
Abstract
Traffic congestion on a road results in a ripple effect to other neighbouring roads. Previous research revealed existence of spatial correlation on neighbouring roads. Similar traffic patterns with regards to day and time can be seen amongst roads in a neighbouring area. Presently, nonlinear models of neural network are applied on historical data to predict traffic congestion. Even though neural network has successfully modelled complex relationships, more time is needed to train the network. A non-parametric approach, the k-nearest neighbour (K-NN) is another method for forecasting traffic condition which can capture the nonlinear characteristics of traffic flow. An earlier study has been done to predict traffic flow using K-NN based on connected roads (both downstream and upstream). However, impact of road congestion is not only to connected roads, but also to roads surrounding it. Surrounding roads that are impacted by road congestion are those having ‘high relationship’ with neighbouring roads. Thus, this study aims to predict traffic state using K-NN by determining high relationship roads within neighbouring roads. We determine the highest relationship neighbouring roads by clustering the surrounding roads by combining grey level co-occurrence matrix (GLCM) with k-means. Our experiments showed that prediction of traffic state using K-NN based on high relationship roads using both GLCM and k-means produced better accuracy than using k-means only.
Keywords
Introduction
Growing population as well as surge in the number of vehicles in urban areas have led to worsening of traffic congestion, causing stress [1] and economic losses, as well as increase in pollution that hampers the environment [2]. Thus, if drivers are provided with traffic information, it would help them with their driving plans, including changing their driving habits as well as choosing driving paths [3]. Furthermore, if traffic information is available, it could result in a chain of movement in traffic state both in downstream and upstream of road segments in the same area.
Traffic jam or congestion is regarded as a situation in which the number of road users surpasses the capacity of the road. Some inherent characteristics of road congestion include long queue, long travelling time, and slow speed of vehicles on the road. Thus, it is important to develop effective algorithm or models to identify congested roads, to analyse congestion distribution in the network and to determine relationship between increasing traffic flow and occurrence of congestion. Some of the research works have employed neural network to predict traffic flow, by considering all day’s data of traffic flow of neighbouring road [4] as well as predicting the traffic flow on road intersections using data on all day’s data [5].
Other studies have shown that adjacent roads demonstrated a similar traffic pattern on the same time interval and day [6, 7]. Studying traffic patterns in adjacent roads can lead to discovery of relationships amongst roads in a neighbouring area. This information is important in studies of traffic state as the results can be used to assist drivers in avoiding congested roads and nearby roads which are affected by the congestion. Moreover, identifying relationships amongst roads in a neighbouring area can produce higher accuracy of traffic state prediction. Based on Fig. 1, we can expect that traffic flow on road I, will also impact the traffic flow on surrounding roads like road II, road III and road IV. In other words, traffic flow on road III would be impacted by traffic flows of neighbouring roads.

Illustrations for high relationship roads impacting traffic flow.
There exists correlation between connected road segments in either downstream, upstream or both [4, 8]. Other research studies also determined the existence of congestion correlation for two road segments [9], between two road segments I and II at a given distance d. This means that if there is congestion in road I at time t and at time t + T, then it results in congestion even in road II. In a different research study, data extracted from sensors was used to determine the relationships amongst road segments using correlation method [10, 11].
Traffic condition is regarded to be nonlinear, uncertain and complex. Thus, it becomes difficult to accurately predict the traffic condition by making use of prediction methods based on regular mathematics models [12]. Previously, the neural network was used by considering the historical data to develop complex relationship models pertaining to traffic flow. However, training the network takes a long time [13]. Thus, the K-nearest neighbour (K-NN), a non-parametric method is a better approach to forecast short-term traffic condition. Various studies have used K-NN to predict short-term traffic flow [13, 14], using three-layer K-NN [15], using with or without weight [12] and using similar data [16].
The research using K-NN to predict traffic state that is closest with our work is [8, 17]. They used connected roads both upstream and downstream [8] and surrounding roads as spatial relationship [17]. However, impact of road congestion is not only to connected and surrounding roads. Road congestion is also impacted by roads having ‘relationship’ with the congested road. Other research that related with our study is [18]. They reduce spatial temporal feature using tensor algebra. Another study by [19, 20] use k-means cluster of similarity traffic in neighbouring roads.
In this study, we proposed spatio-temporal K-NN model to predict traffic state. The acquired spatial information is based on the similarity of traffic flow features among roads. The features of traffic flow are extracted using grey level co-occurrence matrix (GLCM). The extracted features are then clustered using k-means to obtain roads that are related to each other, or in other words having ‘relationship’. Roads with high relationship are then used as spatial relationship for prediction using K-NN. Our study shows that combining GLCM with k-means clustering produced better prediction of traffic state in comparison with prediction based on k-means without GLCM.
The rest of the paper is structured as follows. Section II introduces our method to construct a nonparametric k-nearest model. Section III discusses results of our experiment. Lastly, we present our conclusion of our work.
Congestion index and congestion determination
In order to determine the level of road congestion, various definitions and variables of traffic congestion were formed. Traffic congestion rank was defined by Rothenberg [21] as the condition in which the number of vehicles on the road surpasses the carrying capacity of the standard road service level. Another study used congestion index by considering the saturation degree, travelling speed and a combination of both [22]. A different study accounted for the speed performance index by segmenting congestion level as four, three or two as needed [23]. In this study, the congestion index for a given time interval was determined to calculate similarity between roads to obtain the congestion level.
Congestion index was calculated based on the travelling speed [22], with some adjustments. Instead of hourly calculation, congestion index was calculated at every 20 minutes using the formula given in (1). For example, for road 158324, congestion index was calculated at every 20 minutes from 05:00 to 09:20 AM as presented in Table 1. For neighbouring roads, congestion index was calculated every day from February 2014 until September 2014.
Details of data from sensor 173011
NDT: normal driving time in kilometre per hour or speed limit, as shown in Table 1.
Vavginterval time: average speed in interval hours
Vmininterval time: minimum speed in interval hours
Volumeinterval time: number of vehicles in interval hours
Volumeday: number of vehicles in a day
As observed in Fig. 2, the road congestion occurred between 06:10 AM until 08:10 AM. From Table 2 show that, the congestion index was found between three (3.03) to five (5.41). In Denmark, the average speed of normal traffic in town is 50km/hour [24]. Based on this information, we defined traffic congestion as the situation when average speed is below 50km/h. As we can observed from Table 2, when the average speed is 50km/hour, the congestion index value is around 3. Thus, for this study, we consider that a road is congested when the congestion index is above or equals 3.
