
Abstract
Wind energy, a highly popular renewable clean energy, has been increasingly valued by the international community and been leaping forward. However, the original wind speed signal characterized by intermittent fluctuations impose heavy burdens on wind speed forecasting of wind farms. This study proposed a wind speed forecasting method by complying with a model integrating the Variational Mode Decomposition (VMD) and the Improved Multi-Objective Dragonfly Optimization Algorithm (IMODA). First, the VMD was adopted to decompose the original wind speed signal, as an attempt to obtain multiple sub-sequences (IMFs) exhibiting stable frequency domain. Second, to simplify the calculation, the sample entropy (SE) was adopted for the sequence recombination, and the respective recombined sub-sequence of the wind speed was forecasted by using four advanced neural networks. Lastly, the IMODA algorithm was adopted to fuse the forecasting results of the neural network, and the results of the optimal wind speed were forecasted. To verify the effectiveness and adaptability of the algorithm, the wind farm data in four different regions were forecasted. As indicated from the results, this algorithm could outperform other algorithms in the comprehensive forecasting accuracy and the model calculation time, and it could be effectively applied for the wind speed forecasting in wind farms.
Introduction
As the concept of low-carbon environmental protection is progressively deepened, the development and utilization of wind energy have increasingly aroused the attention of the international community [1]. Accurate wind speed forecasting is capable of reducing the cost of wind power generation operation, rationally arranging dispatching plans of power sector, and laying reliable bases for market bidding, which is of great application significance in economy and engineering [2, 3]. However, the randomness and volatility of wind power increase the difficulty of power dispatching. Currently, domestic and foreign scholars have conducted numerous researches on wind speed forecasting [4], from the perspective of modeling mechanism (e.g., physical methods, statistical methods and intelligent methods) [5–7]. On the whole, the physical method builds the wind speed mathematical model of the wind turbine’s wheel height by using atmospheric boundary layer dynamics, boundary layer meteorological theory and physical processes. As impacted by the specific geographical conditions and operating conditions of wind turbines, the model exhibits poor versatility [8]. Compared with the physical method, the statistical method exhibits a strong generalization ability, and it is not required to consider the meteorological characteristics around the wind turbine. In [9], an ARIMA with a regression analysis was applied to the practical short-term wind forecasting. Kalman filtering method [10] was adopted to optimize the time series model. It could dynamically modify the weights based on the ARMA model. As indicated from many documents, time series models are only capable of obtaining good forecasting accuracy in short-term scale scenarios [11]. Intelligent learning wind speed forecasting represented by artificial neural networks can approximate any non-linear function by training data to determine the mapping relationship between variables, thereby making the model more flexible [12–14]. Yin et al. [15] proposed an LSSVM forecasting model, which achieved favorable forecasting results. Xu et al. [16] established an optimized RBF neural network wind speed forecasting model, which has higher forecasting accuracy in short-term wind speed forecasting.
To improve the forecasting accuracy, given the non-stationary characteristics of wind speed, scholars worldwide proposed a method of modal decomposition of the original wind speed, which covered the EMD [17], the EEMD [18], the CEEMDAN [19], the EWT [20] and the VMD [21] and other decomposition methods. Zhang et al. [18] introduced a hybrid model of EEMD and VNN, which could effectively mine the characteristics of power time series and obtain higher forecasting accuracy. Zhang et al. [19] proposed a fully integrated CEEMDAN method based on the EEMD. By adaptively adding positive and negative white noise, the problem that the EMD is prone to modal aliasing is solved, and the iteration is effectively reduced. The number of times increases the reconstruction accuracy, and it is more suitable for analyzing nonlinear signals. Liu et al. [20] used the EWT to decompose the raw wind speed data into several sub-layers, and then they forecasted the low and high frequency wind speed sub-layers by using two different networks. Zhang et al. [21] introduced a forecasting model based on the VMD and the Lorenz disturbance models. The VMD is capable of decomposing the wind speed into several IMFs that fluctuate around the center frequency according to needs. Reducing the effect of uncertain factors helps restore the fluctuation characteristics of the wind speed signal during the forecasting process, while improving the forecasting accuracy. Gu et al. [22] used the VMD and the optimized k-means algorithm [23], and they used radial basis function neural network for the forecasting. This method can effectively improve the regularity of wind speed, as well as the accuracy of wind speed forecasting. Compared with other data processing methods, the VMD more significantly impacts the processing of non-stationary and non-linear signals, and it can more effectively recover the fluctuation characteristics of the signal.
Though the forecasting models based on VMD show that the method has a favorable forecasting effect, the scholars all used a single forecasting model to predict the decomposition sub-sequence of wind speed. However, different frequency domain subsequences exhibit different characteristics. For a single forecasting model, each sub-sequence attribute cannot be satisfied simultaneously. Accordingly, to improve the forecasting accuracy, multiple single neural network forecasting models are used to construct a combined forecasting model to fully exploit the advantages of each forecasting model.
To study combined models, Zhang et al. [24] proposed a combined forecasting model based on the CEEMDAN and the CLSFAP. The method uses the CLSFAP optimization algorithm to find the optimal weight coefficient. Besides, it effectively exploits the advantages of each single forecasting model and greatly improves the forecasting accuracy of the model. Compared with the single neural network model and the benchmark ARIMA model, the combined model exhibits the optimal performance. Xiao et al. [25] adopted the CSO optimization algorithm [26] to determine the optimal weight coefficient of the combined model. Hirose et al. [27] built a k-nearest neighbor algorithm and the MLR combined forecasting model. Since single forecasting models solved the same forecasting problem, their forecasting results were highly correlated, and MLR methods may encounter collinearity or singularity problems, thereby resulting in inaccurate weighting coefficients. In accordance with the theory of non-negative constraints, Niu et al. [28] developed a fully integrated empirical mode decomposition with adaptive noise and a multi-objective grasshopper optimization algorithm. The combined model considers the linear and nonlinear characteristics exhibited by the sequence, successfully addresses the limitations of the single model, and improves the stability and accuracy of the forecasting results. In brief, wind speed forecasting needs accuracy, while requiring the stability of the forecasting algorithm. Single objective optimization algorithms fail to comply with the requirements of accurate and stable wind speed forecasting simultaneously, while multi-objective optimization algorithms can more effectively balance the relationship between objective functions.
