
Abstract
The development in science and technical intelligence has incited to represent an extensive amount ofdata from various fields of agriculture. Therefore an objective rises up for the examination of the available data and integrating with processes like crop enhancement, yield prediction, examination of plant infections etc. Machine learning has up surged with tremendous processing techniques to perceive new contingencies in the multi-disciplinary agrarian advancements. In this pa- per a novel hybrid regression algorithm, reinforced extreme gradient boosting is proposed which displays essentially improved execution over traditional machine learning algorithms like artificial neural networks, deep Q-Network, gradient boosting, ran- dom forest and decision tree. Extreme gradient boosting constructs new models, which are essentially, decision trees learning from the mistakes of their predecessors by optimizing the gradient descent loss function. The proposed hybrid model performs reinforcement learning at every node during the node splitting process of the decision tree construction. This leads to effective utilizationofthesamplesbyselectingtheappropriatesplitattributeforenhancedperformance. Model’sperformanceisevaluated by means of Mean Square Error, Root Mean Square Error, Mean Absolute Error, and Coefficient of Determination. To assure a fair assessment of the results, the model assessment is performed on both training and test dataset. The regression diagnostic plots from residuals and the results obtained evidently delineates the fact that proposed hybrid approach performs better with reduced error measure and improved accuracy of 94.15% over the other machine learning algorithms. Also the performance of probability density function for the proposed model delineates that, it can preserve the actual distributional characteristics of the original crop yield data more approximately when compared to the other experimented machine learning models.
Keywords
Introduction
On all accounts of learning and perception, individuals have developed an enormous framework of data that empowers them to understand and foresee fluctuating natural incongruity. Machine learning, an articulation of the more extensive field artificial intelligence and a prompt successor of statistical modeling utilizes this massive data framework to define the underlying significant information [26]. Exuberant advances in machine learning have evidently in- definite potential results. Machine learning has surged together with huge data advances and better measure implementation that make new opportunities to envision data exhaustive processes in agrarian functional environment [19]. Agriculture essentially being a conventional source of sustenance is a standout amongst the most demanding sectors in a country’s economy. Numerous researchers and experts in current agribusiness are examining their hypothesis at an undeniable predominant scale, in assistance to progressively ac- curate and reliable forecast [16, 24]. Existing agrarian frameworks can explore necessarily more machine learning methods to utilize upgrades and essentiality more productively, conforming to various environ- mental changes. In the agrarian development machine learning enhances crop administration that aids in forecasting crop yields [39], management of crop disease [22, 44], plant weed recognition [31, 35], affirmation of plant arrangements [2, 3], management of soil characteristics [18], estimation of agro-climate and rain- fall [1, 9], monitoring ground water characteristics [5], etc.
Machine learning algorithms are broadly classified as supervised, unsupervised and semi supervised depending on the training dataset. Supervised learning incorporates analysis on a pre-characterized arrangement of training models. Unsupervised learning doesn’t comprise of pre-trained data but are generally dependant with finding associations inside information [25]. Further more to the above mentioned machine learning approaches another class of machine learning approach is characterized as reinforcement learning [45]. Reinforcement learning resembles the performance of an intelligent agent that describes in achieving a task with an increasingly rewarding action. This ensures in constructing a better non-linear frame- work with a robust performance. Machine learning algorithms sustain near or even improved potential in contrary to traditional statistics in expressing the linear or non-linear relations for the agricultural frameworks, and in addition has imperative predicting capability.
Initially at the start of every cropping season, agrarian coordinators require evaluating the yield for arduous crops. Predicting the crop yield is critical since it depends on different associated factors like climate, soil, ground water, manures and pests, rotation of crops, irrigation system, etc. In addition crop yield also varies transiently and spatially with a non-linear aspect manifesting huge variation every year. The advantage of machine learning advancement for agronomical applications is that they are sufficiently precise, non-destructive and yield enduring results. Gradient boosting is a supervised machine learning algorithm for regression and classification based problems, which delivers a better forecast model from an ensemble of weak predicting models [15]. The algorithmic optimizations are performed in function space rather than parameter space, making simple use of custom loss function. Boosting concentrates gradually at every step on crucial precedents providing a decent strategy to manage unbalanced datasets by reinforcing the effect of positive class. In comparison to a single machine learning framework a hybrid approach of associating two or more approaches to attain better execution model is still under research. Endorsing this approach for study, a hybrid model accommodating the functionality of the extreme gradient boosting (XGBoost) algorithm with reinforcement learning is analyzed.
