
Abstract
Pulsars are highly magnetized, rotating neutron stars with small volume and high density. The discovery of pulsars is of great significance in the fields of physics and astronomy. With the development of artificial intelligent, image recognition models based on deep learning are increasingly utilized for pulsar candidate identification. However, pulsar candidate datasets are characterized by unbalance and lack of positive samples, which has contributed the traditional methods to fall into poor performance and model bias. To this end, a general image recognition model based on adversarial training is proposed. A generator, a classifier, and two discriminators are included in the model. Theoretical analysis demonstrates that the model has a unique optimal solution, and the classifier happens to be the inference network of the generator. Therefore, the samples produced by the generator significantly augment the diversity of training data. When the model reaches equilibrium, it can not only predict labels for unseen data, but also generate controllable samples. In experiments, we split part of data from MNIST for training. The results reveal that the model not only behaves better classification performance than CNN, but also has better controllability than CGAN and ACGAN. Then, the model is applied to pulsar candidate dataset HTRU and FAST. The results exhibit that, compared with CNN model, the F-score has increased by 1.99% and 3.67%, and the Recall has also increased by 6.28% and 8.59% respectively.
Keywords
Introduction
Pulsars are highly magnetized, rotating neutron stars that emit a beam of electromagnetic radiation. The discovery of pulsars is of great significance in the fields of physics and astronomy. The Five-hundred-meter Aperture Spherical Telescope(FAST), known as the “Chinese Sky Eye”, is located in Pingtang County, Guizhou Province, China and was completed on September 25, 2016. Discovering pulsars is one of FAST’s most important scientific goals. Millions of pulsar candidates are produced when the raw data are processed via the pipeline system, such as Pulsar Exploration and Search Toolkit(PRESTO). Pulsar candidate datasets are characterized by extreme imbalance and lack of positive samples, because the number of pulsars discovered is limited, while interference signals are widespread. For example, there are 1196 positive samples and 89996 negative samples in High Time Resolution Universe(HTRU) dataset, with the imbalance ratio of approximately 75: 1. In recent years, with the development of artificial intelligence(AI), deep convolutional neural network(CNN) [1–3] have been increasingly employed to identify pulsar candidates. However, these methods exhibit poor performance and inevitably suffer from model bias. Rebalancing dataset is the most frequent and convincing strategy for handling imbalanced dataset. Synthetic minority over-sampling technique(SMOTE) [4] is one of the classic methods and works well on low-dimensional imbalanced datasets. However, it is not suitable for image datasets, partly because it is based on the k-Nearest Neighbor(KNN), and also because the synthesized samples are convex combinations of existing samples. Recently, with the emergence of generative adversarial nets(GANs) [5], ones have been exploring the application of the model for over-sampling [6–8].
Generative adversarial nets, which exhibits superiority in generating visually sharp images and feature representation learning, consists of a generator(G) and a discriminator(D). The generator takes random noise
Two perspectives can be considered when applying GANs to the classification of unbalanced datasets. One strategy is to train the conditional GANs(CGAN) to rebalance the dataset before adopting CNN for classification; the other is to train the CGAN and CNN simultaneously under a unified framework. The former is widely adopted in various unbalanced image datasets [14, 15]. However, it also suffer from two thorny issues, which are as follows: Firstly, it is not an end-to-end learning model. Ones must determine the convergence of CGAN model according to their experience, so the results are difficult to reproduce; Secondly, the samples generated by CGAN concentrate on the center of the real distribution, which is of little significance for improving the diversity of training samples. To this end, we adopt the second strategy and present a general image classification model based on adversarial training, abbreviated as ICAT. it is an end-to-end learning model which contains a generator, a classifier, and two discriminators. During the training, the generator and the classifier cooperate with each other to achieve equilibrium. Meanwhile, the labels that are adopted for generating images are restored when the images are fed into classifier. Theoretical analysis demonstrates that the model has a unique optimal solution and the classifier happen to be the inference network of the generator, which means, for conditional generation samples, the prediction label of the classifier is exactly the same as the input label of the generator. When the model reaches equilibrium, the generator can produce completely controllable samples, and the classifier can predict labels for the generated samples and unseen samples. The main contributions of this paper are rendered in the following three aspects.
