maximizing deviation method for solving multi-attribute decision-making problems where the evaluation information provided by the decision-makers (DMs) is expressed in the form of Pythagorean hesitant fuzzy numbers and the information about attribute weights is incomplete. Sun et al. [16] construct a novel synthetic grey relational degree by considering both the closeness and the variation tendency factors of the data to improve the existing information measures and enhance the grey relational analysis (GRA) theory for the interval-valued hesitant fuzzy sets. Akram et al. [1] introduced a novel hybrid model called hesitant fuzzy N-soft sets.
Distance and similarity measures are important tools in several applications such as pattern recognition, clustering, medical diagnosis, etc. Thus, a large body of research has focused on introducing distance and similarity measures for fuzzy sets and their extension. For example, Wang [20] introduced two similarity measures for fuzzy sets. Hung and Yang [13] introduced similarity measures for type-2 fuzzy sets. Arefi and Taheri [2] proposed a new method to introduce similarity measure between IVFSs. Grzegorzewski [11] suggested new methods based on the Hausdorff metric to measure the distance between IFSs. Xu and Xia [22] introduced different distance and similarity measures for HFSs. Farhadinia [9] investigated the relationship between entropy, similarity, and distance for HFSs and interval-valued hesitant fuzzy sets. Zeng et al. [27] introduced several new distance and similarity measures for HFSs, considering the hesitance degree for these sets. Yang and Hussain [23] proposed the construction of new distance and similarity measures based on the Hausdorff metric for HFSs. Farhadinia and Xu [10] reported the concept of metrical T-norm-based similarity measure for HFSs. They discussed the relationship between the proposed metrical T-norm-based similarity measure and the other type of information measure, known as the metrical T-norm-based entropy measure. Yong et al. [24] proposed a Jaccard similarity measure between cubic hesitant fuzzy sets and investigates their properties. Chen et al. [5] develop a novel hybrid multi-criteria group decision-making model for sustainable building material selection under uncertainty which needs accurate distance measures. Hu et al. [12] propose axiom definitions of the distance measure and the possibility degree of hesitant interval-valued fuzzy sets and generate a series of distance measure models, similarity models, and possibility degree models.
The motivations of this paper: As will be shown in this paper, some of the distance and similarity measures introduced for hesitant fuzzy sets may not be logical in some cases, also is noted that the definition of hesitance degree for hesitant fuzzy sets based solely on the number of membership degrees, may be inadequate. These motivated the paper to introduce improved and new distance and similarity measures for these sets, which will lead to better results for various applications. Therefore, in this paper, by introducing a new hesitance degree for these sets, new distance and similarity measures are proposed for HFSs.
This paper is organized as follows: The required definitions are presented in Section 2. In Section 3, the new distance and similarity measures are proposed for HFSs. In Section 4, the application of the proposed measures in clustering is presented. Finally, Section 5 discusses the conclusion.
Preliminaries
This section will provide the basic definitions needed for other sections. In these definitions, X = {x1, x2, …, x n } is assumed to be a universal set.
In [21] for conveniences, the hesitant fuzzy set H on X is shown as the following mathematical symbol:
Where h H (x) is a set of possible membership degrees of the element x ∈ X in the set H, and h = h H (x) is called a hesitant fuzzy element (HFE).
0 ≤ d (H1, H2) ≤1 d (H1, H2) =0 iff H1 = H2 d (H1, H2) = d (H2, H1)
0 ≤ s (H1, H2) ≤1 s (H1, H2) =1 iff H1 = H2 s (H1, H2) = s (H2, H1)
It should be noted that the number of membership degrees may be different in different hesitant fuzzy elements. As an example, let h1 and h2 be two HFEs on the universal set X, it may be l (h1 (x)) ≠ l (h2 (x)) for x ∈ X. To have an appropriate performance, the HFE with a fewer number of membership degree is extended until the number of membership degrees of two HFEs becomes equal. Also, the membership degrees of a HFE should be ordered. In this paper, the HFE with a fewer number of membership degree is extended by adding the largest membership degree, and the membership degrees of a HFE are ordered in descending order.
In [28], by defining a hesitancy index (ℏ) for hesitant fuzzy sets, two kinds of new ordering methods for these sets are introduced as follows:
The strict component-wise ordering of HFSs: H1 ≤ H2 iff The strict total ordering of HFSs: H1 ⪯ H2 iff score (H1) < score (H2) or score (H1) = score (H2) and ℏ (H2) ≤ ℏ (H1)
where
assuming that H1, H2 and H3 be three HFSs on X, it is stated in [28] that the distance measure for hesitant fuzzy sets should satisfy the following property: if H1 ≤ H2 ≤ H3, then d (H1, H2) ≤ d (H1, H3) and d (H2, H3) ≤ d (H1, H3) if H1 ≤ H2 ≤ H3, then s (H1, H2) ≥ s (H1, H3) and s (H2, H3) ≥ s (H1, H3)
The above property for the similarity measure between the hesitant fuzzy sets is also stated as follows [28]:
Xu and Xia [22] have introduced various distance measures for hesitant fuzzy sets. Assuming that H1 and H2 be two hesitant fuzzy sets on the universal set X, based on the well-known Hamming distance and the Euclidean distance, they proposed the hesitant normalized Hamming distance, the hesitant normalized Euclidean distance and the generalized hesitant normalized distance in the form of Eqs. (2), (3) and (4), respectively.
