
Abstract
Large-scale datasets collected from heterogeneous sources often require a join operation to extract valuable information. MapReduce is an efficient programming model for processing large-scale data. However, it has some limitations in processing heterogeneous datasets. This is because of the large amount of redundant intermediate records that are transferred through the network. Several filtering techniques have been developed to improve the join performance, but they require multiple MapReduce jobs to process the input datasets. To address this issue, the adaptive filter-based join algorithms are presented in this paper. Specifically, three join algorithms are introduced to perform the processes of filters creation and redundant records elimination within a single MapReduce job. A cost analysis of the introduced join algorithms shows that the I/O cost is reduced compared to the state-of-the-art filter-based join algorithms. The performance of the join algorithms was evaluated in terms of the total execution time and the total amount of I/O data transferred. The experimental results show that the adaptive Bloom join, semi-adaptive intersection Bloom join, and adaptive intersection Bloom join decrease the total execution time by 30%, 25%, and 35%, respectively; and reduce the total amount of I/O data transferred by 18%, 25%, and 50%, respectively.
Introduction
The advancement of many technological trends, such as smart devices, the Internet of Things, cloud computing services, web-based services, and social networks, have contributed to the massive amount of data being generated every day at unprecedented rate. Such technologies have led to the emergence of the era of Big Data, the era of processing Gigabytes, Terabytes, or even Petabytes of data. Consequently, Big Data analytics has become one of the hottest topics in the field of computer science. In this newly challenging world, data is everywhere, and the driving forces are access to ever-increasing volumes of data and our ever-increasing technological capabilities to mine that data for commercial insights [1]. According to the International Data Corporation report [2], the volume of data we created in 2017 reached about 19 Zettabytes (ZB=1021) and it is expected in 2025 that the volume of data we create and copy will reach 163 ZB.
Prior to the revolution of Big Data, companies were using traditional database management systems to store and analyze their data. However, the performance of such systems degrades significantly in the context of Big Data. This is due to the very characteristics of Big Data and the lack of scalability and flexibility of these systems. Various frameworks have been developed by industry and academia to overcome the limitations of the traditional database management systems for processing large-scale data. Among these are Google MapReduce [3], Yahoo PNUTS [4], Microsoft SCOPE [5], and Apache Spark [6]. These platforms combine an infrastructure of commodity machines that can scale up to millions of servers and can store databases up to Exabytes (EB=1018) of volume. Moreover, with their powerful failure handling mechanism, a large amount of data can be processed in a reasonable time in order to extract valuable information.
The analysis of large-scale data is attracting substantial interest from the communities of business and academia. It has the potential to enhance the decision-making process through identifying valuable hidden information in the data [7]. In most circumstances, a join operation is crucial to analyze heterogeneous datasets. To process huge amounts of raw data, an efficient, reliable, and scalable framework is required, one of which is MapReduce [3]. However, despite MapReduce’s merits, it has some limitations in performing the join operation. This is because MapReduce was originally designed to process homogeneous data rather than heterogeneous data [8]. The main problem of join processing in MapReduce is the large number of redundant records that are transferred through the network. Several techniques have been developed to alleviate this issue, such as the Filter-Based Joins [9–15]. However, these techniques require additional MapReduce jobs to perform the join operation.
In this paper, we present optimizations for the state-of-the-art filter-based joins in order to perform the join operation within a single MapReduce job. The fundamental idea is to perform the processes of filters creation and redundant records elimination with the lowest cost possible in terms of I/O and total execution time. To achieve this, we introduce two strategies to dynamically compute and distribute the filters. Moreover, we provide analytical and experimental comparisons of the introduced join algorithms and the state-of-the-art filter-based joins.
The rest of the paper is organized as follows. Section 2 summarizes the related work, addresses their limitations, and positions our paper with respect to existing literature. Section 3 introduces the implementation of the adaptive filter-based join algorithms. Section 4 provides a cost-based comparison of the filter-based joins. Section 5 presents the experimental results. Finally, Section 6 concludes the paper and discusses future work.
Related work
There has been extensive research in recent years to optimize join processing in the MapReduce framework [10, 16–21]. Al-Badarneh and Rababa [22] classified join algorithms in MapReduce into four categories: standard joins, filter-based joins, skew-insensitive joins [18, 23–27], and MapReduce variants [28, 29]. Standard joins are further divided into map-side joins and reduce-side joins. Map-side joins [10, 30–32] perform the join operation in the map phase, since there are no intermediate records sent from mappers to reducers. In contrast, the reduce-side joins [8, 32] send a large amount of intermediate records to reducers and produce the join result in the reduce phase. There is a tradeoff between the performance and feasibility of these join algorithms, the better the performance the lesser the feasibility. However, there are some drawbacks that confront both types of joins. Map-side joins have restrictions with regarding the characteristics of the input datasets, and most of the times, additional MapReduce jobs are required to meet these requirements. Reduce-side joins, on the other hand, are more general but the large amount of redundant records degrades the join performance. A computer-implemented system for optimizing reduce-side join was presented in [33]. The system executes a series of operations to group data in one of the input datasets and to retrieve descriptive metadata of the other dataset. Then, the join operation is performed using one of the provided lookup approaches. Although the authors introduced a method to optimize reduce-side join, it does not natively run in the MapReduce framework and additional processing is required to perform the join operation.
Filter-based joins are alternative join methods to resolve the redundant records problem in standard joins. Bloom Join [34] is a distributed join algorithm that uses a Bloom filter [35] to eliminate redundant records in the input datasets. Bloom joins using MapReduce have been introduced in [17, 37]. The approaches are implemented in two independent phases and each corresponds to a separate MapReduce job. The first job constructs a Bloom filter for one table while the second job eliminates redundant records in the other table and performs the join operation. Further developments of Bloom join [14, 15] suggested the use of an intersection Bloom filter to eliminate irrelevant intermediate records in both tables before performing the join operation. However, this comes at a cost of adding complexity to the preprocessing job.
Koutris [38] theoretically investigated the potential of implementing the Bloom join technique within a single MapReduce job. Two strategies were proposed on how to construct and broadcast the Bloom filter. Strategy A computes the Bloom filter at one node and broadcasts it to every participating node in the cluster. Strategy B, on the other hand, overcomes the bottleneck of central processing in strategy A by computing the local Bloom filters in parallel and sending them out to a target node for merging and aggregation. However, strategy B increases the communication cost by a factor of n (the number of nodes) compared to strategy A. Although several techniques for join processing using Bloom filter within a single MapReduce job were discussed in [38], not enough technical details were provided. Lee et al. [12, 13] addressed the implementation issue and introduced an architecture for join processing using Bloom filter within a single MapReduce job. Two internal modifications to the MapReduce framework were performed. Specifically, the scheduler of the map tasks was altered to allow assigning them in sequential order and the functionalities of the jobtracker and tasktrackers were expanded to be able to send the local filters and receive the global filter. The architecture was further extended in [11] to introduce the Threshold-based Map-Filter-Reduce Join, which measures the efficiency of the constructed Bloom filter. That is, if the false positive rate of the global filter exceeds a certain threshold (τ), it will be disabled, and reduce-side join is implemented instead. The experimental results showed that the introduced technique had a stable performance close to that of the better of reduce-side join and Bloom join. However, the introduced architecture still requires modifications to the MapReduce framework. Further developments of bloom join have been proposed in [39, 40], however, additional MapReduce jobs are required to perform the join operation. To the best of our knowledge, this paper is the first to implement the Bloom join technique within a single MapReduce job and without any prior modifications to the MapReduce environment.
Implementation of adaptive filter-based join algorithms
Consider an equijoin operation between two tables R and S. This section presents the implementation of the adaptive filter-based join algorithms and discusses two strategies to dynamically compute and distribute the filters.
Algorithm1: Adaptive Bloom Join
Reduce-side Bloom join in [9] requires two MapReduce jobs to implement the join operation. We introduce the Adaptive Bloom Join algorithm which creates the Bloom filter and performs the join operation within a single MapReduce job. To make this possible without any prior modifications to the Hadoop architecture, we enable the worker nodes to communicate during a running job through the Hadoop Distributed File System (HDFS) with the use of Mapper’s functionalities. Each instance of the Mapper class has four methods, setup(), map(), cleanup() and run(). The adaptive Bloom join utilizes the setup() and cleanup() methods to initialize important parameters and to write the local filters to HDFS, respectively. In addition, our approach utilizes the map() method to extract the key/value pairs and to construct the local filters. Figure 1 shows the flow diagram of a join operation between R and S using the adaptive Bloom join.
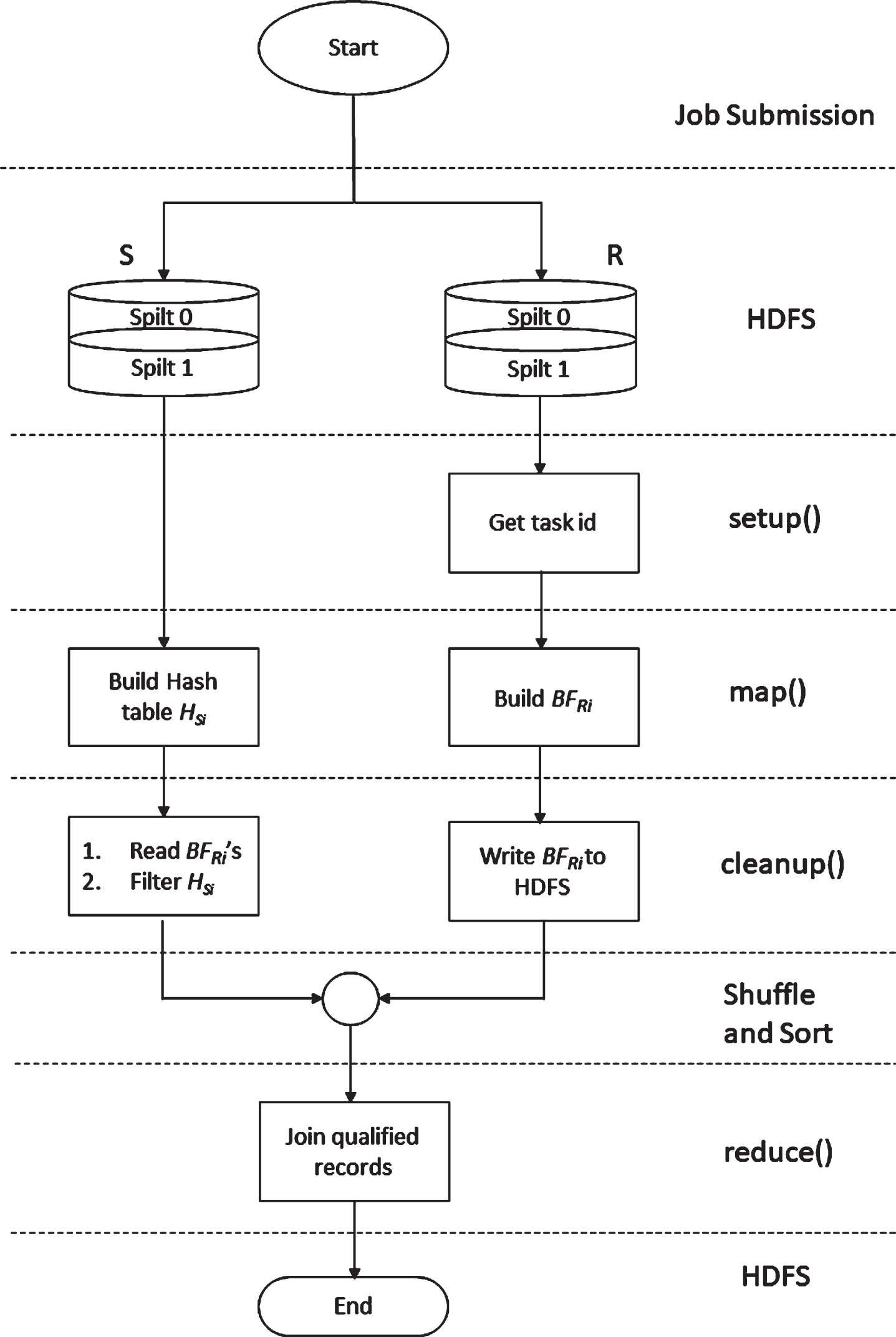
Flow diagram of adaptive Bloom join.
