
Abstract
Data skew in parallel joins results in poor load balancing which can lead to significantly varying execution times for the reducers in MapReduce. The performance of join operation is severely degraded in the presence of heavy skew in the datasets to be joined. Previous work mainly focuses on either input or output load imbalance among reducers, which is ineffective for load balancing. In this paper, we present a new data skew handling method based on Cluster Cost Partitioning (CCP) for optimizing parallel joins in MapReduce. A new cost model which considers the properties of both input and output is defined to estimate the cost of the parallel join. CCP employs clusters instead of join keys from input relations to create join matrix. Using the cost model, CCP identifies and splits heavy cells in the cluster join matrix. Then CCP assigns a set of non-heavy cells to reducers for join load-balancing. For different applications, the input and output weight values in the cost model could be dynamically adjusted to depict the join costs more precisely. The experimental results demonstrate that CCP achieves a more accurate load balancing result among reducers.
Introduction
With the rapid growth of information and data, there is an urgent need for large-scale data analysis and processing. MapReduce – a software framework developed by Google, due to its remarkable features in simplicity, fault tolerance, and scalability, is by far the most successful realization of data-intensive cloud computing platforms [1].
Join operation is one of the most widely used operations in relational database systems, but it is also a heavily time-consuming operation [2]. Unfortunately, it is not directly supported by the MapReduce framework. This is because (1) the framework is originally designed for the processing of a single dataset, and the join operation typically requires two or more datasets, and (2) MapReduce’s key-equality based data grouping makes it difficult to support complex join conditions [3].
One of the major obstacles hindering effective parallel join processing on MapReduce is data skew. Data skew refers to the imbalance in the amount of data assigned to each task, or the imbalance in the amount of work required to process such data [4]. The job completion time in MapReduce depends on the slowest running task in the job. If one task takes significantly longer to finish than others (the so-called straggler), it could delay the progress of the entire job. Stragglers can occur due to various reasons, among which data skew is a serious one.
Standard repartition join based on hash partitioning.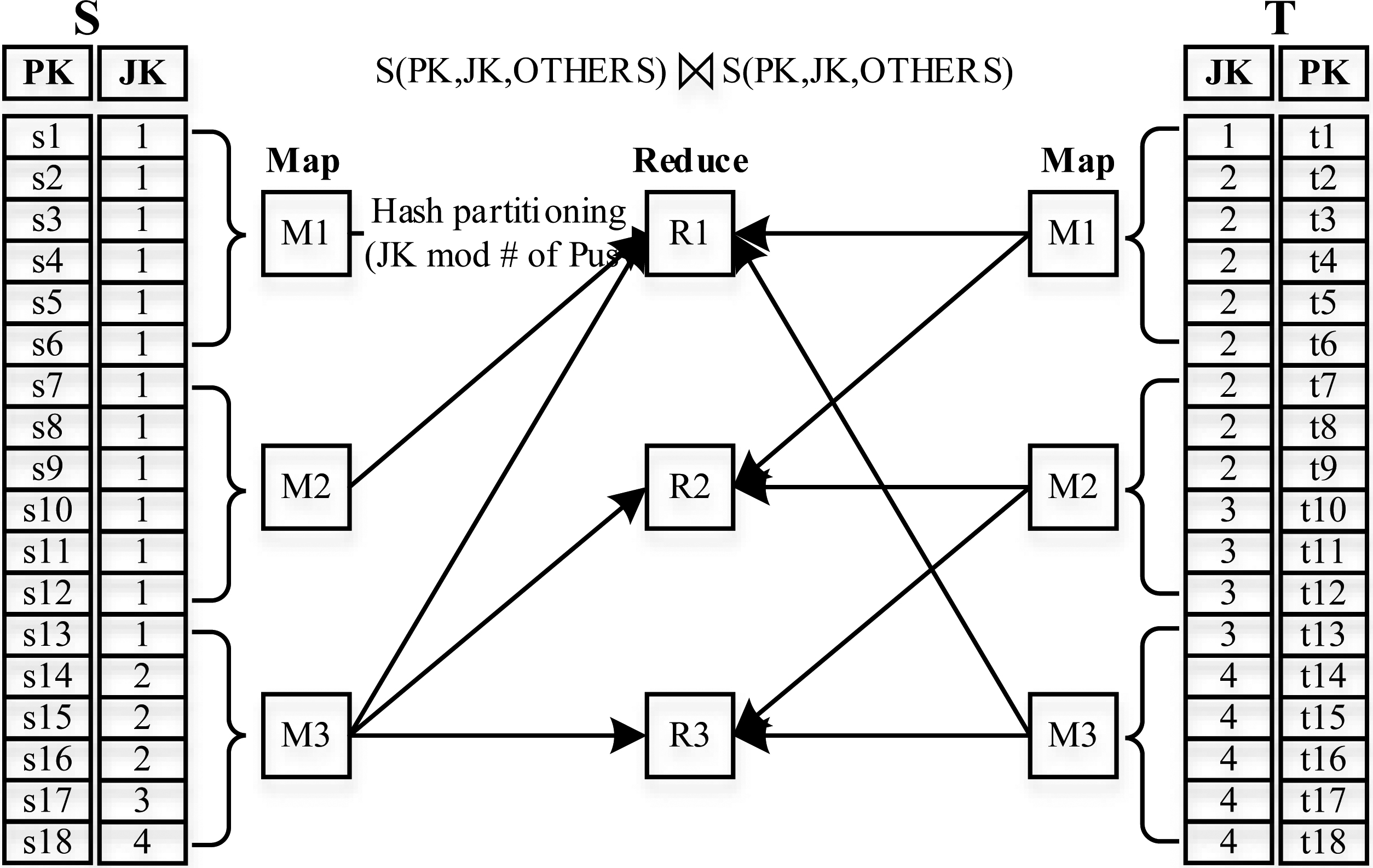
Data skew has been studied previously in the parallel database literature, but only limited on join [5, 6, 7], group [8], and aggregate [9] operations. Handling data skew effects on join operations using MapReduce is a challenging problem, and a simple extension of the traditional solution is insufficient. Recent many researches have been reported in the literature on join operations. Such works roughly fall into the two categories. The first is to design novel join algorithms on top of Hadoop [10, 11, 12, 13]. And the second is to change the internals of Hadoop or build a new layer on top of Hadoop for the optimization of traditional join algorithms [14, 15, 16, 17].
