
Abstract
The rapid development of the Internet of Things and 5G networks have generated a large amount of data. By offloading computing tasks from mobile devices to edge servers with sufficient computing resources, network congestion and data transmission delays can be effectively reduced. The placement of edge server is the core of task offloading and is a multi-objective optimization problem with multiple resource constraints. Efficient placement approach can effectively meet the needs of mobile users to access services with low latency and high bandwidth. To this end, an optimization model of edge server placement has been established in this paper through minimizing both communication delay and load difference as the optimization goal. Then, an Edge Server placement based on meta-Heuristic alGorithM (ESH-GM) has been proposed to achieve multi-objective optimization. Firstly, the K-means algorithm is combined with the ant colony algorithm, and the pheromone feedback mechanism is introduced into the placement of edge servers by emulating the mechanism of ant colony sharing pheromone in the foraging process, and the ant colony algorithm is improved by setting the taboo table to improve the convergence speed of the algorithm. Then, the improved heuristic algorithm is used to solve the optimal placement of edge servers. Experimental results using Shanghai Telecom’s real datasets show that the proposed ESH-GM achieves an optimal balance between low latency and load balancing, while guaranteeing quality of service, which outperforms several existing representative approaches.
Introduction
Mobile edge computing (MEC) offers cloud capabilities and service environment for Internet of Things (IoT) applications at the edge of the mobile cellular network, such as 5G [1], which reduces the delay of mobile service delivery, and restrain network congestion. The main components of the MEC system include the mobile edge server and various mobile devices. The mobile edge server is usually deployed by a mobile network operator as a small data center close to the user. It is connected to the core network via the Internet, cooperates with the wireless access point such as base stations, and handles user’s service requests forwarded by all base stations in its service range. Deploying the MEC server on the base station which is close to the user’s mobile devices can greatly reduce the time delay for user requests and greatly improve the user’s service experience. Similar to mobile cloud and micro cloud, there are also problems with the placement of edge servers in MEC environments [2, 3]. The main goal of MEC is migrating computing tasks from the core network to edge servers to reduce core network’s congestion and data transmission delays. However, there is no clear approach for where the edge server should be placed, so the problem of placing the edge server emerges [4]. Considering the constraints of users and resources on the premise of meeting user needs and goals, the placement of edge server should program a specific approach to select the appropriate geographical location within a certain geographical range for the edge server to deploy and achieve the ultimate goal of minimizing network delay and equalizing access resources. Due to the rapid development of network technology, the current urban area covered by wireless metropolitan area has a high population density, so edge servers are suitable for placing in wireless metropolitan area [5, 6]. Through the accessing of mobile user, the idle rate of edge server is reduced, and both the cost effectiveness of edge servers and user satisfaction are improved. However, the placement of mobile edge servers in a wireless metropolitan area has the following constraints:
(1) The placement of edge server has an important impact on the communication delay of mobile users. When users access some communication-intensive applications, the distance between the user and the edge server will greatly affect the user’s access performance. Therefore, in order to improve the QoS and reduce the network delay, users should choose a local access point to access the edge server.
(2) The placement of edge server has a greater impact on the resource utilization of the edge server. The locations of edge servers determine the range of users whom they serve. Unreasonable placement may cause the workload of the edge server to be unbalanced or idle.
At present, mobile edge service has attracted many attentions from scholars, but most of the existing researches focused on the offloading of mobile user’s workloads from the micro cloud or remote cloud center to achieve low latency, and these researches assumed that devices such as microclouds have been placed [7–11]. Few researchers have concerned about the deployment of micro cloud and offloading mobile user’s workloads from edge servers to improve mobile user’s access performance [12, 13]. With the rapid development of the IoT and 5G networks, the deployment of mobile edge servers will be an essential work with the goal of addressing the requirements of low latency and high bandwidth. Most studies focus on offloading mobile users’ workloads to edge clouds or edge servers and to achieve energy saving on mobile devices, while these studies assume that the edge devices have been assumed to be set in a certain location. Some scholars proposed the problem of edge servers’ deployment to offload mobile users’ workloads, and improve the quality of service. However, most studies only consider access latency, and do not consider server’s workload balancing. Wang et al. [14] considered workload balancing, but did not consider edge server’s capacity constraints. We not only consider the delay of user’s access, but also consider server’s capacity limitation on the basis of server’s workload balancing. In this paper, we propose a hybrid edge server placement based on the combination of K-means and the ant colony algorithm, minimizing both communication delay and load balancing as the goal.
The rest of this paper is organized as follows: Section 2 summaries related work about MEC and placement of mobile edge servers. Section 3 introduces system model and problem definitions. Section 4 presents ESH-GM algorithm proposed in this paper in detail. Section 5 presents the experimental results and analysis. The final section summarizes the whole paper and discusses future work.
Related work
In the current era of big data, we hope that various IT systems can provide accurate algorithms and high user service quality [15]. Edge computing is a general term for a cloud-based IT service environment located at the edge of a network. The purpose of edge computing is to bring real-time, high-bandwidth, low-latency access to latency-dependent applications distributed at the edge of the network. Various examples that have already been realized include augmented reality (AR), virtual reality (VR), connected cars, IoT applications and so on [1]. Edge computing lets operators host content and applications close to the edge of the network. It also brings new levels of performance and access to mobile, wireless, and wired networks. The technology is routinely mentioned in conversations about the infrastructure of 5G networks and Network Function Virtualization (NFV) technology, particularly for handling the huge number of IoT devices (commercial and industrial) that are constantly connected to the network [16, 17].
In the mobile edge computing environment, mobile users can access edge servers that are in close proximity within the range of base stations. Edge servers can now also be considered as offloading destinations of mobile users, with the aim of reducing the access latency between mobile users and remote clouds. This is realized by importing the computation and storage capacity from the core network to the edge server. Many studies have focused on offloading in mobile edge computing, such as [18–22]. But Few studies have focused on edge server placement in mobile edge computing environments. Most studies’ research basis is that edge devices have been assumed to be set in a certain location.
Before the research on the placement of mobile edge server, some scholars have studied several similar placement problems. Qiu et al. studied the placement of web server replicas in content distribution. They described the placement of web server replicas as a K-median problem and derived a graph theory equation for the placement of replicas [23]. Yin et al. adopted a new K-means clustering-based media selection algorithm to determine the best match between the client and the media server in the multimedia environment. They also used the latest network coordinate technology to obtain global network information and optimized the trade-off between service latency performance and deployment cost under the constraints of client location distribution [24].
In the content distribution network, the replica server or cache server is a mirror of the remote server, which provides content delivery to customers while maintaining efficient and balanced resource consumption. Remote users obtain services from the cache replica server. This model reduced the bandwidth of remote access, shared network traffic and reduced the server’s load on the original website. However, the edge server in mobile edge computing is very powerful and it can provide more computing resources for remote users. Therefore, different servers in different network environments cause different placement problems.
There have been several studies on edge cloud placement in recent years. Jia et al. studied the edge cloud placement problem, distributed mobile users to the edge cloud concentration in the wireless metropolitan area network, and proposed two different heuristic algorithms for the edge cloud placement problem [6]. Xu et al. studied the layout of edge clouds in a large-scale wireless metropolitan area network. They placed K edge clouds in strategic locations in the wireless metropolitan area and then used a heuristic algorithm to allocate mobile users to minimize average communication delay between mobile devices [12]. Ahmed et al. studied the effect of network-centric parameters on the application migration process [25]. The performance of the migration process is analyzed by simulating the migration process in OMNeT++. Their analysis shows that the application and its running states migration time is affected by the changes in the network conditions. Based on their research findings, they recommend application execution framework designers to incorporate the network-centric parameters along with other parameters in the decision process of the application migration. Xiang et al. proposed an adaptive cloudlet placement method for mobile applications over GPS big data. Specifically, the gathering regions of the mobile devices are identified based on position clustering, and the cloudlet destination locations are confirmed accordingly. Besides, the traces between the origin and destination locations of these mobile cloudlets are also achieved [26].
