
Abstract
Time series classification is a fundamental problem in the time series mining community. Recently, many sophisticated methods which can produce state-of-the-art classification accuracy on the UCR archive have been proposed. Unfortunately, most of them are parameter-laden methods and require fine-tune for different datasets. Besides, training these classifiers is very computationally demanding, which makes them difficult to use in many real-time applications and previously unseen datasets. In this paper, we propose a novel parameter-light algorithm, MDTW, to classify time series. MDTW has a few parameters which do not require any fine-tune and can be chosen arbitrarily because the classification accuracy is largely insensitive to the parameters. MDTW has no training step; thus, it can be directly applied to unseen datasets. MDTW is based on a popular method, namely the nearest neighbor classifier with Dynamic Time Warping (NN-DTW). However, MDTW performs much faster than NN-DTW by representing time series in different resolutions and using filters-and-refine framework to find the nearest neighbor. The experimental results demonstrate that MDTW performs faster than the state-of-the-art, with small losses (<3%) in average classification accuracy. Besides, we embed a technique, prunedDTW, into the MDTW procedure to make MDTW even faster, and show by experiments that this combination can speed up the MDTW from one to five times.
Keywords
Introduction
Time series classification (TSC) is one of the most challenging problems and widely used in the time series data mining community. With the growing popularity of temporal data, TSC has been highly applied to many real-world applications, including human activity recognition [44], classification of Electrocardiograms [22], acoustic scene classification [28], speech recognition [38], and many more.
TSC differs from traditional classification problems because time series are always high-dimensional data, and the order of the attributes does matter. In the past few years, a multitude of inspiring algorithms have been investigated to solve the TSC problem, and the greatest research emphasis has been focused on improving the classification accuracy. Representative methods include Elastic Ensemble (EE) [26], Bag-of-SFA-Symbols (BOSS) [35], Shapelet Transform (ST) [16], Collective of Transformation-based Ensembles (COTE) [2], Hierarchical Vote COTE (HIVE-COTE) [27]. These methods are sophisticated and can garner state-of-the-art classification accuracy on the UCR archive [10], which is the primary benchmark for TSC researches. Unfortunately, these newly developed methods suffer from two main drawbacks, which limit their use in many real-life applications.
Firstly, most of the mentioned TSC algorithms require the setting of input parameters, and the researcher is always forced to fine-tune the parameters to achieve the optimal results [14]. Nevertheless, these parameters are dependent on the dataset, and the unsatisfactory results may be obtained if poorly parameter settings are chosen. Thus, these parameter-laden methods can not be directly applied to previously unseen datasets because the trained models rely on a particular dataset [43]. Besides, training these high accuracy classifiers, such as COTE and HIVE-COTE, has very high space and time complexity. For example, training HIVE-COTE on a time series dataset with only 1500 instances can require eight days of CPU time [39]. Therefore, HIVE-COTE is infeasible for many real-life applications, although it can achieve state-of-the-art classification accuracy.
Secondly, in many domains, time series data such as sensor data can be very dynamic. For many parameter-laden methods, it is challenging to generate a trained model when time series in the real-time analytics or mutable database because the user may need to change the model frequently.
We believe that the NN-DTW [42] is an effective TSC method for overcoming these drawbacks. This is for two main reasons: (1) NN-DTW is a non-parametric TSC method that can be directly exploited with mutable and previously unseen datasets. (2) NN-DTW has been widely used and can achieve performance which is not significantly different than the state-of-the-art. However, calculating DTW distance between two time series is rather slow because DTW has quadratic time complexity. Thus, NN-DTW cannot scale well to real-time applications where the responsiveness is essential. With these motivations, in this paper, our objective is to design a parameter-light and efficient method to solve TSC problem. Specifically, the MDTW (shorthand for Multilevel Dynamic Time Warping) is proposed. The MDTW is based on NN-DTW; however, it performs much faster than NN-DTW. The MDTW is a parameter-light method. It involves only a few parameters and needs not to fine-tune the parameters for different datasets. More importantly, the parameters can be chosen arbitrarily because the classification accuracy is largely insensitive to the parameters. MDTW has a pre-processing step; however, the pre-processing time is very small (less than one second) even on large time series datasets, and thus, the overhead of the pre-processing step can be ignored.