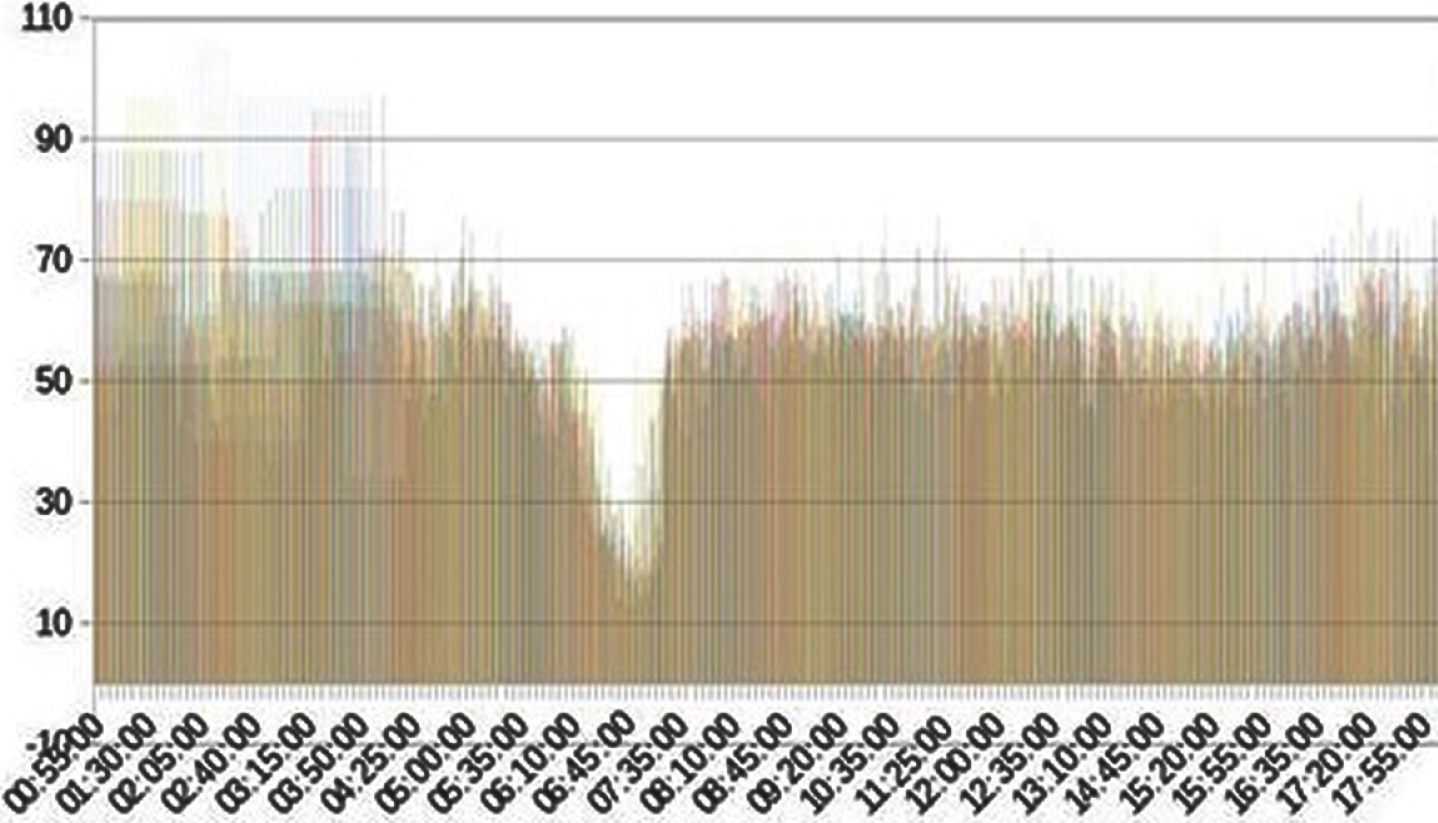
The average speed on road 158324 every five minutes.
Congestion on Road 158324 from 06.00-08.20 AM
In this study, we use grey level co-occurrence matrix (GLCM) fusion with k-means to find the relationship between roads. GLCM refers to a method for describing texture by studying the spatial correlation characteristics of grayscale. Since traffic flow pattern is formed by the repeated occurrence of the congestion distribution in the spatial position, there will be a certain traffic state relationship between two matrix values at a certain distance in the traffic state space. This is the spatial correlation characteristics of traffic state. Traffic congestion has same pattern in interval time and interval day as shown in Table 3. Based on this pattern, we set our GLCM matrix with a horizontal offset of 2 to the right and vertical offset of 2 downwards. By referring to Fig. 2, 0 indicates clear state and 1 indicates congestion state.
Traffic congestion pattern in time and day on road 158324, road 158386, and road 158536
Traffic congestion pattern in time and day on road 158324, road 158386, and road 158536

Contrast is a measure of intensity between a matrix value and its neighbour over the whole matrix [25–27]. Contrast is calculated using equation (2) and correlation of a matrix value to its neighbour is given by the equation (3). Homogeneity is a value that measures the closeness of the distribution of elements in the GLCM to the GLCM diagonal. It is given by equation (5). Energy is the sum of squared elements in normalized GLCM. It is given by equation (4).
K-means is a data grouping algorithm that will divide data into several k groups. It is a very famous algorithm because of its simplicity [28]. This algorithm tries to divide the data into k groups. Where data from a group will have the same character between each of its members. On the other hand, the data in a group will have different character from other group members. This algorithm tries to find variations that are very minimal between the same groups and will look for variations that are maximum with other groups [29]. The algorithm used is as follows: Specify k=six (6). This value is obtained by observing the elbow curves in Fig. 3. From Fig. 3, it can be seen that all roads have similar pattern. The elbow points are around 6. Randomly select k distinct data points as initial cluster means. Then, compute the Euclidean distance between each mean cluster and all other points. Assign each point to the cluster having the closest mean. Move the centroid. Recalculate the cluster centroid (means) for each of the k clusters by computing the new mean value of all the data points in the cluster. Do steps 3 to 5 repeatedly, until the centroids stop moving. or they reach the maximum number of repetitions.
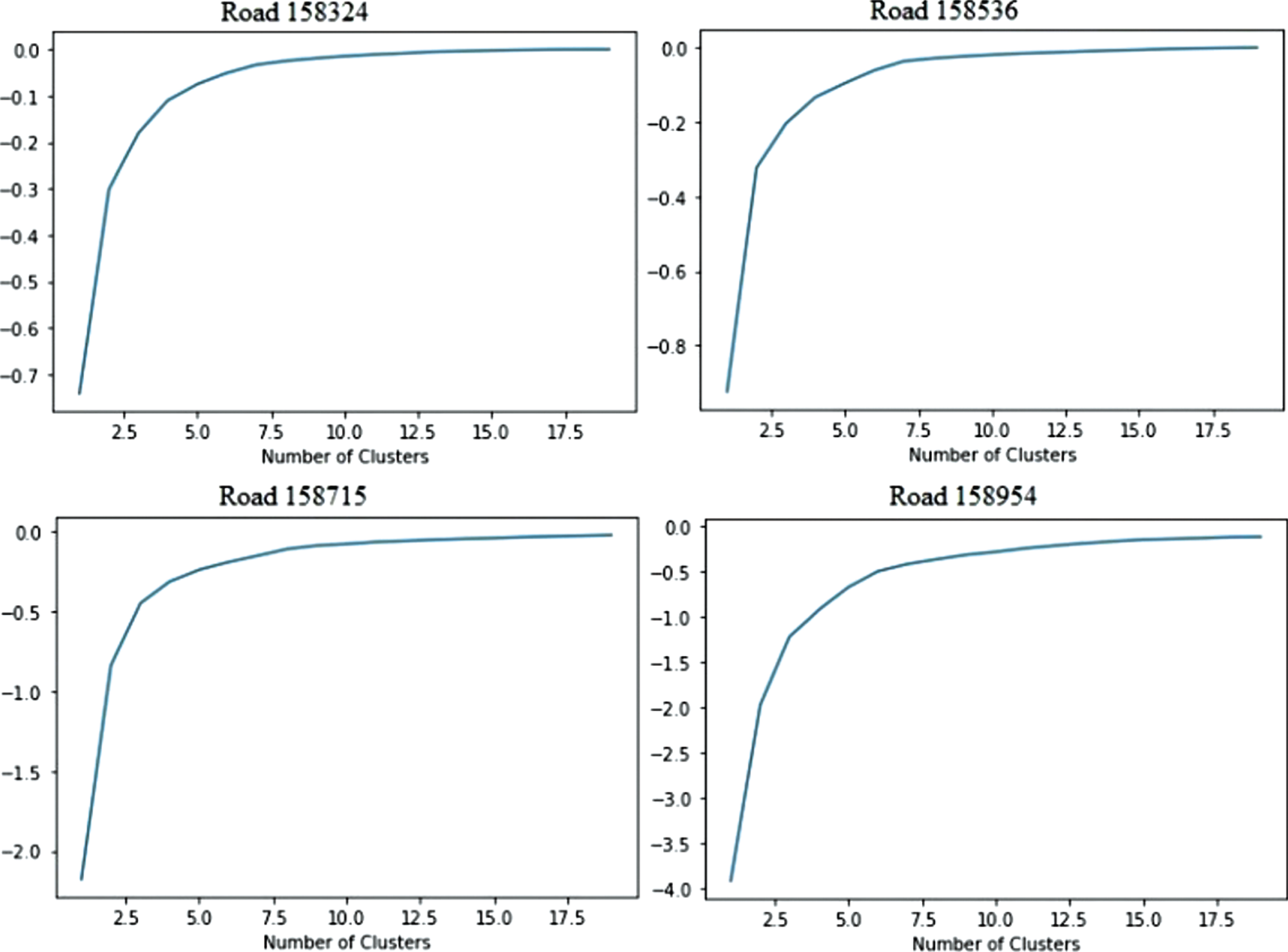
Elbow curves for road 158536, road 178600, road 210173 and road 195817.
