
Abstract
Aiming at the problem that the traditional OCR processing method ignores the inherent connection between the text detection task and the text recognition task, This paper propose a novel end-to-end text spotting framework. The framework includes three parts: shared convolutional feature network, text detector and text recognizer. By sharing convolutional feature network, the text detection network and the text recognition network can be jointly optimized at the same time. On the one hand, it can reduce the computational burden; on the other hand, it can effectively use the inherent connection between text detection and text recognition. This model add the TCM (Text Context Module) on the basis of Mask RCNN, which can effectively solve the negative sample problem in text detection tasks. This paper propose a text recognition model based on the SAM-BiLSTM (spatial attention mechanism with BiLSTM), which can more effectively extract the semantic information between characters. This model significantly surpasses state-of-the-art methods on a number of text detection and text spotting benchmarks, including ICDAR 2015, Total-Text.
Introduction
Text spotting in natural scenes has high research value. Firstly, text is an important carrier of human civilization. Secondly, a large amount of high-level semantic information helps to understand the world better. In addition, text spotting in natural scenes has a wide range of application scenarios, such as industrial automation, instant translation, robot navigation, image search and blind assisted reading. Thus, text spotting in natural scenes is one of the current research hotspots.
However, the text in the natural scene has more complicated features. Firstly, text diversity, such as different languages, fonts, sizes, and shapes in natural scenes, as shown in Fig. 1a. Secondly, complex text background, such as leaves, bricks, windows, fences, etc., as shown in Fig. 1b; Lastly, low image quality, such as low resolution, distortion, and blurring, as shown in Fig. 1c.

Features in natural scenes. a. Text diversity; b. Complex text background; c. Low image quality.
Long et al. [25] proposed traditional OCR (optical character recognition) processing methods generally decompose text spotting in natural scenes into two independent subtasks: text detection task and text recognition task. The traditional OCR processing method has achieved good performance in text spotting in natural scenes. However, this method ignores the inherent connection between text detection and text recognition. Firstly, the accumulation of training errors, the errors in the text detection stage will be passed to the text recognition process. In addition, the performance of the text detection task and the performance of the text recognition task cannot be optimized at the same time.
To address the issues of current OCR methods, end-to-end OCR processing has been proposed by Li et al. [1], Liu et al. [2], He et al. [3], Sun et al. [4] and Lyu et al. [5]. They shared a feature extraction network for text detection tasks and text recognition tasks to achieve joint optimization of the two tasks.
The end-to-end method first proposed by Li et al. [1], which can achieve good performance on horizontal text data sets, but cannot well deal with text diversity in natural scenes. For multi-directional text, Liu et al. [2], He et al. [3] and Sun et al. [4] all proposed similar end-to-end recognition models. Their first step is to extract the features of the text area through the feature extraction network, then modify the text area features, and finally, input the rectified text feature maps into the text recognizer. Lyu et al. [5] Although text detection performance can be improved, but the loss of the potential inter-character sequence information.
Liu et al. [2] and Qin et al. [10] both use a joint optimization of text detector and text recognizer, which can make good use of the potential internal connection between text detection and text recognition, thereby improving the overall performance. However, Liu et al. [2] is not suitable for processing Curve text, Qin et al. [10] can’t solve the negative sample problem of text detection well.
To better solve the above problems, This paper propose a novel end-to-end text spotting framework. This model jointly optimizes the text detector and the text recognizer, effectively utilizes the potential internal relationship between text detection tasks and text recognition tasks, and improves the overall performance. The text detector uses an improved Mask R-CNN framework, and adds a TCM to the original, which can alleviate the problem of negative samples. The text recognizer is a text recognition model based on the SAM-BiLSTM, which can more effectively extract semantic information between characters. In addition, this model can handle text of arbitrary shape.
The paper main contributions are summarized as follows: The paper propose a novel end-to-end text spotting framework. By sharing convolutional features, the text detection network and the text recognition network can be jointly optimized at the same time. On the one hand, it can reduce the computational burden; on the other hand, it can effectively use the inherent connection between text detection and text recognition. The model add the TCM module on the basis of Mask RCNN, which can effectively solve the negative sample problem in text detection tasks. The paper propose a text recognition model based on the SAM-BiLSTM spatial attention mechanism, which can more effectively extract the semantic information between characters. The method significantly surpasses state-of-the-art methods on a number of text detection and text spotting benchmarks, including ICDAR 2015, Total-Text.