To further improve the accuracy of wind speed forecasting, after fully analysis on the advantages and disadvantages of each decomposition method and weight optimization method, a combined wind speed forecasting model based on the VMD and the IMODA was proposed. First, the original wind speed data were decomposed into IMF components of different frequencies by the VMD. In order to simplify the computation, the sample entropy (SE) was adopted to recombine the subsequences, and several components with typical characteristics were obtained. Subsequently, four kinds of neural networks were adopted to build the forecasting models of each component. Lastly, the method of IMODA was adopted to perform weighted fusion of the forecasted results, which synthesized the advantages of each forecasting model to obtain wind speed forecasting results. Furthermore, compared with a variety of forecasting models, the forecasting effect of the model was analyzed.
The main contributions of this paper are listed as follows: In order to improve the prediction accuracy and reduce the computational complexity, while preserving the fluctuation characteristics of the wind speed series, a parameter-optimised VMD decomposition method is used to decompose the original wind speed to obtain wind speed signals of different frequencies. In this paper, a multi-objective optimisation algorithm, IMODA, is used to combine the wind speed results predicted by different models in a weighted manner to achieve the optimal prediction results.
The rest of this study is organized as follows: In Section 2, the VMD and the single forecasting models are introduced. In Section 3, the process of the IMODA combination model is described. In Section 4, the forecasting results of the combined model are analyzed and compared. In Section 5, conclusions are drawn. Table 1 lists the abbreviations used in this study.
List of Abbreviation
List of Abbreviation
Data processing
Data preprocessing: The large amount of raw data collected from wind farms could be very messy, with more or less duplicate data and missing data. Proper data processing of the mentioned anomaly data would effectively improve the forecasting accuracy of the wind speed forecasting model. Imputation of missing data: In the modeling calculation process, complete wind power data is required to make more accurate wind speed predictions for wind farms. Therefore, the data is checked for completeness before pre-processing the data, and the data is filled in according to the missing types. In this paper, we use the mean fill method [29] to fill the missing data by finding the average of the values before and after the missing values. Outlier handling: During transmission, abnormal communication lines, poor contact, abnormal acquisition software, and inconsistent computer and acquisition time can cause wind power data outlier situations. In this paper, the DBSCAN algorithm [30] is selected to reject outlier data such as wind turbine shutdown and underpower. Data normalization: The units of different eigenvalues in the original data were different, and the order of magnitude might vary greatly. If the mentioned data were not processed and analyzed, the feature quantity with small value range would be covered by the considerable features and cannot be exploited. Thus, normalization was performed before the data input model, so all the characteristic variables were normalized to the same order of magnitude, which could simplify the calculation and accelerate the convergence of the model. Lastly, the actual value of the forecasting was calculated through denormalization. The data characteristics were generally normalized to [–1, 1], as expressed in (1):
Where Amax and Amin denote the maximum and minimum values of feature A, respectively, which are p
i
eigenvalues, and
The VMD refers to a novel adaptive signal processing method, exerting a significant processing effect on non-stationary and nonlinear signals [31]. Its adaptability can be manifested in determining the number of modal decompositions of a given sequence by complying with the actual situation. In the searching and solving processes, the optimal center frequency and limited bandwidth of each mode could be adaptively matched to realize the effective separation of IMFs and the frequency domain segmentation of the signal, to obtain the effective decomposition of the given signal. Lastly, the optimal solution of the variational problem was obtained. The VMD is expressed as a constrained variational problem:
Where f (t) expresses the original signal; t implicates the time script; K denotes the total number of the modes; μ k denotes the kth mode; σ (t) represents the Dirac distribution; ω k is the center frequency. Moreover, the mode with high-order denotes the low-frequency sub-layers.
To convert the mentioned optimization problem into an unconstrained one, the penalty term and Lagrangian multipliers were employed, which is expressed as:
Where α is the balancing parameter of the needed data fidelity constraint.
The mentioned variation problem was solved by using the ADMM (Alternate Direction Method of Multipliers), which could determine the saddle point of the Lagrangian expression by updating:
According to the VMD theory, when using the VMD algorithm to process signals, the modal component k and the penalty parameter α should be initialized, and different parameter settings can lead to different VMD results. Based on the parameters set manually, the decomposition result will be uncertain and random. Accordingly, optimization algorithms should be used to find the optimal parameter combination. In the literature [32], Liang et al. adopted the MIGA to optimize VMD parameters and achieved good decomposition results in bearing vibration signals. This study applied it to the decomposition of wind speed signal. The optimized parameter values are α=2000 and k = 10. The decomposition results are presented in Fig. 1.