The total within the sum of squares or the total within-cluster variation is defined as:
Where:
x i is data point member of the cluster C k
μ k is the mean value of the points defined to the cluster C k .
The k-Nearest Neighbour (K-NN) is a straightforward machine-learning non-parametric technique, that is, without model and without any parameter. The primary principle of this technique is that if k number of most similar samples in the feature space are of one group in the dataset, then the sample belongs to that group. The concept of K-NN is given in Fig. 4. Assume that the elements in the data set are represented by triangles and squares as shown in the figure. Supposedly, we need to find out the category to which the brown circle belongs to. It depends on the value of k. If k=3, then the 3 nearest neighbours to the brown circle are 2 squares and one triangle. Then, this brown circle is regarded as belonging to the square category on the basis of the statistics. If k=6, then the six nearest neighbours to the brown circle are 4 triangles and 2 squares. Thus, this brown circle is regarded as belonging to the triangle category as can be seen from the statistics.
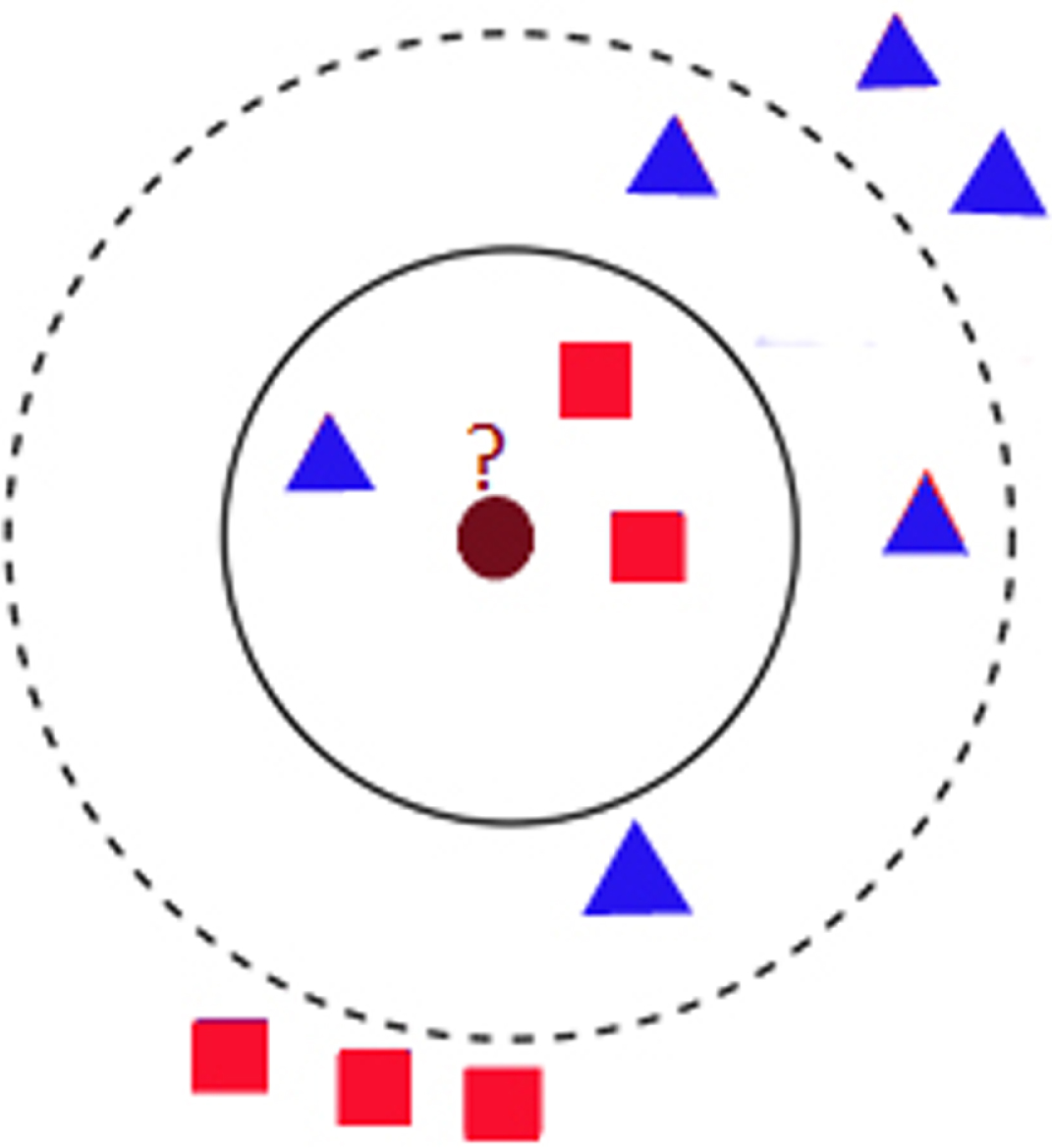
Example of k-NN concept.
In this study, the K-NN technique is applied to estimate short-term traffic condition. The technique searches for the nearest matching neighbours between previous data according to similarity of time and data value based on distance between historical data and current data. There is no need to specify in advance the mathematical model or the parameters. Detailed explanation for the K-NN technique is explained in [8, 12]. Distance, state vector, number of nearest neighbours and prediction algorithm are included in the K-NN technique. The distance and prediction algorithms are explained in more depth as follow:
The distance is required for comparing the value among the test data and sample data. Data having the nearest distance between historical data and sample data are then chosen to be used in the K-NN model. This data is then used in the prediction algorithm. We consider Euclidean distance as distance in this study. See Equation (7).
Traffic congestion index on a road changes according to day of the week and duration of time. So different days and different time intervals affect the future of traffic conditions. For the same time (time and day) in both historical and forecast data, distance between time in forecasting and state vector should be as small as possible.
where
d i =distance of group i between forecast data and historical data;
Vj=congestion index value of vector j in forecast data;
v ji =congestion index value of state vector j in historical data i.
Typically the K Number chosen is the square root of the N training data [30]. In this study, the neighbouring results are obtained from clustering (GLCM with k-means). The K-NN estimations are based on a voting process, statistically.