This paper proposes an end-to-end text spotting model and adopts a joint optimization strategy to improve the performance of text spotting.
Text detection
Natural scene complexity characteristic increases the difficulty of text detection. Tian et al. [26] uses the advantages of RNN (recurrent neural networks) to improve the detection performance of horizontal text, but it is not suitable for non-horizontal text detection. Shi et al. [38] first cuts each word into more directional small text segments that are easier to detect, and then connects each small text block into a word with a neighboring link, which is conducive to recognizing a wide range of lengths with directions Words and lines of text. Zhou et al. [14] uses FCN (full convolutional network) to generate multi-scale fusion feature maps to improve the performance of text detection.
Text recognition
The mainstream methods of natural scene text recognition tasks are: CTC-based methods and attention mechanism-based methods. Graves et al. [27] used the CTC-based method for the first time and achieved good performance. Shi et al. [19], Su et al. [28], Liu et al. [29], Gao et al. [30] and Yin et al. [31] also adopted the improved CTC method to further verify the performance of CTC method. In machine translation tasks, Bahdan et al. [32] first proposed the attention mechanism and achieved good performance. Now the attention mechanism is widely used in text recognition tasks in natural scenes. Liu et al. [33] proposed an attention mechanism based on encoding and decoding, which can better adapt to the problem of text recognition. Aiming at the problem of irregular text recognition, Shi et al. [34] proposed to combine the attention mechanism with the spatial transformation network to improve the performance of irregular text recognition in natural scenes.
Text spotting
The traditional OCR method ignores the inherent connection between text detection tasks and text recognition tasks. However, end-to-end text spotting can make full use of the potential connection between text detection and text recognition to improve overall performance. Liao et al. [21] uses a text detector based on SSD (single shot multibox detector) [35] and a text recognizer based on CRNN (convolutional recurrent neural network) [36]. Li et al. [1] uses a text detector based on RPN (region proposal network) [37] and a text recognizer based on the attention LSTM (Long Short Term Memory Network). Liu et al. [2] and Qin et al. [10] all adopted joint optimization strategies to improve the overall performance of text spotting.
The method has two mainly advantages compared to them. This papre adopt a joint optimization strategy, which can not only reduce the computational burden but also make full use of the inherent connection between text detection and text recognition. The TCM module effectively solves the negative sample problem of text detection. The text recognition model based on the SAM-BiLSTM can more effectively extract the semantic information between characters.
Model design
Model
This paper propose an end-to-end text spotting model, as shown in Fig. 2. It includes three parts: shared convolution feature extraction, text detection task branch and text recognition task branch. Firstly, the picture is fed into the feature extraction network for feature learning, and the obtained feature map is input to a text detector and a text recognizer. Inspired by Xie et al. [6], the text detection branch adds a TCM module on the basis of Mask R-CNN, which can better solve the problem of negative samples. The text recognizer is a text recognition model based on the SAM-BiLSTM spatial attention mechanism, which can more effectively extract semantic information between characters. This paper uses joint optimization to further improve the overall performance of text spotting in natural scenes.

End-to-end OCR model overall framework.
The feature extraction uses the ResNet-50 structure by He et al. [7], as shown in Fig. 3. Natural scene text size is usually large and small, in order to better adapt the text of various sizes, the need to maintain a large receptive fields and more feature-rich. Use Dilated convolution to maintain a large receptive field. Inspired by the FPN (feature pyramid networks) network proposed by Lin et al. [8], this paper used a method of cascading low-resolution feature maps and high-resolution feature maps to extract richer text features.

Shared convolution network.
The detection branch is improved based on Mask R-CNN. Negative samples are one of the difficulties in text detection. Text in natural scenes will contain many regular objects, such as fences, walls, etc. These objects are easily mistaken for text. Therefore, the introduction of contextual information helps the network to extract more significant features and accurately classify regions of interest. In order to solve the negative sample problem of text detection, the TCM module proposed by Xie et al. [6] is added on the basis of Mask RCNN, and the evaluation mechanism was also improved.