MEC has received much attention from the research community in recent years. There also have some studies on MEC server placement. Hadzic et al. has studied the telecom-centric MEC architecture and further show that common probing metrics can easily fail when used to select the service site for an application and discuss possible improvements to server-selection reliability [27]. Zeng et al. found that existing studies mostly assume the edge servers have been deployed properly and they just pay attention to how to minimize the delay between edge servers and mobile users. But they considered the practical environment and investigated how to deploy edge servers effectively and economically in wireless metropolitan area networks. Thus, they addressed the problem of minimizing the number of edge servers while ensuring some QoS requirements [28]. Chen et al. defined the QoS-guaranteed efficient cloudlet deployment problem in wireless metropolitan area network, which aims to minimize the average access delay of mobile users, the average delay when service requests are successfully sent and being served by cloudlets. Meanwhile, they try to optimize total deployment cost represented by the total number of deployed cloudlets [29].
Some scholars conducted researches from the viewpoint of edge user allocation to minimize the number of edge servers deployed in the mobile edge environment. Lai et al. tackled the edge user allocation (EUA) problem from the perspective of an app vendor. Each QoS level leads to a different QoE level. Thus, the app vendor also needs to decide the QoS level for each user so that the overall user experience is maximized. Thus, they proposed a heuristic approach that is able to effectively and efficiently find sub-optimal solutions to the QoE-aware EUA problem [30]. Peng et al. considered that the edge-user-allocation problem are yet to be properly addressed and user-mobility-related information is not fully exploited. To overcome the above limitations, they considered the edge user allocation problem as an online decision-making and evolvable process and develop a mobility-aware and migration-enabled approach, named MobMig, for allocating users at real-time [31].
Although the approaches studied by the above scholars are effective, they have not considered both the workload balancing of edge clouds or edge servers in mobile edge networks and the communication delay of mobile users. Inspired by this, in our approach, we comprehensively consider the two factors of communication delay and workload balancing during the placement of the edge server.
System model and problem definitions
Related notations involved in the mobile edge server placement model are explained in detail in Table 1.
Notations
Notations
In the mobile edge computing environment, the main components of the MEC system include mobile edge servers and various mobile devices, and the mobile edge server is usually deployed close to the base stations, so the system model of edge server placement can be regarded as an undirected network G = (B ∪ S, E). In this network, B represents the set of base stations, S represents the set of edge servers and E represents the relationship between the base station and the edge server. All base stations’ addresses can be used as the location of the edge server, and each base station must be assigned to an edge server. If the number of edge server is K, the K addresses of edge servers are known to B and all base stations are assigned to the K edge servers. Each edge server is fixedly forwarded the network requests from the users of all base stations in the area it covers. Due to the limited computing capacity of each edge server, and data transmission delay has relationship with the distances, the location of the edge server and the distance between the edge server and its assigned base station are very important. There are two key issues that need to be resolved during the placement of edge server: one is the place of the edge server, the other is the allocation approach of each base station.
The placement of the edge server is related to the data transmission delay between the base station and the edge server. This paper measures the data transmission delay by the distance between the edge server and the base station. Each base station has its own edge server and the delay in accessing the edge server is proportional to the distance between the base station and the edge server. The longer the distance, the bigger the delay. Therefore, the placement of edge server in mobile edge computing environments is optimized by minimizing the mobile user’s network communication delay as soon as possible.
The base station can directly access its own edge server through the link and offload the tasks to the edge server. However, the computing capacity of each edge server is limited, it is considered that making the workload of each edge server as balanced as possible which can balance the workload between the edge servers and prolong the service life of the edge server. Therefore, each base station needs to be allocated to achieve optimal load balancing when allocating to each edge server.
In order to describe the edge server placement system model more intuitively, we introduce an example as shown in Fig. 1. There are three edge servers s1, s2 and s3 in the figure and a total of 12 base stations accessing these three edge servers. Taking the s1 edge server as an example, s1 is responsible for processing user’s requests forwarded by these four base stations: b1, b2, b3 and b4. The workload of s1 is the sum of the four base stations’ workloads. Each solution of edge server placement in the model tries to meet the two goals: workload balancing and minimizing latency. Because the relationship of base stations and the relationship between base stations and mobile edge devices are not focused in this paper, it is not shown in Fig. 1. After understanding the system model of edge server placement in a mobile edge computing environment, the following in this paper will define the edge server placement issues.
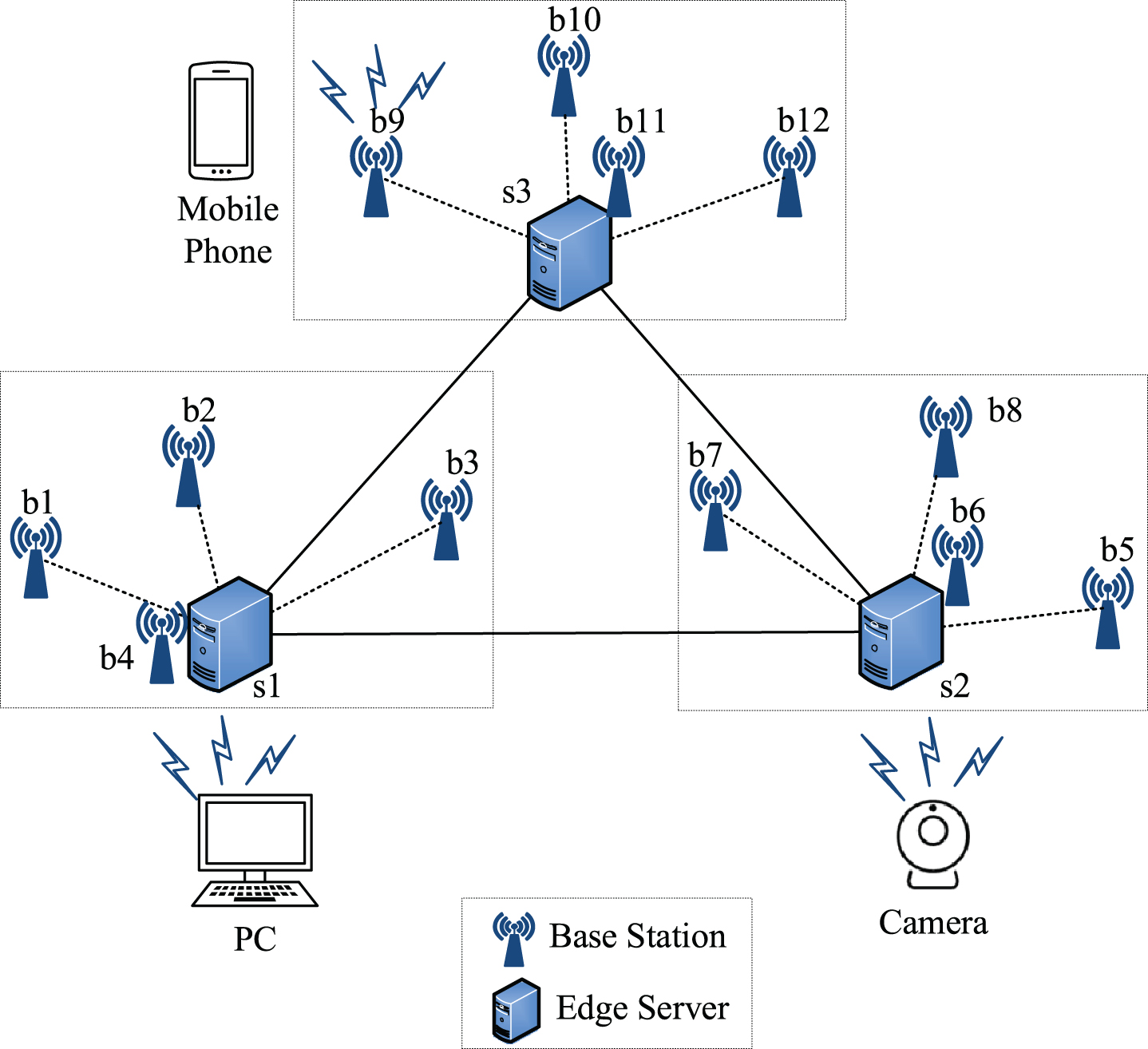
Edge server placement model.