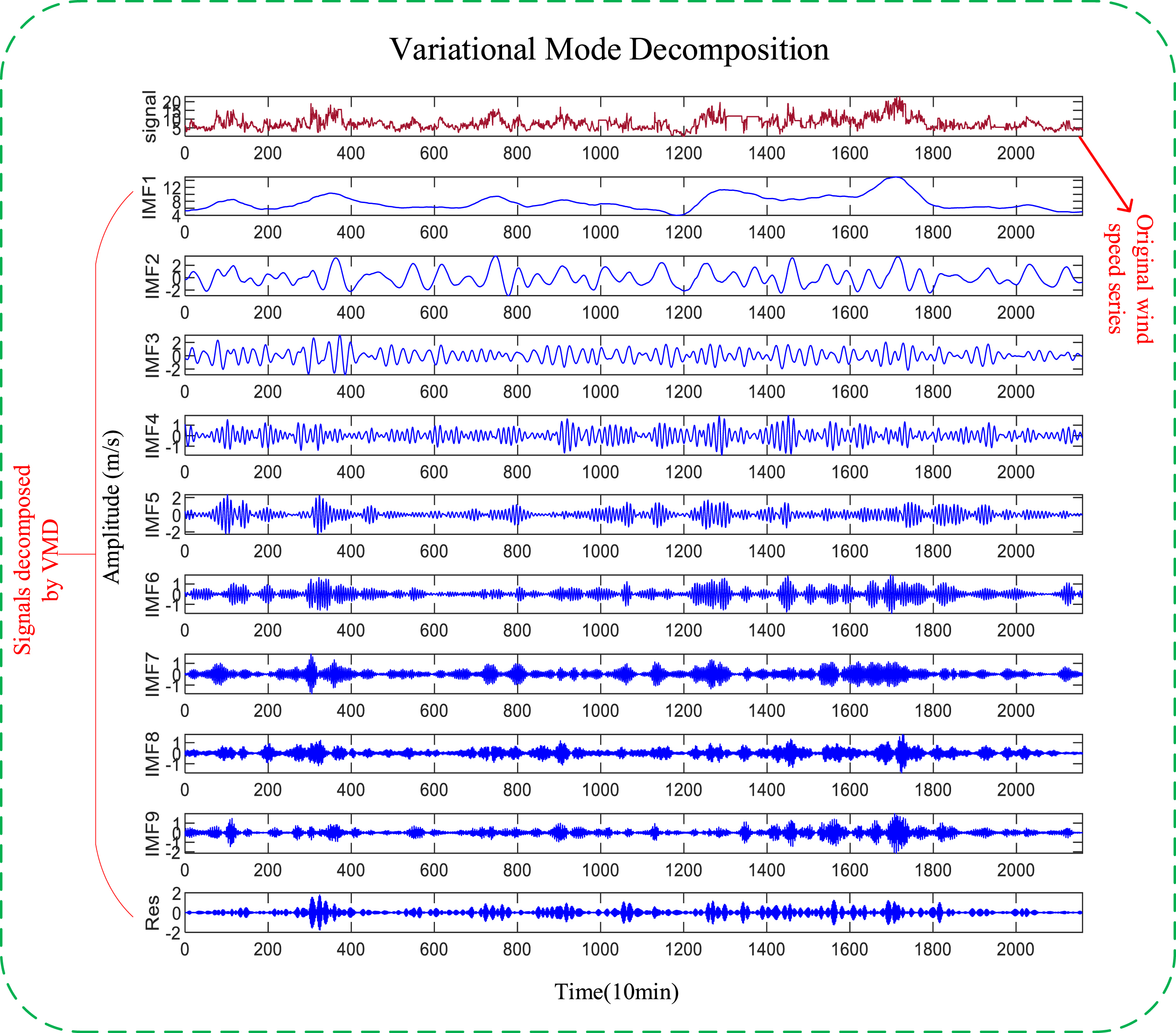
The IMFs of the VMD method.
For the multiple IMF components decomposed by the VMD, if the prediction model is established separately, the calculation amount will increase, and the correlation between the individual components will be ignored. To simplify the calculation, the characteristics of the similar sequences were highlighted, and the components with correlation were recombined. The sample entropy in 2004 refers to an algorithm proposed by Richman and collaborators to improve the time series complexity for the approximate entropy improvement [33]. The smaller the value of the sample entropy, the lower the complexity of the sequence would be. Conversely, the sequence would be more complex. Given this, the sub-sequence was processed by sample entropy.
The sample entropy is represented by SampEn (m, v, N), where N is the data length, m denotes the dimension, and v is the tolerance. For a given vector X(i), count the number of j(1≤j≤N-m,j≠i) with distance less than tolerance v between X(i) and X(j),denoted as B(v). With N as a finite value, the sample entropy estimate is expressed as:
Though the sample entropy was related to the values of m and v, the sample entropy exhibits high consistency, and the entropy value change trend was not affected by m and v. Typically, m was 1 or 2, and v was 0.1 to 0.25 SD, where SD denotes the standard deviation of the sequence. In this study, m = 1, v = 0.15SD, as shown in Fig. 2, the sample entropy value distribution of the sequence. The sample entropy values of some subsequences were relatively close, and the IMF components were regrouped. The larger the sample entropy value, the higher the complexity would be. The complexity of IMF2 and IMF3 should be separately modeled. The entropy values of IMF1, IMF4 and IMF5 were close to each other and should be merged into one subsequence for modeling. The complexity of IMF6 IMF10 was combined into one subsequence for modeling. Reorganized IMF1 IMF10 into IMF1’, IMF2’, IMF3’, IMF4’.