TCM
TCM structure as shown in Fig. 4. F is the output feature map of FPN. Firstly, the feature map F passes through three convolutional layers to output a text segmentation feature map F′, secondly, feature map F and text segmentation feature map F′ multiply element by element to output feature map F″, finally, the feature map F″ and the feature map F are added element by element to output the feature map F″′, thereby fusing the detection features and segmentation features to obtain richer features.
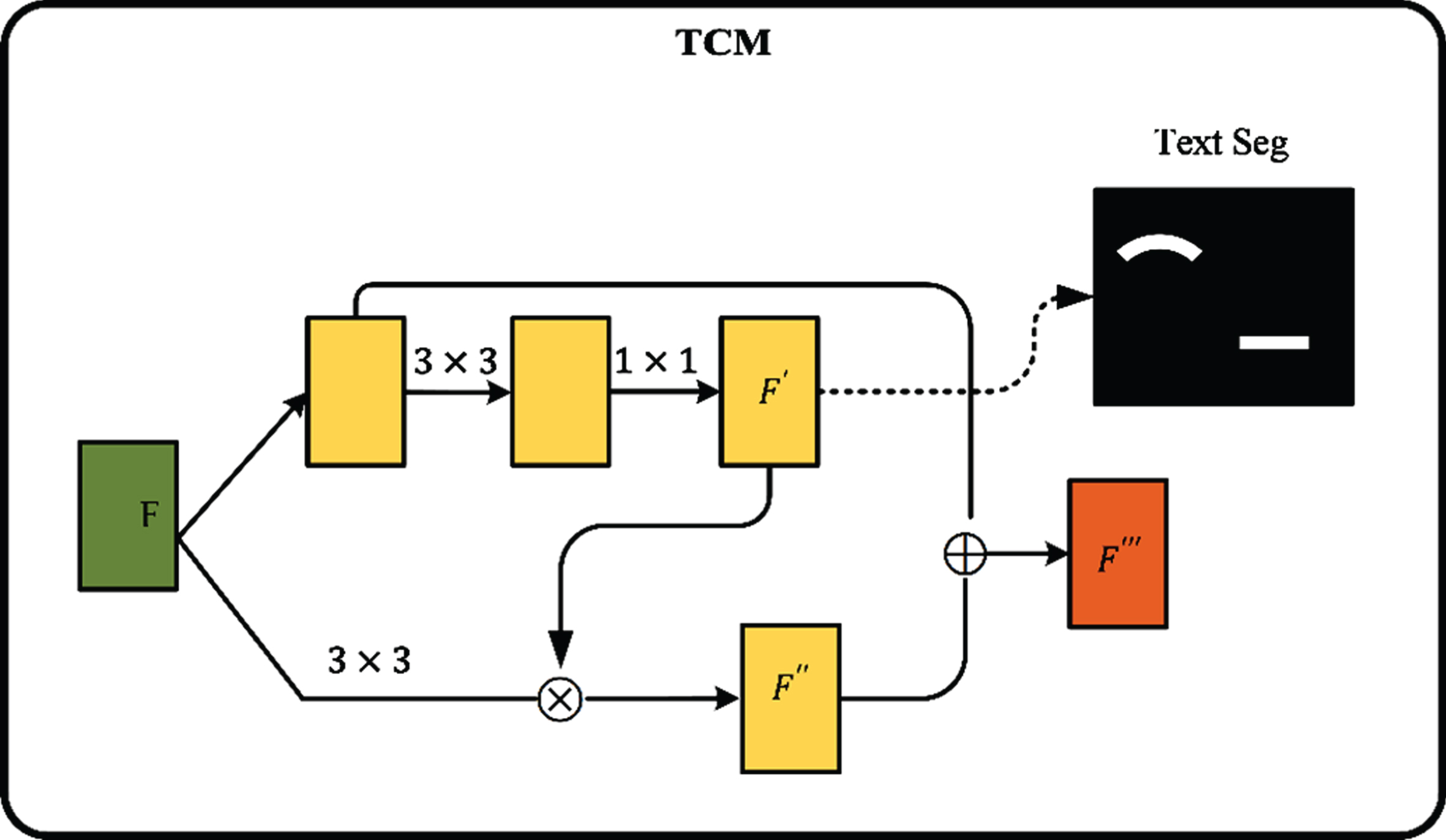
TCM structure.