To summarize, we make the following contributions In this paper, we propose the MDTW method for time series classification problem. The MDTW involves several different resolutions for time series representations and uses the filters-and-refine framework to calculate the nearest neighbor. Many expensive DTW distance computations can be reduced in the filters-stage. Thus, MDTW can speed up the conventional NN-DTW procedure. The MDTW is orthogonal to most of the methods of accelerating DTW computations and can be used in conjunction with them. To illustrate this point, in this paper, we embed a recently presented technique, prunedDTW [40], into the MDTW procedure to make MDTW even faster. We compare the performance of MDTW with related state-of-the-art methods using the UCR archive. The experimental results show that MDTW achieves similar classification accuracy as NN-DTW. Furthermore, there is no significant difference between our approach and the state-of-the-art in average accuracy, with very small losses (<3%). The empirical studies also demonstrate that MDTW is orders of magnitude faster than the competitors.
The paper is organized as follows. Section 2 presents the necessary background knowledge and related work of our research. In Section 3, we start with some necessary definitions, as well as with a brief introduction of the DTW distance. We then describe the intuition behind our method and give the formal statement and time complexity analysis of the MDTW. The experimental results can be found in Section 4. Finally, the paper is concluded in Section 5.
Background
Time series classification
Given a time series training set, the task of TSC is to train a classifier on a training set and use this classifier to predict the class labels of unlabeled time series. A multitude of techniques have been proposed and we can classify these techniques into five types [1], i.e., interval-based [5, 12], shapelet-based [7, 29], dictionary-based [25, 37], ensemble-based [2, 27] and instance-based [17, 51].
The above four types of algorithms are all parameter-laden algorithms. They involve input parameters and parameters usually determine the best performance of these algorithms. The unsatisfactory results may be obtained if poorly parameter settings are chosen. In order to achieve the best classification accuracy, the user has to fine-tune the parameter settings. Nevertheless, this tuning always has a high space complexity and is very computationally demanding [23, 34]. Thus, the parameter-laden algorithms often perform on servers and are difficult to apply to devices with limited storage and computing resources. In addition, the parameters are highly dependent on a given dataset and may fail to generalize to an unseen but very similar dataset.
The instance-based classifiers have advantages over parameter-laden algorithms in that they can be directly applied to previously unseen and mutable datasets [43]. Instance-based methods calculate the class label of query time series by computing its similarity to all the time series in the training set and the label is determined by its nearest neighbor. Thus, few parameters need to be tuned. In this paper, we focus on the instance-based method. The most prevalent similarity measure in time series domain is DTW. The NN-DTW has been widely used for TSC and experimental results demonstrate that it is not easy to beat on many datasets. However, using conventional NN-DTW to predict class labels is somewhat slow because DTW has quadratic time complexity. Thus, in this paper, we propose the MDTW to accelerate NN-DTW.
We note that the idea behind MDTW can be exploited with most time series similarity measures. We use DTW as a representative example in this paper. However, it is straightforward to implement the idea for various similarity measures. It will be interesting to know the trade-off between efficiency and accuracy.
Accelerating the NN-DTW
To speed up the NN-DTW, a multitude of optimization techniques have been investigated in the past few years. Most of them can be generally divided into:
PDTW and IDDTW are two methods that share some similarities with our method MDTW. We all use the PAA technique. Our method is different from them in that: PDTW only uses one level of approximation and the nearest neighbor is obtained at that level. The user must carefully choose the resolution; however, the best resolution depends on the dataset itself. Our method uses multilevel resolutions, and it has a refine-stage, which calculates the nearest neighbor at the original resolution. Thus, our method is more accurate and robust. Like our proposal, IDDTW uses multilevel approximations. IDDTW builds probabilistic models of the estimation errors for all levels of approximation [11]. Then, IDDTW uses these models to decide whether a candidate time series should be pruned or is worth considering at a finer level. This approach heavily relies on probabilistic models and these models should be built before the querying process. Therefore, it can not be directly applied to an unseen dataset.
The MDTW algorithm
In this part, we introduce the proposed algorithm beginning with describing some useful definitions.
Definitions and Dynamic Time Warping
A time series can be divided into k non-overlapping subsequences. The first k - 1 subsequences have the length of l which is equal to
Typical local descriptor include statistical features (mean, max and variance) and more complex features such as HOG-1D [50]. In this paper, we use mean as our local descriptor, i.e.,
By definition 3.1, the time series T can be reduced from n-dimensional space to k-dimensional space, and the k-resolution sequence becomes the time series reduced dimensionality representation. For example, given a time series T = (2, 1, 0, 2, 1, 3, 4, 2), then we can get
Next, we discuss how to compute DTW distance between the pairwise time series. Given a time series A of length m, A = (a1, a2, . . . , a m ), and a time series B of length n, B = (b1, b2, . . . , b n ), the DTW(A,B) can be calculated as follows. Note that we only present the methodology for calculating DTW due to the limited space. We direct the reader to [8] for a comprehensive survey of DTW.
