
Abstract
Linguistic intuitionistic fuzzy sets can qualitatively rather than quantitatively express data in the form of membership degree. But quantitative tools are required to handle qualitative information. Therefore, an improved linguistic scale function, which can more accurately manifest the subjective feelings of decision-makers, is employed to deal with linguistic intuitionistic information. Subsequently, due to some commonly used distance measures do not comprehensively evaluate the information of linguistic intuitionistic fuzzy sets, an improved distance measure of linguistic intuitionistic fuzzy sets is designed. It considers the cross-evaluation information to get more realistic reasoning results. In addition, a new similarity measure defined by nonlinear Gaussian diffusion model is proposed, which can provide different response scales for different information between various schemes. The properties of these measures are also studied in detail. On this basis, a method in linguistic intuitionistic fuzzy environment is developed to handle multi-attribute decision-making problems. Finally, an illustrative example is given to demonstrate the effectiveness of the proposed method and the influence of the parameters is analyzed.
Keywords
Introduction
Multi-attribute decision-making (MADM) is a branch of decision-making which is considered as a human activity based on cognition. Before choosing the best scheme, a set of alternatives is assessed against multiple influential attributes. The problems of MADM are studied in various fields, and many practical problems are solved by many useful methods, such as artificial intelligence [1], web data [2], granular computing [3] and so on [4–6].
Since the environment in reality is complicated, imprecise and vague, it is difficult for the decision-makers (DMs) to provide the correct decision in practical applications [7, 8]. Therefore, to handle the uncertainty in the data, Zadeh [9] proposed fuzzy sets (FSs), which is a powerful tool to address the vagueness [10]. After that, its extension has been studied, for example, intuitionistic fuzzy sets (IFSs) [11] has become more powerful tools to describe the MADM problems [12, 13]. Since then, the research on IFSs and its extension theory have been increased substantially. In 2018, various types of centroid transformations of intuitionistic fuzzy values are introduced and explored based on aggregation operators [14]. In 2019, a graphical ranking method of IFSs based on the uncertainty index and entropy is proposed [15]. In 2020, a new extension of the preference ranking organization method for enrichment evaluation is proposed by taking advantage of IFSs [16]. But the above fuzzy theory cannot handle qualitative information. Moreover, in practical problems, many qualitative attribute values cannot be numerically represented. For example, to measure one’s quality, DMs are prone to express it in terms of “excellent”, “good”, “bad”, etc. rather than in numerical terms [17]. Therefore, in the many complex and fuzzy decision-making problems, the expression of DMs’ opinions on decision objects is based on linguistic variables [18], which can enhance the flexibility and reliability of the classical decision-making model [19], and has been widely employed in various fields [20]. Based on some preliminary linguistic models, some extended linguistic concepts have been improved, such as hesitant fuzzy linguistic sets (HFLSs) [21], linguistic hesitant fuzzy sets (LHFSs) [22], etc. After that, combining linguistic models with IFS and considering linguistic membership and non-membership, the concept of linguistic intuitionistic fuzzy sets (LIFSs) is proposed [23]. The LIFSs can easily express the qualitative as well as the quantitative aspects.
When tackling decision-making problems with linguistic information, the DMs need to choose an effective calculation model to process linguistic information [24]. The 2-tuple linguistic computing model is one of the most commonly used computing models [25]. It not only improves the fuzzy linguistic method, but also increases the accuracy of linguistic computations [26]. Subsequently, a linguistic scale function (LSF) which can accurately manifest the DMs’ subjective feelings is proposed [27] based on the prospect theory and the numerical scale models of linguistic term sets (LTSs) [28, 29]. However, the loss-aversion attitude of DMs is not considered by the LSF in [27], which results in its inability to accurately reflect the DMs’ subjective feelings. To handle this problem, an improved LSF is proposed [30]. But the semantics corresponding to the linguistic terms in [30] cannot accurately reflect the DMs’ subjective cognition.