The following steps describe the implementation of the adaptive Bloom join algorithm.
The adaptive bloom join algorithm facilitates the processes of creating the Bloom filters on one side and reading them on the other side. Figure 2 shows an example of an equijoin operation using adaptive Bloom join. In this example, the mapper of R builds a local Bloom filter ‘Filter0’ and writes it to a predefined directory D R in HDFS, as well as an acknowledgment file Ack0. Then, the R side mapper outputs the tagged key/value pairs. In the S side, each mapper verifies if the acknowledgment file exists in the predefined directory D R , if so, it reads the local filter and eliminates redundant records in the input data. Finally, the intermediate records are sorted and shuffled and eventually sent to the reducers to produce the join result.
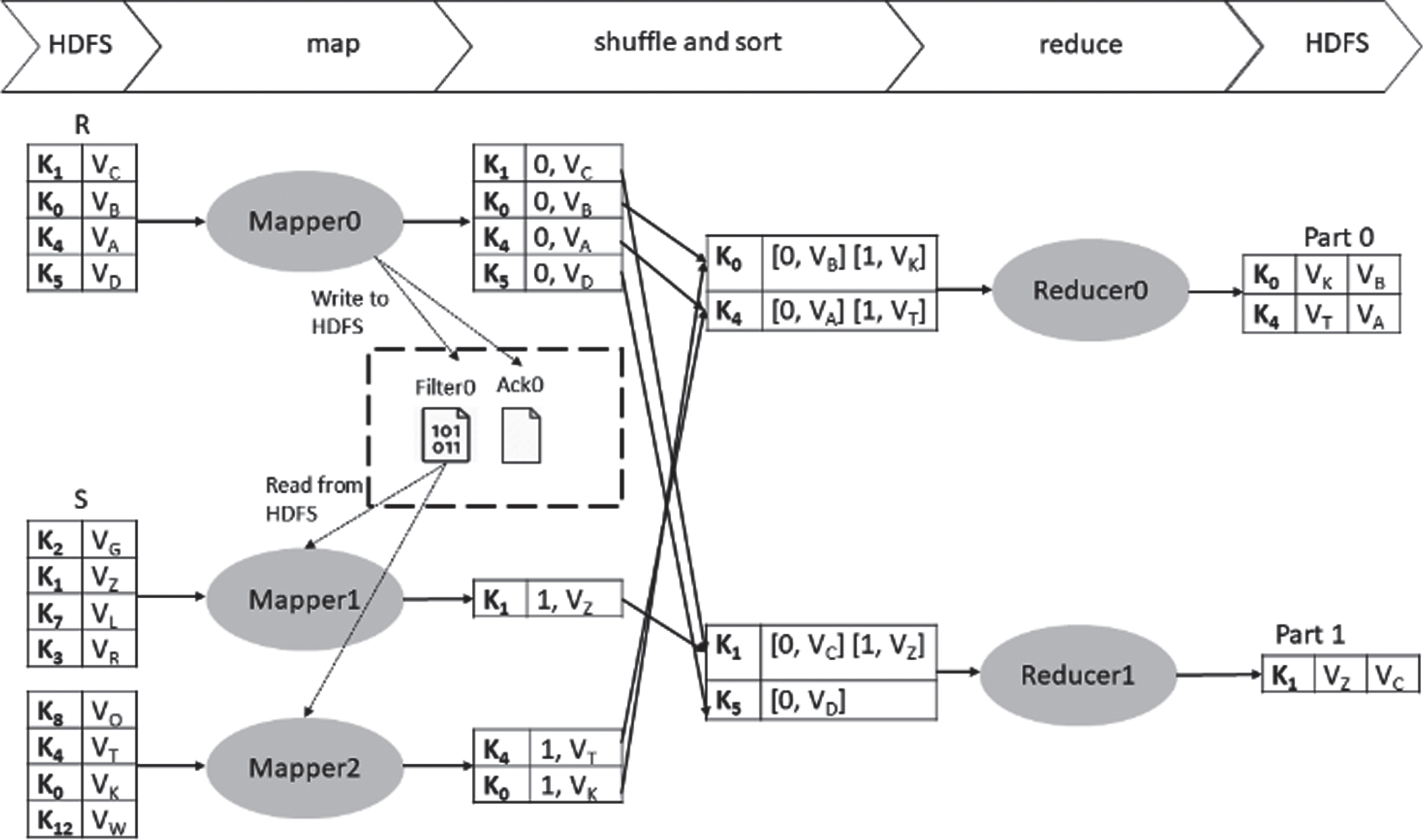
Example of adaptive Bloom join.
Compared to Bloom join in [9], the adaptive Bloom join eliminates the cost of implementing the first job that constructs the Bloom filter. And compared to join processing using Bloom filter in [13], our approach is implemented in the MapReduce framework without any prior modifications to its architecture.
The intersection Bloom join [14, 15] significantly improves the join performance by eliminating redundant records in both tables using the intersection filter. However, the preprocessing is more involved compared to other Bloom joins. Therefore, we introduce the Semi-Adaptive Intersection Bloom Join algorithm to alleviate this problem. The introduced algorithm is implemented in two MapReduce jobs. The first job runs a full MapReduce job to construct a Bloom filter BF S for table S. Each mapper builds a local filter for the input split S i of S. Then, the local filters are eventually fed to a reducer, which in turn merges them into one global filter BF S . The second MapReduce job constructs a Bloom filter BF R for table R on-the-fly and performs the join operation after eliminating redundant records in both tables. Figure 3 shows the flow diagram of the second MapReduce job.
Flow diagram of semi-adaptive intersection Bloom join.
The following steps describe the implementation of the second MapReduce job.
The semi-adaptive intersection Bloom join filters out redundant records in both tables before entering the reduce phase. Figure 4 shows an example of an equijoin operation using the introduced algorithm. In this example, firstly, the R side mapper uses the global filter of S table, which is created in an independent MapReduce job, to eliminate redundant records in R. The rest of the implementation flows exactly as in the description of Fig. 2. Compared to the intersection Bloom join [14, 15], the semi-adaptive intersection Bloom join reduces the cost of preprocessing and increases the cost of processing in the join job. However, the reduced I/O cost in the preprocessing job overcomes the cost of the extra processing in the join job.
Example of semi-adaptive intersection Bloom join.
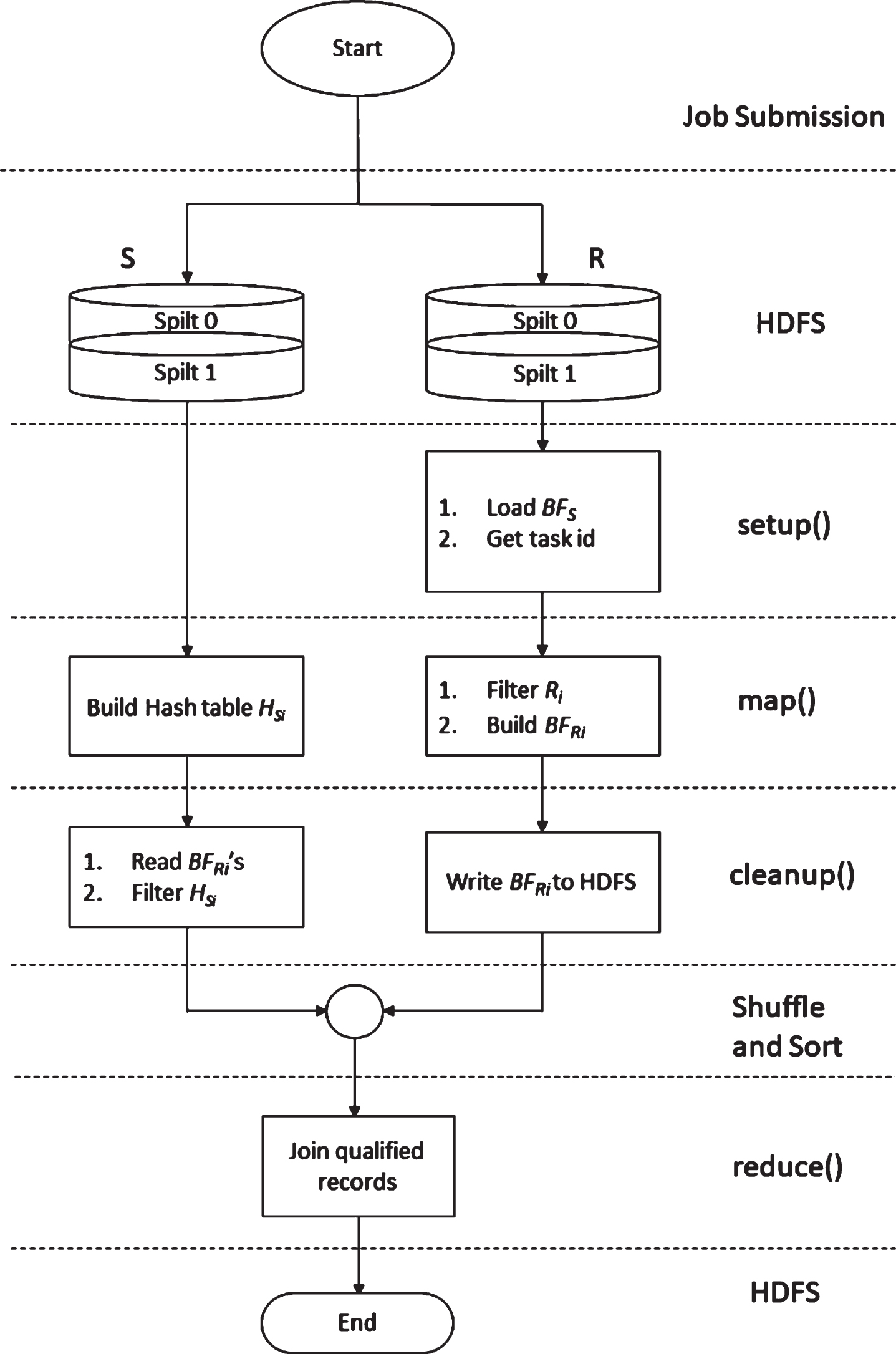
To eliminate the cost of the preprocessing job in semi-adaptive intersection Bloom join, we introduce the Adaptive Intersection Bloom Join algorithm. It constructs Bloom filters for both tables and performs the join operation within a single MapReduce job. The local Bloom filters of both tables are constructed in the map method and interchanged in the cleanup method. Figure 5 shows the flow diagram of the introduced algorithm.