In this paper, a new hybrid forecasting machine learning algorithm based on extreme gradient boosting and reinforcement learning is constructed to strengthen the crop yield forecasting accuracy with rewarding iterations. With regards to the ensemble based methods gradient boosting is particularly convincing for the proposed application. Gradient boosting repeatedly develops a group of learners, with an objective that every new learner exerts to address the errors of its forerunners by improving certain differentiable loss function. A reinforcement learning model is imported in the tree construction process to achieve a predominant predictive efficiency of the crop yield prediction model. The rest of the paper is organized as follows. Section 2 presents the review of existing works in literature. Section 3 explains in detail the proposed hybrid reinforced XGBoost crop yield prediction model. Section 4 defines the agrarian dataset and the area considered for study. Section 5 explains the experimental frameworks and outcomes of the proposed hybrid model over other machine learning algorithms. Section 6 wraps up with conclusion and future works.
Related works
Dynamic progress in machine learning have considerably unlimited potential outcomes. Progressively to accomplish new contingencies machine learning has advanced together with enormous information progresses. It has been examined that agriculturist’s revenue rise or fall contingent upon the yields they secure from their harvests. In significance to reinforce the procedure of decision making it is imperative to perceive the well defined existing relationship between the crop yield and numerous factors impacting it [34]. Further- more improved measure prerequisites are in need to regulate, estimate and envision information extensive techniques in agrarian environment [43]. Several examiners and experts in present agribusiness are observing at their hypothesis at dynamically predominant scale, encouraging in achieving progressively exact and reliable prediction. Present day agrarian frameworks can determine significantly more machine learning advances to preserve water resources, utilize enhancements and vitality more considerably and incorporate to substantial environmental transformations.
Forecasting the crop yield is an exceptional process among the most convincing fields in precision agriculture. It is of high relevance for yield mapping, yield assessment, organizing crop market activity and crop agency to improve the effectiveness. Gradient boosting is one of the ensemble based supervised machine learning algorithms providing solutions to numerous agrarian applications. With respect to the application of crop yield prediction [46], gradient boosting algorithm has contributed to the construction of gridded crop models with downscaled spatial temporal approaches [11]. Analysis of the land satellite data to determine the land coverage for cropping [40], urban classification and formulating the essential vegetation indices using the gradient boosting algorithm is attained [41]. Gradient boosting algorithm also contribute to the determination and forecasting of essential climatic parameters assisting for crop yield like solar radiation, precipitation [28], solar irradiance [23] and wind energy [4]. As an intriguing contributor to precision agriculture by enhancing crop yield using the remotely sensed data, the gradient boosting machine learning algorithm has assisted in identifying the essential soil properties like soil organic matter (SOM), cation exchange capacity (CEC), magnesium (Mg), potassium (K), and pH [37]. A decision tree based gradient boosting algorithm has contributed in observing the soil moisture indications over the Tibetan plateau thereby contributing to crop based application in that area [47].
Another propelled machine learning approach is the reinforcement learning algorithms. In agrarian systems till date reinforcement learning has been exposed only to some constrained applications. Reinforcement learning focuses on interactions among the various states of an environment, obtaining result based training that can get familiar with the performance dependant interactions [42]. Some of the prevalent applications of reinforcement learning in agronomy are effective and dynamic resource allocation for superior economic benefits [45]. Construction of intelligent weed map dependant on spatial dissemination of weeds among the crop yields utilizing markov random field reinforcement learning framework [33]. Reinforcement learning also enables to interpret the relative forest quality based on a spatial optimizing agent [14]. Administering the maize crop irrigation scheme depending on dynamic reinforcement algorithm produced persistent outcomes to irrigation professional [8]. Reinforcement learning additionally helps with increasing water assignment for river basins encountering sparse water resource [6].
From the existing literature it is recognized that the hybrid prediction algorithms are limitedly examined, and the predominant techniques have constraints in their processing and assessment criteria. Accordingly a unique hybrid prediction algorithm, contrary to the existing hybrid techniques which incorporates the extreme gradient boosting ensemble algorithm and markov decision based reinforcement algorithm is proposed. Gradient boosting is an ensemble based machine learning algorithm which forms a group of weak learner to produce a strong base learner. Reinforcement learning provides a superior optimization framework that can be definitely characterized and conformed. The following section briefs about the proposed hybrid prediction algorithm for the enhanced crop yield prediction.
Proposed methodology
Machine learning has advanced together with enormous information growth and better measure persistence to conceive unique contingencies for agrarian systems by regulating, evaluating and acknowledging data intensive procedures. Constructing a machine learning model for the agrarian based framework is very arduous, since they are extremely eccentric in nature and they maintain a dynamic non-linear behavior. In designing an agrarian framework functional task should be analyzed with persistent description of actions; and the system’s execution should be adequately compelling to embrace continually dynamic activities.