We assume that in the undirected network G, S = {s1, s2, s3, . . . , s k } is an edge server set where k represents the number of edge servers, and each edge server is homogeneous and the computing capacity is limited and the same; B = {b1, b2, b3, . . . , b n } is a base station set where n represents the number of base stations, and the base station is responsible for processing all requests in mobile network from the users within its coverage. When the edge server is placed, each edge server is responsible for processing user’ requests forwarded by all base stations in its coverage. Each edge server’s workload is equal to the sum of the workloads of all base stations in its coverage. The d (P b i , P s i ) represents the distance between the location of base station b i and the location of the edge server s i which the base station is allocated to. Therefore, we need to solve two main problems: one is the placement of K edge servers, the other is the allocation approach of N base stations. As long as it can meet the needs of load balancing between the edge servers and minimizing latency when mobile users access each base station, the edge server placement solution is the exact optimal placement solution that we are looking for.
According to the previous description of the problem definition, we first give two optimization models: the delay minimization model and the workload balancing model. Let w represents the workload of data processed by the base station. The workload of base station b j is w bj and the workload of edge server s i is denoted as w s i , which is the sum of all the base stations assigned to it, so we define w s i = w b 1 + w b 2 + . . . + w b i .
The delay minimization model mainly considers that in the edge server placement scheme, the distance between the base station and its assigned edge server must be minimized, that is:
The workload balancing model mainly considers that the difference in workload size between edge servers is minimized as much as possible. In order to quantify the workload balancing of edge servers, the calculation equation for defining workload balancing indicators is designed as follows:
We make the problem of edge server’s placement as a multi-objective optimization problem. In order to obtain the Pareto optimal solution or weakly Pareto optimal solution, we use the weighting method to transform the multi-objective problem into a single-objective problem for solution. Combining the workload balancing model and the minimum delay model, the following weighted objective optimization function is established:
However, when seeking the optimal solution of the edge server placement, the following two constraints need to be considered:
(1) Each base station is assigned to an edge server and be assigned only to one edge server. There is no base station intersection between any edge servers, E
s
i
∩ E
s
j
= ∅. The sum of the base stations covered by all edge servers is equal to the total number of base stations. It is formalized as Eq. (6):
(2) The workload of each edge server is equal to the sum of the workloads from the base stations covered by edge server. It is formalized as Eq. (7):
(3) Each edge server’s workload can’t exceed the average workload of all the edge servers.
To concrete the problem of mobile edge server placement, it is necessary to determine where edge server is placed and which base station the edge server serves. From these, the workload between edge servers can be more balanced and user communication delays are smaller. In the mobile edge computing environment, the location of the edge server is generally configured at the location of a certain base station. On this basis, the base stations are clustered with the edge server as the center to achieve the purpose of minimizing access delay and workload balancing. In this paper, K-means algorithm and load-first heuristic algorithm are used to solve the problem of edge server placement. This optimization approach is called ESH-GM algorithm for short.
ESH-GM algorithm obtains the duration time of each user’s visit to the base station from the start time and end time of each user’s visit to the base station, and uses the time length as the workload of the base station to obtain the historical workload of the base station. ESH-GM algorithm itself takes into account the historical workload of the edge server in different time periods, and is able to cope with the dynamic characteristics of time.
K-means algorithm and Ant algorithm
K-Means algorithm is the most popular algorithm in clustering algorithm. It was first used by MacQueen in 1967 [32]. Compared with other clustering algorithms, K-Means algorithm has better effect and simple idea in clustering algorithm. It has been widely used. The K-Means algorithm is an unsupervised learning [33]. Euclidean distance is generally used as an index to measure the similarity between data objects. However, the K-Means algorithm also has its own limitations, such as the number of clusters k in the algorithm needs to be determined in advance, the initial clustering center is randomly selected and so on.
Ant system is an intelligent bionic optimization algorithm proposed by Italian scholars M. Dorigo inspired by the foraging behavior characteristics of ant populations in nature [34]. Ant colony algorithm is a population-based meta-heuristic approach. The optimization mechanism of the ant colony algorithm includes two phases: the adaptation phase and the collaboration phase. Each ant chooses and adjusts the path it considers optimal based on its accumulated information in adaptation phase. The larger the amount of information on the path, the more ants choose the path. During the collaboration phase, ants pass information between them. Ants share information in order to produce a solution that optimizes performance. Each ant has its own memory. A taboo list is used to store the nodes that the ant has visited.
Ant colony algorithm has the characteristics of positive feedback, parallel computing, and good robustness, so it has been widely used in many fields. However, ant colony algorithm also has some problems such as slow convergence speed, easy to fall into local optimum, premature convergence and so on. In view of the problems existing in the basic ant colony algorithm, many scholars have proposed many fruitful improvement measures, such as ant colony system [35, 36], max-min ant system [37], ant system with elitist strategy [38], ant system with elitist strategy [39] and ranking [40], etc. These classic improved algorithms effectively improve the optimization ability, but use a fixed mode to update pheromone and probability transition rules, lack flexibility, and fail to solve the premature convergence of the algorithm [41].
The clustering method of K-means algorithm is consistent with the characteristic of edge server placement’s access delay minimization, but the workload of edge server is not considered in the clustering process. The positive feedback mechanism of ant colony algorithm can speed up the base station allocation speed, which exactly meets the workload balancing requirements of edge server placement. Therefore, we combine the K-means algorithm with the ant colony algorithm and make corresponding improvements, make the most of these two algorithms, achieve server workload balancing on the basis of minimizing access latency and ultimately achieve the best overall performance.
Overview of ESH-GM algorithm
The ESH-GM algorithm is used to solve the problem of edge server placement. In the selection of edge server locations, we make some improvements in distance-based non-hierarchical clustering algorithm, divide the data into a predetermined K classes (K is the number of edge servers) on the basis of minimizing the error function. Using the location of the base station as the similarity evaluation indicator, the closer the location is, the higher the similarity is. Base stations with higher similarity belong to the same category. In practice, in order to obtain better results, we select a different initial clustering center in base station dense area when it runs each time and runs multiple times. After all base stations are assigned, the centers of the K clusters are recalculated. For edge data, the cluster center takes the mean of the cluster. When the center of mass does not change, stop and output the clustering result. In the edge server placement approach, we set the position of the base station where the centroid is located as the position of the edge server from the clustering results. Since the clustering approach we use is clustering using the location as the similarity evaluation indicator, it meets the requirements of minimizing communication delays of each base station in the problem of edge server placement.