Distance measures and similarity measures are important tools for measuring the closeness of two patterns. They have influence on numerous research topics such as classification and decision-making. These measures could increase classification or recognition rate and refine the choice of appropriate solution for decision-making problems. In particular, when dealing with MADM problems, distance or similarity measures are usually used to compare all alternatives with positive and negative solutions to obtain the ranking of alternatives, such as the distance measures and similarity measures of IFSs in [31–34]. Some basic properties of distance measure of LIFSs are introduced in [17]. And some distance measures of LIFSs are proposed [17, 36] to tackle MADM problems. However, the distance measures of LIFSs as mentioned above have not thoroughly evaluated the linguistic intuitionistic fuzzy (LIF) information because the cross-evaluation between membership degrees and non-membership degrees are not considered. Hence, these measures are not really effective in the complex decision-making problems. For example, medical diagnosis depends not only on the current symptoms, but also on the medical history of a patient. In this case, if the distance measure uses the cross-evaluation, it is easy to evaluate the importance degrees between the membership and the non-membership degrees of a patient at present. It also can measure those degrees of a patient in the past time as well as the cross-time between the past and present. Therefore, in practical application, it will bring more information and accuracy of diagnosis for patients to evaluate LIF medical information fully through cross-evaluation. In addition, the most existing similarity measures are usually base on linear functions. That will bring difficulties to DMs. For example, in some practical problems, especially when the similarity degree of alternatives is high, the similarity measure based on linear function may not well distinguish these alternatives. So, it is necessary to construct a more flexible similarity measure.
To deal with the above drawbacks, in this paper, an improved LSF, which can more accurately express the DMs’ subjective feelings, is introduced based on the prospect theory. Then an improved distance measure of LIFSs is proposed, where the cross-evaluation is considered. Further, we study a similarity measure defined by nonlinear Gaussian diffusion model. It can provide different response scales for different information between various schemes. Finally, a method to address the decision-making problems in LIF environment is presented. The novelty of this paper in comparison with the relevant researches is highlighted as follows:
(1) To flexibly express semantics, an improved LSF which can more accurately reflect the DMs’ subjective feelings than [27, 30] is introduced based on the previous LSFs.
(2) By comparing with the common distance measures which have not thoroughly evaluated the information of LIFSs, a new distance measure of LIFSs which considers the cross-evaluation is designed to get more realistic reasoning results.
(3) Compared to the existing similarity measures based on linear functions [31, 32], a similarity measure of LIFSs which can more effectively reflect the response ability of different scales for the difference information between alternatives is proposed based on nonlinear Gaussian diffusion model [37].
(4) On these basis, a method for solving MADM problems is discussed, and the effectiveness of the method is illustrated by an example. Finally, the calculation results are compared with the existing methods to verify its effectiveness.
The rest of this paper is arranged as follows: Some basic concepts are reviewed in Section 2. In Section 3, a novel LSF is presented based on the prospect theory and LIFSs. After that, the improved distance measure and similarity measure of LIFSs is further defined in Section 4. Then, we give a method to cope with MADM problems under LIF environment in Section 5. For the sake of checking the validity of the proposed method, the comparative analysis and parameter analysis are carried out after a practical example in Section 6. Finally, the conclusion is given in Section 7.
Preliminaries
This section reviews and discusses some relevant concepts about IFSs, LTSs and LIFSs.
(1) The elements in S are ordered: s i > s j if and only if i > j;
(2) There exists a negation operator: neg (s i ) = s2t-i.
Then the discrete term set S is extended to a continuous LTS
For example, a manufacturing company desires to search the best global supplier for one of its most critical parts used in assembling process. Alternative A1 means the first supplier while attribute G1 means quality of the product. Suppose that attribute G1 of alternative A1 is evaluated as γ = (s u , s v ) = (s4, s2) according to the linguistic term set: S = {s0 = extremelypoor, s1 = verypoor, s2 = poor, s3 = fair, s4 = good, s5 = verygood, s6 = extremelygood}. The linguistic membership s4 indicates that the degree of alternative A1 satisfies attribute G1 is good, while linguistic non-membership s2 indicates that the degree of alternative A1 does not satisfy attribute G1 is poor.
Linguistic scale functions
The LSFs make the qualitative and quantitative linguistic evaluation information both available for the DMs to make decision, which can provide more definite decision results based on semantics [27].
It has been argued that using only the subscripts of LTSs to cope with decision-making problems may result in information distortion[40]. To overcome this problem, on the basis of Definition 4, three common LSFs are constructed [27].