Among the ensemble based algorithms gradient boosting is exceptionally compelling to the proposed work. Gradient boosting iteratively constructs an ensemble of learners, essentially decision trees, so that each new learner endeavors to correct the errors of its predecessors, enhancing some differentiable loss function. To accomplish a superior prognostic performance for the crop yield prediction model, reinforcement based learning model is introduced in the extreme gradient boosting ensemble machine learning algorithm. Reinforced extreme gradient boosting is a hybrid tree based model that delineates a basically improved execution over the existing machine learning models. The proposed hybrid model implements reinforcement learning at each variable split selection of decision tree, which are the learners of the boosting algorithm. This empowers the trees constructed to handle the accessible information samples in an increasingly improved manner. In the forthcoming sections the extreme gradient boosting and random forest algorithms are explained in de-tailed followed bythe proposed hybrid prediction model.
Extreme gradient boosting (XGBoost) algorithm
In XGBoost stands for “eXtreme Gradient Boosting”, and was introduced by TianqiChen. XGBoost implements the gradient boosting decision tree algorithm [21]. Boosting is an ensemble based procedure where the new models are added to address the errors made by the existing models. In boosting techniques the selection of subsamples are made more intelligently by adding weights to the misclassified observations or errors. Gradient boosting is a methodology where the new models are made that predict the errors or residuals of earlier models and are then included together to make the final prediction. It is called gradient boosting for the reason that it utilizes the gradient descendant algorithm [12] to reduce the loss while including new models. This methodology supports both regression and classification predictive modeling problems. The statistical architecture gives boosting a role as a numerical optimization problem where the motivation is minimize the loss of the model by including weak learners utilizing a gradient descendant procedure. The XG Boost concentrates on the following three elements during the tree construction: Loss function optimization Enabling a weak learner to make predictions An additive model to add weak learners to reduce the loss function
The XGBoost algorithm fits the ensemble models of the type as in Equation (1)
Here g0 (x) is the initial guess, θm is the weight for the ‘m’th estimator, φm (x) is the base estimators of the ‘m’th iteration. The product of weight and the base estimator θmφm (x) is defined as a “step” at the ‘m’th iteration.
The boosting algorithm to be solved by the XGBoost using the gradient descent for each iteration can be viewed as follows in Equation (2)
Here g(m-1) represents the current estimation. In this way the ensemble problem is improved greedily as a forward stagewise additive model. The ensembles are not optimized in a global manner, but rather enhance the outcome dependant on the current estimate as shown in Equation (3). At each iteration a regression tree model is fitted to forecast the negative gradient. Generally the squared error is utilized as a surrogate loss.
XGBoost is faster on comparison to the normal gradient boosting because for gradient boosting the weights are generally the aggregate of the gradients. While for XGBoost it is the sum of the gradients scaled by the sum of the hessians. This results in faster execution of XGBoost eliminating the necessity for line search as in gradient boosting. XGBoost also enhances more randomization using sub sampling for optimum results.
Reinforcement learning is an intriguing classification of machine learning algorithms, where an agent in an environment learns to act bcarrying out rewarding actions. The actions are performed successively that is, the outcome depends on the contribution of the current state. For this procedure of study a Markov decision process (MDP) is characterized that sustains the compliance for embracing the reinforcement learning problems. MDP is a tuple (S, A, Psa, D, R) which represents set of all possible states (S) of the agent; set of all possible actions (A) an agent can engage into; the state transition probability (Psa) from one state to another by an agent; a discount factor (D) which includes value from 0 to 1; and a reward function (R).
For every state a policy π is defined which determines the action the agent performs. The policy is generally a function mapping the states and the actions of an agent. For a given stateaction pair (s, a) the value Vπ (s, a) is an analogy of the expected future reward. The value function [20] satisfying the Bellman equations and is given in Equation (4).
The reward R is discounted by a discount factor γ. An agent’s goal or objective is to identify an optimal policy π* as shown in Equation (5), that expands the sum of the discounted rewards amid the agent’s life time.
The value function that is obtained using the optimal policy forms the optimal value function as defined in Equation (6).
In reinforcement learning to accomplish the best result, the expected cumulative reward should be augmented.