(i) A general image classification model with adversarial training is proposed, and the convergence of the model is demonstrated theoretically.
(ii) 10,000, 20,000, 30,000 and 40,000 samples are extracted from MNIST for model training, and classification and generation experiments are conducted. The results show that, compared with the CNN model, the recognition accuracy of ICAT is improved by 0.16%, 0.12%, 0.09%, 0.08% and 0.07%, respectively. In addition, classification on the generated samples, with "perfect" classifier, indicates that the ICAT behave better controllability than CGAN and ACGAN.
(iii) The model is applied to the unbalanced pulsar candidate datasets HTRU and FAST. The results exhibit that, compared with CNN model, the F-score has increased by 1.99% and 3.67%, and the Precision has also decreased by 2.75% and 3.99% respectively. Meanwhile, the recognition performance of ICAT is also better than that of CGAN+CNN model.
The remainder of this paper is organized as follows: Section 2 introduces the development of pulsar candidate identification algorithms and the application of GANs on unbalanced datasets. Section 3 outlines the proposed model and the theoretical analysis. Section 4 presents the results and corresponding discussions. Section 5 ends this paper with concluding remarks.
The methods of pulsar candidate recognition can be divided into two categories namely artificial recognition algorithm and machine learning recognition algorithm. The artificial recognition mainly includes the classification algorithm based on statistical information such as signal-to-noise ratio [16], the scoring and sorting algorithm based on statistical feature [17] and the image software-assisted classification algorithm [18]. As such method is an unsupervised, no labels are required. However, the features of the sample need to be designed and weights must be assigned for each feature, which greatly depends on the professional knowledge and experience of the researchers.The machine learning method that has emerged in recent years mainly includes artificial neural network (ANN) algorithms based on empirical features and data-driven image recognition algorithms. In 2010, Eatough et al. [19] designed 12 sample features and adopted a three-layer ANN model for training and testing; In 2012, Bates et al. [20] added another 10 statistical features for ANN training. In 2014, Morello et al. [21] optimized the ANN model and presented the SPINN method(Straightforward Pulsar Identification using Neutral Networks). The application of ANN model greatly improves the accuracy and processing speed of pulsar candidate classification. However, it is based on experience and certain assumptions, and the selection of features is also strongly dependent on the data set. In 2014, Zhu et al. [22] designed novel artificial intelligence program that identifies pulsars by using image pattern recognition with deep convolutional neural networks-the PICS(Pulsar Image-based Classification System). Different from the recognition method based on ANN, the system directly takes candidates as input. Therefore, no sample features need to be designed. In 2018, Wang et al. [23] proposed to replace the CNN in the PICS with ResNet[24] and retrained the system on the FAST dataset. The GANs model is also considered for the recognition of pulsar candidate[25], where the discriminator of GANs is employed as a feature extractor. A similar design appeared in [26], where the ANN model was applied for feature extraction. These methods have improved the accuracy of pulsar candidate identification, but do not solve the problem of model deviation caused by the imbalance of the dataset and the lack of the diversity of positive samples.
The classification of imbalanced data has always been a hot topic in the fields of machine learning and artificial intelligence, and is widely found in biomedical [27, 28], financial [29] and information security [30]. The research of imbalanced data classification mainly focuses on data preprocessing and classifier construction. Data preprocessing is to rebalance the dataset by resampling the raw data, which mainly includes data under-sampling, over-sampling and mixed sampling. In terms of classifier construction, the structure of the classifier is changed to obtain a higher classification accuracy for majority samples and the minority samples. These methods have been successful on low-dimensional imbalanced data, but suffer from limitation on high-dimensional data. With the development of artificial intelligence and deep learning, generative adversarial nets(GANs) have been increasingly adopted for the classification of unbalanced data. At present, the general workflow is to employ the CGAN model for data rebalancing before adopting the CNN model for classification. CGAN has achieved clear advantage in the classification of high-dimensional unbalanced dataset due to its unique ability to generate realistic samples. However, it also suffers from certain limitations, which are as follows: 1. The samples generated by CGAN are mainly concentrated in the center of the data distribution, which limits the supplementation of data diversity; 2. the method is non end-to-end learning model, so the results are hard to reproduce and rely heavily on the researcher’s experience.