After determining the locations of edge servers, each base station needs to be allocated to K edge servers and try to meet the workload balancing of each edge server. In the base station allocation process, we have improved the pheromone update method and probability transfer rules of the ant colony algorithm. The update of the pheromone matrix is mainly based on whether the workload currently carried by the edge server has reached the upper limit of the edge server’s workload.
The pheromone matrix T t is used to record the historical experience obtained by ants in traversing each edge server. All base stations can share the information of the accumulated edge server from T t during the search of the edge server, so find the closest edge server which doesn’t exceed edge server’s average workload.
The taboo table is used to record the edge servers that the ants have visited and the workload has exceeded the average workload. It is initially empty and is gradually added during the traversal process until all edge servers have been added. The taboo table stores the workload that has reached edge servers’ average workload. All edge servers in the table no longer participate in base station allocation. Probabilistic transfer rules are based on pheromone matrices and taboo table.
The element τ ij in the pheromone matrix T t is the pheromone accumulated by the base station b i placed on the edge server s j , and its value is the workload of the base station b i served by the edge server s j . At each base station allocation, the pheromone matrix will judge the workload of the current edge server, if the edge server’s workload has reached the upper limit, τ ij is set to 0 and the edge server is added to the taboo table, can not participate in allocation; if not reached, the base station belongs to the closest edge server and use the load value of the base station as τ ij , the taboo table does not change. In the next base station allocation process, the pheromone matrix and taboo table are browsed to select the edge server to be allocated and achieve the optimal choice of minimizing communication delay and maximizing load balance.
ESH-GM algorithm model
The ESH-GM algorithm is mainly used to solve the problems of edge server location selection and base station allocation. We define the following two equations:
The clustering approach used in the ESH-GM algorithm is that the location of the edge server is set at the center of a cluster, and the location of the base station in the cluster is the same as the location of the edge server p s j . For example, if the base station b i is selected as the edge server s j address, the base station’s address b i is the edge server’s address s j , so we have p s j = p b i .
The edge server’s position obtained through the ESH-GM algorithm can meet the requirements of delay minimization and obtain the optimal edge server placement scheme.
K edge server locations can be obtained from the optimal edge server placement scheme a, and next step is base station allocation. Firstly, calculate the average workload of the edge server, as shown in the following equation:
In the process of base station allocation, the pheromone matrix T
t
and the taboo table F in the ant colony algorithm are introduced. The pheromone matrix T
t
is defined as follows:
In Eq. (12), when base station b
i
is not allocated on s
j
, τ
ij
is 0; when base station b
i
is allocated on s
j
, τ
ij
is the workload value of the base station b
i
. After the base station allocation, the sum of all elements on the j column from the pheromone matrix T
t
is the workload of the edge server s
j
, so
The taboo table F is a list of edge servers whose workload are exceed the average edge server workload
In the base station allocating process, the load priority allocation principle is adopted, the base station b i with a heavy load is assigned preferentially.
When the base station b
i
traverses the list of edge servers outside the taboo table, it find the nearest edge server s
j
to determine: if the sum of edge server s
j
pheromone in the pheromone matrix and the workload w
b
i
exceeds the edge server average workload
After completing the base station allocation, we output the allocation scheme C (b i , s j ), b i ∈ B ∪ s j ∈ S, and the workload standard deviation w under this scheme, as shown in Eq. (13). The average delay as shown in Eq. (14):
Experiments and analysis
Dataset description
These experiments use a real base station dataset of Shanghai Telecom, which contains 562,914 records accessed by 6,262 mobile users on 2,768 base stations. The dataset records the start time and the end time of each user’s access to the base station within 15 days, and the base station’s latitude and longitude in detail. Using Google map tools, we make a distribution map of the Shanghai base station in Fig. 2.
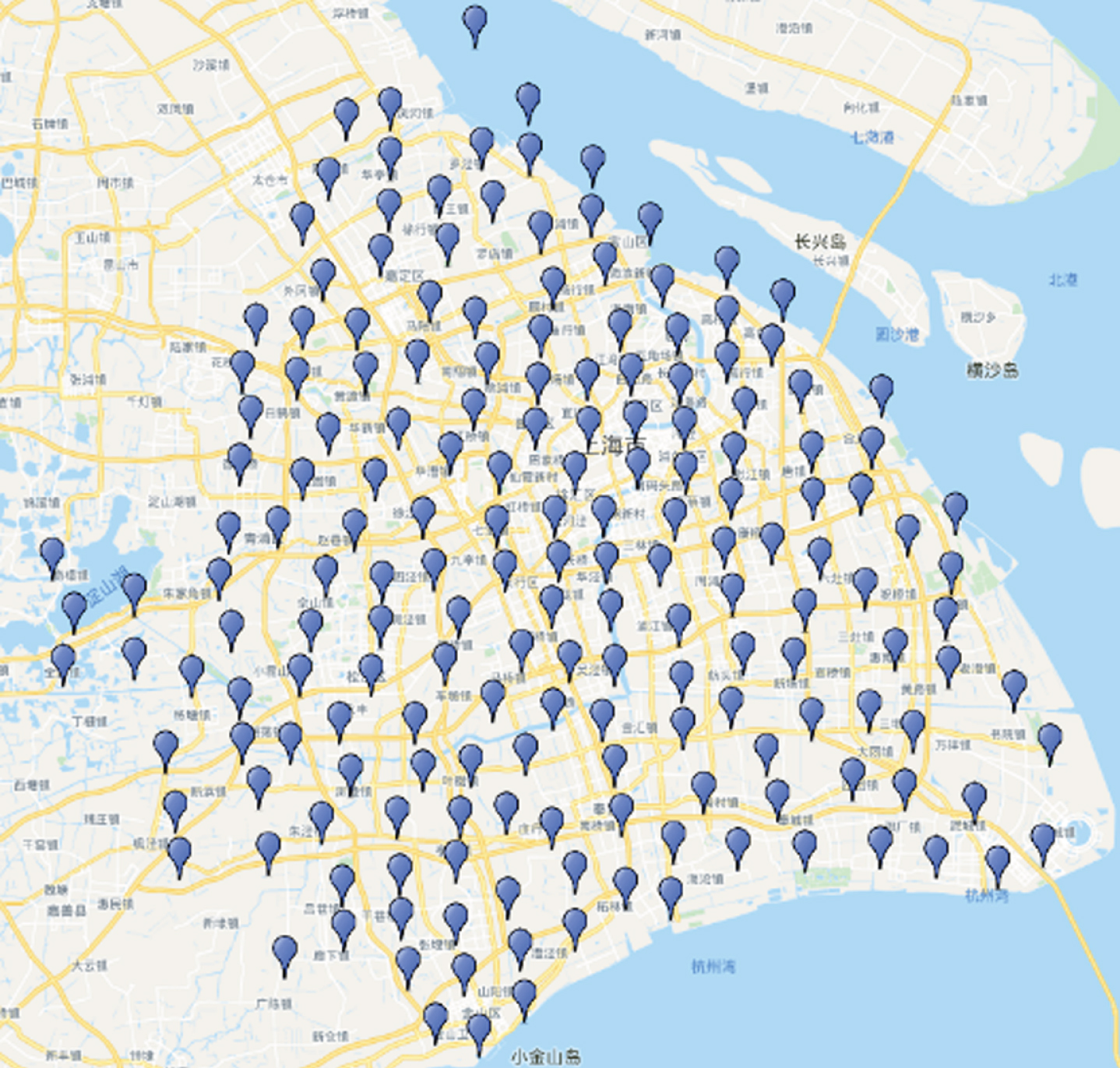
Shanghai base station distribution map.