For our study, we proposed the spatio-temporal K-NN algorithm, as shown in Fig. 5. For state vector, we consider historical data (t) of the traffic congestion index on the destination road and neighbouring roads of the same cluster (GLCM with KNN). K-NN model is then used to predict traffic condition on destination road (t+1).
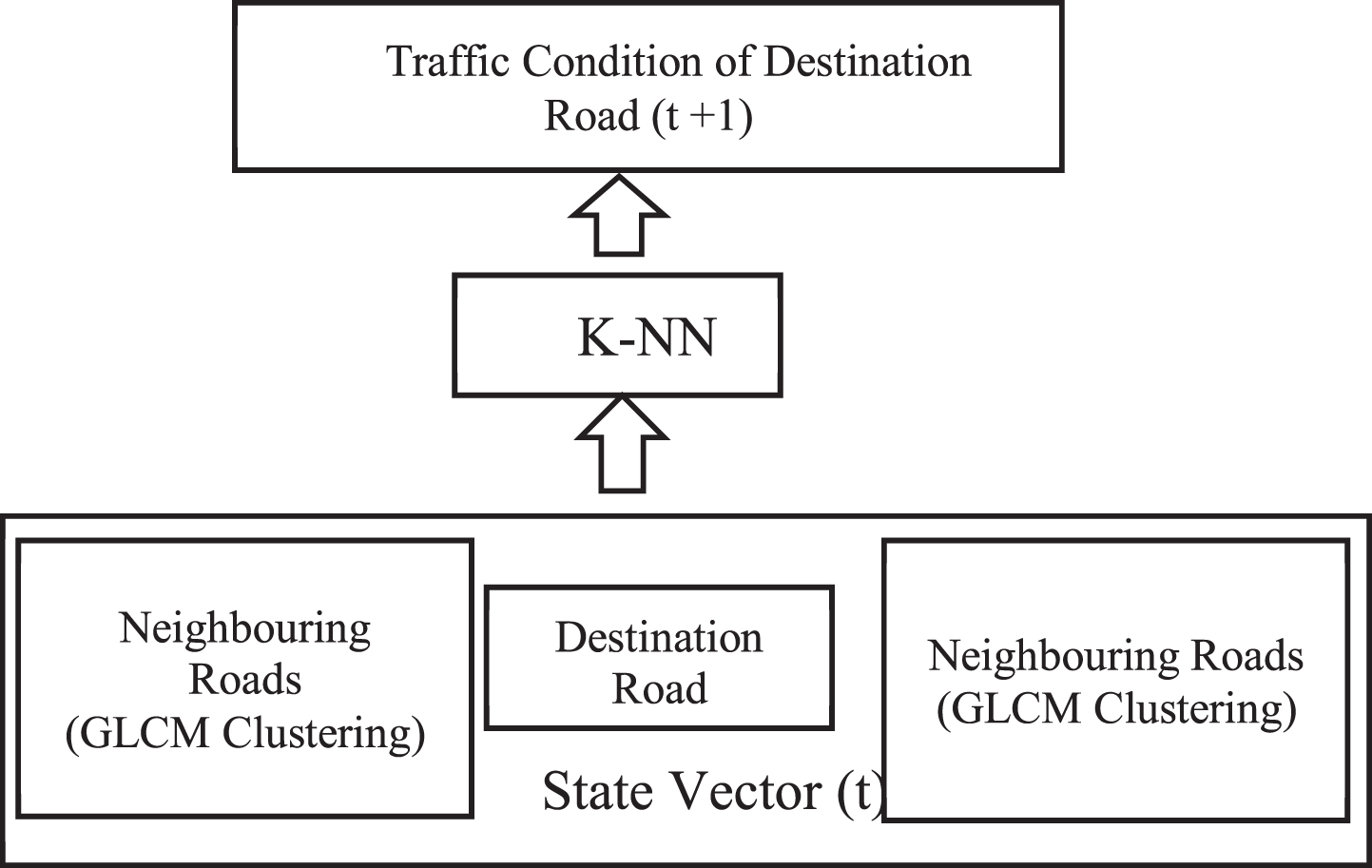
Spatio temporal K-NN model for predicting traffic state.
Some studies discovered that there is a difference in traffic flow pattern on weekends and on weekdays [6, 31]. We considered the road 158324 for studying traffic flow pattern and found that there exists a similar pattern of the traffic flow on weekdays. The weekdays’ data is traffic data from Monday to Thursday while the weekends data is traffic data from Friday to Sunday as seen in Fig. 6.

Traffic pattern on road 158324, (a) pattern on weekdays, (b) pattern on weekends.
Dataset
In this study, we used the dataset obtained from the IoT traffic sensors located in Aarhus, Denmark [32–34]. The approximate number of sensors at this place is 449 as displayed in Fig. 7.
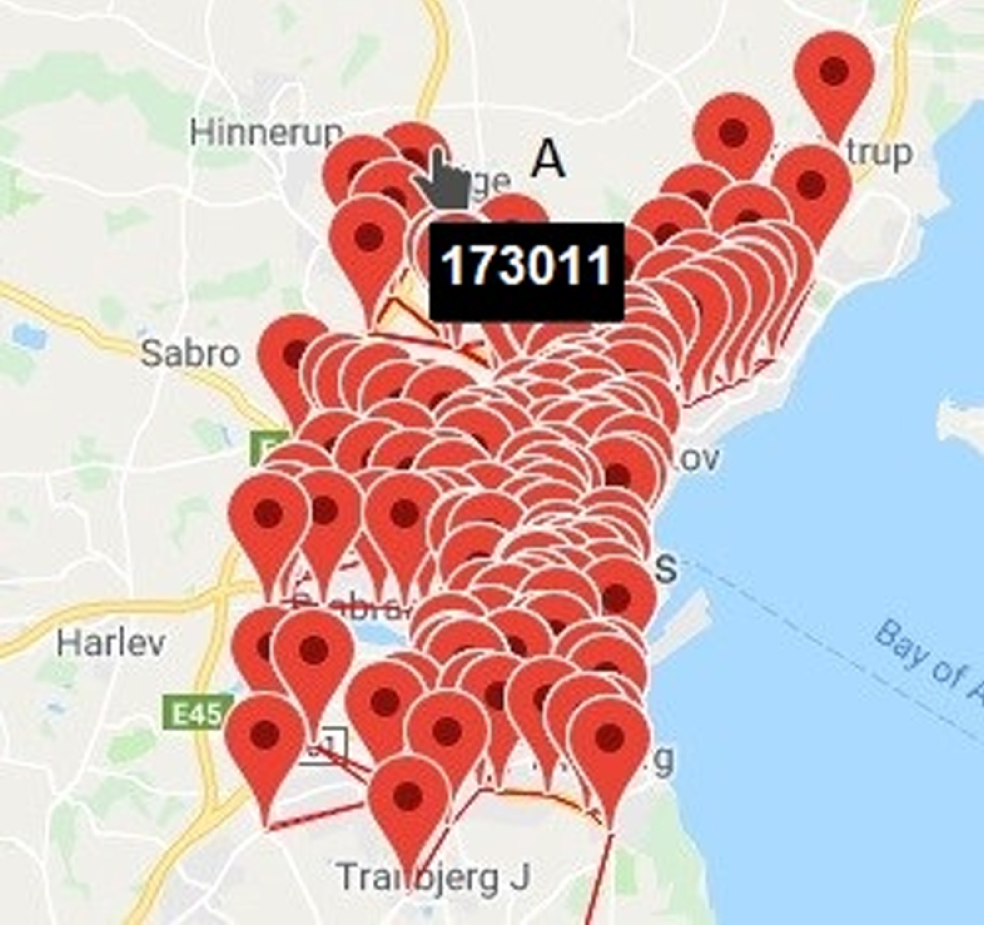
Map of location of 449 IoT traffic sensors in the city of Aarhus, Denmark.