First, the linguistic information evaluation scale, which is simple and universal, but lacks reasonable theoretical basis is given as following [41].
The following LSF inspired by prospect theory is defined, as well as the DMs’ different sensitivities with respect to the absolute deviation between adjacent linguistic subscripts:
To facilitate the calculation without losing of information, the above function is expanded as
In most practical decision process, people tend to make decision according to their risk preference attitudes as well as the way of thinking [30]. However, the LSFs listed above cannot accurately reflect the DMs’ subjective feelings, which include DMs’ risk preference attitude corresponding to the gains, losses and loss-aversion. To overcome this shortcoming, a LSF is proposed in [30].
Inspired by [30], a LSF which can more accurately reflect the DMs’ subjective feelings is proposed. This function can assign different linguistic preference values to the corresponding linguistic terms.
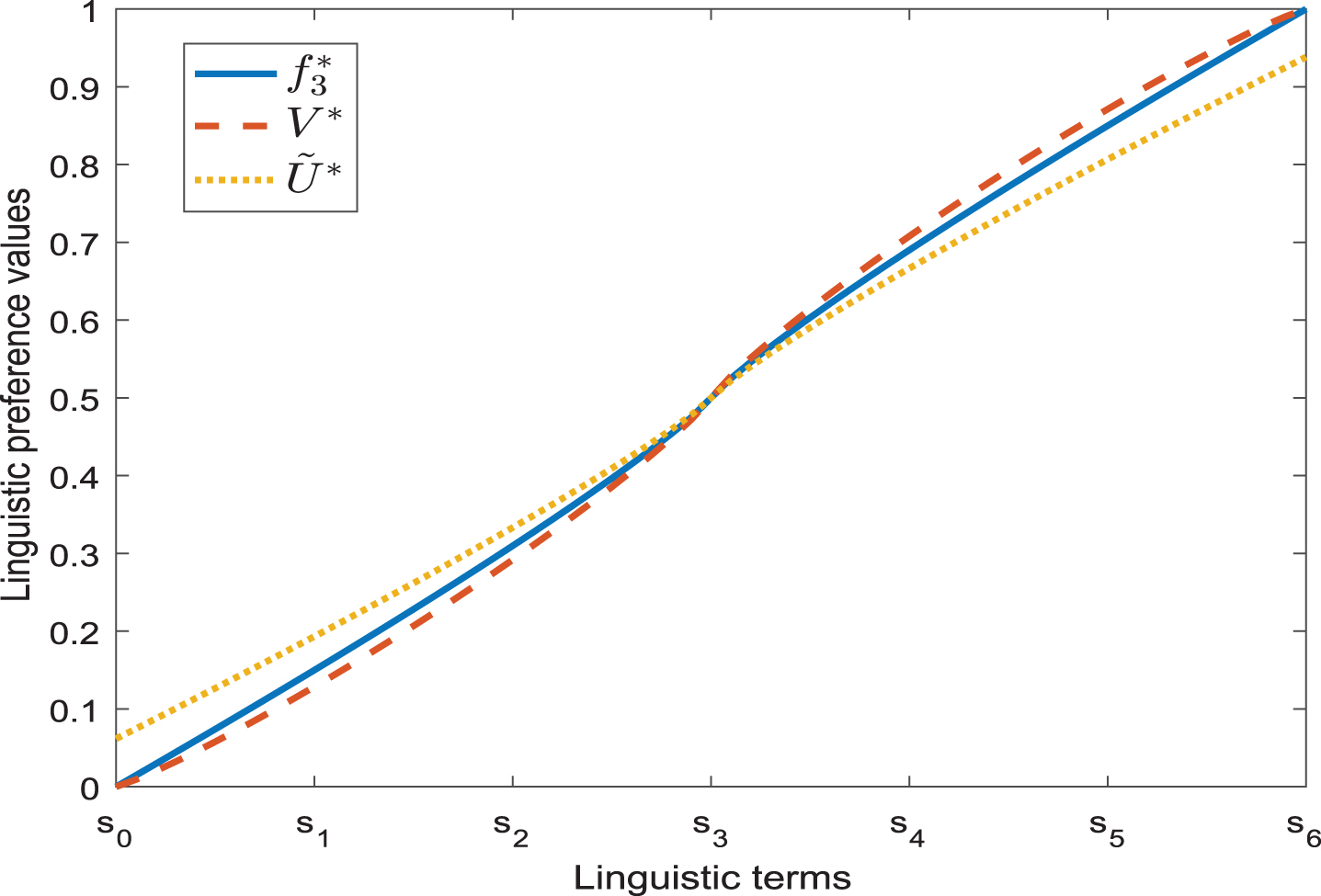
In addition, by Eq. (1), different values of risk preference parameters can be used to transform the semantics into their corresponding linguistic preference values and also can reflect different subjective feelings of DMs. For example, for a set of seven LTS S = {s0 = none, s1 = verylow, s2 = low, s3 = medium, s4 = high, s5 = veryhigh, s6 = perfect}, by Eq. (1), the obtained linguistic preference values are shown as Fig. 1.