Also, in [22], the hesitant normalized Hamming-Hausdorff distance, normalized Euclidean-Hausdorff distance, hybrid hesitant normalized Hamming distance, and hybrid hesitant normalized Euclidean distance are presented as Eqs. (5), (6), (7), and (8), respectively.
Considering the above definition, several distance and similarity measures are introduced in [27].
While the proposed measures in [27] overcome the problem of ignoring the number of membership degrees in HFEs, it can be demonstrated that considering the hesitance degree only based on the number of membership degrees may be inadequate. The following example shows a condition when the defined measures in [27] do not provide reasonable results.
As shown in Table 1, it is not possible to recognize that the sample h belongs to which of the patterns h1 and h2 by using the distance measures (2), (3), (4), (5), (6), (7), and (8). Furthermore, the sample h belongs to the pattern h2 by using the distance measures (10), (11), and (12). However, it is not concluded that the hesitance degree in these sets depends only on the number of their membership degrees. As shown, the membership degrees in the HFS h1 are close, and it may be concluded that the decision-maker has less hesitation when assigning these membership degrees. On the other hand, the available membership degrees in the HFS h2 are more diverse with a greater distance, which reflects the greater hesitation. Hence, it is not reasonable to consider only the number of membership degrees as a hesitance degree and, consequently assign the sample h to the pattern h2.
To overcome the above problem, this paper defines a new hesitance degree for hesitant fuzzy sets.
As indicated by definition mentioned above, if the decision-maker assigns membership degrees with great distances to an element like x i , r will have a greater value which seems reasonable since the greater distance among the membership degrees indicates the greater hesitation of the decision-maker. Similar to Definition 2, the following definition is considered for ordering hesitant fuzzy sets in this paper.
The strict component-wise ordering of HFSs: H1 ≤ H2 iff The strict total ordering of HFSs: H1 ⪯ H2 iff score (H1) < score (H2) or score (H1) = score (H2) and r (H2) ≤ r (H1)
Hence, considering r as a new hesitance degree for HFSs, this paper proposes the following new distance and similarity measures for these sets.
According to Remark 2.1, the following new similarity measures for hesitant fuzzy sets H1 and H2 on the universal set X can be defined:
(D1) For x i ∈ X, i = 1, 2, …, n, j = 1, 2, …, l x i :
0 ≤ |r (h
H
1
(x
i
)) - r (h
H
2
(x
i
)) |
λ
≤ 1, 0 ≤ |u (h
H
1
(x
i
)) - u (h
H
2
(x
i
)) |
λ
≤ 1,
(D2) if d
nghn
(H1, H2) =0 then for x
i
∈ X, i = 1, 2, …, n, j = 1, 2, …, l
x
i
:
(D3)
(D4) if H1 ≤ H2 ≤ H3 with the same length, then for x
i
∈ X, i = 1, 2, …, n, j = 1, 2, …, l
x
i
according to Definition 3.2 that
Usually, in real applications, different members x
i
, (i = 1, 2, …, n) of the universal set have different important degrees. Therefore, weighted distance measures for these sets should also be defined. Assuming w
i
, (i = 1, 2, …, n) is the weight of x
i
∈ X where 0 ≤ w
i
≤ 1 and
If there are different preferences between the hesitance degrees u and r and the difference of membership degrees, the new distance measures are defined as follows.