The following steps describe the implementation of the algorithm.
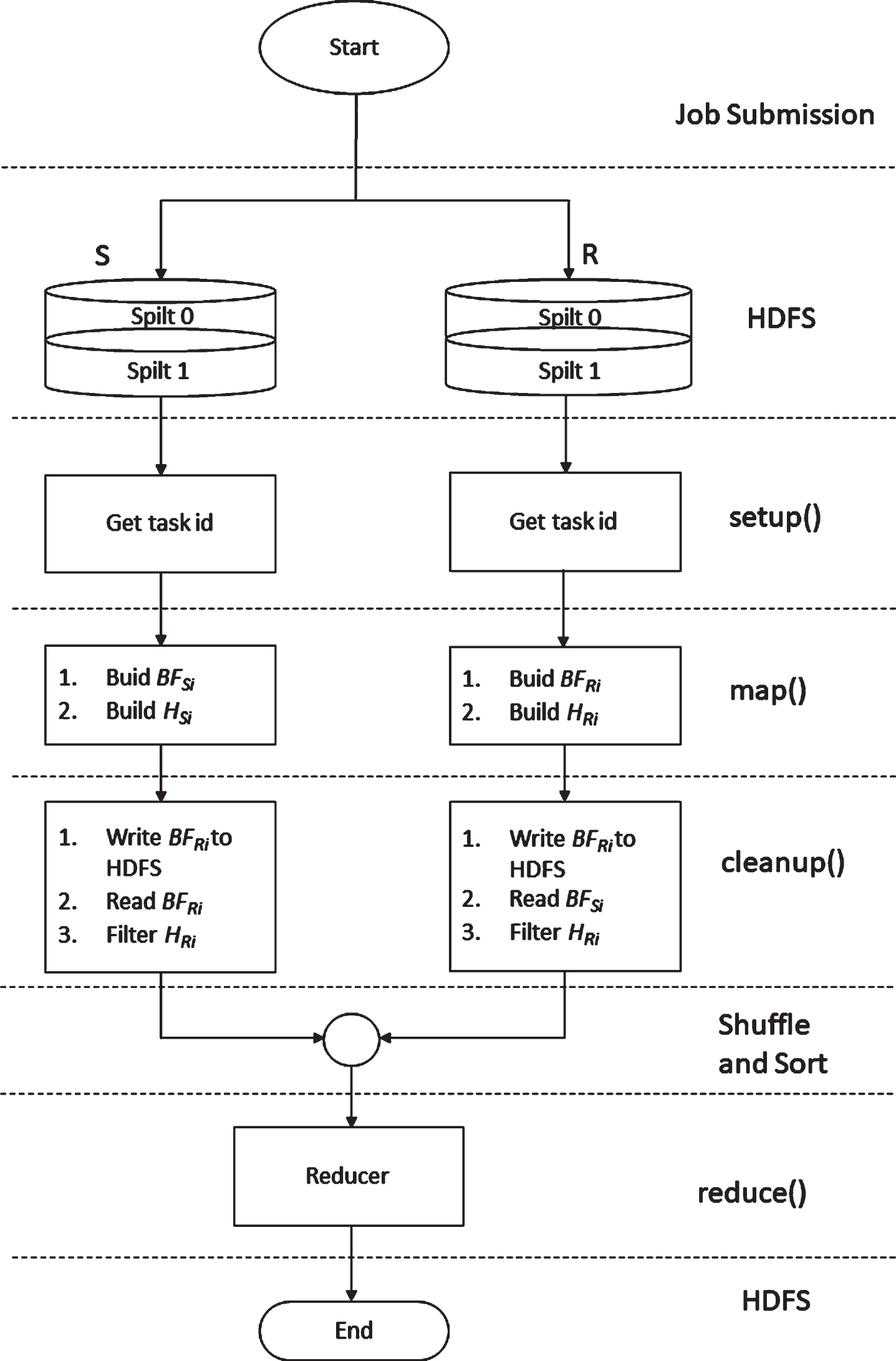
Flow diagram of adaptive intersection Bloom join.
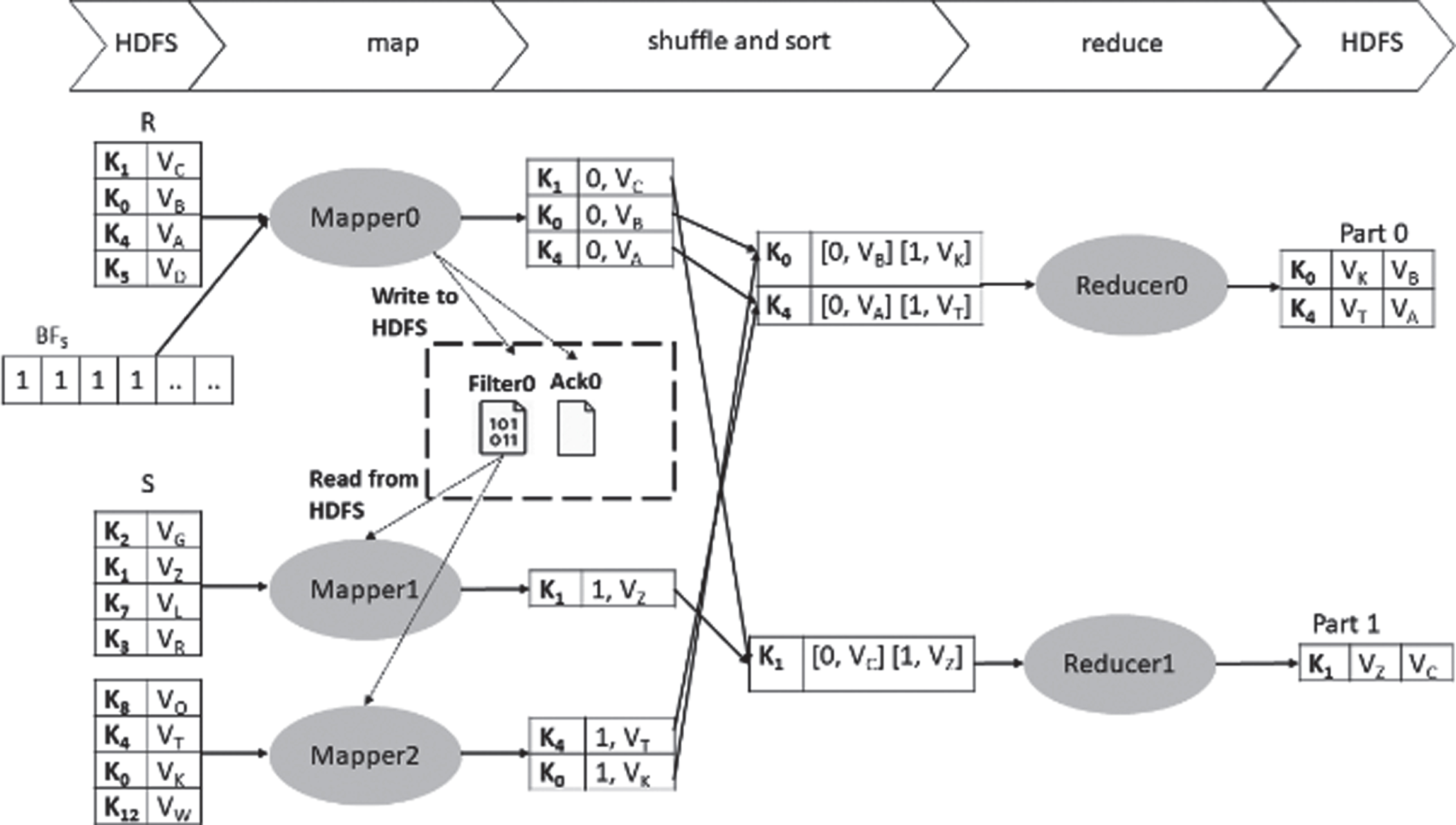
Figure 6 shows an example of an equijoin operation using the adaptive intersection Bloom join, where D R and D S are directories in HDFS used to store the local filters and acknowledgment files of R and S, respectively. The mapper of R side builds a local filter ‘Filter0’ for the input split and writes it to D R , as well as the acknowledgment file Ack0. Concurrently, mappers of S side build the local filters ‘Filter1’ and ‘Filter2’ and write them to D S , as well as the acknowledgment files Ack1 and Ack2. Then, each mapper reads the local filters of the other side and use it/them to eliminate redundant records in its input spilt. Finally, the filtered intermediate records are sent to the reducers to produce the join result.