The intuitions behind our method
The critical insight of our method is that the k-resolution sequences of time series can provide us with useful heuristic information to help us find the nearest neighbor. The observation is that
For example, in Fig. 1(a-d), we present four raw time series collected from the dataset Trace [10] in which the length of time series is 275. Fig. 1(e-h) are their 25-resolution sequences, respectively. Time series a and c belong to the same class, and obviously, they are very close at the original resolution. Moreover, we observe that their 25-resolution sequences, e and g are also close. On the other hand, time series a and b are dissimilar; thus, they are also dissimilar at the coarse resolution.

An example to illustrate that if two time series are similar at the original resolution, their k-resolution sequences must also be similar.
If we want to calculate the nearest neighbor of time series a, an efficient method is that we can scan across all the 25-resolution sequences and calculate the nearest neighbor at that resolution. In our example, g is the nearest neighbor of e; thus, we infer that c is the nearest neighbor of a at the raw resolution. This efficient method is actually PDTW. However, two drawbacks limit the use of PDTW in real-life datasets. Firstly, it only uses one level of approximation. However, the best resolution depends on the dataset itself [11] and users must carefully specify the resolution used. Secondly, the nearest neighbor is found at the coarse resolution. However, two time series can be arbitrarily close at the coarse resolution but very far apart at the original resolution. We will give a concrete example later. Thus, the classification results of PDTW are unsatisfactory.
We propose a hierarchical method, MDTW, to solve the problems which occur when only using one resolution. The MDTW involves several different resolutions for time series representation and calculates the nearest neighbor at the original resolution in the refine-stage. Before formally describing the MDTW, we here provide a concrete example to illustrate our method and help the reader gain an appreciation for the MDTW. Fig. 2 shows a small dataset with six time series. The value on time-axis ranges from 0 to 4×π with fixed step size 0.01; thus the length of time series is 1256. In this example, the objective is to find the nearest neighbor of time series a when using DTW distance as the similarity measure. The sequential scan (exhaustive search) examines the DTW distances between a and all time series in the dataset sequentially. Hence the query time complexity in exhaustive search is high.

A small dataset with six time series. Note that
MDTW uses useful heuristic information at the coarse resolution to reduce the number of expensive DTW distance computations. MDTW first calculates the 2-resolution sequences and 4-resolution sequences of all raw time series. The results can be found in Table 1. It is worth noting that although time series a, b, c, e are totally different, their 2-resolution sequences are exactly the same. Then, MDTW uses the filters-and-refine framework to find the nearest neighbor. Specifically, MDTW calculates the DTW distance from

The framework diagram of using MDTW to find the nearest neighbor.
Representing raw time series in different resolutions
To significantly accelerate the NN-DTW, we must find a way to reduce the number of DTW computations. This is critical because each DTW computation takes quadratic time. MDTW uses the filters-and-refine framework to prune off a significant fraction of DTW computations so that the algorithm does not need to calculate the distance between query and all time series. In the following, a formal and detailed description of MDTW is presented. We list notations frequently used in this paper in Table 2.
The notations frequently used in this paper
The notations frequently used in this paper
Given a dataset D of N time series
The time complexity of Algorithm 1 is O (NMn). Note that when amortized over large numbers of time series queries, the overhead of pre-processing will be relatively minor. We then define a filter vector T of M integers (T1, T2, . . . , T M ), in which 1 < T M < TM-1 < . . . < T1 < N. The filter vector represents that at i-th level, MDTW only preserves the T i -nearest neighbors and prunes off the remaining data. We also use DTW distance to measure the similarity at each resolution.