Among the solutions proposed, for users to change the internals of Hadoop or build a new layer on top of Hadoop is a much harder task. When balancing the workload for parallel joins in MapReduce, the distribution of input data received from mappers and the output data produced by reducers are both important for performance. Previous work which designs novel join algorithms balances either input share (for input-size dominated joins) or output share (for output-size dominated joins), stands ineffective for load balancing [13]. Such as skew handling join (Sand-join) [18] which employs range partitioning instead of hash partitioning considers only input load distribution. M-Bucket-I and M-Bucket-O need more detailed input statistics (Multiple-bucket histogram), minimize max-reducer-Input and max-reducer-Output. These two algorithms are designed for input-size dominated joins and output-size dominated joins respectively [10].
In this paper, we present a new skew handling method based on cluster cost partitioning. The method balances both the input data and the output data among reducers when processing skewed data, to overcome the limitations of traditional methods. No modifications of the origin MapReduce framework are necessary. The main contributions of our work include the following.
We proposed a novel load-balancing algorithm, called Cluster Cost Partitioning (CCP), for parallel joins in MapReduce. The algorithm optimizes both input and output imbalance based on cluster cost partitioning and it can achieve a better load balancing result among reducers. The optimization CCP algorithm extended the cluster splitting method for a single dataset to the join algorithm which involves two datasets to handle data skew in MapReduce. We adopted clusters to create join matrix and to build the cluster cost model. We implemented the CCP algorithm on Hadoop and conducted comprehensive experiments. It does not require any modification to the Hadoop source code. All the functions are achieved by specifying the appropriate Map and Reduce functions on top of Hadoop.
The remainder of the paper is organized as follows. Section 2 briefly introduces MapReduce and the recent skew handling methods in MapReduce. The design and implementation of the CCP approach are detailed in Section 3. Section 4 shows representative experimental results. Section 5 reviews related works, and Section 6 concludes the paper.
Overview of MapReduce
The MapReduce programming model introduces a way of processing large-scale data that is based on two functions: Map and Reduce. Map and Reduce are the two primitives provided by the framework for distributed data processing. The signatures of these primitives for key ‘
The Map function transforms a key-value pair into a list of intermediate key-value pairs which are distributed among the reduce functions for further aggregation. In simple terms, data is distributed among the nodes for processing during the Map phase and the result is aggregated in the Reduce phase [19].
Repartition join is the most commonly used join strategy in the MapReduce framework. A two ways equi-join example is illustrated in Fig. 1.
In the standard repartition join, skew in the distribution of the join attribute’s value can overshadow the strengths of parallel processing infrastructure. Figure 1 presents the first example, with default hash-based partitioning. R1 receives 14 input tuples {
Range-based partitioning.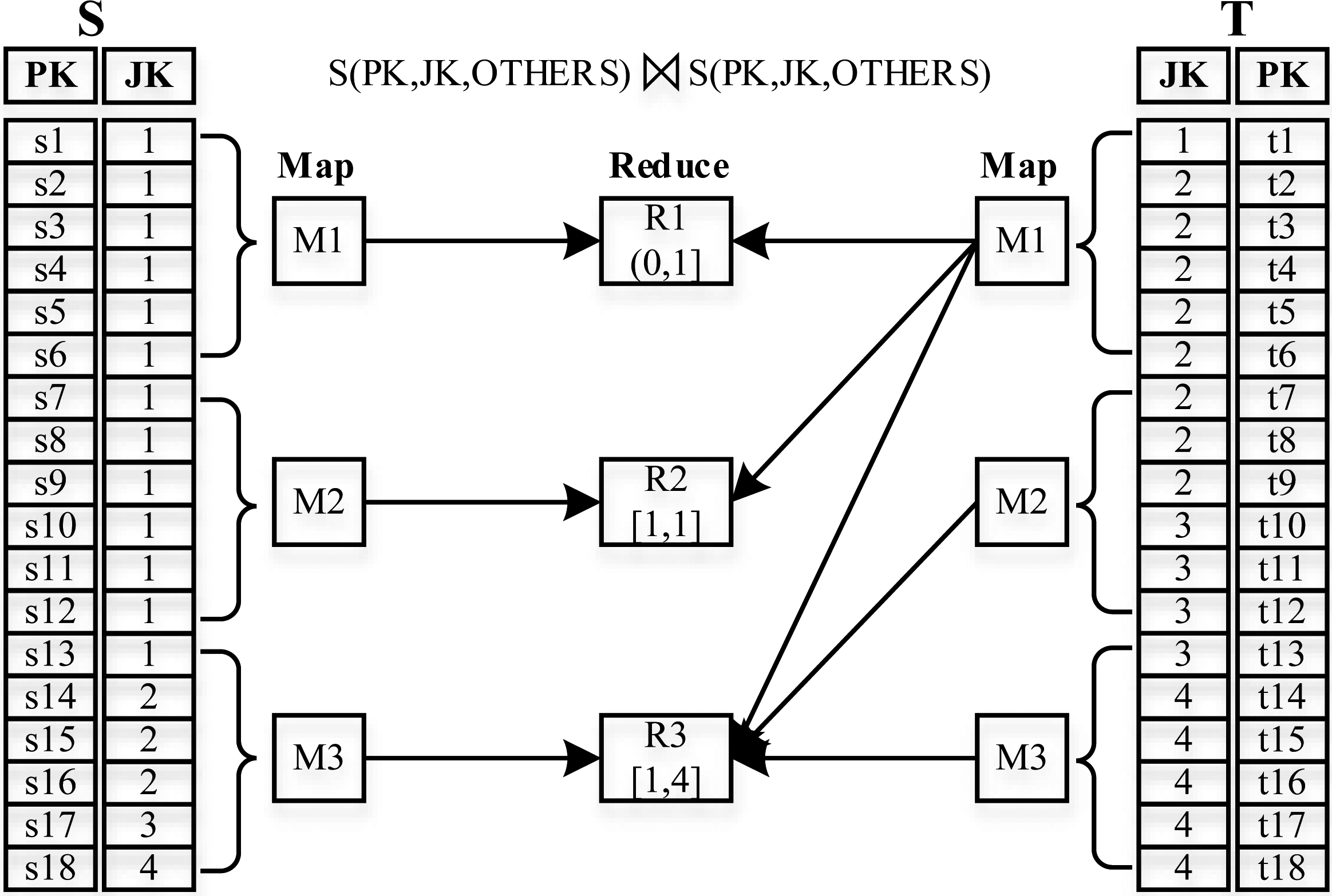
In this section, we discuss three important skew handling methods with intuitive examples. To compare with the performance of our proposed algorithm, the data in all examples is the same. Our original idea of the cluster cost partitioning method is inspired by these examples.