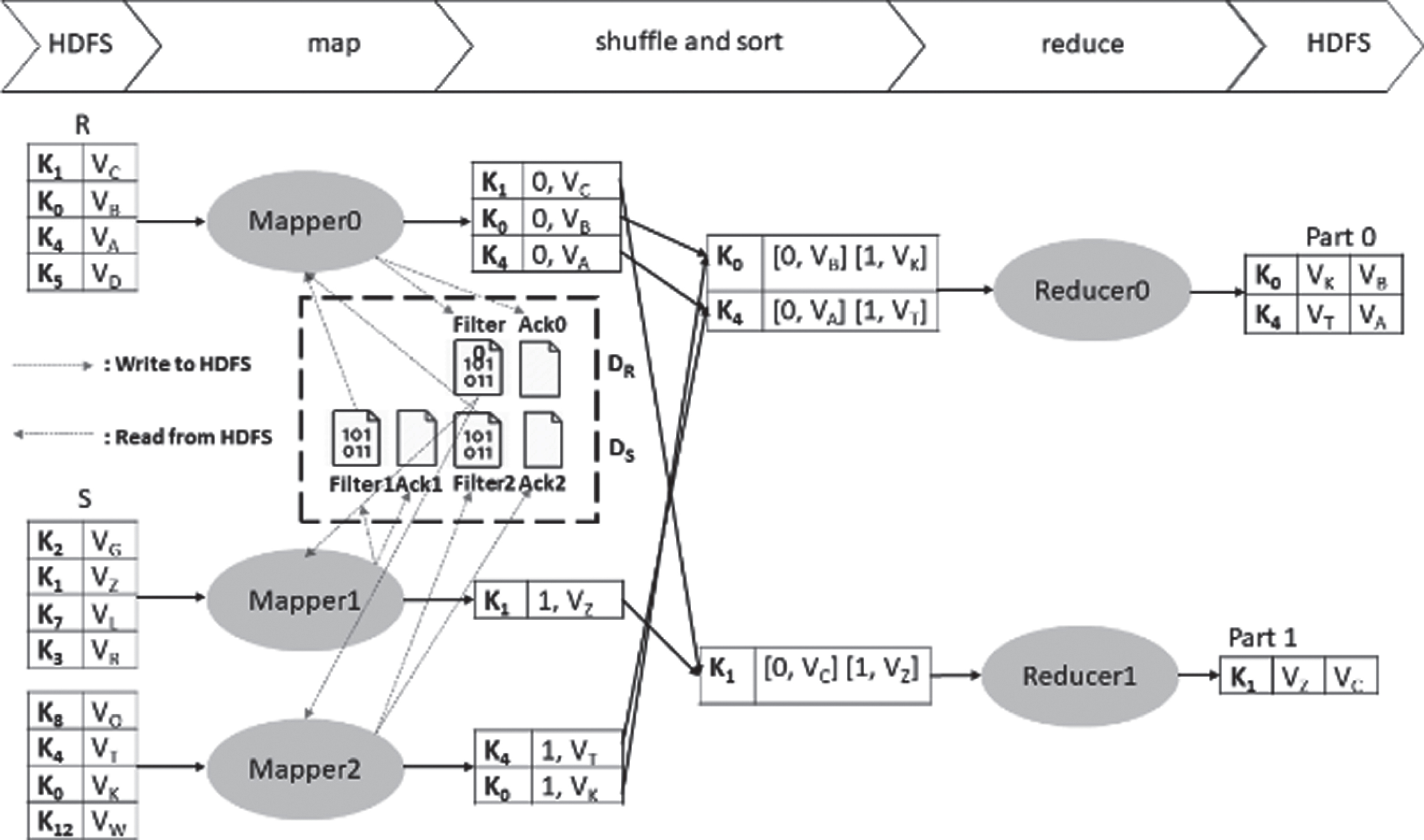
Example of adaptive intersection Bloom join.
Communicating through HDFS facilitates the processes of writing and reading the local filters within one MapReduce job. Compared to the intersection Bloom join [14, 15], the adaptive intersection Bloom join reduces the total amount of transferred data between mappers and reducers and eliminates the cost of the preprocessing job.
The introduced adaptive filter-based join algorithms utilize HDFS to distribute the local filters between mappers of the input datasets. However, a network bottleneck might occur if the size of these filters or the number of map tasks is relatively large. In this subsection, we introduce two strategies to dynamically compute and distribute the local filters and discuss their efficiencies. A cost analysis of these strategies is presented in the next section.
Given an input dataset R, we can compute the size of the Bloom filter BF
R
, denoted as m
R
, using Equation (1) [41], where n
total
is the total number of join keys and p is the false positive probability.
Strategy1: Each mapper of R constructs a local filter and writes it to a predefined directory D R in HDFS. On the other hand, each mapper of S reads the written filters and merges them into one global filter. The size of each local filter is constructed based on the total number of keys of R and the false probability rate, as in Equation (1). To increase the efficiency, we could alter the block size of R to be larger than that of S in order to guarantee the early assignment of R‘s map tasks. Strategy1 is used in the description of the introduced algorithms in the previous subsections.
Strategy2: Each mapper of R constructs a local filter and writes it to a predefined directory D R in HDFS. Once all filters are written, the last assigned map task of R reads the written filters and merges them into one global filter. Then, it writes the global filter file along with an acknowledgment file to D R . In the S side, each mapper continuously probes for the acknowledgment file in directory D R , and once it is written, each mapper of S reads the global filter file. In this way, mappers of S read only one filter. The local filters and the global filter used in this strategy2 have the same size.
By comparing strategy2 to strategy1, it is clear that strategy2 reduces the total number of I/O operations. On the other hand, it requires extra time to process the global filter. There is a tradeoff between these two measures. If the size of the input datasets is relatively large, then strategy2 becomes more efficient than strategy1, because the decrease in the total number of I/O operations overcomes the increase in the processing time. Otherwise, strategy1 becomes more efficient than strategy2.
Consider an equijoin operation between R and S in the MapReduce environment. This section presents the cost analysis of the state-of-the-art join algorithms: Standard Repartition Join, Bloom Join, and Intersection Bloom Join, respectively. In addition, we present the cost analysis of the introduced join algorithms: Adaptive Bloom Join, Semi-Adaptive Intersection Bloom Join, and Adaptive Intersection Bloom Join, respectively. The naming convention for representing the join algorithms is provided in Table 1.
Abbreviations for representing the join algorithms
Abbreviations for representing the join algorithms
We adapt the cost model introduced in [42]. Table 2 summarizes the parameters of the model. The cost of the mentioned algorithms is analyzed under the same assumption of the introduced cost model, which states that the execution time is dominated by I/O operations, such as reading, writing, and copying. All costs, denoted by small c, are measured in seconds per page and the total costs, denoted by capital C, are measured in seconds. The total cost of a two-way equijoin operation using MapReduce is given in Equation (2).
Parameters of the cost model
where: C
read
= c
r
· |R| + c
r
· |S| C
sort
= c
l
· |D|·2 · (log
B
|D| - log
B
(mp) + log
B
(mp)) as in [42]. C
tr
= c
t
· |D| C
write
= c
r
· |O|
The additional component C pre depends on the amount of I/O operations involved in the preprocessing job of the algorithm. For instance, the C pre of SRJ is equal to zero. The two components C read and C write are fixed regardless of the join algorithm, since they only depend on the size of the input datasets, |R| and |S|, and the size of the join output |O|. The remaining components, C sort and C tr , strongly influence the total cost of a join algorithm, because they depend on the size of intermediate data |D|. Therefore, an optimized join algorithm should minimize the total amount of intermediate data.
In this subsection, we analyze the cost of the join algorithms in terms of |D|, C
pre
, and the cost of any additional phase. We set the cost of SRJ as the base cost to highlight the effect of filtering. Since ABJ is an optimization of BJ, and SAIBJ and AIBJ are optimizations of IBJ, we divide the filter-based join algorithms into two categories: BJ and ABJ in the first category and IBJ, SAIBJ, and AIBJ in the second category. We denote the following symbols for the below parameters. δ
R
: the ratio of joined records of R with S. δ
S
: the ratio of joined records of S with R. p(R): the false positive probability of BF
R
. p(R, S): the false positive probability of the intersection Bloom filter, IBF = BF
R
∩ BF
S
.
Standard Repartition Join (SRJ): The preprocessing cost of SRJ is equal to zero and the total amount of intermediate data is equal to the size of the input datasets, R and S.
Category1: The I/O operations in the preprocessing job of BJ involve the following: reading the input dataset R, writing the local filters to the local disk of the worker nodes, transferring them to the reducers and writing the merged filter to HDFS. The join job eliminates the cost of transferring the redundant records of S. Equations (5) and (6) compute the total preprocessing cost and the total amount of intermediate data of BJ.
ABJ eliminates the cost of preprocessing, however, it adds an extra phase to write and read the local filters of R to/from HDFS, respectively, denoted as C
f
(cost of the filters). We ignore the computation of the I/O operations of strategy1 and strategy2 that involve writing and checking the acknowledgment files because these are empty files and the cost of their creation is almost negligible compared to the total cost. We compute C
f
in the worst-case scenario, assuming that all map tasks of S read the local filters from HDFS remotely. However, in real clusters, the introduced join algorithms benefit from the file replication property of MapReduce. The I/O operations of C
f
using strategy1 involve writing the local filters of R and reading them on S side. Equation (7) computes the cost of this phase.
The I/O operations of C
f
using strategy2 involve writing the local filters of R, then, one map task of R reads them and write the global filter to HDFS. Finally, all map tasks of S read the global filter from HDFS. Equation (8) computes C
f
of strategy2.
The size of intermediate data of ABJ is equal to that of BJ, given in (6). However, the cost of processing the filters is different. From Equations (5), (7), and (8) we can infer the following.
We hereby analyze the cost of the introduced join algorithms using strategy2. To shorten the discussion and highlight the conclusion, we eliminate analyzing the cost using strategy1.
By default, the split size is equal to 128MB. Therefore, |R| is approximately equal to the split size multiplied by the total number of mappers. Let g = ct/cl, and h=cr/cl. Then, by dividing the above inequality by cl and by substituting the value of | R |, we get the following:
From inequalities (11) and (12), α is a constant coefficient that is less than one. It depends on the size of the input datasets and the characteristics of the cluster. However, in real clusters, the coefficient α could exceed one.
Category2: The preprocessing of IBJ is more involved than that of BJ. On the other hand, the amount of intermediate data of IBJ is smaller than that of BJ, because IBJ filters out redundant records in both datasets. The preprocessing of IBJ involves reading R and S, writing a local filter for each input split, and transferring the local filters to the reducers. Then, the global filter is written in the reduce phase. Equations (13) and (14) compute the cost of the preprocessing job and the total amount of intermediate data of IBJ.