For instance, the sensor at location A is identified by 173011. This sensor is placed at Søftenvej Street, Aarhus city and at rhusvej Street, Hinnerup city, Denmark. The distance between both the sensors is 2061 metres. We conducted the experiment using vehicle count, average speed and time to calculate the congestion index. Example of data taken from sensor 173011 are presented in Table 4.
Example of traffic data taken from sensor 173011
In this paper, we present results of traffic flow prediction at 10 different neighbouring areas which cover the road 158536, road 178600, road 210173, road 195817, road 185131, road 178767, road 195286, road 188225, road 201855, and road 206316 as seen in Fig. 8. We define neighbouring roads as roads within the radius of four (4) kilometres or less from a target location.
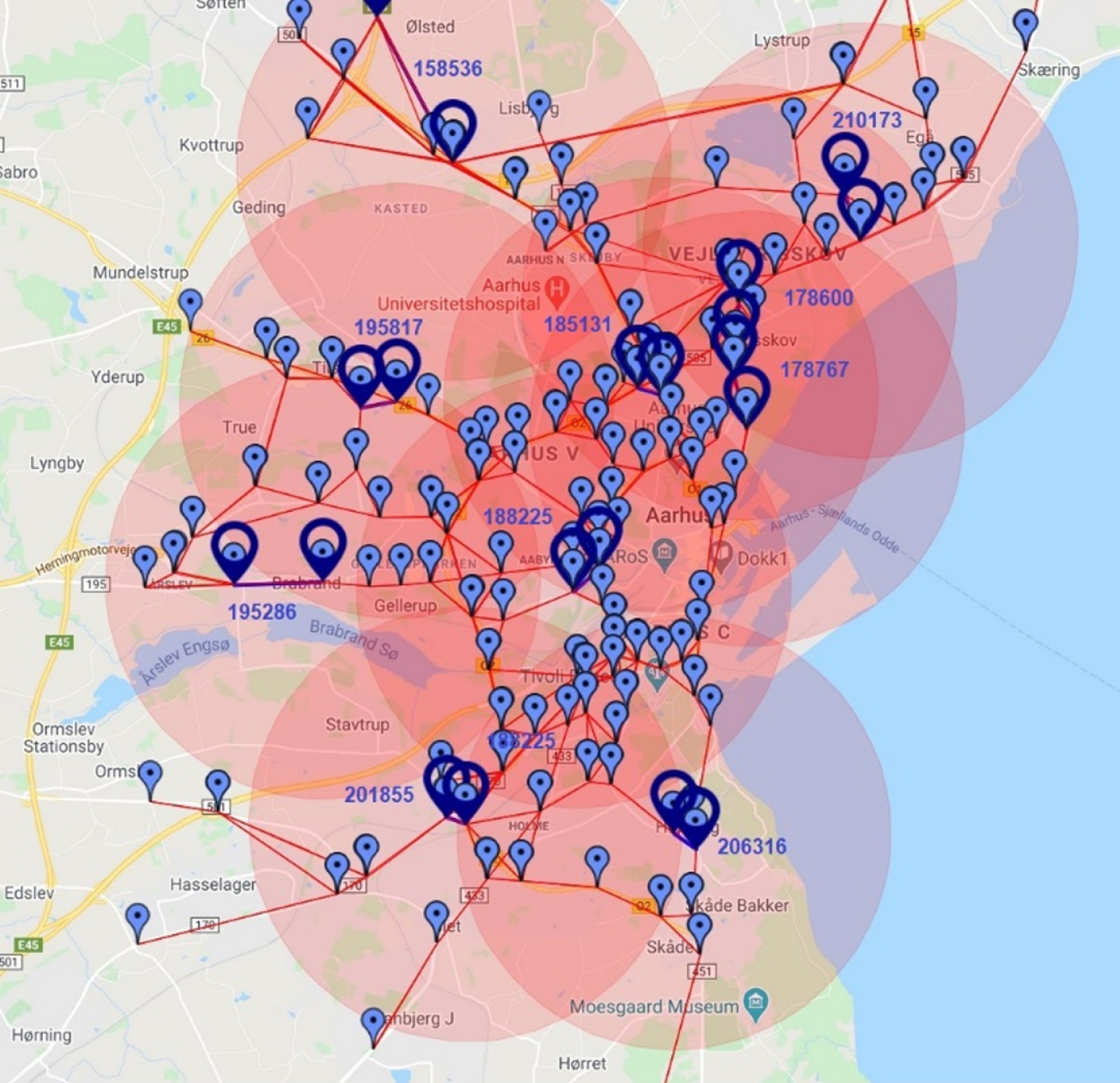
Map of 10 neighbouring areas in the city of Aarhus, Denmark considered in experiment.
We compare K-NN results obtained from k-means clustering against K-NN result obtained from GLCM-k-means clustering method. Since we are interested to predict traffic flow for the weekdays, we compute the similarity of the congestion index on weekdays starting from 15 Feb 2014 to 31 May 2014. Detailed explanations are provided in section 2.1. We split 20 percent of our dataset for testing the proposed K-NN model.
We observed that clustering using k-means obtained higher number of roads if compared with clustering using GLCM and kmeans. The combination of GLCM with kmeans filtered more roads which have relationship with target road. We also compared our results with roads obtained by Pearson correlation. Using this method, we filter only roads that have correlation value above 0.5. Therefore, we only visualized location of the three roads with correlation value above 0.5 namely road 158536, road 195286 and road 201855.
The results of clustering on location 158536 are shown in Fig. 9. The combination of GLCM with k-means filtered more roads that have relationship with road 158536. When using Pearson correlation, we obtained 18 roads which is three roads more than using k-means method.
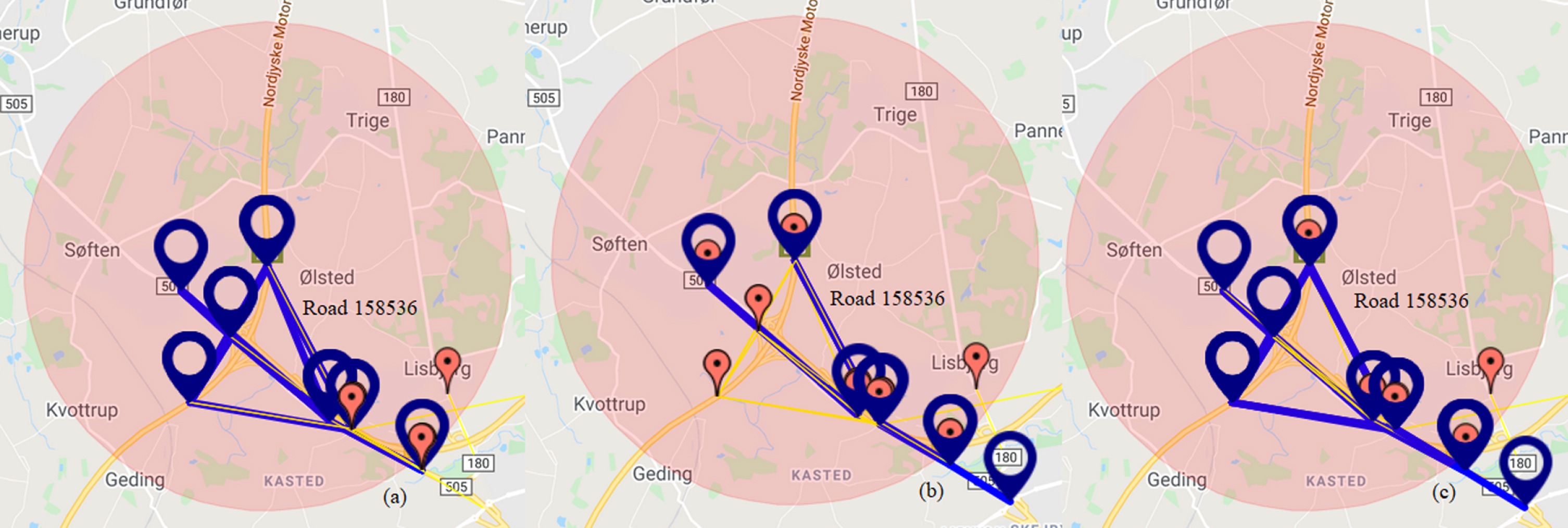
Traffic pattern on road 158536, (a) clustering with k-means, (b) clustering with GLCM and k-means, (c) high Pearson correlation value.