The proposed reinforced XGBoost prediction algorithm is a predominant extreme gradient boosting of decision trees with uniquely selected split variables. So as to recognize the most significant variable at any internal node, formerly introduce the XGBoost and appropriate the importance measures for all the cofactors. Further utilizing the essential variables the nodes are split. While executing this recursively in every daughter node of the tree, the variables are chosen which prompts to a tree that is adaptable to a minimum prediction error in the more extended run. The splitting of nodes continues until the samples obtained are meeting the stopping criterion and the gradient descent loss function for the tree models are minimized. The proposed hybrid prediction algorithm framework is presented in Fig. 1.

Framework of proposed hybrid Reinforced XGBoost prediction model.
XGBoost performs based on the boosting technique; where the trees are build sequentially aiming to reduce the errors of the previous trees. Boosting comprises of the following steps: Defining an initial model M0 to predict the target variable y associated with a residual (y-M0) From the residuals of the previous step a new model r1 is fit. A boosted version of M0 which is M1 is produced by combining M0 and r1, resulting in an lower error than M0.
When generalizing to m iterations Equation (7) can be rewritten as follows:
While constructing the loss function a gradient descendant algorithm is considered which enables to minimize any differential function. The average gradient component for every node is computed. For each node in considering the split the discount factor γ is multiplied with the residual accounting for the difference in the impact of every branch split. XGBoost assists in predicting an optimal gradient for every additive model. The following algorithm summarizes the reinforced XGBoost prediction algorithm.
Algorithm 1: Reinforced XGBoost Model
The proposed approach ensures using the most significant variables for constructing the trees subsequently providing better prediction. The following sections briefs about the dataset utilized for the proposed method and the area under which the study is carried out.
The data required for this examination is procured from the various village blocks of the Vellore district in the state of Tamil Nadu, India. The blocks of the Vellore district considered for the study include Ponnai, Arcot, Sholinghur, Ammur, Thimiri, and Kalavai. The paddy crop is considered for the examination of yield. Paddy being one of the dominant financial crops developed in this region therefore, this district is considered for analysis. In differing to the regular climatic and soil parameters, the dataset includes distinctive climate, soil, groundwater properties together with the fertilizer volume devoured by crops of the study area. Some of the parameters explored in the present study like evapotranspiration, ground frost frequency, aquifer characteristics, wet day frequency and groundwater nutrients are not recognized in the prior works existing in the literature. The data is taken for a period length of 30 years. Figure 2 presents a snapshot of few of the 37 dataset parameters of the actual paddy crop dataset used for the current study. The dataset contains paddy yield in terms of area cultivated (in hectares), paddy production (in tons) and yield acquired (in kg/hectare). The information pertinent to climatic components like precipitation, temperature, potential evapotranspiration, reference crop evapotranspiration and distinctive climatic parameters like ground frost frequency, diurnal temperature range, humidity, wind speed has been used which is acquired from the Indian water portal ‘metdata’ tool. The soil and groundwater properties comprises of soil PH, topsoil density, measure of the soil macronutrients (Nitrogen, Phosphorus a Potassium) present and the distinctive hydro-chemical properties of groundwater like aquifer type, transmissivity, permeability, electrical conductivity, pre-monsoon and post-monsoon micro-nutrients (sodium, magnesium and chloride) content in groundwater. Table 1 presents concise information about the different parameters utilized in the examination.

Snapshot of few crop dataset parameters used for constructing the yield prediction models.
List of dataset parameters and their description
All these data parameters together form a productive dataset that aspires in enhancing the crop yield prediction, by achieving better precision over the conventional methodologies. The following section briefs the experimental results attained by the proposed approach and the other machine learning algorithms.
Machine learning algorithms demand a permissible portion of information for efficient data processing. Information with consistent attributes streamlines the effort of finding regularities by eliminating the redundant features with respect to the learning objective. The viability of a learning model is constrained by evaluating the model distinctive execution measures or by examining the performance by various assessment measures. This section briefs about the experimental outcomes attained utilizing the proposed approach and the other existing machine learning algorithms.
During the advancement of machine learning models, the dataset is arbitrarily split into training set and test set, where the prevalent measure of information is taken for training. Despite the fact that the test dataset is small, there exists a possibility of overlooking certain significant data that may have enhanced the model. This may likewise brings about a high variance in the dataset. To regulate this problem, k-fold cross validation is used. It is a strategy that is utilized to evaluate the machine learning models by reassessing the training data for enhancing the performance. Randomly portioning a time series data for cross-validation results in temporal dependency as there prevails a constant dependence on past observation. At the same time a leakage from the response variable to lag variable will occur undoubtedly, leading to a non-stationarity in the information space. In order to overcome this forward chaining cross validation is performed. For the proposed reinforced extreme gradient boosting model, five-fold forward chaining cross validation is enforced. It starts with a small subset of data for training, predict for the following data and determining the efficiency of the predicted data. The same predicted data are confined as a segment for the following training subset and its consecutive data points are predicted. This results in contriving an increasingly precise model, where the model is constructed on past information and predicts the onward information. The results of five-fold forward chaining cross validation are tabulated in Table 2.