A set of seven linguistic terms with their linguistic preference values.
From Fig. 1, it is noted that V is a strictly monotonically increasing and continuous function, where the absolute deviation of linguistic preference values between two adjacent subjective feelings gradually decreases. we can also see that the linguistic preference value
It is noted that
The curves of
From Fig. 2, we can see that for LSFs
In this section, a novel distance and similarity measures of LIFSs are constructed.
A novel distance measure of LIFSs
Inspired by [17, 33] and [34], some common distance measures between LIFSs can be listed as follows:
The Hamming distance measure between LIFSs A and B:
The Hausdorff distance measure between LIFSs A and B:
The values of distance measures d Ham , d Euc and d Hau
In view of the shortcoming of the above distance measures, a new distance measure between LIFSs is proposed.
After defining a distance measure d LIF , the corresponding similarity measure of LIFSs will be discussed.
Inspired by the distance measure d LIF , a similarity measure of LIFSs is proposed after we give the definition of similarity measure.
Based on Theorem 1 and 2, it is easy to find that the distance measure and similarity measure can be regarded as two opposites of a problem. The similarity measures are basically based on Hamming distance, Euclidean distance measures and some others improved forms [33, 34], which can be generally used s = 1 - d (d and s represent distance measure and similarity measure, respectively). Based on the relationship between d and s, a more general expression of similarity measure can be given as follows:
The existing similarity measures usually base on linear functions [31, 32]. It will bring difficulties to DMs, especially when the similarity degree of alternatives is high, the similarity measure based on linear function may not have a good ability to distinguish alternatives. In this case, if the similarity measure can provide different scales of response capabilities for the different