Method
Model presentation
The proposed model consists of a generator, a classifier and two discriminators. The architecture of the model is shown in Fig. 1, where p (
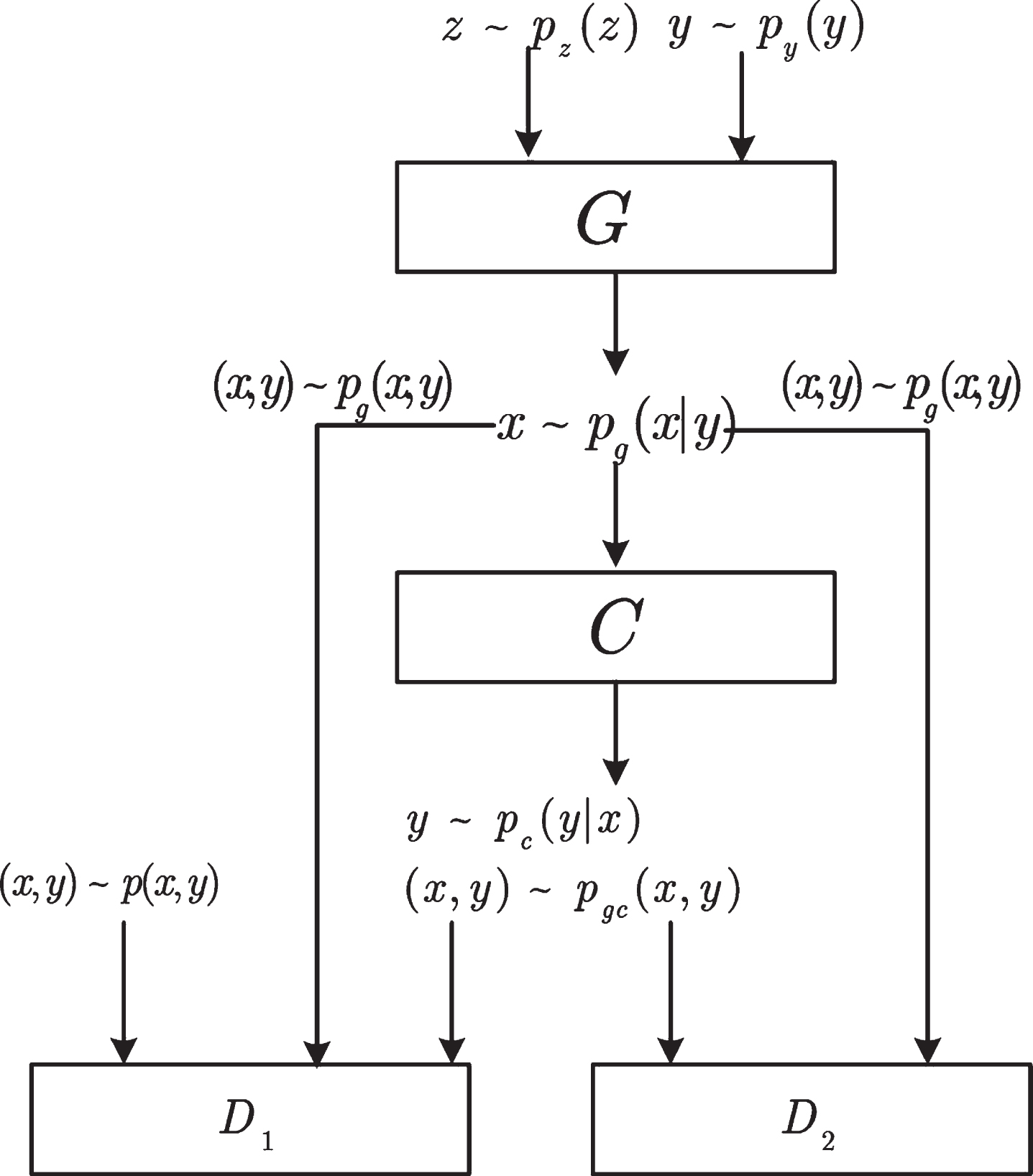
Structure of the proposed ICAT model.