Results of 5- fold forward chaining cross-validation for the Reinforced XGBoost model
Results of 5- fold forward chaining cross-validation for the Reinforced XGBoost model
Pre-processing of the dataset is carried out using the min-max scaling technique which normalizes the information. The whole information is partitioned into five subsets and then administered to training and testing with a test size of 0.25. The model is prepared all through the five-fold forward chaining cross validation process and the error metric is characterized. The determined error metric is the R2 score, which is delineated in every iteration and achieves the best value depicting the principal model efficiency.
The proposed model stability is defined by examining the model against different execution measures or definite evaluation measures. The empirical system which consolidates the enhance execution over the other machine learning algorithms and linear regression models. Generally decision trees produce lower bias and are likely to over-fit. Therefore ensemble procedures of running numerous trees are sufficient for pertinent predictions. Gradient boosting repeatedly develops an ensemble of learners, basically decision trees, with a goal that each new tree tries to address the mistakes of its predecessors, improving some differentiable loss function. Reinforced extreme gradient boosting is a hybrid tree based model that portrays an essentially improved execution over the current machine learning models. The proposed model enforces reinforcement learning at every variable split of the decision tree, which is the learner of the boosting algorithm. This engages the trees built to deal with open datasets in an undeniably improved way. The expected output is acquired by collecting the sum of the gradients scaled by the sum of the hessians. The proposed technique efficiently reduces both bias and variance. As larger number of trees may decrease the variance the number of trees is chosen depending on the precision function enforced by the computation time. Here the number of trees is chosen as 500 and the number of randomly chosen feature at each node is selected as 20. Contingent upon the idea of pruning that can fix potential over fitting, it is observed that above the sufficient number of nodes the efficiency prevailed to be the same prompting faster calculations. Hence the maximum depth of the tree is expanded up to 10 nodes. The learning rate is set to 0.1 and the least squares regression loss function is implemented for the tree construction. With this parameter framework, the proposed model resulted in an R2 value of 0.88 and an accuracy of 94.15%.
The proposed reinforced extreme gradient boosting model is examined and tested with five other substantial and significant machine learning algorithms like decision tree, random forest, gradient boosting, artificial neural networks and deep Q-network. For the construction of the feed forward propagation artificial neural network an input layer of 37 neurons representing the crop dataset parameters, a single hidden layer with 15 neurons and an output layer with one neuron representing the crop yield value is constructed. A sigmoid activation function is used to introduce non linearity in the neuron output for better non linear representations. The weights of the neural networks are assigned randomly. The crop model developed with artificial neural network resulted in a model accuracy of 91.5%. A convincing aspect of the assessment metrics is their capacity to segregate between the results of various learning models. The various assessment metrics considered for the proposed work are Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE) and Determination Coefficient (R2).
Mean Squared Error is one of the most frequently used regression loss function. It is the total sum ofthe squared distance between the predicted and the target variables. It is a risk function with respect to the determined value of squared error. The randomness of the MSE makes it to almost remain strictly positive. Since the model developed is a regression model, the linear regression line equation considered is given in Equation (9).
Here m is the slope and c is the intercept. After the identification of the optimal parameters the result is assessed using MSE. The minimum the MSE value the better the model performance. The formula for MSE is defined in Equation (10).
Here yi is the predicted value and
Differentiating Equation (12) with respect to m and b is defined in Equations (13) and (14).
To attain better execution results the MSE should to maintained as minimum as possible which results in the tuning of the slope and intercept parameters of the regression equation.
Root Mean squared error is an intermittently used measure to observe the difference between the actual value and the value predicted by a model or an estimator. In other words it is just the square root of the mean squared error. RMSE peorms to accumulate the prediction error magnitudes of various time series into a single predictive measure. It is a measure of accuracy to analyze prediction errors of different models for a specific dataset since it is scale dependant. The formula for defining the RMSE is presented in Equation (15).
The RMSE in terms of an estimated parameter θ is defined in Equation (16).
Differentiating Equation (16) partially with respect to θ to observe the performance of the individual parameter is defined in Equation (17).
Mean Absolute Error is a loss function that is utilized for regression models. It is the sum of the absolute differences between the predicted and the target variables. Hence it determines the average degree of the errors in a group of predictions without taking into account the directions of predictions. Its value ranges from 0 to ∞. The MAE is described as follows in Equation (18).