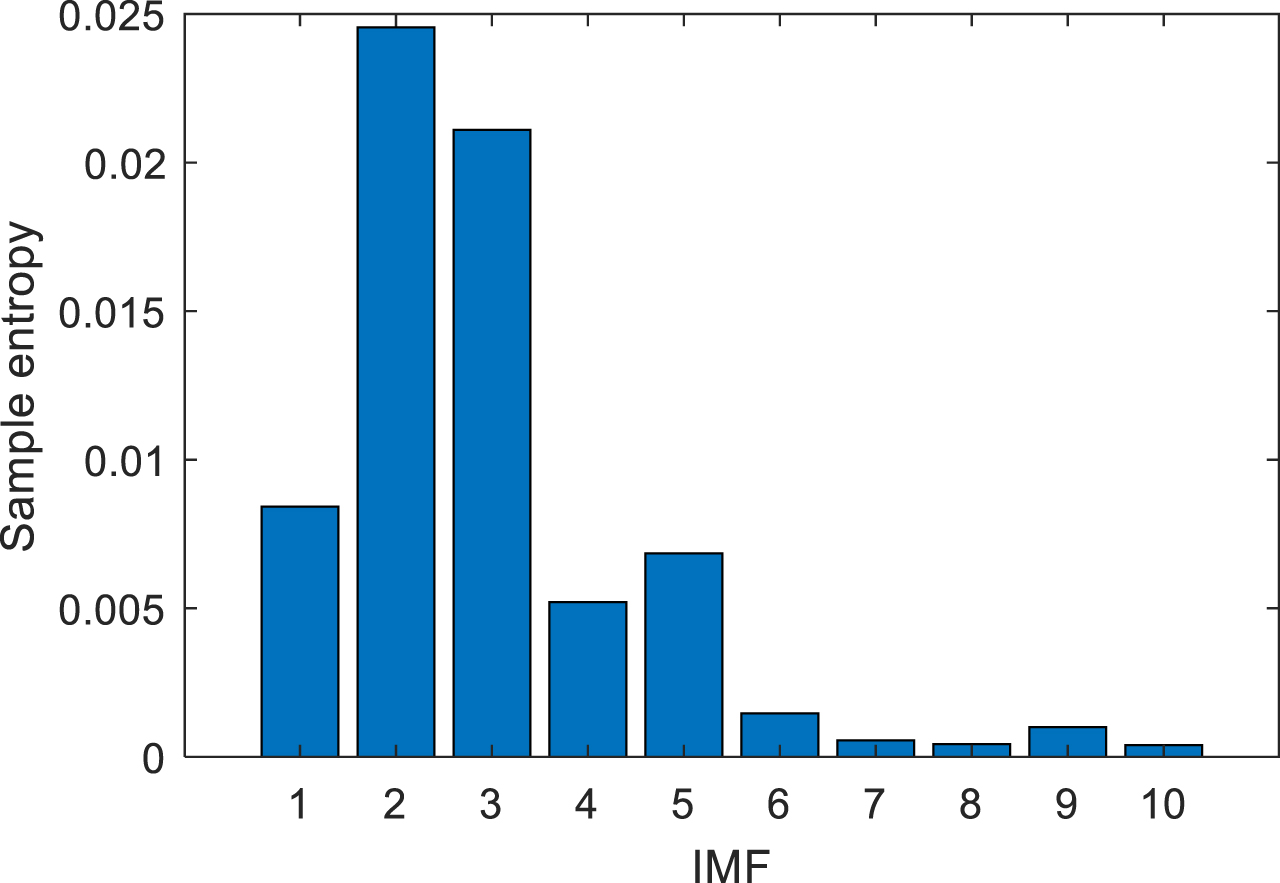
The SampEn of the IMFs.
(1) BP neural network
The BP neural network refers to a multi-layer forward neural network based on the gradient descent method [34]. The learning process could roughly have two parts, i.e., forward calculation and back propagation. The back propagation falls to two stages of updating and learning.
Where w ij denotes the weight between nodes i and j; η is the learning speed; α expresses the impulse parameter; t is the current number of iterations; E is the error hypersurface.
(2) RBF neural network
The RBF neural network structure comprises an input layer, an implicit layer and an output layer, which is a typical feedforward neural network [35]. Set the input of the RBF neural network as X = [x1, x2, ⋯ , x
p
], and then the function of the h-th hidden node is set as follows;
Where c h and σ h respectively represent the center and width of the h-th hidden layer node kernel function; ∥· ∥ is adopted to calculate the Euclidean distance.
The output of the network to the p-th sample is:
Where ω h denotes the connection weight of the h-th hidden node and the output node.
(3) Wavelet neural network
Wavelet neural network combines wavelet transform and artificial neural networks [36]. It comprises the time domain localization of wavelet analysis and the self-learning ability of artificial neural networks. The mother wave function can represent a traditional sigmoid function, as more accurately reflected in time series and time domain distributions of different scales. A set of mother waves can be approximated by:
Where
(4) Generalized Regression Neural Network
GRNNs refer to an important branch of radial basis neural networks [37]. They mainly consist of four parts, i.e., an input layer, a mode layer, a summation layer and an output layer. The algorithm exhibits a strong nonlinear mapping capability and a flexible network structure, as well as high fault tolerance and robustness, and it is suitable for solving various nonlinear problems.
Mode layer: The number of neurons in the pattern layer is equated with that of learning samples, and each neuron corresponds to a different sample. There is a nonlinear transformation transforming the input space into a pattern space. The relationship between the input neurons and the pattern layer can be stored in the respective neuron of the layer.
Summing layer: The summation layer employs two types of neurons for summation, i.e., simple summation s s and weighted summation s w . Subsequently, the summation layer is transferred to the output layer.
The input and output nodes of the four neural networks are set to 5 and 1. The parameter settings for the four neural networks are listed in Table 2.
Experiment parameters of the four ANN’s
In ordinary combined forecasting, it is usually only the use of simple optimization algorithms to combine the forecasting models with the forecasting accuracy as the objective function, and the stability of the forecasting is ignored [28]. For combined models, the weights should be scientifically and comprehensively determined to acquire accurate and stable forecasting results. Thus, the IMODA was adopted to determine the weights of the four forecasting models to achieve the optimal forecasting effect.