The generator G is similar to the generative model in CGAN, which takes the latent variable
Therefore, the joint distribution p
g
(
The classifier C is similar to a CNN model, which takes the generated samples as input and outputs the corresponding prediction labels. Suppose p
c
(
where p
g
(
Discriminators D
i
are binary classifiers with the same function as the discriminant model in the original CGAN. D1 separates the joint distribution p (
Therefore, the objective function of the ICAT model is written as
Theoretically, it can be proved that the model has a unique global optimal solution. Similar to GANs, the proof is divided into two steps. Firstly, fix the generator and classifier, maximize the objective function with respect to the discriminators. Secondly, substitute the discriminators and minimize the objective function with respect to the generator and classifier.
Proposition 1. For given G and C, the optimizer solution of objective function V (G, C, D1, D2) with respect to discriminators D1, D2 can be found at:
Proof: For fixed G and C, the objective function can be abbreviated as V′ (D1, D2). Then, the training criterion is to maximize V′ (D1, D2) with respect to D1, D2. Rewrite the objective function as:
Proposition 2. The global optimal solution of V (G, C, D1, D2) is achieved if and only if p (
Proof: Let Δ = p (
During the training, in order to speed up the convergence of the model, label posteriori error ψ l of real samples is introduced into classifier C, where
Minimizing ψ
l
is equal to minimizing KL (p (
The experiments are divided into two parts: The first is to investigate the classification performance and controllability of ICAT on the widely used MNIST dataset; The second is to apply the model to the pulsar candidate datasets HTRU and FAST to verify classification and generation ability on unbalanced dataset.
Datasets and evaluation metrics
MNIST [31] is a handwritten digit dataset, which consists of 50,000 training data, 10,000 cross-validation data and 10,000 test data, each of which represents a grayscale image with the size of 28 × 28. In the experiment, 10,000, 20,000, 30,000 and 40,000 samples are extracted from the training data for the model training.