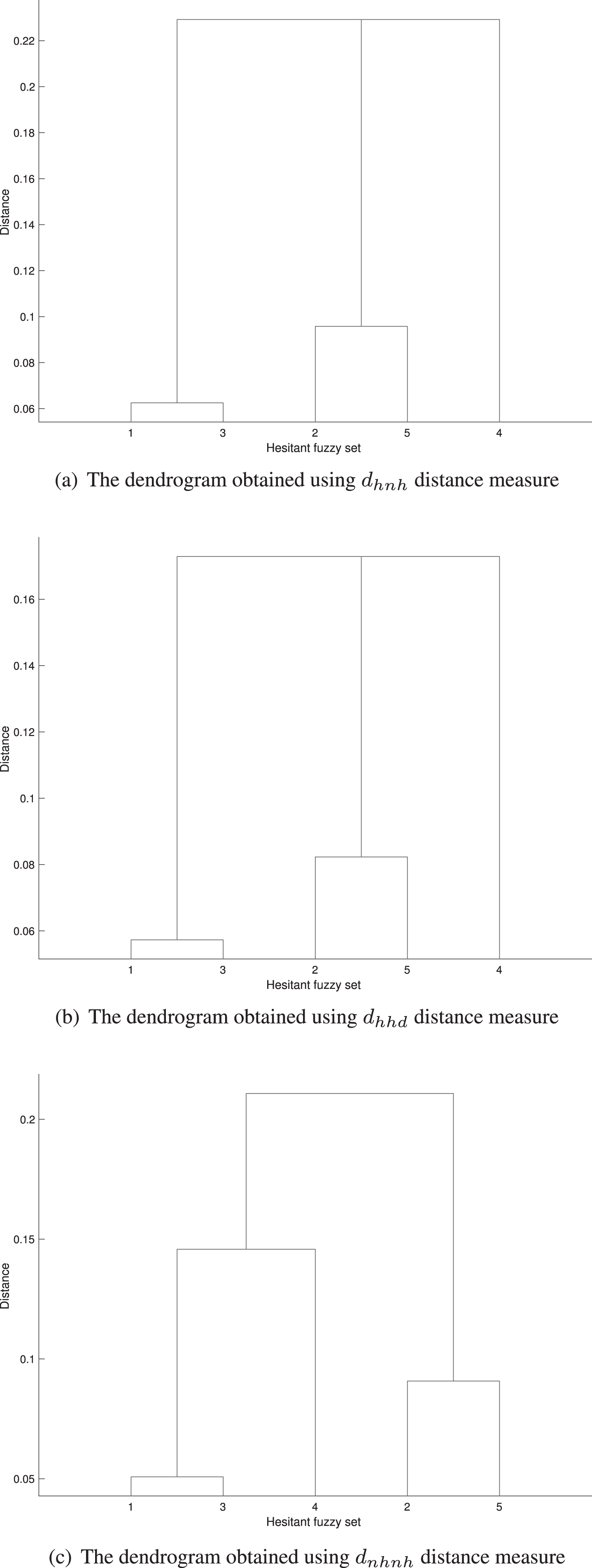
The clustering dendrograms.
Also, considering the different weights for the members of the universal set as well as the different preferences for the hesitance degrees and the difference of membership degrees, the new distance measures can be considered as follows.
Data clustering is considered as one of the important methods of data analysis. Hence, recently, uncertain data clustering, such as hesitant fuzzy data, has attracted a lot of researchers’ attention [7, 29]. Since distance and similarity measures have significant effects on data clustering, in this paper, the proposed measures are used for the clustering of several energy projects to show their application. The idea of considering these projects for clustering was obtained from [22].
The single linkage hierarchical clustering algorithm [15] is used to cluster the data. Supposing that HFSs H1, H2, … H m over the universal set X are hesitant fuzzy data to be clustered, each set is considered as a cluster firstly. Next, by calculating the distance matrix D = [d ij ] m×m whose element d ij represents the distance between the clusters C i and C j , two closest clusters are merged in each step. This process continues until all data is placed in one cluster. It should be noted that the distance between the clusters C i and C j is calculated using Equation (30).
Collected comments for five energy projects
To compare the performance of the aforementioned distance measures, clustering has been done using distance measures d hnh , d hhd , and d nhnh , and the results are shown in Tables 4, 5, and 6, respectively. As can be seen from the results, the distance measures d hnh and d hhd are not able to provide an accurate clustering, given the number of clusters equal to 2. But if the proposed distance measure d nhnh is used, the projects are precisely clustered, taking into account the number of clusters equal to 2. Figure 1 shows the dendrograms corresponding to the clustering results.
Clustering results using d hnh
Clustering results using d hhd
Clustering results using d nhnh
In order to make more comparisons, the clustering algorithm introduced in [28] has also been used to clustering the energy projects using similarity measures s hnh = 1 - d hnh , s hhd = 1 - d hhd , and s nhnh = 1 - d nhnh . The clustering results are presented in Tables 7, 8, and 9, respectively. As can be seen, the clustering method was not able to produce two clusters using the s hnh and s hhd similarity measures but, by using the s nhnh similarity measure, clustering with two clusters will be obtained accurately.
Clustering results using the clustering algorithm introduced in [28] and s hnh
Clustering results using the clustering algorithm introduced in [28] and s hhd
Clustering results using the clustering algorithm introduced in [28] and s nhnh
In this paper, new and various distance and similarity measures were proposed for HFSs by introducing a new hesitance degree for these sets. It was shown that the proposed measures could provide more reasonable results in pattern recognition than some available distance measures. Furthermore, the proposed measures were used for the clustering of several energy projects to show their application. The comparison of clustering results from the proposed measures with those of using some available measures indicated that the use of the proposed measures in clustering leads to more accurate clustering. Researchers can focus on adjusting preference parameters for the hesitance degrees and distance between membership degrees, in addition to adjusting weight values in the proposed distance and similarity measures for future works.