information between different alternatives, the difficulties faced by DMs will be greatly reduced. For example, for two alternatives with large difference, the similarity measure can be more easily identified, for two alternatives with small difference information, the similarity measure can appropriately enlarge the difference information and provide more distinct results. So, it is necessary to construct a different and more flexible similarity measure.
Based on Gaussian function, the diffusion process of pollutants can be reduced very well. Gaussian diffusion model is the most widely used diffusion model of pollutants [37]. The diffusion principle of the model is that the closer to the diffusion source, the higher the pollutant concentration, the faster the pollutant diffusion speed; similarly, the farther away from the pollution source, the lower the pollutant concentration, the slower the pollutant diffusion speed. The form of Gaussian diffusion model is as follows:
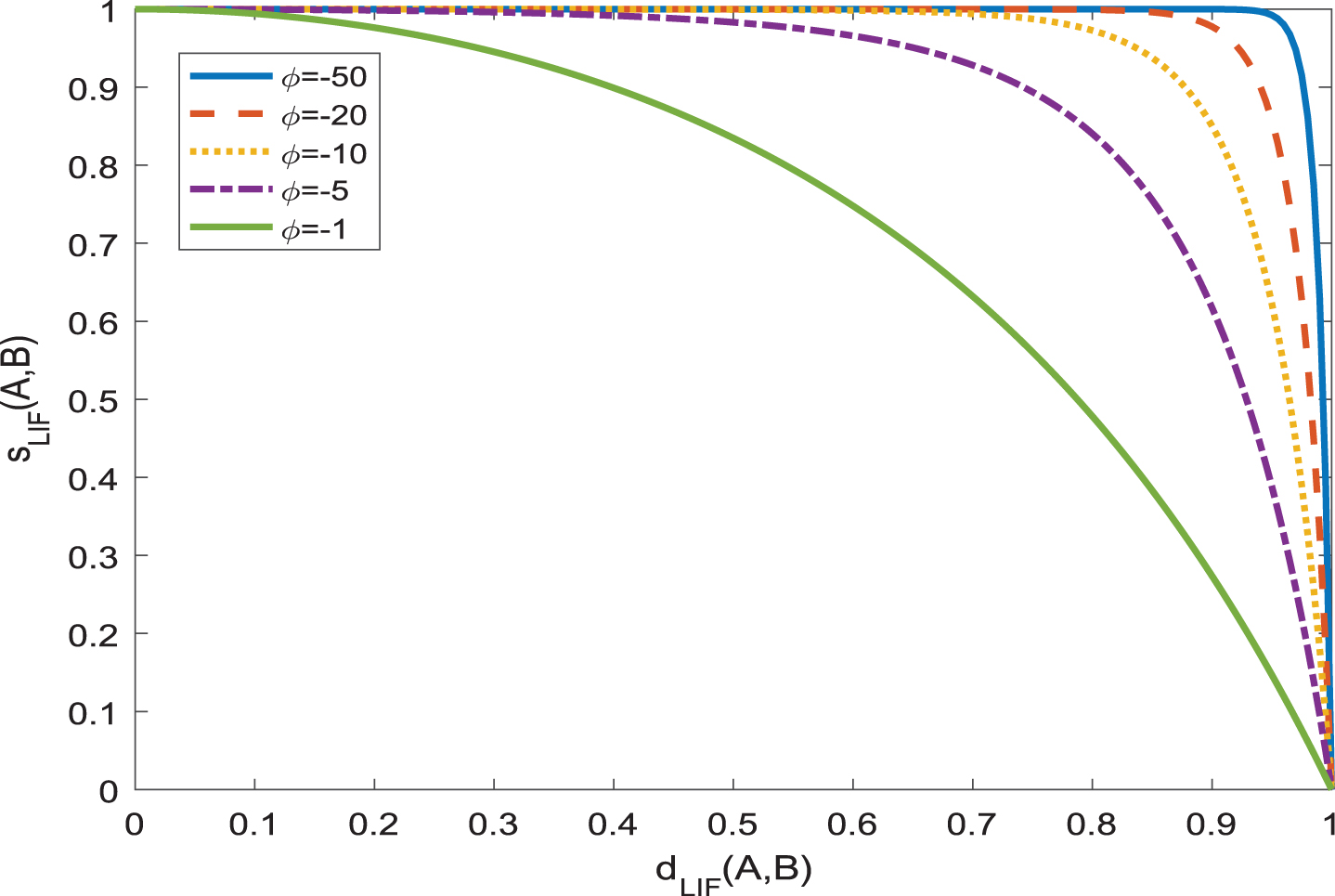
In order to observe the change characteristics of similarity measure s LIF (A, B) in Eq. (7) more intuitively, some similarity measure curves are drawn in Figs. 3-4, which are drawn with different values of parameter ϕ.

s LIF (A, B) changes with d LIF (A, B) when ϕ > 0.
s LIF (A, B) changes with d LIF (A, B) when ϕ < 0.
From Figs. 3-4, it can be seen that the similarity measure s LIF (A, B) can show the response ability of different scales by adjusting parameter ϕ according to different difference information between alternatives. For example, in Fig. 3, for two alternatives with small difference information, we can appropriately adjust parameter ϕ to a small value, so that the similarity measure s LIF (A, B) can appropriately enlarge the small difference information and get a more distinct result. The Fig. 4 shows that for two alternatives with large difference information, properly adjusting parameter ϕ to a large value can make the discrimination ability of the similarity measure s LIF (A, B) better.