A pulsar candidate(Fig. 2) contains several diagnostic plots, where the most important subplots highlighted are summed profile histogram, time-vs-phase plot, frequency-vs-phase plot and dispersion-measure(DM) curve. Here, two pulsar candidate datasets, HTRU and FAST, are chosen for experiment.
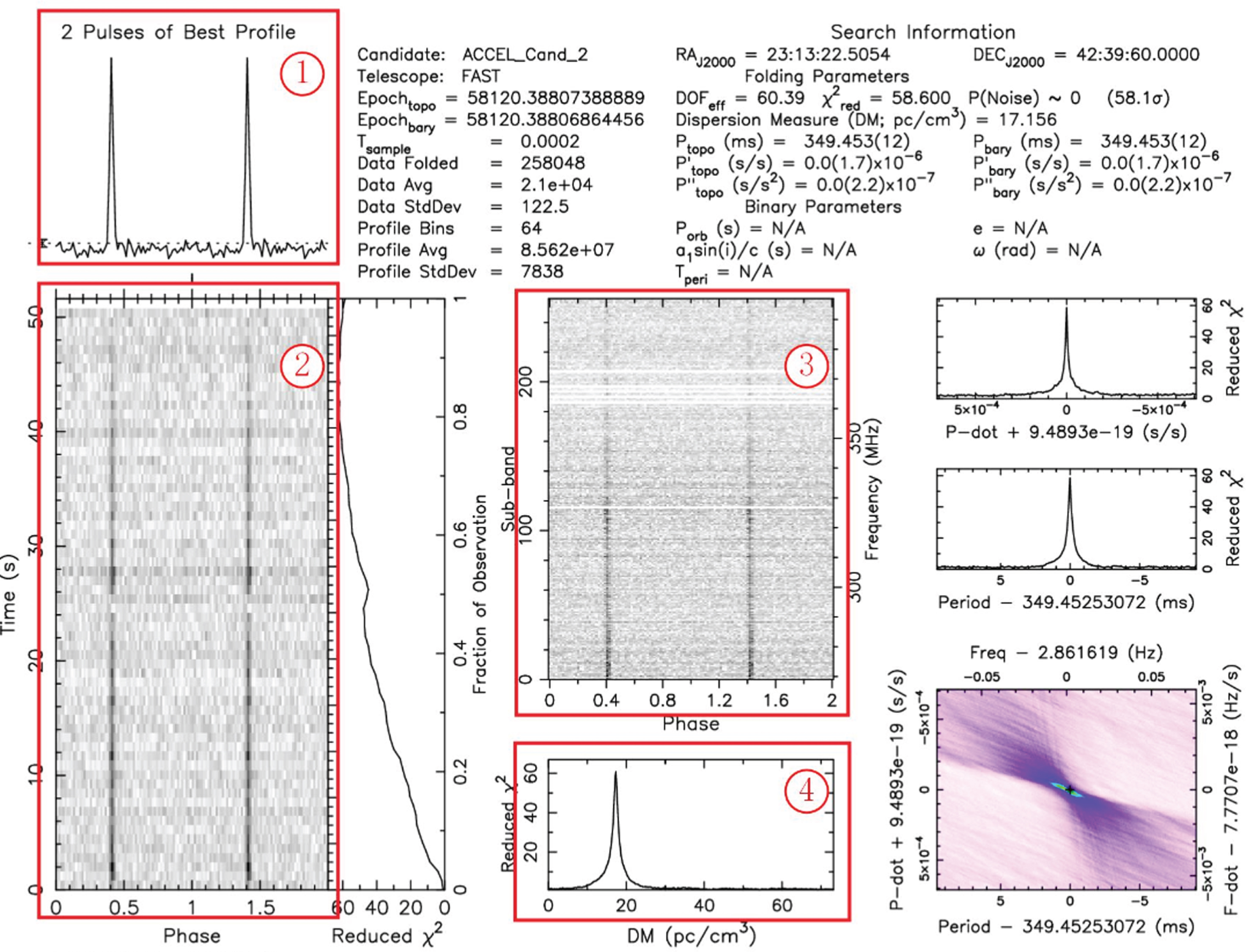
Diagnostic plot of candidate.
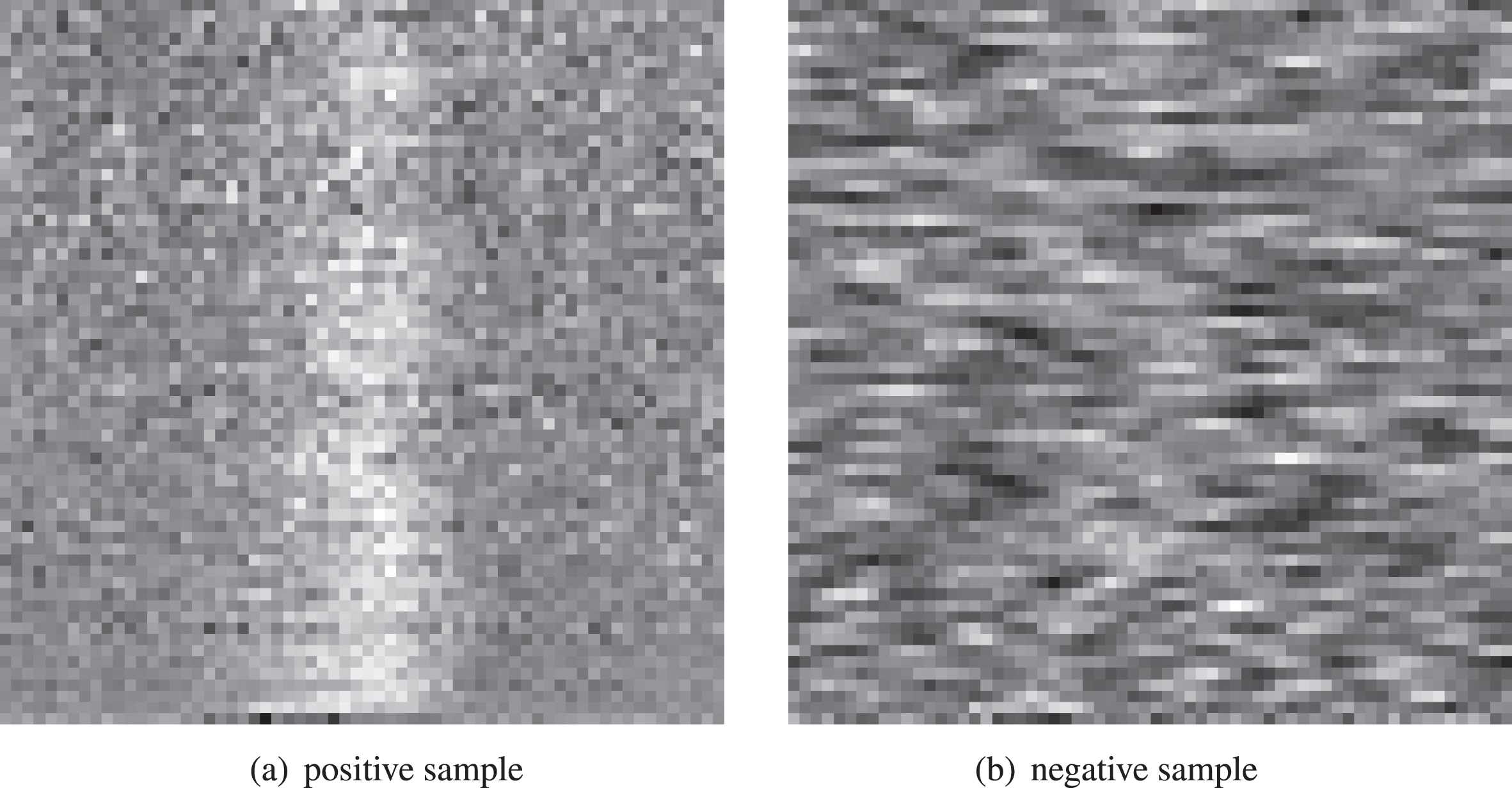
HTRU is the first publicly available labeled benchmark pulsar candidate dataset, which contains 1,196 positive samples(pulsar) and 89,996 negative samples. The positive and negative samples on HTRU are shown in Fig. 3.

Samples on HTRU dataset.
The 2D plot in the top is the frequency-vs-phase, abbreviated as sub-bands; The 2D plot in the middle is time-vs-phase, abbreviated as sub-int; The bottom one is the DM curve. There is a vertical stripe on both the sub-bands and the sub-int plot of the positive samples, which is the trace left by the pulse signal during the survey. When the signal is weak or the interference is strong, the vertical stripe may not be noticeable. In contrast, there are no vertical lines on the subplots of the negative samples. In the experiment, sub-int is adopted for model training. The dimension of the sub-int in the raw data is 18 × 64. Therefore, all images are uniformly resized to 64 × 64 and normalized to [0, 1]; then the dataset is divided into training set, validation set and test set. Table 1 lists the number of positive and negative samples on the split HTRU.
FAST is another pulsar candidate dataset, which consists of 1160 positive samples and 14319 negative samples. Fig. 4 respectively exhibit the sub-int plot of positive and negative sample, which are adopted for model training. The dimensions of sub-int is 64 × 64. Therefore, all images are normalized to [0, 1] and the dataset are divided into training set, validation set and test set. Table 1 also lists the number of positive and negative samples on the split FAST.
Samples on FAST dataset.