As described it is the arithmetic average of the absolute error
The probability distribution of R exists such that ‘mn’ is a median of R iff ‘mn’ is the reducer of MAE with respect to R. To be more specific ‘mn’ is a reference median iff ‘mn’ reduces the average mean of the absolute deviations. This median is defined as the multivariate or spatial median and is defined in Equation (20).
This optimization of the median of the MAE is utilized for statistical data analysis.
The coefficient of determination is an evaluation metric used to assess a model and is closely analogous to correlation coefficient. It is the ratio of thevariance of the dependant variable which is predicted from the independent variable. It is ud to analyze how the differences in one variable can be defined by the differences in another variable. It possesses an advantage of being scale free and defines the value between 0 and 1. The formula to determine the coefficient of determination is defined in Equation (21).
To assure fair assessment of the results, the estimation is performed on both training and test set. Accordingly two sets of these six models were built to analyze the predicting accuracy. Table 3 defines the performance of the models on both training and test datasets.
Accuracy and evaluation metrics of the proposed Reinforced XGBoost model and other machine learning models
In analyzing the importance of the residual spread, the performance and the accuracy of the model is determined. By means of adaptability and precision, the proposed reinforced XGBoost model outruns other machine learning models with an accuracy of 94.15% and improved error measure. On the other hand the performance of the artificial neural networks and deep-Q learning algorithm are analogously close to the proposed reinforced XGBoost model. Figure 3 explains the experimented model’s performance metric evaluation results.
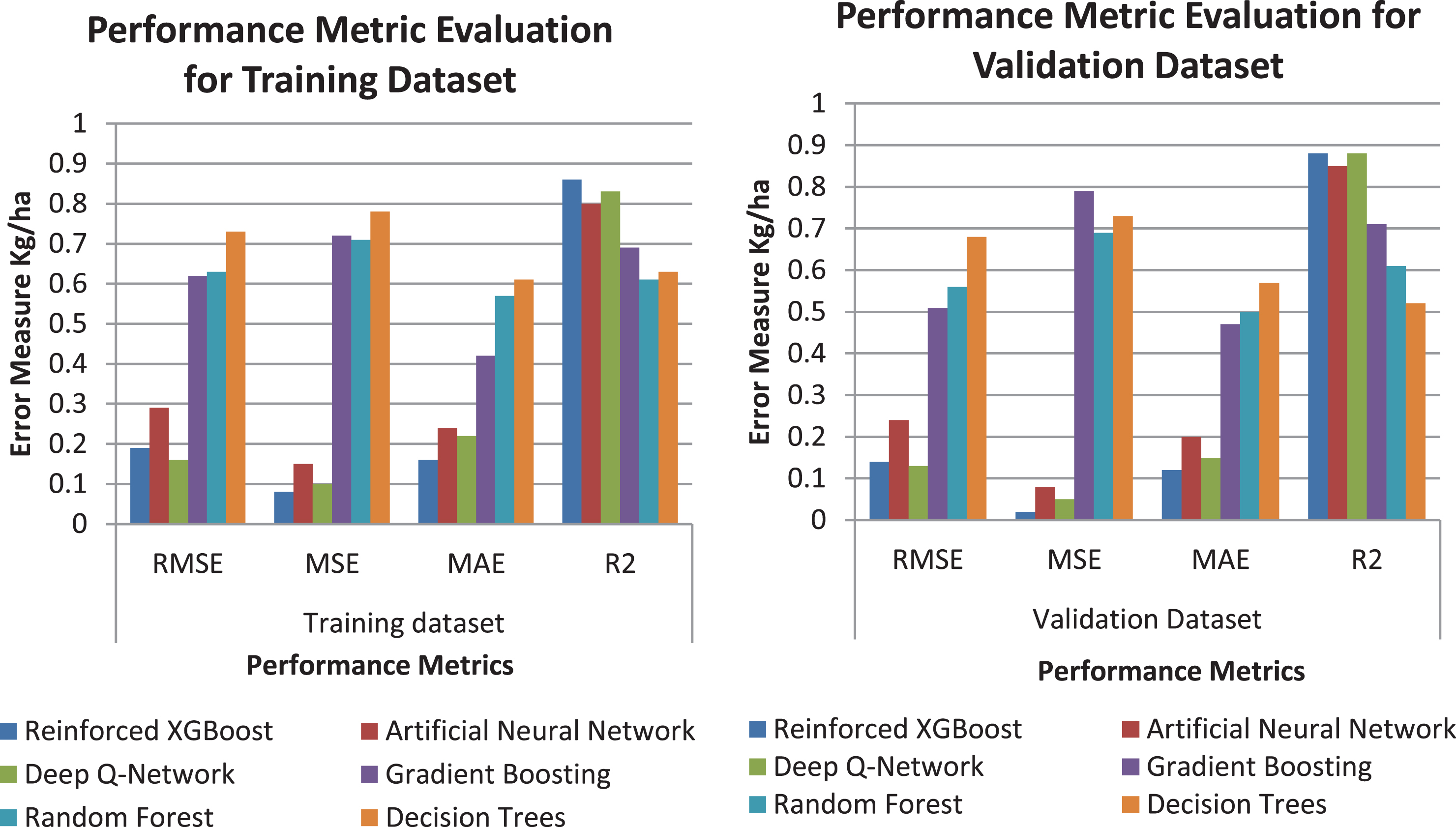
Evaluation metric results of the machine learning models.