Figure 10 shows the results of clustering for location 195286. It can be seen from Fig. 10 that when using k-means we obtained more roads than when using GLCM. Clustering using combination of GLCM and k-means filtered more roads that have relationship with road 195286. When using Pearson correlation, we obtained three roads that have correlation value above 0.5 with road 195286. However, all methods obtained roads with distance outside 3.5km from road 195286.
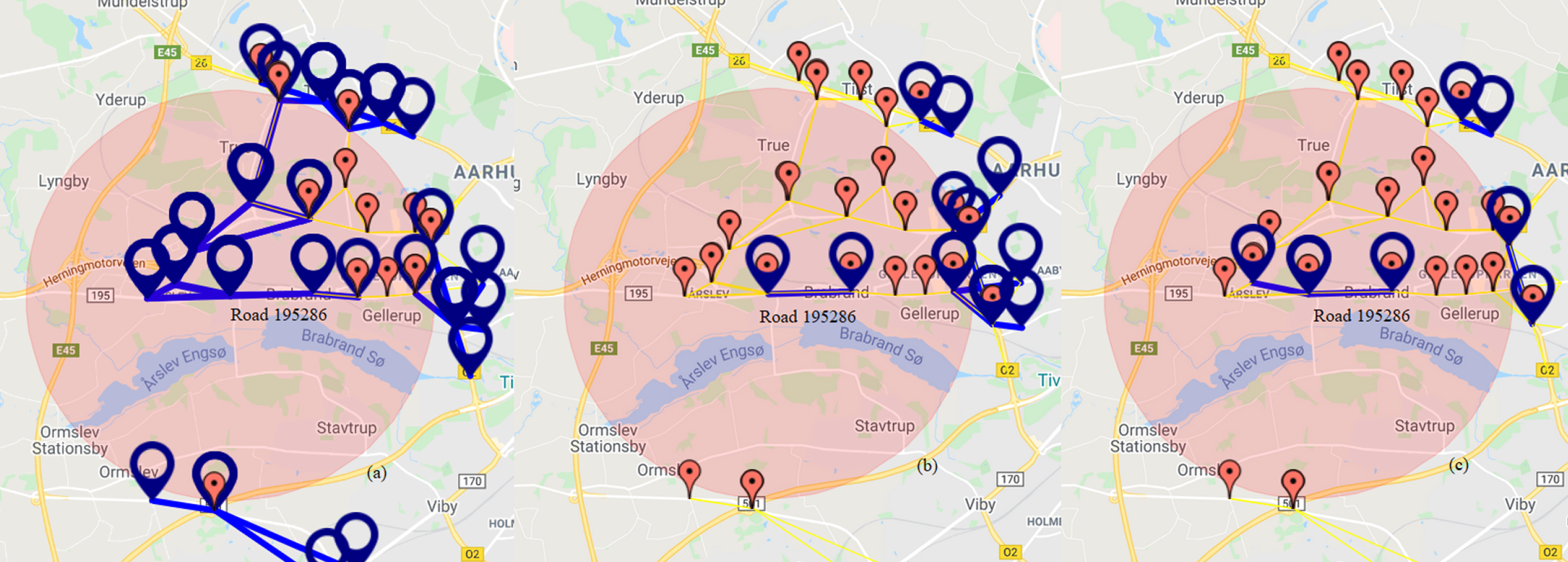
Traffic pattern on road 195286, (a) clustering with k-means, (b) clustering with GLCM and k-means, (c) high Pearson correlation value.
Figure 11 shows the results of clustering for location 201855. From Fig. 11, we observed that clustering using k-means obtained more roads when compared to clustering using GLCM. Clustering results of GLCM with k-means filtered more roads which have relationship with road 201855. Using Pearson correlation, we obtained one road that has correlation value above 0.5. All methods obtained roads outside 3.5km from road 201855, except when using Pearson correlation. However, the prediction accuracy (classification and regression) at location 201855 using clustering method is better when compared with Pearson correlation value.
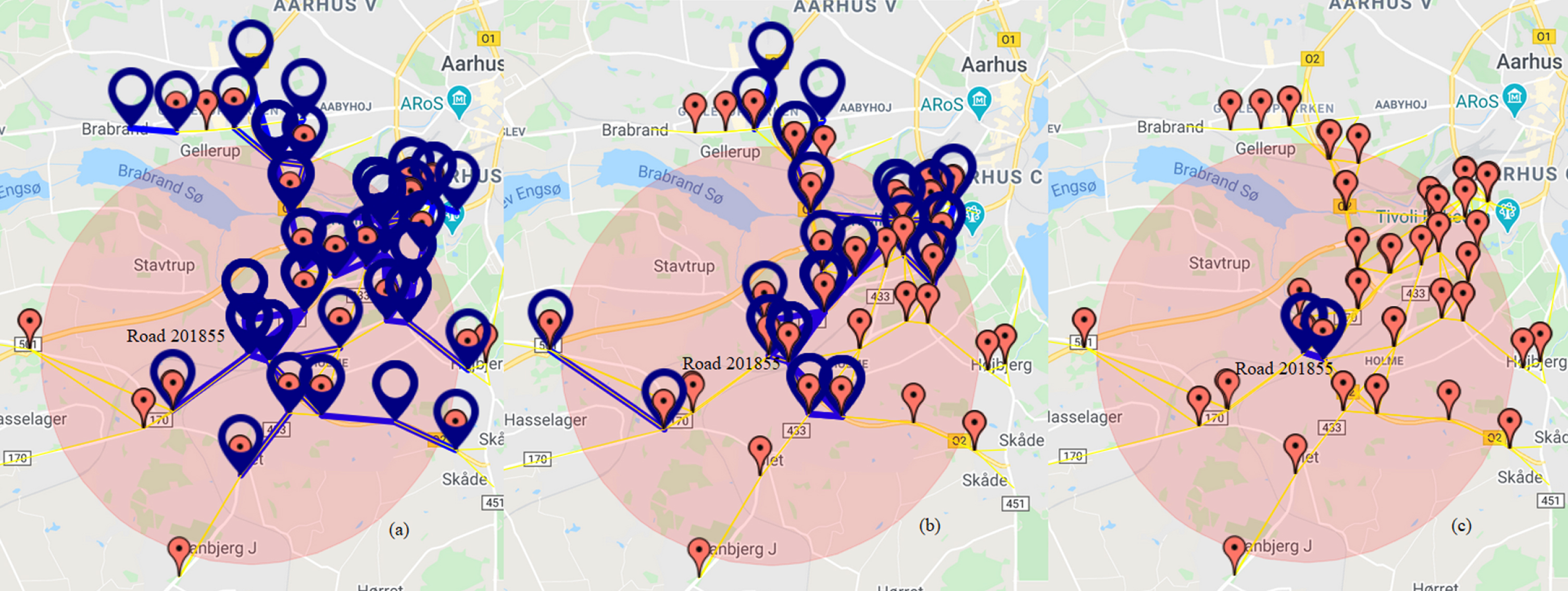
Traffic pattern on road 201855, (a) clustering with k-means, (b) clustering with GLCM and k-means, (c) high Pearson correlation value.