M: the number of approximate levels;
K: resolution vector K = (K1, K2, ..., KM);
D: the time series dataset;
1:
2:
3: temp ← K i -resolution sequence of D j ;
4:
5:
6:
7:
We conclude a procedure of MDTW as shown in Algorithm 2. The filters-and-refine approach is used in Algorithm 2, which aims at reducing the number of exact DTW evaluations by using a computationally efficient strategy. In the filters stage (line 1-11), we first initialize the candidateSet with all time series in D (line 1). The K i -resolution sequence of the query time series at i-th level is computed in line 3. Then we calculate all DTW distances between query and every time series in candidateSet at i-th level (line 4-8), and only preserve the T i -nearest neighbors while removing others from candidateSet (line 9-10). To further filter out more time series data, we refine these candidates in a more refined resolution. The process of refining and calculating is continued until all M levels are evaluated (line 2). We note that compared to other time series, the remaining T M time series are more likely to be the nearest neighbor of query time series.
In the refine stage (line 12-21), MDTW examines the 1-nearest neighbor by calculating the actual DTW distance at the original resolution among the remaining T M time series. In MDTW, many DTW computations can be calculated in low-dimensional space. Therefore, the query processing is accelerated.
As described in Section 2.2, there are dozens of methods for accelerating NN-DTW. Although such methods can be faster than traditional NN-DTW in the best case, some of these methods, such as the lower bound techniques, degenerate to sequential scan in the worst case. In contrast, we will show that the performance of the MDTW is completely independent of the dataset and can always be faster than NN-DTW.
q: query time series;
M: the number of approximate levels;
T : filter vector T = (T1, T2, ..., TM);
K: resolution vector K = (K1, K2, ..., KM);
D: the time series dataset D = {D1, D2, ..., DN};
res: the nearest neighbor of query
1: candidateSet← all time series of D;
2:
3:
4: DTW _ res = [];
5:
6:
7: DTW _ res . add (temp);
8:
9: newCandidateSet = sort (DTW _ res, T i );
10: candidateSet = newCandidateSet;
11:
12: best _ so _ far← + ∞;
13: res ← null;
14:
15: temp = DTW (q, D i );
16:
17: best _ so _ far = temp;
18: res = D i ;
19:
20:
21:
We give some complexity analysis of MDTW outlined in Algorithm 2. At the 1-th level, MDTW costs
operations to calculate DTWs.
Suppose that cK
M
= n and bT1 = N, in which the value of c can be considered as the compression rate, which is the ratio of the length of the original time series (n) to the length of its K
M
-resolution sequence (K
M
). Similarly, b is the filter rate, which is the ratio of the the size of time series dataset (N) to the size of the remaining candidateSet (T1) in the first filter-stage. By introducing c and b, we have
Note that the purpose of introducing b and c is to help us analyze the time complexity of the MDTW; otherwise, it is very difficult to establish the relationship between Equation 1 and Equation 5.
Equation 7 is a worst case bound, which demonstrates that MDTW performs faster than NN-DTW. The astute reader will note that, in our analysis, the time complexity of online transformation (line 3) and sort function (line 9) is omitted. However, for high dimensional time series, this cost is relatively minor and the main part of time complexity of MDTW is calculating DTW distances. Therefore we can reasonably ignore the cost of online transformation and sort function.
MDTW focuses on reducing the total number of expensive exact DTW computations. However, MDTW still needs to calculate the exact DTWs between q and the remaining T M time series. The simplest way to implement the refine stage is to compute the DTWs using traditional DTW distance calculation method [8]. However the traditional method involves quadratic time complexity; thus, even being performed only to the few time series, the refine stage still could be computationally expensive.
To make MDTW even faster, in this paper, we embed a recently proposed method, prunedDTW [40], into the MDTW procedure. Specifically, we adapt the prunedDTW algorithm to compute the DTW distance in Algorithm 2 (line 15). We choose prunedDTW for three main reasons: (1) prunedDTW is an exact algorithm. For two arbitrarily chosen time series A and B, we have prunedDTW (A, B) = DTW (A, B) . (2) prunedDTW has no parameters. This property is consistent with our purpose of designing MDTW. (3) prunedDTW can improve the efficiency of the DTW computation. Thus, we can speed up the refine stage.
Although combining with prunedDTW is just a small trick, in Section 4, we demonstrate that this small trick can speed up the MDTW from one to five times.
Experimental evaluation
We carry out an extensive set of experiments to verify the efficiency and effectiveness of the proposed method for TSC. This section reports and analyzes the experimental results. We implemented all methods in MATLAB (version R2019b), and performed all experiments using Windows 10 enterprise with 2.60 GHz and 16 GB memory.