Improved multi-objective dragonfly optimization algorithm
The multi-objective Dragonfly algorithm is a novel swarm intelligence algorithm proposed by Mirjalili of Griffith University in Australia in recent years [38]. Such an algorithm is primarily inspired by the static and dynamic group behavior of dragonflies, which indicates that the group preys, and the dynamic group behavior means that the group migrates. The mentioned two cluster behaviors can be equivalent to the searching and development of the optimization algorithm. In the algorithm, a mathematical model is built to simulate the group behavior of dragonflies. Dragonfly algorithm exhibits the advantages of its high accuracy, fast convergence and good stability. However, consistent with other population-based heuristic algorithms, the basic multi-objective Dragonfly algorithm is prone to fall into local optimum and uneven distribution of non-inferior solutions. In this study, the IMODA was proposed. The hybrid mutation operator was introduced into the multi-objective dragonfly optimization algorithm to increase the diversity of the population and reduce the possibility that the population falls into the local optimum. Subsequently, the dynamic file maintenance strategy based on the crowding distance was adopted to make the Pareto solution set distributed more effectively [39].
MODA
In the MODA, there are five main factors of the population, i.e., separation, alignment, aggregation, food attraction and natural enemy dispersion. The mathematical models of the mentioned five factors are presented below: Separation is the avoidance of collisions between individuals and other nearby individuals:
Where X represents the location of the current individual, X
j
denotes the location of the j-th neighboring individual, and N expresses the number of individuals. Alignment represents to the degree to which an individual and other nearby individual have the same speed:
Where V
j
expresses the speed of the j-th individual nearby. The degree of aggregation refers to the tendency of the individual to approach the center of mass nearby:
Where X represents the position of the individual; N denotes the number of nearby individuals. Food attraction refers to the tendency of individuals to approach food:
Where X is the position of the current individual; X+ expresses the position of the food. The dispersal of natural enemies is the degree to which the individual is far away from the natural enemies in nature:
Where X denotes the current personal position; X- represents the position of natural enemies. Mathematical model of step vector update:
Where s represents the separation coefficient; a is the alignment coefficient; c is the aggregation coefficient; f is the food attraction coefficient; e is the natural enemy dispersal coefficient; ω is the inertia coefficient; t is the iteration count subscript. Mathematical model of position vector update:
Where t denotes the current number of iterations.
By applying the mutation operator [40] to the optimization algorithm, the algorithm’s exploration ability can be improved. Since uniform mutation can cause degradation, this study employed a mixed mutation operator based on random average mutation and Gaussian mutation, and the mutation method of selected individuals was calculated as:
Where t is the current iteration number; α represents the random number on [0, 1]; xt,d denotes the position before the individual mutation; xmax,d and xmin,dare the maximum and minimum values of the individual on the d-th dimension, respectively;
At the early stage of the algorithm, a larger mutation probability increased the population diversity and helped find more non-inferior solutions. At the subsequent stage of the algorithm, a smaller value contributed to the convergence of the algorithm. The variation probability was applied to the variation range, so the variation range decreased with the increase in the number of iterations. At the early stage of the algorithm, the entire search space could be optimized, and the smaller variation range at the subsequent stage was to ensure the development ability of the algorithm in the subsequent iteration.
In the algorithm, the crowding distance was adopted to estimate the density of the non-dominated solutions, thereby keeping the non-dominated solutions distributed effectively [41]. In this study, a dynamic maintenance strategy based on crowding distance was adopted to maintain the diversity of Pareto solution sets. The congestion distance component was calculated as:
Where p (x, k) represents the location information of the optimal solution x on the k-th objective dimension; fp(x,k) is the corresponding objective function value.
In the dynamic maintenance, only the optimal solution with the smallest congestion distance was deleted each time, and the optimal solution affected in each target dimension was yielded according to the location information of the deleted optimal solution. The congestion distance component of the affected optimal solution was recalculated, and its congestion distance was updated. Next, the Pareto optimal set was maintained based on the novel crowding distance, as an attempt to avoid deleting individuals in numerous dense areas at one time. Accordingly, the size of Pareto optimal solution was continuously recycled to reach the maximum capacity of external files.
As indicated from the results of VMD decomposition, different IMF components exhibited different characteristics, and a single forecasting model failed to satisfy all the properties of IMF’ components. A combination method with IMODA was proposed for mentioned problem. The specific steps are presented as follows:
Step 1: The original wind speed signal was decomposed by the VMD with MIGA optimized parameters to obtain several IMFs with different frequencies. Then, the sample entropy of each IMF was calculated, and the subsequence was recombined according to the sample entropy value, as an attempt to obtain four typical components, i.e., IMF1’, IMF2’, IMF3’ and IMF4’.
Step 2: The four reconstructed signals IMF1’, IMF2’, IMF3’ and IMF4’ were forecasted by using four models of BP, RBF, WNN and GRNN to obtain four forecasting values with different accuracies, respectively. Next, the four forecasted values of each reconstructed signal were put into IMODA algorithm respectively, and the optimal weights w1, w2, w3 and w4 of the four forecasted values were calculated by IMODA with
Where w i (i = 1, 2, . . . , N) is the weight coefficient of the model N.
Step 3: The optimal forecasting results of the four reconstructed signals were obtained by IMODA optimization, and the final wind speed forecasting results could be obtained by summing the forecasting results of the four components.
The specific steps are illustrated in Fig. 3.

The procedure of the proposed combined model.
Data description
In this study, based on the wind power data of four wind farms in Xin Yu, Dong Tuanbao, Liu Jiazhuang and Hai Xing (hereinafter referred to as site 1, site 2, site 3 and site 4, respectively) in 2017, the forecasting effect was evaluated, as presented in Fig. 4. Moreover, the data were used to verify whether the proposed model is suitable for different occasions. From January 1, 2017 to January 15, 2017, wind speed data was sampled every 10 minutes, 2160 samples from 15 days were selected, and 288 sample data from the next two days were adopted to propose a combined forecasting model performance testing. The forecasting results are presented in Fig. 4. To test the proposed combined forecasting model, four evaluation indicators were used to compare the combined model with other single models. The mean absolute error (MAE), root mean squared error (RMSE), sum of squares due to error (SSE), mean absolute percent error (MAPE) calculation is listed in Table 3.