By zooming in the distribution map, we found that the distribution of base stations is unbalanced, as shown in Fig. 3 and Fig. 4, where the red letters under the base station points represent the workload of each base station.
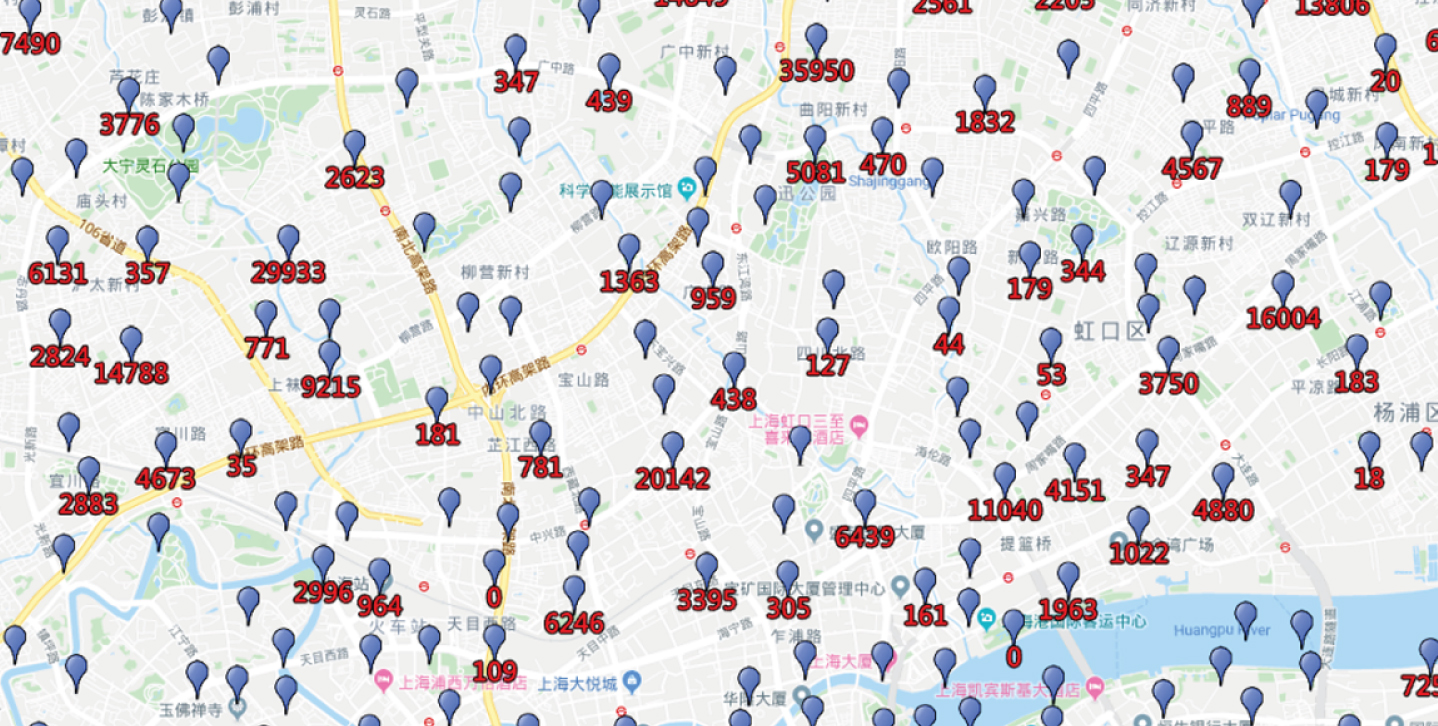
Shanghai base station densely populated area.
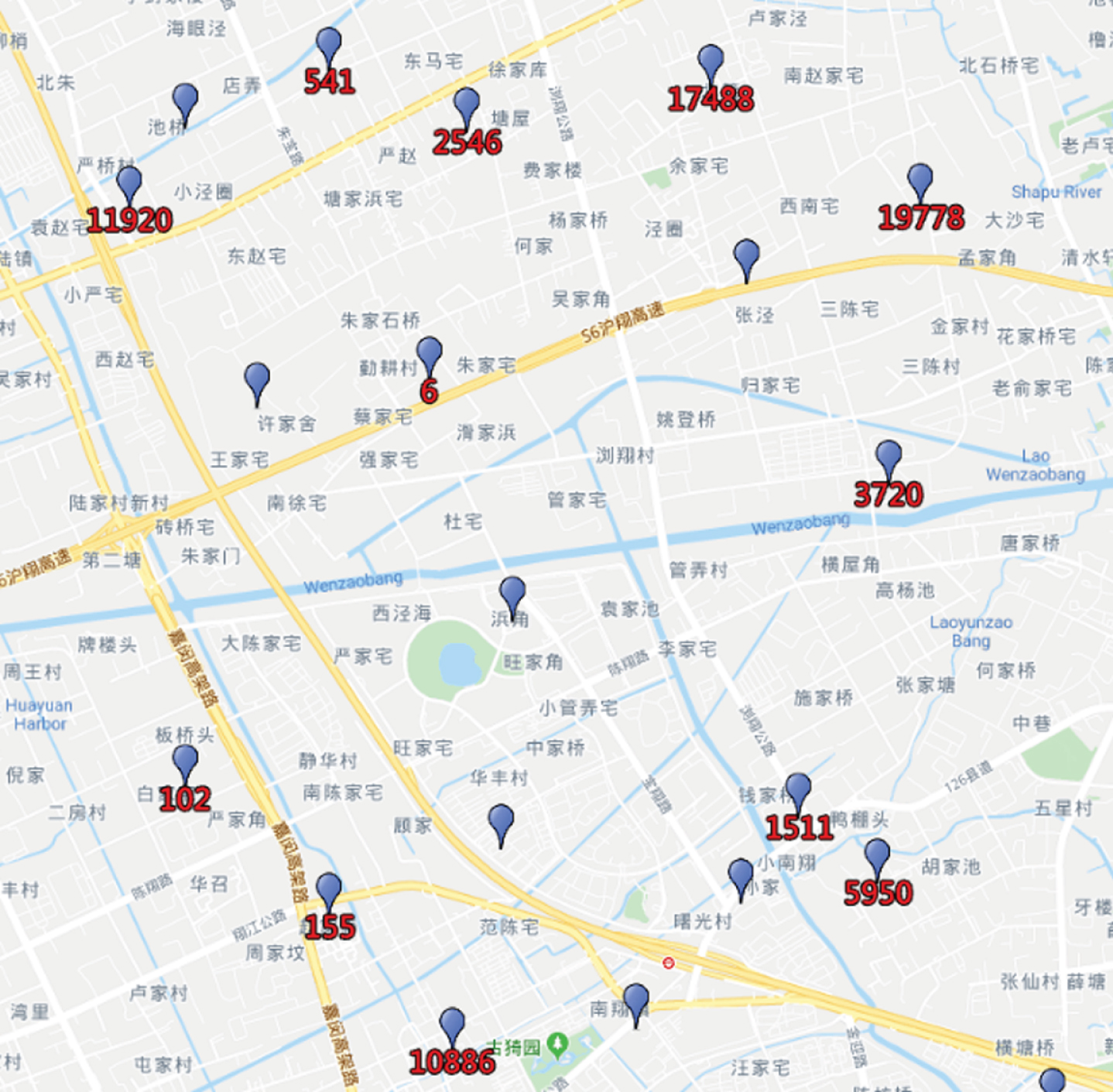
Shanghai base station distribution sparse area.