SAIBJ reduces the total cost of I/O operations in the preprocessing job compared to IBJ, since it only constructs the filter of R. On the other hand, it adds an extra phase Cf to construct the filter of S in the join job. Equations (15) and (16) compute the cost of the preprocessing job and the cost of the filters of SAIBJ.
AIBJ completely eliminates the cost of preprocessing, however, it adds an extra cost Cf to the join job. The I/O operations in Cf involve creating the filters of R and S. Equation (17) computes the cost of filters of AIBJ.
The size of intermediate data of AIBJ and SAIBJ is equal to that of IBJ, which is given in Equation (14). From Equations (13–17) we can infer the following.
And by dividing the above inequality by cl, we get the following:
And by dividing the above inequality by cl, we get the following:
In summary, the introduced algorithms ABJ, SAIBJ, and AIBJ reduce the total cost of the join operation compared to BJ and IBJ. Theoretically, they have been proven to be more efficient than the state-of-the-art filter-based joins for all filter sizes less than a certain fraction (α) of the split size. Therefore, ABJ is a better choice than BJ, SAIBJ, and AIBJ are better choices than IBJ. However, if the join ratio is relatively high, then SRJ outperforms the filter-based joins, because the cost of constructing and distributing the filters becomes relatively significant.
In this section, we present experimental results of the state-of-the-art filter-based joins and our algorithms. We implemented four tests to capture the performance in different aspects of the join operation. Test1 and Test2 examined the effect of varying the input size and join ratio, respectively. Test3 was dedicated to measure the performance of AIBJ, since the algorithm is restricted to the available resources in the cluster. Finally, Test4 examined the effect of varying the Bloom filter size. The performance is measured in terms of the total execution time and the total amount of I/O data.
Cluster Environment. All experiments were run on a cloud-based cluster, IBM Analytics Demo Cloud. It is a high-performance cluster that demonstrates the advantages of parallelized processing of big datasets. It consists of four nodes, one master node and three worker nodes. Table 3 summarizes their characteristics. The cluster supports multiple services such as Apache Hadoop and Apache Spark and managed by Apache Ambari. The Hadoop version is 2.7.1 and the Ambari version is 2.1.0. The default configurations of the cluster were maintained, where the block size was 128MB, the block replication factor was three, the dedicated memory for sorting data was 819MB, the I/O buffer was 128KB and the JVMs heap-size was 1638MB. Furthermore, the total number of reduce tasks was set to four. Each worker node can simultaneously run up to 20 tasks.
Cluster characteristics
Cluster characteristics
Datasets. The self-join datasets of the Purdue MapReduce Benchmark Suite [43] were used in the experiments. The Purdue MapReduce benchmark, called “Puma”, represents a wide variety of MapReduce applications with low/high computing requirements and low/high shuffle volumes. Two datasets, namely Dataset1 and Dataset2, with an equal size were used in the implementation of the join operation. The maximum number of attributes in each dataset is 39, and the string length of each attribute is equal to 19 characters. The attributes of each record are separated by a comma and each record ends with a new line. The first attribute of Dataset1 is a foreign key that refers to the sixth attribute of Dataset2. We used the following query in the execution of the join algorithms.
Select *
From Dataset1(A0,..., A20) d1,
Dataset2(A0,..., A20) d2
Where d1.A0=d2.A5
The above query merges the first 21 attributes of Dataset1 and Dataset2 based on an equijoin condition; whenever the first attribute A0 of Dataset1 matches with the sixth attribute A5 of Dataset2.
We used three sets of input Set1, Set2, and Set3 with respective sizes 30GB, 80GB, and 120GB to examine the scalability of BJ, IBJ, ABJ, and SAIBJ. Table 4 summarizes the characteristics of the input datasets. To highlight the effect of varying the input size, the join ratio of this test was set to 0.1%.
Test1 input datasets
Test1 input datasets
In BJ and ABJ, the Bloom filter was constructed for Dataset2. In SAIBJ, the Bloom filters of Dataset1 and Dataset2 were constructed in the first and second jobs, respectively. In order to maximize the efficiency of the filtering process, we specified the sizes of the Bloom filters according to the cardinality of the join key values of the input datasets and chose the most appropriate size with the smallest false positive probability. Table 5 shows the characteristics of the Bloom filters; where m is the size of the filter, k is the number of hash functions, n is the join key cardinality, m/n is the number of bits allocated for each key, and p is the false positive probability. The hash function type used in all filters was MurmurHash, which is a widely used hash function.
Bloom filters parameters of Test1
The following shows the comparison of the experimental results.
Total Execution Time: Figure 7 shows the total execution time of BJ, ABJ, IBJ, and SAIBJ. Looking at ABJ and BJ, the total execution time of ABJ is less than that of BJ by percentages of 28%, 27%, and 34% for Set1, Set2, and Set3, respectively. As the input size increases, the difference between the total execution time of ABJ and that of BJ increases as well. This is because of the increase in the I/O cost of the preprocessing job of BJ. The same is true when comparing SAIBJ to IBJ. The total execution time of SAIBJ is less than that of IBJ by percentages of 23%, 27%, and 24% for Set1, Set2, and Set3, respectively. Although SAIBJ requires a preprocessing job like IBJ, its preprocessing I/O cost is minimized compared to that of IBJ. Therefore, SAIBJ has less total execution time than IBJ. Briefly, the dynamic creation of Bloom filter in ABJ and SAIBJ outperforms the static creation of Bloom filter in BJ and IBJ by average reductions of 30% and 25%, respectively.
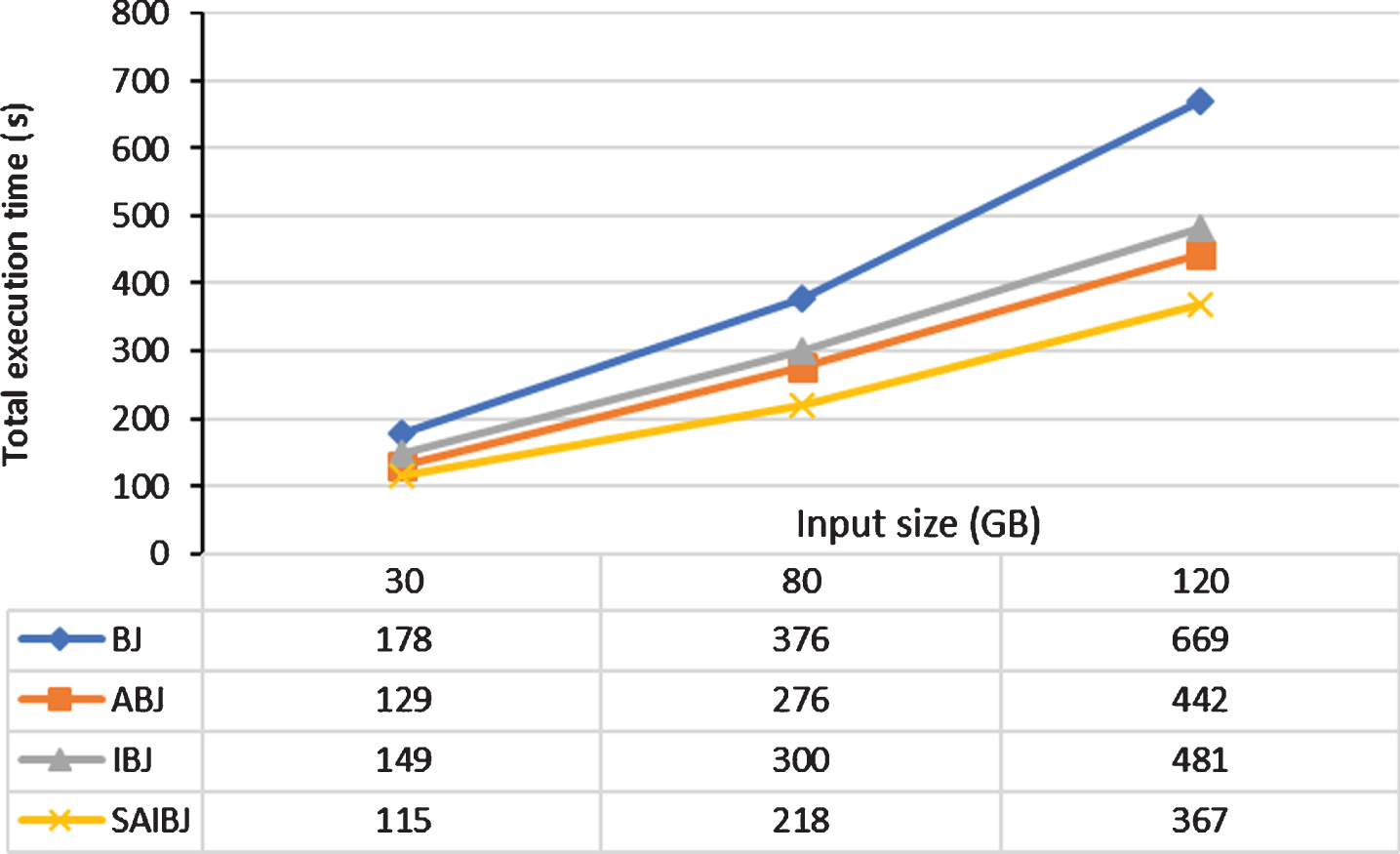
The total execution time of filter-based joins with varying the input size (Set1, Set2, Set3).
Total Amount of I/O Data: The I/O operations play a major role in evaluating the performance of the join algorithms. Minimizing I/O operations improves the join performance and vice versa. We calculated the total amount of I/O data using the provided job counters, number of bytes read and number of bytes written locally or remotely. Figure 8 shows the total amount of I/O data of ABJ, BJ, SAIBJ, and IBJ. It can be noted that the differences between the total amount of I/O data of the existing approaches and that of the introduced approaches are approximately equal to the size of one input dataset for each set. For instance, in Set2, the difference between the total amount of I/O data of BJ and that of ABJ, and the difference between the total amount of I/O data of IBJ and that of SAIBJ, are both approximately equal to 40GB. What is worth noting is that increasing the input size results in increasing the total difference between their total amount of I/O data. This will improve the performance of the introduced algorithms ABJ and SAIBJ. Concisely, by virtue of the dynamic creation of the Bloom filter in ABJ and SAIBJ, the total amount of I/O data is minimized by percentages of 18% and 25% compared to BJ and IBJ, respectively.

Total amount of I/O of filter-based joins with varying the input size (Set1, Set2, Set3).