No. of samples on split HTRU FAST dataset
For unbalanced data sets, accuracy is no longer an convincing indicator for evaluating recognition performance of the model. Therefore, the evaluation metrics we adopt for the HTRU and FAST dataset are Precision, Recall and F-score. The binary classification confusion matrix is defined in Table 2.
Binary classification confusion matrix
Then Precision, Recall and F-score are defined as:
A generator, a classifier, and two discriminators are included in ICAT model, and their network structures are slightly different according to datasets. Fig. 5 exhibits the structures on MNIST, and Fig. 6 is the structures on HTRU and FAST, where Conv, Deconv, MaxPool and Dense represent convolutional layer, transposed convolutional layer, maximum pooling layer and full connection layer respectively.

Network structure of ICAT model on MNIST.

Network structure of ICAT model on HTRU and FAST.
All experiments were implemented on Theano [32]. The mini-batch size was set to 100 and the ADAM [33] algorithm was employed for model optimization, where β1, β2 are 0.5 and 0.999 respectively. The learning rates on MNIST, HTRU and FAST were set to 0.001, 0.05 and 0.05 respectively, and the corresponding training epoch were set to 500, 300, 200. Latent variable
The error rates on MNIST, averaged by 5 run, are listed in Table 3. In our comparison, the network structure of the CNN is the same as that of the classifier C in ICAT; 40PCA-SVM takes 40 principal components extracted by principal component analysis(PCA) of input samples as the features, and these features are adopted to train a support vector machine(SVM) classifier. As can be seen from Table 3, with the increase of the training samples, the recognition accuracy of the model are also improved accordingly. By contrast, CNN model behave better than PCA-SVM and PCA-KNN. However, compared with CNN, the error rate of the ICAT model is reduced by 0.16 %, 0.12 %, 0.09 %, 0.08 %, and 0.07 %, respectively. It is found that the magnitude of error rate decrease became small with the number of training samples.