Experimental Setup
Datasets
We conduct experiments on 18 representative datasets collected from the UCR archive [10]. Table 3 shows detailed information about the datasets. The selected datasets are collected from different application fields and are of various types, including sensor data, motion, image, simulated, and ECG data. The datasets vary widely in their time series lengths, number of classes, the size of the dataset, and the number of queries. Besides, compared with other UCR datasets, the chosen datasets can be regarded as large datasets that are generally larger in dimensionality or size. The small datasets can be performed relatively fast with the traditional methods; thus, in our experiments, we mainly focus on large datasets.
Datasets descriptions and the pre-processing time (second) of MDTW for each dataset
Datasets descriptions and the pre-processing time (second) of MDTW for each dataset
In this part, we give a short introduction of the baseline methods. We select these baseline methods for two main reasons: (1) they are all parameter-light classifiers, and few parameters need to be tuned. (2) They are widely used for TSC and can achieve state-of-the-art performance on many datasets. NN-DTW is one of the benchmark methods for TSC. It uses brute-force strategy to find the nearest neighbor. Weighted DTW (WDTW) [17], shapeDTW [51] and Complexity-Invariant DTW (CIDTW) [3] are three popular DTW variants for solving TSC problem and they improve the performance of DTW significantly. Move-Split-Merge (MSM) [41] and Edit Distance with Real Penalty (ERP) [9] are two well-established similarity measures for time series and are widely used in instance-based framework.
In addition to the above algorithms, three techniques of accelerating NN-DTW procedure are also considered as baseline methods to demonstrate the efficiency of the MDTW. PDTW [20] shares some similarities with our method. However, only one coarse resolution is used and the nearest neighbor is calculated at this resolution. Thus, the classification accuracy is unsatisfactory. FTW+prunedDTW is a combination of prunedDTW [40] and FTW [31]. FTW+prunedDTW uses the prunedDTW to calculate the DTW distance and uses the lower bound presented in FTW to reduce the number of prunedDTW computations. MDTW+prunedDTW is the method described in Section 3.5. In this Section, we will show that MDTW+prunedDTW can make MDTW even faster.
Parameter setup
In MDTW, the number of approximate levels M, the resolution vector K and the filter vector T should be considered before the evaluation. However, these parameters can be determined arbitrarily, and fine-tuning is not required for various datasets. Thus, in our next experiments, we set the same parameters for all datasets. Specifically, we set M = 2, K = (10, 20) and
Pre-processing time
As described in algorithm 1, the time series in the dataset need to be approximated in different resolutions before the query procedure is executed. In this experiment, we evaluate the time cost of the pre-processing stage in MDTW approach.
Table 3 shows the pre-processing time (in seconds) of the MDTW on different datasets. It can be found that the pre-processing time is very small (less than one second). For example, the pre-processing time of MDTW on the ElectricDevices dataset with 8926 instances is only 0.7923 second. It is an important characteristic in many real-time applications because the overhead of the pre-processing step can be ignored.
Efficiency
This subsection shows the evaluation of the efficiency of each approach against NN-DTW in classifying query time series. For each dataset, the speedup rate is reported. Assume that t1 is the query processing time for NN-DTW and t2 is the query processing time for a particular method Θ, then the speedup rate of the method Θ is t1/t2. Fig. 4 shows the speedup rate of different methods on the UCR datasets. Note that the time complexity of the shapeDTW is too high and we can not obtain its specific query time on our laptop; thus, we do not list its speedup rate.