In order to improve the exploratory performance of the model diagnostic plots are created for the regression analysis [27]. In determining the model efficiency, residuals which are the difference between the actual and predicted values are usually leftover after fitting a model to the data. A normal Q-Q plot defines if residuals are normally distributed. Q-Q plot represents good result if residuals are lined well on the straight dashed line [17]. Scale-Location plot also defined as the spread location plot depicts if the residuals are equally distributed along the predictor range [36].
The scale-location plot with a horizontal line and equally spread points represent better data distribution. The residual-leverage graph identifies the influential outliers in a regression model [10]. A margin is created using the cooks distance measure, the outliers possessing higher cooks distance score [13] or those occurring outside of the cooks distance are the influential outliers [32]. These outliers need to be observed carefully as they may enhance or degrade the models performance by their presence or absence. The residuals assisting in defining the unexplained patterns in the data by means of diagnostic graphs are represented in Fig. 4.

Linear regression analysis diagnostic plots.
Evaluation and interpretation of the model efficiency is a fundamental part of the model enhancement process. It entitles in interpreting the ideal model for representing the information and administering the model for following timestamps. Accuracy describes the ratio of predictions that the model has predicted precisely. Accuracy interprets the closeness of the predicted values to the actual values. The model’s performance in terms of accuracy measure of the proposed reinforced XGBoost prediction algorithm along with the existing machine learning models is explained graphically in Fig. 5.

Accuracy measure of the (a) Proposed Reinforced XGBoost algorithm, (b) Deep Q-Network algorithm, (c) Artificial neural network algorithm, (d) Gradient Boosting algorithm, (e) Random Forest algorithm, (f) Decision tree algorithm.
To ascertain whether the proposed reinforced XGBoost model sustained the actual data distributional properties, the probability density functions (PDF) of the actual crop yield data and the tested models are observed. PDF is an analytic interpretation that outlines probability distribution for a continuous random variable against a discrete random variable. In graphically characterizing the PDF, the area under the curve will define the interval where the predicted variable occurs. The complete area in the graph interval associates the probability of occurrence of the continuous random variable. It empowers to ascertain the probabilities of the range of outcomes. The probability density functions of the actual crop yield data and the predicted crop yield data using the proposed reinforced XGBoost model and other machine learning algorithms are defined in Fig. 6. It is performed to examine if the proposed model and the other experimented algorithms can preserve the distributional characteristics of the original crop yield data.

Probability density functions of the actual crop yield data along with other experimented models: (a) Reinforced XGBoost, (b) Artificial Neural Networks, (c) Deep Q-Network, (d) Gradient Boosting, (e) Random Forest, (f) Decision Trees.
Model execution time is the time taken for the machine learning model to run the algorithm for the experimented dataset. It enables to determine the computational cost of training process and define better hyperparameter settings that eventually enhance the model accuracy. For the experimented models the execution time is measured for 1000 epochs. An epoch is a total performance of the dataset that is to be learned by a learning machine. All the experimented models are developed in Python environment.
The time module of the python enables to determine the model execution time using the perf_counter() function.
The hardware specification of the system used for experimenting the machine learning algorithms for the paddy crop dataset is as follows: Model –HP pavilion, CPU –3.2 GHz Intel core i5, RAM –8GB 1867 MHzDDR3, GPU –AMD Radeon r9 m390 2GB, OS –Windows 10. To determine the model computation time performance for the experimented models, the total time taken for building the training model and the time taken to determine the results from the test data are examined and are tabulated in Table 4. From the model computation time of the experimented machine learning models it is observed that the proposed reinforced XGBoost model comprises of faster computation time for both training and test data.