Test error rate(%) on limited MNIST data(averaged by 5 run)
Test error rate(%) on limited MNIST data(averaged by 5 run)
The basic principle of the presented ICAT model is to expand the diversity of training samples by generating samples. Therefore, the controllability of the generated samples is crucial. Fig. 4 exhibits the generated images on MNIST. Intuitively, the quality and controllability of the generated images are continuously improved with the increase of training samples. To further study the controllability of the generated samples, we conducted the following experiments: Firstly, A "perfect" CNN classifier(0.35% error rate) was trained on MNIST with all 60,000 samples; Secondly, CGAN, auxiliary classifier GANs(ACGAN) and ICAT models were trained with limited data, and 10,000 samples were conditionally generated(average:1,000 per category); Finally, classify the generated samples with the “perfect” classifier. Table 4 summarizes the quantitative results. Although the classifier is not completely perfect, it is sufficient to illustrate that the ICAT behave better controllability than the CGAN and ACGAN.
Classify on generated samples
In summary, experiments on MNIST show that the generator and classifier in ICAT model promote each other. On the one hand, the samples produced by the generator increase the diversity of training samples so as to improve the classification performance of the classifier. On the other hand, the classification errors of the generated samples are propagated back to the generator, which improves the controllability of the generator.
Comparison of F-score between ICAT and other models is shown in Fig. 8. Intuitively, we can see that the recognition performance of ICAT model is the best, and the convergence speed is also relatively fast. Table 5 lists the performance metrics of the models on HTRU and FAST dataset, where CGAN+CNN represents that the CGAN model is trained on HTRU and FAST, and 10,000, 8,000 positive samples are generated respectively to rebalance the datasets before the CNN model is applied for classification.

Generated samples on MNIST.
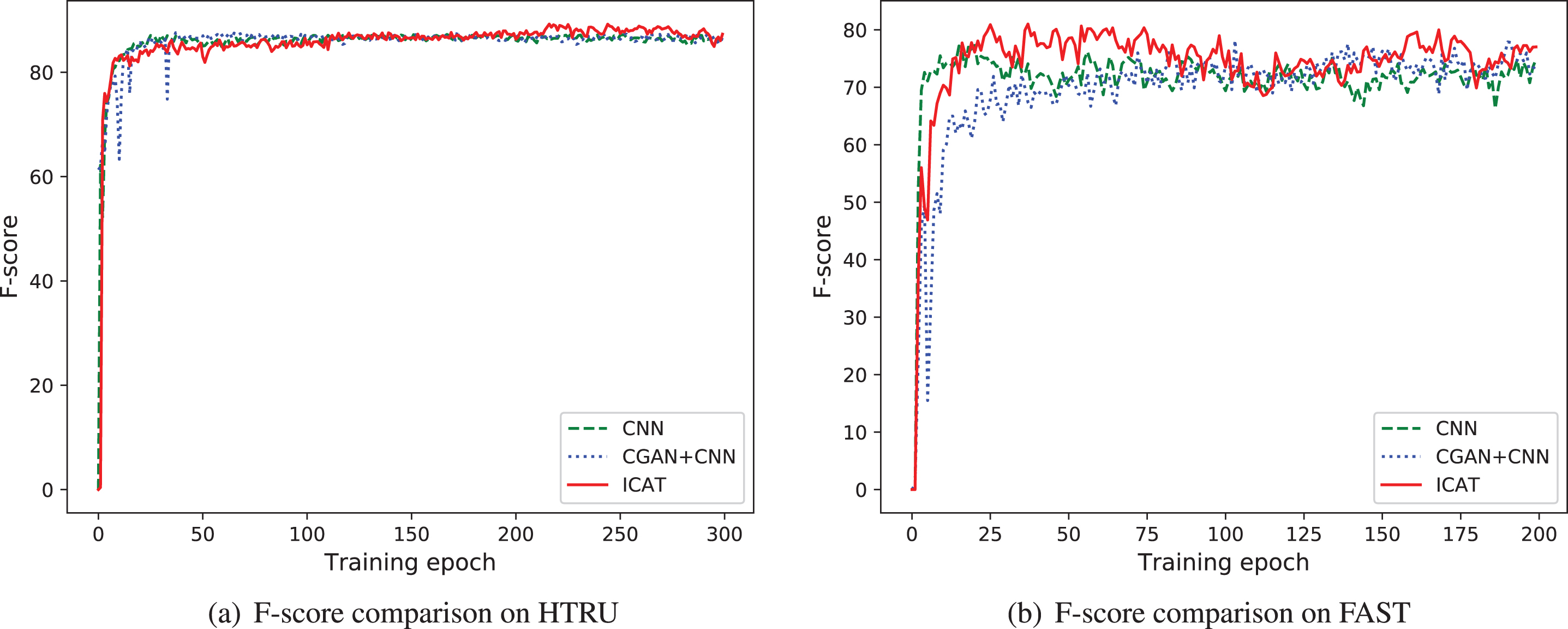
Comparison of F-score between ICAT and other models.