The output feature F of the shared convolutional layer is fed into the TCM module, and the text salient feature F′ is calculated as follows:
The feature map generated by TCM has two channels: text and non-text, and then is activated by the Softmax function to obtain the text salient feature F′.
Then, F′ broadcast operation after the element-wise multiplied with the feature F, is calculated as follows:
The symbol ⊙ stands for multiplication by element.
Because the features around the text are better for detecting the text, adding the original features and salient features element by element is helpful for better detecting the text. The calculation is as follows:
The symbol ⊕ represents element-wise addition, and Conv3×3 represents a 3×3 convolution.
Finally, feed the output feature F″′ into Mask R-CNN.
Mask R-CNN text classification score detected text box as the final score, to filter out lower box score text prediction by setting a threshold value. However, if the text area is relatively low, it will result in a lower classification score but a higher score on the semantic segmentation map. Some negative samples have higher detection scores but lower scores on semantic segmentation graphs. Therefore, the fusion of the features of semantic segmentation and instance segmentation, and recalculation of reasonable scores can reduce false sample detection.
The calculation is as follows:
CBAM
The CBAM (convolutional block attention module) proposed by Woo et al. [9] has achieved good performance in object recognition tasks. So CBAM was added to the text recognition branch. CBAM contains two dimensions: the channel dimensions and the spatial dimension. The channel attention mechanism can better obtain global features, and the spatial attention mechanism can better obtain local features. As shown in Fig. 5.

CBAM structure diagram.
The module adopts a sequential combination attention mechanism: the output feature F of the shared convolution layer is first fed into the channel attention module, and then the output result F cam is fed into the spatial attention module to obtain a modified attention feature map F rf . This can better coordinate global and local attention.
The calculation is as follows:
Qin et al. [10] proposed ROI masking, which can be better extract the instance features of irregular text. Similarly, this paper inputs the output feature map of CBAM to ROI Masking. ROI Masking filters out the background around the text to avoid focusing on non-text areas. It consists of two steps: firstly, using the predicted rectangular bounding box to cut out the features; secondly, multiplying the mask by the corresponding instance.
Attention decoder
Zhou et al. [11] proposed a decoder based on attention mechanism. However, it has been further improved to increase spatial attention on the basis of the original. As shown in Fig. 6.