Range-based partitioning method
In range-based partitioning, the domain of join keys is divided into a number of blocks, called ranges. The number of ranges is equal to the number of partitions [18]. Figure 2 presents the second example using range-based partitioning method.
Randomized method
Okcan and Riedewald model a join between two data sets
Skew handling methods based on join matrix.
In order to identify large regions in the join matrix that do not contain any output tuples, a M-Bucket algorithm which need the detailed input statistics of multiple-bucket histogram was proposed by constructing an approximate equi-depth histogram with
A skew handling method called multi-dimensional range partitioning (MDRP) is stochastic like the range-based algorithm and the M-Bucket algorithm.
Processing pipeline at a reducer.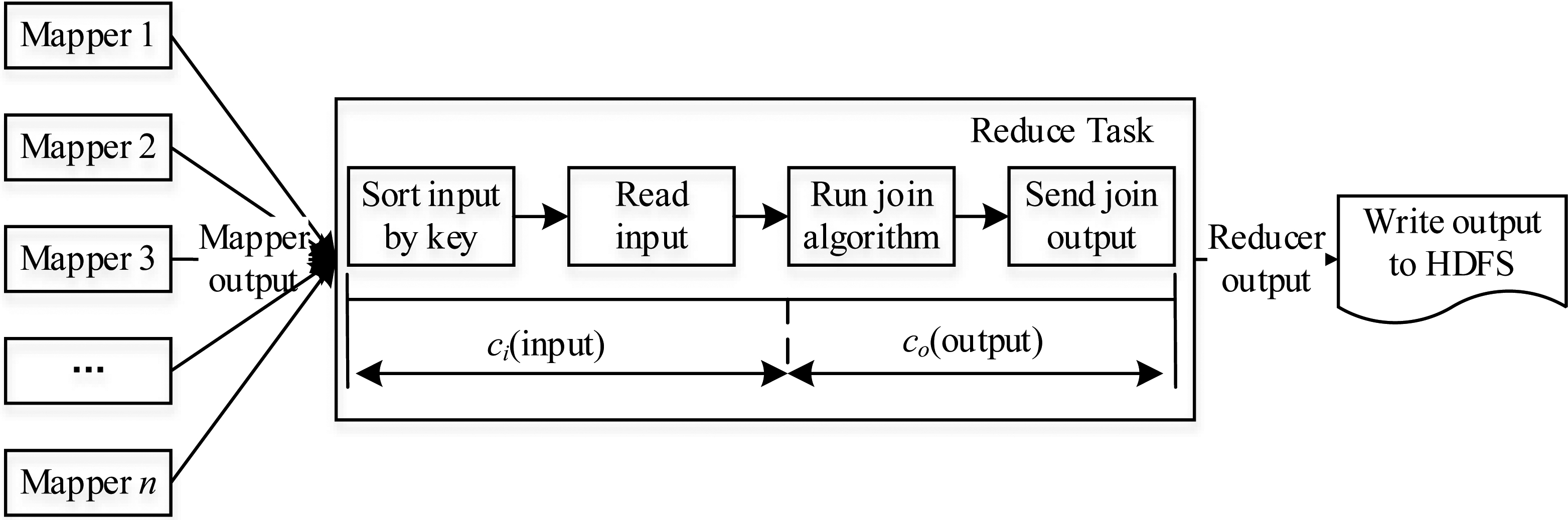
Among different skew handling join algorithms discussed above, the range-based algorithm mainly focuses on balancing input workloads of reducers, it does not consider the join output distribution. While 1-Bucket method practically guarantees to balance the cross-product output across reducers using randomized approach, and M-Bucket can reliably balance input-related join with equi-depth histogram because it knows exactly how many input tuples from each relation belong to each bucket. The multi-dimensional range partitioning method balances output very well by the range-based matrix. However, it uses the range-based cell to replace the key-level cell to balance the input. The number of join key may vary between different ranges in the join matrix. Hence it may incur input imbalance. These algorithms fall into the shortness of considering both the input and the output imbalance.
The cluster cost partitioning (CCP) method is designed to overcome the incapability of existing join algorithms which optimize either for input or output. We consider the properties of both input and output data based on our cost model.
Cost model
Due to the nature of MapReduce, it is easy to balance load between mapper nodes. However, some reducers may receive a much larger amount of data using standard join algorithm. We first analyze the completion time of the Reduce phase, consider a single reducer. The MapReduce shuffles the mapper output to reducers based on the partition function, the reducer uses this shuffled data as its input. It sorts the input key, reads the corresponding value-list for a key, computes the join for this list, and then writes its locally created join tuples to the distributed file system (DFS) [10]. The process of the reducer is shown in Fig. 4.
The objective of load balancing is to minimize the maximum reducer load. As seen in Fig. 4, the problem with the optimal solution is the size of the input and the output data. Since the size of input data received from mappers and the output data produced by the join algorithm in reducers are both important. For a simple example, reducer
where
Cluster cost partitioning
The map function transforms input data into (key, value) pairs. A cluster is the subset of all (key, value) pairs, or tuples, sharing the same key. The clusters are distributed to different reducers by applying a hash function. The proposed CCP algorithm create a join matrix based on the clusters. Each dimension in the matrix represents an input relation, and a cell represents the cross-product of the clusters of the two relations. From the frequency values of each cluster, we can estimate the detailed cost of a cell in terms of both input and output tuples. For the purpose of load balancing, the cluster cost partitioning method identifies and splits the heavy cells into no-heavy cells. Finally, all the no-heavy cells are assigned to reducers based on the greedy heuristics to achieve a load balancing result.