The neighbouring roads obtained by clustering method are then used for prediction of traffic state using K-NN. The prediction results of traffic state at location 158536 are presented in Table 5. The summary of traffic state predictions and prediction of average speed (regression) for all location are presented in Table 6.
The result of prediction of road 158536, prediction of traffic state (classification) and prediction of average speed (regression)
The results of prediction for all location, prediction of traffic state (classification) and prediction of average speed (regression)
The results of experiment for all locations show that clustering using combination of GLCM and k-means produce fewer neighbouring roads than clustering using k-means. See Fig. 12. From Fig. 12, it can be seen that the Pearson correlation failed to obtain 7 high correlation roads out of 10. This is because traffic flow is nonlinear. Thus, pattern recognition is needed to obtain the relationship between roads.

Number of high relationship roads among neighbouring roads obtained by different clustering method.
The average accuracy of prediction for traffic state (classification) of all roads using K-NN show that GLCM and k-means method performed the best when compared with k-means and Pearson correlation. This is shown in Fig. 13.
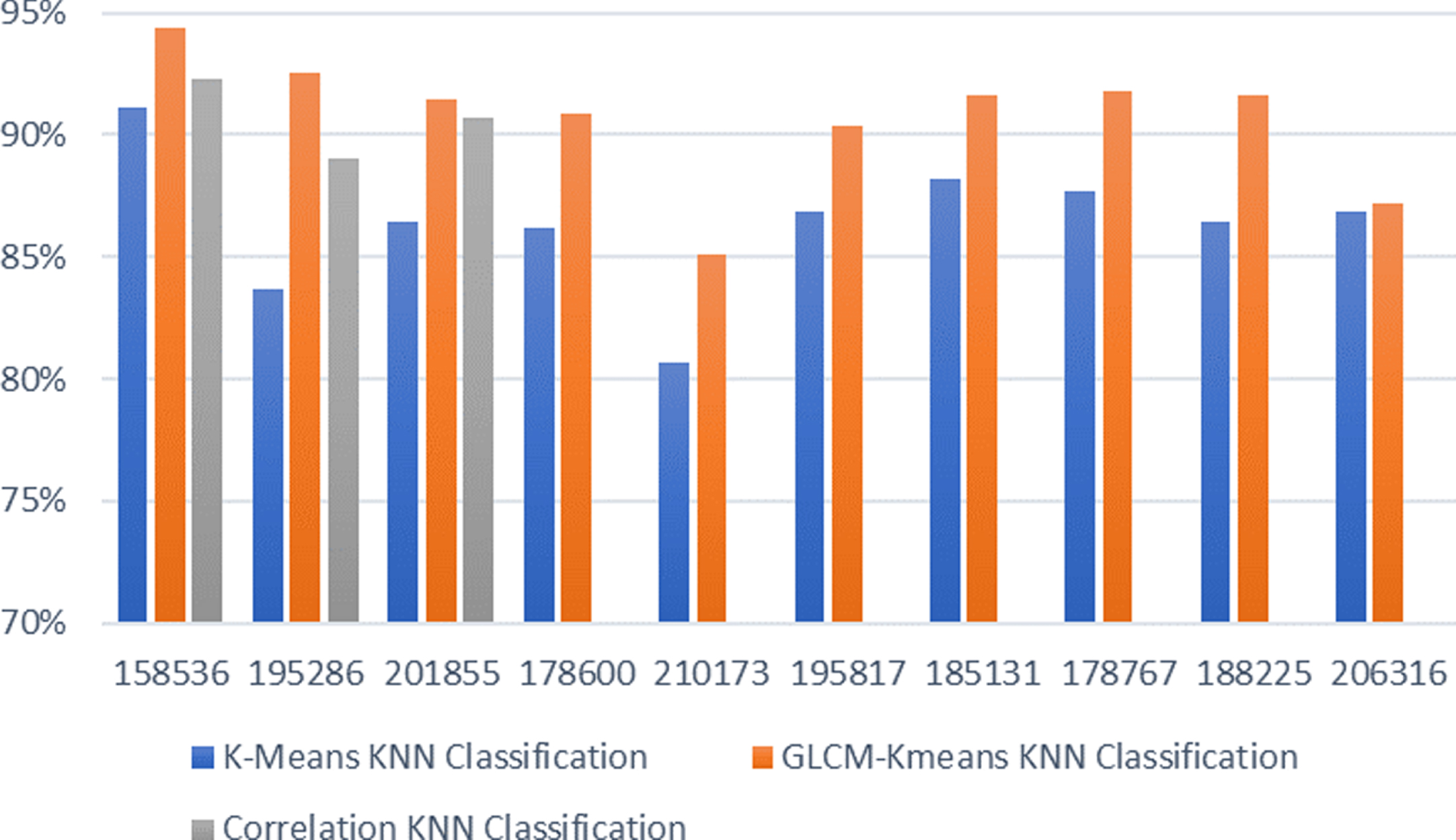
Comparison of traffic state prediction accuracy using the 3 methods for all locations.
To evaluate our findings, we calculate the prediction of average speed (regression). The results show that our proposed GLCM with k-means has better performance in predicting average speed using linear regression or KNN regression. This is shown in Fig. 14 and Fig. 15.