For the sake of concrete explanation, it can display the response ability of different scales according to the difference information between alternatives. We give the following example:
The evaluation matrix M LIF
According to the evaluation matrix M LIF , by calculation, it is easy to get that d LIF (A1, A2) =0.0361, d LIF (A1, A3) =0.0722, d LIF (A1, A4) =0.1083. Then, we have d LIF (A1, A2) < d LIF (A1, A3) < d LIF (A1, A4). To demonstrate the characteristic of similarity measure s LIF , the values of similarity measure s LIF with different values of parameter ϕ and linear similarity measure s = 1 - d LIF are given in Table 3. From Table 3, we get s LIF (A1, A2) > s LIF (A1, A3) > s LIF (A1, A4). This means that A1 and A2 have the largest similarity, and A1 and A4 have the smallest similarity. According to the discussion of the difference for A i , it can find that the conclusions obtained by using the distance measure and similarity measure are the same.
The values of s LIF (A1, A i ) and s (A1, A i ) with different values of parameter ϕ
Note d LIF (A1, A3) - d LIF (A1, A2) = d LIF (A1, A4) - d LIF (A1, A3) =0.0361, which means the difference between d LIF (A1, A3) and d LIF (A1, A2) is equal to that between d LIF (A1, A4) and d LIF (A1, A3). We can get that s (A1, A2) =0.9631, s (A1, A3) =0.9278, s (A1, A4) =0.8917 are three numbers with little differences and close to 1, which makes it hard to distinguish them. In addition, the differences between distances are equal which leads to the differences of linear similarity measure s are equal. But we can see that s LIF (A1, A2) - s LIF (A1, A3) =0.1665 < d LIF (A1, A3) - d LIF (A1, A4) = 0.2144 when ϕ = 50; s LIF (A1, A2) - s LIF (A1, A3) =0.4181 > d LIF (A1, A3) - d LIF (A1, A4) =0.2567 when ϕ = 200. Comparing with the linear similarity measure s, the differences are quite large, and the difference between s LIF (A1, A3) and s LIF (A1, A2) is not equal to the difference between s LIF (A1, A4) and s LIF (A1, A3). Furthermore, the difference between s LIF (A1, A3) and s LIF (A1, A2) is smaller than that between s LIF (A1, A4) and s LIF (A1, A3) when ϕ = 50 while larger when ϕ = 200. The explanation to this phenomenon is that, when ϕ is a large number and d LIF is small (close to 0), the similarity measure s LIF is very sensitive to d LIF . From Table 3 and Fig. 3, we can see that s LIF is a very steep function when d LIF ∈ [0, 0.1], which makes it more easy to distinct. For the situation described in Fig. 4, we can make a similar analysis.