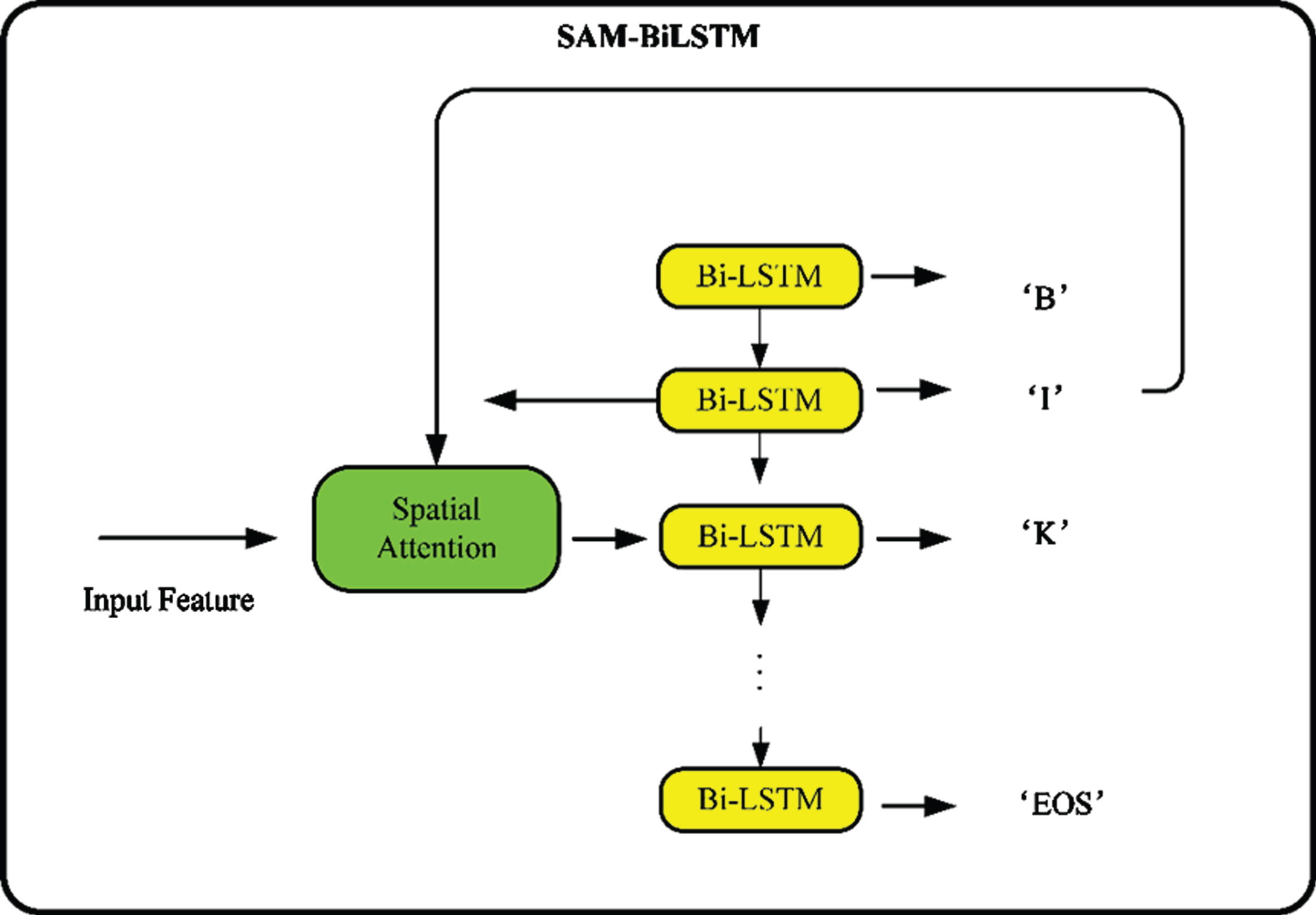
SAM-BiLSTM module structure diagram.
Suppose T iterations are needed, and the predicted character sequence is y = (y1, …, y T ). There are three inputs at step t: the input feature F, the hidden state st-1 of the previous iteration and the character category yt-1 predicted by the previous iteration.
Firstly, expand the st-1 vector into a feature map of shape (V, H
p
, W
p
). V represents the size of the RNN hidden layer and is set to 256.
Secondly, calculate the weight α
t
of attention:
The shapes of e t , α t are (H p , W p ), W t , W s , W f and b are training weights and bias.
Thirdly, calculate the weighted feature g
t
:
Embed the characters of the character type yt-1 predicted by the previous iteration and perform a concat operation with g
t
to calculate the input r
t
of the RNN:
W y , b y are weights and bias, and N c is the number of types of sequence decoders. This paper set it to 79, including English letter case, Arabic numerals, and several special characters.
The r
t
, st-1 is fed into the RNN (Bi-LSTM):
Finally, the prediction result of the t-th iteration is as follows:
The end-to-end text spotting framework is a multi-objective task. Therefore, the multi-objective loss function is defined as follows:
L
cls
, L
box
and L
mask
are loss functions in Mask R-CNN. L
gts
is used to optimize global text semantics and is defined as:
L
gts
is a Softmax loss function, and p is the predicted output of the network.
T is the length of sequence tags. λ1, λ2, λ3, λ4, and λ5 are respectively set to 2.0, 1.0, 1.0, 1.0, and 1.0.
Data sets
The datasets and experiments used in the experiment are as follows:
Experimental details
The training data set used in the experiment is mainly SynthText, and some data in the training set in ICDAR2017 MLT are 200 k and 7 k pictures, respectively. The test set is mainly ICDAR2015 and Total-Text dataset. A model trained on ImageNet data is used as a pre-trained model.
The end-to-end text spotting model is different from the previous independent training or alternate training of text detection and text discovery, it can simultaneously and end-to-end joint training.
The entire training process includes two phases: first pre-training on SynthText, and finally fine-tuning on actual data. Use different training data sets for different tasks.
The experiment uses the SGD (stochastic gradient descent) optimization algorithm, the weight attenuation value is 0.0001, and the momentum value is 0.9. During the pre-training phase, the model was trained 300 k iteratively, The default value of the initial learning rate is 0.01, and the learning rate decreased by 150 k and 300 k iteration one. During the fine-tuning phase, The default value of the initial learning rate is set to 0.001 and then reduced to one-tenth in 150 k iterations. Fine-tuning process stops at 200 k times.