In this test, we examined the effect of varying the join ratio of the input datasets on the performance of the filter-based joins. The total size of the input datasets was 30GB. We used MapReduce to tune the join ratio of the input datasets. Then, the algorithms were executed multiple times with different join ratios. Precisely, the join ratios were: 0.01%, 0.1%, 1%, and 2%. The following shows the comparison of the experimental results.
Total Execution Time: Figure 9 shows the total execution time of the filter-based joins with varying the join ratio. It is clearly noted that increasing the join ratio results in increasing the total execution time. Looking at ABJ and BJ, the difference between the total execution time of ABJ and that of BJ for each join ratio is within a range of 60 seconds. Therefore, we can deduce that increasing the join ratio mainly affects the shuffle time and the reduce time. Similarly, the difference between the total execution time of SAIBJ and that IBJ is approximately within a fixed range.

Total execution time of filter-based joins with varying the join ratio.
Total amount of I/O Data: Increasing the join ratio affects the size of the intermediate data and the size of the join result. That is, large join ratios result in large amount of I/O data. Figure 10 depicts the effect of increasing the join ratio on the total amount of I/O data of the algorithms. ABJ and SAIBJ reduce the total amount of I/O data compared to BJ and IBJ, respectively, by a steady value that is approximately equal to 15GB. Therefore, we can conclude that varying the join ratio has the same effect on all join algorithms.
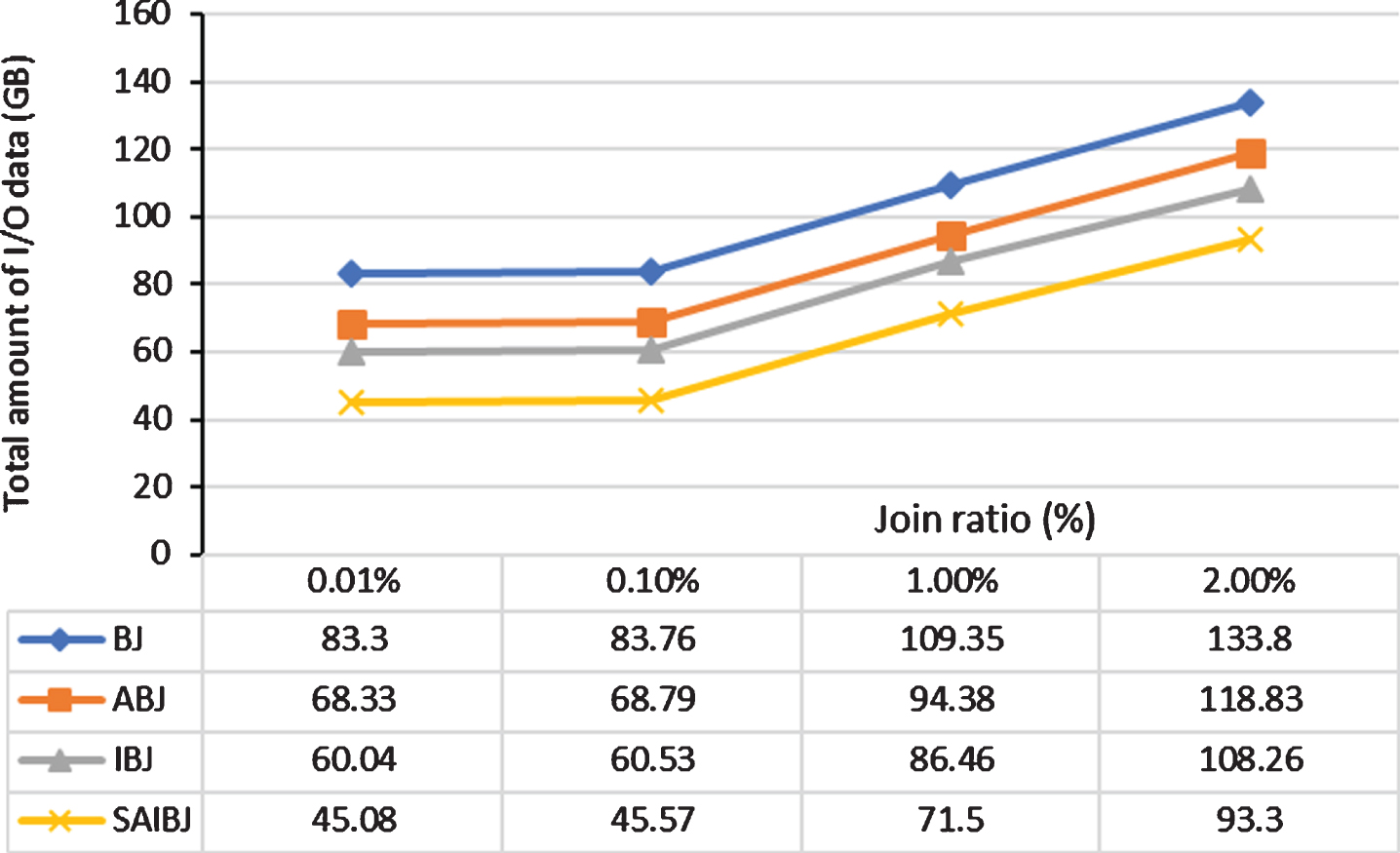
Total amount of I/O data of filter-based joins with varying the join ratio.
AIBJ requires all map tasks to be executed at the same time. If at least one map task of AIBJ is waiting for other map tasks of the same job to release some resources, then AIBJ will not complete execution. In order to avoid this deadlock, we should consider the available resources in the cluster and the number of map tasks of a MapReduce job. Therefore, we dedicated Test3 according to the capacity of resources in our cluster. Table 6 shows the characteristics of the input datasets used in this test. The performance of AIBJ was compared to that of IBJ according to the same metrics used in the previous tests. As in Test1, the Bloom filter size was chosen according to the cardinality of the join key values and the false positive probability. The size of the Bloom filter was set to 16137 bits and the join ratio was set to 0.1%.
Test3 input datasets
Test3 input datasets
The following shows the comparison of the experimental results.
Total Execution Time: Figure 11 shows the total execution time of AIBJ and IBJ. The advantage of eliminating the preprocessing job is clearly depicted in Fig. 11; the total execution time is reduced by a percentage of 34%. Although the join job of AIBJ consumes more time than that of IBJ, the payoff is evident in the preprocessing job.
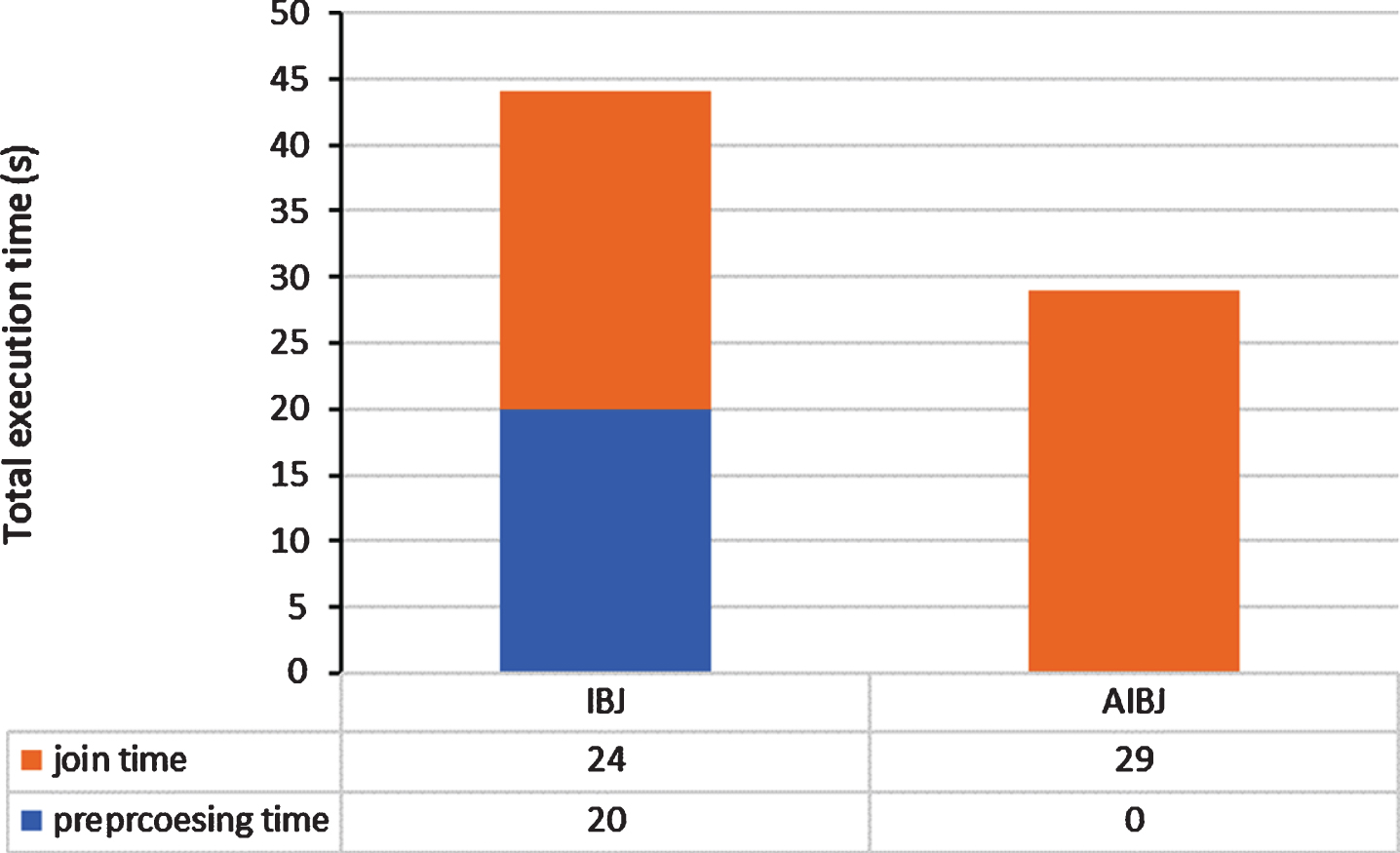
The total execution time of IBJ and AIBJ.
Total Amount of I/O Data: Figure 12 shows the total amount of I/O data of AIBJ and IBJ. The difference in the total amount of I/O data of AIBJ and that of IBJ is equal to the size of the input datasets (4GB). Since AIBJ eliminates the I/O cost of the preprocessing job, the total amount of I/O data is reduced by a percentage of 50% compared to IBJ.