Based on a statistical analysis of the workload dataset of 6,262 mobile users on 2,768 base stations, we randomly select 10 users’ data, as shown in Table 2, and it is easy to find that there is serious unbalanced between the workload of base stations.
Workload of each base station in Shanghai
To evaluate the performance of different approaches in terms of the workload balance and the communication delay in our experiments, Top-K, Random, K-means and ESH-GM approaches are mainly used for comparison. Three experiments are designed as follows: The number of base stations n is increased from 300 to 3000 with a step size of 300, with the placement ratio of the edge server PR = 0.1 (for example, 300 base stations are configured with 30 edge servers). The number of edge server K is increased from 100 to 500 with a step size of 100, with the number of base stations n is 3000. The ESH-GM approach is used to evaluate the impact of different placement ratio of edge server on the workload balance and the communication delay.
Baseline algorithms
Top-K, Random and K-means approaches are mainly used for compare with ESH-GM approach.
Our problem is the placement of the edge server and it must solve two sub-problems: the first is the locations of edge servers. We use K-means approach to find a proper edge server’s location in the global environment to perform the second problem of base station allocation. The ant colony algorithm is a probabilistic algorithm used to find the optimal path and can be used in the second problem of base station allocation, and it cannot solve the whole problem alone. In our paper, the K-means approach is compared with ESH-GM.
Comparison results with the number of base stations
When the placement ratio PR of the edge server is 0.1 and the number of base stations n is increased from 300 to 3000, as shown in Fig. 5. The average access distance of the base station of ESH-GM approach is the smallest, followed by K-means, Top-K and Random. In overall, the approach of Random obtains the worst results in communication delay. With the number of base station n increases, whereas the placement ratio of edge servers remains, the average access distance of base station has shown a descending trend in ESH-GM approach.

Base station access average distance under different placement approaches when PR = 0.1.
When the number of base stations becomes larger and the number of edge servers gradually increases, the standard deviation of the workload of each edge server gradually decreases. Top-K approach uses the top K base stations with the largest workload as the edge server address, so the standard deviation of this approach’s workload is the smallest, and the result of ESH-GM approach is the second, and the K-means approach obtains the biggest standard deviation, which have been shown in Fig. 6.
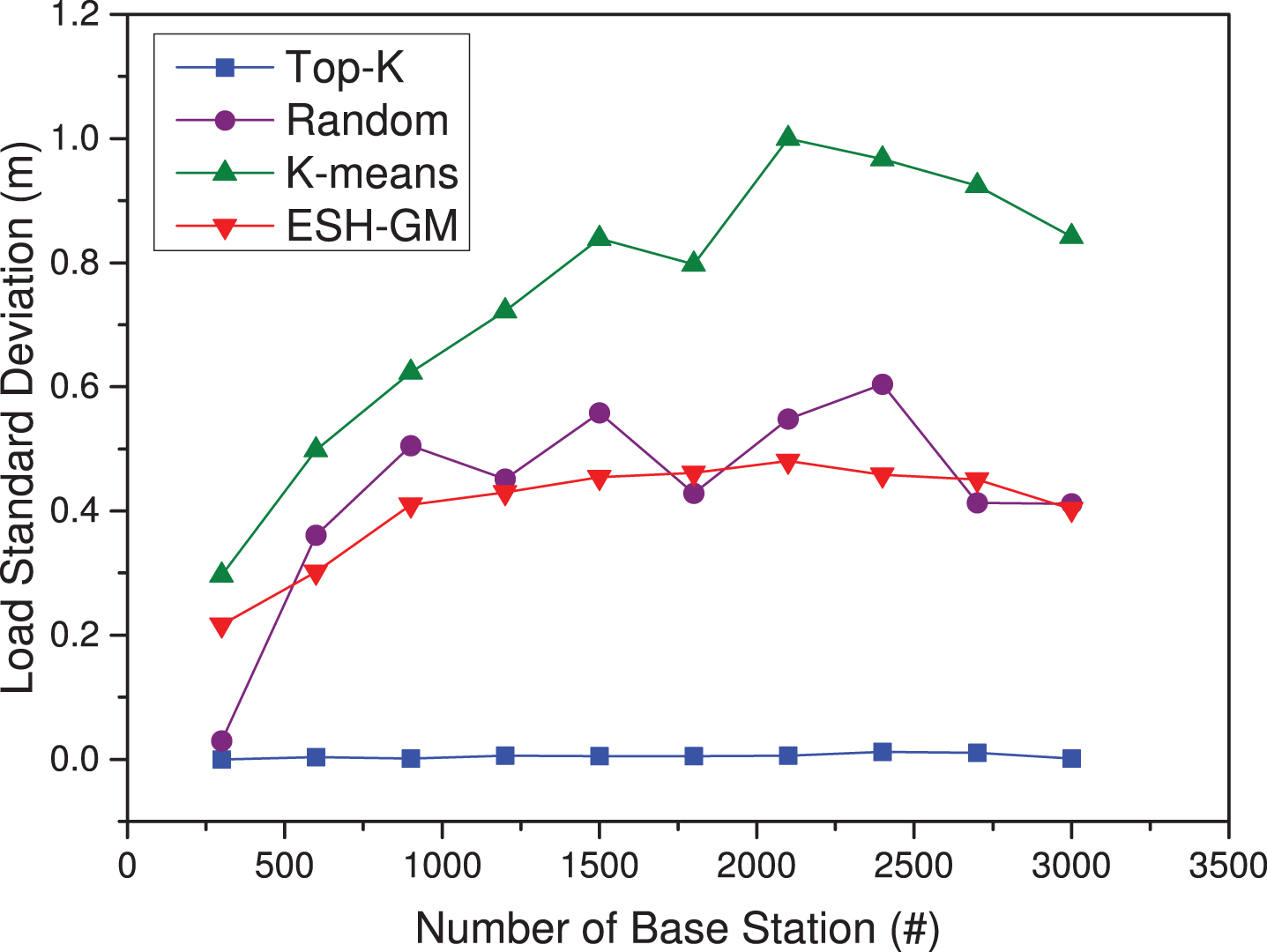
Load standard deviation under different placement methods when PR = 0.1.
Considering the two attributes of average distance and the standard deviation of the workload together, we set the weight of each attribute λ to 0.5, which means that the importance of access delay and the importance of workload balancing in mobile edge server placement are the same. From Fig. 7, we found that when the number of base stations n is more than 800, the average distance of the base station access and the standard deviation of the workload in ESH-GM approach is the smallest, that is nearly outperforms others.

Comprehensive performance value under different placement methods when PR = 0.1.
According to Equation (3), we take λ = 0.5, and the value of pw (a) in the four different placement approaches is shown in Table 3.
Comprehensive performance value under different placement methods when PR = 0.1
The number of base stations n is 3000, and the number of edge server starts from 100 to 500 with the step size of 100. The average access delay and workload standard deviation of the four approaches under different edge server numbers are evaluated. As shown in Fig. 8, as the number of edge servers increases, the average access distance of base station decreases, that is the more edge servers are deployed, the more the nearest edge server can be selected by the base station, so the average access distance gradually decreases. Among the four approaches, ESH-GM obtains the minimal average access distance, and Random approach obtains the worst result.