Evaluations of different models on HTRU and FAST(%)
Three conclusions can be drawn from the classification experiment on HTRU. Firstly, the F-score of the ICAT model is 89.24%, which is 1.99% higher than the CNN model. Meanwhile, the Recall of the ICAT model is the highest. Therefore, the false negative rate of the proposed model is the lowest. Secondly, the Precision of the CNN model is the highest and the Recall is only 83.05%, which indicates that the false negative rate of the CNN model is higher and the model bias is grave. Finally, the F-score of the CGAN+CNN method is 87.59 %, which is 0.34 % higher than that of the CNN model, which implicates that it is feasible to apply CGAN to supplement sample diversity.
Similar conclusions can be drawn from experiments on the FAST: Firstly, compared with the CNN model, the F-score of the ICAT model has increased by 3.67%, and the Recall is also the highest 75.97%. Secondly, the Precision of the CNN model is the highest 90.75%, and the Recall is 67.38%. Therefore, it also exhibits higher false negative rate and severe model migration. Finally, CGAN+CNN method also improves the recognition performance to some extent.
Fig. 9 exhibits the generated samples of ICAT model on HTRU and FAST, in which the first 50 are positive samples and the last 50 are negative samples. It can be seen that even on the unbalanced dataset, the samples generated by the ICAT model are also controllable.

Generated samples on HTRU and FAST.
It can be concluded from Table 5: compared with the CGAN+CNN model, the ICAT not only has a simpler training method, but also has better recognition performance. Of course, in addition to image classification, it also performs better than CGAN and ACGAN models in terms of the controllability of generated samples, which has been confirmed by Table 4. These two sets of experiments further revel that the performance of generator and classifier in ICAT model is improved synchronously, which is completely consistent with our theoretical analysis. To sum up, For the unbalanced pulsar candidate dataset, the traditional recognition models show the problems of poor recognition performance and model bias, while the proposed ICAT model can alleviate the dilemma. Therefore, it is more suitable for pulsar candidate recognition.
In this study, we present a novel image classification model based on adversarial training and apply it for pulsar candidate identification. A generator, a classifier and two discriminators are included in the model. During the training, the generator and classifier supervise and cooperate with each other, and finally achieve the optimum. Theoretical analysis demonstrates that the model has a unique optimal solution, and when the model reaches equilibrium, it can not only predict labels for unseen data, but also generate controllable samples. Experimentally, we firstly verify the classification performance of ICAT model on MNIST and confirm that ICAT behave better controllability than CGAN and ACGAN. Then, the model is applied to pulsar candidate datasets HTRU and FAST. The results manifest that it significantly improves the recognition accuracy and reduces the false negative rate. Therefore, the ICAT model is more suitable for pulsar candidates identification. An interesting area of our future investigation is to train the model on frequency-vs-phase plot, DM curve, and other hand-crafted features to obtain a pulsar candidate recognition system.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant no. U1831131) and Cultivation Project for FAST Scientific Payoff and Research Achievement of CAMS-CAS.