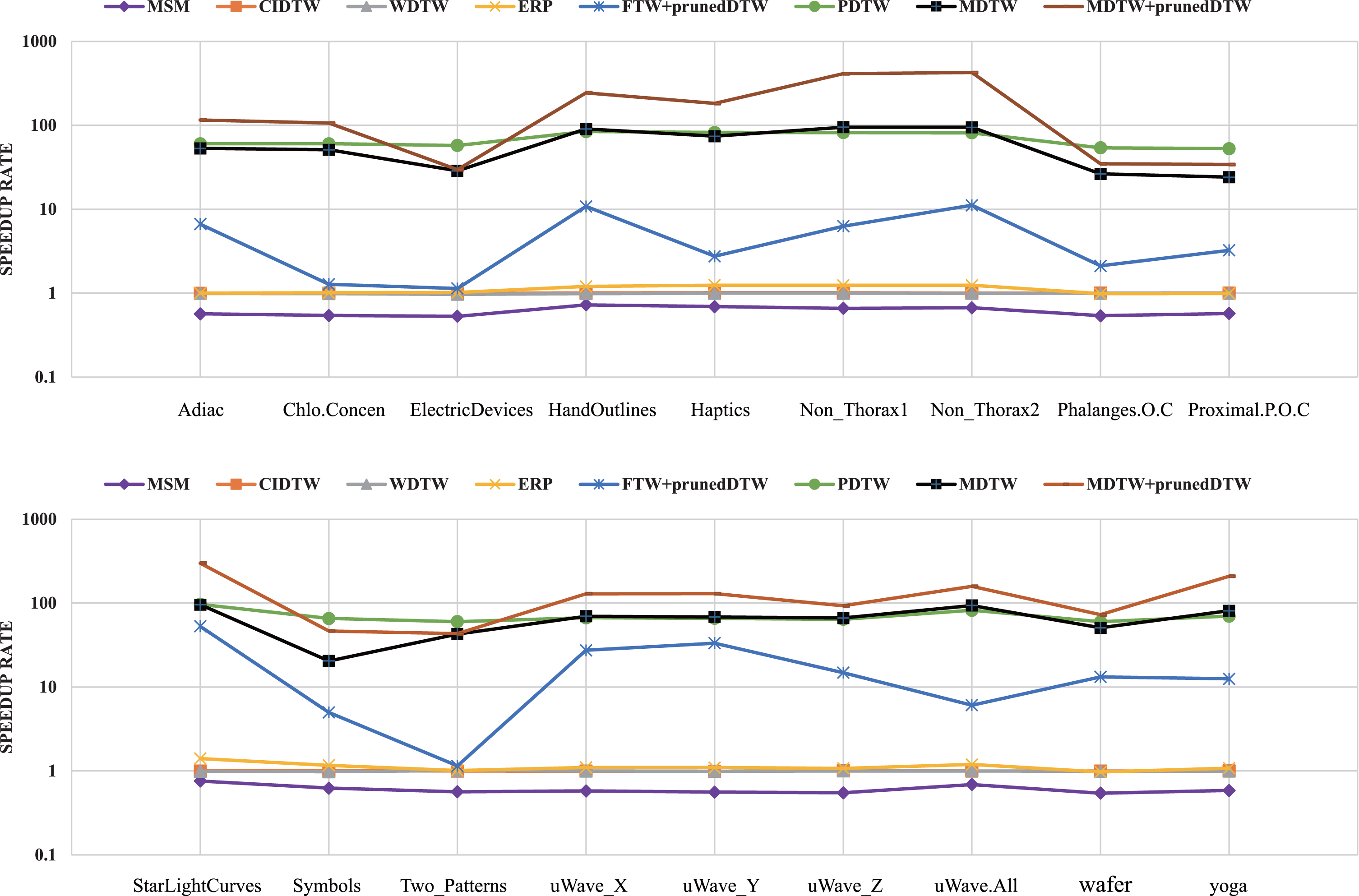
The speedup rate of different methods on the UCR datasets.
Fig. 4 illustrates that the MSM demonstrates poor result (the speedup rate is smaller than 1), and its query efficiency is worse than other methods. The CIDTW, WDTW and ERP are all quadratic-time algorithms, and as shown in Fig. 4, they have a similar query processing time as DTW under the nearest neighbor classifier (the speedup rate is close to 1). Furthermore, it can be clearly seen that NN-DTW spends much more time than MDTW, which demonstrates that MDTW can speed up NN-DTW as we expected. Specifically, MDTW achieves 20 to 95 faster than NN-DTW. Besides, it can be noted that MDTW+prunedDTW performs faster than MDTW and FTW+prunedDTW from 1 to 5 times and 4 to 85 times, respectively. Thus, we verify that when MDTW and prunedDTW are combined, MDTW+prunedDTW significantly outperforms both MDTW and prunedDTW individually.
Fig. 4 also shows that PDTW performs faster than NN-DTW and FTW+prunedDTW. Thus, PDTW can be regarded as the most competitive method among all the baseline methods. The Wilcoxon signed-rank test is conducted to demonstrate the superiority of the proposed approaches. Specifically, the p-value between PDTW and MDTW is 0.2668 > 0.05, which shows that the difference is not significant with the confidence of 95%; thus, the efficiency of MDTW is comparable to PDTW. The p-value between PDTW and MDTW+prunedDTW is 0.0043 < 0.05; thus our proposed improved MDTW method performs significantly better than PDTW and can be regarded as the most efficient algorithm among all competitors.