Creation of a cluster join matrix
We first consider the join of two relations
Using these clusters, we can create a cluster join matrix
The cluster join matrix.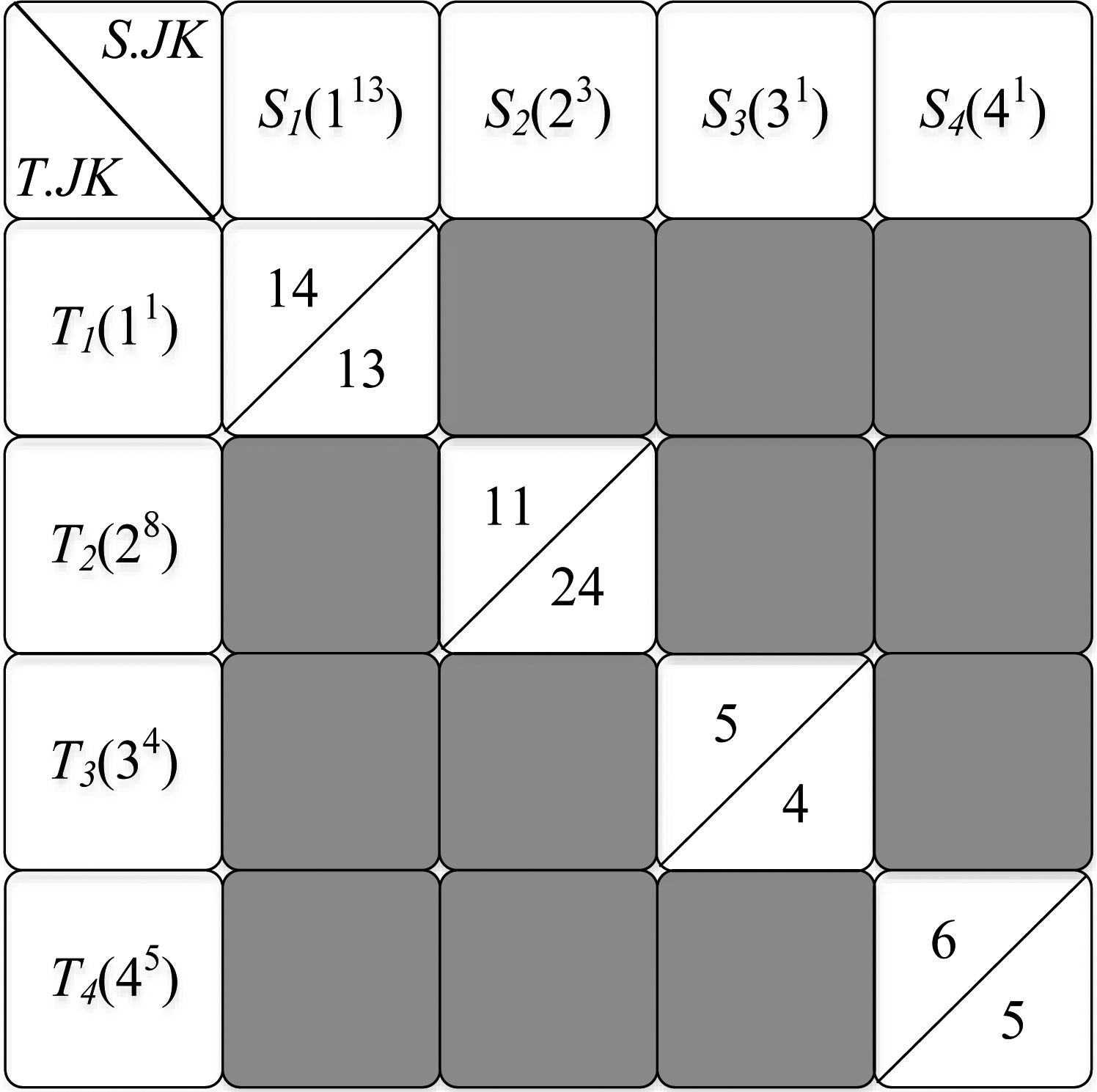
The cluster join matrix can be used to distribute the load to the reducers. Our goal is to find a mapping from the cluster join matrix cells to reducers that achieves optimal for both input and output. When the Map function receives an input tuple from relation
Notice that the cluster join matrix
Since some keys appear more frequently in the intermediate results than others, the clusters may vary considerably in size. Thus, even if each reducer receives the same number of clusters, the overall number of tuples per reducer may still be different. In order to balance reducers’ workloads, we first define a heavy cell as follows:
where
Three partitioning schemes.
For example,
sub-cells. Where
Since the value of
Proof Since
Since
Then the actual workload of the last sub-cell is:
If the frequency value of the cluster
After splitting all the heavy cells in the cluster join matrix, we now have a set of non-heavy cells
A cell
The workload of the first sub-cell is
Seeing the input-size dominated and the output-size dominated examples in Fig. 6a and b, the heavy cell is split into two sub-cells, too. In Fig. 6a, after the sub-cell (
In contrast to previous work in this field, the proposed CCP algorithm achieves load balancing on minimal work per reducer, which considers both input and output workload. And the weight values of
Techniques presented above which include the creation of cluster join matrix, identifying and splitting heavy cells, assigning a cluster to join matrix cells to reducers aim at distributing clusters to reducers such that the workload on all reducers is balanced well. We use
Proof Since all the heavy cells in the matrix
After all the non-heavy cells are assigned to
The total workloads of these
Then in the worst case, the workload imbalance
Since
We use the fragment-replicate technique for actual equi-join processing. For each heavy cell in the matrix, the cluster with larger frequency value is fragmented, and the cluster with smaller frequency value is replicated to multiple sub-cells. As seen in Fig. 6c, the heavy cell (
The frequency value of the cluster
Compared to the range-based method and the MDRP method, CCP algorithm provides fine-grained fragment-replicate control. A sub-range of a relation is determined to be fragmented or replicated in the range-based method and the MDRP method, while our approach determines whether a cluster should be fragmented or replicated based on the frequency value of the cluster. For a heavy cell,
Implementing over MapReduce
In this section, the implementation details of CCP over MapReduce is described. We first introduce the sampling stage, which samples
In our implementation, for an incoming tuple from
Using clusters’ statistics information, we can create a cluster join matrix and split the heavy cells in the matrix. Before the MapReduce job starts, the partitioning matrix is copied to all the mappers. This is achieved by a facility called DistributedCache, which is provided by the MapReduce framework to cache the files required by the applications.
The pseudocode of the map function is shown in Algorithm 1. For each incoming tuple from relation
At the end of the Map function, each reducer receives a list of tuples from relations
The pseudocode of the reduce function is shown in Algorithm 2. The reduce function separates and buffers the input records into two empty sets according to the table tag (Lines 1–8). Then computes the cross-product between the records in these two sets (Lines 9–13).
Experiments
Experimental environment and datasets
Our experiment platform is a cluster of 4 nodes running Hadoop 2.6.0. One machine serves as the master node, and the remaining 3 nodes act as the worker nodes. Each node is equipped with a 3.30 G quad-core Intel i5-4590 Central Processing Unit (CPU), 8 GB of Random-Access Memory (RAM), and a 1 TB hard disk. To show the detailed number of tuples in each reducer with varying the weight values of input and output when evaluating the cost model, the number of reducers in the cluster is set to 10, and Hadoop distributed file system block is set to 128 MB.