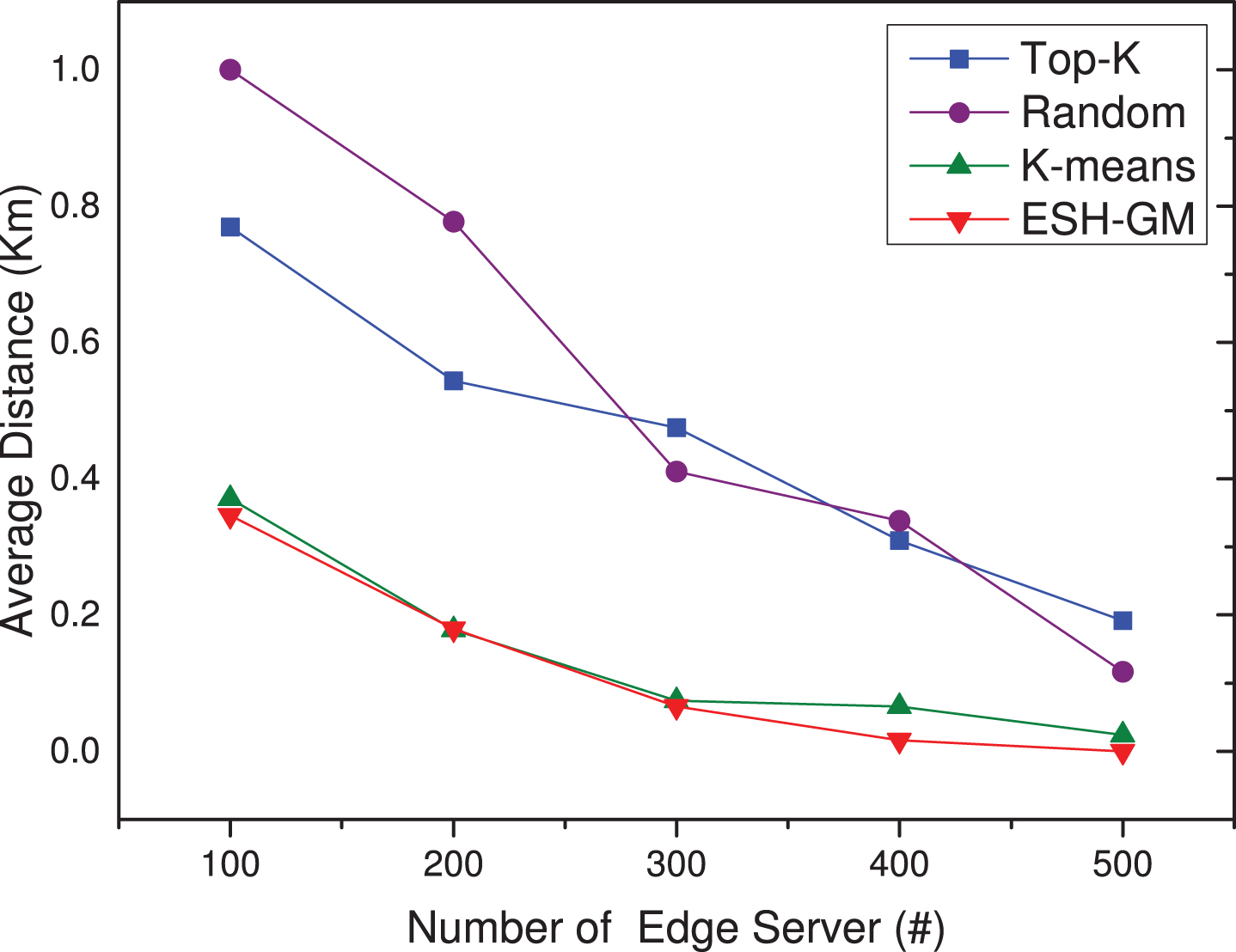
Base station access average distance under different placement approaches when K changes.
In Fig. 9, the standard deviation of the access workload of the edge server also gradually decreases as the number of edge servers increases. The workload standard deviation of Top-K approach is the smallest, followed by the ESH-GM, Random, and K-means, as shown in Fig. 9. According to Equation (3), we take λ = 0.5, among the four placement approaches, pw (a) is the comprehensive performance parameter shown in Fig. 10.
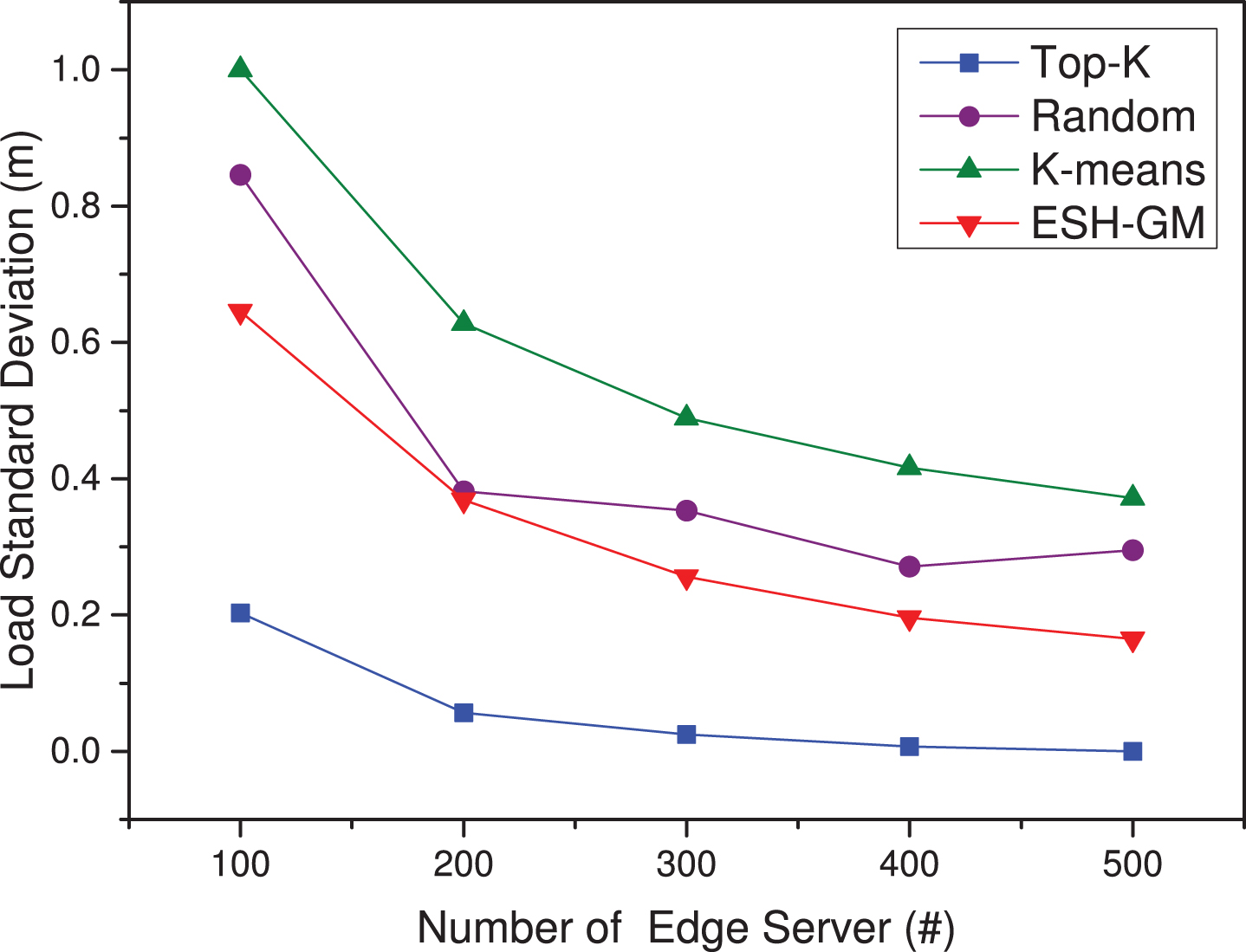
Workload standard deviation under different placement approach when K changes.