In this subsection, we compare MDTW with baseline algorithms to evaluate the effectiveness of MDTW. The classification accuracy is reported. The experiment results of the PDTW are implemented by ourselves, and the results of the other six baseline approaches can be obtained in [1, 48]. Table 4 presents the classification results and average accuracy. Note that MDTW+prunedDTW and FTW+prunedDTW are not listed in Table 4 because they have the same accuracy with MDTW and NN-DTW, respectively.
The results of the classification accuracy
The results of the classification accuracy
From Table 4, it is clearly seen that in general, no single method outperforms all other methods for all datasets. Furthermore, we discover that MDTW, compared to NN-DTW, can even achieve improved classification accuracy on some datasets, like Haptics. It may be because although DTW does achieve a global minimal score, the alignment process itself takes no local structural information into account, possibly resulting in an alignment with little semantic meaning [51], which may lead to misclassification. However, MDTW takes local structural information into account by using mean operation on subsequences. Therefore, the pathological nearest neighbor calculated by NN-DTW may be filtered out by MDTW in a coarse resolution. Consequently, a reasonable nearest neighbor can be found by MDTW, and then the accuracy is improved. We also do the Wilcoxon signed rank test between the MDTW and NN-DTW in terms of accuracy. The p-value is 0.7582 > 0.05, which demonstrates that the difference between MDTW and NN-DTW is not significant with the confidence of 95%.
The results in Table 4 show that the classification accuracy of PDTW is not good enough. Our method achieves better accuracy than PDTW on 12 datasets out of 18, and the p-value of Wilcoxon signed rank test between PDTW and MDTW in terms of accuracy is 0.0474 < 0.05. However, five strong competitors (i.e., CIDTW, ERP, MSM, WDTW and shapeDTW) outperform our method MDTW in most cases and the p-value >0.05. It is understandable because these methods can be considered as state-of-the-art methods for TSC and are hard to beat. We acknowledge this weakness. Nevertheless, it is worth noting that there is no significant difference between our algorithm and the state-of-the-art in average accuracy, with very small losses (<3%). In addition, we note that in some datasets such as Chlo.Concen and Two_Patterns, the MDTW can even perform better than state-of-the-art or achieve comparative performance (losses <1%).
The optimal classification results are not always required in many real-time applications in which the responsiveness is more critical than classification accuracy and sub-optimal results with quality guarantee are also acceptable. The experiment results show that our method can improve the classification efficiency significantly and achieve comparative performance with the state-of-the-art, with very small losses in accuracy. For example, MDTW can achieve 32 to 140 faster than MSM while having minor losses in average accuracy (2.7%). Thus, in the situations where the responsiveness is more important than the accuracy, e.g., when in real-time analytics, MDTW can be considered as a good solution.
In the previous subsection, we report the classification accuracy and the speedup rate under a fixed parameter setting. Nevertheless, the performance robustness under various parameter settings deserves our attention. Thus, in this part, we explore the effects of parameters on classification results and speedup rate. To see how them changes, we vary one parameter at a time and maintain other parameters fixed. We use the dataset wafer as the example here to evaluate the performance sensitivity of MDTW to each parameter.
In our previous experiments, for dataset wafer, we set K = (10, 20) and
Fig. 5 reports the classification accuracy and speedup rate under different input values of T1, T2, K1, K2. From Fig. 5(a)-(d), we find the accuracy nearly keeps stable, which suggests that our method is largely insensitive to the resolution vector K and the filter vector T. It is because even if the parameters are different, in most cases, after consequent filtering out dissimilar time series at each resolution level, the final candidateSet still contains the actually nearest neighbor time series. So in the refine-stage, the MDTW can obtain the same result. This is a beneficial characteristic because it means that we do not require any fine-tuning for a dataset. Besides, from Fig. 5(e)-(h) we find that T2 and K1 greatly affect the speedup rate while T1 and K2 have little effect on the speedup rate. Thus, in practice, a higher efficiency can be obtained by changing parameters T2 and K1. Note that although the speedup rate is affected by the T2 and K1, the classification accuracy is insensitive to the parameters.