We generate two independent datasets as the input relations of the join algorithm. For the sake of performance comparison, we construct datasets of cardinalities 1,000,000 with varying degrees of skew. Each dataset contains three attribute fields (
Experimental results and analysis
Performance evaluation
We first conduct experiments to compare the performance of our proposed CCP algorithm with the other four partitioning approaches (HASH, RANGE, RANDOM, and MDRP). We implemented the Hash partitioning method ourselves. And the range partitioning method is implemented based on [18] and [10]. The MDRP algorithm is implemented according to [3]. For the virtual processor Range partitioning method, we keep the factor of virtual processor ‘2’ i.e. the total number of partitions is 20. To reduce the amount of replication, all the partitions of a table are mutually disjoint except for the highly skewed partitions. The Random algorithm is an implementation of the M-Bucket-O algorithm proposed by Okcan and Riedewald [10]. Experiments in the literature [10] show that the algorithm achieves better load balancing when the number of the buckets is greater than or equal to 100. The number of the buckets in equi-depth histogram is set up to 100. The MDRP requires a square matrix based on deterministic sub-ranges of data. The dimension of the matrix is equal to the number of reducers in the cluster. In our implementation, we have overridden the default hash partitioning method in MapReduce. Each experiment is conducted three times and the mean of those values are presented.
Execution times on skew datasets.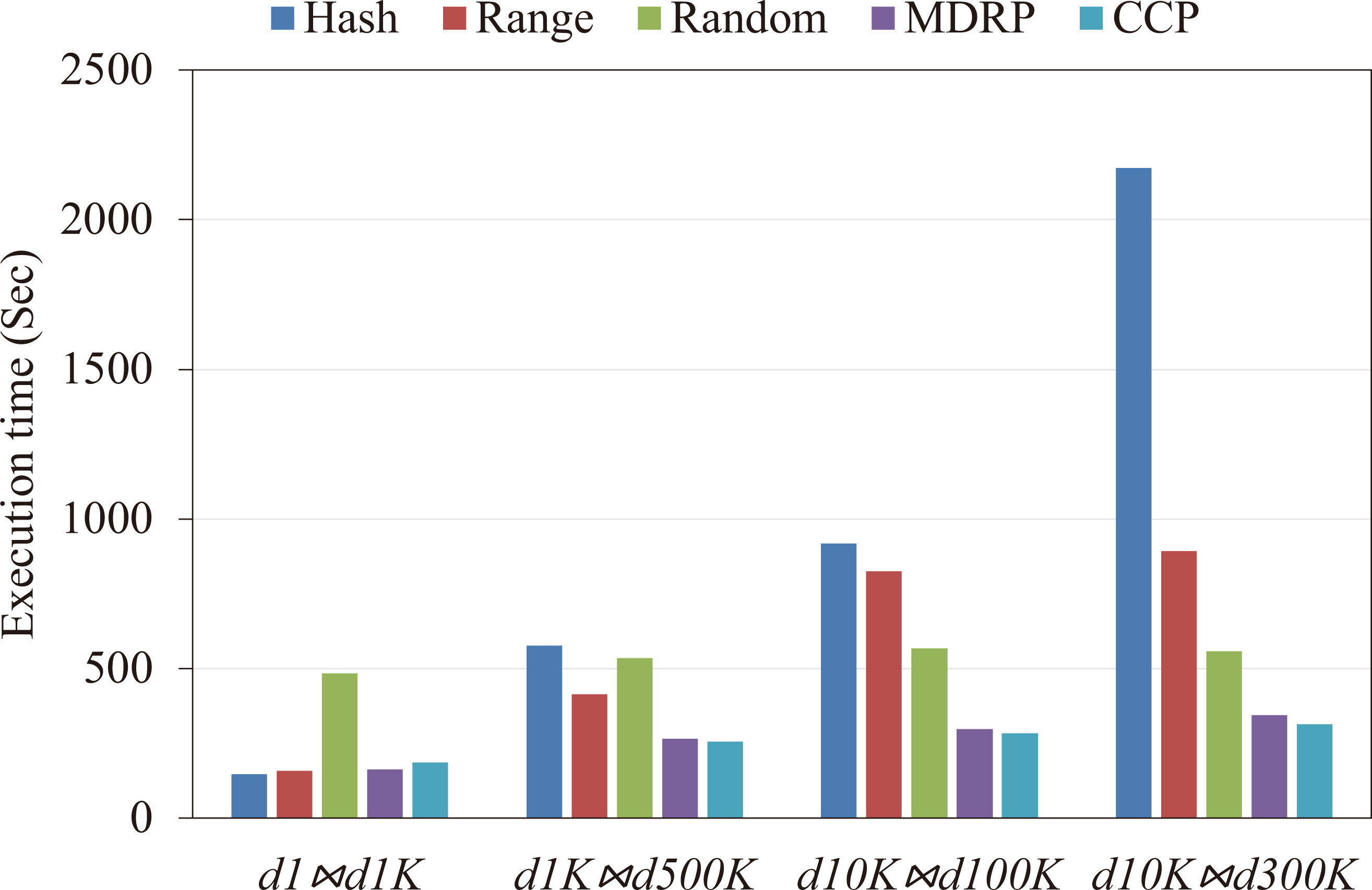
Figure 7 shows the performance comparison of algorithms while varying the degree of skew in the input data. The results of
As the skew increases, the performance of the Hash algorithm starts degrading. This is because the keys are distributed among the reducer nodes according to the hash code of the join key. The reducer receiving the skewed keys are overloaded as compared to the other reducers, hence the overloaded reducer takes more time to compute the join [18]. We notice that the execution time of the Range increases sharply from
Since the total workloads are fixed. The optimal workload of each reducer decrease as the number of reducers increase. Our proposed algorithm divides all the heavy cells into non-heavy sub-cells. These sub-cells are assigned to reducers based on the greedy heuristics. Theorem 2 in Subsection 3.2.3 shows that in the worst case, the workload imbalance is less or equal to 2. Therefore, the elapsed time will decrease as the number of reducers increase. And the CCP algorithm distributes the tuples evenly to the reducers. Hence its performance scales with varying the number of reducers.