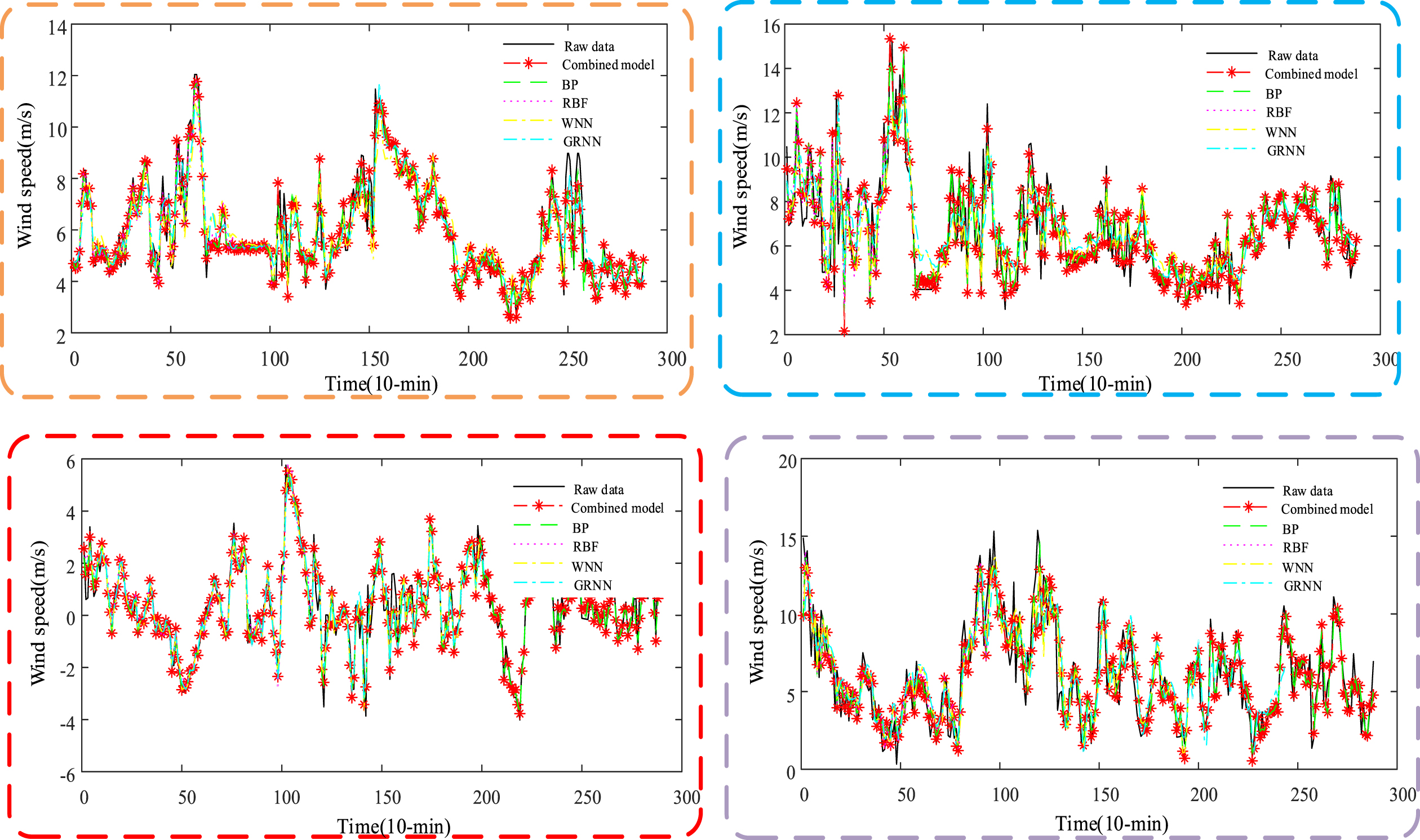
Forecasting results of the combined model and individual models.
The four evaluation rules
Different neural network forecasting models have different forecasting accuracy and forecasting stability for different wind speed series. To improve the accuracy and adaptability of the model, a number of classic neural networks were selected for comparative experiments, including BP, RBF, GRNN, WNN and ENN five typical forecasting models. The forecasting results of the five models in the four wind fields are listed in Table 4.
The evaluation among the five ANNS models in four sites
The evaluation among the five ANNS models in four sites
With site 1 as an example, the MAPE values of each forecasting model reached 14.3095%, 13.4813%, 15.3145%, 15.5635%, and 16.3725%, respectively. The RBF neural network exhibited the highest forecasting accuracy, and the ENN exhibited the worst forecasting accuracy. In station 2, the RMSE values of the forecasting models are 1.3901, 1.4271, 1.6122, 1.6521, and 1.7344, respectively. It can be seen that BP and RBF have the highest forecasting accuracy, followed by WNN and GRNN, and ENN has the largest error. In site 3, the MAE values of each model are 0.8119, 0.9013, 1.0258, 1.1254, and 1.1344, respectively, and the forecasting accuracy of the BP neural network is the highest. In site 4, the SSEs of the forecasting models were 421.2501, 452.2103, 482.1520, 492.1500, 516.3789, respectively. The BP and the RBF were suggested to exhibit the best stability in the forecasting of this site, and the GRNN and the ENN exhibited relatively poor forecasting stability. As revealed from the experimental results of the mentioned four sites, the forecasting effects of the BP and the RBF were relatively good, and the forecasting stability of the GRNN and the ENN was poor, whereas the average forecasting ability of the GRNN was higher than the ENN.