In most MADM methods based on distance measures, TOPSIS has been successfully applied [45, 46]. TOPSIS theorem uses the distance measure to calculate the closeness between each alternative and the positive or negative ideal alternatives, and then the optimal decision results are given [47]. Therefore, the accuracy and reliability of TOPSIS depend on the selection of positive and negative ideal alternatives and distance measures. The positive and negative ideal alternatives are defined in accordance with the best and worst alternatives of the given alternative set or obtained according to empirical knowledge. Therefore, the main factor determining the accuracy and reliability of TOPSIS is the distance measure. This section introduces a method based on distance measure d LIF to deal with MADM problem under LIF circumstance.
Suppose that there exists an alternative set A = {A1, A2, ⋯ , A
n
} which consists of n alternatives. DMs would like to choose the best alternative or rank the alternatives in preference order from the above set A according to the set of attributes G = {g1, g2, ⋯ , g
m
} and the LTS S = {s
i
|i = 0, 1, ⋯ , 2t} is established for evaluation. let M
LIF
= (γ
ij
) n×m be a LIF matrix, where γ
ij
= (s
u
ij
, s
v
ij
) is an evaluation value indicated by LIFN, and
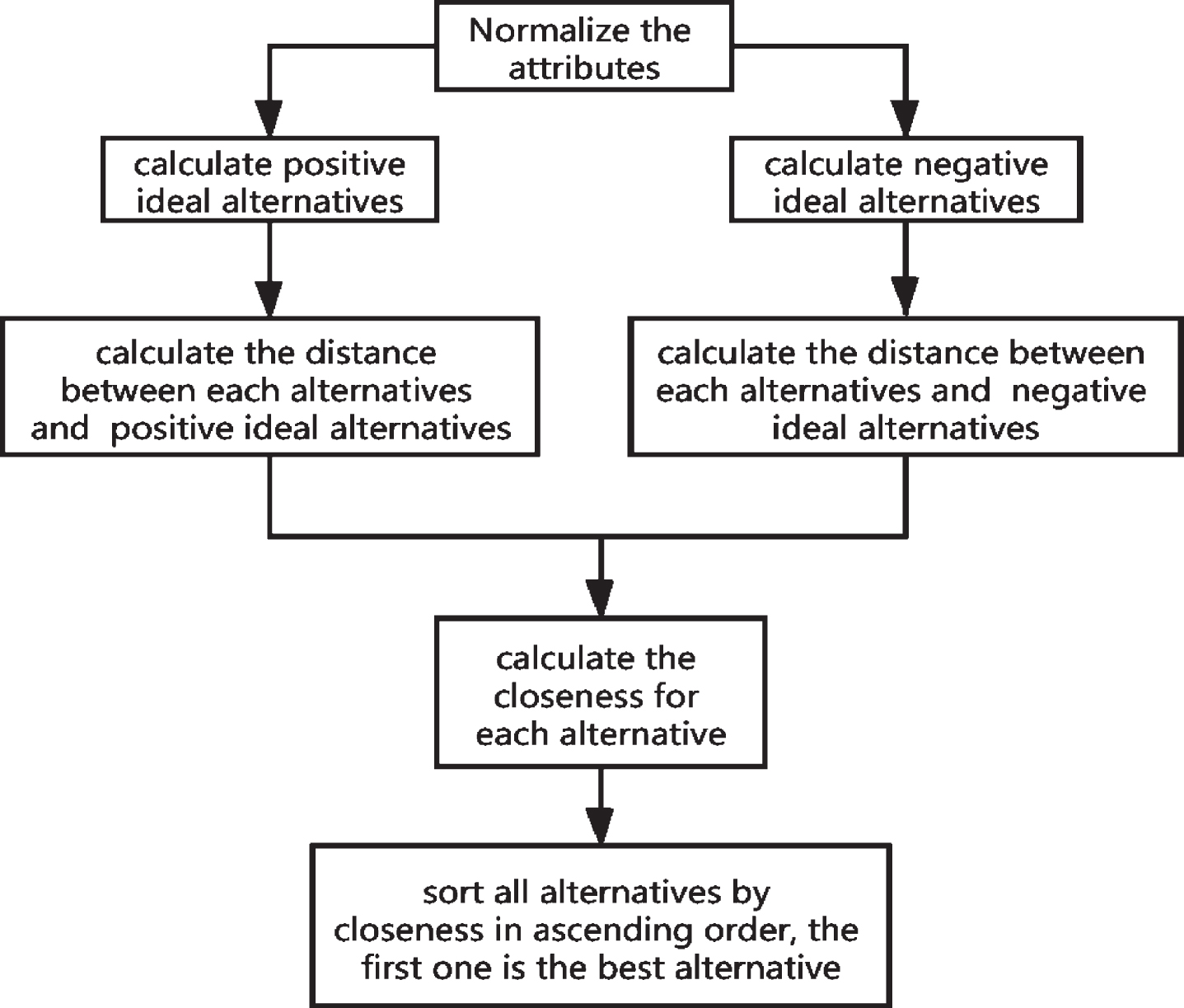
Flow diagram for the MADM method.
To eliminate the influence of different dimensions on the operation process, all evaluation values should be normalized to the same magnitude grade, which can be expressed as follows [48]:
Next, to better illustrate the given method in Section 5, we apply it to a coal mine safety evaluation problem [17] as an example.
The evaluation matrix
The evaluation matrix
The values of d LIF (A i , Γ+) and d LIF (A i , Γ-) (i = 1, ⋯ , 5)
Comparative analysis: In order to verify the effectiveness of the proposed method, we apply other existing methods to Example 3 and make a comparative analysis.
From Table 6, it can be seen that A1 is always the best alternative among the different existing methods mentioned above. Table 6 also illustrates that the ranking result given by the first method in [51] is the same with that given by the proposed method, the ranking result given by [49] is the same with the method in [50], the second method in [51] and the second method in [23]. On the basis of the above simulation results, there are some possible reasons for this difference in rankings.