The MDRP mainly considers the output balance when assigning candidate cells to reducers. It assumes every cell in the join matrix has the same size of input tuples. In contrast, the CCP algorithm is a hybrid method for both input and output load. As we discussed in Section 3.1, we define the weight function for load balancing among the reducers as:
Load balancing in 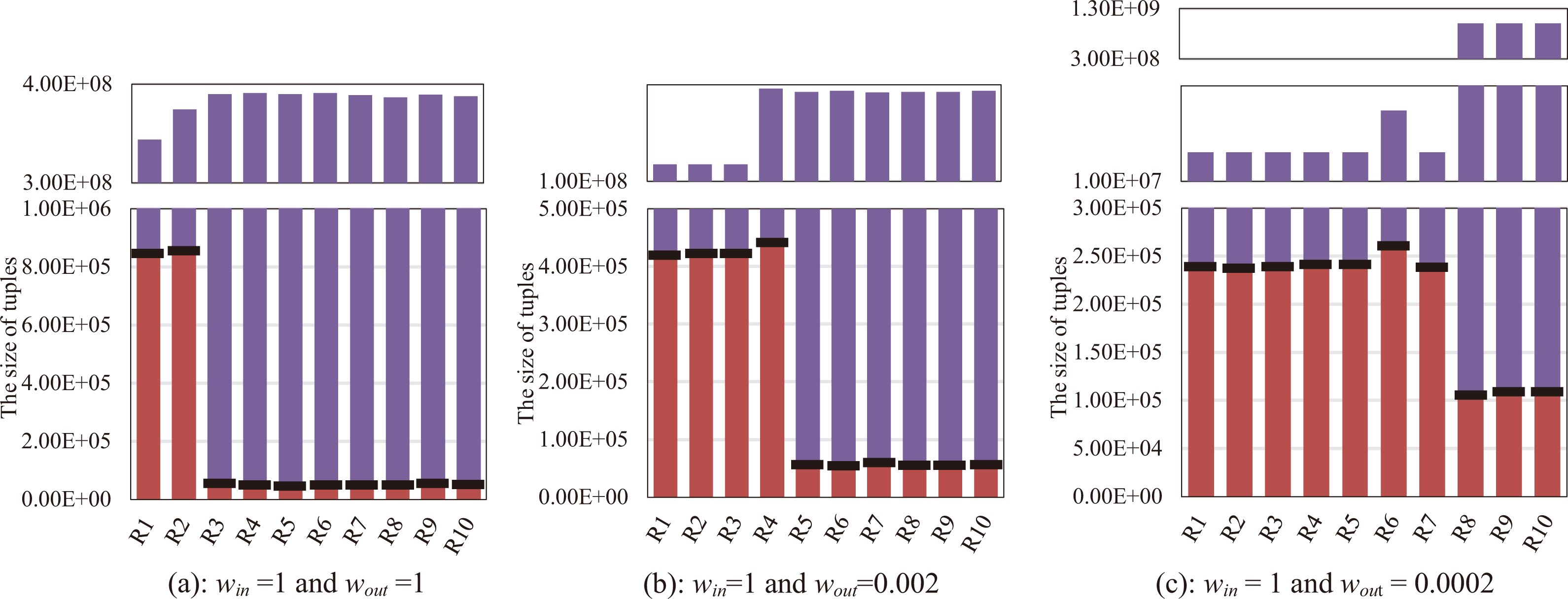
In the
Figure 8 shows the size of the input and output data in each reducer on different weight values. In Fig. 8a, the heavy cell in the join matrix is split into 8 non-heavy candidate cells and these non-heavy cells are assigned to 8 reducers. The reducer 1 and the reducer 2 account for a large proportion of non-heavy cells that the join key attribute values are from 2 to 1000. As we adjust the output weight value
Figure 9 compares the load balancing results with the Hash in the
Before the MapReduce job starts, we sample approximately
Load balancing in 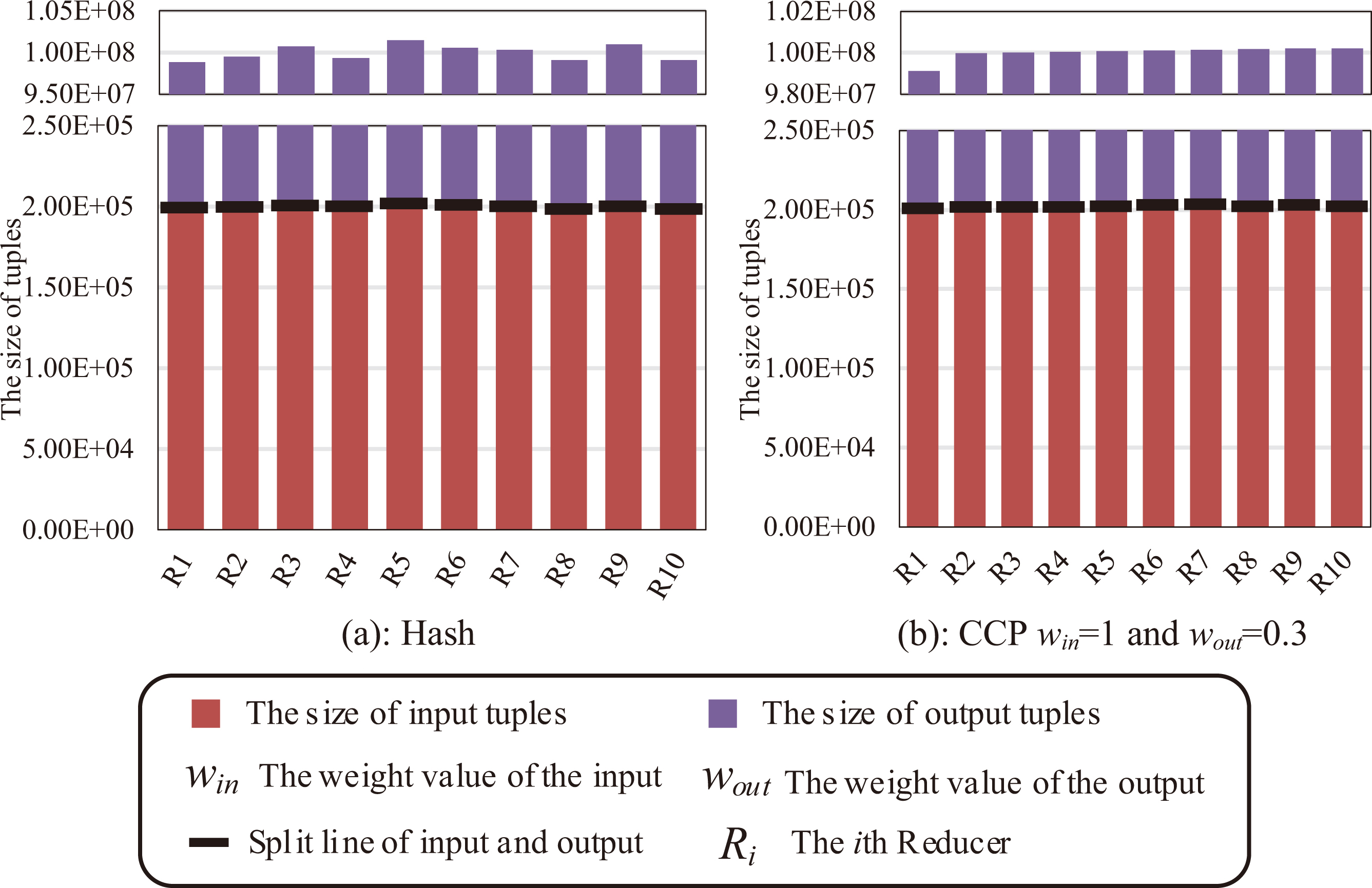
Processing times for the extra cost.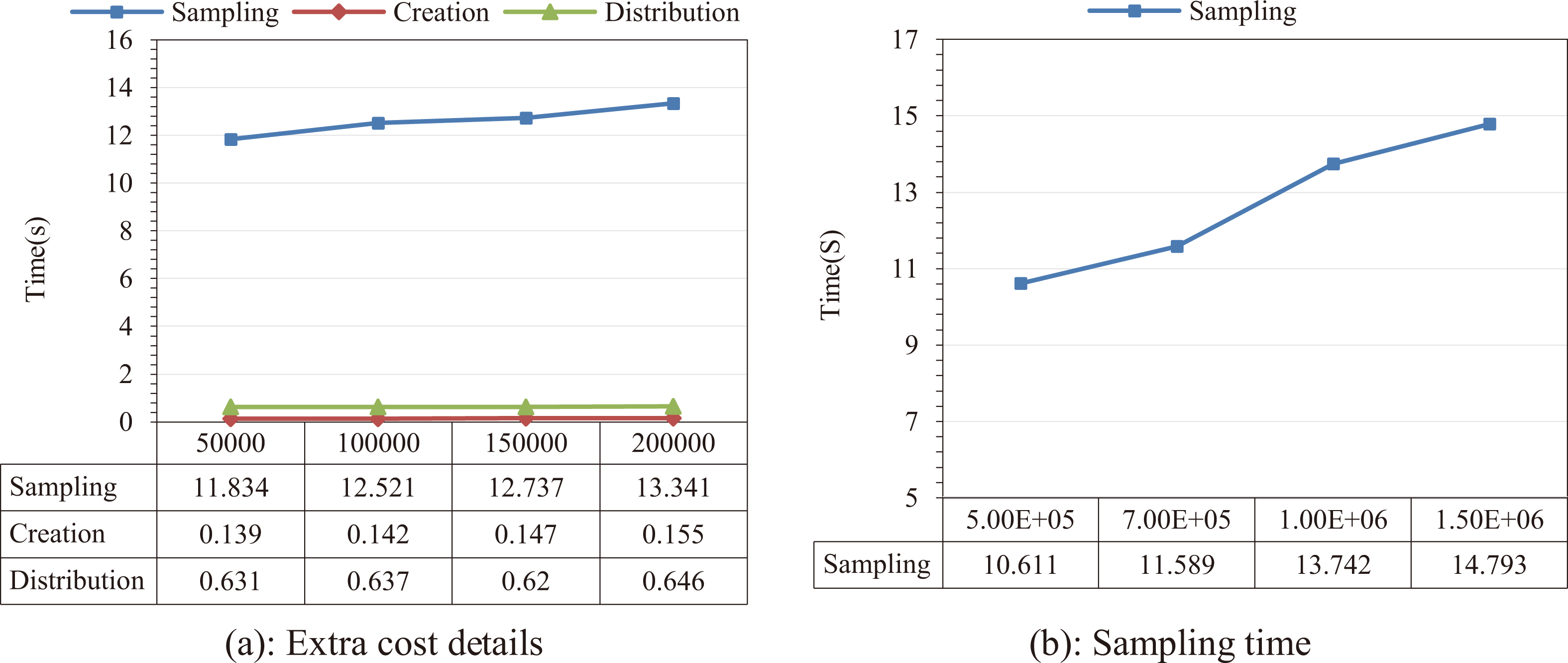
Figure 10a shows the details of the extra cost added with varying the number of sampling size. The creation time and the distribution time is relatively very small compared with the sampling time. As the sampling records increase, the processing time of the sampling also starts increasing. However, the amount of the increasing time is small. This is easy to understand since when the input dataset is fixed, each mapper has to process more records when the sample size increases.
In Fig. 10a, the sampling cost dominates the extra cost, and it increases with the increasing amount of sampled data. To further understand the sampling cost, we change the size of the input dataset to observe the trend of the sampling time. In Fig. 10b, the sampling time increases with the increase of the dataset when the sample size is fixed. However, the same as in Fig. 10a, the increasing time is relatively small. It is notable in our experiments, the MapReduce program is implemented by MyEclipse in Window 7. The sampling time includes the time to initialize Java Virtual Machine (JVM) metrics. From the experimental results, we can conclude that the extra cost is affordable because gains from the skewed input data are significantly bigger than the sampling cost.
Effective handling of skew is an important problem in any parallel system because improper skew handling can counter all the benefits of parallel processing [20]. There has been extensive researchs on handling data skew in parallel databases. While MapReduce shares many challenges and solutions, the fixed execution phase (map, shuffle, reduce) and user-defined functions differentiate the practices for MapReduce applications from the skew resistant relational algorithms in parallel databases [21].