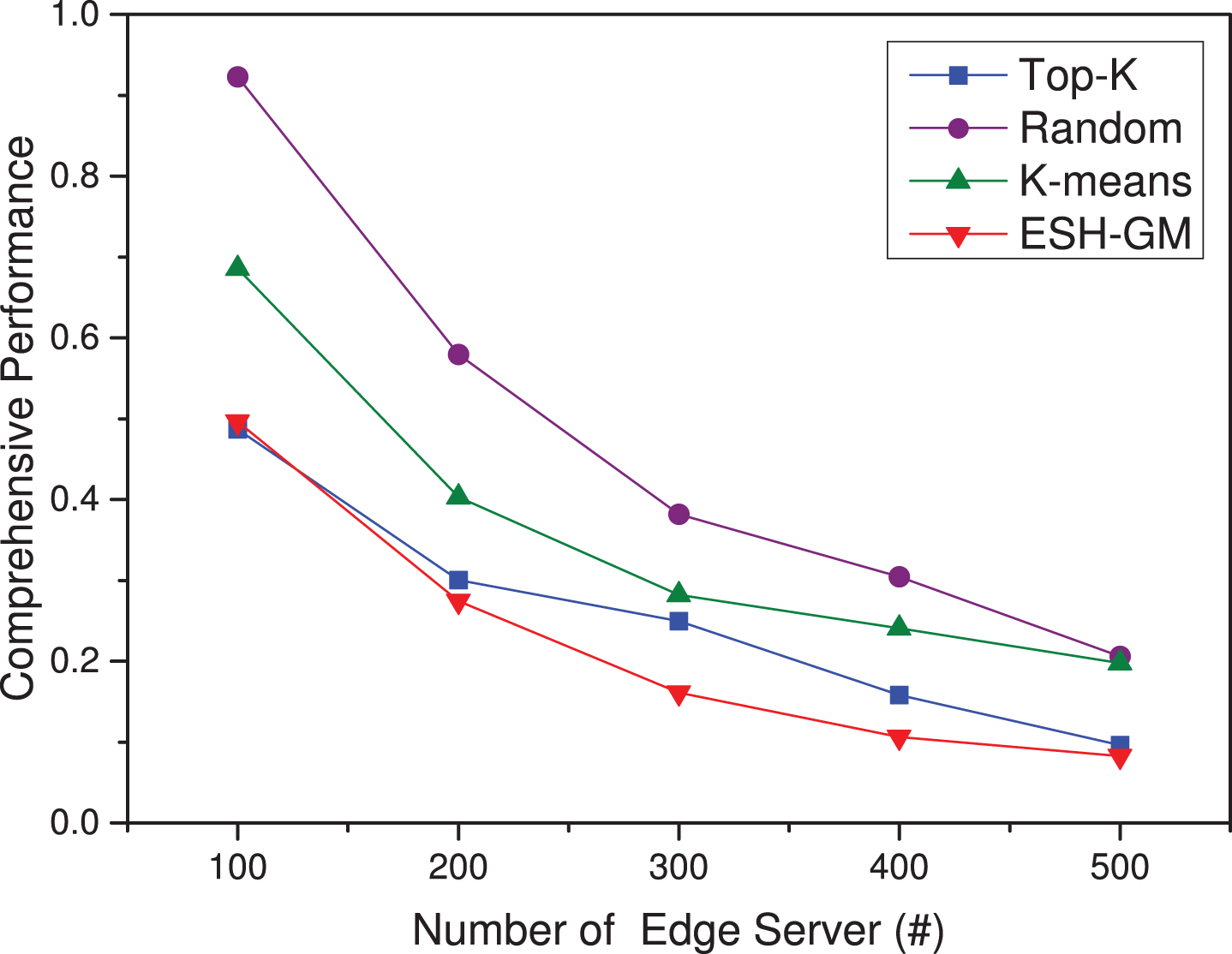
Comprehensive performance value under different placement approaches.
The pw (a) is shown in Table 4. By Comparing the performance of the edge server placement among the four approaches, ESH-GM outperforms others.
Comprehensive performance value under different placement methods when K changes
The execution time compared results under different placement methods is shown in Table 5 and Table 6. When the edge server placement ratio PR = 0.1, the number of base stations reaches 3000, and the execution time of ESH-GM method spent 4.4987 seconds. When the number of edge servers K changes to 500 and the number of base stations reaches 3000, ESH-GM method spent around 5.2389 seconds.
Execution time under different placement methods when PR = 0.1
Execution time under different placement methods when PR = 0.1
Execution time under different placement methods when K changes and n = 3000
When the number of base stations n is 3000, the edge server placement ratio PR is changed in the range [0.03, 0.07, 0.10, 0.13, 0.17], the base station access delay and workload standard deviation are shown in Fig. 11. Without considering economic costs, the larger the edge server placement ratio, the smaller the average access delay of each base station and the workload standard deviation of each edge server smaller.

Comparison of performance values under ESH-GM placement method when PR changes and n = 3000, in terms of average distance and load standard deviation.
The objective optimization function in the edge server placement problem is a comprehensive consideration of two factors: access latency and edge server workload balancing. In the comparison results of the experimental data, our method is only slightly better than the K-means in the access latency result, but it is far superior to the K-means in edge server’s workload balancing. In comparison of comprehensive performance, our method is also optimal. In terms of method execution time, ESH-GM algorithm has no advantage over three other methods, but during all experiments, when the number of base stations equals 3000 and the number of edge servers reaches 500, the average execution time of the algorithm is still within 6s. In edge server placement issues, we don’t need real-time results. Therefore, this method is feasible in solving practical problems.
Conclusions
Mobile edge computing is an important technology for extending remote computing resources. Through the placement of edge servers to improve the access quality of mobile users, this paper studied the placement problem of edge servers. In mobile edge computing, the placement problem is considered as a multi-objective optimization problem and an optimal deployment scheme is proposed. ESH-GM has been proposed which is the combination of K-means algorithm and improved ant colony algorithm to extensively evaluate the performance of edge server workload balancing and communication delay under four different approaches. We have designed three experiments using real Shanghai Telecom’s base station dataset and the experiment results show that our approach ESH-GM is better than other typical approaches.
Because workload balancing and communication latency are two factors that affect each other, the deployment of edge servers is a more complex problem. How to dynamically deploy edge servers, which can be turned on and off in real time is our next future work.
Conflicts of interest
We declare that there are no conflicts of interest in this paper.
Footnotes
Acknowledgments
This research is supported by the National Natural Science Foundation of China under grant no. 61872138 and 61602169, and the Natural Science Foundation of Hunan Province under grant no. 2018JJ2135, as well as the Scientific Research Fund of Hunan Provincial Education Department under grant no. 18A186.