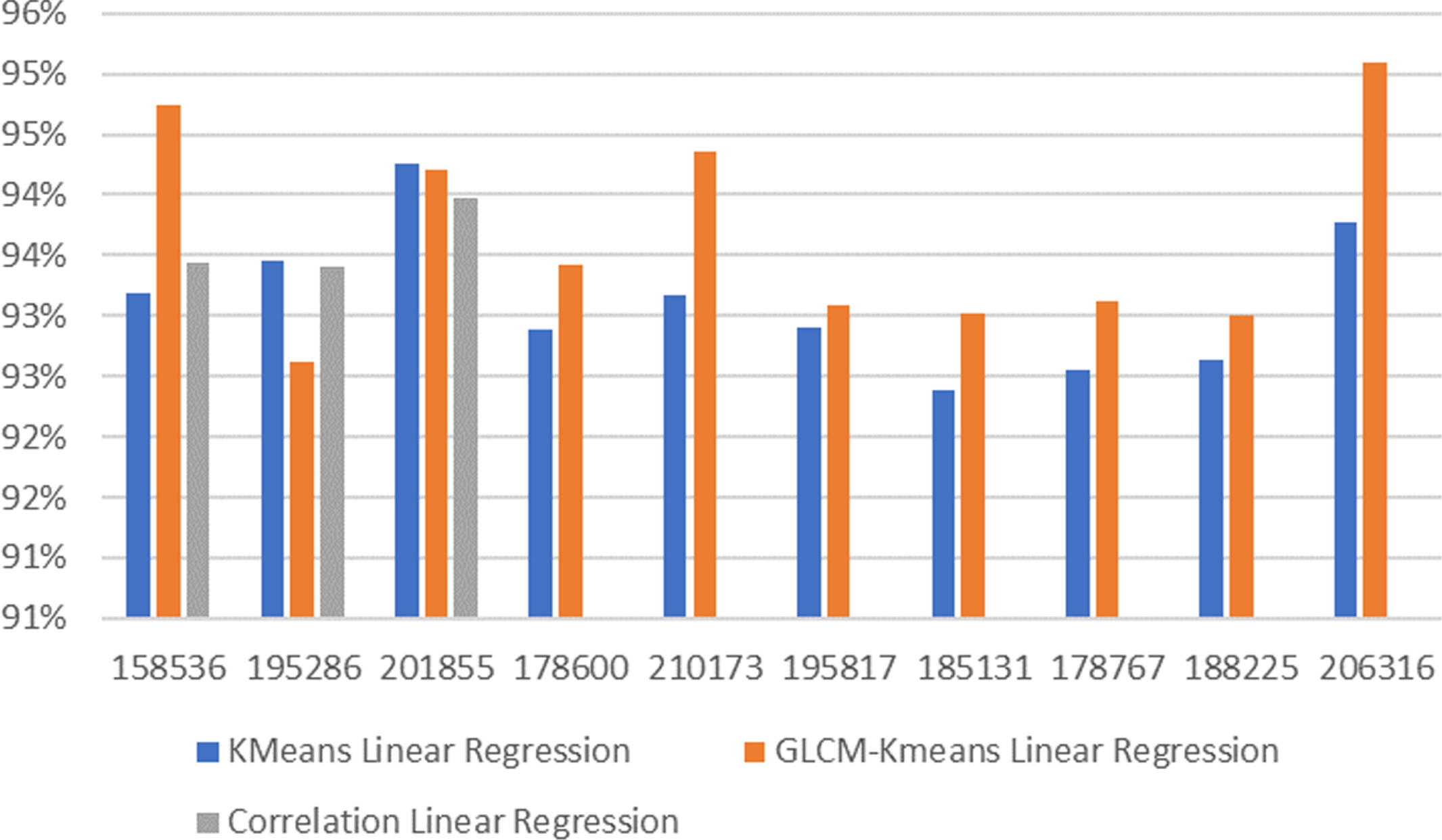
Comparison of average speed prediction accuracy using linear regression for all locations.
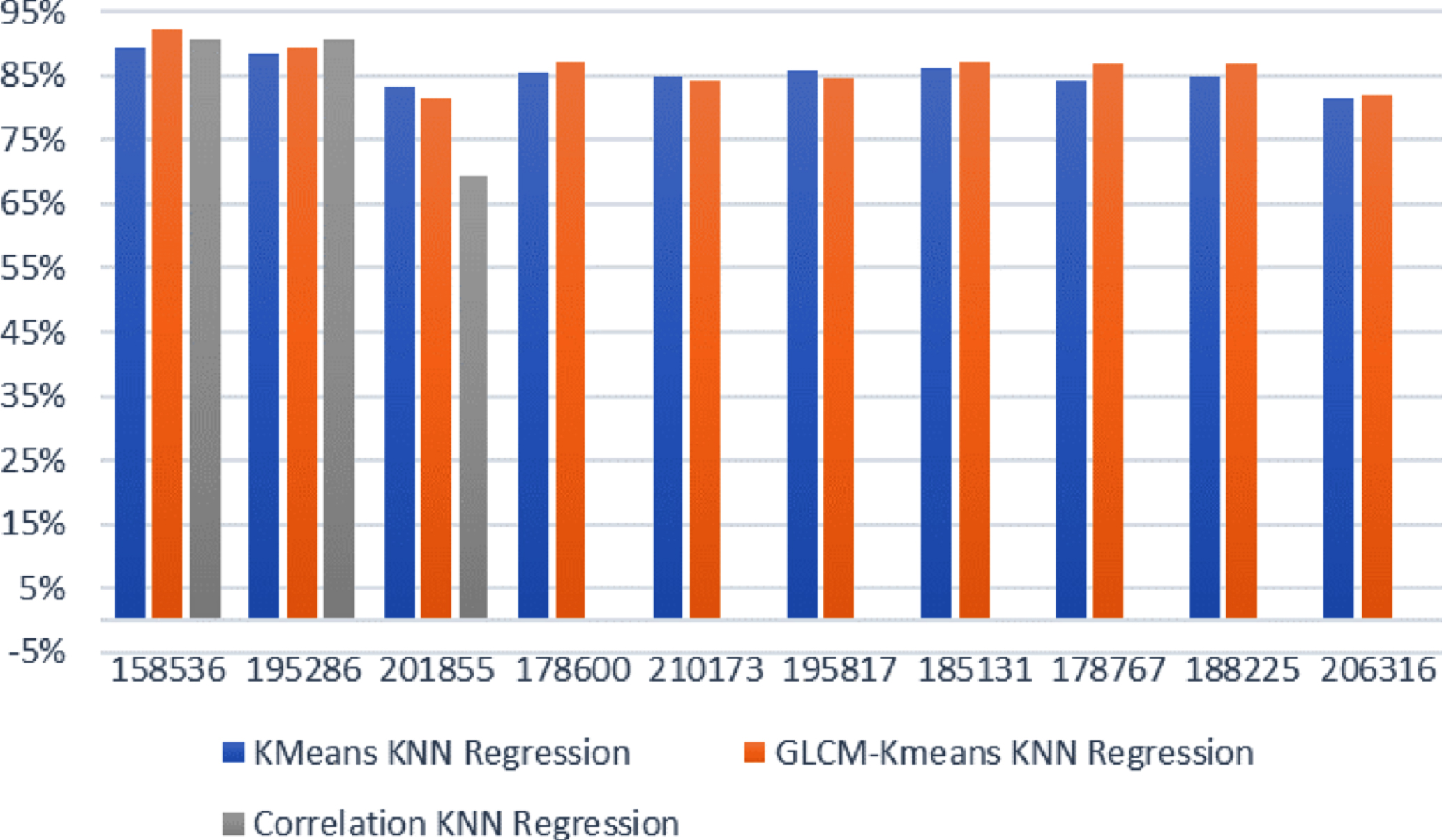
Comparison of the average speed prediction accuracy using knn regression for all locations.
Furthermore, the experimental results show that the high relationship roads obtained from GLCM with k-means improve prediction results for both traffic state (classification) and average speed (regression).
The main aim of our experiments in this study is to predict traffic state using K-NN based on highest relationship neighbouring roads. Highest relationship road is identified by obtaining the pattern of traffic congestion during day and time at a neighbouring area. We used the grey level co-occurrence matrix (GLCM) to extract the pattern of traffic congestion. GLCM is a method that has been widely used for pattern recognition. By combining GLCM with k-means, it improves the results in obtaining high relationship roads. Thus, prediction of traffic state based on combining GLCM with k-means produce better results when compared with the predictions based on Pearson correlation and k-means. Our experiments show that finding roads with high relationship is important to increase the accuracy of traffic flow prediction. The higher the relationship between roads, the higher the average prediction accuracy. In the future, we will investigate three dimensional GLCM in finding the highest relationship between roads in a neighbouring area.
Footnotes
Acknowledgments
The authors would like to thank the Ministry of Higher Education (Malaysia) for funding this research work through Fundamental Research Grant Scheme (Project Code: FRGS/1/2018/ICT02/UKM/02/8). The authors would also like to extend the acknowledgement for the use of service and facilities of the Intelligent Visual Data Analytics Lab at IIR4.0, Universiti Kebangsaan Malaysia.