Kwon et al. [22] presented SkewReduce, a system that statically optimizes the data partitioning according to user-defined cost functions. The approach effectively addresses potential data skew problems, but it relies on domain knowledge from users and is limited to specific types of applications. In 2012, they proposed another system called SkewTune [23], the SkewTune system tackles the data skew problem from a different angle. It does not aim to partition the intermediate data evenly at the beginning. Instead, it adjusts the data partition dynamically: after detecting a straggler task, it repartitions the unprocessed data of the task and assigns them to new tasks in other nodes. SkewTune fully utilizes the nodes in the cluster and preserves the ordering of the input data so that the original output can be reconstructed by concatenation. But it does not detect or split large keys and hence cannot make a better partition decision. Chen et al. [4] developed LIBRA (Lightweight Implementation of Balanced Range Assignment), a lightweight strategy to address the data skew problem. LIBRA and SkewTune are complementary to each other. When the load changes dynamically or when reduce failure occurs, it is better to mitigate skew lazily using SkewTune. On the other hand, when the load is relatively stable, LIBRA can better balance the copy and the sort phase in reduce tasks and its large cluster split optimization can improve the performance further when application semantic permit. One feature of LIBRA is its support of large cluster split. This feature is similar to our cluster cost partitioning algorithm, but the LIBRA only considers a single input data set, which is not applicable to join operations. Ibrahim et al. [1] designed the LEEN (Locality-aware and Fairness-aware key partitioning) algorithm to determine the corresponding partition of map output based on the frequency of key-value pairs. All the above methods belong to the strategy of changing the internals of Hadoop or building a new layer on top of Hadoop. In contrary, we design the CCP algorithm on top of Hadoop, it does not require any modifications to the MapReduce environment. Literature [24] proposed two load balancing approaches, fine partitioning, and dynamic fragmentation. Fine partitioning produces a fixed number of data partitions, dynamic fragmentation dynamically splits large partitions into smaller portions and replicates data if necessary. The rationale of splitting large clusters between the fine partitioning and dynamic fragmentation approaches is similar to our CCP algorithm. However, these two methods focus on processing a single dataset. The cost model of the cluster is different with our cost model. Gao et al. [25] proposed a two-stage strategy and the partition tuning method to disperse key-value pairs in virtual partitions and recombines each partition in case of data skew. The proposed Partition Tuning-based Skew Handling (PTSH) algorithm is more suitable for association rule mining on healthcare data. It is similar to the LEEN and the fine partitioning algorithm in the literature [24]. The difference between our CCP and these approaches is that the CCP algorithm can handle data skew in joins.
There has been much work done towards devising efficient join algorithms using MapReduce framework. Blanas et al. [11] surveyed several well-known join strategies in MapReduce. Among these different join algorithms, repartition join is the most commonly used join strategy in the MapReduce framework. In this join strategy, the join datasets are dynamically partitioned on the join key and the corresponding pairs of partitions are joined. When one of the reference table is much smaller than the other table, broadcast join is a better choice in this case. However, this strategy based on hash function for partitioning the data do not handle skew in the input data effectively. Atta et al. [18] introduced “Skew Handling join” that employs range partitioning instead of hash partitioning for load distribution. This contributes to balance the input workloads. A limitation of their algorithm is that they do not consider the output workloads of reducers. Almost at the same time, Okcan and Riedewald [10] proposed the randomized algorithm called 1-Bucket-Theta for arbitrary joins in a single MapReduce job. They also derived the M-Bucket class of algorithms that can improve runtime of theta-join compared to 1-Bucket-Theta by exploiting input statistics to exclude large regions of the join matrix. The general idea of our cluster cost partitioning method comes from this literature. The difference between CCP and randomized algorithm is that we use cluster to create the join matrix. Obviously, the size of clusters is smaller than the number of tuples from two join relations. Using the cluster to create the join matrix can reduce the size of each dimension in the matrix. Zhang et al. [26] extended the randomized method to multi-way theta-join queries. The algorithm can process multi-way theta-join in a single MapReduce job, they proposed a Hilbert curve based on space partition method that minimizes data copying volume over network and balances the workload among reduce tasks. To process multi-way joins in a single MapReduce job need to replicate the map output records multiple times. So, the data transmission from the Map phase to the reduce phase become a bottleneck in the join execution. Myung et al. [3] presented a MDRP method. In MDRP, they use sub-ranges of two relations to create the partitioning matrix. It is stochastic like the range-based algorithm and the M-Bucket algorithm. This work mainly focuses on optimizes either for input or output. Our CCP algorithm can achieve a little better load balancing result than the MDRP. Since the MDRP create the join matrix based on the sub-ranges of join relation. Every sub-range has almost the same number of input tuples. After splitting the heavy cell into several no-heavy cells, the size of input tuples in each sub-cell is less than the other cells in the matrix, while the output in all reducers is balanced. The CCP algorithm considers both the input and the output balance when assigning non-heavy cells to reducers. Vitorovic et al. [13] were the first to employ rectangle tiling algorithms for join load-balancing, the method considers the properties of both input and output data through sampling of the original join matrix. It introduced a coarsening stage to further reduce the regionalization input and built an equi-weight histogram to capture workload skew and partition the work. Our cost model is similar with the cost model in [13], the difference between the two algorithms is we use the cluster instead of the join key to create the join matrix, the size of each sub-cell that is assigned to reducers can be computed based on the frequency value of the cluster in the join matrix. Hassan and Bamha [27] introduced a groupBy-join algorithm called MRFAG-Join (MapReduce Frequency Adaptive GroupBy-join) based on distributed histograms to get detailed information about data distribution. The histogram used in MRFAG-join and the frequency values of clusters in our CCP play the same role. However, the MRFAG-join proceeds in three MapReduce job. It requires two additional MapReduce jobs to compute distributed histogram and partial aggregation of relevant data. Zhao et al. [28] presented a KNN-DP (K-Nearest Neighbors Data Partitioning) algorithm to handle data skewness in KNN joins. The partition strategies used in the KNN-DP algorithm is like the range-based partitioning method. The difference between KNN-DP and CCP is that the k-nearest-neighbor join combine the KNN query and the join operation, it is a very expensive operation.
Conclusions
In this paper, we address the problem of load imbalance of reducers in parallel joins for MapReduce. After providing a survey of current skew handling methods, a novel skew migrating algorithm based on cluster cost partitioning is proposed which considers both input and output load imbalance among reducers. Using our cost model, all the heavy cells in the cluster join matrix are split into non-heavy cells and are assigned to reducers. Skewed clusters in the join matrix are fragmented, and the size of each fragmentation could be computed preciously since the frequency values of each cluster in the join matrix have been obtained through a sampling of the original datasets. The CCP algorithm is capable of handling skew in different applications by adjusting the weight values of input and output in the cost model. The experimental results show that the CCP algorithm achieves a better time and load balancing results.
For future work, we will further extend this algorithm to multi-join queries on large-scale systems. As MapReduce is lack of a schema, lack of a declarative query language, and lack of indexes. We will explore indexing methods to speedup join queries.
Footnotes
Acknowledgments
This work is partly supported by the National Science Foundation of China under Grant Nos. 61640209 and 91746116, the Science and Technology Project of Sichuan under Grant No. SCMZ2006 012, and the Science and Technology Project of Guizhou under Grant No. [2014]2004, [2014]2001, [2016]7433, [2018]5702 and [2015]13.
Authors’ Bios