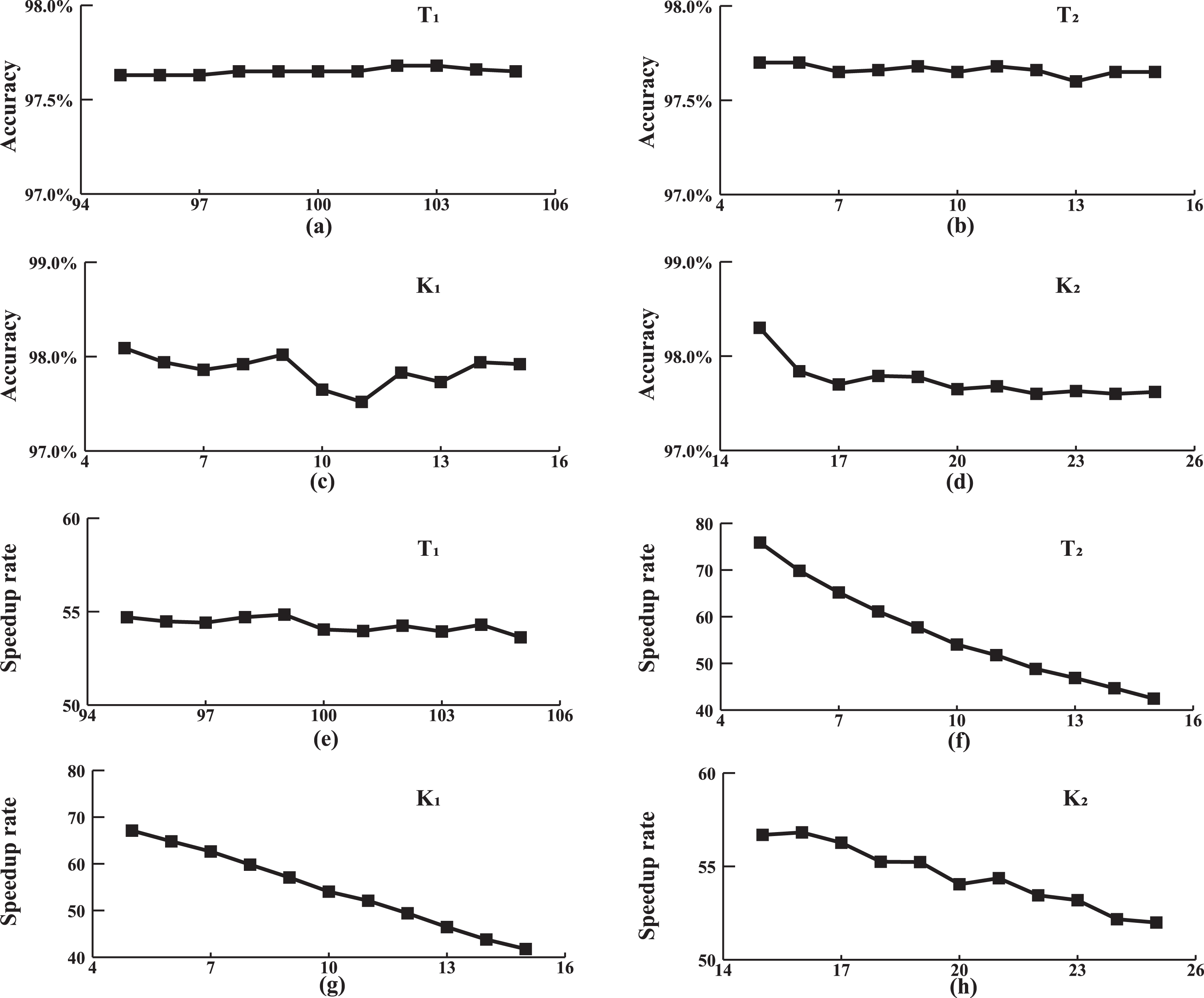
The classification accuracy and the speedup rate of MDTW under different input values of T1, T2, K1, K2. The results show that the classification accuracy is not sensitive to parameters T and K, and the speedup rate is approximately linear by T2 and K1.
In this paper, we propose a parameter-light method, called MDTW, for time series classification, and present its effectiveness and computational efficiency compared with existing methods. Experimental results show that MDTW achieves substantial speedups and comparative accuracy performance compared with state-of-the-art methods. Besides, we do the experiments to show that our approach is largely insensitive to parameters. We also provide a strategy to make MDTW even faster. Specifically, we embed the prunedDTW technique into the MDTW procedure. As shown in experimental results, MDTW+prunedDTW can speed up the MDTW from one to five times.
The discussion in this paper has focused on DTW distance. However, the idea behind MDTW can be applied to most time series similarity measures. In future research, we will implement the idea for various similarity measures. It will be interesting to know the trade-off between efficiency and accuracy. Another meaningful direction is testing the impacts of different local descriptors on the time series classification accuracy.