Experimented machine learning model execution time
Decision Trees are essentially precise and agile. They are transparent in development and gives successfully interpretable principles that encourage in perceiving the significant fields. On account of huge datasets, they are expensive in processing information because of the development of an extensive number of sub-trees. More over decision trees doesn’t regulate outliers and missing values effectively. Random forests are simpler for legitimate analysis but its theoretical assessment is very unpredictable. Random forests use decision trees which are susceptible for over-fitting. In order to attain higher accuracy random forest develops large number of trees based on bagging. The underlying objective is to resample the data regularly and for every sample training a new tree. Different trees over-fit the data in various ways and based on voting the differences are averaged. Xgboost is a boosting algorithm which is constructed on weak trees. Its objective is to add a tree at a time, so that the next tree is trained to enhance the already trained ensemble. Boosting lowers the both bias and variance. By utilizing multiple models it handles variance and reduces the bias by training the consequent models based on the residuals obtained from the previous models. The proposed model with embedded XGBoost and reinforcement learning upgrades regularization refraining from data over-fitting. Reinforced XGBoost integrating sparsity aware splitting method empowers to deal data sparsity productively. Also the data is handled in non-continuous memory blocks, empowering it to be reuse in consecutive iterations rather than re-computing resulting in faster parallel data computation. The experimental results obtained illustrates the fact that the proposed reinforced extreme gradient boosting model presents better performing results than the other experimented machine learning models. On the other hand the outputs acquired from the artificial neural networks and the deep Q-learning models predict moderately closer results to the proposed approach. This can be inspected and acknowledged from the investigations in recent literature [7, 38], that the applied machine learning has explained the outcomes of deep learning and ensemble based systems are identical for reasonable sample size. The prior consideration of the proposed work is to keep the systems and techniques as transparent and more conceivable as possible, to lean in favor of reinforced XGBoost approach. Besides performing internal cross validation, the proposed method needs less parameter tuning and are simpler than neural networks, which are generally analyzed as black boxes. Though reinforced XGBoost model is implemented with un-pruned regression trees, limiting the tree’s depth is a choice. Still this doesn’t have any negative impact by means of over-fitting, but instead has a positive outcome for agile calculations. The results interpret improved model performance by bringing down the model’s complexity and experimental errors. The models accuracy measure concludes that the proposed reinforced extreme gradient boosting model is better with 94.15% over the other machine learning models. Further the model’s predicting ability is inspected from their performance with lower error measures. The following section concludes the paper and discusses the future scope.
Agriculture is a prevalent sector among the most rigorous fields to encompass an ultimate objective of statistical assessment. There exists a staggering potential for machine learning to enhance agribusiness by incorporating varying factors like climate, soil characteristics, crop disease and pest infestations. Machine learning models secure an immense degree to interpret the significant data, transform the data acquired giving deeper insight to the process. A hybrid reinforced XGBoost prediction algorithm is proposed to predict the crop yield by coordinating the various climate, soil and ground water factors. A reinforced tree node splitting is introduced in the decision tree construction of the extreme gradient boosting framework. The proposed hybrid model with embedded XGBoost and reinforcement learning enhances regularization through L1 and L2 regression methods preventing over-fitting of the data. XGBoost utilizes block structure to store data, enabling the data to be reused in subsequent iterations rather than re-computing it. The gradient statistics are also stored in these non-continuous memory blocks. This results in faster parallel data computation of the proposed model. Thus the proposed reinforced XGBoost model enables faster execution and also precise prediction results when compared to the prevailing machine learning algorithms. The results achieved using the proposed reinforced XGBoost model illustrates improved performance by bringing down the model intricacy and experimental errors. This is attained by evaluating using various assessment metrics like Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE) and Determination Coefficient (R2). In addition the accuracy measure obtained concludes that the proposed model performs better with an accuracy of 94.15% over the other experimented machine learning models, which defines the model’s prediction capability and also preserved the original crop data distributional properties which are described by the probability density function graphs. Furthermore the diagnostic plots define the regression model exploratory performance by observing the influential outliers, distribution of the data and residual spread. The process of achieving a tight error bound for node splitting and contrasting it with other models becomes tedious. The ensuing step of future research to extend the proposed model to an easier embedded framework and relatively to a restricted baseline function in a prospect to accomplish tight error bound. Administering the reinforcement learning approach to several other agrarian applications along with varying hybrid algorithms furthermore can be an interesting area of research.
Footnotes
Acknowledgments
We thank the India water portal for providing the meteorological data relevant to climatic factors from their MET data tool. The MET data tool provides district wise monthly and the annual mean of each metrological indicator values. We also thank the Joint Director of Agriculture, Vellore, Tamil Nadu, India for providing the details regarding the soil and groundwater properties for the respective village blocks.