When multiple neural networks were weighted and combined, the literature [42] proved that on average, the more single forecasting models combined, the higher the forecasting accuracy would be. However, if all wind farms were combined with more neural networks, the forecasting results would not be better. With the increase in predictive neural networks, the calculation time of the combined model would also increase significantly. This study selected three (BP, RBF and WNN), four (BP, RBF, WNN and GRNN), and five (BP, RBF, WNN, GRNN and ENN) neural networks with the best forecasting results to conduct the combined comparison experiments. According to the comparison experiments, the average forecasting indicators of the combined model in the four wind fields are listed in Table 5. From the experimental results, the SSE values of the combined model combining three, four, and five neural networks were 194.5399, 72.8405, and 68.3770, respectively. It can be seen that the forecasting accuracy of the five neural networks was the highest, and the average SSE value of the four neural networks was much higher than the average SSE value of the three neural networks. However, the SSE value based on five neural networks after joining the ENN network was only 4.4635 higher than the SSE value based on four neural networks, while the model calculation time increased significantly. Accordingly, when the forecasting effect of the model was nearly the same, it could be more practical to choose a forecasting model combining four neural networks with a faster calculation speed.
Evaluation index of combined model of different number of ANNs
In this study, four neural networks BP, RBF, WNN, and GRNN with relatively favorable forecasting effects are selected for model combination. The comparison of the forecasting results of a single neural network and the combined model is shown in Fig. 4.
The purpose of this experiment is to verify the forecasting effectiveness of the forecasting model proposed in this study for signals of different complexity. The BPNN, RBFNN, WNN and GRNN forecasting models based on the IMODA combination model were used to predict the IMF’ sequence, i.e., IMF1’, IMF2’, IMF3’ and IMF4’ obtained by reconstructing IMF sequence in Section 2.3.
The SSE acted as the evaluation index to evaluate the performance of the model. The forecasting results of the single model and the combined model are presented in Fig. 5 and Table 6. For site 1, by comparing the SSE values of four IMF’ sequence, it can be seen that the higher the complexity of the sequence, the greater the forecasting error. However, the SSE values of the combined model proposed in this study were the lowest among the four sequences with different complexity, and the combined model can allocate weights reasonably according to the prediction effects of different prediction models to achieve the best prediction effect. It was therefore indicated that the proposed model could predict the signals with different complexity effectively. Furthermore, to verify the adaptability of the model, four sites were forecasted in total, and the forecasting results of site 2, site 3 and site 4 were as expected.

The SSE comparison among combined model and single models by forecasting each IMF’s.
The forecasting results of the models in four sites
Comparison with other VMD-based models
In this experiment, four VMD-based forecasting models were used to compare with the proposed combined model. VMD-based forecasting models include the VMD-BPNN, the VMD-RBFNN, the VMD-WNN and the VMD-GRNN, each model used to predict all IMFs decomposed by the VMD. The forecasting results of the combined model and comparison with other models are presented in Fig. 6 and Table 7.
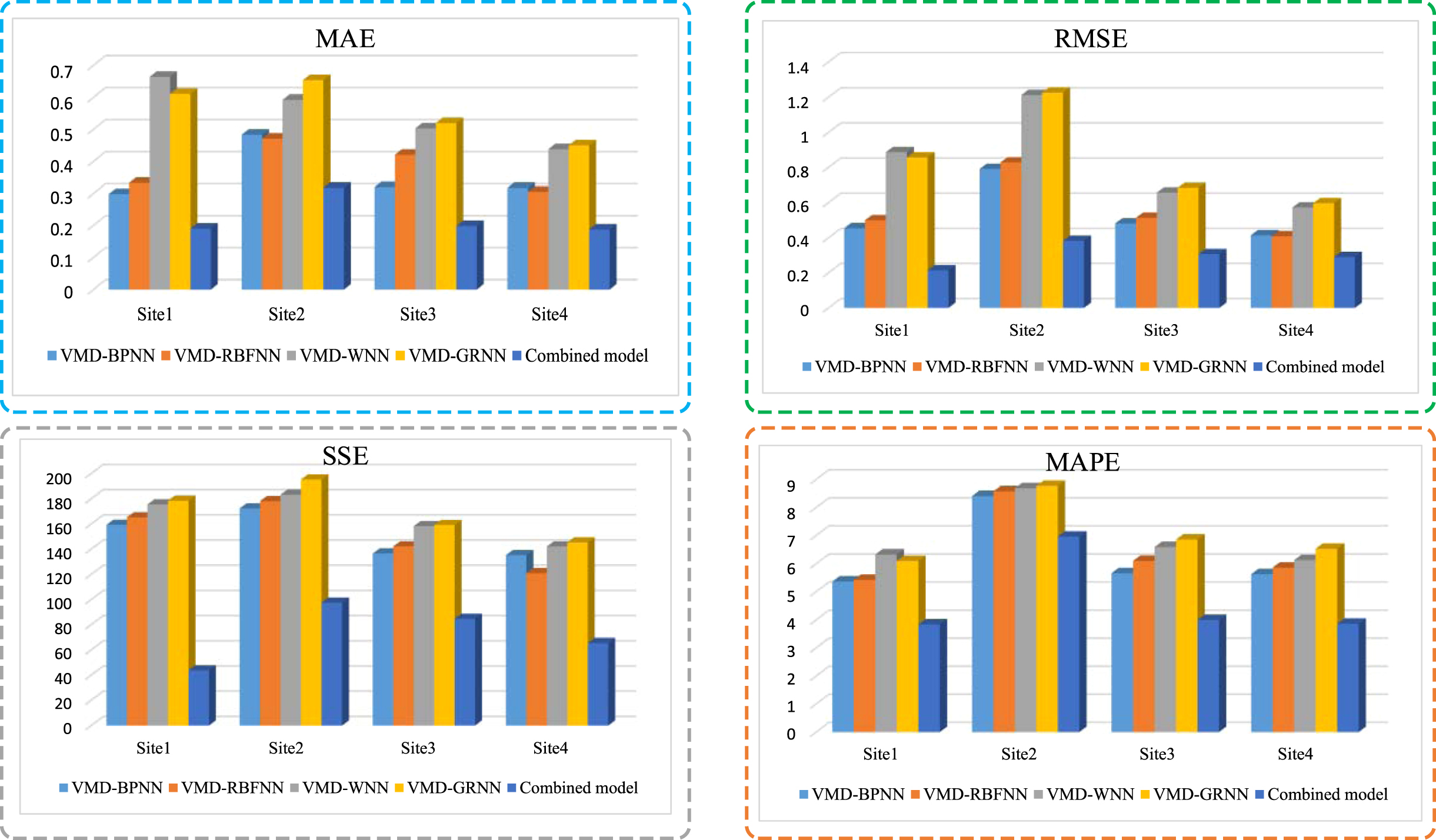
Evaluation index of four wind farms.