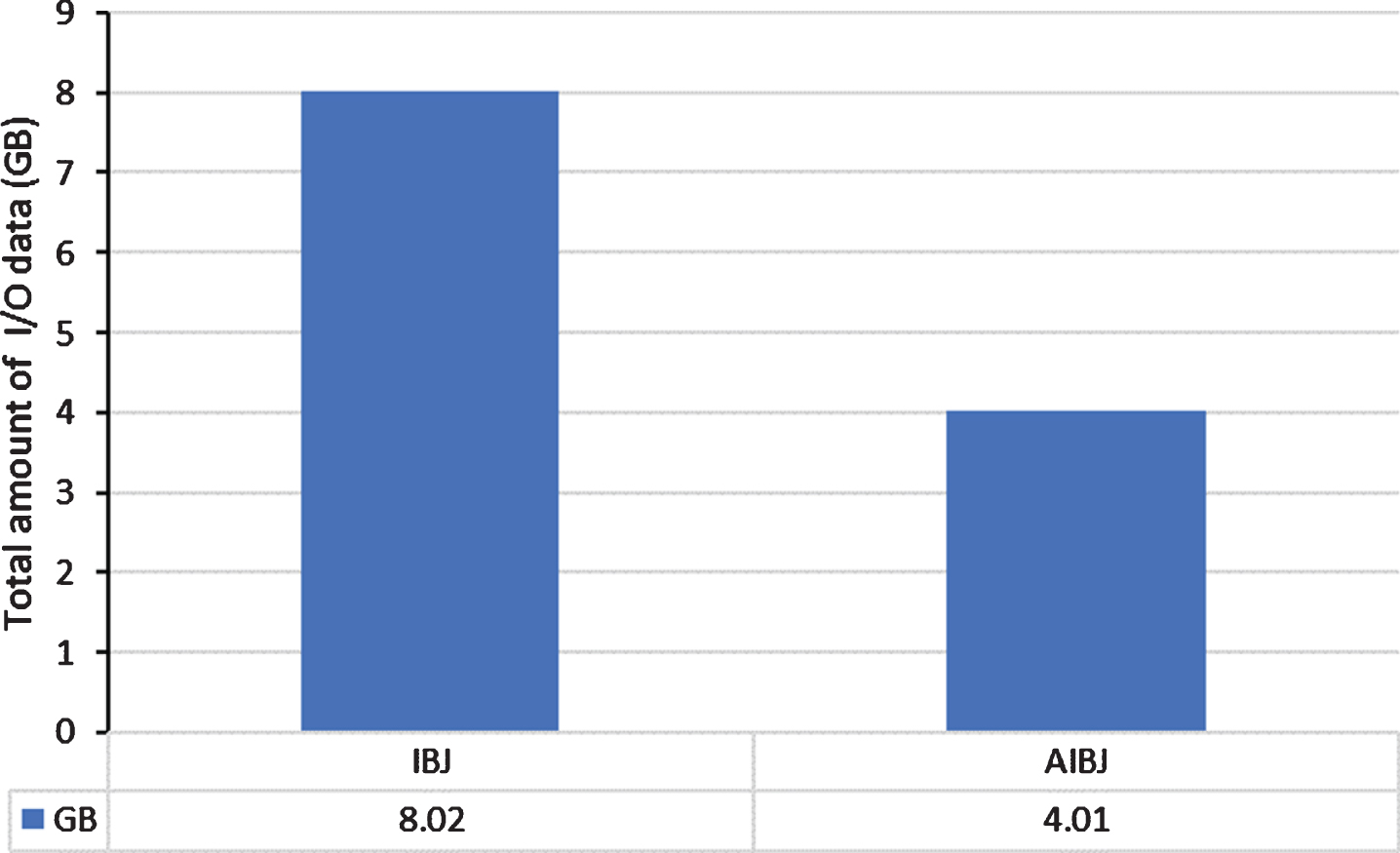
The total amount of I/O data of IBJ and AIBJ.
The Bloom filter size plays a major role in the performance of the filter-based joins. Small filter sizes produce a high false-positive probability and, therefore, increase the number of intermediate records. In contrast, large filter sizes minimize the false positive probability, but they become inefficient in the processes of building and distributing the filters. Therefore, we should choose the optimal size that minimizes the false positive probability and can be efficiently distributed. In the previous tests, we considered these issues. However, in this test, the purpose is to examine the effect of increasing the filter size on the join performance and to find the threshold sizes of our algorithms that are analyzed in Lemma2, Lemma3, and Lemma4. In the experiments, the filter size varied from a minimum of 1MB to a maximum of 75MB. Furthermore, the input size was 30GB and the join ratio was set to 0.01%.
Figure 13 shows the total execution time of SRJ, BJ, ABJ, IBJ, and SAIBJ with varying the filter size. It can be clearly seen that increasing the filter size increases the total execution time of the algorithms, except SRJ. Looking at ABJ and BJ, ABJ exhibits a better performance than BJ for all filter sizes less than 75MB. Therefore, we can conclude that the threshold filter size of ABJ is approximately equal to 75MB. However, for filter sizes larger than 15MB, the filtering process in BJ becomes inefficient, and the same is true in ABJ for filter sizes larger than 25MB. This is because the performance of SRJ becomes better than ABJ and BJ. Turning to SAIBJ and IBJ, SAIBJ exhibits a better performance than IBJ for all filter sizes less than 15MB. Between 15MB and 50MB, both approaches exhibit a comparable performance. Then, SAIBJ begins to exhibit a better performance than IBJ for filter sizes larger than 50MB. This is because IBJ constructs an intersection filter, whereas SAIBJ constructs a pair of filters. However, for all filter sizes larger than 15MB, SRJ becomes the optimal choice.
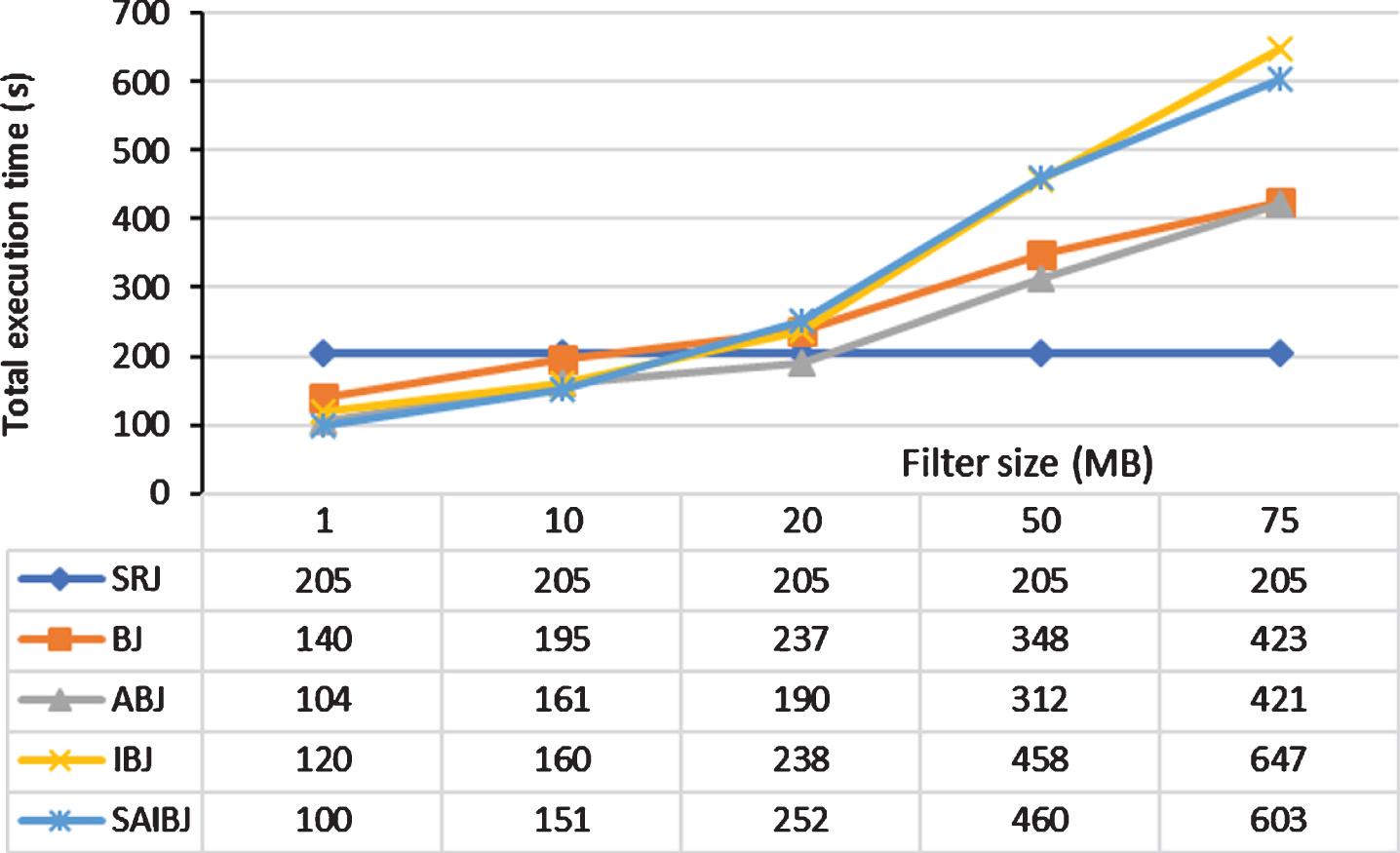
The total execution time of SRJ, BJ, ABJ, IBJ, and SAIBJ with varying the Bloom filter size.
In the evaluation of AIBJ, we used datasets with a total size of 4GB. Figure 14 shows the total execution time of AIBJ and IBJ with varying the filter size. As can be seen from Fig. 14, AIBJ exhibits a better performance than that of IBJ for all filter sizes. Therefore, the threshold filter size of AIBJ for this test is greater than 75MB.