Experimental results and analysis
The model was tested and evaluated on the ICDAR2015 dataset and the Total-Text dataset.
Straight text
The experiment verify the performance of the method proposed in this paper in staight text spotting on the IDAR2015 dataset. This data set is an image captured by a wearable camera, without deliberately focus on the text area. Therefore, it’s text size, text direction, and font size vary greatly. In addition, the text is an example word level mark. Providing quadrilateral side text box and the transcription.
In the training phase, first pre-train on the SynthText dataset and then fine-tune on the ICDAR2015 dataset. For the evaluation of detection, if the IOU closest to the real situation is greater than 0.5, the prediction is counted as a positive example. For end-to-end evaluation, the predicted text content must be the same as the label to be considered positive. Unreadable words are collectively labeled as “do not cate.” The evaluation indicators used in the experiment are Precision, recall and F-measure.
“P”, “R” and “F” mean Precision, Recall and F-measure in detection task respectively, “E2E” means end-to-end, “S”,“W” and “G” mean recognition with strong, weak and generic lexicon respectively.
Curve text
The experimental results are shown in Table 1. In the text detection task, compared with Liu et al. [2], the precision of the method proposed in this paper is increased by 0.11%. Compared with Qin et al. [10], in the end-to-end text spotting task (with strong lexicon) increased by 1.74%. In general, the model achieves good performance on the ICDR2015 data set.
Results on the ICDAR2015 dataset
Results on the ICDAR2015 dataset
The biggest advantage of the method proposed in this paper is the excellent performance on irregularly shaped text. The experiments were tested on the Total-Text text dataset. First, pre-training on SynthText dataset, and then fine-tune the model on Total-Text training set. The Total-Text data set contains a large amount of curvilinear text, the annotation level is the word level, the training data set contains 1255 images, and the test data set contains 300 images. The evaluation protocol used for detection is based on the protocol proposed in [12], and the evaluation protocol for end-to-end identification uses the end-to-end evaluation protocol based on ICDAR2015.
The experimental results are shown in Table 2. The method proposed in this paper has made great breakthroughs in both text detection tasks and end-to-end text spotting tasks. Especially in the end-to-end text spotting task, the performance is improved by 3.16% compared with Qin et al. [10].
Results on the Total-Text dataset
Figure 7 is the visualization results on the ICDAR2015 dataset and the Total-Text dataset. As you can see from the first two lines, the model can handle curved and non-curved text very well. The third line, due to the complexity of the text background and blurred image quality, leads to false detections and missed detection.

Visualize the results. The first column is the visual result of the Total-Text data set, and the second column is the visual result of the ICDAR2015 dataset.
Ablation experiments can better verify the model proposed in this paper and use the average accuracy (AP) score as an indicator. The ablation experiment used the ICDAR2015 dataset.
The experimental results are shown in Table 3.
Results on the ICDAR 2015 dataset
Results on the ICDAR 2015 dataset
“P”, “R” and “F” mean Precision, Recall and F-measure in detection task respectively. “E2E” means end-to-end, “None” means recognition without any lexicon.
Results on the ICDAR 2015 test set under different model configurations. AP number are reported. “TCM” and “SAM-BiLSTM” stand for TCM and SAM-BiLSTM respectively.
For texts of arbitrary shapes in natural scenes, this paper proposes an end-to-end text discovery model, which can jointly optimize text detection performance and text recognition performance and promote each other. On the one hand, this method can solve the problem of negative samples to a certain extent. And on the other hand, it can be better extracted semantic information of the text in natural scenes. The method proposed in this paper has achieved some breakthroughs in both ICDAR15 and Total-Text benchmark tests. In general, the method proposed in this paper has made great progress in text spotting tasks.
The inherent features of text in natural scenes are the difficulties of text spotting and the trend of future research. For example, the diversity of text (different languages, fonts, font sizes, shapes), the complexity of the text background (leaves, bricks, windows, fences), and the low quality of data (low resolution, distortion, and blur). How to deal with these problems becomes the key to text spotting in natural scenes.
Footnotes
Acknowledgments
The authors are grateful for the support from the Key Research Program of Shandong Province (2018GGX101011).