The evaluation among the combined model and four VMD-ANNS models in four sites
In site 1, the minimum values of MAE, RMSE, SSE and MAPE were all taken from the combination model proposed in this study. In site 2, the four evaluation values of the combined model were 0.3891, 0.4567,142.2156 and 7.2051%, respectively, which exerted the optimal forecasting effect compared with other models. In site 3, the evaluation error of the combined model was also far lower than other models. From the results of site 4, the forecasting accuracy of the combined model was also greatly improved. To be specific, the average MAPE of the combined model decreased by 20.9%, 23.7%, 28.6%, and 29.9%, respectively. As revealed from the mentioned results, the forecasting accuracy of the model was significantly improved, and the model exhibited a wide range of adaptability and achieved satisfactory results in four sites.
This experiment aimed to compare the VMD-based combined model with models based on different decomposition algorithms (e.g., VMD, EMD, and CEEMDAN). The comparison results are listed in Table 8.
Evaluation of different decomposition algorithms in four sites
Evaluation of different decomposition algorithms in four sites
For site 1, the MAE values of the combined model based on the three decomposition methods were 0.1903, 0.2672, 0.2081, and the SSE values reached 43.7549, 89.6573 and 59.6354, respectively. As indicated from the comparison result, in site 1, the VMD-based combined model was more accurate and effective in wind speed forecasting. In site 2, as impacted by the complexity and change of the original wind field signal, the combined model based on the three decomposition methods achieved MAE values of 0.3179, 0.4257 and 0.3891, respectively, slightly higher than those of the other three sites. However, the accuracy of the combined model based on VMD remained the highest. In site 3, the forecasting results of the VMD-based combined model were better than those of the other two, with the optimal forecasting effect. In site 4, compared with other data decomposition models, the VMD-based model still exhibited the most prominent predictive performance. To be specific, the VMD-based model obtained the lowest MAE, RMSE, SSE, and MAPE values, respectively, i.e., 0.1875, 0.2899, 65.4763, and 3.8571%, while the EMD-based model achieved the highest MAPE value, i.e., 4.5674%. Based on the mentioned experimental results, the values of MAE, RMSE, SSE and MAPE in the proposed model could be significantly lower than other models in this experiment. The average MAPE value of the four sites was 4.6602%, the lowest among all models. Thus, the combination model based on VMD could constantly outperform the combination model based on other data processing technologies.
This experiment aimed to compare the combined model based on IMODA with the model based on different optimization algorithms. The combined models comprised the Combined IMODA, the Combined Particle Swarm Optimization (PSO) [43], and the Combined CLSFPA. The comparison forecasting results are listed in Table 9.
The evaluation among the combined models in four sites
The evaluation among the combined models in four sites
The combination model proposed in this study exhibits similar forecasting performance with the combination model optimized by various optimization algorithms, which could improve the forecasting accuracy of the model to a certain extent. In general, the MAPE values of the four sites based on the combined model of IMODA, PSO and CLSFPA ranged from 4% to 7%, and the average MAPE values were 4.6602%, 5.5287% and 5.3544%, respectively. The proposed combined model based on IMODA exhibited the highest forecasting accuracy, 0.69% higher than that of the CLSFPA and 0.87% higher than that of the PSO. Moreover, the SSE values of the IMODA-based model among the four sites were the smallest. In brief, the proposed model was significantly better than other models in terms of forecasting accuracy and stability, and it exhibited higher adaptability.
Over the past few years, the wind power industry has boomed, and accurate and reliable wind speed forecasting is critical to wind power systems. The original wind speed data set is very difficult to be accurately forecasted due to the high noise, irregularity and instability of the wind speed series. Accordingly, successful and accurate wind speed forecasting is urgently required to solve the scheduling problem and further improve the operational efficiency of the power market. In this study, a combined model and an optimization algorithm were proposed, which effectively exploited the advantages of data processing techniques. First, an advanced and effective decomposition technique, the VMD, was adopted to decompose the original wind speed sequence into multiple IMF signals and reconstruct the IMF sequence by using sample entropy to facilitate the analysis and the forecasting. Subsequently, four forecasting models, i.e., the BPNN, the RBFNN, the GRNN and the WNN, were used to predict the reconstructed signals with different characteristics, and the optimal combination weights of the four models were obtained using the IMODA method, and lastly the forecasting results of the reconstructed signals were summed to obtain the final forecasting results. As indicated from the comparison results of five comparative experiments in the paper, the proposed combined model could outperform five single models, four VMD-based forecasting models and two other combined forecasting models, so it could act as an effective forecasting method for high-precision wind speed forecasting and improving the accuracy and stability of short-term wind speed forecasting. As revealed from the forecasting results of four different wind sites, the model exhibited good adaptability and could be applied to wind speed forecasting in different environments. The future development of the wind power industry required higher forecasting accuracy and timeliness of the wind power forecasting system, so the research direction of future work should further improve the accuracy and stability of wind speed forecasting, while reducing the calculation time and improving the timeliness of the forecasting.
Footnotes
Acknowledgments
This work obtained the support of Hebei Province Science and Technology Plan Project (19214501D, 20314501D).