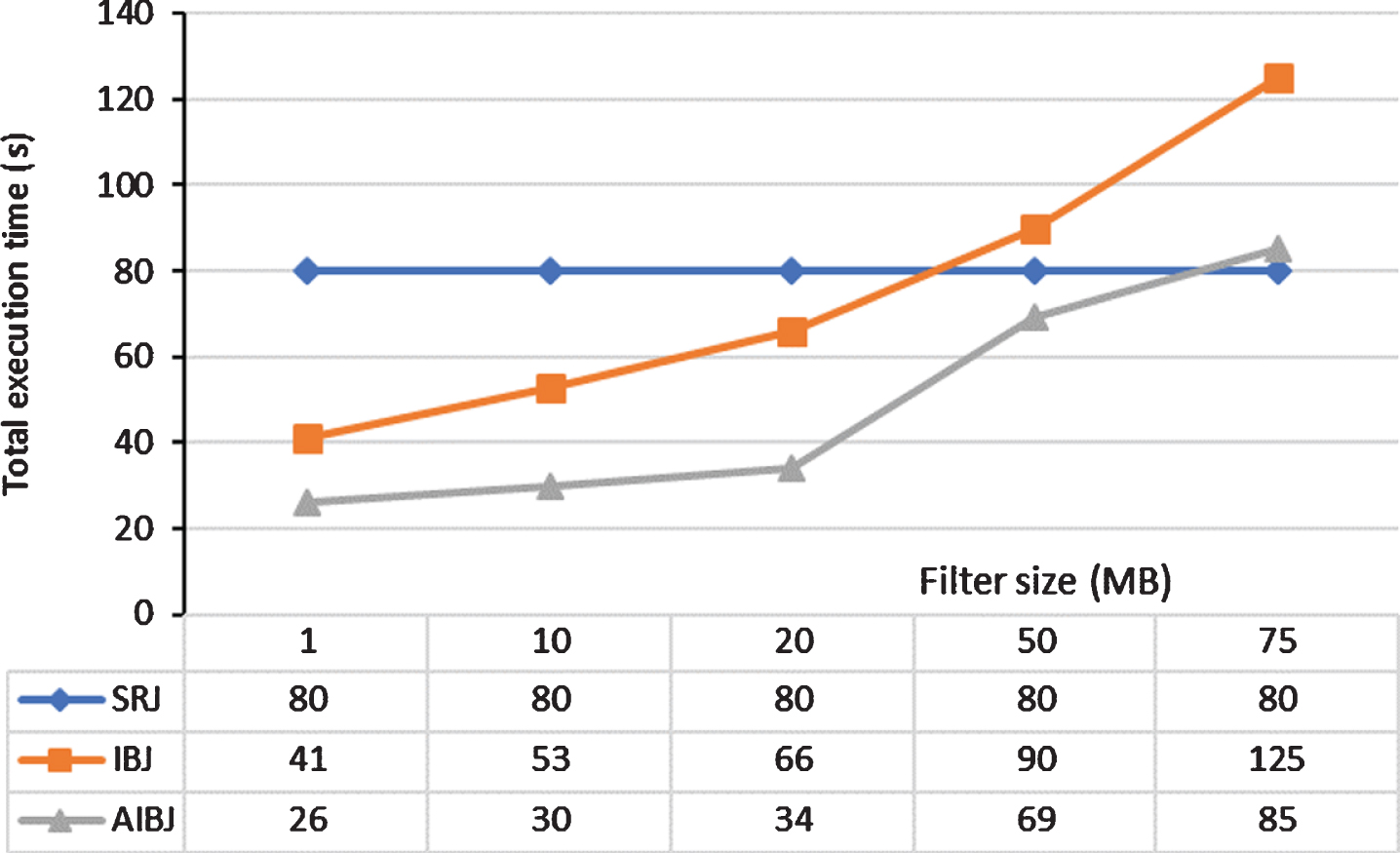
The total execution time of AIBJ and IBJ with varying the Bloom filter size.
It is quite evident from the results presented in Test1 that ABJ and SAIBJ are scalable algorithms and outperform BJ and IBJ. Furthermore, the introduced algorithms improve the join performance as the input size increases. The results presented in Test2 show that ABJ and SAIBJ steadily outperform BJ and IBJ with varying the join ratio. This is because increasing the join ratio only affects the shuffle time and the reduce time. On the other hand, increasing the join ratio decreases the efficiency of the filtering process. In Test3, AIBJ outperforms IBJ, since it eliminates the I/O cost of preprocessing. The results of Test4 show that ABJ, SAIBJ, and AIBJ are more efficient than BJ and IBJ for all filter sizes that enable the filtering process to outperform SRJ. What is worth noting is that as the filter size increases, the performance of SAIBJ and IBJ degrades faster than that of ABJ and BJ. This is because the latter approaches build a filter for only one input dataset.
In summary, the filtering process can boost the performance of a join query. SRJ sends all records from both datasets to the reduce phase. BJ and ABJ send all records from one dataset and the relevant records to the join operation from the other dataset. IBJ, SAIBJ, and AIBJ send only the relevant records to the join operation from both datasets. Table 7 shows the number of intermediate records for each join algorithm executed in Test1 in addition to SRJ. Figure 15 shows their respective total execution time. SRJ has the largest execution time, while SAIBJ has the smallest execution time. As the input size increases, the performance of the filter-based joins becomes more efficient compared to SRJ. This is because the larger the input size the larger the number of redundant records. Concisely, the best of the state-of-the-art filter-based joins decreases the total execution time by a percentage of 45% compared to SRJ, while the best of the introduced algorithms decreases the total execution time by a percentage of 59%.
Number of intermediate records
Number of intermediate records
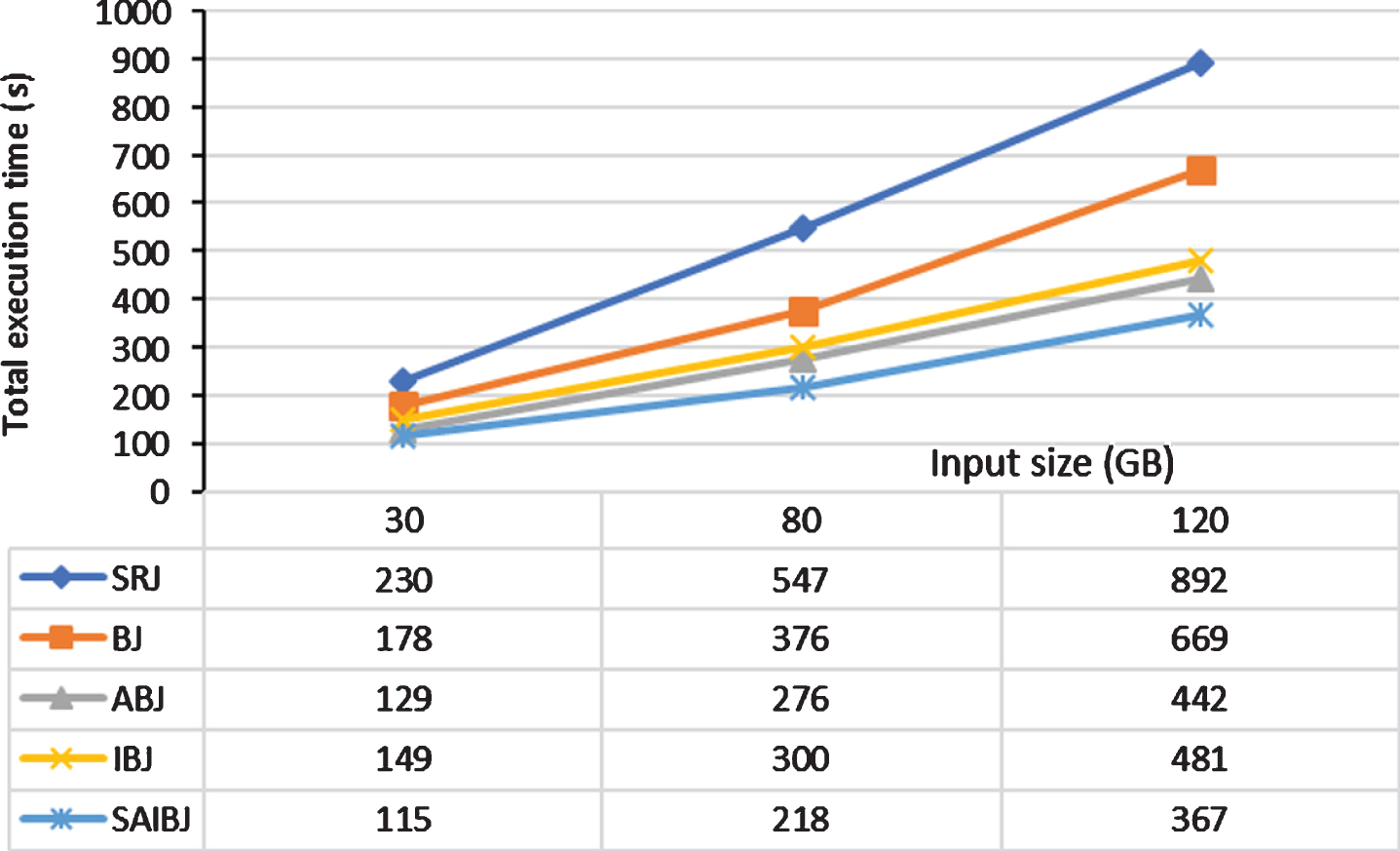
The total execution time of the join algorithms with varying input size (Set1, Set2, Set3).
The join operation is one of the most essential, costly, and frequently used operations for data analysis. Join processing using MapReduce is expensive and not easy to implement. In Section 2, we summarized the state-of-the-art studies that address this issue.
The implementation of the adaptive filter-based join algorithms was described in Section 3. We adapted the concept of filter creation and redundant records elimination within a single MapReduce job and without any prior modifications to the MapReduce architecture. Two strategies were presented in order to dynamically build and distribute the filters. Strategy1 builds the global filter in a distributed manner. On the other hand, strategy2 computes the global filter in a central manner. Theoretically, it has been proven that strategy1 is well suited for small input sizes while strategy2 is well suited for large input sizes. The cost analysis presented in Section 4 shows the introduced algorithms reduce the total I/O cost compared to the state-of-the-art filter-based joins, for all Bloom filter sizes less than a certain fraction (α) of the input split size.
The conducted experiments in Section 5 were divided into four tests. Test1 and Test2 examined the effect of varying the input size and join ratio, respectively. Test3 evaluated the performance of the adaptive intersection Bloom join. Test4 examined the effect of varying the Bloom filter size. The performance of the join algorithms was evaluated in terms of the total execution time and the total amount of I/O data. The experimental results show that the adaptive Bloom join, semi-adaptive intersection Bloom join and adaptive intersection Bloom join decrease the total execution time by averages of 30%, 25%, and 35%, respectively, compared to the state-of-the-art filter-based joins and reduce the total amount of I/O data by percentages of 18%, 25%, and 50%, respectively.
In future work, we plan to extend the introduced algorithms to handle data skew problems. The new approach could retrieve crucial statistical information of the input datasets using the local filters and the hash table of each input split to allow for load balancing Also, we plan to integrate our algorithms in current distributed engines such as Spark and Flink and investigate the potential of building a foundation of a query processing system that selects the most efficient join algorithm.