(1) First, the present methods are defined by simply dealing with the subscript of the linguistic term [23] and the loss-aversion attitude of DMs is not considered [17], which makes it cannot accurately reflect the DMs’ subjective cognition. So, these strategies have some non-negligible shortcomings and leads to the loss and distortion of the original information. However, the proposed method in this paper is constructed based on an improved LSF and distance measure, which can accurately represent the semantics of linguistic terms and obtain the decision results that are consistent with the DMs’ cognition and can effectively negate the drawbacks in the existing methods.
(2) Second, the existing methods and the proposed method have different methods to determine the final ranking for alternatives. The linguistic score function and linguistic accuracy function are used to compare comprehensive evaluation values [23], and the possibility degree and complementary matrix are utilized to obtain final rankings in [49–51]. In contrast, the proposed method depend on the improved distance measure of LIFSs to compare the comprehensive evaluation values for each alternative, and then the final ranking is determined.
The ranking results using different existing methods
The ranking result in Table 6 is obtained by the proposed method under the parameters (a, b, λ) = (0.88, 0.88, 2.25) [44]. When the values of parameters a, b and λ in the proposed LSF are different, it is necessary to discuss whether and how the ranking results change. Three sets of parameter values which can well reflect the DMs’ subjective feelings are (a, b, λ) = (0.88, 0.88, 2.25), (a, b, λ) = (0.88, 0.88, 1.25) and (a, b, λ) = (1.68, 0.88, 2.25) [44, 52]. Based on the above discussion, more ranking results are gave with different parameter values in Table 7.
The ranking results using different values of parameters a, b and λ
The ranking results using different values of parameters a, b and λ
According to Table 7, it is noted that the ranking results change when the values of parameters a, b and λ change. First, we discuss the influence of λ by variable control. Table 7 shows that the rankings do not change with λ when a = 0.88, b = 0.88 or a = 1.68, b = 0.88 or a = 1.68, b = 1.68, while the ranking change with λ when a = 0.88, b = 1.68. This indicates that the ranking result is sensitive to λ. Second, how the ranking changes with parameter a is also analyzed. Table 7 shows that the rankings do not change with a when b = 0.88, λ = 1.25 or b = 0.88, λ = 2.25 or b = 1.68, λ = 1.25, while the ranking change with a when b = 1.68, λ = 2.25. This indicates the ranking result is sensitive to a. Third, we discuss how the ranking change with the value of parameter b. Table 7 shows that the rankings change with b except when a = 0.88, λ = 2.25. This indicates the ranking result is more sensitive to b than parameters a and λ in this coal mine safety evaluation problem.
In addition, whatever the value of the parameter, the best choice is always A1. The consistency of the results fully prove the reliability and accuracy of the proposed method. The preceding discussion demonstrates that the values of parameters a, b and λ can influence the ranking results. Parameters a and b represent risk preference attitude coefficients of DMs towards gains and losses, respectively. The bigger the value of a or b is, the more strong DMs’ risk preference attitude toward gains or losses is. Parameter λ represents DMs’ attitudes toward loss-aversion. The bigger the value of λ, the more the DMs tend to avoid losses, vice versa.
Therefore, the method proposed in this paper has certain flexibility for coal mine safety evaluation. And DMs can choose appropriate values of parameters a, b and λ based on their subjective feelings to obtain desirable result.
In this paper, a novel LSF is proposed to convert the linguistic terms into the linguistic preference values. Considering the cross-evaluation, a new distance measure of LIFSs is proposed. Additionally, based on the principle of nonlinear Gaussian diffusion model, a similarity measure of LIFSs is further defined, which can provide different response capabilities according to the difference information between alternatives. On this basis, a method is developed to handle MADM problems, and the effectiveness of the method is illustrated by an example. Finally, the calculation results are compared with the existing methods to verify its effectiveness.
For future research, we can continue to improve LSFs to handle the information under the subscript-symmetric LTSs. Moreover, the method proposed in this paper can also be used to deal with MADM problems in supply chain management, medical diagnosis and other fields.
Footnotes
Acknowledgments
This research was supported by the National Natural Science Foundation of China (Grant Nos. 11671001 and 61876201), the Science and Technology Project of Chongqing Municipal Education Committee (Grants no. KJQN201800624) of China and the Project of Humanities and Social Sciences planning fund of Ministry of Education (18YJA630022) of China.